图像处理
寻找边界
Downsampling
使用图像数据集
使用神经网络识别图像是一个非常通用的任务,这章将探索Encog怎样使用图像,使用在前几章中同样的前馈神经网络,神经网络能够设计去识别某些图像,专用数据集简化了将图像数据输入神经网络的过程。
这章将介绍ImageMLDataSet.这个类能够接受加载图像列表以及加工成一种Encog友好的形式。ImageMLDataSet是基于BasicMLDataSet之上,BasicMLDataSet实际上只是输入和理想值的一个double值数组,ImageMLDataSet简单地添加一个特殊的功能来加载图像到一个double数组。
当加载图像数据到一个神经网络的时候有几个重要的问题要考虑,ImageMLDataSet有两个重要的方面要考虑,第一个方面是边界侦测识别,第二个是采样图像通常是在高分辨率下的采样格式,采样格式必须统一转为低分辨率在送入神经网络,
9.1寻找边界
一个图像是一个矩形区域,指定其数据对神经网络来说很重要,对于图像来说仅仅只有一部分也许有用,理想情况下,神经网络识别的实际图像等于整个物理图像,而不仅仅是原始图像的一部分。例如图9.1的例子。

正如你所见在上面的图中,字符”X”几乎是在整个物理图像绘制的,这个图像将要求最小化,如果有,则边界检测。
图像不总是完美的创建,考虑图9.2指定的图片。
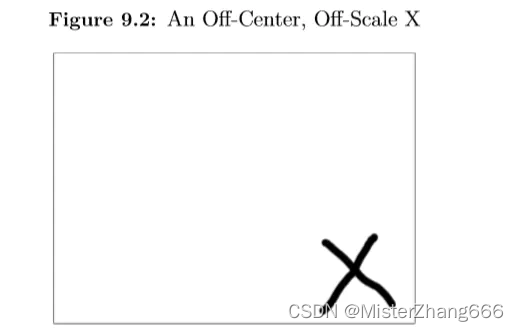
这里的字母”X”比之前的图像不同缩放,要正确地识别它,我们必须查找边界,图9.3在字母X周围显示了一个边界框,只有包围盒子内部的数据才能用来识别图像。

正如你所见,字母X边界已被检测,边界框表示的内部数据将要被识别,现在X的方向与图9.1大致相同。
9.2图像的下采样
即使使用边界框,图像大小也不一定一致。图9.3字母X大大的小于图9.1.当图像识别的时候,我们将在图像上画一个网格,每个网格依次对应于一个输入神经元,要这样做,这个图像就必须统一大小,进一步,大多数图像都过高分辨率地使用神经网络。
Downsampling解决这两个问题,通过减少图像分辨率和缩放所有图像使其大小一致。看这个动作,考虑图9.4,这幅图显示了Encog Logo的高分辨率。

图9.5显示了downsampled后的图像。

你注意到网格图案了吗?它已经减少为32*32像素,这个像素将要输入到神经网络,神经网络将要求有1024个输入神经元,如果网络值看每平方的亮度,看着亮度极限让神经网络只能看见“黑与白”。
如果你想要神经网络能看到颜色,那就有必要为每一个像素提供红绿蓝(RGB)值,这将意味着每一个像素有三个输入神经元,输入神经元数量将有3072个。
Encog图像数据集提供边界检测,以及RGB和Downsamling, 在下一节,将介绍Encog图像数据集。
9.2.1如何处理输出神经元
输出神经元应该代表这些图像将要落入的组,例如,如果写一个OCR应用程序,为每一个识别字符使用一个输出神经元,等边编码在这里也很有用,它已在第二章“为Encog获取数据”中讨论。
监督训练也要求为每个图像提供理想的输出数据,例如一个简单的OCR,这里可能有26个输出神经元,每个字母一个神经元,这些理想输出训练神经网络的图像实际上是什么。无论训练是监督或者无监督训练,输出神经元都会传递神经网络如何解释每个图像。
9.3使用Encog图像数据集
在ImageMLDataSet对象实例化之前,必须创建一个Downsampled对象,该对象是Encog的一个工具,使用来执行downsample。所有Encog downsample对象必须实现Downsample接口,Encog目前支持两个downsample类,如下:
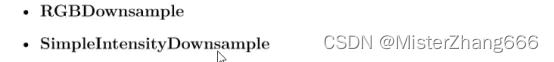
SimpleIntensityDownsample不考虑颜色,它简单计算亮度或者暗度像素,输入神经元数量为高度乘以宽度值,因为这里仅仅需要为每一个像素对应一个输入神经元。
RGBDownsample比SimpleIntensityDownsample更先进,该Downsample对象包含了你指定的分辨率和每一个像素的三原色(RGB)输入,该对象生成的输入神经元总数将是高度乘以宽度乘以三。以下代码实例化一个SimpleIntensityDownsampe对象,该对象将使用于创建训练集。

现在创建了一个downsample对象,是时候使用ImageMLDataSet类创建数据集了,它必须指定几个参数,代码如下:

参数1和-1指定颜色规范化的范围,亮度颜色或者三原色RGB之一,false值代表数据集不应该尝试检测边界,如果该值为true,Enog将尝试去检测边界。
目前的Encog边界检测不是很先进,它在图像的两侧寻找一个一直的颜色,并试图尽可能地删除该区域,更多先进的边界检测将有可能在未来的Encog版本,如果先进的边界检测是有必要的,最好是在送它们到ImageMLDataSet对象之前修建图像,
现在ImageMLDataSet对象已经创建,是时候添加一些图片了,添加图片到这个数据集,必须为每一个图片创建一个ImageMLData对象,以下的代码将从一个文件添加一个图像。

使用Java ImageIO类从一个文件加载图像,从文件读取图像,可以使用任何图像有效的java对象数据集。
当使用监督训练的时候应该指定理想输出,无监督训练,这个参数可以省略,一旦实例化ImageMLData对象,就将其添加到数据集,重复这些步骤为每个图像添加。
一旦所有图片加载完,它们准备downsampled, downsample图像调用的是downsample方法.

指定downsample的width和height,所有的图像将被downsample这个大小,调用downsample方法之后,训练数据将生成以及可以让一个神经网络进行训练。
9.4图像识别示例
现在,我们将看到如何用一个例子形象化所有Encog类。一个通用的图像识别程序将作为一个例子,它可以很容易地成为一个更复杂的图像识别程序的基础,这个例子从一个脚本文件驱动,清单9.1显示了这个脚本驱动文件

这个脚本文件使用了非常简单的语法,有一个命令,后面跟着一个冒号,之后跟着一个逗号分隔的参数列表。每个参数也是通过一个逗号分割的键值对,这里有五个控制命令:CreateTraining, Input, Network, Train和 WhatIs。
CreateTraining命令创建一个新的训练集,要做到这一点,需指定采样高度,宽度和类型(RGB或者亮度)。
Input命令为训练集输入新的图像,每个输入命令指定图像以及图像的身份,多个图像可以有同样的身份。
Network命令为训练和识别创建一个新的神经网络,有两个参数,指定了第一个和第二个隐藏层的大小,如果你不想要第二个隐藏层,则指定hidden2参数为0。
Train命令训练该神经网络,model可以选择控制台或者GUI模式,minutes参数指定网络需要训练多少时间,这个参数仅仅使用在控制台模式下训练,对于GUI训练,该参数应该设为0,The strategy tellsthetrainingalgorithmhowmanycyclestowaittoresettheneuralnetwork if the error level has not dropped below the specified amount.
WhatIS命令接受一个图像和识别它,这个示例将打印它认为最相似的图像的身份。
我们现在来看一看这个图像识别例子,这个例子在如下位置。
在上面例子中涉及一些代码,脚本文件和参数。字符串解析不是本书真正的重点,我们将重点讨论每个命令是如何执行的,以及如何构造神经网络。下一节讨论这些命令的实现。
9.4.1创建训练集
CreateTraining命令通过processCreateTraining方法实现,该方法如下:
获取CreateTraining命令的三个参数,以下行读取这些参数:

Width和height是两个整型参数以及需要解析。
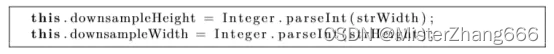
我们现在必须创建downsample对象,如果模式市RGB,那使用RGBDownsample,否则,使用SimpleIntensityDownsample.

现在可以创建ImageMLDDataSet.

目前该训练集已创建,我们可以输入图像,下一节将描述怎样这样做。
9.4.2图像输入
Input命令通过processInput实现。该方法如下显示:


获取Input命令的两个参数,以下行读取这些参数:

Identity是一个文本字符串,指定了图像是什么,我们跟踪唯一标识的数量,并为每个标识分配一个递增的数字。这些identities队列架构来自神经网络的输出层,每个identity队列将标记为一个输出神经元,当图像传递到神经网络之后,输出最高的输出神经元将代表网络中该图像的identity,assignIdentity方法是一个简单的方法,它标记增加的计数,以及identity字符串到神经元索引的映射。

创建一个文件对象持有这个图像,之后使用来读取这个图像,
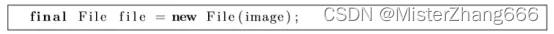
在这点上,我们不希望实际加载整个单个图像,我们将简单通过一个ImagePair对象保存图像。ImagePair对象为图像到输出神经元索引数字。ImagePair类不是Encog构建的,当然,它是本例用来使用构造一个图像map。
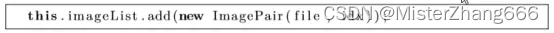
最后,我们显示一个消息告诉我们图像被添加了。

一旦所有图像添加完,输出神经元数量很明显了,以及可以创建实际神经网络了,创建神经网络在下一节介绍。
9.4.3创建神经网络
Network命令通过processInput方法实现,方法如下显示:

开始采样图像,循环之前创建的每一个ImagePair.

创建一个BasicMLData为每一个输出神经元持有理想的输出。
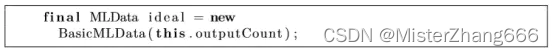
与当前正在训练的图像的标识相对应的输出神经元将被设置为1,另外的输出神经元将被设置为-1.

训练集中的输入数据设置为下采样率的图像。首先,加载图像到一个java Image对象。
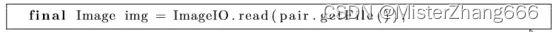
创建一个ImageMLData对象持有该图像以及将它添加到训练集。

这儿Network命令提供了有两个参数,用来指定两个隐藏层的神经元数量,第二个隐藏层没有神经元,这儿是一个单一的隐藏层。

我们现在为所有图像准备downsample。

最后,按照指定的参数创建一个新的神经网络,最后的true参数指定我们将要使用双曲正切激活函数。

一旦神经网络创建完成,通过打印消息报告完成。

现在神经网络已创建,它能够训练,训练在下一节介绍。
9.4.4训练神经网络
Train命令通过processTrain方法实现,该方法如下显示。

Train命令有四个参数,以下行读取这些参数。

一旦参数被阅读,显示一条消息表示训练开始。

解析两个strategy参数。

神经网络初始化为随机权重和阈值,有时候,权重和阀值的随机性设定会导致神经网络训练停滞,这种情况下,重新设置一个新的随机值在训练一次。
训练初始化通过创建一个新的ResilientPropagation训练器,RPROP训练在第五章“传播训练”中已经包括了。

Encog允许添加策略来处理这种情况,一个特别有用的训练策略是ResetStrategy,它有两个参数,
9.4.5图像识别
WhatIs命令通过processWhatIs方法实现,该方法显示如下:

WhatIs命令获取一个参数,以下这行读取这个参数。

加载图像到ImageMLData对象:

图像下采样率到合适的标准:

下采样后的图像呈现给神经网络,选择“胜利者”神经元。获胜的神经元是所呈现模式输出最大的神经元。这是简单的“第2章中讨论的标准化”之一。第2章也引入了等边正规化,也可以使用。

最后,我们展示了神经网络识别的模式。
这个例子演示了一个简单的基于脚本的图像识别程序。此应用程序可以很容易地用作其他更高级的图像识别应用程序的起点。此应用程序的一个非常有用的扩展可能是加载和保存受过训练的神经网络的能力。
9.5总结
这章证明了怎样使用图像数据作为Encog的输入,在本书中讨论的任何神经网络类型都能够使用来识别图像,Encog主要处理图像数据所提供的一种用于神经网络类,而不是定义实际的神经网络结构。
Encog图像处理类提供了一些非常重要的功能包括边界检测和下采样率。
边界检测是处理修剪图像中不重要的部分,Encog支持简单的边界检查,它简单地删除背景一致的颜色,这样可以防止输入图像中的对象削弱神经网络对图像的处理能力。如果边界检测时,如果要识别的图像在左上方或者是右下角,则无需考虑。
下采样率是处理降低图像的分辨率,图像有着很高的分辨率和经常包含了大量的颜色,Encog提供了下采样率处理这两种情况,图像能够被降低到一个很低的分辨率送到输入神经元上,下采样率也可以丢弃颜色信息仅仅处理强度。
在这本书中,我们看了大量不同的神经网络类型,这章展示了前馈神经网络怎样运用在图像上,自组织映射(SOM)是另外一种使用在图像的神经网络类型,下一章将看看SOM。