【SpringBoot高级篇】SpringBoot集成Sharding-JDBC分库分表
Apache ShardingSphere
Apache ShardingSphere(Incubator) 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
ShardingSphere 定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。它通过关注不变,进而抓住事物本质。关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。Apache 官方发布从 4.0.0 版本开始。
分库分表
数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查的开销也会越来越大;另外,由于无法进行分布式式部署,而一台服务器的资源(CPU、磁盘、内存、IO 等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
分库分表的方式
数据库的切分指的是通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)中,以达到分散单台设备负载的效果,即分库分表。
数据的切分根据其切分规则的类型,可以分为 垂直切分 和水平切分
- 垂直切分: 把单一的表拆分成多个表,并分散到不同的数据库(主机)上
- 水平切分:根据表中数据的逻辑关系,将表中的数据按照某种条件拆分到多台数据库上
垂直切分
一个数据库有多个表构成,每个表对应不同的业务,垂直切分是只按照业务将表进行分类,将其分布到不同的数据库上,这样就将数据分担到了不同的库上(专库专用)
垂直分表
操作数据库中某张表,把这张表中一部分字段数据存到一张新表里面,再把这张表另一部分字段数据存到另外一张表里面
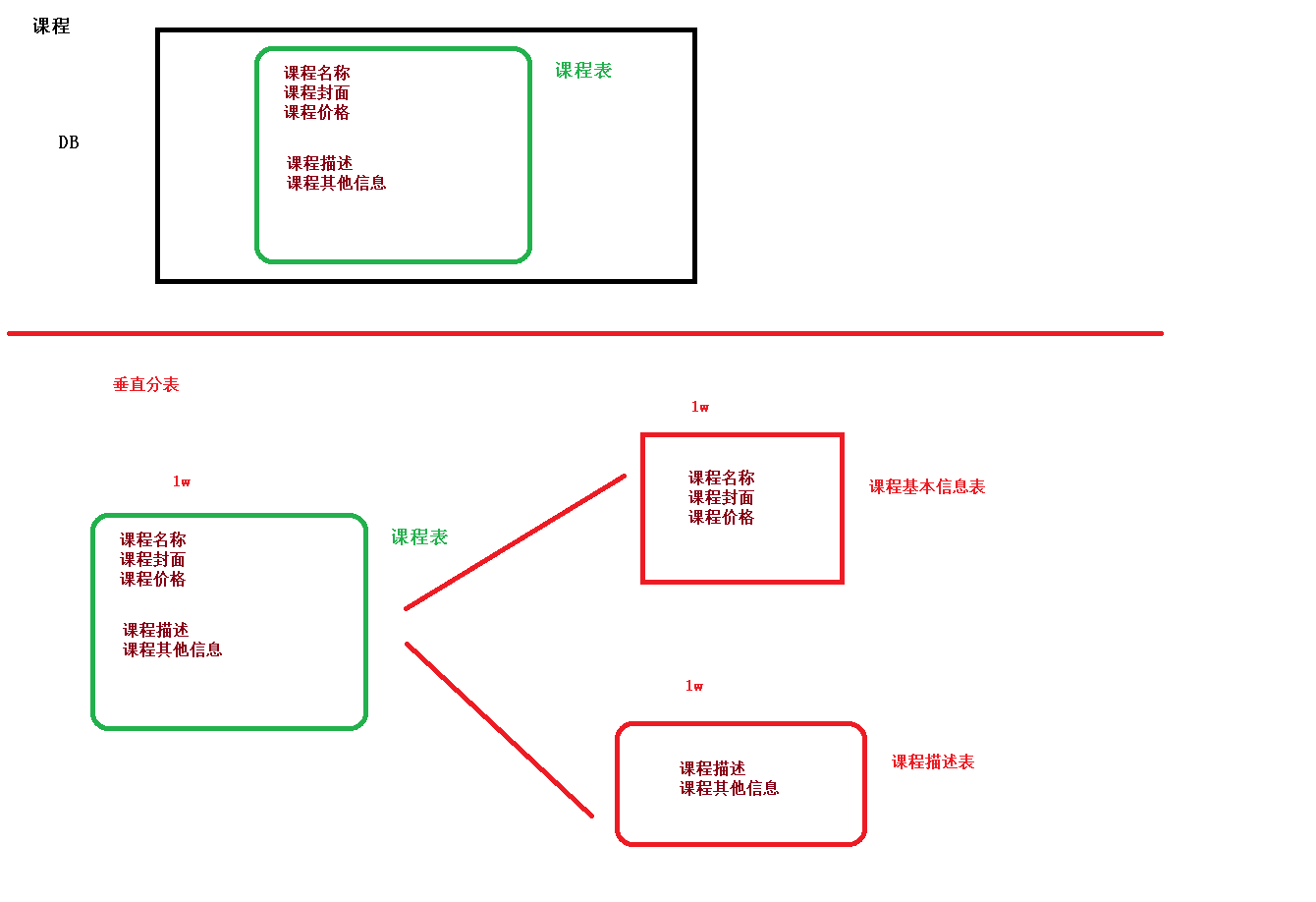

垂直分库
把单一数据库按照业务进行划分,专库专表
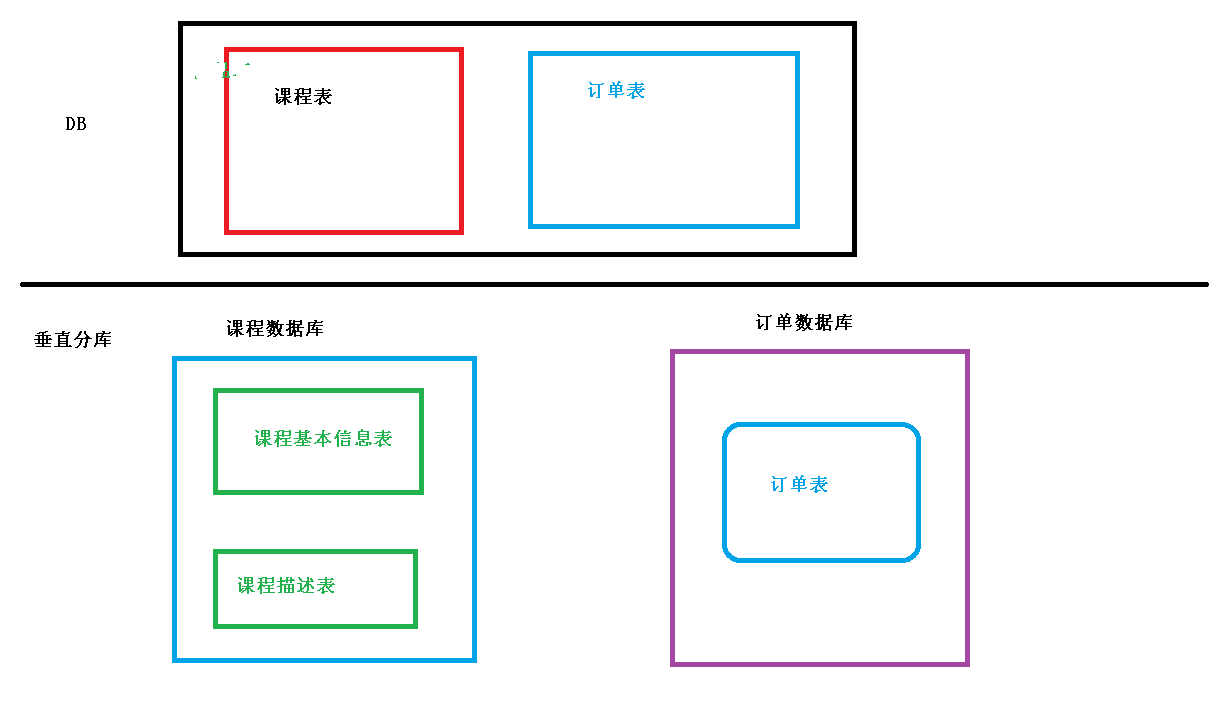
垂直切分的优点如下:
-
拆分后业务清晰,系统之间进行整合或扩展很容易。
-
按照成本、应用的等级、应用的类型等奖表放到不同的机器上,便于管理,数据维护简单。
垂直切分的缺点如下:
-
部分业务表无法关联(Join), 只能通过接口方式解决,提高了系统的复杂度。
-
受每种业务的不同限制,存在单库性能瓶颈,不易进行数据扩展和提升性能。
-
事务处理变得复杂。
水平切分
与垂直切分对比,水平切分不是将表进行分类,而是将其按照某个字段的某种规则分散到多个库中,在每个表中包含一部分数据,所有表加起来就是全量的数据。
简单来说,我们可以将对数据的水平切分理解为按照数据行进行切分,就是将表中的某些行切分到一个数据库表中,而将其他行切分到其他数据库表中。
水平分库
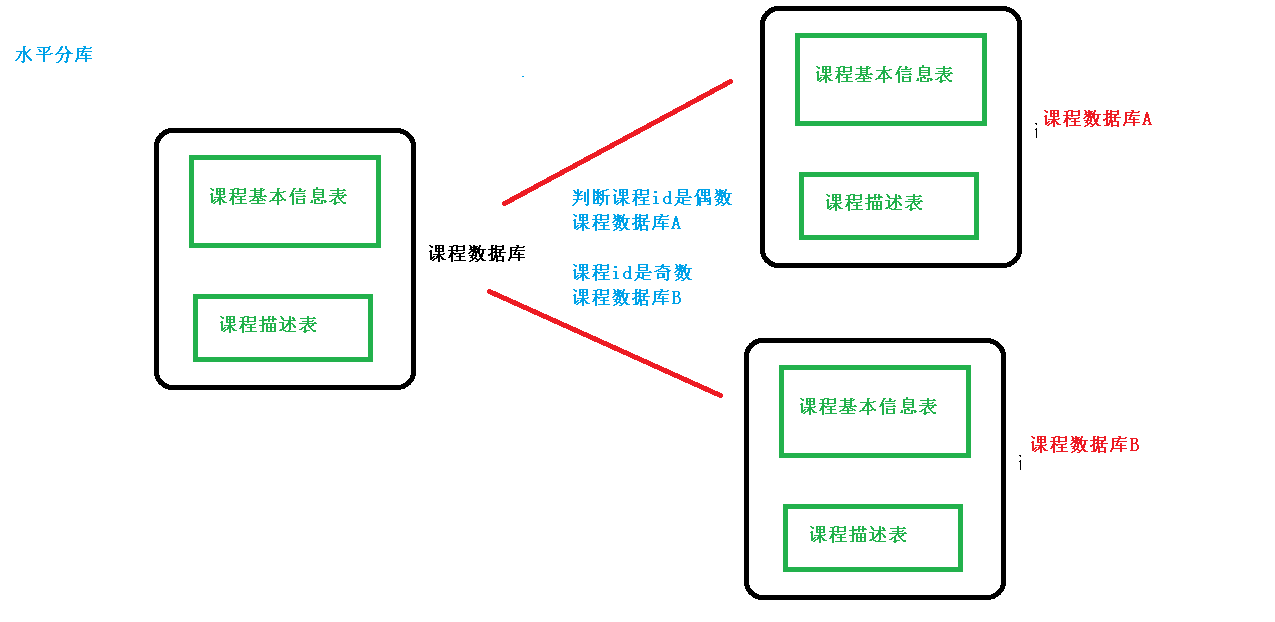
水平分表

水平切分的优点:
-
单库单表的数据保持在一定的量级,有助于性能的提高。
-
切分的表的结构相同,应用层改造较少,只需要增加路由规则即可。
-
提高了系统的稳定性和负载能力。
水平切分的缺点如下:
-
切分后,数据是分散的,很难利用数据库的 Join 操作,跨库 Join 性能较差。
-
分片事务的一致性难以解决,数据扩容的难度和维护量极大。
分库分表带来的问题
- 存在跨节点 Join 的问题。
- 存在跨节点合并排序、分页的问题。
- 存在多数据源管理的问题
分库分表中间件
目前,国内使用比较多的分库分表的中间件,主要有:
- Apache ShardingSphere
- Mycat
Sharding-JDBC
Sharding-JDBC 是当当网研发的开源分布式数据库中间件,从 3.0 开始 Sharding-JDBC 被包含在 Sharding-Sphere 中,之后该项目进入进入 Apache 孵化器,4.0 版本之后的 版本为 Apache 版本。maven坐标
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
Sharding-JDBC 是 ShardingSphere 的第一个产品,也是 ShardingSphere 的前身。 它定 位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库, 以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
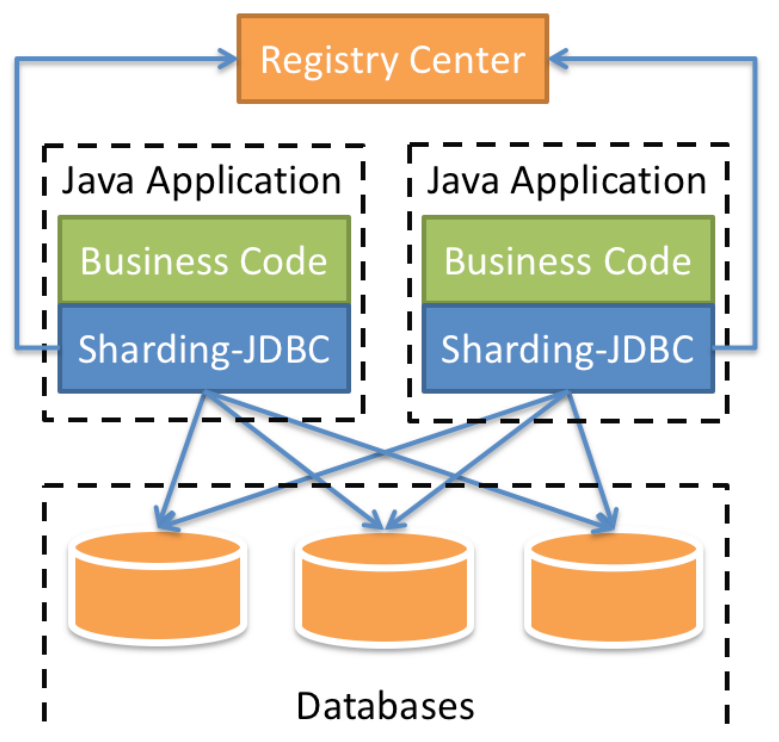
Sharding-JDBC的核心功能为数据分片和读写分离,通过Sharding-JDBC,应用可以透明的使 用jdbc访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及数据如何分布。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 支持任意实现 JDBC 规范的数据库。目前支持 MySQL,Oracle,SQLServer, PostgreSQL 以及任何遵循 SQL92 标准的数据库。
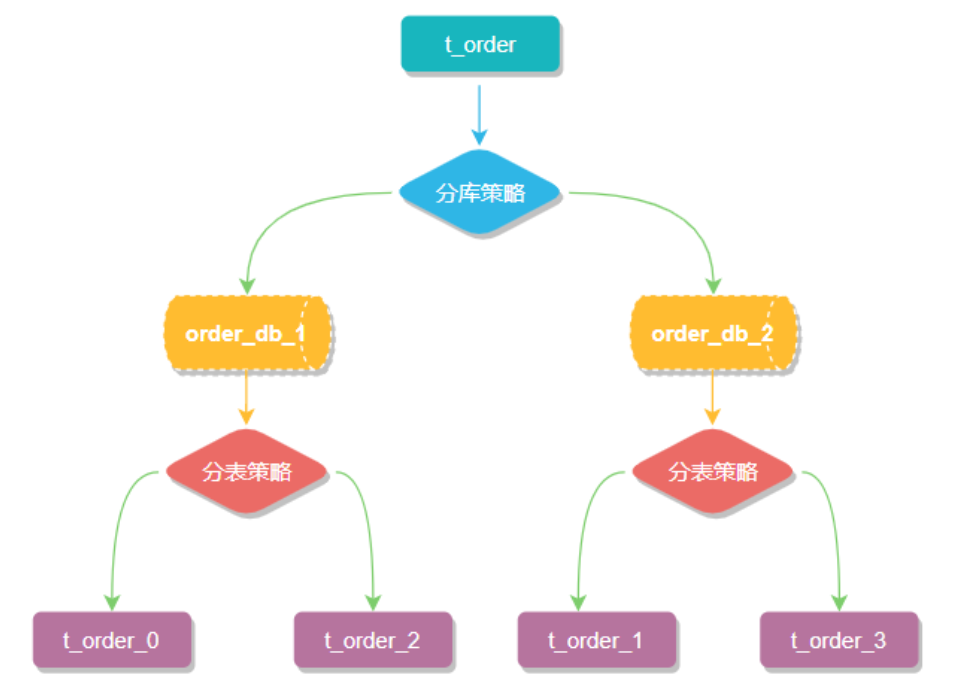
sharding-jdbc实现水平分表
db脚本
db: order_db_1
table: t_order_1、t_order_2
CREATE TABLE `t_order_1` (
`id` int NOT NULL,
`order_type` int DEFAULT NULL,
`customer_id` int DEFAULT NULL,
`amount` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;

pom
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.23</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
Order
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Order {
private Integer id;
private Integer orderType;
private Integer customerId;
private Double amount;
}
application.yml
spring:
shardingsphere:
datasource:
# 配置数据源的名称
names: ds1
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/order_db_1?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
username: root
password: root
# 打开sql输出日志
props:
sql:
show: true
sharding:
tables:
# 逻辑表,SQL语句中写对应的逻辑表
# 如:insert into t_order(id,order_type,customer_id,amount) values(?,?,?,?)
# 虽然写的是添加数据到t_order表,实际会根据分表策略路由到t_order_1或t_order_2
t_order:
# 指定t_order表的分布情况,配置表在哪个数据库中,表名称是什么
actual-data-nodes: ds1.t_order_$->{
1..2}
# 指定t_order表里主键id生成策略
key-generator:
column: id
type: SNOWFLAKE
# 指定分片策略。根据id的奇偶性来判断插入到哪个表
table-strategy:
inline:
algorithm-expression: t_order_${
id%2+1}
sharding-column: id
水平分表测试
@SpringBootTest(classes = ShardingJdbcApplication.class)
public class OrderTest {
@Autowired
private JdbcTemplate jdbcTemplate;
@Test
public void testSave() {
String saveSQL = "insert into t_order(id,order_type,customer_id,amount) values(?,?,?,?)";
ArrayList<Order> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(new Order(i, i, i,1000.0*i));
}
jdbcTemplate.batchUpdate(saveSQL, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement preparedStatement, int i) throws SQLException {
Order order = list.get(i);
preparedStatement.setInt(1,order.getId());
preparedStatement.setInt(2,order.getOrderType());
preparedStatement.setInt(3,order.getCustomerId());
preparedStatement.setDouble(4,order.getAmount());
}
@Override
public int getBatchSize() {
return list.size();
}
});
}
@Test
public void getOrder() {
String querySQL = "select * from t_order";
List<Order> orders = jdbcTemplate.query(querySQL, new BeanPropertyRowMapper<>(Order.class));
orders.forEach(System.out::println);
}
}
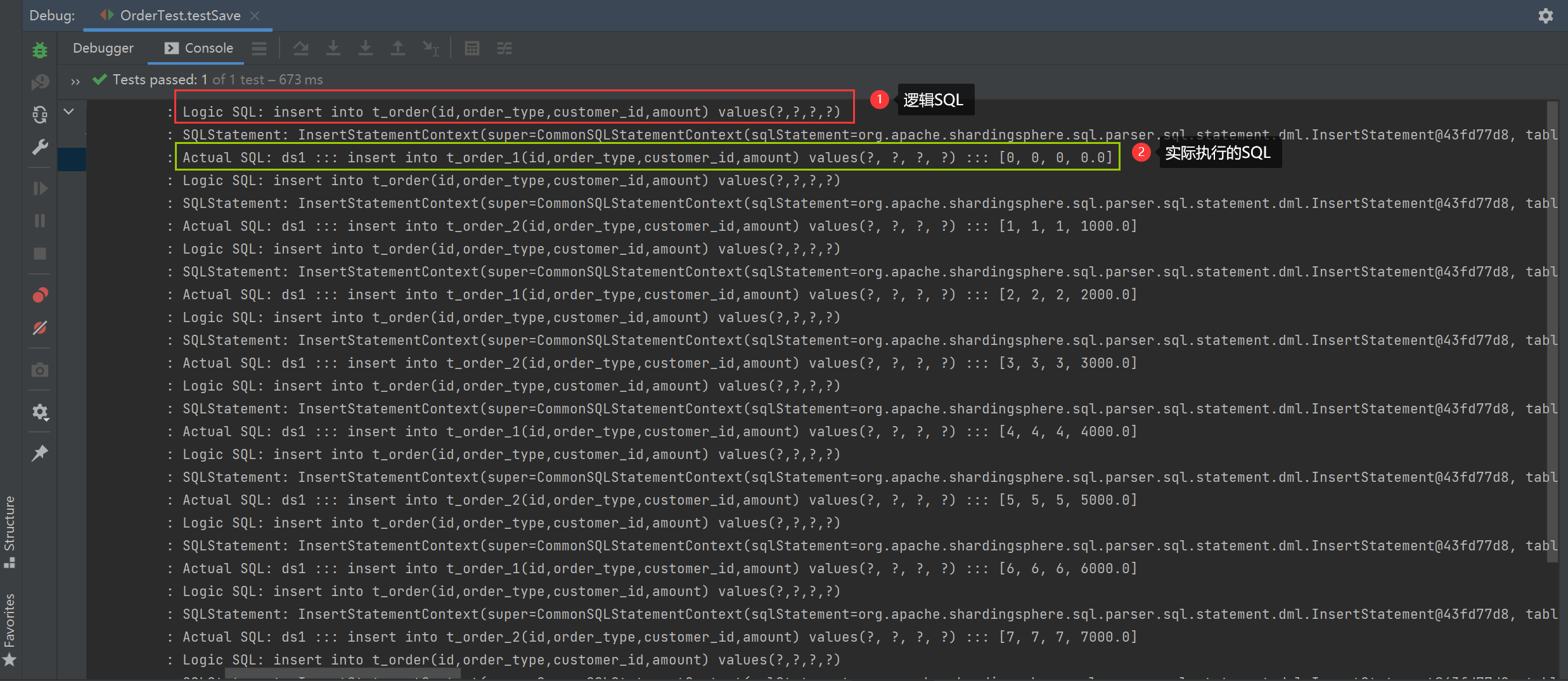
1、testSave()方法执行结果
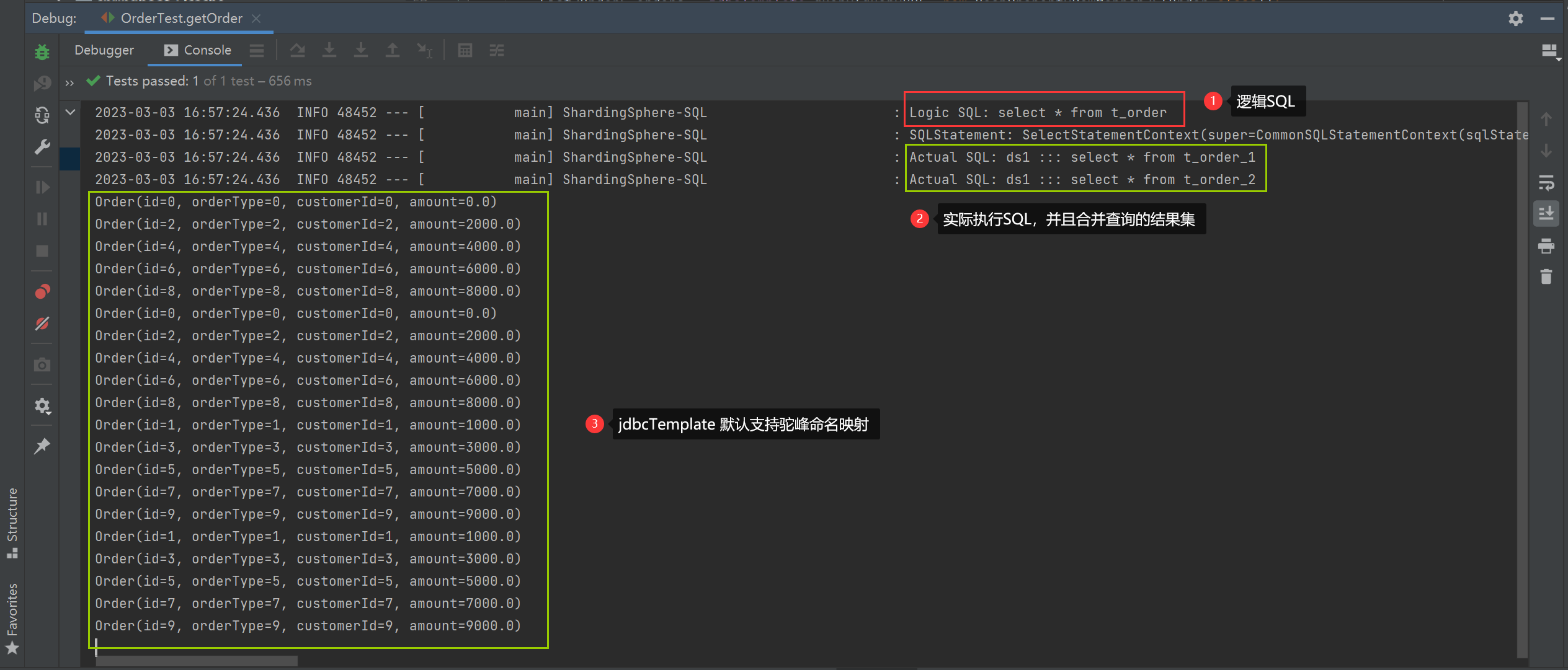
2、getOrder方法执行结果
sharding-jdbc实现水平分库
db

application.yml
spring:
shardingsphere:
datasource:
# 配置不同的数据源
names: ds1,ds2
#配置ds1数据源的基本信息
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/order_db_1?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
username: root
password: root
#配置ds2数据源的基本信息
ds2:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/order_db_2?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
username: root
password: root
#打开sql输出日志
props:
sql:
show: true
sharding:
tables:
# 逻辑表,必须配置正确,如:分表t_order_1,t_order_2,则逻辑表为 t_order
t_order:
#指定数据库表的分布情况
actual-data-nodes: ds$->{
1..2}.t_order_$->{
1..2}
#指定库分片策略,根据customer_id的奇偶性来添加到不同的库中,customer_id为基数路由到ds2,customer_id为偶数路由到ds1
database-strategy:
inline:
sharding-column: customer_id
algorithm-expression: ds$->{
customer_id%2+1}
#指定t_order表的主键生成策略
key-generator:
column: id
type: SNOWFLAKE
#指定表分片策略,根据id的奇偶性来添加到不同的表中,id为基数路由到ds2,id为偶数路由到ds1
table-strategy:
inline:
sharding-column: id
algorithm-expression: t_order_$->{
id%2+1}
路由测试验证
不指定路由键
/**
* 不指定路由键,扫描全库全表查询汇总,效率低
*/
@Test
public void getOrder() {
String querySQL = "select * from t_order";
List<Order> orders = jdbcTemplate.query(querySQL, new BeanPropertyRowMapper<>(Order.class));
orders.forEach(System.out::println);
}
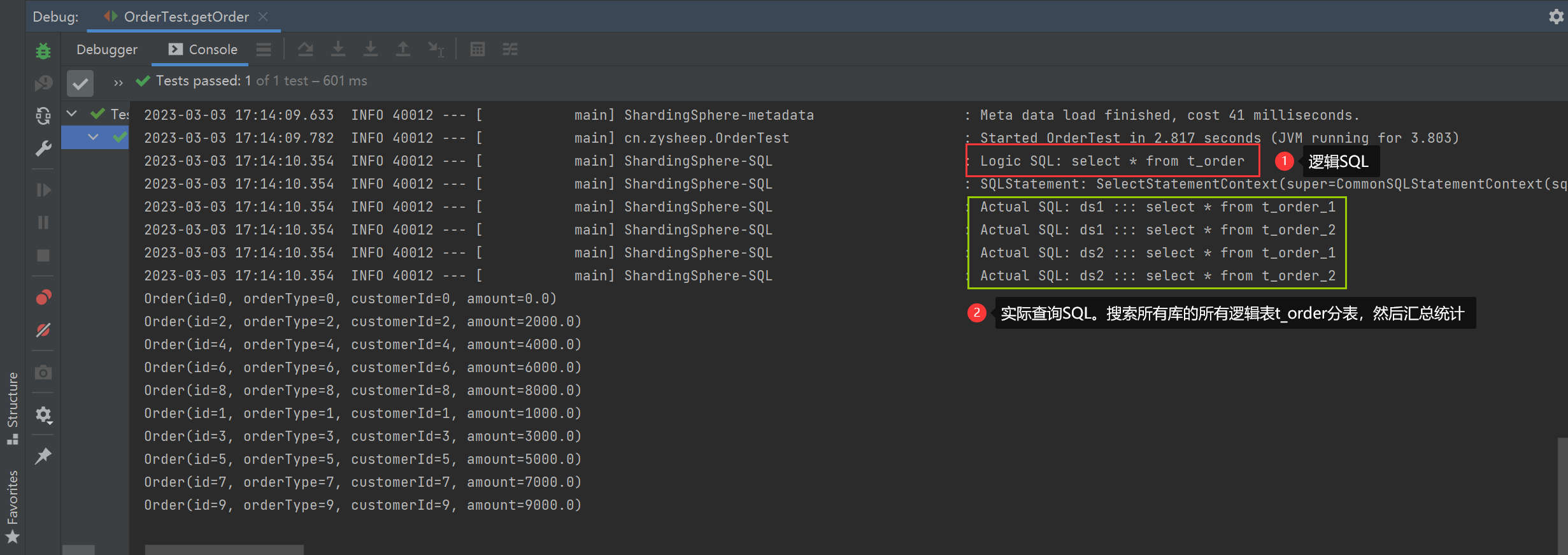
指定库路由键
/**
* 指定库路由键
*/
@Test
public void getOrderByCustomerId() {
String querySQL = "select * from t_order where customer_id = ?";
List<Order> orders = jdbcTemplate.query(querySQL, new BeanPropertyRowMapper<>(Order.class), 2);
orders.forEach(System.out::println);
}
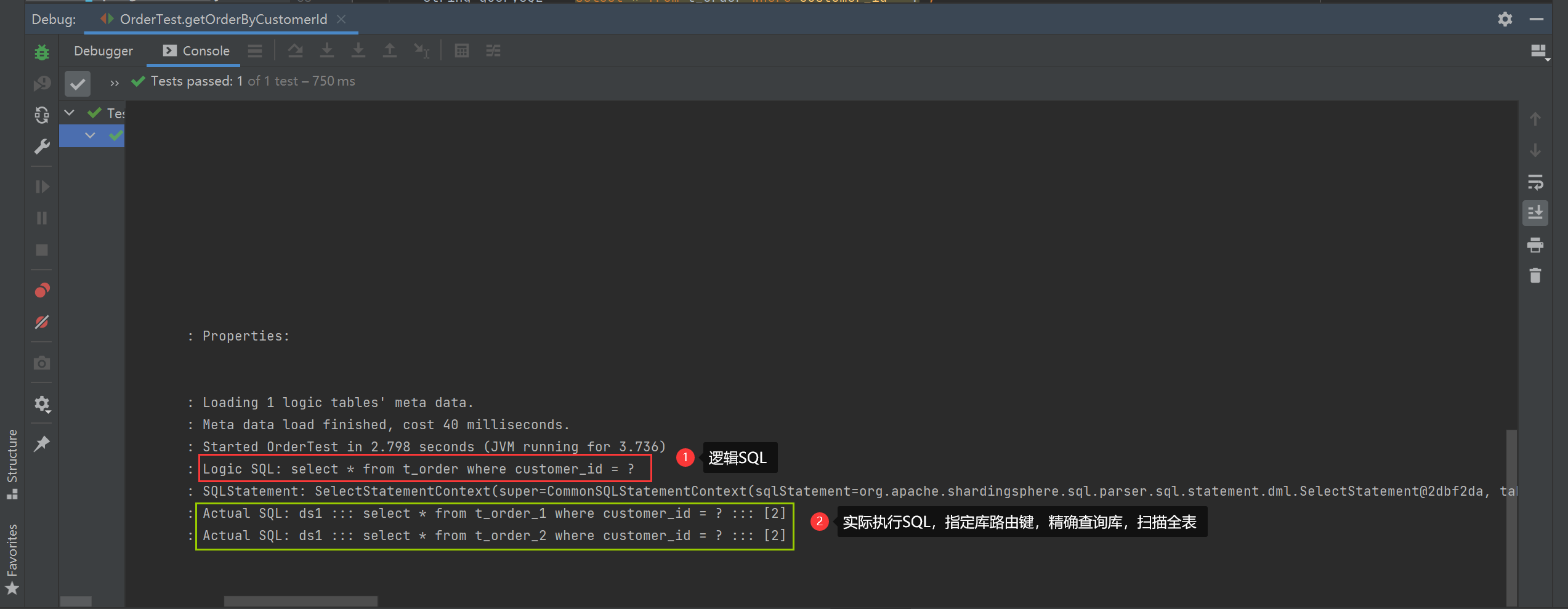
指定表路由键
/**
* 指定表路由键
*/
@Test
public void getOrderById() {
String querySQL = "select * from t_order where id = ?";
List<Order> orders = jdbcTemplate.query(querySQL, new BeanPropertyRowMapper<>(Order.class), 2);
orders.forEach(System.out::println);
}
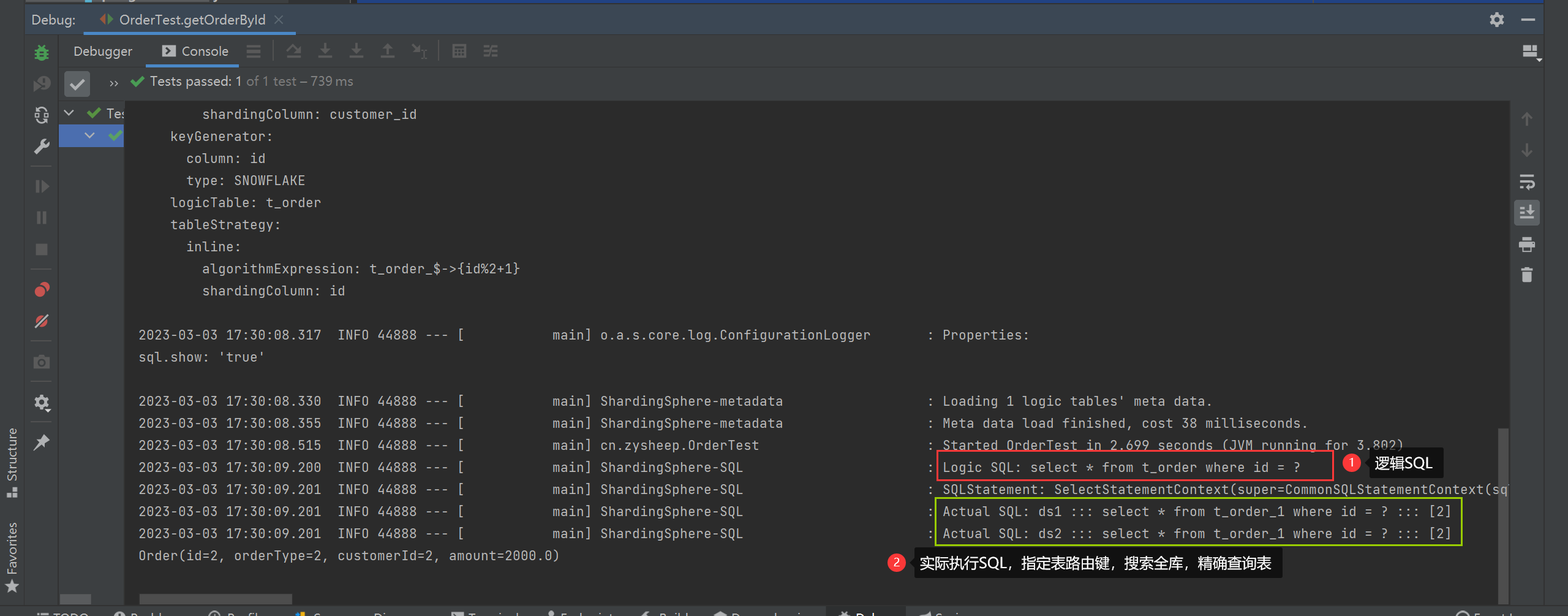
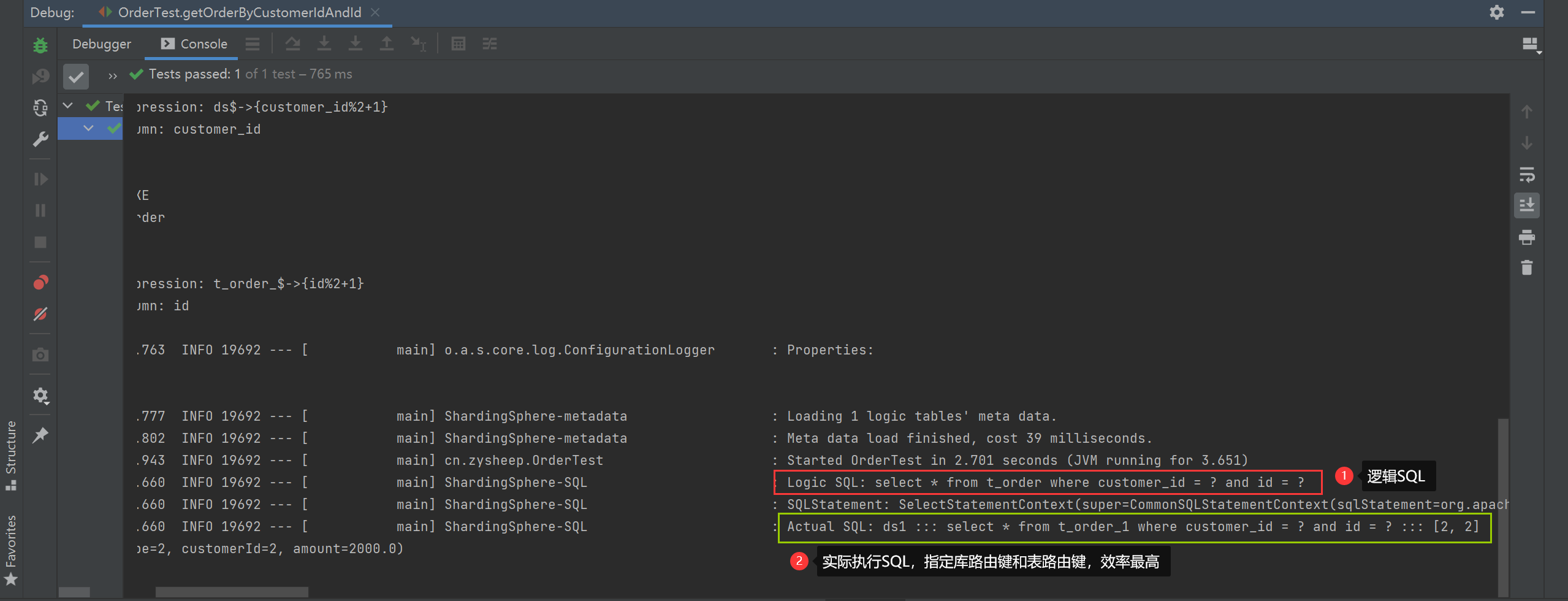
指定库路由键和表路由键
/**
* 指定库路由键和表路由键 效率最高
*/
@Test
public void getOrderByCustomerIdAndId() {
String querySQL = "select * from t_order where customer_id = ? and id = ?";
List<Order> orders = jdbcTemplate.query(querySQL, new BeanPropertyRowMapper<>(Order.class), 2,2);
orders.forEach(System.out::println);
}
sharding-jdbc实现垂直分库
在不同的数据节点创建相同的库order_db_1库。
我本地一个数据库,虚拟机使用docker启了一个数据库
db
docker pull mysql:5.7
docker run -d -p 3306:3306 --privileged=true -e MYSQL_ROOT_PASSWORD=123456 --name mysql mysql:5.7 --character-set-server=utf8mb4 --collation-server=utf8mb4_general_ci


application.yml
spring:
shardingsphere:
datasource:
# 配置不同的数据源
names: ds1,ds2
#配置ds1数据源的基本信息
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://localhost:3306/order_db_1?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
username: root
password: root
#配置ds2数据源的基本信息
ds2:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://192.168.56.10:3306/order_db_1?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
username: root
password: 123456
#打开sql输出日志
props:
sql:
show: true
sharding:
tables:
# 逻辑表,必须配置正确
customer:
#配置customer表所在的数据节点
actual-data-nodes: ds2.customer
#指定orders表的主键生成策略
key-generator:
column: id
type: SNOWFLAKE
#指定表分片策略
table-strategy:
inline:
sharding-column: id
algorithm-expression: customer
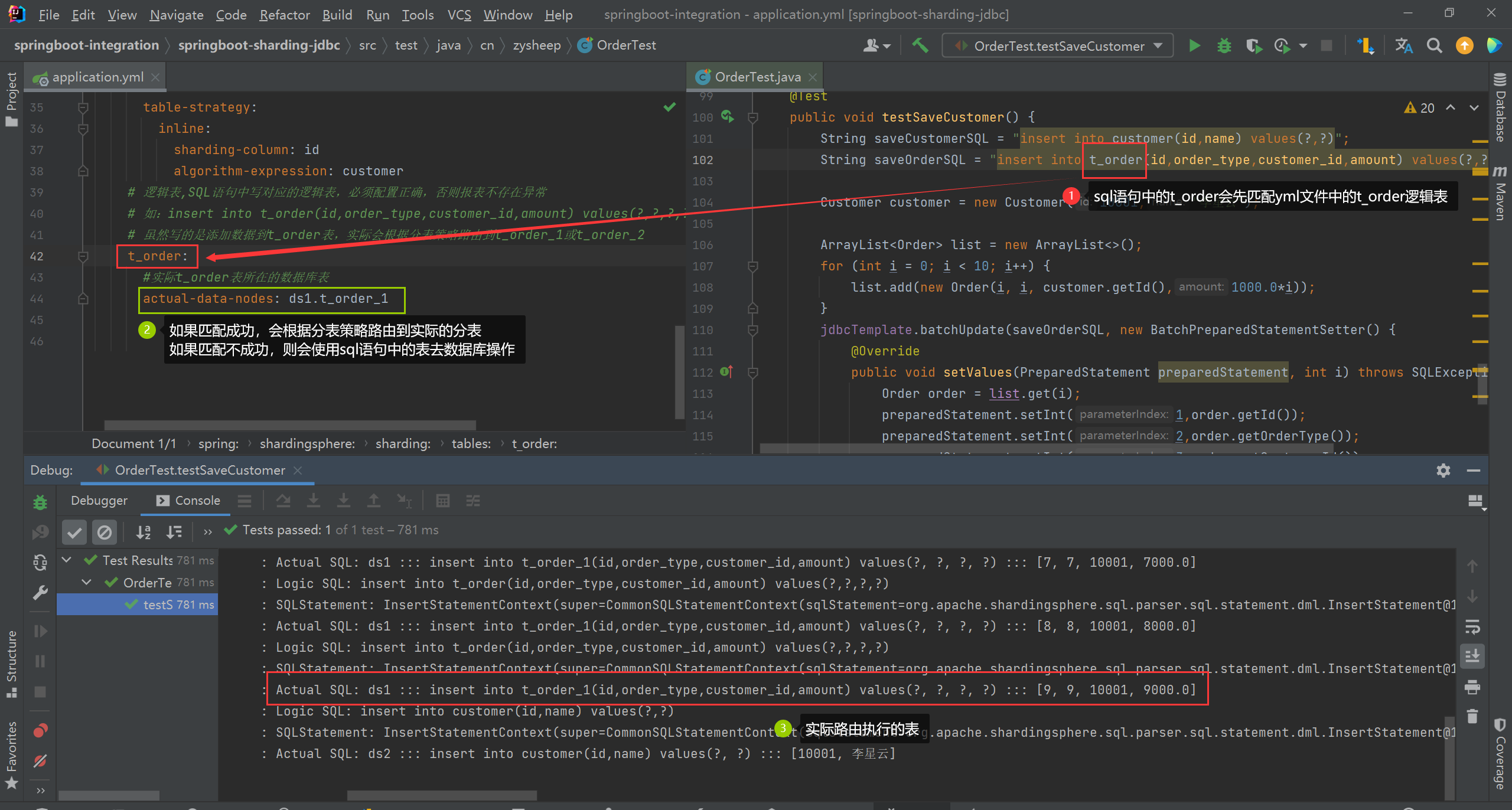
# 逻辑表,SQL语句中写对应的逻辑表,必须配置正确,否则报表不存在异常
# 如:insert into t_order(id,order_type,customer_id,amount) values(?,?,?,?)
# 虽然写的是添加数据到t_order表,实际会根据分表策略路由到t_order_1或t_order_2
t_order:
#实际t_order表所在的数据库表
actual-data-nodes: ds1.t_order_1
测试垂直分库策略
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Customer {
private Integer id;
private String name;
}
/**
* 测试垂直分库
*/
@Test
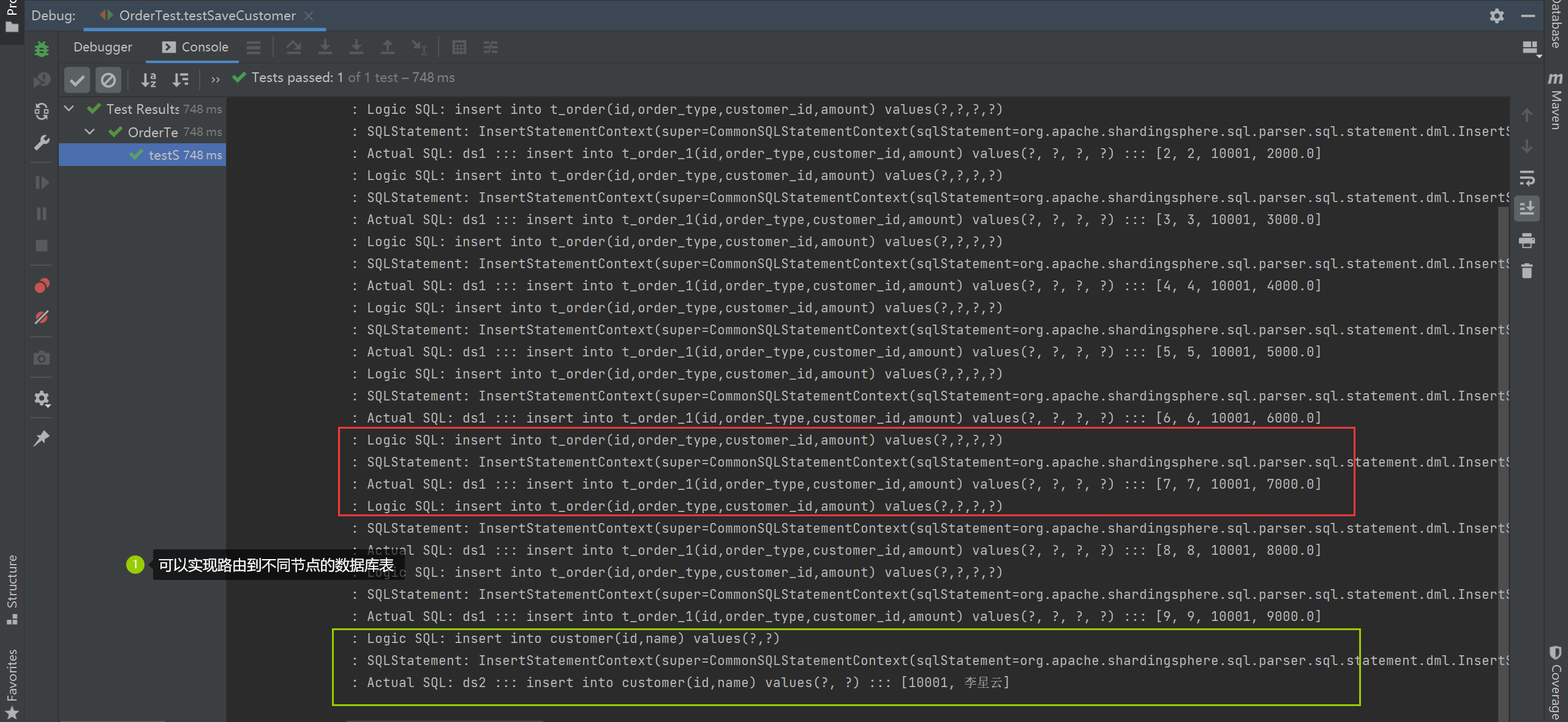
public void testSaveCustomer() {
String saveCustomerSQL = "insert into customer(id,name) values(?,?)";
String saveOrderSQL = "insert into t_order(id,order_type,customer_id,amount) values(?,?,?,?)";
Customer customer = new Customer(10001,"李星云");
ArrayList<Order> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(new Order(i, i, customer.getId(),1000.0*i));
}
jdbcTemplate.batchUpdate(saveOrderSQL, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement preparedStatement, int i) throws SQLException {
Order order = list.get(i);
preparedStatement.setInt(1,order.getId());
preparedStatement.setInt(2,order.getOrderType());
preparedStatement.setInt(3,order.getCustomerId());
preparedStatement.setDouble(4,order.getAmount());
}
@Override
public int getBatchSize() {
return list.size();
}
});
jdbcTemplate.update(saveCustomerSQL, preparedStatement -> {
preparedStatement.setInt(1,customer.getId());
preparedStatement.setString(2, customer.getName());
});
}
分库分表总结
1、使用sharding-jdbc做分库分表时,按规则指定对应的库路由键和表路由键效率最高,所以可以把路由键设置为对应表的索引,提供查询效率。如果开发中实在无法设置两个路由键,则尽量设置一个,避免扫描全库全表。效率低
2、关于spring.shardingsphere.sharding.tables.(逻辑表).actual-data-nodes=ds1.t_order_1配置问题
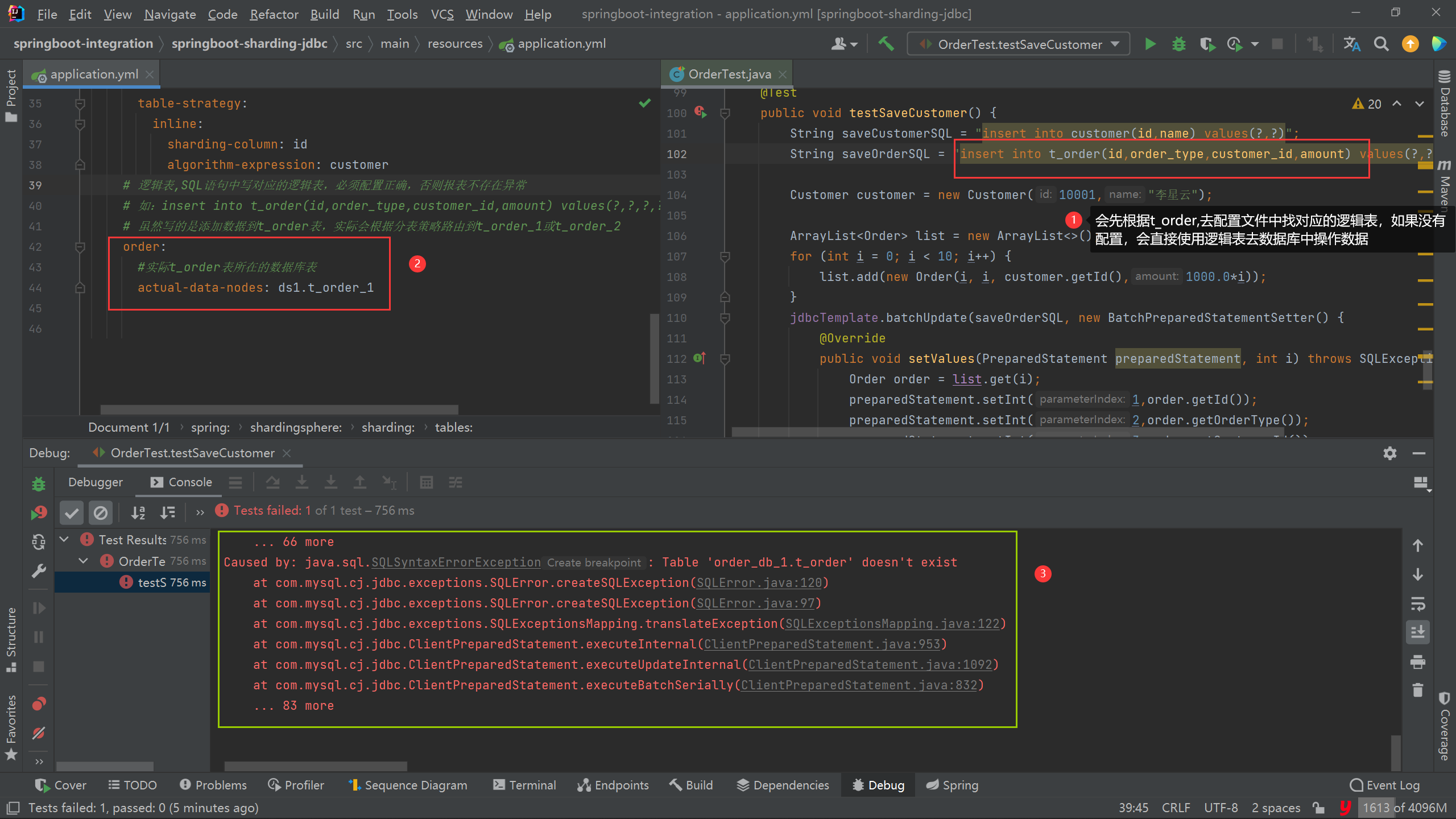
正确逻辑表路由配置应该是: