
1.背景介绍
近年来,人们能够轻松的访问互联网上的教学视频,这成为了一种趋势并彻底改变了以往的获取信息或传递知识的方式[1]-[2]。许多人意识到在他们完成某项任务之前通过观看教学视频是一种更高效的方式,因为他们能通过视频中一系列循序渐进的步骤来学习如何完成特定任务[3]-[4]。为此,我们提出了基于中文医疗教学视频时刻答案定位(TAGV) 的新任务,这项任务的目的是找到与输入问题对应的视频帧跨度。该任务的视频来自YouTube 网站上高质量的中文医学教学频道,其中医学问题对应的视频答案片段时间戳由医学专家标注。本次NLPCC2023 Shared Task5 任务的最终目的是开发一个可以为医疗急救或医学教育提供视频时刻问答功能的系统。
2. 任务综述
本次NLPCC 2023 Shared Task 5任务共包括三个赛道:单个视频中视频问答定位(Temporal Answer Grounding in Singe Video, TAGSV),视频数据库检索(Video Corpus Retrieval, VCR)和视频数据库中时序问答定位(Temporal Answer Grounding in Video Corpus, TAGVC)。

赛道1. 单个视频问答定位 (TAGSV):如图1所示:给定一个医学或健康相关的问题和一个未修剪的中文医疗教学视频,该赛道旨在视频中找到视频答案所在的时间戳。例如,图中0:54s~1:25s 是给定中文问题“如何利用工具缓解头部前倾的问题”的视频答案时间戳。

赛道2. 视频数据库检索 (VCR):如图2所示:给定一个医学或健康相关的问题和大量未经剪辑的中文医学教学视频,该赛道旨在从给定视频数据库中找到与给定问题最相关的视频。例如,图中第一个视频是与中文问题“如何利用工具缓解头部前倾的问题”最相关的目标检索视频。

赛道3. 视频数据库的时序问答定位(TAGVC):如图3所示:给定一个医学或健康相关的问题和大量未经剪辑的中文医学教学视频,该赛道旨在从给定视频数据库中与找到与给定问题最匹配的视频答案时间戳。例如,图中0:54s~1:25s 是给定中文问题“如何利用工具缓解头部前倾的问题”下该视频数据库中最匹配的视频答案时间戳。
3.数据集简介
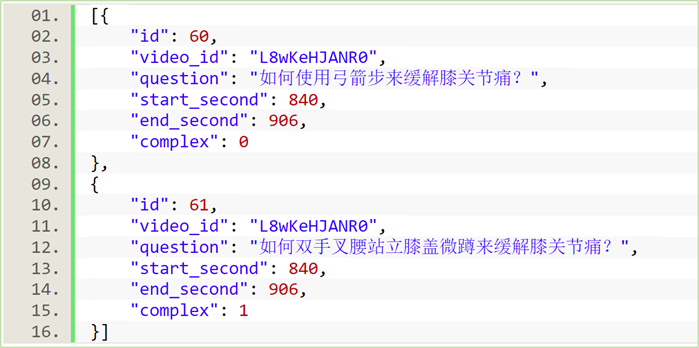
本次比赛的视频是从YouTube网站的中文医学教学频道中爬取的,其中的字幕(中文)是从相应的视频中自动转录出来的。问题和相应的视频答案时间戳是由具有医学背景的专家进行标注而得到的。每个视频可能包含多个问答对,其中每个问题对应一个唯一的答案。数据集分为训练集、验证集和测试集,训练集共包含1,228个视频,包含2,937个视频问答对,供参赛选手进行模型训练。
图4展示了 CMIVQA 竞赛数据集的示例。其中,“id”是用于视频检索赛道的样本编号。“video_id”是指来自 YouTube 的唯一 ID。“问题”项由医学专家手写。“开始和结束秒”代表相应视频答案的时间戳。比赛期间分为A、B榜单进行测试,每周更新榜单数据,最后以B榜的结果作为获奖参评依据。测试集中赛道2与赛道3的真实 “id”数据编号在发布时不对外公开。总而言之,我们的最终目标是从测试语料库中检索目标视频 ID,然后定位视觉答案。更多数据集细节与基准线方法请访问:
比赛官网:
https://cmivqa.github.io/
比赛Github:
https://github.com/cmivqa/NLPCC-2023-Shared-Task-5
4.评价指标
赛道 1:
单个视频问答定位任务
我们使用如下所示的度量计算公式来评估结果。具体来说,我们使用 (1) 交并比(Intersection over Union, IoU),和 (2) 平均交并比 mIoU,mIoU数值为所有测试样本的平均 IoU。参考研究工作[3]-[5]后,我们采用“R@n,IoU = μ”和“mIoU”作为评估指标,将视频答案帧的时间戳定位视为跨度预测任务。“R@n, IoU = μ”表示预测时间答案跨度与真实跨度的交并比 (IoU),其中重叠部分在前 n 个检索时刻中大于“μ”。“mIoU”是样本的平均 IoU。在我们的实验中,我们使用 n = 1 和 μ ∈ {0.3, 0.5, 0.7} 来评估 TAGSV 结果。
其中和代表不同的跨度, 分别代表IoU = 0.3/0.5/0.7, .
注:该赛道的主要排名是基于mIoU分数,我们同时也提供了该赛道的其他指标以供进一步分析。
赛道 2:
视频数据库检索
继开创性的工作[6]之后,我们采用了像“R@n”这样的视频检索指标。具体来说,我们采用 n=1、10 和 50 来表示视频检索的召回性能。同时,采用平均倒数排序(MRR)得分这项指标评价中文医疗教学视频语料库检索性能,计算方法如下。
其中 是视频数据库大小数目. 对于每个测试样本 , 排名表示真实视频标签在预测列表中的位置。
注: 该赛道的主要排名是基于Overall分数。Overall分数是将 R@1, R@10, R@50 and MRR scores进行相加,计算如下。
其中 是相加的个数. 是第个指标的得分(包括R@1, R@10, R@50 和MRR), .
赛道3:
视频数据库时序问答定位
我们保留与 赛道1 相似的 交并比 (IoU) 指标和与 Track 2检索指标“R@n, n=1/10/50”和 MRR,用于赛道3结果的进一步分析。我们仍然使用像R@n, IoU = 0.3/0.5/0.7这样的指标,同时,我们将n = 1、10、50 进行评估。值得注意的是,视频检索子任务中的平均 IoU 指标,即“R@1/10/50|mIOU”,也用于衡量参与模型的性能表现。
注: 该赛道的主要排名是基于Average分数。Average分数是将R@1|mIoU, R@10|mIoU, R@50|mIoU进行平均,计算如下。
其中 评价指标个数. 第个指标(例如:R@1|mIoU, R@10|mIoU, R@50|mIoU), .
5.比赛奖励一览
每个赛道的前三名团队将获得奖金(¥3000、¥2000、¥1000),所有奖金总价值¥18000。
此外,每个赛道的第1名参赛队伍将获得NLPCC和CCF认证的获奖证书,并获得NLPCC 2023会议论文(CCF-C)发表资格。每个赛道的现金奖励如下:
一等奖(*1):¥3000
二等奖(*1):¥2000
三等奖(*1):¥1000
6.重要的日期
提交截止日期为晚上 11:59。规定的截止日期 (UTC/GMT+08:00)。
| 比赛任务公告及参与报名 | 2023年3月15日 |
| 发布任务指南和训练数据 | 2023年4月3日 |
| 测试A数据发布 | 2023年4月10日 |
| 比赛报名截止 | 2023年5月28日 |
| 测试B数据发布 | 2023年5月21日 |
| 测试B数据结果提交 | 2023年5月28日 |
| 比赛结果发布并征集系统报告和会议论文 | 2023年6月10日 |
| 会议论文提交截止日期(仅适用于比赛任务) | 2023年6月30日 |
| 会议论文接受/拒绝通知 | 2023年7月18日 |
| 论文提交截止日期 | 2023年8月1日 |
7.举办单位信息
主办方:CCF自然语言处理与中文计算国际会议
承办方:湖南大学 视觉感知与人工智能湖南省重点实验室

协办方:赛灵药业科技集团股份有限公司

8.协办方介绍
赛灵药业科技集团股份有限公司是一家集药品研发、生产、销售为一体,获“高新技术企业”认证的综合性医药企业。公司以“仁爱心,赛灵药”为企业宗旨,专注于构建骨健康生态体系,打造骨健康领域领先品牌,为广大医患提供更具临床价值的新产品和新技术。
赛灵药业积极践行“成为人人信赖的骨健康专家“企业愿景,探索科普教育、基层医疗教育新模式,助力人工智能更好的服务大众,为健康中国贡献赛灵力量!
9.赛事联系方式
更多赛事信息及报名方式,请关注“中文医疗教学视频问答任务”官方网站
官网:
cmivqa.github.io
官网Github:
https://github.com/cmivqa/NLPCC-2023-Shared-Task-5
Baseline网址:
github.com/WENGSYX/CMIVQA_Baseline
官方微信群:

失效请关注官网Github的群链接
联系人:




[1]Li, Bin, et al. “Towards visual-prompt temporal answering grounding in medical instructional video.” arXiv preprint arXiv:2203.06667 (2022).
[2]Weng, Yixuan, and Bin Li. “Visual Answer Localization with Cross-modal Mutual Knowledge Transfer.” arXiv preprint arXiv:2210.14823. (Accepted in ICASSP 2023).
[3]Deepak Gupta, Kush Attal, and Dina Demner-Fushman. “A Dataset for Medical Instructional Video Classification and Question Answering.” arXiv preprint arXiv:2201.12888, 2022.
[4] Deepak Gupta, and Dina Demner-Fushman. “Overview of the MedVidQA 2022 Shared Task on Medical Video Question-Answering. ” BioNLP 2022@ ACL 2022 (2022): 264.
[5]Zhang, Hao, et al. “Natural language video localization: A revisit in span-based question answering framework.” IEEE transactions on pattern analysis and machine intelligence 44.8 (2021): 4252-4266.
[6]Li, Bin, et al. "Learning to Locate Visual Answer in Video Corpus Using Question." arXiv preprint arXiv:2210.05423. (Accepted in ICASSP 2023).