大家好,我是易安!
我们知道,在并发程序中,并不是启动更多的线程就能让程序最大限度地并发执行。线程数量设置太小,会导致程序不能充分地利用系统资源;线程数量设置太大,又可能带来资源的过度竞争,导致上下文切换带来额外的系统开销,今天我们就来谈下线程的上线文切换。
什么是上下文切换
在单个处理器的时期,操作系统就能处理多线程并发任务。处理器给每个线程分配 CPU 时间片(Time Slice),线程在分配获得的时间片内执行任务。
CPU 时间片是 CPU 分配给每个线程执行的时间段,一般为几十毫秒。在这么短的时间内线程互相切换,我们根本感觉不到,所以看上去就好像是同时进行的一样。
时间片决定了一个线程可以连续占用处理器运行的时长。当一个线程的时间片用完了,或者因自身原因被迫暂停运行了,这个时候,另外一个线程(可以是同一个线程或者其它进程的线程)就会被操作系统选中,来占用处理器。这种一个线程被暂停剥夺使用权,另外一个线程被选中开始或者继续运行的过程就叫做上下文切换(Context Switch)。
具体来说,一个线程被剥夺处理器的使用权而被暂停运行,就是“切出”;一个线程被选中占用处理器开始或者继续运行,就是“切入”。在这种切出切入的过程中,操作系统需要保存和恢复相应的进度信息,这个进度信息就是“上下文”了。
那上下文都包括哪些内容呢?具体来说,它包括了寄存器的存储内容以及程序计数器存储的指令内容。CPU 寄存器负责存储已经、正在和将要执行的任务,程序计数器负责存储CPU 正在执行的指令位置以及即将执行的下一条指令的位置。
在当前 CPU 数量远远不止一个的情况下,操作系统将 CPU 轮流分配给线程任务,此时的上下文切换就变得更加频繁了,并且存在跨 CPU 上下文切换,比起单核上下文切换,跨核切换更加昂贵。
上下文切换的诱因
在操作系统中,上下文切换的类型还可以分为进程间的上下文切换和线程间的上下文切换。而在多线程编程中,我们主要面对的就是线程间的上下文切换导致的性能问题,下面我们就重点看看究竟是什么原因导致了多线程的上下文切换。开始之前,先看下系统线程的生命周期状态。
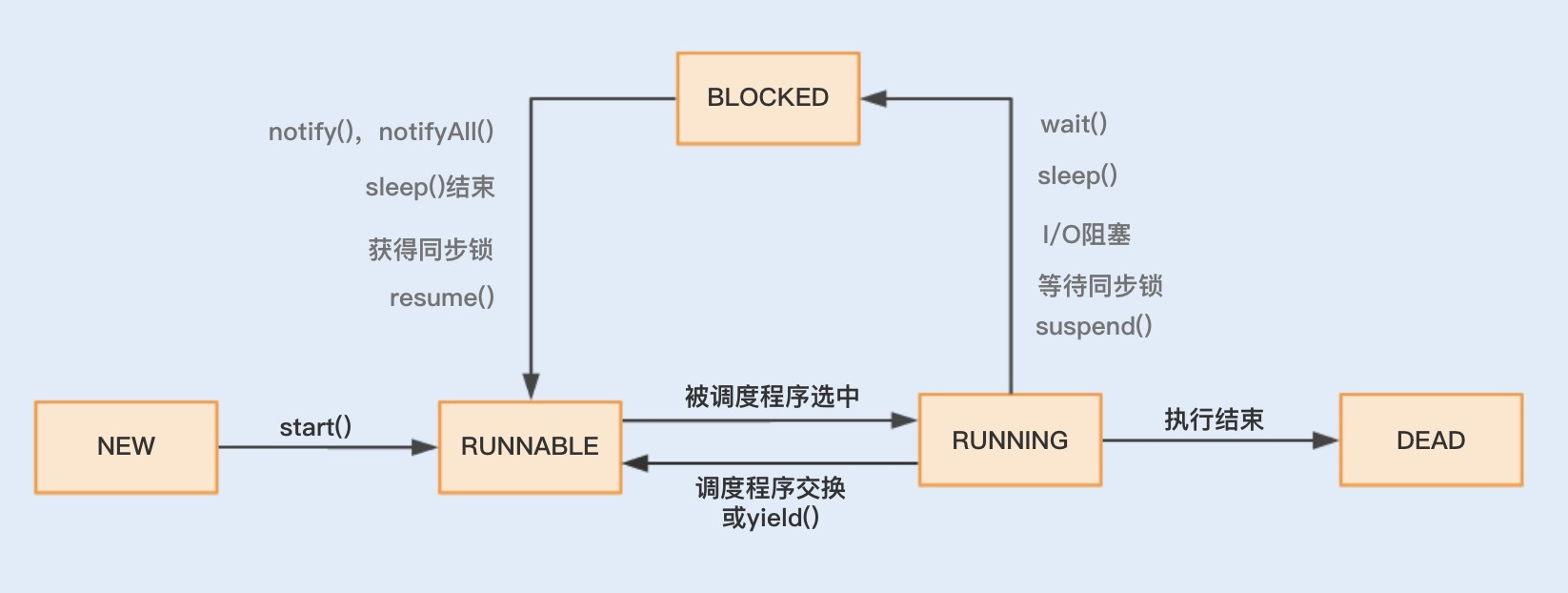
结合图示可知,线程主要有“新建”(NEW)、“就绪”(RUNNABLE)、“运行”(RUNNING)、“阻塞”(BLOCKED)、“死亡”(DEAD)五种状态。到了Java层面它们都被映射为了NEW、RUNABLE、BLOCKED、WAITING、TIMED_WAITING、TERMINADTED等6种状态。
在这个运行过程中,线程由RUNNABLE转为非RUNNABLE的过程就是线程上下文切换。
一个线程的状态由 RUNNING 转为 BLOCKED ,再由 BLOCKED 转为 RUNNABLE ,然后再被调度器选中执行,这就是一个上下文切换的过程。
当一个线程从 RUNNING 状态转为 BLOCKED 状态时,我们称为一个线程的暂停,线程暂停被切出之后,操作系统会保存相应的上下文,以便这个线程稍后再次进入 RUNNABLE 状态时能够在之前执行进度的基础上继续执行。
当一个线程从 BLOCKED 状态进入到 RUNNABLE 状态时,我们称为一个线程的唤醒,此时线程将获取上次保存的上下文继续完成执行。
通过线程的运行状态以及状态间的相互切换,我们可以了解到,多线程的上下文切换实际上就是由多线程两个运行状态的互相切换导致的。
那么在线程运行时,线程状态由 RUNNING 转为 BLOCKED 或者由 BLOCKED 转为 RUNNABLE,这又是什么诱发的呢?
我们可以分两种情况来分析,一种是程序本身触发的切换,这种我们称为自发性上下文切换,另一种是由系统或者虚拟机诱发的非自发性上下文切换。
自发性上下文切换指线程由 Java 程序调用导致切出,在多线程编程中,执行调用以下方法或关键字,常常就会引发自发性上下文切换。
-
sleep() -
wait() -
yield() -
join() -
park() -
synchronized -
lock
非自发性上下文切换指线程由于调度器的原因被迫切出。常见的有:线程被分配的时间片用完,虚拟机垃圾回收导致或者执行优先级的问题导致。
这里重点说下“虚拟机垃圾回收为什么会导致上下文切换”。在 Java 虚拟机中,对象的内存都是由虚拟机中的堆分配的,在程序运行过程中,新的对象将不断被创建,如果旧的对象使用后不进行回收,堆内存将很快被耗尽。Java 虚拟机提供了一种回收机制,对创建后不再使用的对象进行回收,从而保证堆内存的可持续性分配。而这种垃圾回收机制的使用有可能会导致 stop-the-world 事件的发生,这其实就是一种线程暂停行为。
发现上下文切换
我们总说上下文切换会带来系统开销,那它带来的性能问题是不是真有这么糟糕呢?我们又该怎么去监测到上下文切换?上下文切换到底开销在哪些环节?接下来我将给出一段代码,来对比串联执行和并发执行的速度,然后一一解答这些问题。
public class DemoApplication {
public static void main(String[] args) {
//运行多线程
MultiThreadTester test1 = new MultiThreadTester();
test1.Start();
//运行单线程
SerialTester test2 = new SerialTester();
test2.Start();
}
static class MultiThreadTester extends ThreadContextSwitchTester {
@Override
public void Start() {
long start = System.currentTimeMillis();
MyRunnable myRunnable1 = new MyRunnable();
Thread[] threads = new Thread[4];
//创建多个线程
for (int i = 0; i < 4; i++) {
threads[i] = new Thread(myRunnable1);
threads[i].start();
}
for (int i = 0; i < 4; i++) {
try {
//等待一起运行完
threads[i].join();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println("multi thread exce time: " + (end - start) + "s");
System.out.println("counter: " + counter);
}
// 创建一个实现Runnable的类
class MyRunnable implements Runnable {
public void run() {
while (counter < 100000000) {
synchronized (this) {
if(counter < 100000000) {
increaseCounter();
}
}
}
}
}
}
//创建一个单线程
static class SerialTester extends ThreadContextSwitchTester{
@Override
public void Start() {
long start = System.currentTimeMillis();
for (long i = 0; i < count; i++) {
increaseCounter();
}
long end = System.currentTimeMillis();
System.out.println("serial exec time: " + (end - start) + "s");
System.out.println("counter: " + counter);
}
}
//父类
static abstract class ThreadContextSwitchTester {
public static final int count = 100000000;
public volatile int counter = 0;
public int getCount() {
return this.counter;
}
public void increaseCounter() {
this.counter += 1;
}
public abstract void Start();
}
}
执行之后,看一下两者的时间测试结果:

通过数据对比我们可以看到: 串联的执行速度比并发的执行速度要快。这就是因为线程的上下文切换导致了额外的开销,使用 Synchronized 锁关键字,导致了资源竞争,从而引起了上下文切换,但即使不使用 Synchronized 锁关键字,并发的执行速度也无法超越串联的执行速度,这是因为多线程同样存在着上下文切换。Redis、NodeJS的设计就很好地体现了单线程串行的优势。
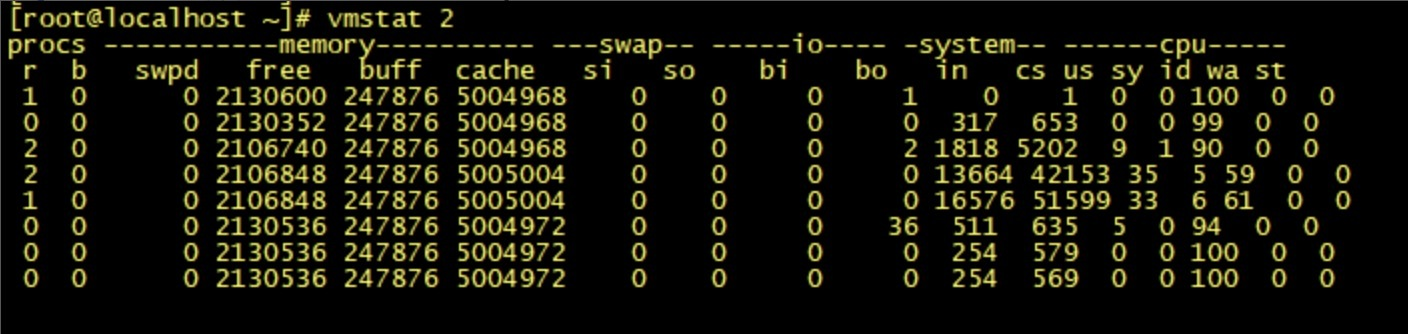
在 Linux 系统下,可以使用 Linux 内核提供的 vmstat 命令,来监视 Java 程序运行过程中系统的上下文切换频率,cs如下图所示:
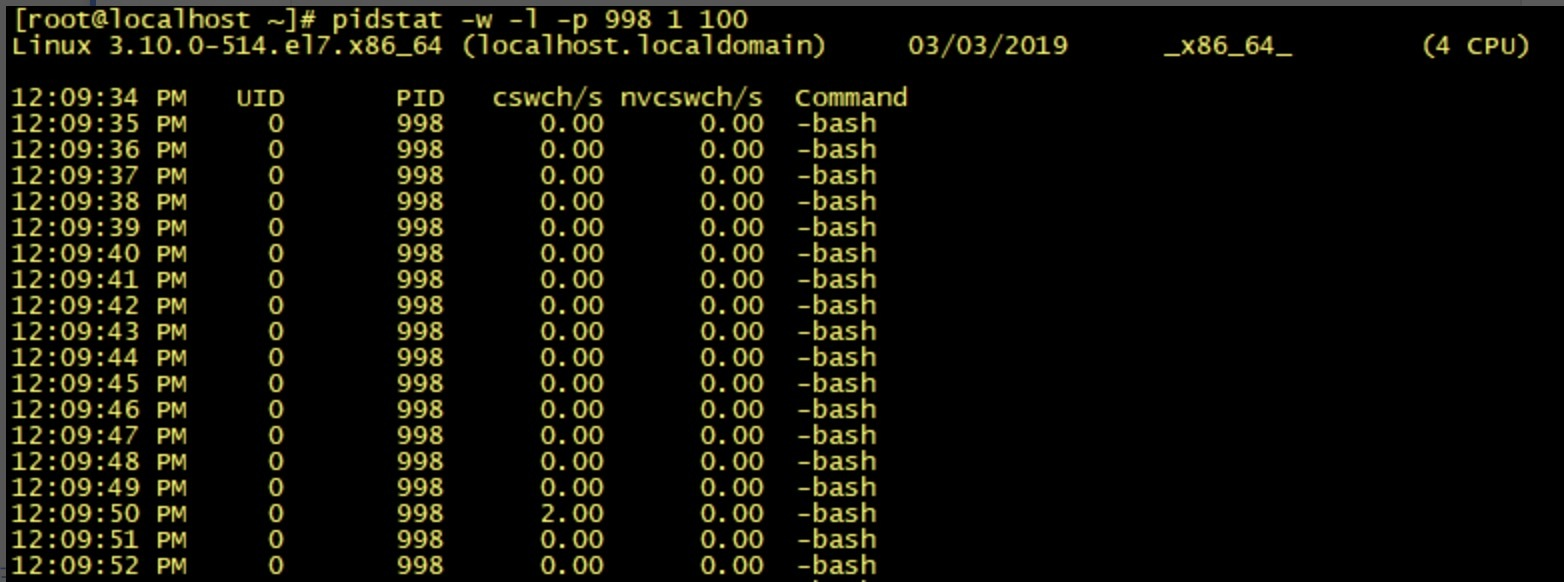
如果是监视某个应用的上下文切换,就可以使用 pidstat命令监控指定进程的 Context Switch 上下文切换。
由于 Windows 没有像 vmstat 这样的工具,在 Windows 下,我们可以使用 Process Explorer,来查看程序执行时,线程间上下文切换的次数。
至于系统开销具体发生在切换过程中的哪些具体环节,总结如下:
-
操作系统保存和恢复上下文; -
调度器进行线程调度; -
处理器高速缓存重新加载; -
上下文切换也可能导致整个高速缓存区被冲刷,从而带来时间开销。
如果是单个线程,在 CPU 调用之后,那么它基本上是不会被调度出去的。如果可运行的线程数远大于 CPU 数量,那么操作系统最终会将某个正在运行的线程调度出来,从而使其它线程能够使用 CPU ,这就会导致上下文切换。
还有,在多线程中如果使用了竞争锁,当线程由于等待竞争锁而被阻塞时,JVM 通常会将这个线程挂起,并允许它被交换出去。如果频繁地发生阻塞,CPU 密集型的程序就会发生更多的上下文切换。
那么问题来了,我们知道在某些场景下使用多线程是非常必要的,但多线程编程给系统带来了上下文切换,从而增加的性能开销也是实打实存在的。那么我们该如何优化多线程上下文切换呢?
竞争锁优化
大多数人在多线程编程中碰到性能问题,第一反应多是想到了锁。
多线程对锁资源的竞争会引起上下文切换,还有锁竞争导致的线程阻塞越多,上下文切换就越频繁,系统的性能开销也就越大。由此可见,在多线程编程中,锁其实不是性能开销的根源,竞争锁才是。
下面我们谈一下锁优化的一些思路:
1.减少锁的持有时间
我们知道,锁的持有时间越长,就意味着有越多的线程在等待该竞争资源释放。如果是Synchronized同步锁资源,就不仅是带来线程间的上下文切换,还有可能会增加进程间的上下文切换。
可以将一些与锁无关的代码移出同步代码块,尤其是那些开销较大的操作以及可能被阻塞的操作。
-
优化前
public synchronized void mySyncMethod(){
businesscode1();
mutextMethod();
businesscode2();
}
-
优化后
public void mySyncMethod(){
businesscode1();
synchronized(this)
{
mutextMethod();
}
businesscode2();
}
2.降低锁的粒度
同步锁可以保证对象的原子性,我们可以考虑将锁粒度拆分得更小一些,以此避免所有线程对一个锁资源的竞争过于激烈。具体方式有以下两种:
-
锁分离
与传统锁不同的是,读写锁实现了锁分离,也就是说读写锁是由“读锁”和“写锁”两个锁实现的,其规则是可以共享读,但只有一个写。
这样做的好处是,在多线程读的时候,读读是不互斥的,读写是互斥的,写写是互斥的。而传统的独占锁在没有区分读写锁的时候,读写操作一般是:读读互斥、读写互斥、写写互斥。所以在读远大于写的多线程场景中,锁分离避免了在高并发读情况下的资源竞争,从而避免了上下文切换。
-
锁分段
我们在使用锁来保证集合或者大对象原子性时,可以考虑将锁对象进一步分解。例如,Java1.8 之前版本的 ConcurrentHashMap 就使用了锁分段。
3.非阻塞乐观锁替代竞争锁
volatile关键字的作用是保障可见性及有序性,volatile的读写操作不会导致上下文切换,因此开销比较小。 但是,volatile不能保证操作变量的原子性,因为没有锁的排他性。
而 CAS 是一个原子的 if-then-act 操作,CAS 是一个无锁算法实现,保障了对一个共享变量读写操作的一致性。CAS 操作中有 3 个操作数,内存值 V、旧的预期值 A和要修改的新值 B,当且仅当 A 和 V 相同时,将 V 修改为 B,否则什么都不做,CAS 算法将不会导致上下文切换。Java 的 Atomic 包就使用了 CAS 算法来更新数据,就不需要额外加锁。
上面我们了解了如何从编码层面去优化竞争锁,那么除此之外,JVM内部其实也对Synchronized同步锁做了优化。
在JDK1.6中,JVM将Synchronized同步锁分为了偏向锁、轻量级锁、自旋锁以及重量级锁,优化路径也是按照以上顺序进行。JIT 编译器在动态编译同步块的时候,也会通过锁消除、锁粗化的方式来优化该同步锁。
wait/notify优化
在 Java 中,我们可以通过配合调用 Object 对象的 wait()方法和 notify()方法或 notifyAll() 方法来实现线程间的通信。
在线程中调用 wait()方法,将阻塞等待其它线程的通知(其它线程调用notify()方法或notifyAll()方法),在线程中调用 notify()方法或 notifyAll()方法,将通知其它线程从 wait()方法处返回。
下面我们通过wait() / notify()来实现一个简单的生产者和消费者的案例,代码如下:
public class WaitNotifyTest {
public static void main(String[] args) {
Vector<Integer> pool=new Vector<Integer>();
Producer producer=new Producer(pool, 10);
Consumer consumer=new Consumer(pool);
new Thread(producer).start();
new Thread(consumer).start();
}
}
/**
* 生产者
* @author admin
*
*/
class Producer implements Runnable{
private Vector<Integer> pool;
private Integer size;
public Producer(Vector<Integer> pool, Integer size) {
this.pool = pool;
this.size = size;
}
public void run() {
for(;;){
try {
System.out.println("生产一个商品 ");
produce(1);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
private void produce(int i) throws InterruptedException{
while(pool.size()==size){
synchronized (pool) {
System.out.println("生产者等待消费者消费商品,当前商品数量为"+pool.size());
pool.wait();//等待消费者消费
}
}
synchronized (pool) {
pool.add(i);
pool.notifyAll();//生产成功,通知消费者消费
}
}
}
/**
* 消费者
* @author admin
*
*/
class Consumer implements Runnable{
private Vector<Integer> pool;
public Consumer(Vector<Integer> pool) {
this.pool = pool;
}
public void run() {
for(;;){
try {
System.out.println("消费一个商品");
consume();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
private void consume() throws InterruptedException{
synchronized (pool) {
while(pool.isEmpty()) {
System.out.println("消费者等待生产者生产商品,当前商品数量为"+pool.size());
pool.wait();//等待生产者生产商品
}
}
synchronized (pool) {
pool.remove(0);
pool.notifyAll();//通知生产者生产商品
}
}
}
wait/notify的使用导致了较多的上下文切换
结合以下图片,我们可以看到,在消费者第一次申请到锁之前,发现没有商品消费,此时会执行 Object.wait() 方法,这里会导致线程挂起,进入阻塞状态,这里为一次上下文切换。
当生产者获取到锁并执行notifyAll()之后,会唤醒处于阻塞状态的消费者线程,此时这里又发生了一次上下文切换。
被唤醒的等待线程在继续运行时,需要再次申请相应对象的内部锁,此时等待线程可能需要和其它新来的活跃线程争用内部锁,这也可能会导致上下文切换。
如果有多个消费者线程同时被阻塞,用notifyAll()方法,将会唤醒所有阻塞的线程。而某些商品依然没有库存,过早地唤醒这些没有库存的商品的消费线程,可能会导致线程再次进入阻塞状态,从而引起不必要的上下文切换。
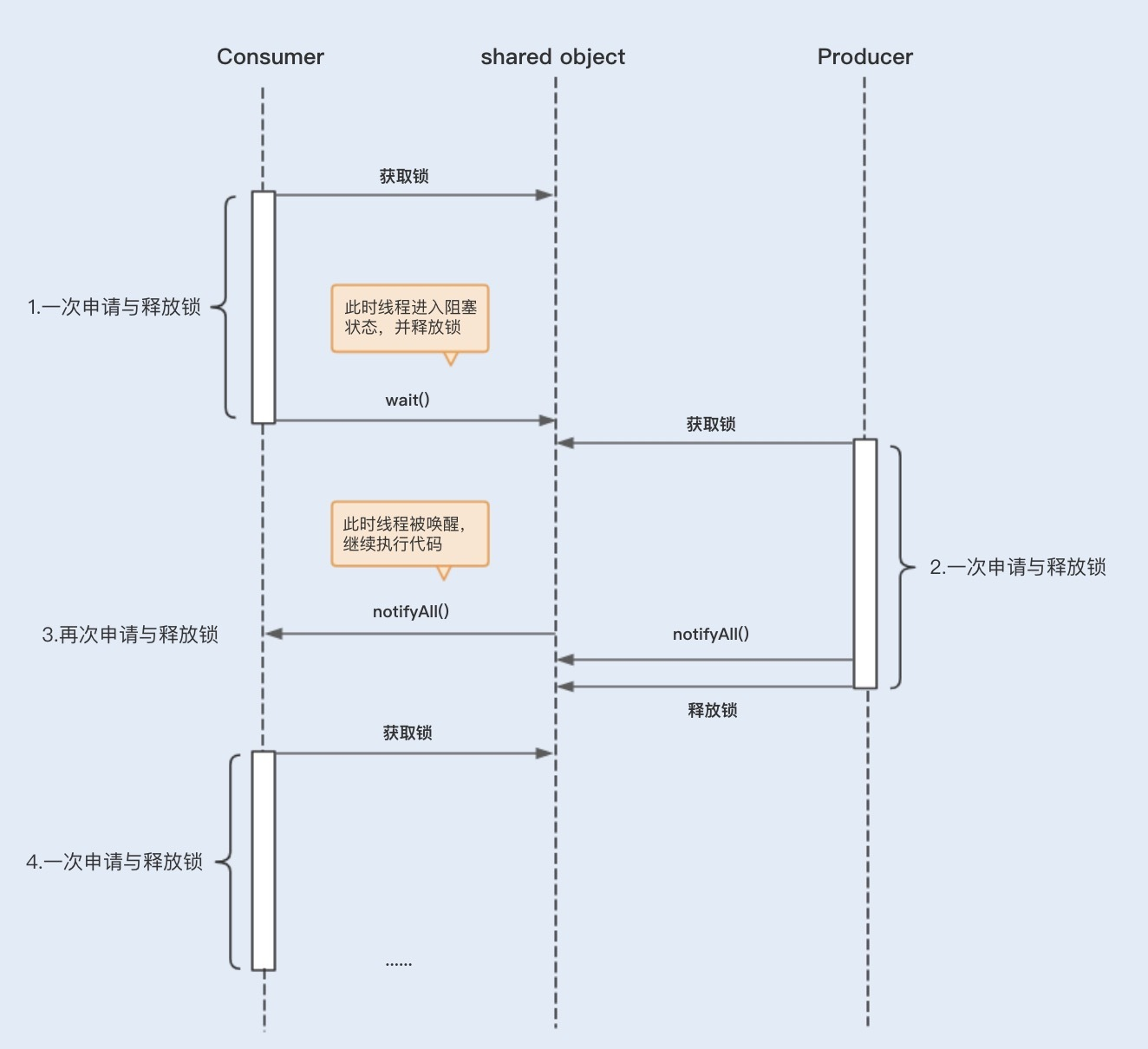
优化wait/notify的使用,减少上下文切换
首先,我们在多个不同消费场景中,可以使用 Object.notify() 替代 Object.notifyAll()。 因为Object.notify() 只会唤醒指定线程,不会过早地唤醒其它未满足需求的阻塞线程,所以可以减少相应的上下文切换。
其次,在生产者执行完 Object.notify() / notifyAll()唤醒其它线程之后,应该尽快地释放内部锁,以避免其它线程在唤醒之后长时间地持有锁处理业务操作,这样可以避免被唤醒的线程再次申请相应内部锁的时候等待锁的释放。
最后,为了避免长时间等待,我们常会使用Object.wait (long)设置等待超时时间,但线程无法区分其返回是由于等待超时还是被通知线程唤醒,从而导致线程再次尝试获取锁操作,增加了上下文切换。
这里我建议使用Lock锁结合Condition 接口替代Synchronized内部锁中的 wait / notify,实现等待/通知。这样做不仅可以解决上述的Object.wait(long) 无法区分的问题,还可以解决线程被过早唤醒的问题。
Condition 接口定义的 await 方法 、signal 方法和 signalAll 方法分别相当于 Object.wait()、 Object.notify()和 Object.notifyAll()。
合理地设置线程池大小,避免创建过多线程
线程池的线程数量设置不宜过大,因为一旦线程池的工作线程总数超过系统所拥有的处理器数量,就会导致过多的上下文切换。
还有一种情况就是,在有些创建线程池的方法里,线程数量设置不会直接暴露给我们。比如,用 Executors.newCachedThreadPool() 创建的线程池,该线程池会复用其内部空闲的线程来处理新提交的任务,如果没有,再创建新的线程(不受 MAX_VALUE 限制),这样的线程池如果碰到大量且耗时长的任务场景,就会创建非常多的工作线程,从而导致频繁的上下文切换。因此,这类线程池就只适合处理大量且耗时短的非阻塞任务。
使用协程实现非阻塞等待
相信很多人一听到协程(Coroutines),马上想到的就是Go语言。协程对于大部分 Java 程序员来说可能还有点陌生,但其在 Go 中的使用相对来说已经很成熟了。
协程是一种比线程更加轻量级的东西,相比于由操作系统内核来管理的进程和线程,协程则完全由程序本身所控制,也就是在用户态执行。协程避免了像线程切换那样产生的上下文切换,在性能方面得到了很大的提升。
减少Java虚拟机的垃圾回收
很多 JVM 垃圾回收器(serial收集器、ParNew收集器)在回收旧对象时,会产生内存碎片,从而需要进行内存整理,在这个过程中就需要移动存活的对象。而移动内存对象就意味着这些对象所在的内存地址会发生变化,因此在移动对象前需要暂停线程,在移动完成后需要再次唤醒该线程。因此减少 JVM 垃圾回收的频率可以有效地减少上下文切换。
总结
上下文切换是多线程编程性能消耗的原因之一,而竞争锁、线程间的通信以及过多地创建线程等多线程编程操作,都会给系统带来上下文切换。除此之外,I/O阻塞以及JVM的垃圾回收也会增加上下文切换。系统和 Java 程序自发性以及非自发性的调用操作,就会导致上下文切换,从而带来系统开销。
线程越多,系统的运行速度不一定越快。那么我们平时在并发量比较大的情况下,什么时候用单线程,什么时候用多线程呢?
一般在单个逻辑比较简单,而且速度相对来非常快的情况下,我们可以使用单线程。例如 Redis,从内存中快速读取值,不用考虑 I/O 瓶颈带来的阻塞问题。而在逻辑相对来说很复杂的场景,等待时间相对较长又或者是需要大量计算的场景,我建议使用多线程来提高系统的整体性能。例如,NIO 时期的文件读写操作、图像处理以及大数据分析等。
本文由 mdnice 多平台发布