接上篇,继续梳理 Python 编码规范中的一些实用建议。
1、基础的规范
<1>、导包:
Python 支持 import 语句、from...import...语句、__import__() 函数等方式引入外部模块。
实际使用中,应避免使用 from a import *,这种语句无法清晰的表达导入哪些模块;建议有节制的使用 from a import b,可以通过 import a,然后使用a.b形式访问b。
# from filecmp import cmp
import filecmp
def delete_file(path1, path2):
# if cmp(path1, path2):
if filecmp.cmp(path1, path2):
path1.unlink()<2>、异常处理:
- 控制异常的粒度,避免在 try 语句中放入过多的代码;
- 注意异常捕获的顺序,在合适的层次进行处理异常,否则有可能导致异常淹没情况发生;
- 谨慎使用单独的 except 语句处理所有异常(像这种 except Exception,也有可能会导致异常淹没情况发生),最好能抛出具体的异常;
- 异常信息的输出要考虑友好性,对于用户需要的是体验,要输出与业务相关的异常信息,而对于开发者,则需要输出具体的异常堆栈信息,便于定位原因和修复。
<3>、Linux系统下编写代码:
Linux 服务器上通过 python 命令执行 xx.py 时,第一步需要声明 Python 解释器。因此,在源码文件内第一行的写法如下:
#!/usr/bin/env python以#!开头的代码标记了该解释器的具体位置,这种风格通常又被称为 “Hashbang” 或 “shebang”。
<4>、努力降低算法的复杂度:
同一个功能可以用不同的算法实现,而算法的优劣也将直接影响程序的效率和性能。算法主要是从时间复杂度和空间复杂度考虑的,关于算法复杂度的内容可以参考另一篇博客,这里重点考虑时间复杂度的影响,常使用大写字母 O 表示,大 O 的排序比较:
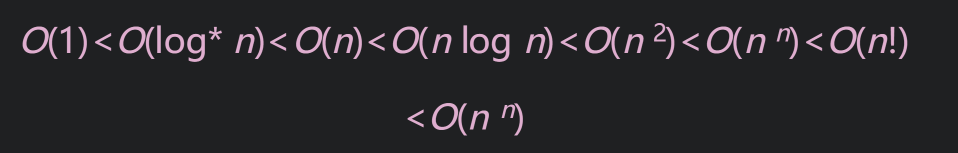
Python 常见的数据结构基本操作的时间复杂度,参考如下:

平时使用中,应多考虑时间复杂度低的操作。
2、容易忽略的陷阱
<1>、++i 的陷阱:
记得刚开始使用 Python 的时候,对一个变量i进行自增,毫不犹豫的使用了 ++i,发现没有报错,但得到的结果却出人意料,测试如下:
elements = []
i = 1
for j in range(10):
elements.append(++i)
print(elements) # [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]正常情况下,列表输出1~10才对啊。这就是一个一不注意就踩坑的地方了,我们把 ++i 赋值给另一个变量可以发现就报错了,原因很简单:Python 不支持自增运算,哈哈哈,真细节啊!那么 ++i 未赋值怎么就不报错了呢?这是因为 Python 解释器会把 ++i 当做 +(+i) 看待,+表示正数,正所谓正正得正,不信可以把 ++i 换成 -+i 试试就明白了,如下:
elements = []
i = 1
for j in range(10):
elements.append(-+i)
print(elements) # [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1]<2>、正确使用类型检查:
通常,我们会在程序出错的情况下通过抛异常进行处理,而在实际应用中,为了提高程序的健壮性,仍需要进行必要的类型检查。当然,最容易想到的就是使用内建函数 type() 了,它可用来返回当前对象的类型。对于基本类型来说,使用 type() 进行类型检查是没什么问题的,但在某些特殊场景,type() 并不能准确的返回结果。
这种情况下,我们可以使用基本类型提供的函数先转换再进行类型检查,比如 str(name),list(listing),set(seting) 等。当然,也可以使用 isinstance() 函数进行类型检查。
a = 1314
# <class 'int'>
print(type(a))
# True
print(isinstance(a, int))<3>、谨慎使用可变长参数:
还记得 *args 和 **kwargs 这两种可变长参数的含义吗?*args 传入的是元组类型的参数列表,而 **kwargs 传入的是字典类型的参数列表。现在自定义一个方法,如下:
def func1(x, y, z, color=None, label=None, *args, **kwargs):
pass猜一猜,以下哪些调用方式是正确的?(哈哈哈,禁止套娃??!!)
# 函数调用
func1()
func1(1, 2)
func1(1, 2, 3)
func1(1, 2, 3, 4)
func1(1, 2, 3, 4, 5)
func1(1, 2, 3, 4, 5, 6)
func1(1, 2, 3, 4, 5, 6, 7)
func1(1, 2, 3, 4, 5, 6, 7, 8)
func1(1, 2, 3, 4, 5, 6, 7, 8, 9)如果方法代码没有判断参数不能为空,以上写法都是合法的!而且理论上可以有无限长的参数列表!!这下能看出来为什么谨慎使用变长参数了吧,使用得当还可以,不然很容易引起混乱。
当不得不使用这种方法时,为了表达清晰,可以写成如下方式:
seq = (6, 7, 8, 9)
func1(1, 2, 3, color=4, label=5, seq)当然,有些场景是非常适合使用变长参数的,比如自定义装饰器、实现方法的多态、子类继承父类并重写父类方法等场景。
<4>、函数参数值传递与引用传递的误区:
在 C++、Java 等编程语言中,函数参数传递存在值传递和引用传递之分,那么如何区分这两个传递类型呢?简单点说就是:
- 值传递:实参向形参传递的是值,在内存上二者是独立的变量,对形参的修改不会影响到实参;
- 引用传递:形参会使用到实参的地址,即实参向形参传递的是堆栈上的地址,在内存上二者指向同一块内存区域,对形参修改会影响到实参;
Python 也是一门面向对象的语言,一切皆对象,无论是不可变的数据类型(如数字,字符串,元组等),还是可变的数据类型(如列表、字典,集合等),它们都是对象。那么,Python 的函数传参有什么不同呢?
对于不可变对象,举例如下:
def func1(b):
print(f'修改前的形参:b={b}, id={id(b)}')
b = b + 1
print(f'修改后的形参:b={b}, id={id(b)}')
if __name__ == '__main__':
a = 1314
func1(1314)
print("------------------------------------")
print(f'实参:a={a}, id={id(a)}')这里的 id() 函数用于获取对象的内存地址,测试结果如下:
修改前的形参:b=1314, id=2033496212336
修改后的形参:b=1315, id=2033216809104
------------------------------------
实参:a=1314, id=2033496212336可以看出,对于不可变对象的修改操作,修改前后的形参的内存地址是两个独立的变量,且形参不会影响到实参(有点类似值传递)。
再来看下可变对象,举例如下:
def func2(list):
print(f'修改前的形参:list={list}, id={id(list)}')
list.append('world')
print(f'修改后的形参:list={list}, id={id(list)}')
if __name__ == '__main__':
list = ['hello']
func2(list)
print("------------------------------------")
print(f"实参:list={list}, id={id(list)}")测试结果如下:
修改前的形参:list=['hello'], id=2746871145984
修改后的形参:list=['hello', 'world'], id=2746871145984
------------------------------------
实参:list=['hello', 'world'], id=2746871145984不难看出,对于可变对象的修改操作,修改前后的形参指向的是同一块内存区域,并且对形参的修改会影响到实参(有点类似引用传递)。
其实,Python 函数的参数传递既不是值传递, 也不是引用传递,更为准确的描述应该是:Python 函数的参数传递方式为对象传递及对象的引用传递。
<5>、排序函数的使用:
Python 提供了两种内置排序函数,分别为 sort() 和 sorted(),二者的源码如下:
sort(self: List[SupportsLessThanT], *, key: None = ..., reverse: bool = ...)
sorted(__iterable: Iterable[_T], *, key: Callable[[_T], SupportsLessThan], reverse: bool = ...)不难看出,二者是有很大的使用区别:
- sort() 是列表内置的排序方法,key 置为 None,reverse 用于标识是否排序反转。
- sorted() 则不限于列表排序,对于可迭代对象(比如元组、字典,以及复合型的迭代对象 --- 列表中混合字典/元组、字典中混合列表/元组等)都可进行排序,第一个参数则是可迭代对象,第二个参数 key 是自定义排序规则,第三个参数 reverse 是标识是否排序反转。
- 使用 sort() 排序列表,会修改原列表并返回 None;使用 sorted() 排序可迭代对象,会返回新的对象,而不改变原对象。
以列表排序为例,说明 sort() 用法:
test_list = [7, 56, 14, 20, 13, 6, 81, 7, 11]
# 按默认顺序
rs1 = test_list.sort()
print(f"{test_list}") # [6, 7, 7, 11, 13, 14, 20, 56, 81]
print(f"{rs1}") # None
# 按倒序
rs2 = test_list.sort(reverse=True)
print(f"{test_list}") # [81, 56, 20, 14, 13, 11, 7, 7, 6]
print(f"{rs2}") # None以列表排序为例,说明 sorted() 用法:
test_list = [7, 56, 14, 20, 13, 6, 81, 7, 11]
# 按默认顺序
rs1 = sorted(test_list)
print(f"{test_list}") # [7, 56, 14, 20, 13, 6, 81, 7, 11]
print(f"{rs1}") # [6, 7, 7, 11, 13, 14, 20, 56, 81]
# 按倒序
rs2 = sorted(test_list, reverse=True)
print(f"{test_list}") # [7, 56, 14, 20, 13, 6, 81, 7, 11]
print(f"{rs2}") # [81, 56, 20, 14, 13, 11, 7, 7, 6]再以复合的可迭代对象类型排序,说明 sorted() 用法:
from operator import itemgetter
nums = [{'name': 'jack', 'age': 12, 'weight': 72.49},
{'name': 'tom', 'age': 16, 'weight': 75.2},
{'name': 'kitty', 'age': 15, 'weight': 71.9}]
# 根据年龄,倒序输出
print(sorted(nums, key=itemgetter('age'), reverse=True))
# 根据体重,正序输出
print(sorted(nums, key=itemgetter('weight')))
# 先按年龄再按体重进行组合排序,正序输出
print(sorted(nums, key=itemgetter('age', 'weight')))结果如下:

参考资料:
- 《Python代码整洁之道编写优雅的代码》
- 《编写高质量代码:改善Python程序的91个建议》