目录
独创性说明
本次实验本人是抱着较大的兴趣去完成的,其中加入了一些我对于当前关于NLP的相关技术的简单了解和初步的看法,某些地方语言描述并不是很严肃。为了节省时间,在论述实验中我引入了一些学术论文的研究成果和理论,所以有些地方并不是我的原创,我也并没有具体标注这些成果的出处,但是本着学习的态度,我坚持写了这样的一篇报告,所以这不能算是一篇正式的论文报告。对了,其中的一些用词可能不是很准确,但是我觉得有逼格,就使用了,所以各位不必深究,经不起推敲的东西看一看就可以了,所以其中有不足之处还请谅解。
第一章 绪论
1.1研究背景
随着计算机技术的飞速发展,人们已经踏入了人工智能时代。尤其是今年极为火爆的由美国人工智能研究实验室OpenAI新推出的一种人工智能技术驱动的自然语言处理(Natural Language Processing)工具ChatGPT,ChatGPT技术的出现,让人工智能技术在语言交互方面的应用变得更加普及和广泛。在twitter上,使用过ChatGPT的用户反馈表示,基于21年语料库训练出来的3.0版本的Chat的智力已经是相当于小狗的水平,而GPT-3只是ChatGPT(这里我们直接跳过1、2版本)唯一美中不足的一点就是国内用户想使用该技术有一定的困难,而且ChatGPT的定价比较高,想要使用最新版本的ChaGPT(据说5.0版本也要上线了),用户需要每月支付20美刀,按最新汇率计算(6.8680,截至2023-03-25 05:00),国内用户每个月至少要花费137元,对于我这种穷鬼来说,简直无法接受!所以还是用3.5版本的吧,要是能白嫖4.0的话...hhh
ChatGPT推出后不久,国内涌现出的一批公司,立马推出关于ChatGP的套壳产品,迅速占领国内市场,割取韭菜,谋取利益,主打的就是一个信息差,这也算是数字鸿沟的一个具体体现了。同时,百度在今年三月份推出了一款类似的产品——文心一言,比较有意思的是在发布会当天,李彦宏介绍玩该产品后,百度股票开始下跌,而且大多数网友都认为文心一言相较于ChatGPT简直不值一提。最近媒体也在炒作关于腾讯将要推出的盘古模型,对此,了解国情的大部分网友持着不是很看好的态度。我只申请了newbing的API接口,和openAI的ChatGPT4的接口,只有微软的通过了(其实它是3.0版本的GPT),openAI至今也没有回我消息。文心一言我只听过,昨儿申请的,其他的再没关注过。我觉得
1.2课题研究
网上的沟通平台各式各样,中国互联网发展至今,各大网络公司推出了QQ、微信、贴吧、微博、知乎等目不暇接的社交软件供人们使用。这些APP极大的改变了人与人之间的交流方式,让人们可以更加高效、准确的表达思想,而人们对待每个问题都有不同的看法,或多或少带有个人的感情倾向,作为一名NLP学者,我们自然是要对这些包含情感的观点进行分析,判断出这些人的喜怒哀乐,至于我将要使用的分析方法,后面会讲到。在各种社交软件中,微博的覆盖群体较广,每日用户活跃数量上亿。随着这几年的发展,微博用户数量的增加使微博的交互内容更加多元化,而丰富多元的内容生态又可使用户得到更好的使用体验。微博上每时每刻产生的海量情感文本,内容涉及政治、经济、娱乐、体育等多种领域,且一般饱含情感倾向和个人立场,带有非常丰富的研究价值。因此这次的课题我们以微博为例,利用自然语言处理技术(NLP),对获取的微博语料建立一个模型,然后利用训练好的模型对训练集进行分词处理和情感分析。
第一章 情感分析准备
2.1情感分析知识基础
情感分析又被称作评论挖掘或者意见挖掘,在情感信息分类方面,一般可根据目标任务划分为粗粒度情感分类和细粒度情感分类,其中粗粒度情感分类是指判断出文本整体所表现出的情感,以此表明一个人对某件事或对某个物体的整体评价。粗粒度情感分类有两种方式,一种是情感倾向性分类,即分为褒、贬、中三类;第二种是情绪分类,表示将个人主观情绪分为喜、怒、悲、恐、惊等类别。迄今为止,文本情感分析的方法主要可划分为三大类,分别为:基于情感词典、基于机器学习、基于深度学习模型。害,这些理论就先别管了,都有ChatGPT了,我们只管提要求就是,再说,现在很多库都能直接调用,直接上项目(注:其实就是一个简单的语言处理作业,还不配被称为项目,但是就当它是了)!
2.2 SnowNLP库
在这次的数据挖掘实验中,我用到了SnowNLP库,这个库是国人自己开发的python类库,专门针对中文文本进行挖掘,里面已经有了算法,需要自己调用函数,根据不同的文本构建语料库就可以,真的很方便。其中有很多算法,这几天我也在努力学习其中的算法原理。不过遇到不少困难,因为我在学习这个库的时候,我查了很多资料发现很少或者基本没有写这个库的具体详解,很多都是转载官网对这个库的简介,有些解释也是模糊不清。我搜到的有关SnowNLP的案例有些是英文写的(包括SonwNLP官网介绍也都是英文),所以英文理解也是学习过程中的一大困难,不过在这个过程中,我确实有所收获,在这我就简单记录一下一些模块的调用,具体的原理就...
首先准备好语料,neg.csv和pos.csv,用他们训练自己的模型,具体步骤如下:调用SnowNLP库里的snetiment模块,然后保存自己模型,把它放到自己的文件夹中,后续会用到。这里的训练语料不是很多,每个文件也就一万多条微博语料数据,大概五分钟就训练好了,卷王们就可以趁这个时间背几个英文单词了

![]()
然后加载自己的模型对测试语料进行情感分析,在这之前记得加载自己的模型,把默认的模型文件路劲改成自己的,以下代码的运行结果显示出这两个路劲是不一样的。

![]()
加载完模型,直接处理数据,然后情感分析。一眼望去,代码都懂,那就不罗嗦了,简而言之就是,
之后我就用简而言之的方法论述我剩下的实验过程:

然后这么的......

再然后就这么的......

再然后实验结束
......
文档备份:

Ok,如果想更深入一点,就接着Copy,下面我简单Copy一下Word2vec模型的原理(注:词向量模型不止这一个)。
2.3 Word2vec方式
采用Word2vec词向量的步骤可分为:中文分词、去停用词、训练词向量。由于实验语料源自中文微博网络平台,所以文本语言以中文为主,极少数语句中参杂个别英文词汇。由于英文词汇间有空格作为天然的分词界限,所以无需进行分词操作,而中文则需要采用分词算法将句子中的词汇、符号依次分隔开来。
实验中应用基于Python的开源分词工具“jieba”对微博评论文本进行分词。该工具拥有三种分词模式,分别为全模式、精确模式和搜索引擎模式,可根据任务目标进行选择。计算机在读取语料文件后,调用jieba.cut()方法开始对每句文本分词处理。其中,需要设置jieba.cut()函数内的三个参数:第一个参数是在引号内输入需要分词的字符串;第二个参数cut_all需要填写True或False来决定采用全模式或精确模式;第三个是HMM参数用来控制是否借助HMM模型。实验中选择使用精确模式以保证分词的准确性。 分词处理的下一阶段是过滤停用词。由于网络评论的文本具有很强的原创性、随意性,所以语句中会夹杂着许多没有实际意义的词,例如“的”“是”“了”等。除此之外,文本中还存在许多对于情感分类无用的标点符号,例如“,”、“*”、“:”、“#”、“?”、“@”、“ [”、“]”等。过多的冗余信息将为情感分析任务带来困难,同时还会影响分析正确率,应在进行进一步分析处理前将其剔除。之后提取其中的关键词。
在这说一下model.Word2Vec的各个参数:
sentences: 我们要分析的语料,可以是一个列表,或者从文件中遍历读出。
size: 词向量的维度,默认值是100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
window:即词向量上下文最大距离,这个参数在我们的算法原理篇中标记为cc,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
sg: 即我们的word2vec两个模型的选择了。如果是0,则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
hs: 即我们的word2vec两个解法的选择了,如果是0则是Negative Sampling,是1的话并且负采样个数negative大于0,则是Hierarchical Softmax。默认是0即NegativeSampling。
negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。
cbow_mean: 仅用于CBOW在做投影的时候,为0则为上下文的词向量之和,为1则为上下文的词向量的平均值。是按照词向量的平均值来描述的。
min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
alpha: 在随机梯度下降法中迭代的初始步长。默认是0.025。
min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。
对于大语料,需要对alpha, min_alpha,iter一起调参,来选择合适的三个值。
2.3 词向量工作原理
基本想法是:通过训练将某种语言中的每一个词映射成一个固定长度的短向量(这里的“短”是相对于one-hot representation的“长”而言),将所有这些向量放在一起形成一个词向量空间,而每一向量则可视为该空间中的一个点,在这个空间上引入“距离”,则可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性。举个例子:假设每个词向量是分布在二维平面上的N 个不同的点,给定其中的某个点,想在平面上找到与这个点最相近的一个点,为解决这个问题,我们按以下步骤:首先,建立一个直角坐标系,基于该坐标系,其上的每个点就唯一地对应一个坐标;接着引入欧氏距离;最后分别计算这个词与其他 N-1 个词之间的距离,对应最小距离值的那个词便是我们要找的词。
当然这里可以直接交给GPT(我这里用的是3.5版本的,4.0用不起,各位魔法师们请谅解)如果能嫖到4.0版本的API就更完美了

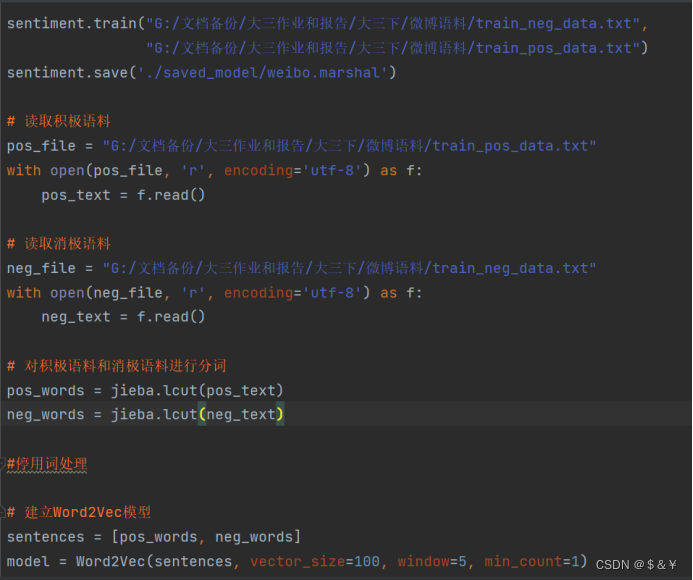
代码展示如下:中间有个停用词处理的代码没写,要是写上,就截两次图,所以...
第三章没想好......
第四章 没想好......
第五章 没想好......
写在末尾:
如果对结果不满意,可以尝试更多模型或者优化数据和模型。做法思路如下:加载模型,读入微博语料(.txt),将Word2vec分别连接到LSTM、Bi-LSTM、Self-Attention、CNN网络模型上进行训练,计算各个模型的准确率、F1分数,写入excel表中...
还有就是我的封面是GPT3.5生成的,看着挺抽象,但也够逼格的。有一说一ChatGPT真挺好用,各位魔法师们要是愿意,可以一起交流学习
Chat一出,码农已死,代码在此,拿走!
Word2vec方式:
from snownlp import sentiment
import gensim
from gensim.models import Word2Vec
import jieba
import os
sentiment.train("train_neg_data.txt",
"train_pos_data.txt")
sentiment.save('./saved_model/weibo.marshal')
# 读取积极语料
pos_file = "train_pos_data.txt"
with open(pos_file, 'r', encoding='utf-8') as f:
pos_text = f.read()
# 读取消极语料
neg_file = "train_neg_data.txt"
with open(neg_file, 'r', encoding='utf-8') as f:
neg_text = f.read()
# 对积极语料和消极语料进行分词
pos_words = jieba.lcut(pos_text)
neg_words = jieba.lcut(neg_text)
#停用词处理
# 建立Word2Vec模型
sentences = [pos_words, neg_words]
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1)
# 保存模型
model_file = '../saved_model/sentiment_analysis.model'
model.save(model_file)
# 加载模型
model = Word2Vec.load(model_file)
# 查看词向量
# print(model.wv['好'])直接调用SnowNLP
import pandas as pd
import snownlp
from snownlp import sentiment
from snownlp import SnowNLP
#数据格式转换
neg = pd.read_excel("neg.xls")
pos = pd.read_excel("pos.xls")
neg.to_csv("neg.csv")
pos.to_csv("pos.csv")
#训练语料,构建模型
sentiment.train("neg.csv",
"pos.csv")
sentiment.save('../saved_model/weibo_pro.marshal_2.0')#这里差不多要五分钟
# Use the saved model to analyze the sentiment of test data
# sentiment = sentiment.classifier.load('../saved_model/weibo_pro.marshal_2.0')
# print("默认的模型文件路径:", sentiment.data_path)
sentiment.data_path ="../saved_model/weibo_pro.marshal_2.0.3"#加载文件路径
# print("自己训练的模型路径:", sentiment.data_path)
#对测试数据进行情感分析
data = []
data_file = "valid_data.txt"
with open(data_file, "r", encoding="utf-8") as f:
data_line = f.readlines()
f.close()
for line in data_line:
data_sentence = line.strip("\n")
data.append(data_sentence)
data_text = pd.DataFrame(data, columns=["sentence"])
data_text_file = "valid_data.xls"
test_data = pd.read_excel(data_text_file)
#把分析结果写入excel文件
test_data["sentiment"] = test_data["sentence"].apply(lambda x: SnowNLP(x).sentiments)
test_data["sentiment"].to_excel("../results/marshal_2.0_test_result.xls")#写入文件import snownlp
from snownlp import SnowNLP
import pandas as pd
#加载训练好的模型
# model_path = "./saved_model/weibo.marshal.3"
# s = SnowNLP(model_path)
snownlp.sentiment.DATA_PATH ="./saved_model/weibo_pro.marshal_2.0.3"
# df = pd.DataFrame(columns=['text', 'sentiment'])
text = []
sent = []
with open("valid_data.txt", 'r', encoding='utf-8') as f:
data = f.readlines()
for line in data:
sentence = line.strip("\n")
sentiment = SnowNLP(sentence).sentiments
text.append(sentence)
sent.append(sentiment)
# df = pd.concat({'text': line, 'sentiment': sentiment}, ignore_index=True)
# df = pd.concat({'text': line, 'sentiment': sentiment}, ignore_index=True)
df_text = pd.DataFrame(text, columns=['text'])
df_sent = pd.DataFrame(sent, columns=['sentiment'])
pf = pd.concat([df_text, df_sent], ignore_index=True)
pf.to_excel('./results/SnowNLP_result.xlsx', index=False)文献参考:
[1] 郎聪.(2021).基于深度学习的微博文本情感分析(硕士学位论文,沈阳工业大学).基于深度学习的微博文本情感分析 - 中国知网
[2]基于LSTM搭建一个文本情感分类的深度学习模型:准确率往往有95%以上_情感分类准确度_YiqiangXu的博客-CSDN博客
[3]https://www.cnblogs.com/always-fight/p/10310418.html
[4]https://louyu.cc/articles/machine-learning/2019/09/?p=1933/