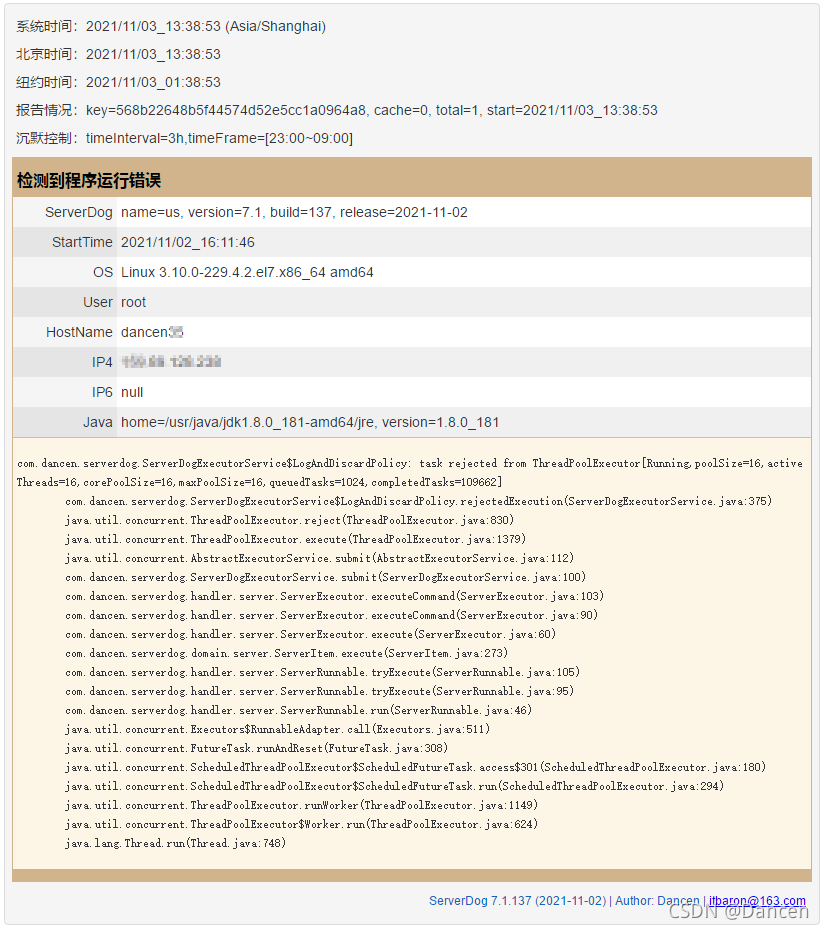
在服务器监控程序ServerDog运行过程中,偶尔收到过几次运行错误报告,报告内容为线程池已满,无法接收新任务:
造成线程池爆满的原因自然是某些线程执行耗时太久,一直占用线程池。
起初,我粗略估计造成这一问题的原因有以下可能:
1. ServerDog与远程服务器的ssh命令执行操作缺少超时设定。
2. ServerDog与远程服务器的ftp/sftp文件传输操作缺少超时设定。
鉴于此,我分别给ssh和ftp/sftp都增加了超时处理。
然而,今天,线程池已满的运行错误再次出现,看来问题并没有解决。
1. 查看JVM状态
保持已经报错的ServerDog处于运行状态,借助jstack将JVM的状态导出:
jstack [java pid] > jstack.txt2. 查看JVM状态报告
查看JVM报告可以发现很多线程处于阻塞状态,在等待获得锁:
"pool-1-thread-4" #40 prio=5 os_prio=0 tid=0x00007f6764015800 nid=0x370f waiting for monitor entry [0x00007f67b5137000]
java.lang.Thread.State: BLOCKED (on object monitor)
at ch.ethz.ssh2.Connection.connect(Connection.java:792)
- waiting to lock <0x00000000fef02a10> (a ch.ethz.ssh2.Connection$1TimeoutState)
- locked <0x00000000fef02940> (a ch.ethz.ssh2.Connection)
at com.dancen.util.ssh.ShellExecutor.getConnection(ShellExecutor.java:210)
可以初步推测程序中出现了死锁。在JVM报告的最后,果然报告了死锁:
Found one Java-level deadlock:
=============================
"Thread-53858":
waiting to lock monitor 0x00007f67640275d8 (object 0x00000000fef02940, a ch.ethz.ssh2.Connection),
which is held by "pool-1-thread-4"
"pool-1-thread-4":
waiting to lock monitor 0x00007f674c0042b8 (object 0x00000000fef02a10, a ch.ethz.ssh2.Connection$1TimeoutState),
which is held by "Thread-53858"
Java stack information for the threads listed above:
===================================================
"Thread-53858":
at ch.ethz.ssh2.Connection.close(Connection.java:603)
- waiting to lock <0x00000000fef02940> (a ch.ethz.ssh2.Connection)
at com.dancen.util.ssh.ShellExecutor.closeConnection(ShellExecutor.java:238)
at com.dancen.util.ssh.ShellExecutor.connectionLost(ShellExecutor.java:307)
at ch.ethz.ssh2.transport.TransportManager.close(TransportManager.java:250)
at ch.ethz.ssh2.transport.ClientTransportManager.close(ClientTransportManager.java:55)
at ch.ethz.ssh2.transport.TransportManager.close(TransportManager.java:183)
at ch.ethz.ssh2.Connection$1.run(Connection.java:744)
- locked <0x00000000fef02a10> (a ch.ethz.ssh2.Connection$1TimeoutState)
at ch.ethz.ssh2.util.TimeoutService$TimeoutThread.run(TimeoutService.java:86)
- locked <0x00000000e0a72168> (a java.util.LinkedList)
"pool-1-thread-4":
at ch.ethz.ssh2.Connection.connect(Connection.java:792)
- waiting to lock <0x00000000fef02a10> (a ch.ethz.ssh2.Connection$1TimeoutState)
- locked <0x00000000fef02940> (a ch.ethz.ssh2.Connection)
at com.dancen.util.ssh.ShellExecutor.getConnection(ShellExecutor.java:210)
at com.dancen.serverdog.handler.command.CommandRunnable.getConnection(CommandRunnable.java:172)
at com.dancen.serverdog.handler.command.CommandRunnable.execute(CommandRunnable.java:92)
at com.dancen.serverdog.handler.common.ExecuteRunnable.run(ExecuteRunnable.java:84)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Found 1 deadlock.
3. 找到死锁原因
从JVM报告可以看出死锁发生在Java的ssh操作依赖包:Ganymed SSH2 For Java。
Connection.close()
和
Connection.connect()
两个方法相互等待锁,形成了死锁。
为什么会发生这种现象呢,查看其源码,理清一下执行逻辑:
执行Connection.connect()
1. 锁住Connection
2. 启动超时处理服务TimeoutService
2.1. 锁住TimeoutState
2.2. 如果超时,关闭TransportManager
1). 通知Connection的监视器ConnectionMonitor连接断开,ConnectionMonitor执行connectionLost()
2.3. 释放TimeoutState锁
3. 与服务器建立连接
4. 锁住TimeoutState
5. 取消超时处理服务TimeoutService
6. 释放TimeoutState锁
7. 释放Connection锁
这个逻辑是没毛病的,问题的症结在于ConnectionMonitor的connectionLost()的实现。ConnectionMonitor是Connection的监视器接口,用于接收Connection的断开消息。
对于Connection来说,如果客户端主动断开自不必说,我们可以知道连接已经断开;如果是服务端主动断开,或者由于其它网络因素导致连接被动断开,则在Ganymed SSH2 For Java的外部,是不知道Connection已经断开的,因此需要依赖向Connection注册ConnectionMonitor来接收Connection断开的消息。
问题在于,Ganymed SSH2 For Java在检测到Connection已经断开时,会向已经注册的ConnectionMonitor发出断开消息,但其自身并没有合理地清理Connection的连接状态。因此,在ConnectionMonitor的实现方法connectionLost()中,我手动执行了Connection.close(),已重置Connection的连接状态。于是,逻辑变成了:
执行Connection.connect()
1. 锁住Connection
2. 启动超时处理服务TimeoutService
2.1. 锁住TimeoutState
2.2. 如果超时,关闭TransportManager
1). 通知Connection的监视器ConnectionMonitor连接断开,ConnectionMonitor执行connectionLost()
A. ConnectionMonitor在connectionLost()中执行Connection.close()
a. 锁住Connection
b. 关闭与服务器的连接
c. 释放Connection锁
2.3. 释放TimeoutState锁
3. 与服务器建立连接
4. 锁住TimeoutState
5. 取消超时处理服务TimeoutService
6. 释放TimeoutState锁
7. 释放Connection锁
现在问题就可以解释清楚了,当Connection.connect()在发生超时的情况时,就有一定的概率发生以下情况:
1. Connection.connect()操作获取了Connection锁,启动超时处理线程TimeoutService,并在准备获取TimeoutState锁;
2. TimeoutService执行超时处理,获得了TimeoutState锁,并通过ConnectionMonitor执行connectionLost,调用Connection.close(),该方法需要获取Connection锁。
如此,就发生了死锁:
1. Connection.connect()获取了Connection锁,并等待TimeoutState锁。
2. ConnectionMonitor.connectionLost()获取了TimeoutState锁,并等待Connection锁。
4. 解决方案
不能在
ConnectionMonitor.connectionLost()
中执行
Connection.close()
请通过其它办法处理Connection的连接状态问题。