目录
1.问题描述
最近在学强化学习,用parl和gym实现Pong游戏的策略梯度-REINFORCE算法,主要的代码参考paddle的parl的教程lesson4课程(具体链接:PARL/examples/tutorials/parl2_dygraph at develop · PaddlePaddle/PARL · GitHub)
但在写代码的过程中遇到了一个问题,在其他代码没有任何问题的情况下,运行train.py
env.step()函数会出现:ValueError: too many values to unpack (expected 4)
2.问题分析
首先排除env.step(action)的传入参数没有问题,那问题只能出现在env.step(action)的执行和返回的过程中(在分析问题的过程中,我参考这个博主的帖子:pytorch报错ValueError: too many values to unpack (expected 4)_阮阮小李的博客-CSDN博客)
(1)env.step()的返回值问题
我通过gym的官网文档(Core - Gym Documentation),查看了env.step()的返回值定义。

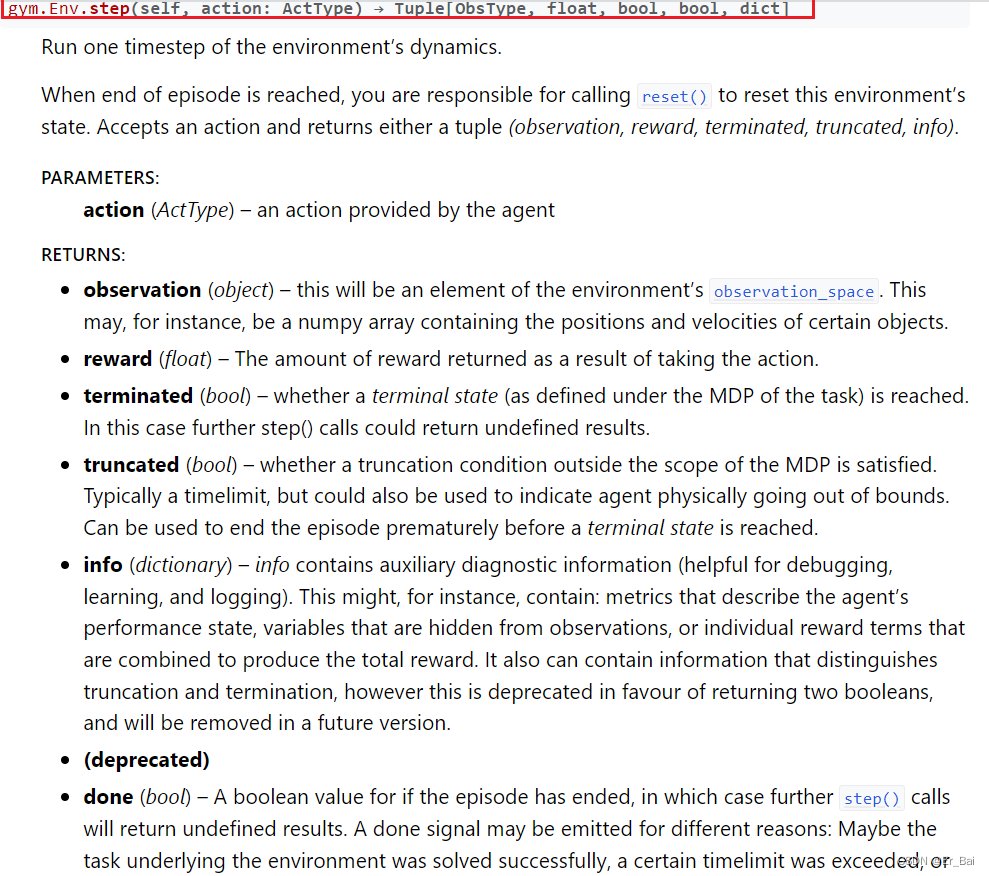
并将train.py代码中的这句话
obs, reward, done, _ = env.step(act)修改为
obs, reward, done, _, _, _ = env.step(act)结果是问题没有解决!
(2)ale-py包问题
因为在这之前,我之前学习的过程中也编写好了其他算法和gym游戏的代码,测试过多次是可以跑通的,在这个错误出现后,我第一时间运行了之前的代码,出现了一模一样的错误,我突然想起来因为在创建Pong游戏环境时,会提示Pong游戏被gym转移到ale-py,所以pip install ale-py安装了ale-py,所以问题就出现在ale-py这个功能包!
env = gym.make('Pong-v4')3.问题解决
使用pip list命令检查gym和ale-py的版本,我的ale-py版本是0.8.0(pip中可安装的最新版本是0.8.0),而我的gym是0.22.0(此时pip可安装的最新版本是0.26.2),我意识到是ale-py版本太高的问题,最后把ale-py的版本重装为0.7.2,问题解决,并且提示我obs, reward, done, _, _, _ = env.step(act)这句话有问题,因为只需要4个输入参数,修改之后问题解决!
4.总结
总结来说就是ale-py的版本太高,不适配gym版本。