随着系统数据的增多,一些查询逐渐变慢,这时候我们可以根据sqlserver的执行计划,查看sql的开销,然后根据开销创建索引。
索引有聚集索引与非聚集索引。
聚集索引:聚集索引在存储上是按照顺序存储的,就像字典里的汉字。
非聚集索引:物理存储不连续,但逻辑上是连续的,因为单独维护着数据的存储位置与数据的关系。
非聚集索引的创建:
create NONCLUSTERED INDEX index1 ON meter_manage(meter_no)
效果:
select * from meter_manage where meter_no='asdasd2'
创建非聚集索引之前,耗时23毫秒左右

创建非聚集索引之后,瞬间完成

经常使用多条件语句查询时,我们可创建复合索引。

select * from meter_manage where meter_no='asdasd2' and meter_name='asdsf2'
未创建非聚集索引,耗时30毫秒:

在meter_no字段创建单索引,耗时3毫秒:
create NONCLUSTERED INDEX index1 ON meter_manage(meter_no)

条件查询位置更换:
select * from meter_manage where meter_name='asdsf2' and meter_no='asdasd2'

查询速度没变,同样3毫秒。
我们同时在另一个字段meter_name上也建立一个非聚集索引:
create NONCLUSTERED INDEX index2 ON meter_manage(meter_name)

发现两个非聚集索引的时间与一个聚集索引的时间没有太大变化,查看执行计划,只命中了index1索引:
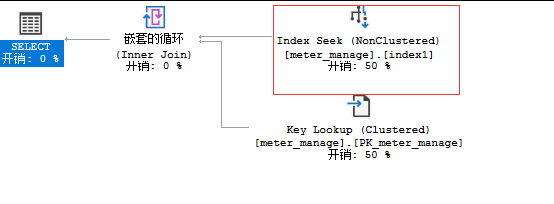
分析:
我们来想象一下当数据库有N个索引并且查询中分别都要用上他们的情况:
查询优化器(用大白话说就是生成执行计划的那个东西)需要进行N次主二叉树查找[这里主二叉树的意思是最外层的索引节点],此处的查找流程大概如下:
查出第一条column1主二叉树等于1的值,然后去第二条column2主二叉树查出foo的值并且当前行的coumn1必须等于1,最后去column主二叉树查找bar的值并且column1必须等于1和column2必须等于foo。
如果这样的流程被查询优化器执行一遍,就算不死也半条命了,查询优化器可等不及把以上计划都执行一遍,贪婪算法(最近邻居算法)可不允许这种情况的发生,所以当遇到以下语句的时候,数据库只要用到第一个筛选列的索引(column1),就会直接去进行表扫描了。
select count(1) from table1 where column1 = 1 and column2 = 'foo' and column3 = 'bar'
所以与其说是数据库只支持一条查询语句只使用一个索引,倒不如说N条独立索引同时在一条语句使用的消耗比只使用一个索引还要慢。
所以如上条的情况,最佳推荐是使用index(column1,column2,column3) 这种联合索引,此联合索引可以把b+tree结构的优势发挥得淋漓尽致:
一条主二叉树(column=1),查询到column=1节点后基于当前节点进行二级二叉树column2=foo的查询,在二级二叉树查询到column2=foo后,去三级二叉树column3=bar查找。
结论:两个单独索引通常数据库只能使用其中一个
创建复合索引:
create index idx1 on meter_manage(meter_no,meter_name)

瞬间完成,发现多条件下适合创建复合索引。
条件位置改变一下
select * from meter_manage where meter_name='asdsf2' and meter_no='asdasd2'

同样瞬间完成。查看执行计划命中了idx1
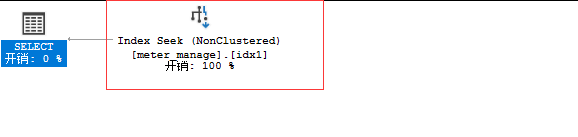
我们去掉二个条件:
select * from meter_manage where meter_no='asdasd2'

同样瞬间完成,也命中了索引 idx1

我们去掉第一个条件:
select * from meter_manage where meter_name='asdsf2'

耗时27毫秒,与不加索引没什么区别,查看执行计划,发现虽然命中了idx1
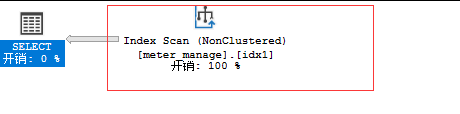
但是类型却是Index Scan,与之前的Index Seek不同
区别:
[Table Scan] 表扫描(最慢),对表记录逐行进行检查
[Clustered Index Scan] 聚集索引扫描(较慢),按聚集索引对记录逐行进行检查
[Index Scan] 索引扫描(普通),根据索引滤出部分数据在进行逐行检查
[Index Seek] 索引查找(较快),根据索引定位记录所在位置再取出记录
[Clustered Index Seek] 聚集索引查找(最快),直接根据聚集索引获取记录
因此,字段上同时存在聚集索引与非聚集索引,这种情况下只会命中聚集索引,因为聚集索引最快,例如:主键上创建非聚集索引
create NONCLUSTERED INDEX index3 ON meter_manage(meter_id)

瞬间完成,执行计划:
