前言
这种应用好像比较冷门哈哈,整体需求是有xml文件,如下所示:
<annotation>
<folder>标注前</folder>
<filename>1080.jpg</filename>
<path>x\1080.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>720</width>
<height>480</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>394</xmin>
<ymin>91</ymin>
<xmax>516</xmax>
<ymax>311</ymax>
</bndbox>
</object>
</annotation>
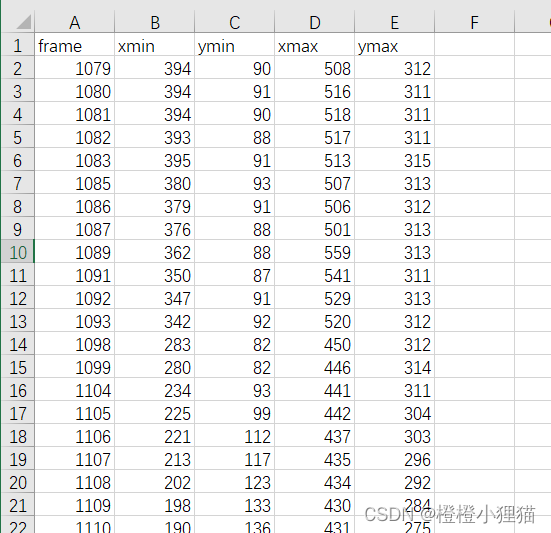
获取这个文件中filename、xmin、ymin、xmax和ymax标签中的值,并将这些值成为表格的样式,如下所示:

转换代码
import os
import pandas as pd # 存储为csv文件的库
import xml.dom.minidom # 读取xml文件的库
import numpy as np
class xml2csv:
def __init__(self, raw_data_dir):
self.csv_date = pd.DataFrame(columns=['frame', 'xmin', 'ymin', 'xmax', 'ymax'])
self.raw_data_dir = raw_data_dir
self.arr_data = np.zeros((1, 5))
def convert(self):
xml_data = os.listdir(self.raw_data_dir)
xml_data = sorted(xml_data, key=lambda x: next((int(num), text) for num, text in [x.split('.')])) # 我需要按顺序存储,所以进行排序
for one_file in tqdm(xml_data):
# 读取xml文件
dom = xml.dom.minidom.parse(os.path.join(self.raw_data_dir, one_file))
element = dom.documentElement
filename = element.getElementsByTagName('filename')[0]
xmin = element.getElementsByTagName('xmin')[0]
ymin = element.getElementsByTagName('ymin')[0]
xmax = element.getElementsByTagName('xmax')[0]
ymax = element.getElementsByTagName('ymax')[0]
# 将文件中所需要的值添加到DataFrame中
self.arr_data[0][0] = filename.childNodes[0].data.split('.')[0]
self.arr_data[0][1] = xmin.childNodes[0].data
self.arr_data[0][2] = ymin.childNodes[0].data
self.arr_data[0][3] = xmax.childNodes[0].data
self.arr_data[0][4] = ymax.childNodes[0].data
# 追加方式填充上数据
one_row_data = pd.DataFrame(self.arr_data, columns=['frame', 'xmin', 'ymin', 'xmax', 'ymax'])
self.csv_date = pd.concat([self.csv_date, one_row_data], ignore_index=True)
def save_date(self, save_dir):
self.csv_date.to_csv(os.path.join(save_dir, 'annotation_data.csv'), index=False) # index=False不显示行名
if __name__ == '__main__':
# 读取源文件
xc = xml2csv(r'../Annotations/') # 写入xml文件的路径
# 进行转化
xc.convert()
# 存储文件
xc.save_data(r'.') # 用于存储的路径
运行效果
源文件
目标格式
版本记录
20230321:
- 将
xml_data.sort()改写为xml_data = sorted(xml_data, key=lambda x: next((int(num), text) for num, text in [x.split('.')]))
说明:在原来的脚本中,不能有效对文件进行排序,比如"101.xml"和"23.xml","23.xml"会排在"101.xml"的后面,原因可能为对字符串排序方法根据ascii码,而实际需要根据文件的数字排序,参考博文Python 使用Lambda对list(列表)中指定格式字符串元素排序方法,目前掌握了lambda匿名函数,但对于代码中的next()还不是很理解。 - append改成了concat,不会再有警告
- 设置了tqdm进度条