“Be the change you wish to see in the world.” - Mahatma Gandhi
文章目录
DNS
我们经常用一个主机名标识一个主机,比如“www.baidu.com”,但在网络中,实际是用IP地址来标识主机的。因此需要一个能从主机名映射到IP地址的索引,这就是DNS的功能。
DNS概述
DNS的组成
DNS包含两个部分:
- 存储大量索引的分布式数据库
- 用于主机查找索引的DNS协议
DNS的服务
- 提供主机名到IP地址的转换。
- 主机别名:给某些主机一个便于记忆的主机名,称为主机别名;原来的不好记的名字称为主机规范名。
- 邮件服务器别名
- 负载分配:一些业务繁忙的站点可能有多个服务器正在运行,这些服务器拥有不同的IP地址,但能用同一个主机名映射到,此时DNS提供从主机名到IP地址集合的映射。
在提供映射时,DNS循环IP集合的次序,因为主机总是向IP集合的第一个IP地址发送报文,这样就可以分摊这个主机名收到的负载了。
DNS运行过程
DNS的分布式数据库
DNS索引用一个很大的分布式数据库存储。
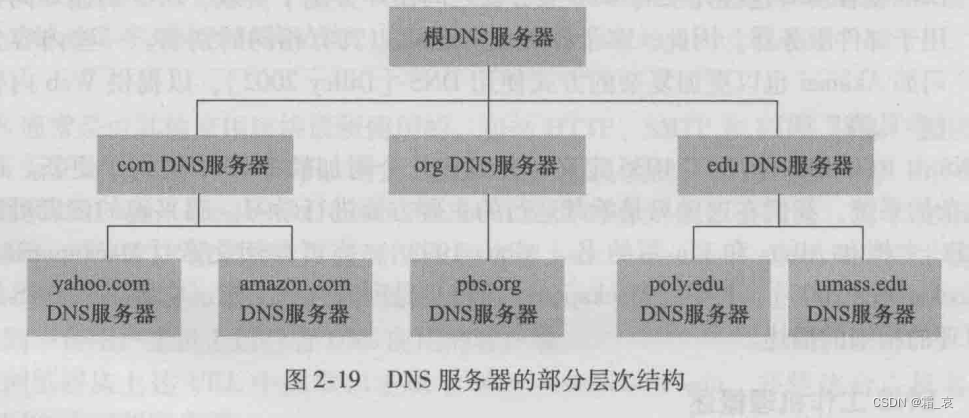
- 根DNS服务器:最上层的DNS服务器,存储着顶级域DNS服务器的IP地址。
- 顶级域(TLD)DNS服务器:负责顶级域名如com,edu等,存储权威DNS服务器的IP地址。
- 权威DNS服务器:存储需要找到的主机的IP地址。
本地DNS服务器
主机进行DNS查询时,先把请求发给本地DNS服务器,本地DNS服务器接收到所需的IP地址时再发送给发出请求的主机。
DNS的运行过程
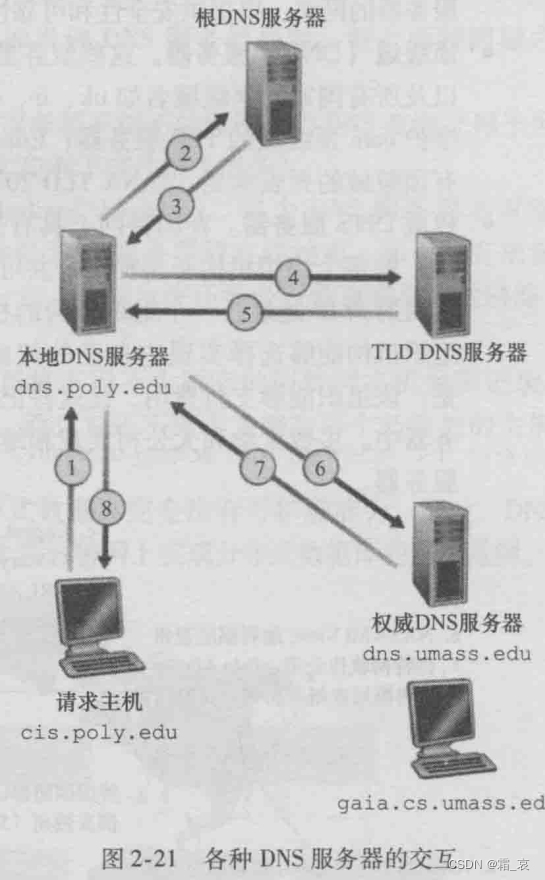
- 请求主机向本地DNS服务器请求目的主机的IP地址
- 本地DNS服务器向根DNS服务器发出请求,根DNS服务器发现主机名有edu后缀,告知本地DNS服务器负责edu顶级域的TLD DNS服务器
- 本地DNS服务器向TLD DNS服务器发出请求,TLD DNS服务器发现主机名中有umass.edu后缀,告知本地DNS服务器负责这个后缀的权威DNS服务器。
- 重复这个过程,本地DNS服务器得到目的主机的IP地址,将这个IP地址返回给请求主机。
递归查询、迭代查询
不难看出,上述过程中请求主机向本地DNS服务器请求,本地DNS服务器再向其他服务器请求的过程是递归的,称为递归查询;而本地DNS服务器一个个向根DNS服务器等查询过去的过程是迭代的,称为迭代查询。
DNS缓存
本地DNS服务器为主机请求过一次IP地址后,会把目的主机名和其IP地址的映射暂时存储起来,称为DNS缓存。这样如果短时间内还有对相同主机名的请求,就可以直接返回需要的IP地址。由于主机名或IP地址可能会换,因此这个缓存一般只会存在两天。
DNS记录
DNS映射以资源记录的方式存储在DNS服务器中,资源记录包含4个元素:(Name,Value,Type,TTL),其中TTL指的是该记录的寿命,即它存在的时间。其他三个元素中,Name和Value的关系由Type决定。

DNS报文
DNS报文格式如下:

首部区域
一个12字节的区域。
- 标识符:标识这个查询的唯一标志,用于把请求报文和响应报文匹配起来。
- 标志字段:带有若干标志的字段。这些标志含有一些想要传达给对方的信息,例如这是一个查询/回答报文、发出该报文的服务器是否是一个权威DNS服务器等。
- 其他字段:指出了在首部后的4类数据区域出现的数量。
问题区域
发送正在查询的问题信息,包括所查询的主机名和类型信息,即资源记录的Name和Type,根据这些信息,能够得到Value。
回答区域
包含了要查询的资源记录。有时可能有多条记录,因为一个主机名可能对应多个IP地址。
权威区域
其他权威服务器的记录。
附加区域
其他有帮助的记录。
插入DNS记录
当你需要插入DNS资源记录时,你需要将你的域名(域就是一个或多个权威DNS服务器管辖的地盘)注册在注册登记机构,
当注册时,你需要提供域名、域中权威DNS服务器的主机名和它的IP地址。注册登记机构会验证信息唯一并将这些信息输入数据库。
P2P
P2P体系结构指在一个网络中,所有主机都既上载文件也下载文件,他们是对等的。
P2P文件分发
P2P的扩展性
由于新加入的主机也会贡献数据和带宽用于传输,P2P网络的扩展性大大强于客户-服务器体系结构。
原书中关于这一点做了比较严密的数学证明,我们这里省略。
BitTorrent
BitTorrent是一个文件分发的P2P协议。
术语
- 文件块:一个特定文件的等长度部分,通常为256KB。
- 洪流:在一个网络中参与同一个文件分发的所有对等方的集合。
- 追踪器:每个洪流含有一个追踪器,一个对等方加入洪流时,向追踪器注册,并周期性通知追踪器它还在洪流中,达到跟踪对等方的目的。
运行过程
- 对等方A加入洪流,追踪器随机挑出随机数量的其他对等方给A,A与这些对等方创建TCP连接。与它创建TCP连接的对等方称为临近对等方。
- A周期性的询问它的所有临近对等方他们拥有该文件的块列表,并由此决定请求哪些块。
重要机制
- 请求哪些块?
A采用最稀缺优先技术,即请求它没有的块中最少邻居拥有的块。例如,如果当它发现有一个块它自己没有且只有一个邻居有,那它一定会先请求这个块。通过这个机制,可以保证最稀有的块能快速传播。 - 向哪些向它请求的邻居发送?
A采用称作一报还一报的方法。这种方法能让主机之间用相接近的快速率相互传输数据。
- 它周期性检测别人给它数据的速度,并为能以最高速率给它提供数据的前四个邻居提供数据。这四个邻居称为疏通
- 同时每30秒,它尝试为另外一个邻居B发送数据,B如果发现A为它提供数据的速度较快,就会把A列入他自己的疏通清单中,并为A提供数据。
- 接收到B数据的A如果发现B为它提供的数据速度也很快,会把B列入它的疏通清单中,这样A和B就能以较快的速率相互传输数据。

我是霜_哀,在算法之路上努力前行的一位萌新,感谢你的阅读!如果觉得好的话,可以关注一下,我会在将来带来更多更全面的计网知识讲解!