目录
编码说明
Base64 是一种基于 64 个可打印字符来表示二进制数据的表示方法,由于 2^6=64,所以每 6 个比特为一个单元,对应某个可打印字符。
Base64 常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据,包括 MIME 的电子邮件及 XML 的一些复杂数据。
项目中遇见处理字节数组与string互转时,如不指定字符集,会导致字符数组长度有变的问题,后文demo里说
Base64 编码要求把 3 个 8 位字节(3*8=24)转化为 4 个 6 位的字节(4*6=24),之后在 6 位的前面补两个 0,形成 8 位一个字节的形式。 如果剩下的字符不足 3 个字节,则用 0 填充,输出字符使用 =,因此编码后输出的文本末尾可能会出现 1 或 2 个 =。
为了保证所输出的编码位可读字符,Base64 制定了一个编码表,以便进行统一转换。编码表的大小为 2^6=64,这也是 Base64 名称的由来。
在 Base64 中的可打印字符包括字母 A-Z、a-z、数字 0-9,这样共有 62 个字符,此外两个可打印符号在不同的系统中而不同(+ 和 /,还有=)。
Base64是一种索引编码,每个字符都对应一个索引,具体的关系图,如下

编码方式
由于64等于2的6次方,所以一个Base64字符实际上代表着6个二进制位(bit)。
然而,二进制数据1个字节(byte)对应的是8比特(bit),因此,3字节(3 x 8 = 24比特)的字符串/二进制数据正好可以转换成4个Base64字符(4 x 6 = 24比特)。
为什么是3个字节一组呢? 因为6和8的最小公倍数是24,24比特正好是3个字节。
具体的编码方式:
-
将每3个字节作为一组,3个字节一共24个二进制位
-
将这24个二进制位分为4组,每个组有6个二进制位
-
在每组的6个二进制位前面补两个00,扩展成32个二进制位,即四个字节
-
每个字节对应的将是一个小于64的数字,即为字符编号
-
再根据字符索引关系表,每个字符编号对应一个字符,就得到了Base64编码字符

上图中的字符串 'you',经过转换后,得到的编码为: 'eW91'。
体积增大
我们可以看到,当3个字符进行Base64转换编码后,最后变成了4个字符。因为每个6比特位,都补了2个0,变成8比特位,对应1字节。
这里正好多了三分之一,所以正常情况下,Base64编码的数据体积通常比原数据的体积大三分之一。
= 等号
3个英文字符,正好能转成4个Base64字符。那如果字符长度不是3的倍数,那应该使用什么样的规则呢?
其实也简单,我们在实际使用Base编码时,常会发现有第65个字符的存在,那就是 '=' 符号,这个等于号就是针对这种特殊情况的一种处理方式。
对于不足3个字节的地方,实际都会在后面补0,直到有24个二进制位为止。
但要注意的是,在计算字节数时,会直接使用总长度除以3,如果余数为1则会直接在最后补一个=,如果余数为2则补两个=。
因此,转码后的字符串需要补的后缀等号,要么是1个,要么是2个,具体的可以见下图:
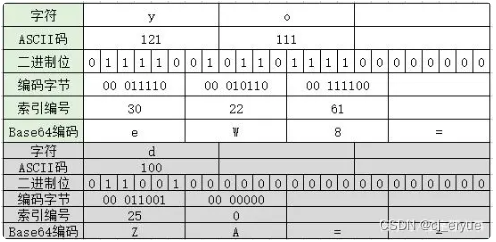
图中第二个,使用的是单独的字符 'd',是为了区分索引字符表里的索引0,这个时候,得到编码中,会存在一个索引0对应的A字符,而'='是直接补上2个。
demo
package com.cjian.security;
import com.sun.org.apache.xerces.internal.impl.dv.util.Base64;
import java.security.SecureRandom;
/**
* @Author: cjian
* @Date: 2022/11/9 17:09
* @Des:
*/
public class Base64Demo {
public static Base64 base64 = new Base64();
public static void main(String[] args) {
String man = base64.encode("you".getBytes());
System.out.println("you的base64结果:"+man);
SecureRandom secureRandom = new SecureRandom();
byte[] randomBytes = new byte[16];
secureRandom.nextBytes(randomBytes);
String str = new String(randomBytes);
System.out.println("原值:" + str);
//问题来了,长度发生了变化
//如果转string和获取字节的时候指定ISO-8859-1就没有问题
System.out.println("原值转byte长度:"+str.getBytes().length);
String r = base64.encode(randomBytes);
System.out.println("base64后:" + r);
String str2 = new String(base64.decode(r));
System.out.println("base64编码:" + str2);
System.out.println("base64解码后byte长度:" + base64.decode(r).length);
}
}
输出:
you的base64结果:eW91
原值:�;Ķp�K�n�ώ�|/
原值转byte长度:26
base64后:1DvEtnCSS55uFMPPjqp8Lw==
base64编码:�;Ķp�K�n�ώ�|/
base64解码后byte长度:16