引言
在进行数据合并时,Excel 数据,我们用到最多的是 vlookup 函数,SQL 数据库数据,join 用得最多,都可以实现多表匹配查询,合并等功能。Python 的 Pandas 也有有类似的功能函数,就是我们今天要介绍的 pd.merge(),更多 Python 进阶系列文章,请参考 Python 进阶学习 玩转数据系列
内容提要:
- merge() 方法介绍
- inner join merge 内连接
- outer join merge 外连接
- left join merge 左连接
- right join merge 右连接
- 指定列名 / index 为键的 join merge
● on 关键字
● left_on 和 right_on 关键字
● left_index 和 right_index 关键字
● 混合 left/right_index with right/left_on 关键字
merge() 方法
pandas 的 merge 方法提供了一种类似于 SQL 的内存链接操作,它的性能会比其他开源语言的数据操作(例如R)要高效.
用法:pd.merge() 或 df1.merge(df2)
pandas.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None)
DataFrame.merge(right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None)
| 参数 | 描述 |
|---|---|
| on | 列名,join用来对齐的那一列的名字,用到这个参数的时候一定要保证左表和右表用来对齐的那一列都有相同的列名。 |
| left_on | 左表作为键 Key 的列,可以是列名,也可以是和dataframe同样长度的arrays。 |
| right_on | 右表作为键 Key 的列,可以是列名,也可以是和dataframe同样长度的arrays。 |
| left_index/ right_index | 如果是True的 index作为键的key |
| how | 数据合并的方法。{‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, 默认inner |
| sort | 根据dataframe合并的keys按字典顺序排序,默认是,如果置false可以提高表现 |
| suffixes | 默认 (“_x”, “_y”)相同列名加前缀用来区分左右数据源 |
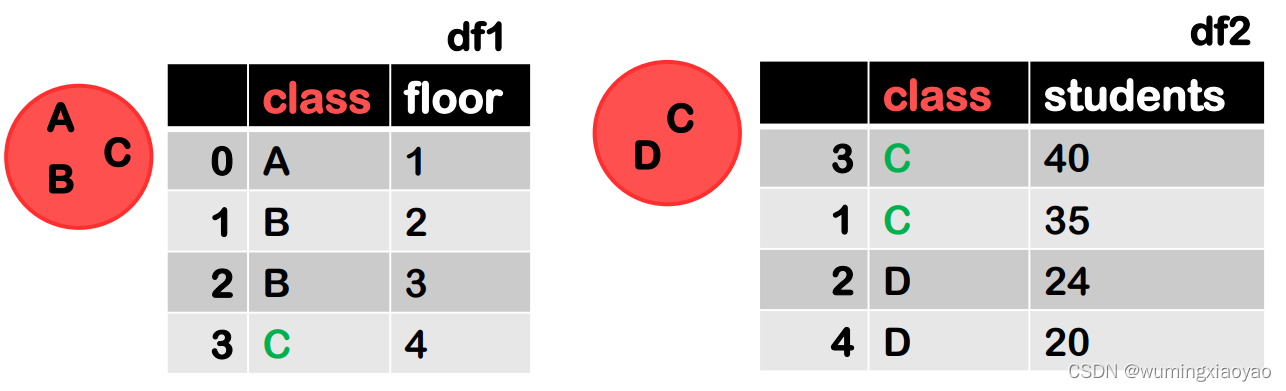
inner join merge 内连接
merge 的 inner 类型称为内连接,它在拼接的过程中会取两张表的键(key)的交集进行拼接。
下面两张表,相同的列名 class 就是默认的主键,对应 class 列所有的值的交集就是 C
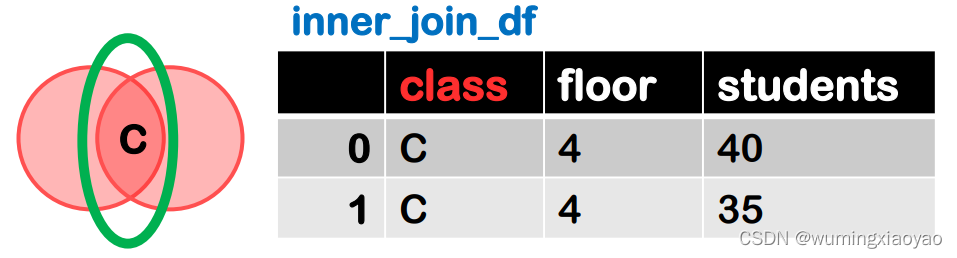
把交集 C 对应的关系列出来,这就是 inner join merge 的结果,下面几条语句都是等价的。
pd.merge(df1,df2)
df1.merge(df2)
pd.merge(df1,df2,how=‘inner’, on=“class”)
df1.merge(df2, how=‘inner’, on=“class”)
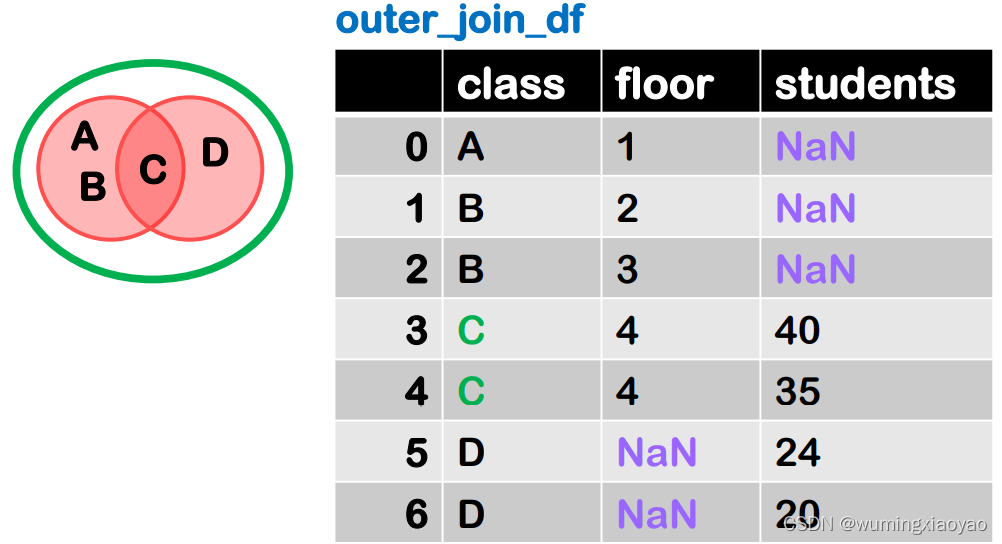
outer join merge 外连接
outer 是外连接,在拼接的过程中它会取两张表的键(key)的并集进行拼接。
下面两张表,相同的列名 class 就是默认的主键,对应 class 列所有的值的并集就是 A B C D
将两张表的数据列拼起来,对于没有匹配到的地方,使用缺失值NaN进行填充,就是 outer join merge 的结果
下面语句都是等价的:
pd.merge(df1,df2, how=‘outer’)
df1.merge(df2, how=‘outer’)
pd.merge(df1,df2, how=‘outer’, on=‘class’)
df1.merge(df2, how=‘outer’, on=‘class’)
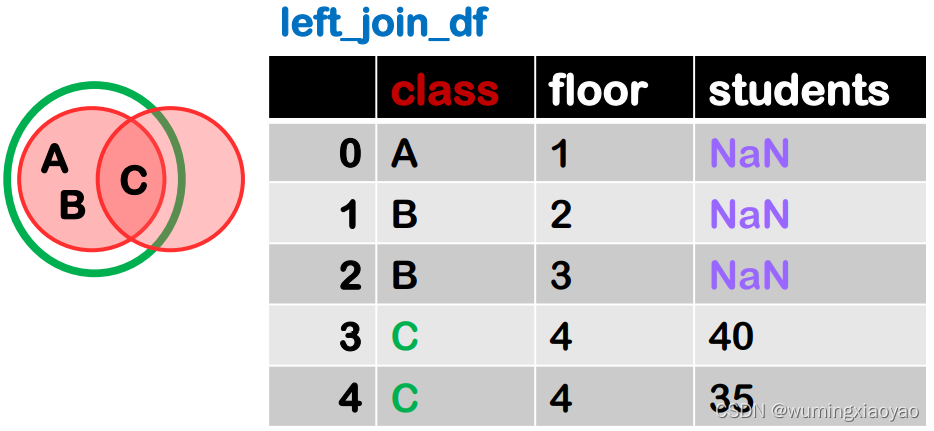
left join merge 左连接
左连接,左边表格的键为基准进行配对,如果左边表格中的键在右边不存在,则用缺失值NaN填充
下面两张表,相同的列名 class 就是默认的主键,对应 class 列左表所有的值就是 A B C
将左边对应键 “class” 列的值跟右边拼接起来,如果对应右边的值不存,则用 NaN 填充.
下面语句是等价的:
pd.merge(df1, df2, how=‘left’)
df1.merge(df1, how=‘left’)
pd.merge(df1, df2, how=‘left’, on=‘class’)
df1.merge(df1, how=‘left’, on=‘class’)
right join merge 右连接
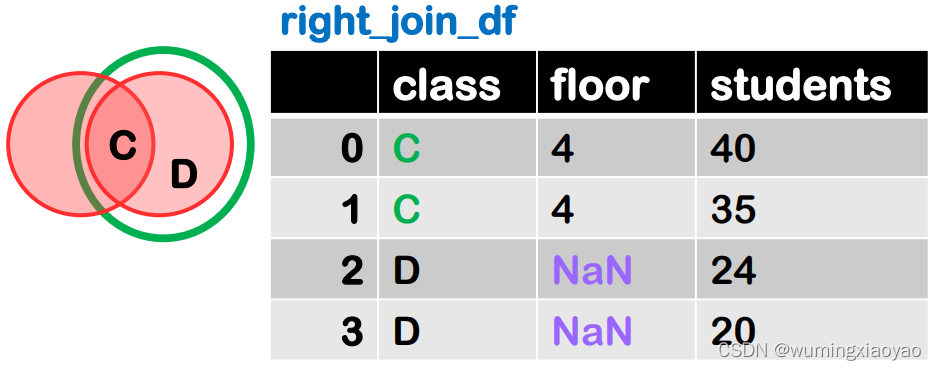
右连接,右边表格的键为基准进行配对,如果右边表格中的键在左边不存在,则用缺失值NaN填充
下面两张表,相同的列名 class 就是默认的主键,对应 class 列右表所有的值就是 C D
将右边对应键 “class” 列的值跟左边拼接起来,如果对应左边的值不存,则用 NaN 填充.
下面语句是等价的:
pd.merge(df1, df2, how=‘right’)
df1.merge(df1, how=‘right’)
pd.merge(df1, df2, how=‘right’, on=‘class’)
df1.merge(df1, how=‘right’, on=‘class’)
指定列名为键的 join merge
on 关键字
默认,表格之间相同的列名作为匹配的键 Key,当然也可以用 on= parameter 指定列名作为键 Key,parameter 可以是一个字符串,也可以是一个 list。采用默认不指定键 Key 的方式只适用于两个表格有相同名字的列。
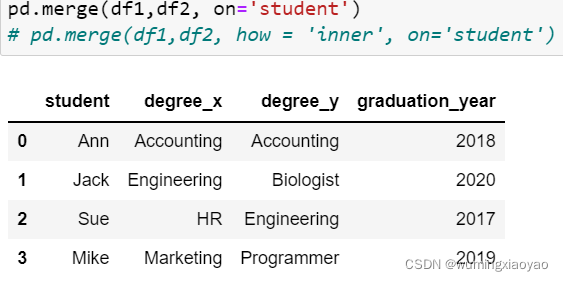
下面两个 DataFrame df1 和 df2. 有相同的列名 “student” 和 “degree”,默认这两个列名组合成键 Key。df1 和 df2 对应键的交集是 Ann Accounting

所以如果是默认的 merge,结果是这样的。这两条语句是等价的。
pd.merge (df1, df2)
pd.merge (df1, df2, how = ‘inner’, on=[‘student’,‘degree’])

但是如果指定 “Student” 列名为键 Key,结果又不一样了。df1 和 df2 对应键 “Student” 的交集是 Ann Jack Sue Mike
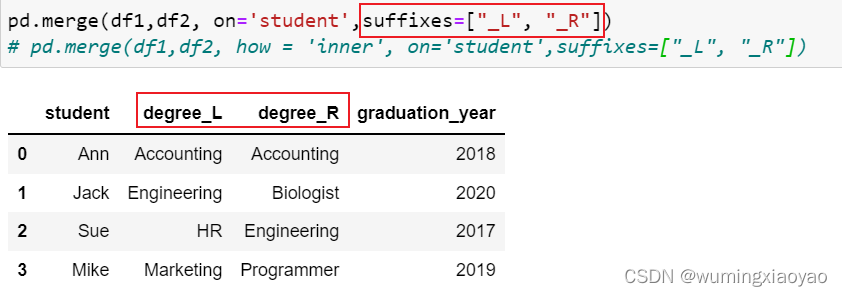
注意,因为 df1 和 df2 相同的列名 degree 有不同的值,为了区分,默认会加上 _x 和 _y 后缀。
当然也可以通过 suffixes 参数自定义后缀
代码:
import pandas as pd
# Default: Common column name(s(): 'degree' and 'student'
df1 = pd.DataFrame ({
'student':['Ann', 'Jack', 'Sue', 'Mike'],
'degree': ['Accounting', 'Engineering', 'HR', 'Marketing']})
df2 = pd.DataFrame ({
'student':[ 'Ann', 'Sue', 'Mike', 'Jack'],
'degree': ['Accounting', 'Engineering', 'Programmer', 'Biologist'],
'graduation_year': [2018, 2017, 2019, 2020]})
df_merge_default = pd.merge (df1, df2)
# df_merge_default = pd.merge (df1, df2, how = 'inner', on=['student','degree'])
df_merge_on_student = pd.merge(df1,df2, on='student')
# df_merge_on_student = pd.merge(df1,df2, how = 'inner', on='student')
df_merge_on_student_suffixes = pd.merge(df1, df2, on = 'student', suffixes=["_L", "_R"])
print("df1:\n{}".format(df1))
print("df2:\n{}".format(df2))
print("df_merge_default:\n{}".format(df_merge_default))
print("df_merge_on_student:\n{}".format(df_merge_on_student))
print("df_merge_on_student_suffixes:\n{}".format(df_merge_on_student_suffixes))
输出:
df1:
student degree
0 Ann Accounting
1 Jack Engineering
2 Sue HR
3 Mike Marketing
df2:
student degree graduation_year
0 Ann Accounting 2018
1 Sue Engineering 2017
2 Mike Programmer 2019
3 Jack Biologist 2020
df_merge_default:
student degree graduation_year
0 Ann Accounting 2018
df_merge_on_student:
student degree_x degree_y graduation_year
0 Ann Accounting Accounting 2018
1 Jack Engineering Biologist 2020
2 Sue HR Engineering 2017
3 Mike Marketing Programmer 2019
df_merge_on_student_suffixes:
student degree_L degree_R graduation_year
0 Ann Accounting Accounting 2018
1 Jack Engineering Biologist 2020
2 Sue HR Engineering 2017
3 Mike Marketing Programmer 2019
left_on 和 right_on 关键字
可能两个 DataFrame 的列名都不相同,但是值表达的是同一个意思(如:‘employee’ 和 ‘name’ 列名都表示的是员工名字),就要用到 left_on= 和 right_on= parameters 来指定匹配的列。还可以把多余的列删除掉。
如:df1 和 df2 列名都不相同,但是列名 employ 和 name 都是表示名字
df1 = pd.DataFrame ({
'employee':['Ann', 'Jack', 'Sue', 'Mike'],
'job_title': ['Accounting', 'Engineering', 'HR', 'Marketing']})
df2 = pd.DataFrame ({
'name':[ 'Ann', 'Sue', 'Mike', 'Jack'],
'salary': [55000, 95000, 37000, 48000]})
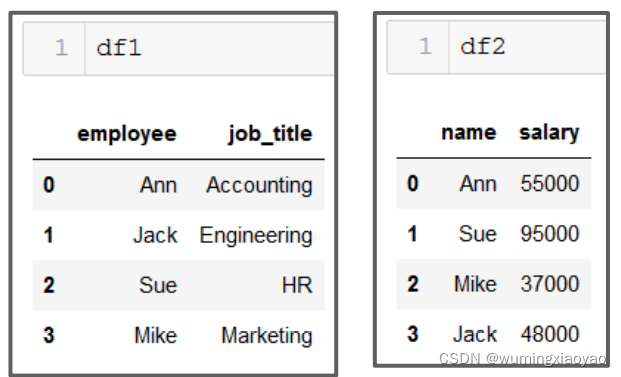
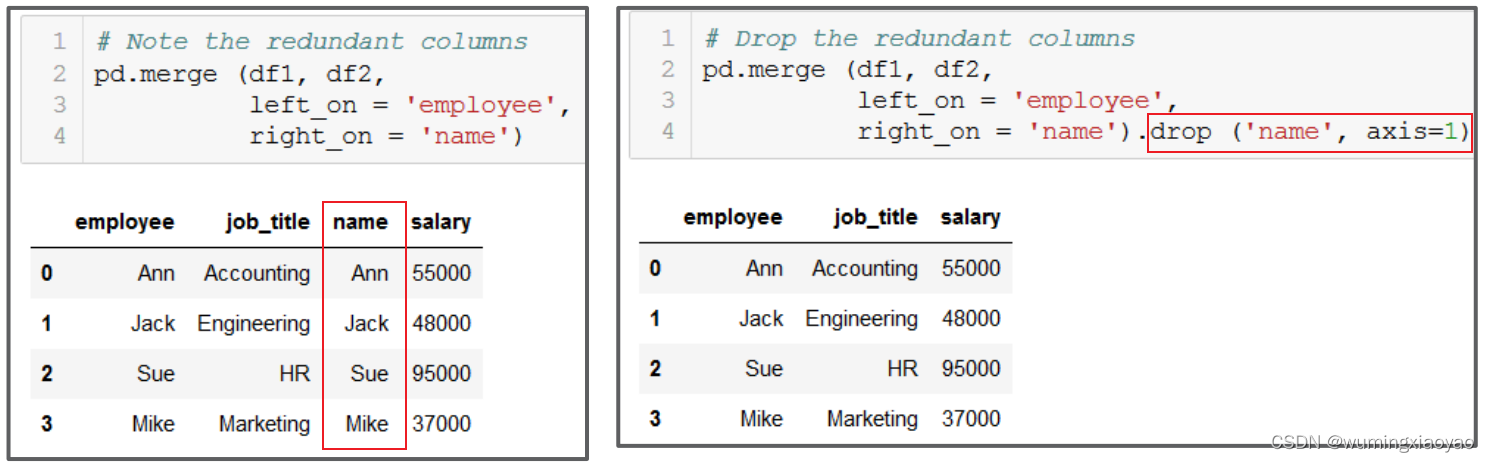
我们就可以分别指定 df1的 employ 和 df2 的 name 作为匹配的列。
pd.merge (df1, df2, left_on = 'employee', right_on = 'name')
pd.merge (df1, df2, left_on = 'employee', right_on = 'name').drop ('name', axis=1)
left_index 和 right_index 关键字
假设不仅仅是合并列,还想合并 index,就可以用 left_index=True 和 right_index=True parameter 使得 index 作为键 Key进行匹配合并。
df1 = pd.DataFrame ({
'employee':['Ann', 'Jack', 'Sue', 'Mike'],
'job_title': ['Accounting', 'Engineering', 'HR', 'Marketing']})
df2 = pd.DataFrame ({
'name':[ 'Ann', 'Sue', 'Mike', 'Jack'],
'salary': [55000, 95000, 37000, 48000]})
df1_index = df1.set_index('employee')
df2_index = df2.set_index('name')
下面两个 DataFrame 分别设置 employee 和 name 为 index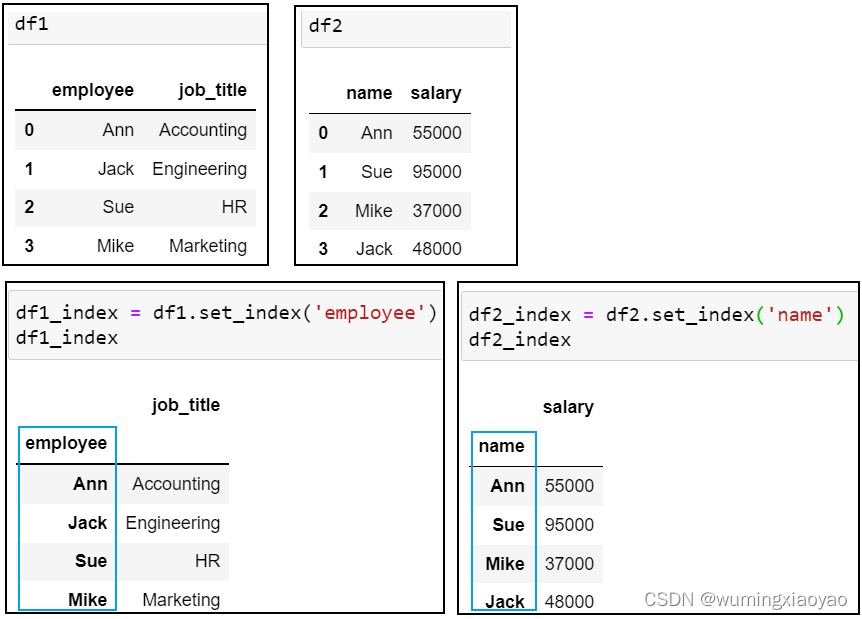
按 index 的交集合并:
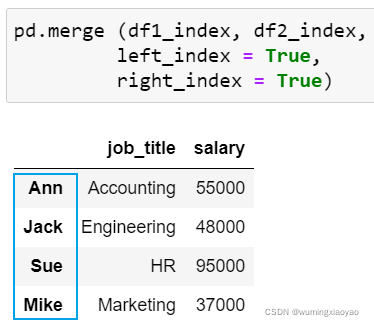
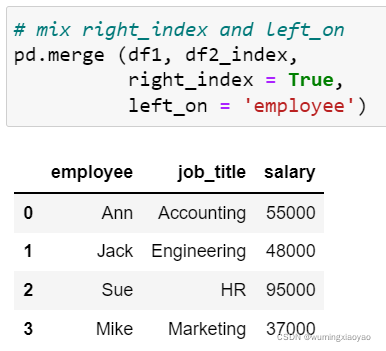
混合 left/right_index 和right/left_on 关键字
也可以混合 列和 index 作为键 Key 进行匹配合并,用 left_index = True 加上 right_on 或 right_index = True 加上 left_on。
下面两个 DataFrame 分别设置 employee 和 name 为 index
df1 = pd.DataFrame ({
'employee':['Ann', 'Jack', 'Sue', 'Mike'],
'job_title': ['Accounting', 'Engineering', 'HR', 'Marketing']})
df2 = pd.DataFrame ({
'name':[ 'Ann', 'Sue', 'Mike', 'Jack'],
'salary': [55000, 95000, 37000, 48000]})
df1_index = df1.set_index('employee')
df2_index = df2.set_index('name')
基于 index 和 column 为键 Key 合并
# mix left_index and right_on
pd.merge (df1_index, df2, left_index = True, right_on = 'name')
# mix right_index and left_on
pd.merge (df1, df2_index, right_index = True, left_on = 'employee')