去年12月1号,自Sam Altman在Twitter上公开宣布ChatGPT后,ChatGPT逐步引发了全球瞩目。据新华社报道,在今年1月份ChatGPT已经拥有了一亿的月活用户,成为了历史上增长最快的应用程序。甚至,斯坦福大学有研究认为它已经具有了人类的心智。
尽管ChatGPT有时会存在事实错误,但是其所拥有的内在的开放域知识、遵循人指示的语言理解能力、代码编写、数学计算、常识推理给我们带来了极大的震撼。就开放域问答这一领域来说,ChatGPT已经完全不同于之前常见的问答技术,带来了全新的范式和变革。
“
本期的Tech Talk,我们邀请到了小米知识问答团队的工程师——刘惠文,为大家介绍ChatGPT的技术演进及问答应用,包括ChatGPT相关的工作和技术,并探讨ChatGPT会给小爱的开放域问答服务带来什么样的转变。

硬核指数:⭐⭐⭐⭐⭐
趣味指数:⭐⭐⭐
阅读时长:约14分钟
一、技术背景
ChatGPT由OpenAI推出,OpenAI是2015年由硅谷大佬里德·霍夫曼、埃隆·马斯克等人创办的非盈利(初始目标)的实验室,旨在研究通用的人工智能技术AGI。ChatGPT也算是在其宗旨下的一个阶段性的成果。
目前其学术论文还没有被公开,不过OpenAI在他们的博客中提到,ChatGPT是基于他们前面的InstructGPT发展而来。其中涉及到GPT系列的相关工作,还有IFT(Instruction Fine-Tuning)、CoT(Chain-of-Thought)和RLHF(Reinforcement Learning from Human Feedback)等。除此之外,目前人们还认为OpenAI的另一份工作Codex也与之相关。总的来说,ChatGPT不是突然出现的,之前的大量研究和技术积累为它的出现创造了条件。
值得一提的是,很多工作并非由OpenAI首创。甚至Meta首席科学家Yann LeCun认为“ChatGPT并没有多大的创新,只是组合的很好,就其底层技术,除了Google和Meta,还有好几家公司都有相似的技术”。但是OpenAI站在前人的肩膀上,借鉴和吸纳了其他的技术最终成就了ChatGPT。在这里,我们首先介绍ChatGPT诞生的技术背景。
>>>> 1.1 GPT1-3
ChatGPT被认为是在GPT系列模型(GPT3.5)的基础上,经过微调和人工反馈强化学习训练得到。GPT(Generative Pre-Training)是一种语言模型(Language Model),最早的模型GPT1在2018年6月由OpenAI推出。GPT1拥有约一亿个可学习的参数,采用自然语言处理(NLP)任务中常见的预训练+微调的模式。值得一提的是,GPT1模型随后被Google团队借鉴和修改,于当年10月份推出了BERT。而在ChatGPT之前,BERT被认为是NLP领域上一个跨时代的工作。
GPT2模型在BERT之后于19年2月份推出。相比GPT1,它具有了更多的参数,达到了15亿,不过它在预训练+微调的模式下仍旧弱于BERT。但是从GPT2开始,OpenAI转变了视角,开始从预训练+微调的模式改为零样本学习。随后而来的Prompt, Instruction以及最终ChatGPT能够自然地与用户交互,都发轫于这一转变。就知名度来说,GPT2可能不如开篇之作GPT1和后面的GPT3,但它承上启下十分的重要。
GPT3在GPT2基础上,于20年5月份推出。它的训练参数达到了1750亿个。这么大规模的参数,需要耗费大量的计算资源才能完成训练,训练花销已高达数百万美元,引发了大型语言模型的新一轮军备竞赛。
GPT3有比较重要的两点:其一,它提出了一种新的范式In-Context Learning,可以认为后面的CoT、IFT都与之相关;其二,GPT3开始表现出了大型语言模型的涌现能力(Emergent Abilities)。涌现能力,通俗点说,就是当模型的参数量比较少时(比如GPT1、GPT2所具备的一亿或者十五亿的参数规模),模型不具备或者具备较弱的相关的能力,但是当参数量变大很多后,这些能力会突然具备或者变得很强。GPT3以数学中的加减法开展了实验,当模型达到GPT3这种参数规模时,它的两位数的加减法运算会好很多。涌现能力是一种意料之外的发现,到目前为止,学术界没有对这一现象给出很好的解释。
>>>> 1.2 IFT
IFT全称是Instruction Fine-Tuning,可以称为遵循指示的微调。通俗点说,就是尽量按照人的语言或者命令等常规说话的那种方式来组织一批训练数据,来对大型语言模型(比如GPT3)进行微调。微调后的这类模型已经是类似于ChatGPT的这种方式,可以更好地“理解”人说的话或者给出的命令,再在这个基础上给出回答。这个领域比较早的工作是2021年10月Google提出的FLAN,FLAN这篇工作在InstructGPT的论文中有提到,被认为和ChatGPT技术相关。
>>>> 1.3 CoT
CoT全称是Chain-of-Thought,中文叫思维链,最早由Google Brain发表在NeurIPS 2022上。思维链,简单点描述,就是用大型语言模型来回答问题前,先给它几个例子,而且在这些例子中给出整个问题的推理过程。比如做数学应用题时,先要给模型出一个例子,例子需要包含题干、答案,思维链的重点是和学生做题时一样,给出中间过程。与思维链相对的是,在给出的例子中,不给中间过程,仅仅给题干和最后的答案。此外,还有一种是鼓励模型自己生成中间过程("Let’s think step by step")的思维链,并基于模型自己的推导过程最终给出答案。
思维连被认为和ChatGPT的能力息息相关,比如,ChatGPT在回答鸡兔同笼的问题时,会给出中间的推导过程。它比较重要的一点在于,没有重新训练或者是微调大型语言模型,而仅仅是在给出的例子中增加了中间步骤的说明,就可以明显提升大型语言模型在数学计算、逻辑推理等任务上的表现。因此,有研究的观点认为,诸如数学计算、逻辑推理是大型语言模型的涌现能力,这些能力在模型规模、训练语料达到一定量级后,就自然而然地出现了,而思维链等方式只是解锁(或者叫唤醒)了这种能力。
>>>> 1.4 RLHF
RLHF,全称Reinforcement Learning from Human Feedback,来自人类反馈的强化学习。不同于模型在预训练阶段使用的大规模无标记文本数据,微调阶段用人工标注好的训练数据。RLHF会在训练过程中,引入人工的干预。模型产生的结果,会被标注人员进行比较和排序,然后这批数据会被用来指导模型的训练和迭代。OpenAI的数据标注质量被认为是比较高的,经过人工的干预,RLHF某种程度上减少了有害和不真实内容的输出。
>>>> 1.5 Codex
除了上述的IFT、CoT、RLHF外,OpenAI的另一项工作Codex有可能和ChatGPT的代码编写、逻辑推理能力相关,Codex也是GitHub的AI代码补全工具Copilot背后的技术。之前GPT3是在互联网上选择文本来进行训练,Codex在训练的过程中加入了GitHub上的代码,并发展了一套评估系统。从论文的结果来看,其在编码能力方面是大大超过GPT3的。
按照介绍,大家可以看到,ChatGPT并不是突然出现的,它所基于的技术,在其他的公司也有积累,甚至做得更早更多。OpenAI做到了集各家之所长,最终拿出了跨时代的成果。
二、问答业务探讨
开放域问答承接的是不限领域的知识类问题,这里我们讨论一下ChatGPT对问答业务的影响。不得不说,ChatGPT已经具备了不限领域,任何问题的回答能力。以下展示ChatGPT在几类知识问题上的效果。
>>>> 2.1 示例
▍2.1.1 语文


图1. ChatGPT回答语文问题示例
▍2.1.2 数学


图2. ChatGPT回答数学问题示例
▍2.1.3 物理
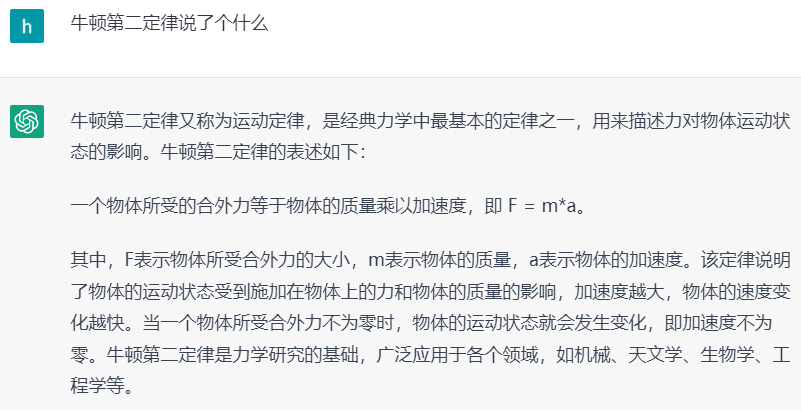
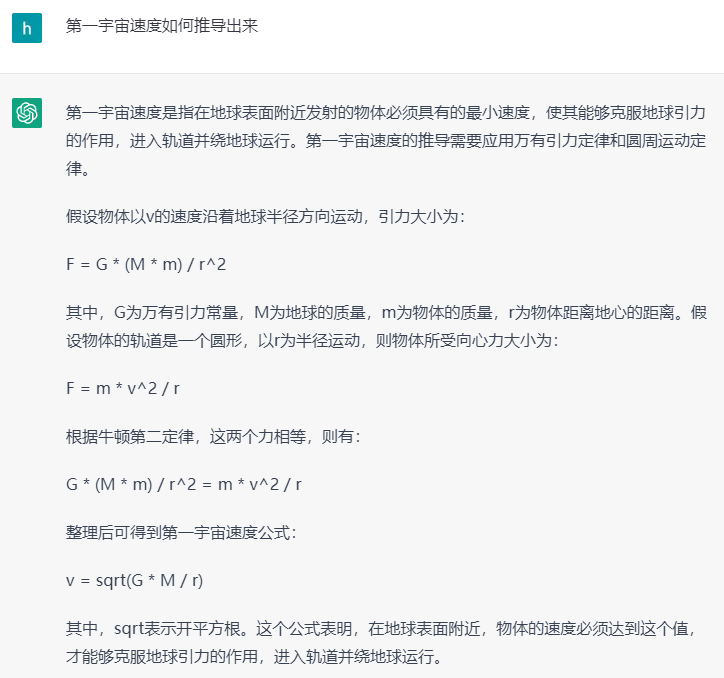
图3. ChatGPT回答物理问题示例
可以看到,ChatGPT能够应付语、数、物等学科知识,而且在比较复杂的数学和物理问题上,ChatGPT不仅给出了结果,还给出了充分的推导过程。除开学科知识,在常识类的长尾问题上,ChatGPT也有很好的表现。
▍2.1.4 常识
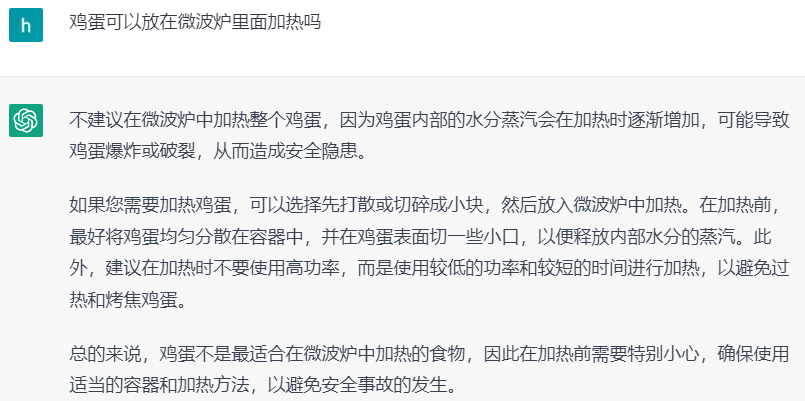
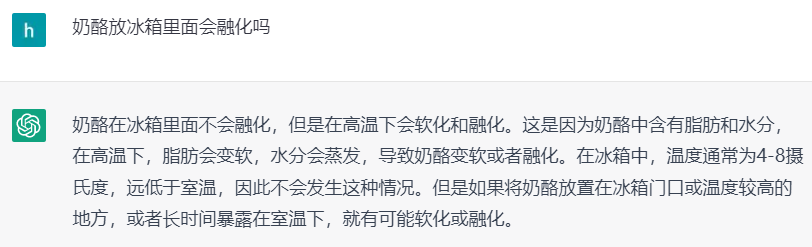
图4. ChatGPT回答常识类问题示例
>>>> 2.2 不足
ChatGPT已经具备很强的问答能力了,如果说存在一些不足的话,我们认为有四点:
① 有时存在事实性错误,无法判断它回答的对错,如下图5所示;
② 不能够像Google搜索那样查询新的信息,无法获知最新的知识;
③ 有时结果并不稳定,换个问法后ChatGPT回答可能会变化,如下图6所示;
④ 缺乏可解释性,这也是现阶段模型的通用问题。
当然,我们认为以上问题,与ChatGPT目前能够带来的变革相比,显得微不足道。
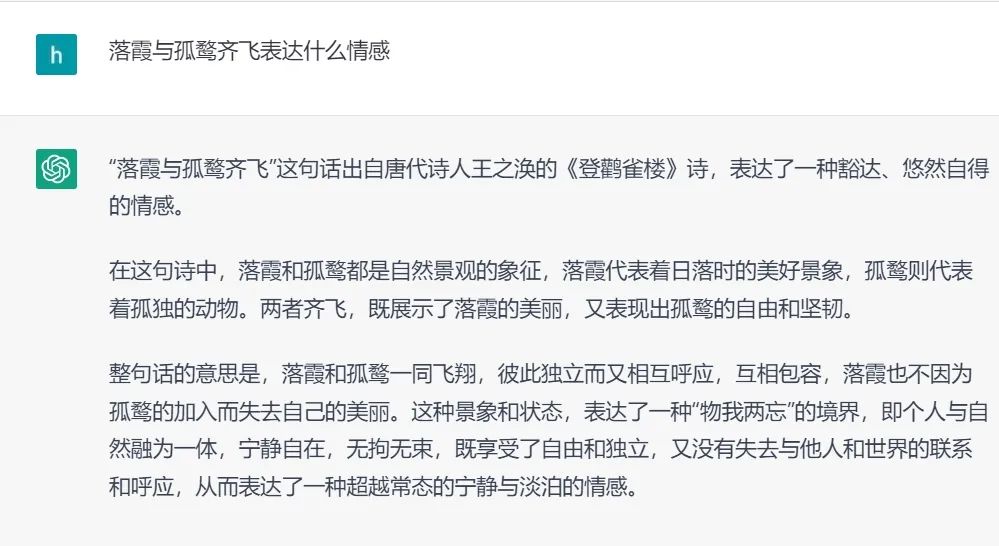
图5. ChatGPT的回答存在事实性错误


图6. 回答不稳定示例
>>>> 2.3 应用
我们可以设想如何在小爱的开放域问答场景中应用ChatGPT以及相关技术。就目前来说,直接采纳ChatGPT会有两个问题:其一,有时它会产生事实性的错误且人们无法进行区分;其二,计算资源消耗大,成本高。
基于以上特点,我们认为对于高频且常规类的问答,仍旧需要传统的技术来提供稳定且可靠的服务,但是ChatGPT提供的开放域问答能力,可以被用来处理长尾且低频的问答。合理的产品形态设计再结合搜索引擎等提供的答案,可以给用户带来更好的产品体验。
除了直接在线使用外,ChatGPT还可以作为问答中的一个离线的工具。以数据构建为例,列举两方面的例子,来简单说明一下:
● 补充槽位抽取的训练数据;
● 补充长尾的问答对数据。
① 槽位抽取的训练数据补充
ChatGPT本身具备有很强的In-Context Learning能力,只需要提供一个槽位提取的例子,它能够模仿着从用户的提问中自动地抽取槽位,如下图7所示。如此,可以将无标记的文本送到ChatGPT中来自动化的抽取槽位信息,经过人工审核后,作为训练数据来使用。

图7. 槽位抽取的例子
② 问答对数据补充
多数时候,问答对数据的收集需要花费产品、运营、标注同学大量的人力。有了ChatGPT,在准备好问题后可以直接用它来生成答案。ChatGPT的回复可能存在事实性错误,在正式使用前还需要进行人工的审核,但这种方式会比直接收集数据便利不少。
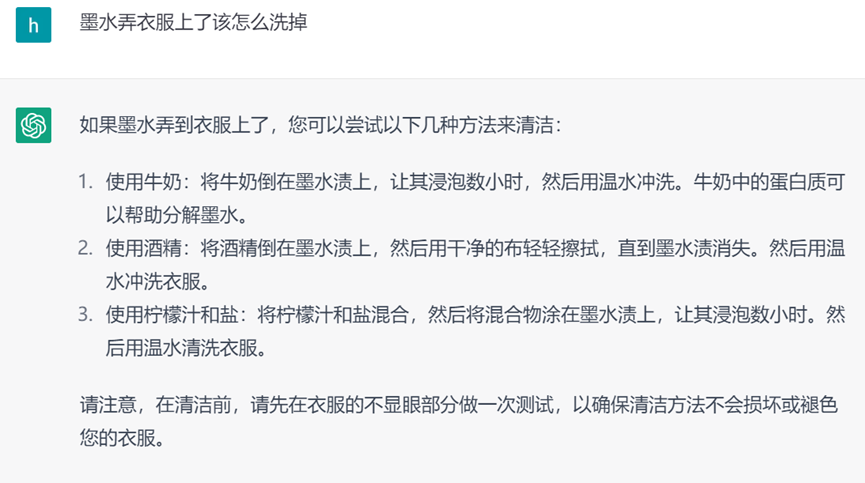
图8. ChatGPT关于生活常识的回答,可以用来补充数据
三、结论和展望
ChatGPT具备了很强的开放域问答能力,于问答技术而言是当之无愧的跨时代的成果,前景无可限量,未来可期。尽管我们提到了它的一些缺点,比如事实性错误问题、不能获取新的知识等,但在当前全球的ChatGPT热潮下,这些问题都是可以避免或有解决的可能性。
拿事实性错误问题来说,就目前阶段而言,看似是大型语言模型无法完全和彻底解决的问题。但如果在给出结果的同时,给出一些材料作为参考或者依据,那么人们就可以自己判断结果的真伪了。据我们所知,给语言模型的生成结果加上参考材料是有相关的研究工作的。关于检索新的信息,其实DeepMind的Sparrow已经在做了,我们有理由期待未来的模型是具备相关能力的。那样的话,不仅可以解决回复的答案带有参考和依据的问题,还可以尝试回答时间上比较新的问题。另外,关于模型的资源消耗大,能不能小型化的问题,在ChatGPT引发全球关注后,相信会有相关研究跟进的。我们乐观地期待,未来ChatGPT一定能够更好地应用到开放域问答中。
不过,尽管ChatGPT前景无限,但并不会全面地替代现有的问答技术。ChatGPT在通用领域的问答能力确实很强,但在需要极其丰厚的领域知识的垂直领域,ChatGPT还不一定合适。
下图9所示是ChatGPT在中文字词相关问题上的回复,涉及拼音相关的知识,尽管好像有一些道理,但结果是错误的。这些细致领域,需要专门的数据建设,但为了回答一个细分领域,对ChatGPT进行重新训练是不太可能的。所以传统的问答方式未来在客服、电商、医疗等专业问答领域还是有一定的优势的。在未来的问答形式中,传统问答可以和ChatGPT共存,优势互补。就像当前BERT并没有在所有的任务中都取代传统的机器学习方法一样。
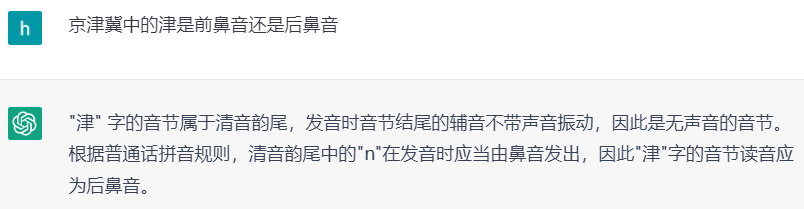 图9. ChatGPT在中文字词问题上出现事实性错误
图9. ChatGPT在中文字词问题上出现事实性错误
参考文献
[1] Improving Language Understanding by Generative Pre-Training
[2] Language Models are Unsupervised Multitask Learners
[3] Language Models are Few-Shot Learners
[4] Finetuned Language Models Are Zero-Shot Learners
[5] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
[6] Large language models are zero-shot reasoners
[7] Training language models to follow instructions with human feedback
[8] Evaluating Large Language Models Trained on Code
[9] Emergent Abilities of Large Language Models
[10] Improving alignment of dialogue agents via targeted human judgements
你还有哪些希望了解的技术?欢迎在评论区留言,我们将继续邀请工程师就大家关心的话题进行分享。更多硬核知识,请持续关注小米Tech Talk!

