版本:JDK 11
为了这篇文章,我已经废了,太绕了。我能力有限,没法保证说的清楚。
前提是看官对这块了解一些,尤其是某些概念,比如 CAS、队列、线程生命周期等。
另外注意:这是纯 AQS 源码解析,没有结合实际子类和使用场景,所以理解起来很困难。后期我会再对 AQS 的子类进行解析,加强理解。
1.什么是 AQS?
AQS 是 AbstractQueuedSynchronizer 缩写,译为抽象队列同步器。
顾名思义,有抽象就有实现,为了什么而抽象很重要。
- 抽象:定义了资源获取的通用逻辑,要求子类实现不同场景下对同步状态的维护。
- 队列:如果请求的资源被占用,那么请求的线程就需要一套阻塞等待以及唤醒的机制。而这个机制,AQS 是用 CLH 队列来实现的,将暂时拿不到锁的线程放到队列中。
- 同步器:如果不看队列,那其实就是“抽象同步器”。即定义了同步工具和锁的基础框架,基于 AQS 能够简单高效地构建出自定义的同步工具:诸如 ReentrantLock、Semaphore 等等。
2.AQS 原理
同步器一般会提供两个操作,acquire 和 release。acquire 阻塞调用线程,直到或除非同步状态允许;release 更改同步状态,使得一个或多个被 acquire 阻塞的线程继续执行。对应引用 [1] 中的伪代码:
acquire:
while (synchronization state does not allow acquire) {
enqueue current thread if not already queued;
possibly block current thread;
}
dequeue current thread if it was queued;
release:
update synchronization state;
if (state may permit a blocked thread to acquire)
unblock one or more queued threads;
AQS 实现的一系列类,实际都是基于两个操作去统一抽象概念,比如 Lock.lock 和 unlock、Semaphore.acquire 和 release 等。
简单来看,如果需要实现上面这样的流程,就又回到了 AQS 至少需要提供的能力以及他们之间的协作:
- 同步状态的原子性管理
- 线程的阻塞和解除阻塞
- 阻塞线程的排队
而 AQS 基于这些能力,又会延伸出:
- 可中断;
- 超时控制;
- Condition,用于支持管程形式的 await/signal 操作。
而同步器对于同步状态的控制会有两种实现(或者说两种管理方式):独占模式和共享模式。

3.核心结构
3.1 同步状态
通过对 同步状态的管理,来标识共享资源能够被获取。
因为涉及到多个线程可能回去尝试操作同步状态,所以两个很关键的点:volatile 和 CAS。
可以注意到操作方法是 protected,这是因为 state 的具体含义是由子类去定义以及操作的,比如代表资源数量、锁的状态等。
- 对于 ReentrantLock中子类 Sync,state 表示线程加锁次数(0表示未加锁,否则表示被同一个线程加锁了多少次-可重入性)
- 对于 ReentrantReadWriteLock 来说,state 的高 16 位表示线程对读锁的加锁次数,低 16 位表示线程对写锁的加锁次数(读锁、写锁也分别是可重入的,并且会有互斥性)
- 对于 Semaphore 来说,state 表示其可用信号量,简短不严谨的说法可以是:代表可以获取的资源数量。
- 对于 CountDownLatch 来说,state 表示锁闩还有多少道“锁”(现实意义的锁,不是代码中的 Lock 或 synchronied 关键字代表的),可以实现多个线程执行解锁后 state 变为0,标识该锁闩被打开(对应阻塞的线程此时才能被释放执行)。
/**
* The synchronization state.
*/
private volatile int state;
// 返回同步状态的当前值。
protected final int getState() {
return state;
}
// 设置同步状态的值。
protected final void setState(int newState) {
state = newState;
}
// 如果当前状态值等于期望值,则以原子方式将同步状态设置为给定的更新值。
protected final boolean compareAndSetState(int expect, int update) {
return STATE.compareAndSet(this, expect, update);
}
3.2 线程阻塞及唤醒
线程阻塞和唤醒,主要是靠 LockSupport 类进行操作。该类是对 Unsafe# park & unpark 的一层封装,在此基础上允许超时的方法。
park 会阻塞线程,直到或除非 unpark。
- 在调用 park 之前,调用了 unpark,那么 park 就没啥用了;
- unpark 的调用是没有被计数的,因此在一个par 调用前多次调用 unpark 方法只会解除一个 park 操作。
3.3 独占模式下的线程保存
Node 关联的线程标识的是资源被占有时等待的线程,那一定就有一个已经占有资源的线程。而 AQS 的父类 AbstractOwnableSynchronizer起到的就是这个作用,源码很简单,只为维护这个独占的线程:
public abstract class AbstractOwnableSynchronizer implements java.io.Serializable {
protected AbstractOwnableSynchronizer() {
}
private transient Thread exclusiveOwnerThread;
protected final void setExclusiveOwnerThread(Thread thread) {
exclusiveOwnerThread = thread;
}
protected final Thread getExclusiveOwnerThread() {
return exclusiveOwnerThread;
}
}
3.4 CLH 队列变体
CLH 锁即 Craig, Landin, and Hagersten (CLH) locks,因为它底层是基于队列(即严格的先进先出)实现,一般也称为 CLH 队列锁。CLH 锁也是一种基于链表的可扩展、高性能的锁,一般用于自旋锁。
第一个变化-结点的链接
CLH 锁的结点通过 pred (原版没有,自旋锁应用场景有) 维护了前驱结点的位置,通过自旋判断前驱结点的状态,来判断当前结点。
入队只用基于 tail 判断竞争和操作;反之出队,只用基于 head。
+------+ prev +-----+ +-----+
head | | <---- | | <---- | | tail
+------+ +-----+ +-----+
这种设计的好处在于,区别于结点之间无关联的普通队列,AQS 可以借助 CLH 锁来处理“超时”和“取消”:在前驱结点超时或取消时,可以通过 pred 往更前“未取消”的结点链接上。(原来的用途是往前一个结点,去使用它的状态字段。)
而这样还不够,CLH 锁在前一个前一个结点状态改变时,下一个结点一定会基于自旋感知到。但是在 AQS 中,还需要维护后驱节点 next,来实现显式唤醒下一个结点(线程)。
如果 next 为空(可能是被取消了),就从 tail 往前找,看看有没有真正的下一结点。
第二个变化-结点属性
原先的结点属性用于判断自旋,而在 AQS 中最重要的线程阻塞、唤醒,即是结点之间的通信。所以,要求结点的状态会更加丰富,来用于独占、共享模式下,可能还有 condition 情况的结点间通信。
4 CLH 队列变体结构
4.1 队列结构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V111JxLl-1616247740859)(/Users/jry/Downloads/code-snapshot (3)].png)
Node 定义了 CLH 队列的结构,可以看到相对于原本的 CLH 队列,还是有很大不同的:
-
waitStatus:标识当前(与原 CLH 最大的不同)结点的状态,列举了所有状态常量来进行设置。
状态之间的流转后面进行详细分析;尤其是负值状态涉及到线程之间的通信。
-
prev、next:前驱以及后继结点;
-
thread:一个结点其实就是一个“等待”的线程。
-
SHARED、EXCLUSIVE:Node实例,用来表示占有模式(共享或独占)。可能设置在 nextWaiter 上。
-
nextWaiter:表示在 condition 上的下一个等待节点;或者是 SHARED 标识共享。自然就不存在等待了。
如果没有值,那就最简单了,标识独占模式。
-
CLH 原会有个虚拟头结点,但是在 AQS 中头结点是延迟到第一次竞争时懒加载的;(同理,尾结点也是,只是一开始头尾是一样的。)
剩下还有重要变量的操作句柄以及对应 CAS 的操作,知道有这个东西就行:
// 其实底层用的还是 Unsafe
private static final VarHandle NEXT;
private static final VarHandle PREV;
private static final VarHandle THREAD;
private static final VarHandle WAITSTATUS;
static {
try {
MethodHandles.Lookup l = MethodHandles.lookup();
NEXT = l.findVarHandle(Node.class, "next", Node.class);
PREV = l.findVarHandle(Node.class, "prev", Node.class);
THREAD = l.findVarHandle(Node.class, "thread", Thread.class);
WAITSTATUS = l.findVarHandle(Node.class, "waitStatus", int.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
}
最终,AQS 整体的数据结构中实际存在两个队列:同步等待队列(代码中提到的名称是 SyncQueue),以及基于这个结构实现的条件队列(nextWaiter:ConditionQueue)。简单来说就是下面这样的:
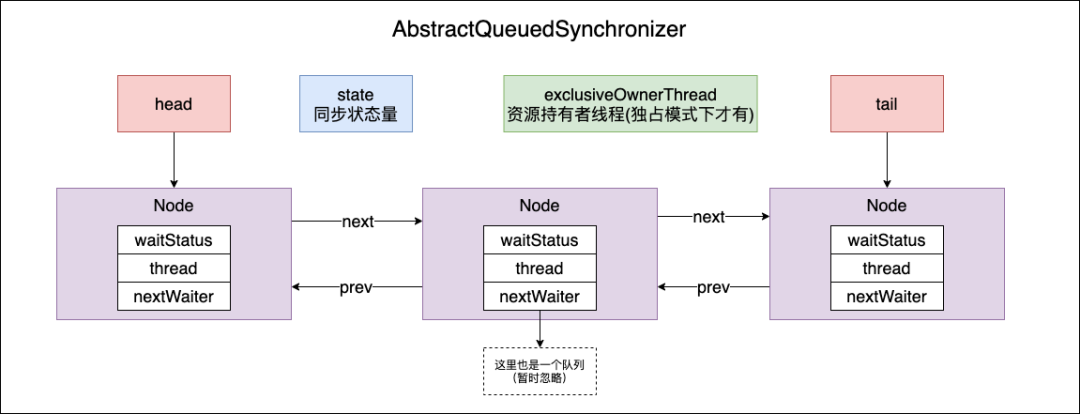 (图源来自:https://blog.csdn.net/y4x5M0nivSrJaY3X92c/article/details/112645551)
(图源来自:https://blog.csdn.net/y4x5M0nivSrJaY3X92c/article/details/112645551)
4.2 SyncQueue
SyncQueue 是等待 state 资源的阻塞队列,是 AQS 负责处理的领域,抽象、规范了一套以阻塞线程为结点,将入队出队操作关联线程阻塞、唤醒、传播的队列。
// 延迟初始化;或者通过 setHead() 设置
// 状态一定不会是 CANCELLED
// 头结点是虚拟结点, 所以一定不会关联线程
private transient volatile Node head;
// 延迟初始化;只能通过 enq() 添加新的结点
private transient volatile Node tail;
// 用于结点出队, 所以这个节点就没用了, 用来设为 head
// 仅通过acquire方法调用, 成功就是获取到资源了, 不用排队了
// 所以对应到上文中, 头结点的状态不会是 CANCELLED
private void setHead(Node node) {
head = node;
// 自然就不关联线程了
node.thread = null;
node.prev = null;
}
// VarHandle mechanics
private static final VarHandle STATE;
private static final VarHandle HEAD;
private static final VarHandle TAIL;
static {
try {
MethodHandles.Lookup l = MethodHandles.lookup();
STATE = l.findVarHandle(AbstractQueuedLongSynchronizer.class, "state", long.class);
HEAD = l.findVarHandle(AbstractQueuedLongSynchronizer.class, "head", Node.class);
TAIL = l.findVarHandle(AbstractQueuedLongSynchronizer.class, "tail", Node.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
// Reduce the risk of rare disastrous classloading in first call to
// LockSupport.park: https://bugs.openjdk.java.net/browse/JDK-8074773
Class<?> ensureLoaded = LockSupport.class;
}
private final void initializeSyncQueue() {
Node h;
// 设置虚拟头结点, 头尾相同
if (HEAD.compareAndSet(this, null, (h = new Node())))
tail = h;
}
// CAS 设置 tail
private final boolean compareAndSetTail(Node expect, Node update) {
return TAIL.compareAndSet(this, expect, update);
}
结点入队时,表示已经被占用了,或者耗尽。继续尝试获取的线程则进行排队,而加入队列时,如果队列未曾初始化,会优先初始化队列(主要是因为 head 是虚拟结点)。
// 结点入队; 首次则初始化
// 主要用于 ConditionQueue 中
private Node enq(Node node) {
// 循环 + CAS
for (;;) {
Node oldTail = tail;
if (oldTail != null) {
node.setPrevRelaxed(oldTail);
// 尾结点的设置可能存在竞争, 所以需要 CAS
if (compareAndSetTail(oldTail, node)) {
oldTail.next = node;
return oldTail;
}
} else {
// 相当于头尾皆空, 第一次入队
initializeSyncQueue();
}
}
}
// 主要用于 SyncQueue 的入队
private Node addWaiter(Node mode) {
// 不同于 enq, node 代表是预设的 EXCLUSIVE 或 SHARED.
// 标识"独占" or "共享"
Node node = new Node(mode);
for (;;) {
Node oldTail = tail;
if (oldTail != null) {
node.setPrevRelaxed(oldTail);
if (compareAndSetTail(oldTail, node)) {
oldTail.next = node;
return node;
}
} else {
initializeSyncQueue();
}
}
}
// 用于结点出队, 所以这个节点就没用了, 用来设为 head
// 仅通过acquire方法调用, 成功就是获取到资源了, 不用排队了
// 所以对应到上文中, 头结点的状态不会是 CANCELLED
private void setHead(Node node) {
head = node;
// 自然就不关联线程了
node.thread = null;
node.prev = null;
}
入队:
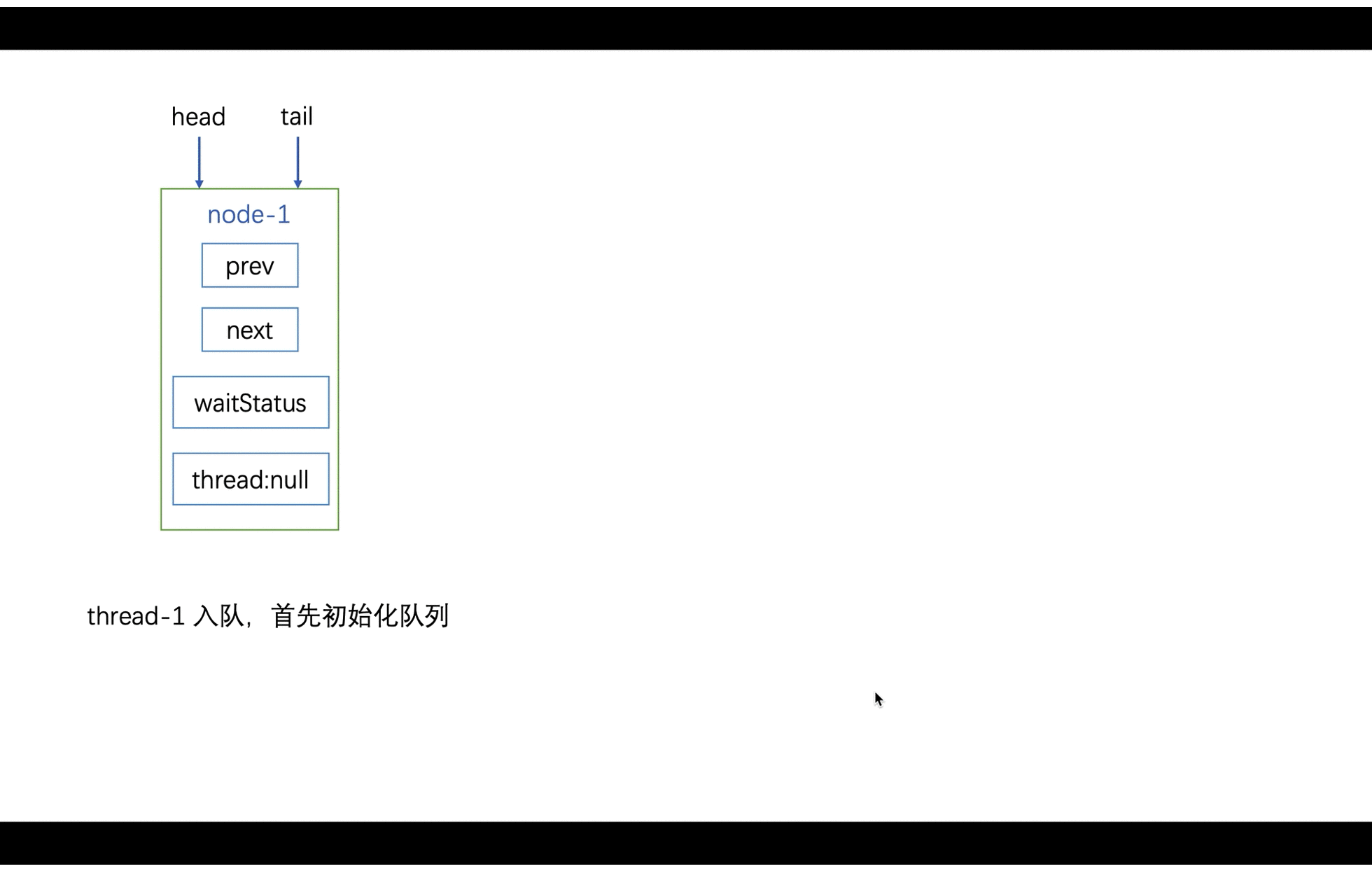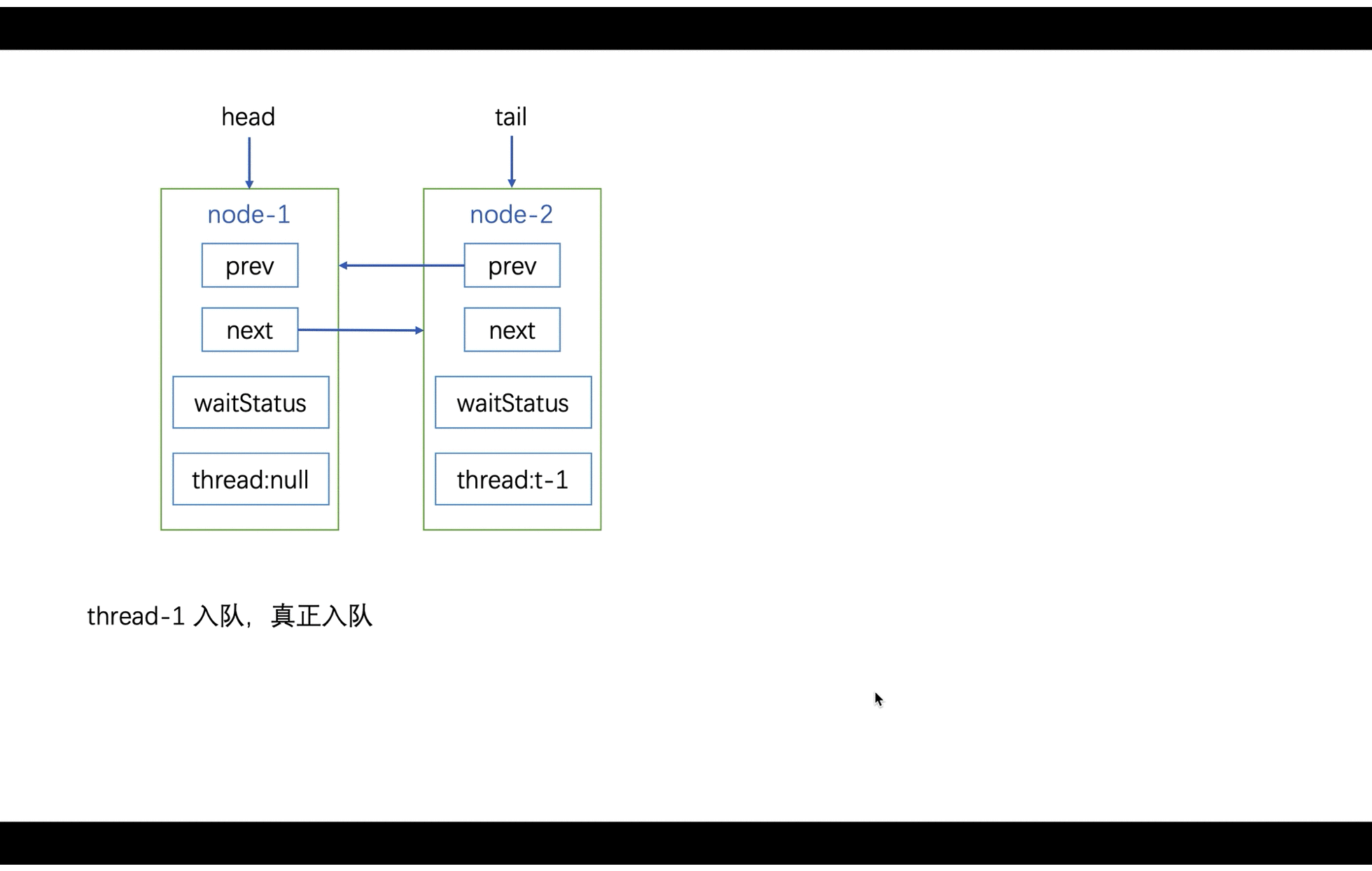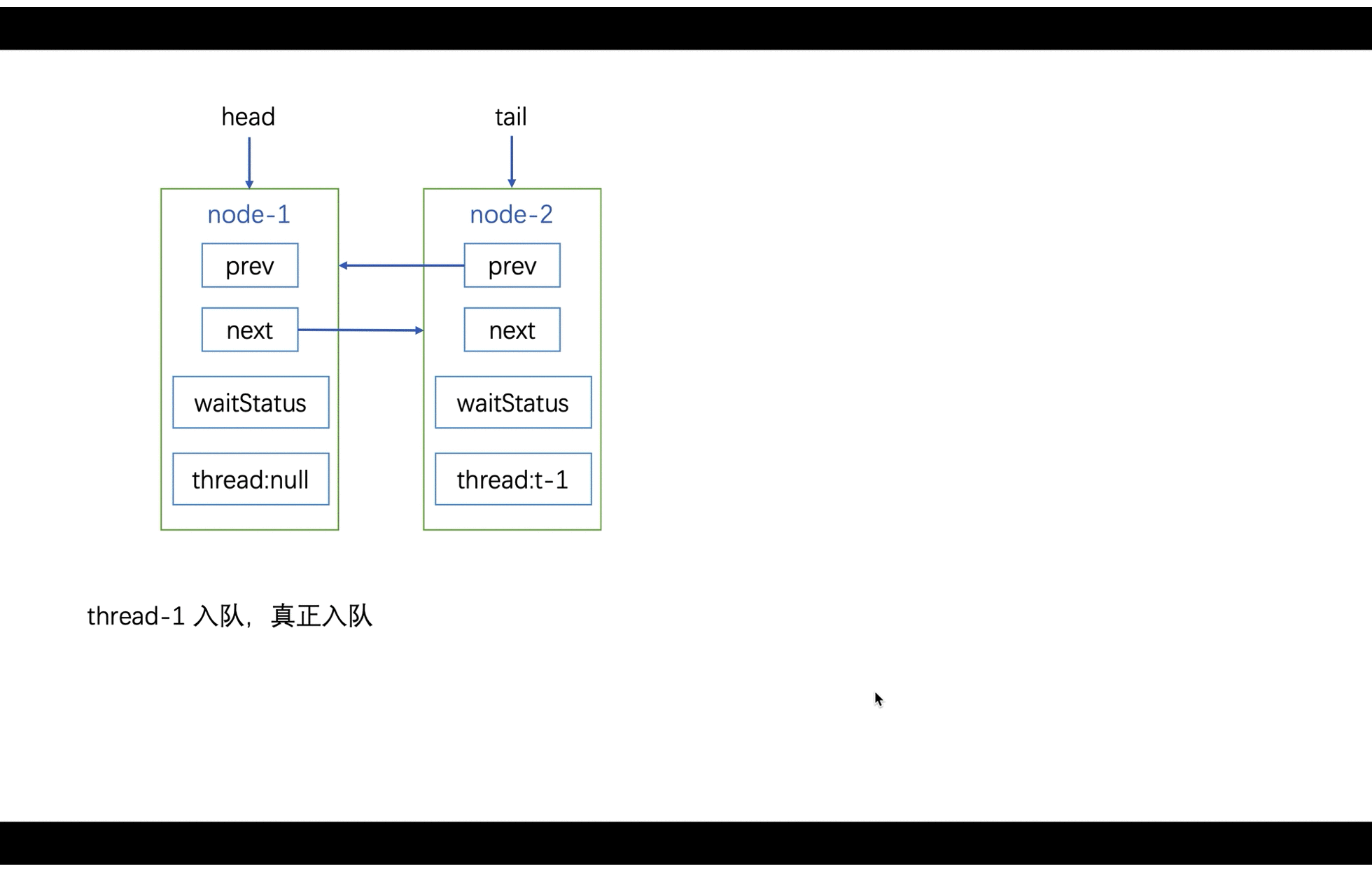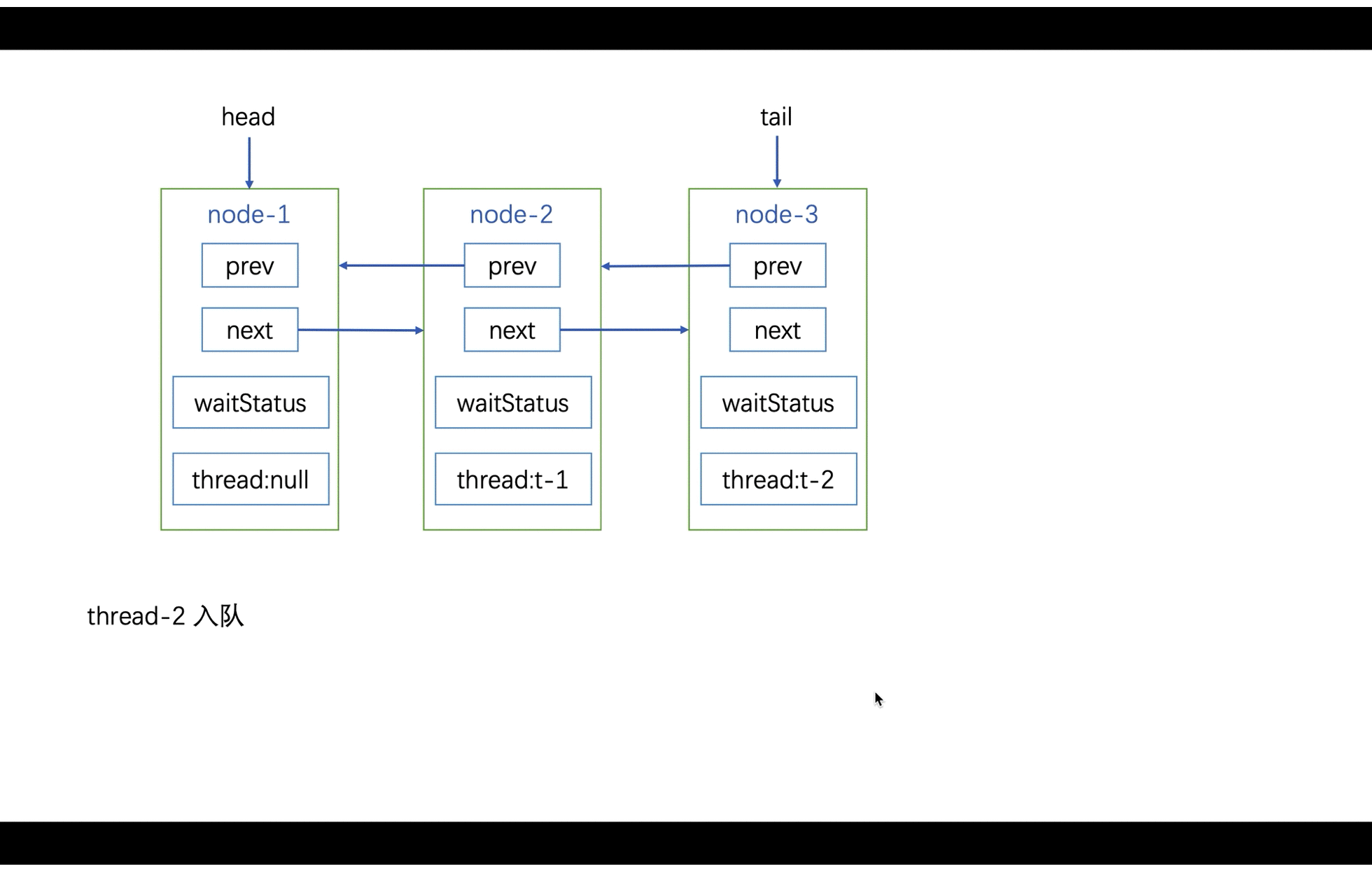
出队:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XotB6UpU-1616247740869)(https://gitee.com/ryan_july/clouding_img/raw/master/img/21312312413123.gif)]
4.3 ConditionQueue
ConditionQueue 是 AQS 中相对特殊、复杂的队列。相比较 SyncQueue 只把资源争抢、线程通信全部在 AQS 中处理,那ConditionQueue 就是为了对标 Object#wait、notify、notifyAll 而设计的数据结构,就是为了让开发人员可以手操线程同行。
ConditionQueue 是基于 SyncQueue的,或者说都是基于 Node 结构的。而它的操作入口,相信接触过 JUC 的同学应该都知道,那就是 Condition接口。
AQS 中的相关方法都在 ConditionObject,该类正是实现了 Conditon接口。
Condition 的等待方法中,反复提及“虚假唤醒”。建议在循环内使用等待方法,唤醒后重新判断条件是否满足。
public interface Condition {
// 当前线程进入等待状态直到被唤醒或者中断
void await() throws InterruptedException;
// 当前线程进入等待状态,不响应中断,阻塞直到被唤醒
void awaitUninterruptibly();
// 当前线程进入等待状态直到被唤醒或者中断,阻塞带时间限制
long awaitNanos(long nanosTimeout) throws InterruptedException;
// 当前线程进入等待状态直到被唤醒或者中断,阻塞带时间限制
boolean await(long time, TimeUnit unit) throws InterruptedException;
// 当前线程进入等待状态直到被唤醒或者中断,阻塞带时间限制
boolean awaitUntil(Date deadline) throws InterruptedException;
// 唤醒单个阻塞线程
void signal();
// 唤醒所有阻塞线程
void signalAll();
}
Condition 可以说目前只有唯一的实现类,那就是 AQS 的 ConditionObject,JUC 中的 Condtion都是使用的该类。来看看ConditionObject的源码,和 SyncQueue 一样,暂时只关注出入队的方法,方便理解队列结构。
public class ConditionObject implements Condition, java.io.Serializable {
private transient Node firstWaiter;
private transient Node lastWaiter;
public ConditionObject() {
}
// 每个 await 方法第一步就是调用该方法加入队列
private Node addConditionWaiter() {
if (!isHeldExclusively())
// 只有独占模式下,才有 Condition 的作用
throw new IllegalMonitorStateException();
Node t = lastWaiter;
// If lastWaiter is cancelled, clean out.
// 在 ConditionQueue 中,只要不是 CONDITION 状态, 都看做取消等待了.需要清除出去
if (t != null && t.waitStatus != Node.CONDITION) {
// 遍历清除"取消"结点
unlinkCancelledWaiters();
t = lastWaiter;
}
Node node = new Node(Node.CONDITION);
if (t == null)
firstWaiter = node;
else
t.nextWaiter = node;
lastWaiter = node;
return node;
}
// 一般都是在等待期间进行取消
// 1.插入新结点发现 lastWaiter 是取消的
// 2.线程被唤醒时, 如果后面还有等待的结点,就做一次处理
private void unlinkCancelledWaiters() {
Node t = firstWaiter;
Node trail = null;
while (t != null) {
Node next = t.nextWaiter;
if (t.waitStatus != Node.CONDITION) {
t.nextWaiter = null;
if (trail == null)
firstWaiter = next;
else
trail.nextWaiter = next;
if (next == null)
lastWaiter = trail;
}
else
trail = t;
t = next;
}
}
}
核心结构讲完了,AQS 所有的操作都是基于这么一个体系。其实从整体来看,也许我们已经摸索出了脉络:
- 1.获取资源,操作 state;
- 2.资源被占用了
- 2.1独占模式下,线程需要等待了,把线程包装成结点入队;
- 第一次入队,head 这个虚拟结点得先构建出来;
- 阻塞结点入队;
- 2.2 共享模式下,也许能够继续操作 state;
- 2.1独占模式下,线程需要等待了,把线程包装成结点入队;
- 3.怎么争抢到资源?
- 4.抢不动了,怎么退出?
- 5.资源被释放了,怎么唤醒排队的后续结点来抢呢?
- 6.那些抢不动跑路的,会不会影响其他人排队?
先来看看获取资源,操作 state 的方法
5.操作资源的模板 API
既然 AQS 只是个抽象框架,定义了同步器的标准流程和操作,剩下留给子类实现扩展的点,就是赋予 state 相关的实际含义,以及对应的操作(acquire 和 release,基于 AQS 对 state 的 CAS 方法)(包括独占和共享)。
isHeldExclusively()//该线程是否正在独占资源。只有用到 condition (AQS.ConditionObject)才需要去实现它。
tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。
tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。
tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。
这些方法都是 protected,且方法都throw new UnsupportedOperationException()。子类必须借助 state 的 CAS 方法,来实现这些方法,来赋予 state 在实际应用场景下的意义。
ps : 其他方法,要么 private,要么就是 final 的。
当然,并不一定要全部实现,还是基于子类场景。比如只用于独占模式的,那就不必实现共享模式的方法,比如 ReentrantLock;同理共享模式的也是不必实现独占方法,比如 Semaphore。
但也不限制都实现,比如 ReentrantReadWriteLock,写锁是独占,读锁是共享。
以 ReentrantLock 为例,state 初始化为 0,表示未锁定状态。A 线程 lock()时,会调用 tryAcquire()独占该锁并将 state+1。此后,其他线程 tryAcquire()时就会失败,直到 A 线程 unlock()到 state=0(即释放锁)为止,其它线程才有机会获取该锁。锁是可重入的,A 线程自己是可以重复获取此锁的(state 会累加)。但要注意,获取多少次就要释放多么次,这样才能保证 state 是能回到零态的。
再以 CountDownLatch 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个数一致)。主线程调用 await() (tryAcquireShared()) 阻塞。而每个子线程执行完后 countDown()(releaseShared(1))一次,state 会 CAS 减 1。等到所有子线程都执行完后(即 state=0),会 unpark() 主线程,然后主线程就会从 await()函数返回,继续后余动作。
6.获取、释放资源
AQS 本身 public 的方法是有限的,而这其中涉及到资源操作的只有 acquire 和 release 相关的方法,区分超时、中断等情况。
理论上说,子类如果没有特殊情况,只要正确定义了模板方法,那使用者可以直接利用 AQS 的公有方法来真正使用上并发工具。比如,ReentrantLock 的 lock、tryLock 以及 release 都是直接调用 AQS 的公有方法。
public void lock() {
sync.acquire(1);}
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
public boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(timeout));
}
public void unlock() {
sync.release(1);}
无论是 acquire 还是 release,都有两种模式,就是上文经常提及的独占和共享。
我们上文已经把两种最底层的操作:资源操作(子类实现)以及线程入队大致说了一下。
接下来,我们需要区分流程来梳理整个流程,将 AQS 的源码走一遍,涉及到线程唤醒、线程通信、资源竞争、状态流转等。
6.1 独占获取
6.1.1 流程总览
先把结论说了,那就是看图!注意,我不是深度搜索,是广度的。先把一个层次的方法解析了,因为都很相似,基本一致;然后一步一步层层递进。
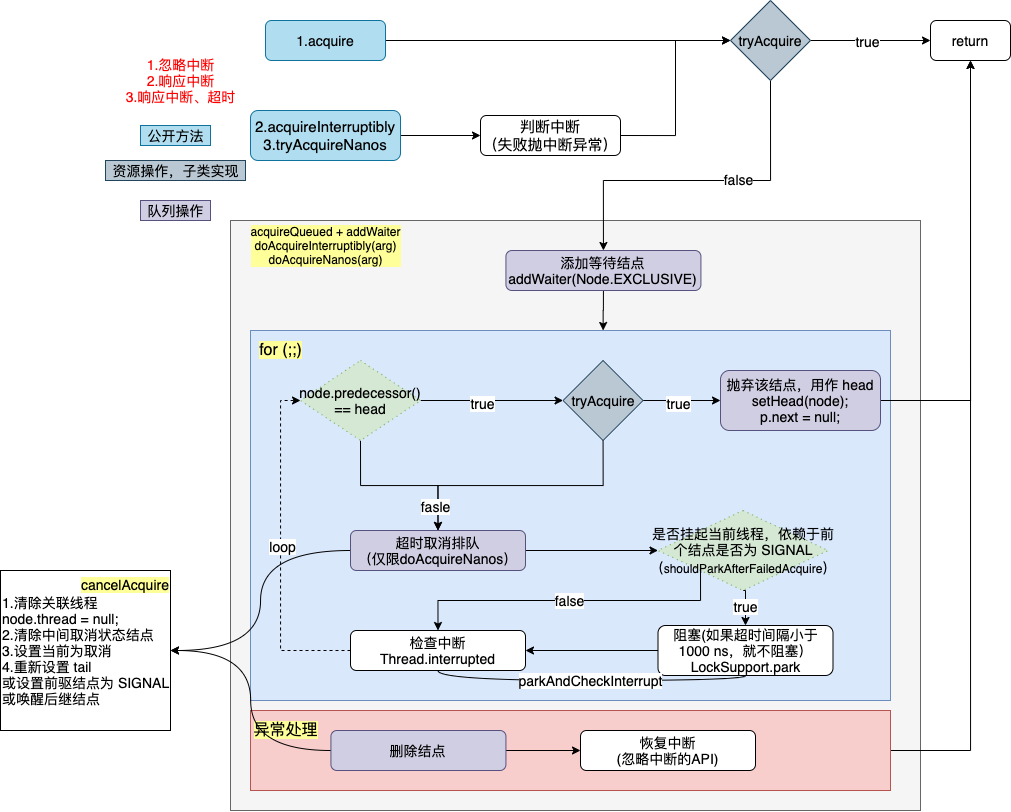
6.1.2 公有入口方法
// 1.独占获取,忽略中断.
// arg 的含义取决于 state 的含义
public final void acquire(int arg) {
// a.首先尝试获取资源
if (!tryAcquire(arg) &&
// b.失败, 标志为独占结点, 进入等待队列
// c.继续循环尝试获取资源(头结点) || 阻塞,等待前驱结点唤醒
// c-d.异常的情况下, 可能需要取消排队, 唤醒后继结点, 恢复中断
acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) {
// e.如果原来是中断的, 则恢复中断
selfInterrupt();
}
}
// 2.可被中断的独占获取
public final void acquireInterruptibly(int arg) throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
// 因为响应中断,所以不用恢复中断
// 和 acquire 中的 acquireQueued(addWaiter(Node.EXCLUSIVE), arg) 是一样的效果,只是阻塞时响应中断
doAcquireInterruptibly(arg);
// 异常的情况下, 可能需要取消排队, 唤醒后继结点
}
// 3.可被中断的超时独占获取
public final boolean tryAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquire(arg) ||
// 和 acquire 中的 acquireQueued(addWaiter(Node.EXCLUSIVE), arg) 是一样的效果
// 不同的是 1.阻塞时响应中断; 2.超时阻塞、循环获取资源时,首先判断时间允许。否则需要取消排队, 唤醒后继结点
doAcquireNanos(arg, nanosTimeout);
// 异常的情况下, 可能需要取消排队, 唤醒后继结点
}
最外层都很简单,一是需要判断、处理中断,二是先去尝试获取资源。
但是一旦获取失败,后续就需要进行队列操作(比如包装为结点、阻塞、唤醒、取消、处理前驱结点等)。
acquireQueued + addWaiter、doAcquireInterruptibly(arg)、doAcquireNanos做的就是这样的事情,只不过对于超时、阻塞的处理不尽相同。
6.1.3 死循环获取、排队、阻塞
我看先看看第一种 acquireQueued(其余类似),是上图中的外框区域:
final boolean acquireQueued(final Node node, int arg) {
// 用来标记原始中断状态
boolean interrupted = false;
try {
for (;;) {
final Node p = node.predecessor();
// 每次循环判断前驱结点是否 head,
// 是,则说明前面无等待的线程, 尝试获取资源
if (p == head && tryAcquire(arg)) {
// 获取成功, 出队
setHead(node);
p.next = null; // help GC
return interrupted;
}
// 判断是否阻塞
if (shouldParkAfterFailedAcquire(p, node))
// 阻塞, 并拿到原始的中断状态
interrupted |= parkAndCheckInterrupt();
}
} catch (Throwable t) {
// 取消排队等待
cancelAcquire(node);
if (interrupted)
// 恢复中断
selfInterrupt();
throw t;
}
}
// 所有类型的获取方法,在循环中都依据该方法,进行阻塞判断
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
// 而当前线程要阻塞的前提, 就是要找个小伙伴到时候叫醒他. 而这个小伙伴,通常就是前驱结点
// 怎么让小伙伴到时候记得提醒自己, 就是将它的状态设为 SIGNAL, 表示到时候叫醒我(如何叫醒见 unparkSuccessor)
return true;
if (ws > 0) {
// 表示前驱结点是取消状态, 往前把取消的都清理掉
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// 前驱结点可能正在获取, 所以这里先设置状态, 但不阻塞, 再尝试一次
pred.compareAndSetWaitStatus(ws, Node.SIGNAL);
}
return false;
}
// 阻塞当前线程,获取并且重置线程的中断标记位
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
而其他两种,都加上了中断处理或超时处理:
private void doAcquireInterruptibly(int arg) throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
return;
}
// 这里是要响应中断的.
if (shouldParkAfterFailedAcquire(p, node) &&
// 被唤醒之后马上检查中断状态, 并尝试恢复
parkAndCheckInterrupt())
throw new InterruptedException();
}
} catch (Throwable t) {
cancelAcquire(node);
throw t;
}
}
private boolean doAcquireNanos(int arg, long nanosTimeout) throws InterruptedException {
// 先检查超时
if (nanosTimeout <= 0L)
return false;
final long deadline = System.nanoTime() + nanosTimeout;
final Node node = addWaiter(Node.EXCLUSIVE);
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
return true;
}
nanosTimeout = deadline - System.nanoTime();
// 每次循环(唤醒)都检查超时
if (nanosTimeout <= 0L) {
cancelAcquire(node);
return false;
}
if (shouldParkAfterFailedAcquire(p, node) &&
// 如果超时剩余时间小于 1000 ns, 就继续循环.避免线程状态切换的损耗
nanosTimeout > SPIN_FOR_TIMEOUT_THRESHOLD)
LockSupport.parkNanos(this, nanosTimeout);
if (Thread.interrupted())
throw new InterruptedException();
}
} catch (Throwable t) {
cancelAcquire(node);
throw t;
}
}
6.1.4 取消排队
当出现异常,或者中断、超时,必须将之前 addWaiter 添加的结点移除(可能不是立即移除,中间通过“取消状态”来避免影响其他结点),意味着取消等待。
那么就要根据当前结点的情况,做一些处理。
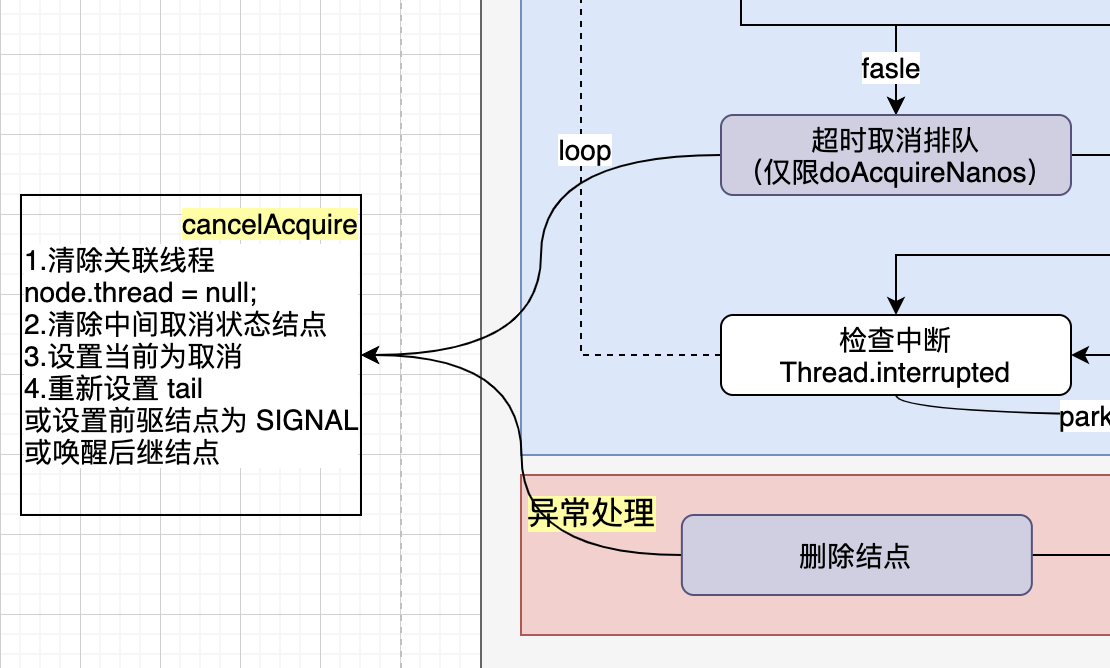
private void cancelAcquire(Node node) {
// Ignore if node doesn't exist
if (node == null)
return;
// 1.置空节点持有的线程,因为此时节点线程已经发生中断
node.thread = null;
// 2.跳过已取消的前驱结点, 找个第一个有效的前驱
Node pred = node.prev;
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
Node predNext = pred.next;
// 3.将状态设为取消
node.waitStatus = Node.CANCELLED;
// If we are the tail, remove ourselves.
if (node == tail && compareAndSetTail(node, pred)) {
// 4.1如果是 tail, 重新设置 tail, 并且将前驱的 next 置空
pred.compareAndSetNext(predNext, null);
} else {
int ws;
// 4.2 既不是 tail, 也不是 head.next
// 则将前继节点的waitStatus置为SIGNAL(因为后面肯定还有等待的)
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL ||
(ws <= 0 && pred.compareAndSetWaitStatus(ws, Node.SIGNAL))) &&
// 注意 原来的状态不能是取消, 或者等待取消(thread == null)
pred.thread != null) {
Node next = node.next;
if (next != null && next.waitStatus <= 0)
// 并使node的前继节点指向node的后继节点
pred.compareAndSetNext(predNext, next);
} else {
// 4.3 如果node是head的后继节点,则直接唤醒node的后继节点
unparkSuccessor(node);
}
node.next = node; // help GC
}
}
6.2 独占释放
相对来说,独占释放就一套模板,且逻辑清晰
- 释放资源(肯定涉及持有线程的判断,不过是子类来做)
- 重置head 状态
- 唤醒 head 有效后继结点的线程
// 独占释放
public final boolean release(int arg) {
// 1.首先释放资源
if (tryRelease(arg)) {
Node h = head;
// 2.头结点不为空, 并且是阻塞的情况(需要唤醒后继的状态)
if (h != null && h.waitStatus != 0)
// 3.唤醒后继结点(跳过中间可能存在取消的结点)
unparkSuccessor(h);
return true;
}
return false;
}
private void unparkSuccessor(Node node) {
int ws = node.waitStatus;
if (ws < 0)
// 重置为 0. 后面结点唤醒后会成为新的 head
node.compareAndSetWaitStatus(ws, 0);
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
// 如果是空的,或者取消,则从后往前找到第一个等待唤醒的:
// 1. addWaiter(Node node) 是先设置前驱节点 后设置后继节点 虽然这两步分别是原子的 但在两步之间还是可能存在后继节点未链接完成的情况
// 2. 在产生CANCELLED状态节点的时候,先断开的是Next指针,Prev指针并未断开,因此也是必须要从后往前遍历才能够遍历完全部的Node
// 如果是从前往后找,由于极端情况下入队的非原子操作和CANCELLED节点产生过程中断开Next指针的操作,可能会导致无法遍历所有的节点
for (Node p = tail; p != node && p != null; p = p.prev)
if (p.waitStatus <= 0)
s = p;
}
if (s != null)
// 被唤醒, 结合前文, 就是退出 parkAndCheckInterrupt, 重新循环
LockSupport.unpark(s.thread);
}
6.3 共享获取
6.3.1 总览
共享模式下,获取和释放与独占模式对资源操作和出队入队时一样的,不同的是(下图红色字体的流程结点)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-28VCQeZm-1616247740874)(/Volumes/personal/note/AQS-第 1 页 的副本.png)]
6.3.2 公有入口方法
// 忽略中断的共享获取
// 最后恢复中断
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
// 获取失败, 结点入队, 循环尝试或阻塞
doAcquireShared(arg);
}
// 可被中断的共享获取
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
// 同 acquireShared, 循环或阻塞过程检查中断
doAcquireSharedInterruptibly(arg);
}
// 可被中断的超时共享获取
public final boolean tryAcquireSharedNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquireShared(arg) >= 0 ||
// 同 acquireShared, 循环或阻塞过程检查中断以及是否超时
doAcquireSharedNanos(arg, nanosTimeout);
}
6.3.3 循环获取、排队、阻塞
从上面的图中,我们可以清晰的看到红色字体的流程就三个:
- 结点入队,模式为共享。
- 对于获取成功后,返回的是剩余可用资源;当前线程需要依次唤醒后继结点,而不是直接退出。
- 释放时,同时批量唤醒后继结点。
所以,就只拿doAcquireShared 举例说明了:
private void doAcquireShared(int arg) {
// 共享模式
final Node node = addWaiter(Node.SHARED);
boolean interrupted = false;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
=================================
| if (r >= 0) {
|
| // 设置头结点, 并传播都后继结点 |
| setHeadAndPropagate(node, r); |
| p.next = null; // help GC |
| return; |
=================================
}
}
if (shouldParkAfterFailedAcquire(p, node))
interrupted |= parkAndCheckInterrupt();
}
} catch (Throwable t) {
cancelAcquire(node);
throw t;
} finally {
if (interrupted)
selfInterrupt();
}
}
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
setHead(node);
// h.waitStatus 是同时处理 SIGNAL 和 PROPAGATE, 结合 doReleaseShared 设置 PROPAGATE.
if (propagate > 0
// 应该是 0 的(当前被唤醒, 或直接拿到)
// 如果不是 0, 则应该是 PROPAGATE. 说明 setHead 完成之前, 其他线程释放资源,然后将老的 head 改为 PROPAGATE.见 doReleaseShared
|| h == null || h.waitStatus < 0 ||
// 新的 head 可能有三种情况
// 1. 0 :没有后继结点或刚入队,没来得及改头, 见 shouldParkAfterFailedAcquire
// 2. -1 : 已入队, 并将 head 改为 SIGNAL , 见 shouldParkAfterFailedAcquire
// 2. -3 : 其他线程释放资源, 将 head 还为 0 时, 改为 PROPAGATE. 见 doReleaseShared
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
doReleaseShared();
}
}
private void doReleaseShared() {
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!h.compareAndSetWaitStatus(Node.SIGNAL, 0))
continue; // loop to recheck cases
// 如果是需要信号的结点, 则直接尝试唤醒
unparkSuccessor(h);
}
else if (ws == 0 &&
!h.compareAndSetWaitStatus(0, Node.PROPAGATE))
// 否则设置为传播
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
// 可能其他线程拿到资源出队了, 所以继续循环
break;
}
}
一直很疑惑 PROPAGATE 的状态有啥用,结合 doReleaseShared 和 setHeadAndPropagate 来看,主要是解决并发情况下的后续唤醒问题。
如果 doReleaseShared 不设置 PROPAGATE, setHeadAndPropagate 只判断 0 和 -1。
那么结果是什么?参考一篇文章:https://juejin.cn/post/6910104545133920269#heading-17

6.4 共享释放
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
// 见上文
doReleaseShared();
return true;
}
return false;
}
至此,总算把 AQS 中获取、排队、阻塞、唤醒、释放的流程说完了,好多好难。
7.队列检查方法
7.1 开放方法 public final
boolean hasQueuedThreads();//是否有等待线程
Collection<Thread> getExclusiveQueuedThreads();//获取独占等待线程列表
boolean hasContended() {
return head != null;}// 是否有线程争抢过资源
Thread getFirstQueuedThread();//第一个等待线程
boolean isQueued(Thread thread);//指定线程是否在排队
boolean hasQueuedPredecessors()//当前线程前是否还有其他排队的线程,一般用作公平锁的实现中
int getQueueLength()// 排队长度,以 thread 不为空 为准
Collection<Thread> getQueuedThreads()//排队线程集合
Collection<Thread> getExclusiveQueuedThreads()//独占排队线程集合
Collection<Thread> getSharedQueuedThreads()//共享排队线程集合
7.2 非公有方法
//获取第一个等待线程,区别于公有方法直接使用 head == tail 判断失败,则使用该方法。
// 先从前往后,找不到则从后往前。避免并发影响
private Thread fullGetFirstQueuedThread();
final boolean apparentlyFirstQueuedIsExclusive()//是否存在第一个排队的线程是以独占模式。读写锁非公平实现中获取读锁时先判断是否有在等待写锁
至此,AQS Sync Queue 流程的方法也讲完了。剩下的一些 Node 操作的方法,是为了 Condition Queue 设计的,后面有机会单独出篇文章,以及子类实现。
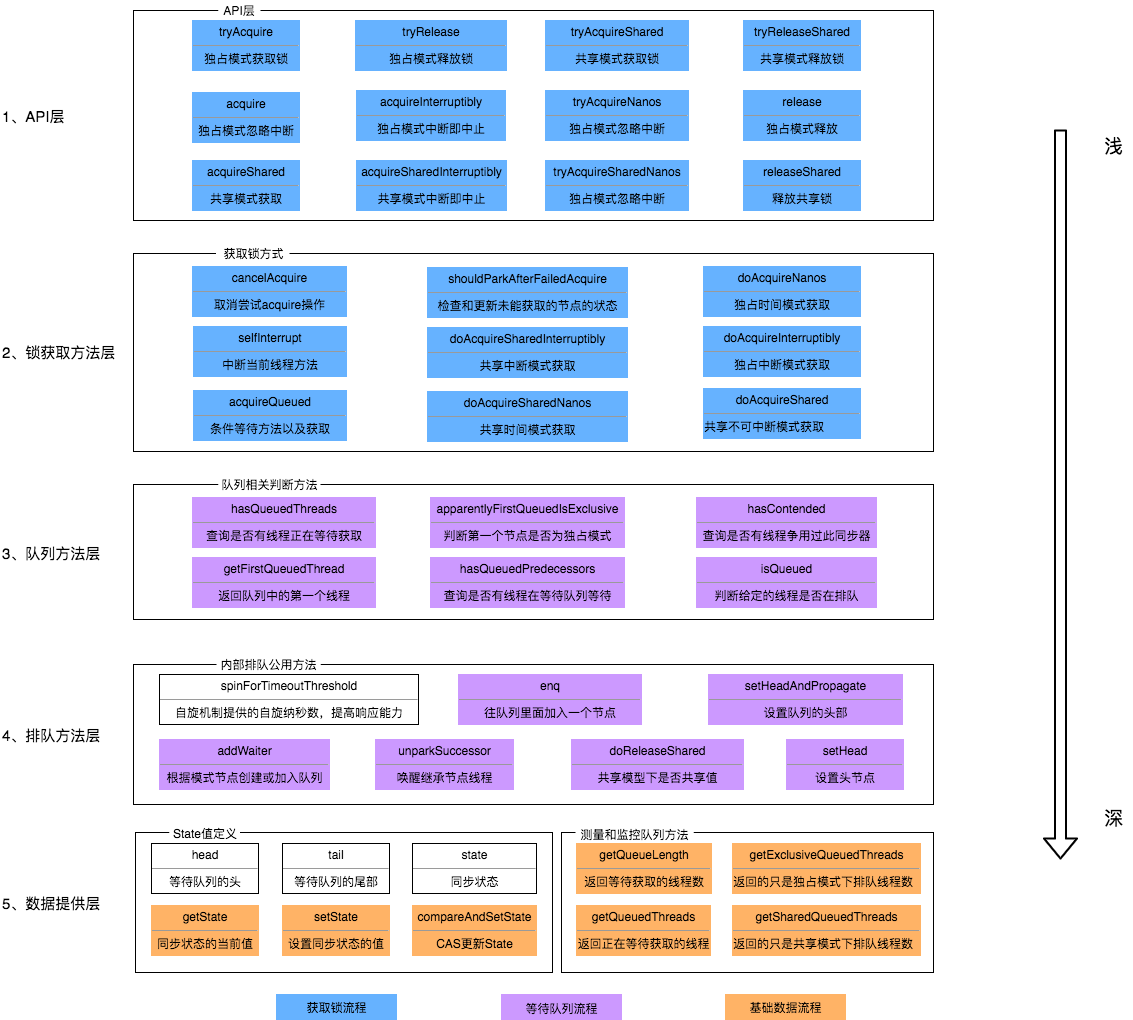
8.框架方法总结
这里借张图,来自美团技术团队的,一览无遗,我觉得也就没必要重复造轮子了。
图片来源:https://tech.meituan.com/2019/12/05/aqs-theory-and-apply.html
9.独占模式实现示例
public class MyLock {
class Sync extends AbstractQueuedSynchronizer {
protected boolean tryAcquire(int arg) {
return compareAndSetState(0, 1);
}
protected boolean tryRelease(int arg) {
setState(0);
return true;
}
protected boolean isHeldExclusively() {
// 主要是 condition用到, 随便意思一下
return true;
}
}
Sync sync = new Sync();
public void lock() {
sync.acquire(1);
}
public void unlock() {
sync.release(1);
}
}
借由这个工具跑个示例
public class AqsDemo {
static int lockCount = 0;
static int unlockCount = 0;
static MyLock myLock = new MyLock();
public static void main(String[] args) throws InterruptedException {
Runnable runnable = new Runnable() {
@Override
public void run () {
try {
for (int i = 0; i < 10000; i++) {
unlockCount++;
}
// 睡一会,确保会有线程切换
Thread.sleep(1000);
myLock.lock();
System.out.println(Thread.currentThread().getName() + ":我开始跑了");
for (int i = 0; i < 10000; i++) {
lockCount++;
}
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName() + ":我跑完了");
} catch (Exception e) {
e.printStackTrace();
} finally {
myLock.unlock();
}
}
};
Thread thread1 = new Thread(runnable, "线程1");
Thread thread2 = new Thread(runnable, "线程2");
thread1.start();thread2.start();thread1.join();thread2.join();
System.out.println("加锁累加: " + lockCount);
System.out.println("未加锁累加: " + unlockCount);
}
}
结果:
线程1:我开始跑了
线程1:我跑完了 // 即使中间睡了一秒钟,也不会切换,线程是持有锁的
线程2:我开始跑了
线程2:我跑完了
加锁累加: 20000
未加锁累加: 14667
总结
源码很多,比较枯燥,可能容易理解无能。主要来自于我自己看源码的脉络和习惯,希望对大家有所参考。

这是我自己写前的脉络,感觉不是很搭边啊。因为篇幅很长了,也没能放下子类实现工具的说明和使用
巨人的肩膀
- The java.util.concurrent Synchronizer Framework 中文翻译版
- http://www.throwable.club/2019/04/07/java-juc-aqs-source-code/
- https://snailclimb.gitee.io/javaguide/#/docs/java/multi-thread/AQS%E5%8E%9F%E7%90%86%E4%BB%A5%E5%8F%8AAQS%E5%90%8C%E6%AD%A5%E7%BB%84%E4%BB%B6%E6%80%BB%E7%BB%93?id=_23-aqs-%e5%ba%95%e5%b1%82%e4%bd%bf%e7%94%a8%e4%ba%86%e6%a8%a1%e6%9d%bf%e6%96%b9%e6%b3%95%e6%a8%a1%e5%bc%8f
- https://tech.meituan.com/2019/12/05/aqs-theory-and-apply.html