yolov5代码使用
关于detection.py各个参数的含义可以参考这篇博客
手把手带你调参Yolo v5 (v6.2)(推理)
https://yolov5.blog.csdn.net/article/details/124378167
detect.py
使用窗口方式运行
python detect.py --source img/street.jpg --data data/coco.yaml --weights weights/yolov5/yolov5s.pt --device 0
修改默认参数运行
parser.add_argument('--weights', nargs='+', type=str, default='weights/yolov5/yolov5s.pt', help='model path(s)')
parser.add_argument('--source', type=str, default='img/street.jpg', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--data', type=str, default='data/coco.yaml', help='(optional) dataset.yaml path')
yoloair.models.experimental.py
报错keyerror:‘ema’
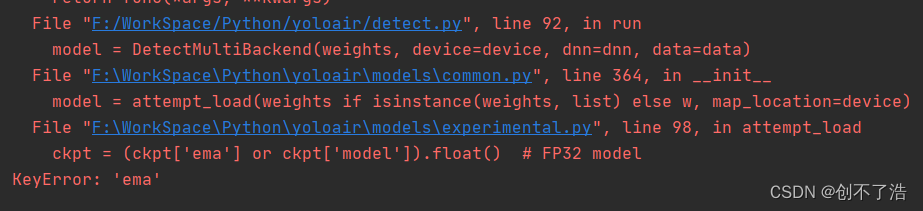
换成 yolov5代码的写法就没错了
# ckpt = (ckpt['ema'] or ckpt['model']).float() # FP32 model
ckpt = (ckpt['ema' if ckpt.get('ema') else 'model']).float() # FP32 model
train.py
报错
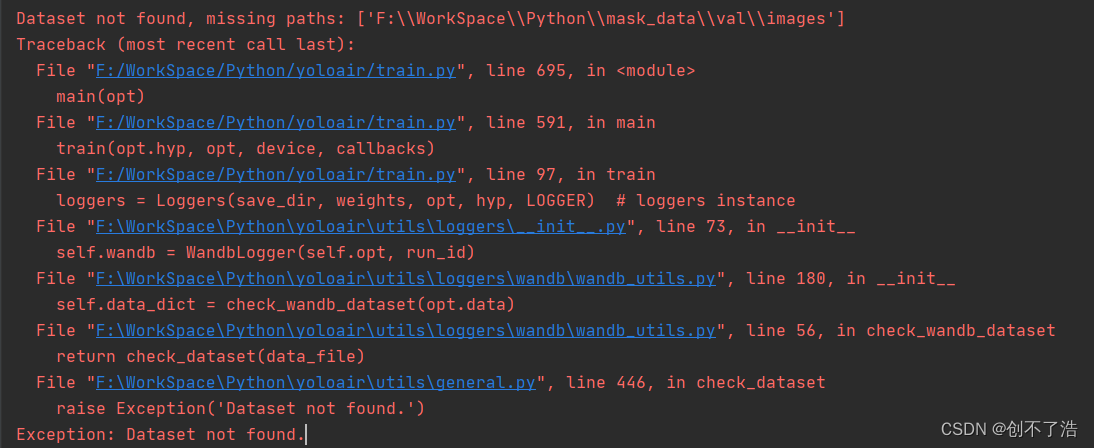
此时目录结构mask_data 与 yoloair项目在同一个目录下,yolov5项目中mask_data在yolov5项目下,可以成功运行。但是我把yolov5的mask.yaml文件复制到yoloair可以直接训练。
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: F:/WorkSpace/Python/yolov5/mask_data/train/images/
val: F:/WorkSpace/Python/yolov5/mask_data/valid/images/
# number of classes
nc: 2
# class names
names: [ 'mask', 'nomask' ]
# Print classes
# with open('data/coco.yaml') as f:
# d = yaml.load(f, Loader=yaml.FullLoader) # dict
# for i, x in enumerate(d['names']):
# print(i, x)
用下面合格mask.yaml文件不能直接运行
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: F:/WorkSpace/Python/mask_data/train/images/
val: F:/WorkSpace/Python/mask_data/val/images/
test: F:/WorkSpace/Python/mask_data/test/images/
# number of classes
nc: 2
# class names
names: [ 'mask', 'nomask' ]
把mask_data移动到yoloair目录下还是报错了
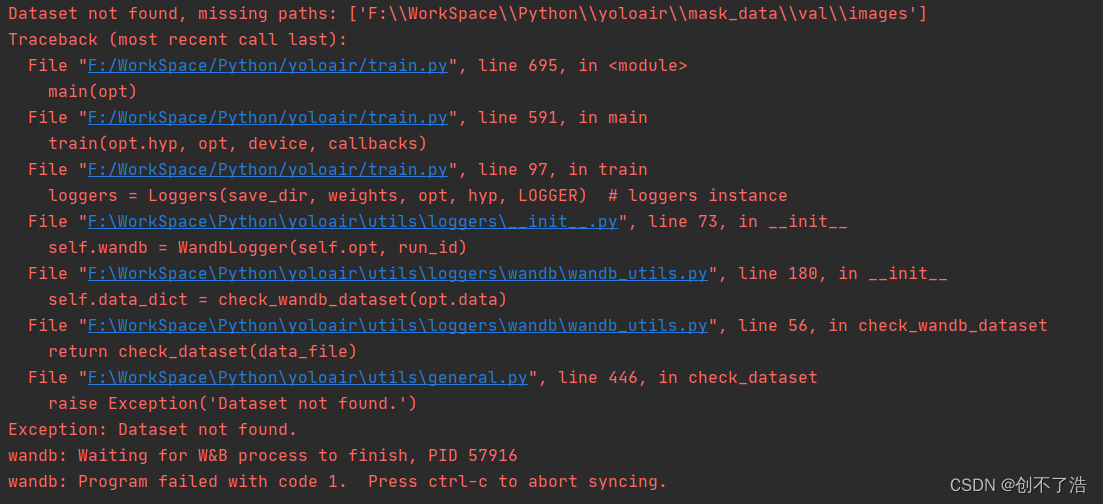
只有debug试一下了,最后获取返回的data数据,发现是路径错了,我是个憨逼
把 val: F:/WorkSpace/Python/mask_data/val/images/ 改成 val: F:/WorkSpace/Python/mask_data/valid/images/ 就没问题了。可以正常训练。
多了一个test的目录,没啥关系,在 utils.general.py 的check_dataset方法中会查验数据集,用字典的形式把train,val,test的目录载入
# Resolve paths
path = Path(extract_dir or data.get('path') or '') # optional 'path' default to '.'
if not path.is_absolute():
path = (ROOT / path).resolve()
for k in 'train', 'val', 'test':
if data.get(k): # prepend path
data[k] = str(path / data[k]) if isinstance(data[k], str) else [str(path / x) for x in data[k]]