目录
前言
本篇主要记录了Java基础相关的面试问题涉及到的知识点透析,如面向对象特征,ArrayList和LinkedList区别,线程安全集合,ArrayList底层扩容,HashMap常问知识点,设计模式,单例设计模式理解等等,后续遇到新的面试题会继续完善并补充详细,最后感谢您的阅览,愿您终有所获
注:这其中的设计模式还没来得及做过多了解,但后续学习到会继续补充,能帮到各位是我得荣幸
并发篇地址:Java面试准备之并发篇
虚拟机篇地址:Java面试准备之虚拟机篇
一. Java基础
1. Java面向对象有哪些特征
Java面向对象有三大特征,封装,继承,多态
其中,封装是增加了代码的复用性,封装好的代码可以重复使用,体现高内聚,低耦合
封装说明的是一个类的行为和属性与其他类的关系
封装隐藏了类的内部实现机制,可以在不影响使用的情况下改变类的内部结构,同时也保护了数据。对外界而已它的内部细节是隐藏的,暴露给外界的只是它的访问方法。
继承也是增加了代码的复用性,不用频繁的重新编写方法,而是直接继承父类方法
继承是父类和子类的关系
继承是从已有的类中派生出新的类,新的类能吸收已有类的数据属性和行为,并能扩展新的能力。
多态是增加了代码的可移植性,健壮性,灵活性
多态说的是类与类之间的关系
封装和继承最后归结于多态,多态指的是类和类的关系,两个类由继承关系,存在有方法的重写,故而可以在调用时有父类引用指向子类对象。多态必备三个要素:继承,重写,父类引用指向子类对象。
2. ArrayList和LinkedList有什么区别
ArrayList底层是以数组实现的,对于随机访问的时间复杂度是O(1)
但是对于头部插入删除操作效率要低于LinkedList,而ArrayList尾部的插入删除操作还要比LinkedList快许多,因为尾部操作,直接在数组后面加或删,根据索引定位,比LinkedList更改指针指向还要更加快
LinkedList底层是以双向链表实现的,它对于头部和尾部添加,删除的操作,时间复杂度为O(1),但是对于随机访问效率要低于ArrayList
重点来了:
①对于查询操作,二者耗时是一样的,根据值去查找,都需要一个一个比较
②对于中间元素的插入,删除操作,LinkedList要比ArrayList耗时更多,因为LinkedList的双向链表,虽然链表对于删除插入操作效率更高,但是它需要先遍历到中间位置,链表遍历耗时长,时间浪费在遍历到对应索引位置上了
③LinkedList占用内存多于ArrayList,下图可以看的很清楚
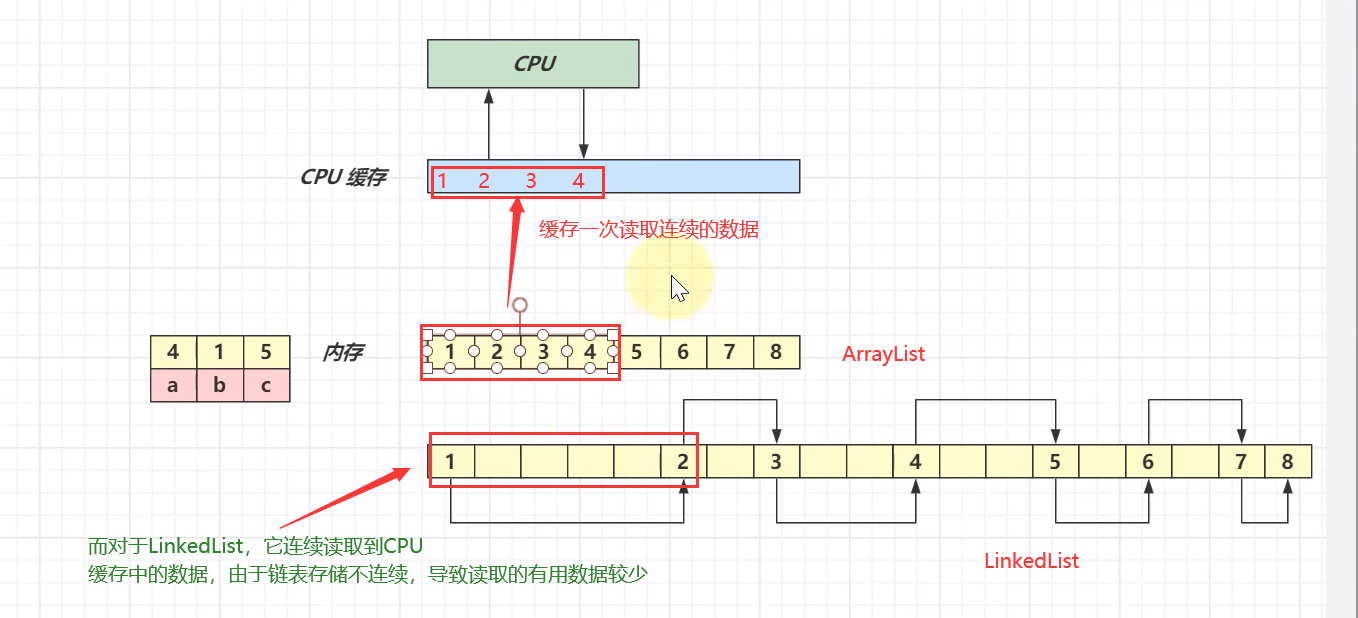
总结
ArrayList
- ①基于数组,需要连续内存
- ②随机访问快(指根据下标访问)
- ③尾部插入、删除性能可以,其它部分插入、删除都会移动数据,因此性能会更低
- ④可以利用cpu缓存,局部性原理
LinkedList
- ①基于双向链表,无需连续内存
- ②随机访问慢(要沿着链表遍历)
- ③头尾插入删除性能高
- ④占用内存多
3. 高并发的集合有哪些问题
线程非安全集合类
ArrayList、HashMap 线程不安全,但是性能好
需要线程安全怎么办呢?
使用Collections.synchronizedList(list); Collections.synchronizedMap(m);
底层使用synchronized代码块锁虽然也是锁住了所有的代码,但是锁在方法里边,比锁在方法外边性能可以理解为稍有提高吧。
线程安全集合类
ConcurrentHashMap
CopyOnWriteArrayList
CopyOnWriteArraySet
底层大都采用Lock锁(1.8的ConcurrentHashMap不使用Lock锁),保证安全的同时,性能也很高。
4. 迭代器的fail-fast和fail-safe
对于迭代器,可以遍历list,set这些单列集合,其中有一个问题,在遍历这些集合时,是否允许其他线程对集合进行插入修改操作呢?
下面是迭代器的两种处理策略
fail-fast一旦发现遍历的同时其它人来修改,则立刻抛异常
fail-safe发现遍历的同时其它人来修改,应当能有应对策略,例如牺牲一致性来让整个遍历运行完成
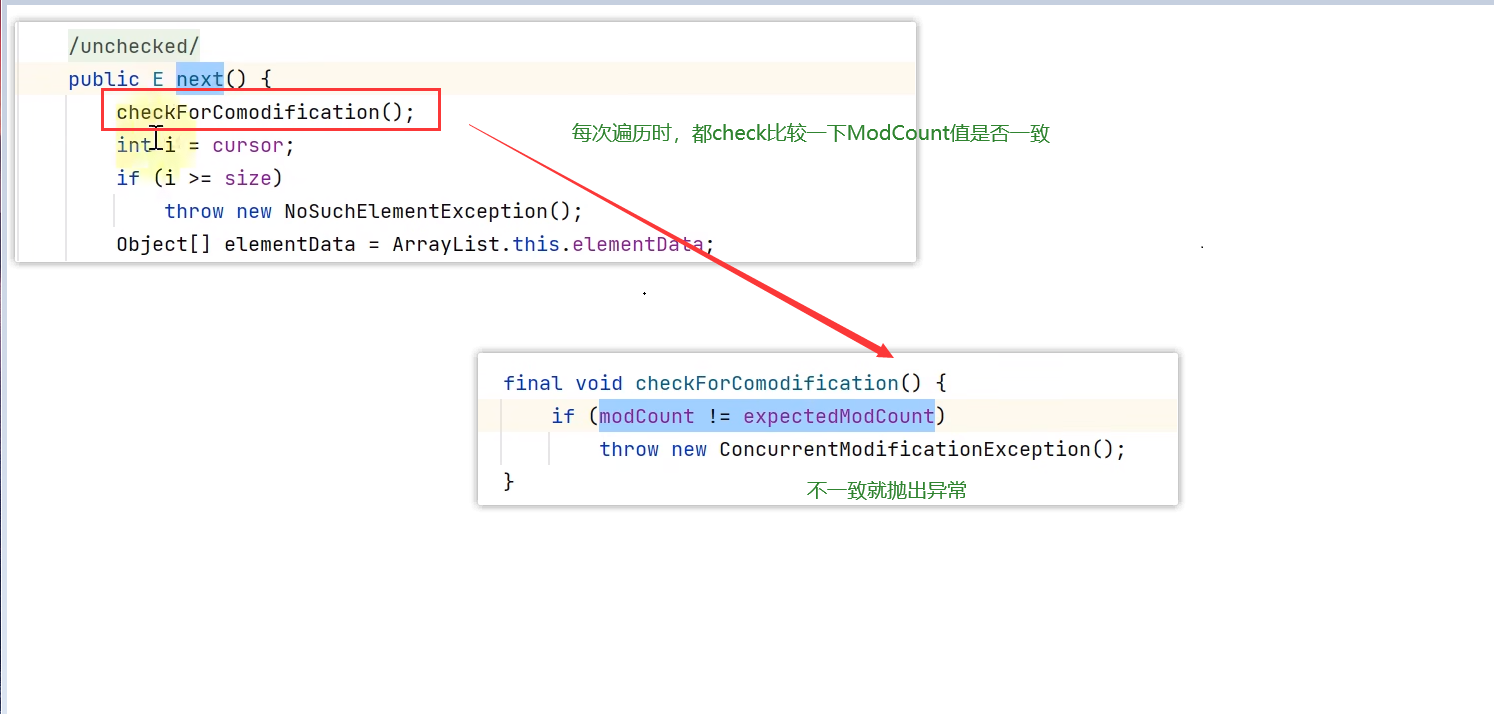
对于ArrayList的迭代器就是属于fail-fast这种策略,它是不允许一边遍历一边修改的,会直接报错,尽快失败
迭代器的fail-fast源码分析,其实就是我之前讲的并发修改异常,地址:http://t.csdn.cn/C43GG;在遍历开始时,记录modCount(修改值),然后在每次的next()中调用checkForComodification()方法;检查modCount,比较两个modCount是否一致来判断
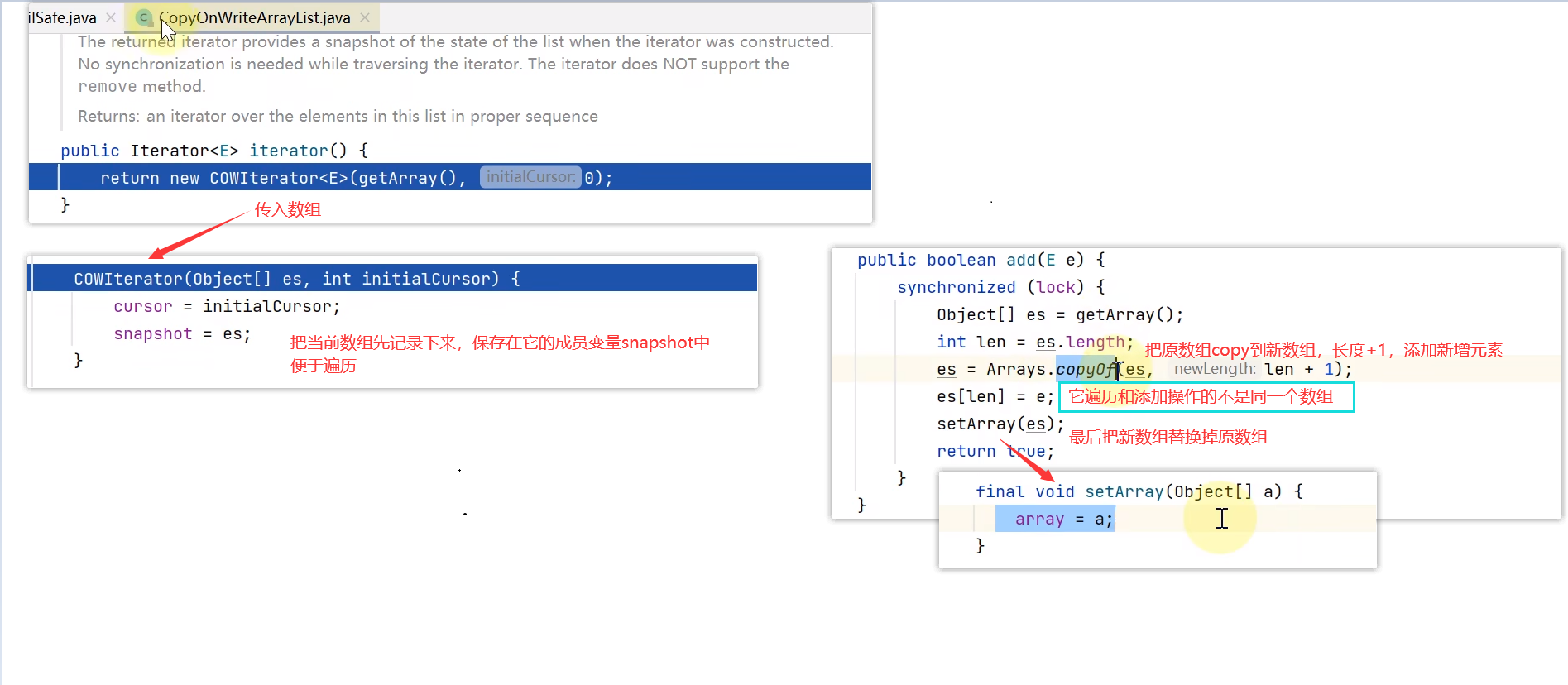
而对于CopyOnWriteArrayList的迭代器(迭代器其实是它里面的内部类,每个集合的迭代器都有可能不同)
具体流程见下图,简而言之就是它的遍历和添加操作的不是同一个数组,用读写分离的方式,来处理遍历时的数组修改,牺牲一致性来让整个遍历运行完成
总结
fail-fast 与fail-safe
- ArrayList是 fail-fast的典型代表,遍历的同时不能修改,尽快失败
- CopyOnWriteArrayList是 fail-safe 的典型代表,遍历的同时可以修改,原理是读写分离
5. ArrayList底层扩容机制
JDK7初始化一个ArrayList集合时,初始容量为10;
JDK8初始化一个ArrayList集合时,长度为0,只有在添加元素时,才会给数组赋予大小
扩容机制分两种
一种是,超过了数组容量大小,底层数组扩容为原数组的1.5倍,并把原数组中的元素拷贝到新数组中
另一种是,新增加的元素数量超过了数组扩容后的容量,简单说就是即使数组扩容1.5倍后,仍然不能满足新增元素的个数(addAll这种方法),这时,扩容长度就是需要容纳所有元素的长度
容易记的说法,下次扩容的容量跟实际元素个数中取一个较大值,来作为数组的最终大小
6. HashMap面试合集解答
底层数据结构,1.7和1.8有何不同
在JDK7,HashMap底层数据结构是: 数组 + 链表的形式
而在JDK8, 其底层结构式:数组 + 链表 + 红黑树的结构
int index =(数组长度-1)&哈希值;
上面就是计算存储位置的公式
哈希表最大的优点就是实现集合中元素的快速查找
因为数组下标索引是根据元素的哈希值来计算得到的,所以可以根据元素值快速定位索引,找到元素位置,判断位置是否有元素,若没有即未找到;位置若有元素,比较二者hash值是否相同,相同即找到了该元素。可以通过值来查询,这是ArrayList无法比拟的,ArrayList只能用索引来查找不能根据元素值来查找
HashMap底层的数组扩容阙值是,元素个数达到了数组容量的3/4(或数组长度*扩容因子),就会扩容为原数组的两倍
树化条件
而它的链表树化时机是当链表长度大于8而且数组长度大于等于64时,链表转化为红黑树
而当数组长度未达到64,而链表长度大于等于8时,虽然不会树化,但是会进行数组扩容(链表长度可能会大于8)
树化为红黑树后,它左侧都是比根节点小的元素,右侧都是比根节点大的元素
为什么不一上来就树化
短链表时,它的性能是比红黑树要好的,最多比较几次而已,长链表情况下,红黑树的效率更高,优化也是优化在这种情况;而且红黑树底层的结构TreeNode(成员变量比Node多)比Node占用内存更多,所以链表较短情况下, 树化是没有性能提升的
为什么树化阙值是8
红黑树用来避免DoS攻击,防止链表超长时性能下降,树化应当是偶然情况
①hash表的查找,更新的时间复杂度是O(1),而红黑树的查找,更新的时间复杂度O(log2n),TreeNode占用空间也比普通Node的大,如非必要,尽量还是使用链表。
②hash值如果足够随机,则在 hash表内按泊松分布,在负载因子0.75的情况下,长度超过8的链表出现概率是0.00000006(一亿分之六),选择8就是为了让树化几率足够小
红黑树何时会退化为链表
退化情况1:在扩容时如果拆分树时,树元素个数<=6则会退化链表
退化情况2: 在remove树节点时,若root(根节点)、root.left(左孩子节点)、root.right(右孩子节点)、root.left.left(左孙子节点)有一个为null(不存在),也会退化为链表
注:举例:当删除左孩子节点时,树不会退化,但是再次执行remove操作时,会判断,若没有左孩子,就会退化为链表;
情况1和情况2不要混为一谈,1是在数组扩容时的条件,2是在删除树的结点时的条件
如何计算索引
计算对象的hashcode(),再进行调用HashMap的 hash()方法进行二次哈希,最后和数组长度减一按位与运算
哈希值 mod 数组长度 等价于==> 哈希值 & (数组长度 - 1)
用位运算效率更高,性能更高
前提是数组长度是2的n次方
二次hash()是为了综合高位数据,让哈希分布更为均匀
计算索引时,如果是2的n次幂可以使用位与运算代替取模,效率更高;扩容时 hash & 原数组长度==0的元素留在原来位置,否则新位置=旧位置索引+原数组长度
缺点:数组容量是2的n次幂时,分布性没有选质数的好
put方法流程,1.7和1.8的区别
扩容过程,先把元素添加到旧数组,然后达到阙值数组扩容,再把旧数组的所有元素迁移到新数组
1.7和1.8的不同之处
-
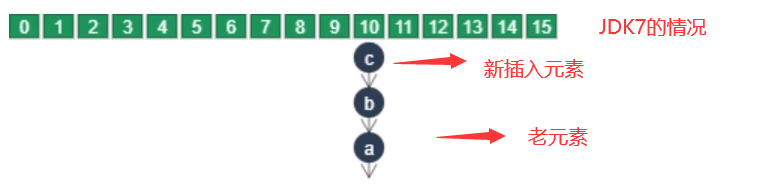
①链表插入节点时1.7是头插法(新元素存数组,老元素挂新元素下面);1.8是尾插法(新元素直接挂老元素下面)
-
②1.7是大于阙值而且没有空位时,数组才会扩容;而1.8时大于阙值就进行扩容
-
③1.8在扩容计算Node索引时,会优化,扩容时 hash & 原数组长度==0的元素留在原来位置,否则新位置=旧位置索引+原数组长度
加载因子 / 扩容因子为何是0.75f
- 在空间占用与查询时间之间取得较好的权衡
- 大于这个值,空间节省了,但链表就会比较长影响性能
- 小于这个值,冲突减少了,但扩容就会更频繁,空间占用也更多,造成空间浪费
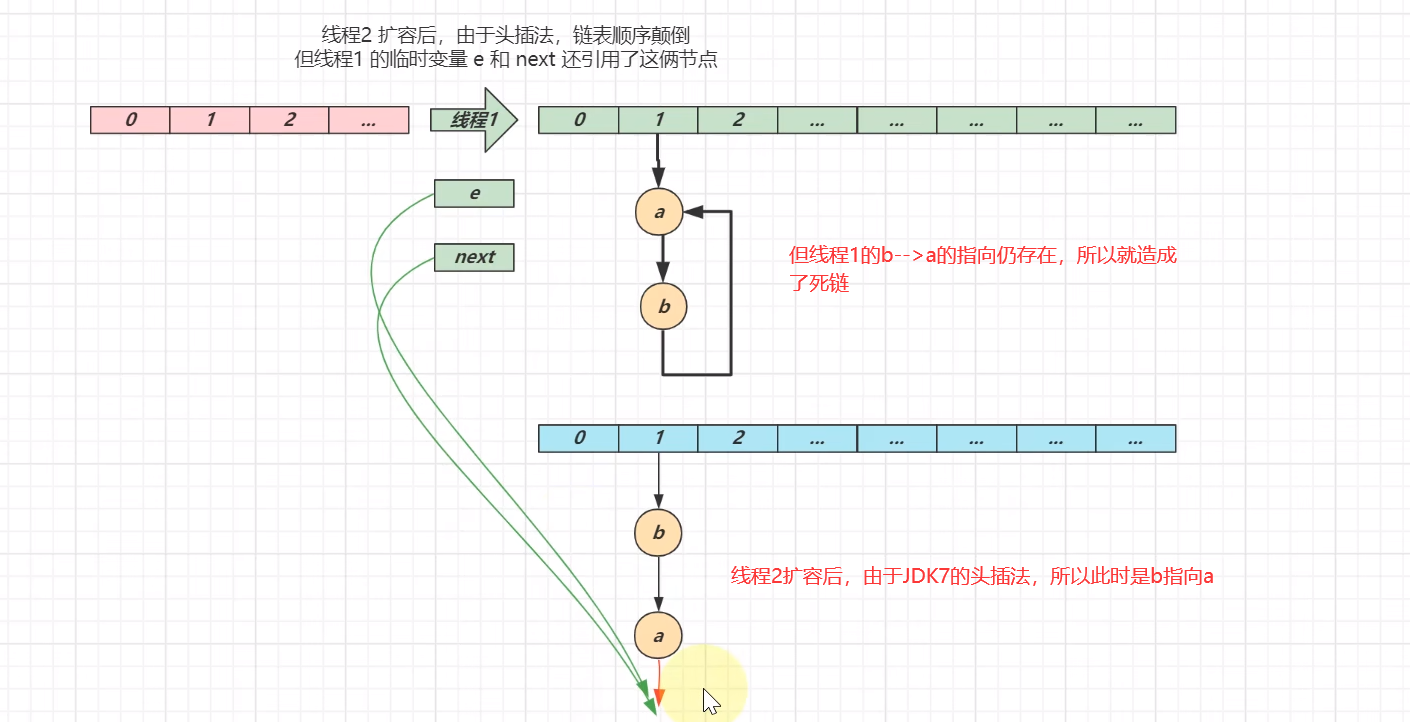
多线程下操作HashMap有啥问题
数据错乱(1.7,1.8 都会存在)
JDK7会发生死链问题,原因就识JDK7的头插法
JDK7的头插法认识
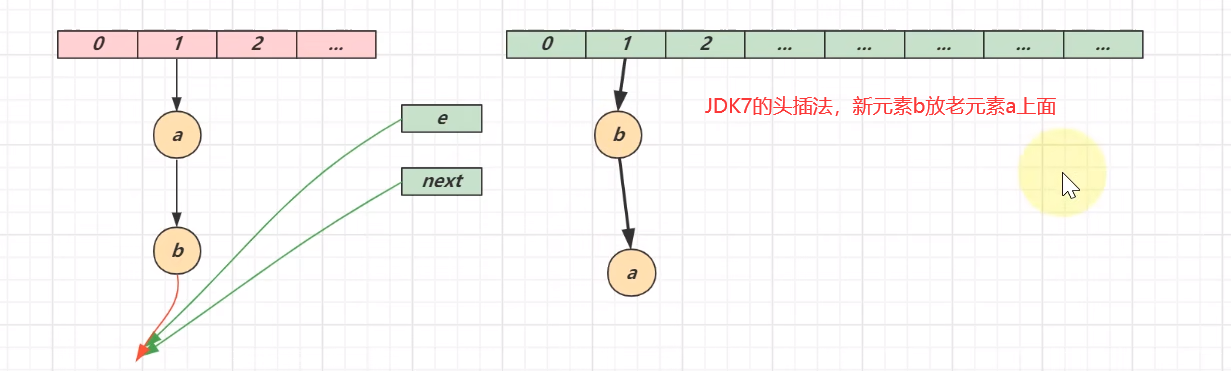
别眨眼,接下来是多线程情况下

Key能否为null,作为key的对象有什么要求
- HashMap 的 key 可以为 null,但 Map 的其他实现则不然
- 作为 key 的对象,必须实现 hashCode(更好的分布性) 和 equals(万一hash值相同,比较equals),并且 key 的内容不能修改(不可变);hashCode不一定equals,但一旦equals了,必然hashCode相同
- key 的 hashCode 应该有良好的散列性
二.设计模式
1. 单例设计模式
实现方式之一
饿汉式:一开始就先把INSTANCE对象创建出来,提前创建
- 构造方法抛出异常是防止反射破坏单例
readResolve()是防止反序列化破坏单例
public class Singleton1 implements Serializable {
private Singleton1() {
if (INSTANCE != null) {
throw new RuntimeException("单例对象不能重复创建");
}
System.out.println("private Singleton1()");
}
private static final Singleton1 INSTANCE = new Singleton1();
public static Singleton1 getInstance() {
return INSTANCE;
}
public static void otherMethod() {
System.out.println("otherMethod()");
}
public Object readResolve() {
return INSTANCE;
}
}
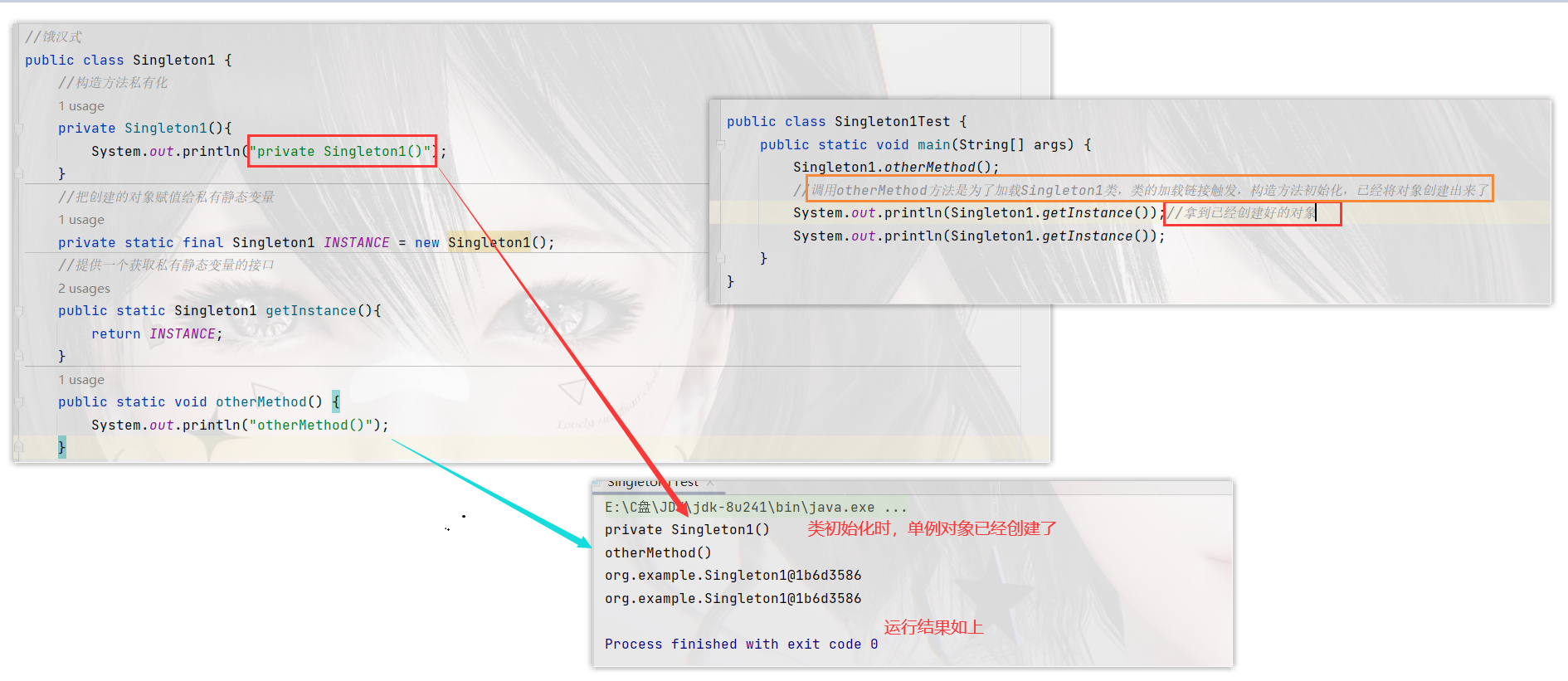
但是以下几种方式会破坏单例
①反射
可以加个判断来防止暴力反射,创建对象,以免破坏单例
已经创建了单例对象,再用反射调用创建对象时会报错
if (INSTANCE != null) {
throw new RuntimeException("单例对象不能重复创建");
}
②反序列化
拿到单例对象后通过ObjectOutStream来把对象变成一个字节流,再通过ObjectInputStream还原成一个对象序列化反序列化过程又可以造出一个新的对象,甚至不需要走构造方法
防止方法
重写readResolve()方法后,反序列化时就会用readResolve()的方法返回值作为结果返回,而不是通过字节数组反序列化生产的对象了
public Object readResolve() {
return INSTANCE;
}
③Unsafe
unsafe是JDK内置的一个类,它其中有一个allocateInstance(clazz)方法,可以根据参数类型,创建这个类型的实例,也不会走构造方法,目前没有防止的方法
实现方式之二
枚举饿汉式
枚举饿汉式能天然防止反射、反序列化破坏单例
public enum Singleton2 {
INSTANCE;
private Singleton2() {
System.out.println("private Singleton2()");
}
@Override
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
public static Singleton2 getInstance() {
return INSTANCE;
}
public static void otherMethod() {
System.out.println("otherMethod()");
}
}
实现方式之三
懒汉式单例
用的时候再创建单例对象,什么时候调,什么时候创
但是饿汉式是线程不安全的,在多线程情况下,无法保证单例,所以只能在创建单例对象方法上加synchronized来修饰,加锁保证单例
public class Singleton4 implements Serializable {
private Singleton4() {
System.out.println("private Singleton4()");
}
private static volatile Singleton4 INSTANCE = null; // 可见性,有序性
public static Singleton4 getInstance() {
if (INSTANCE == null) {
synchronized (Singleton4.class) {
if (INSTANCE == null) {
INSTANCE = new Singleton4();
}
}
}
return INSTANCE;
}
public static void otherMethod() {
System.out.println("otherMethod()");
}
}
为何必须加 volatile:
INSTANCE = new Singleton4()不是原子的,分成 3 步:创建对象、调用构造、给静态变量赋值,其中后两步可能被指令重排序优化,变成先赋值、再调用构造- 如果线程1 先执行了赋值,线程2 执行到第一个
INSTANCE == null时发现 INSTANCE 已经不为 null,此时就会返回一个未完全构造的对象
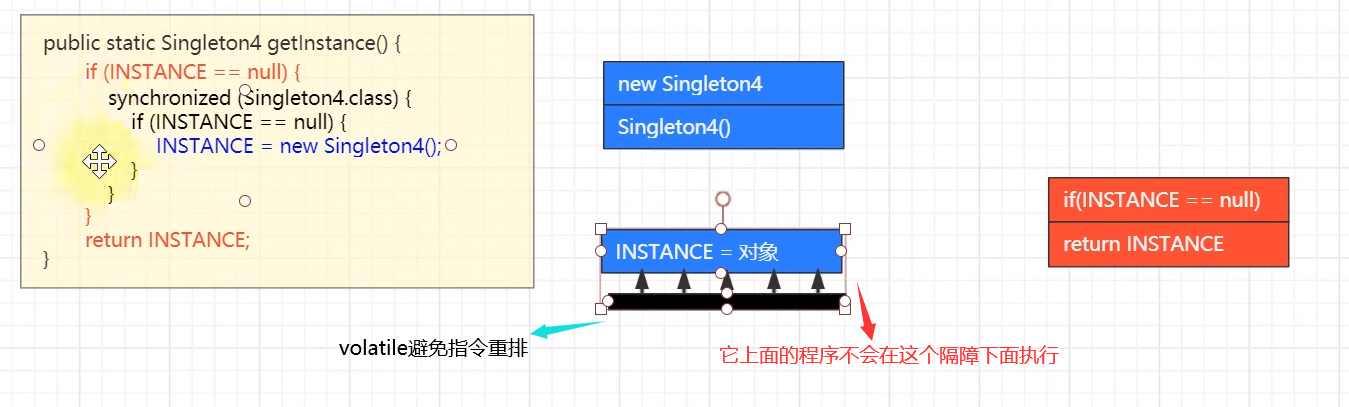
这里注意一下使用的是双检锁的方式来创建单例对象,在多个线程竞争锁时,获取到锁的执行,未获取到锁的挂起,等到释放锁后,挂起的线程被唤醒,而此时单例对象已经存在了,所以需要再次进行判断,防止创建新的对象
if (INSTANCE == null) {
synchronized (Singleton4.class) {
if (INSTANCE == null) {
INSTANCE = new Singleton4();
}
}
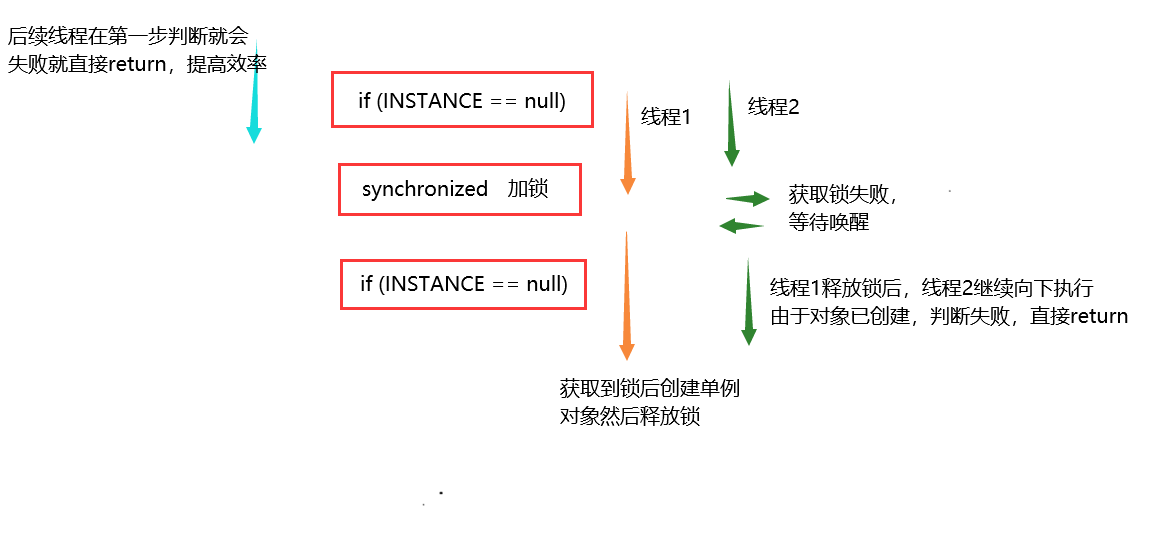
反问:为什么饿汉式不用考虑线程安全问题?
因为饿汉式创建单例对象时赋值给静态变量的,单例对象会在类加载时就创建了,由JVM保证其原子性且安全执行;JVM保证了初始化阶段的线程安全
枚举饿汉式也是在静态代码块里创建枚举变量的,它的线程安全也不需要考虑
实现方式之四
内部类懒汉式
这就运用了饿汉式的保证线程安全的方法
内部类在使用时初始化,这样创建单例对象的操作就在静态代码块中执行,避免了线程安全问题
public class Singleton5 implements Serializable {
private Singleton5() {
System.out.println("private Singleton5()");
}
private static class Holder {
static Singleton5 INSTANCE = new Singleton5();
}
public static Singleton5 getInstance() {
return Holder.INSTANCE;//这时会触发内部类的加载链接触发
}
public static void otherMethod() {
System.out.println("otherMethod()");
}
}
既兼备了懒汉式的特性又避免了双检锁的缺点
2. 哪些地方体现了单例模式
- Runtime 体现了饿汉式单例
- System.java的Console 体现了双检锁懒汉式单例
- Collections 中的 EmptyNavigableSet 内部类懒汉式单例
- ReverseComparator.REVERSE_ORDER 内部类懒汉式单例
- Comparators.NaturalOrderComparator.INSTANCE 枚举饿汉式单例