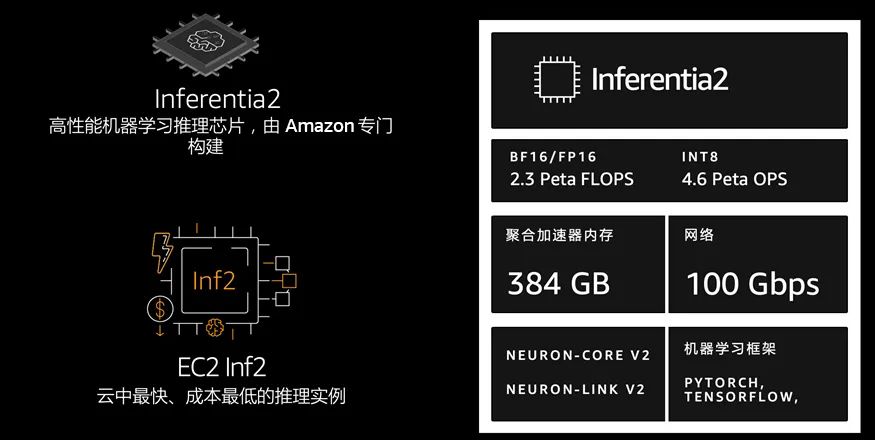
在 re:Invent 2019上,亚马逊云科技发布了 Inferentia 芯片和 Inf1 实例。Inferentia 是一种高性能机器学习推理芯片,由亚马逊云科技定制设计,其目的是提供具有成本效益的大规模低延迟预测。时隔四年,2023年4月亚马逊云科技发布了 Inferentia2 芯片和 Inf2 实例,旨在为大型模型推理提供技术保障。
Inf2 实例提供高达 2.3 petaflops 的 DL 性能和高达 384 GB 的总加速器内存以及 9.8 TB/s 的带宽。Amazon Neuron SDK 与 PyTorch 和 TensorFlow 等流行的机器学习框架原生集成。因此,用户可以继续使用现有框架和应用程序代码在 Inf2 上进行部署。开发人员可以在 Amazon Deep Learning AMI、Amazon Deep Learning 容器或 Amazon Elastic Container Service (Amazon ECS)、Amazon Elastic Kubernetes Service (Amazon EKS) 和 Amazon SageMaker 等托管服务中使用 Inf2 实例。
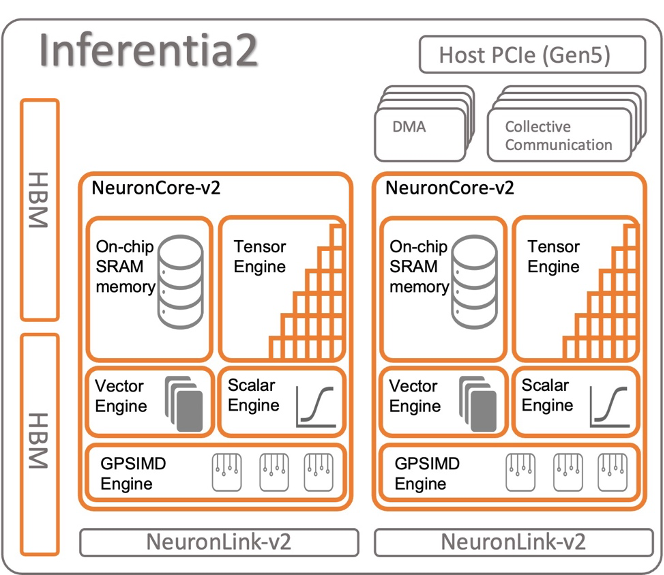
Amazon EC2 Inf2 实例的核心是 Amazon Inferentia2 设备,每个设备包含两个 NeuronCores-v2。每个 NeuronCore-v2 都是一个独立的异构计算单元,具有四个主要引擎:张量(Tensor)、向量(Vector)、标量(Scalar) 和 GPSIMD 引擎。张量引擎针对矩阵运算进行了优化。标量引擎针对 ReLU(整流线性单元)函数等元素运算进行了优化。向量引擎针对非元素向量操作进行了优化,包括批量归一化或池化。下图显示了 Amazon Inferentia2 设备架构的内部工作原理。
Amazon Inferentia2 支持多种数据类型,包括 FP32、TF32、BF16、FP16 和 UINT8,因此用户可以根据工作负载选择最合适的数据类型。它还支持新的可配置 FP8 (cFP8) 数据类型,这与大型模型特别相关,因为它减少了模型的内存占用和 I/O 要求。
Amazon Inferentia2 嵌入了支持动态执行的通用数字信号处理器(DSP),因此无需在主机上展开或执行控制流运算符。Amazon Inferentia2 还支持动态输入形状,这对于输入张量大小未知的模型(例如处理文本的模型)来说非常关键。
Amazon Inferentia2 支持用 C++ 编写的自定义运算符。Neuron Custom C++ Operators 使用户能够编写在 NeuronCores 上本机运行的 C++ 自定义运算符。使用标准 PyTorch 自定义运算符编程接口将 CPU 自定义运算符迁移到 Neuron 并实现新的实验运算符,所有这些都不需要对 NeuronCore 硬件有深入了解。
Inf2 实例是 Amazon EC2 上的第一个推理优化实例,可通过芯片之间的直接超高速连接(NeuronLink v2)支持分布式推理。NeuronLink v2 使用集体通信 (Collective Communications)运算符(例如 all-reduce)在所有芯片上运行高性能推理管道。
Neuron SDK

Amazon Neuron 是一种 SDK,可优化在 Amazon Inferentia 和 Trainium 上执行的复杂神经网络模型的性能。Amazon Neuron 包括深度学习编译器、运行时和工具,这些工具与 TensorFlow 和 PyTorch 等流行框架原生集成,它预装在 Amazon Deep Learning AMI 和 Deep Learning Containers 中,供客户快速开始运行高性能且经济高效的推理。
Neuron 编译器接受多种格式(TensorFlow、PyTorch、XLA HLO)的机器学习模型,并优化它们以在 Neuron 设备上的运行。Neuron 编译器在机器学习框架内调用,其中模型由 Neuron Framework 插件发送到编译器。生成的编译器工件称为 NEFF 文件(Neuron 可执行文件格式),该文件又由 Neuron 运行时加载到 Neuron 设备。
Neuron 运行时由内核驱动程序和 C/C++ 库组成,后者提供 API 来访问 Inferentia 和 Trainium Neuron 设备。TensorFlow 和 PyTorch 的 Neuron ML 框架插件使用 Neuron 运行时在 NeuronCores 上加载和运行模型。Neuron 运行时将编译的深度学习模型(也称为 Neuron 可执行文件格式(NEFF))加载到 Neuron 设备,并针对高吞吐量和低延迟进行了优化。
Inf2 实例的应用场景
使用 Inf2 实例运行流行的应用程序,例如文本摘要、代码生成、视频和图像生成、语音识别、个性化等。Inf2 实例是 Amazon EC2 中的第一个推理优化实例,引入了由 NeuronLink (一种高速、非阻塞互连) 支持的横向扩展分布式推理。用户现在可以在 Inf2 实例上跨多个加速器高效部署具有数千亿个参数的模型。Inf2 实例的吞吐量比其他类似的 Amazon EC2 实例高出三倍,延迟低八倍,性价比高出40%。为了实现可持续发展目标,与其他类似的 Amazon EC2 实例相比,Inf2 实例的每瓦性能提高了50%。
使用 Inf2 实例运行 GPT-J-6B 模型
GPT-J-6B 是由一组名为 EleutherAI 的研究人员创建的开源自回归语言模型。它是 OpenAI 的 GPT-3 最先进的替代方案之一,在聊天、摘要和问答等广泛的自然语言任务中表现良好。
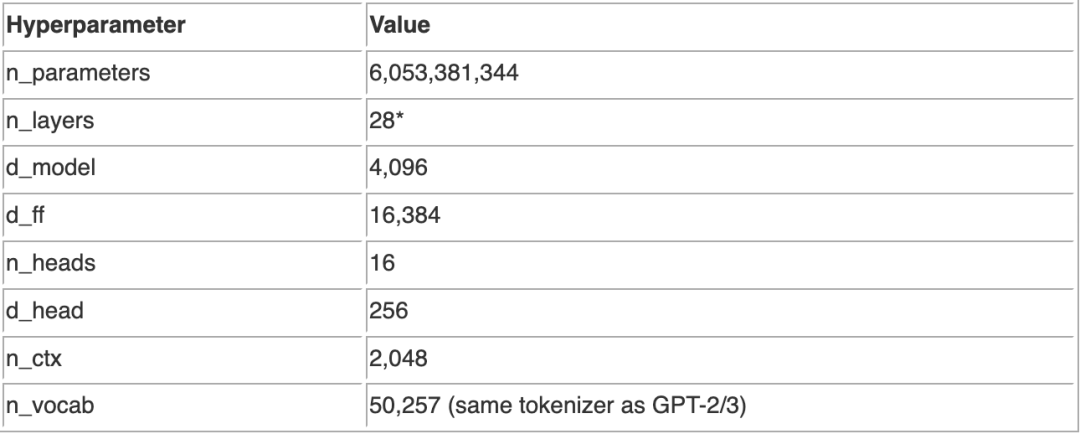
该模型由28层组成,模型维度为4096,前馈维度为16384。模型维度分为16个头,每个头的维度为256。旋转位置嵌入(RoPE)应用于每个头的64个维度。使用与 GPT-2/GPT-3 相同的一组 BPE,使用50257的标记化词汇训练模型。
GPT-J-6B 有60亿个参数,非常适合大语言模型(LLM)学习的入门版本,进行文本生成测试。下文我们就以 GPT-J-6B 为例在 Inf2 实例上进行部署。在部署过程中,我们用到了 Neuron SDK 和 transformers-neuronx。transformers-neuronx 是由 Amazon Neuron 团队构建的开源库,可帮助使用 Amazon Neuron SDK 运行转换器解码器推理工作流程。目前,它提供了 GPT2、GPT-J 和 OPT 模型类型的演示脚本,它们的前向函数在编译过程中重新实现,以进行代码分析和优化。客户可以基于同一个库实现其他模型架构。Amazon Neuron 优化的转换器解码器类已使用称为 PyHLO 的语法在 XLA HLO (高级操作) 中重新实现。该库还实现了张量并行(Tensor Parallelism),以跨多个 NeuronCore 对模型权重进行分片。
部署流程如下:
▌1. 准备创建 Inf2 实例
进入到 Amazon 控制台,区域选择 us-east-1 或者 us-west-2,实例类型建议选择 8xlarge,配置为 CPU:32 核、内存:128G、GPU:32G、存储:500G,操作系统选择 Amazon Linux 2(作者使用的是 us-east-1 的 AMI:ami-0aa7d40eeae50c9a9)。Inf2 实例也可以使用 Amazon Deep Learning AMI 进行部署,好处是开箱即用,AMI 中内置了 Inferentia 的驱动程序和 Neuron SDK。为了让读者更加深入的了解 Inf2 的工作原理,我们并没有采用 Amazon Deep Learning AMI 。当 Inf2 实例创建完成后,通过 SSH 客户端登陆到 Inf2 实例。
▌2. 安装驱动和 Neuron 工具
# Configure Linux for Neuron repository updates
sudo tee /etc/yum.repos.d/neuron.repo > /dev/null <<EOF
[neuron]
name=Neuron YUM Repository
baseurl=https://yum.repos.neuron.amazonaws.com
enabled=1
metadata_expire=0
EOF
sudo rpm --import https://yum.repos.neuron.amazonaws.com/GPG-PUB-KEY-AMAZON-AWS-NEURON.PUB
# Install OS headers
sudo yum install kernel-devel-$(uname -r) kernel-headers-$(uname -r) -y
# Update OS packages
sudo yum update -y
# Install Neuron Driver and tools
sudo yum install aws-neuronx-dkms
sudo yum install aws-neuronx-tools
# Add PATH
export PATH=/opt/aws/neuron/bin:$PATH左滑查看更多
▌3. 安装 PyTorch Neuron (torch-neuronx)
# Install Neuron Runtime
sudo yum install aws-neuronx-collectives-2.* -y
sudo yum install aws-neuronx-runtime-lib-2.* -y
# Install Python venv
sudo yum install -y python3.7-venv gcc-c++
# Create Python venv
python3.7 -m venv aws_neuron_venv_pytorch
# Activate Python venv
source aws_neuron_venv_pytorch/bin/activate
python -m pip install -U pip
# Install Jupyter notebook kernel
pip install ipykernel
python3.7 -m ipykernel install --user --name aws_neuron_venv_pytorch --display-name "Python (torch-neuronx)"
pip install jupyter notebook
pip install environment_kernels
# Set pip repository pointing to the Neuron repository
python -m pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com
# Install wget, awscli
python -m pip install wget
python -m pip install awscli
# Install Neuron Compiler and Framework
python -m pip install neuronx-cc==2.* torch-neuronx torchvision左滑查看更多
您也可以参考文档:
https://awsdocs-neuron.readthedocs-hosted.com/en/latest/frameworks/torch/torch-neuronx/setup/pytorch-install.html#pytorch-neuronx-install
进行安装
▌4. 更新 transformers 并安装 transformers-neuronx
pip install --upgrade pip transformers
pip install "git+https://github.com/aws-neuron/transformers-neuronx.git"左滑查看更多
▌5. 下载 GPT-J-6B 模型
gptj_demo --model_name="EleutherAI/gpt-j-6B" save gpt-j-6B-split左滑查看更多
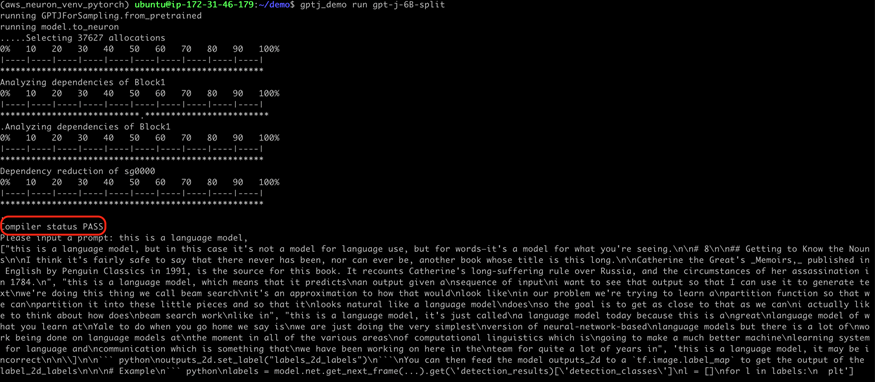
▌6. 编译并运行 GPT-J-6B 演示程序
gptj_demo run gpt-j-6B-split▌7. 观察输出和运行结果
▌8. gptj_demo 接受如下参数,读者可以根据需要自行调整

例如运行下列命令就是,序列长度为100,并设置输入批量大小为1。
gptj_demo run gpt-j-6B-split --n_positions 100 --batch_size 1左滑查看更多
▌9. 修改模型运行代码,使用循环接受连续输入
cd /home/ubuntu/aws_neuron_venv_pytorch/lib/python3.8/site-packages/transformers_neuronx
vi gpt_demo.py左滑查看更多
注释到99-108行
'''
with torch.inference_mode():
encoded_text = tokenizer.encode(prompt_text)
input_ids = torch.as_tensor([encoded_text])
input_ids = torch.cat([input_ids for _ in range(args.batch_size)], dim=0)
print('running model.sample')
generated_sequence = model.sample(input_ids, sequence_length=args.n_positions)
print('generated_sequence=', generated_sequence)
outputs = [tokenizer.decode(gen_seq) for gen_seq in generated_sequence]
print(outputs)
'''左滑查看更多
在后面加入
prompt_text = input('Please input a prompt: ')
while prompt_text!='exit':
#print(prompt_text)
with torch.inference_mode():
encoded_text = tokenizer.encode(prompt_text)
input_ids = torch.as_tensor([encoded_text])
input_ids = torch.cat([input_ids for _ in range(args.batch_size)], dim=0)
#print('running model.sample')
generated_sequence = model.sample(input_ids, sequence_length=args.n_positions)
#print('generated_sequence=', generated_sequence)
outputs = [tokenizer.decode(gen_seq) for gen_seq in generated_sequence]
print(outputs)
prompt_text = input('\nPlease input a prompt: ')左滑查看更多
再次运行以下命令
gptj_demo run gpt-j-6B-split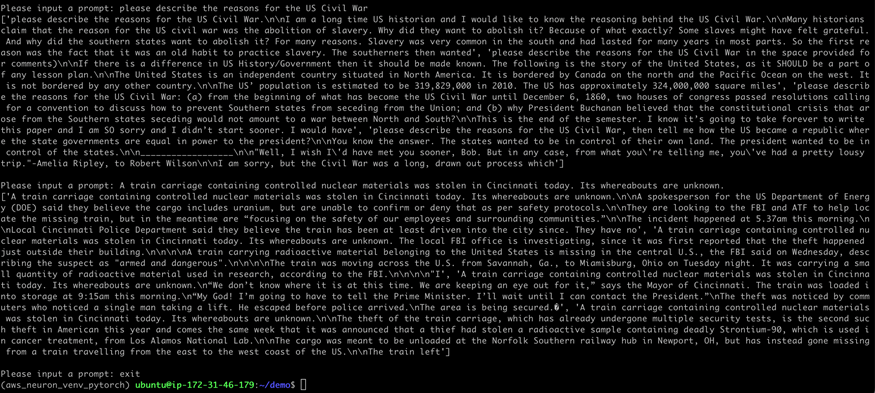
▌10. 至此,我们看到 GPT-J-6B 模型成功在 Inferentia2 芯片上完成了文本生成任务。运行完成后,用户不要忘记删除 EC2 Inf2 实例以节约成本。
总结
本文介绍了亚马逊云科技的最新发布推理实例 Inf2,并演示了如何编译运行大语言模型 GPT-J-6B,为正在调研 Inf2 实例的用户提供参考。
由于 Inferentia2 芯片使用了与 Inferentia1 完全不同的架构设计,Neuron SDK 会同时包含对 Inferentia1 和Inferentia2 的支持,Inferentia1 对应的 SDK 名称为 neuron,Inferentia2 对应的 SDK 名称为 neuronx。Inf2 不会取代 Inf1。亚马逊云科技将继续向客户推荐 Inf1 和 Inf2 推理工作负载。一般来说,对于模型参数量较小的CV、NLP 模型,Inf1 更适合;而 Inf2 为较大的 ML 模型提供更好的性能和性价比。对 Inf2 的 Neuron SDK 模型支持在整个2023年的功能路线图中不断迭代,详细路线图可以参阅参考资料。
参考资料
● https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html
● https://aws.amazon.com/blogs/aws/amazon-ec2-inf2-instances-for-low-cost-high-performance-generative-ai-inference-are-now-generally-available/
● https://github.com/orgs/aws-neuron/projects/1/views/1
● https://aws.amazon.com/blogs/machine-learning/deploy-large-language-models-on-aws-inferentia2-using-large-model-inference-containers/
本篇作者

张铮
亚马逊云科技机器学习产品技术专家,负责基于亚马逊云科技加速计算和 GPU 实例的咨询和设计工作。专注于机器学习大规模模型训练和推理加速等领域,参与实施了国内多个机器学习项目的咨询与设计工作。

郎建英
亚马逊云科技资深解决方案架构师,专注于机器学习和高性能计算在加速计器上面的应用,致力于云原生应用推广、落地。具有15年以上的 AIML/HPC 行业专业经验,在加入亚马逊云科技之前曾就职于 Intel 公司。

听说,点完下面4个按钮
就不会碰到bug了!