如何进行堆排序?
排序算法有很多种,比如冒泡、选择、插入归并等等,今天要给大家介绍的称之为 “堆排序” (heap sort),它是一种通过 “堆” 这个数据结构进行排序的方法,完成这个算法需要两个步骤,首先是将乱序数组转换成一个堆,然后对这个堆进行排序操作,这个算法由John William博士在1964年首先提出。
约翰·威廉·约瑟夫·威廉姆斯 (1930年9月2日 – 2012年9月29日)是一位加拿大计算机科学家,以1964年发明二叉堆数据结构和堆排序而闻名 。他出生于 奇彭纳姆, 威尔特郡并在加拿大度过了职业生涯的后半段。
✤ 前置基础知识
堆排序,顾名思义,首先我们需要建立一个”堆“。那么,什么又是 “堆” 呢? 堆是一种特殊的二叉树结构,而二叉树又是一种数据结构,这里只简单说一下定义:
✧ 二叉树
二叉树(英语:Binary tree)是每个节点最多只有两个分支(即不存在分支度大于2的节点)的树结构。通常分支被称作“左子树”或“右子树”。
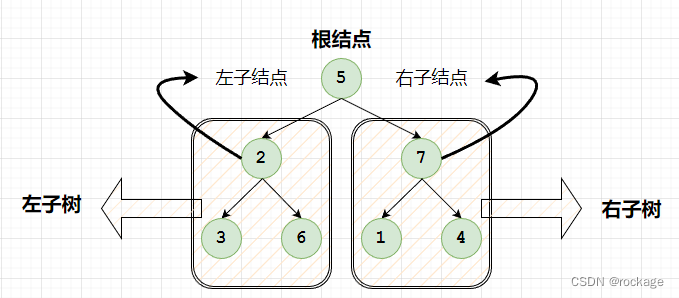
为了方便叙述,上例是一个 “满二叉树” 。事实上,只要满足每个节点不超过两个分支这个条件,以下结构也符合“二叉树”的定义:

那么,上图这种二叉树能不能称为“堆”呢?答案是否定的,因为要成为“堆”,还需要一些额外的条件。
✧ 堆(Heap),是一种特别的二叉树
它需要满足以下条件, 首先是从结构而言:
-
除了最后一行之外,任何一行都必须完整填满;
-
最后一行,须满足从左到右依次填充,中间不允许有空缺,比如:
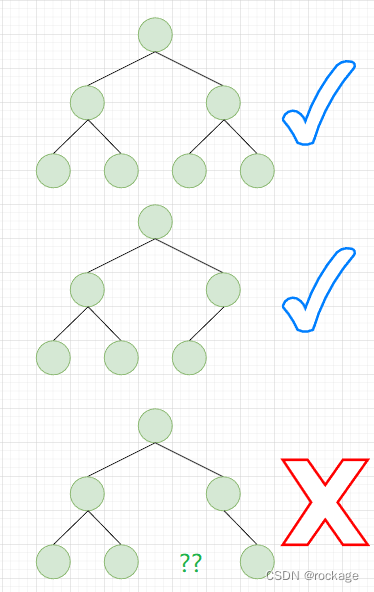
如上图,第1、2个二叉树可以称为 “完全二叉树”, 而第3个则不是,因为最后一行出现了空缺。思考一下,为什么必须是完全二叉树才能称之为堆呢?
因为只有这种“完全二叉树”才能将数据映射到一个一维数组上,如果二叉树中出现了不连续的空节点,则无法映射到一个一维数组上了。
除了结构上必须满足上述要求外,对于节点的值也有要求,一个 “堆” 还必须满足以下两种”堆序性“:
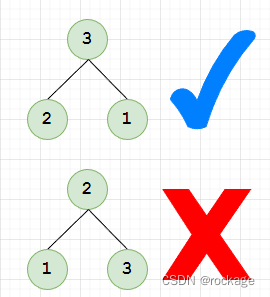
- 大根堆:任何父节点的值必须大于或等于其子节点的值,如图:
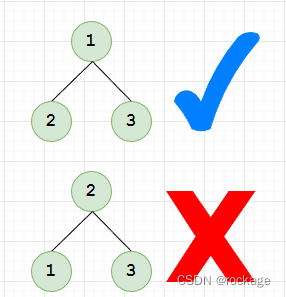
- 小根堆:任何父节点的值必须小于或等于其子节点的值,如图:
✧ 堆的基本操作 (以大根堆为例)
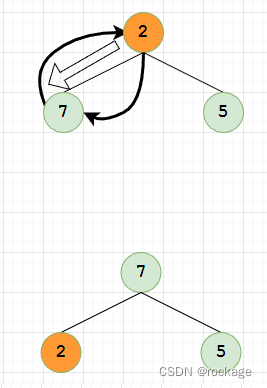
- 下滤 (Percolate Down)
操作一个子树的根节点,与其左右两个子节点相对比,如不满足堆序性则交换,因为方向是从上往下,所以被称为下滤。
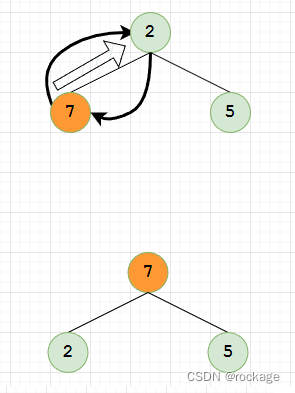
- 上滤(Percolate Up)
操作一个子树中的任何一个子节点,与其根节点相对比,如不满足堆序性则交换,方向是从下往上,因此称为上滤。
两种方法结果完全一样,作用都是让一个二叉树符合 “堆序性”。区别是下滤操作的是父节点,而上滤则是子节点。尽管两者乍看上去没有什么不同,但是在接下来我们在讲述 “建堆” 这个环节的时候,你会发现这两种操作的区别。
✤ 建堆 (Build Heap)
所谓建堆,就是将一个一维数组映射到一个堆上。我们前面说过,一维数组本质上就是一个完全二叉树。因此,只需要调整这个一维数组的顺序,让其值符合其 ”堆序性“ 的要求,也就完成了建堆操作。PS: 建堆可以是建立一个”大根堆“,也可以建立一个”小根堆“,下面谈及 ”建堆“ 的例子都是指 ”大根堆“ 。
✧ 1. 用 ”上滤法“ 建堆
现有一个乱序的一维数组: tree = [3, 2, 1, 5, 6, 4]
将之映射为一个完全二叉树,如图:
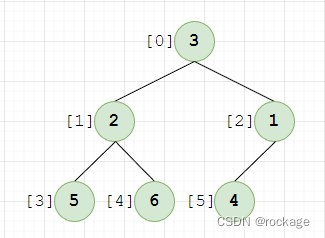
方括号里的编号对应的是原一维数组的下标。注意,此时我们还不能称其为一个”堆“,尽管结构上满足了堆的要求,但是每个节点的值并没有符合 ”堆序性“,现在开始调整:
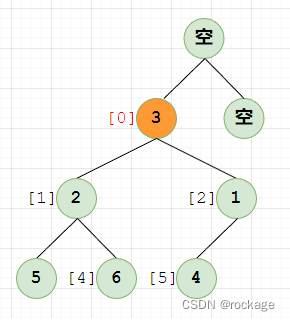
我们从编号为0这个节点(值=3)开始。这里需要特别注意,用上滤法进行建堆,总是将当前节点视为子节点代入子树中进行操作的,因此就有可能会产生找不到父节点的情况出现。这时我们直接忽略,然后继续操作:
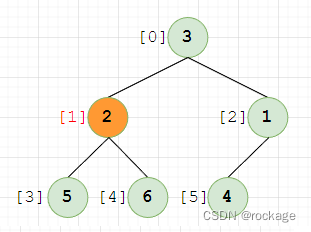
现在,下标递增到1这个节点(值=2),与其父节点(编号=0,值=3)做对比,2 < 3 ,符合堆序性,无需调整,继续操作:
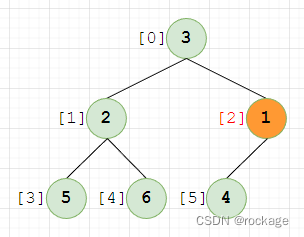
下标递增到2这个节点(值=1),与父节点做对比,1 < 3,也符合堆序性,无需调整,继续操作:
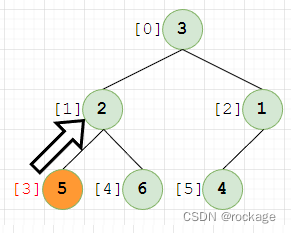
下标递增到3,节点值=5,与父节点(下标=1,值=2)做对比,5 > 2 ,不满足大根堆的堆序性,需要进行交换,交换完毕后变成了这样:
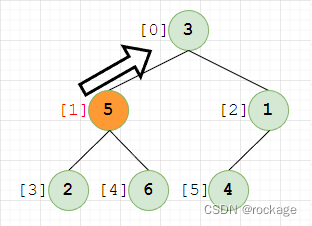
因为上一步产生了交换,整个树的堆序性也发生了改变,我们必须将交换后的值与前面的节点进行对比,才能确定其堆序性。现在,将当前节点(下标=1,值=5)作为一个子节点,与其父节点(下标=0,值=3)做对比,5 > 3,不符合堆序性,还得继续上移:
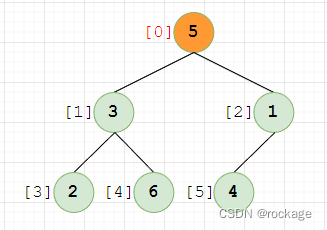
当前下标=0,值=5这个节点此时已经到达树的顶部,是整个树的根节点,已无法上移,我们直接略过,继续推进主循环:
注意:之前在下标推进到3的时候,发生了一次交换,一旦发生交换我们都需要将这个节点继续往上推动与上一层的父节点做对比,直到符合堆序性或者推到顶部为止。完成了这个操作后,我们返回主循环,继续检索下一个节点,直至遍历完整个数组。
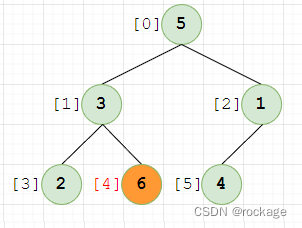
下标增加到4,值=6这个节点,又不符合堆序性了,需要和父节点(下标=1,值=3)做交换,限于篇幅,因为处理方法和之前讲述的完全一样,下面开始直接放图,不浪费口舌了:
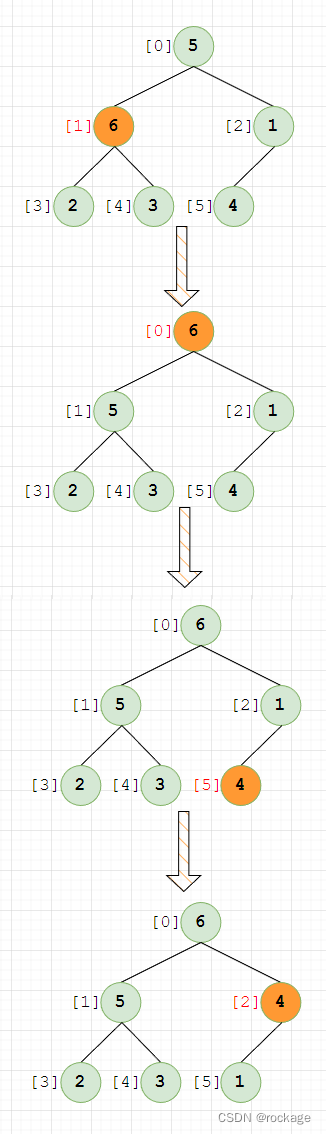
至此,我们就用上滤法完成了建堆操作,观察最后的结果,每一个父节点的值都大于其左右两个子节点的值,因此我们称这种堆为 ”大根堆“。
代码如下:
package main
import (
"fmt"
)
func percolate_up(tree []int, size int, child_node int) {
parent_node := (child_node - 1) / 2 // 父节点
left_node := 2*parent_node + 1 // 左子节点
right_node := 2*parent_node + 2 // 右子节点
var max_node = parent_node
// 如果左子节点存在且值大于父节点:
if left_node <= size && tree[left_node] > tree[parent_node] {
max_node = left_node
}
// 如果右子节点存在且值大于父节点:
if right_node <= size && tree[right_node] > tree[max_node] {
max_node = right_node
}
// 如果最大节点不是原父节点(需要进行数据交换)
if max_node != parent_node {
tree[parent_node], tree[max_node] = tree[max_node], tree[parent_node]
// 以当前父节点出发,继续向上递归执行上滤
percolate_up(tree, size, parent_node)
}
}
func main() {
var tree = []int{
3, 2, 1, 5, 6, 4}
var n = len(tree) - 1
for i := 0; i <= n; i++ {
// 遍历整个数组
percolate_up(tree, n, i) // 每个元素都进行一次上滤操作
}
fmt.Println(tree)
}
上面这段代码演示了用上滤法进行建堆操作的流程,逻辑还是比较简单。
已知一个子节点的下标的 n,无论左右,其父节点下标为:int (( n-1) / 2):
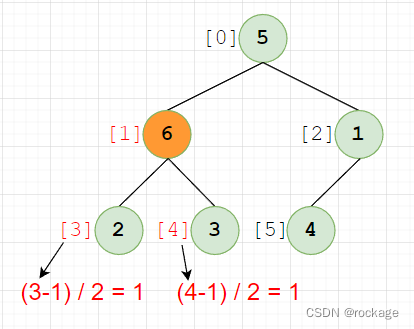
同理,已知一个父节点的下标 i ,很容易推出左右子节点的下标:
左子节点: 2 * i + 1
右子节点: 2 * i + 2
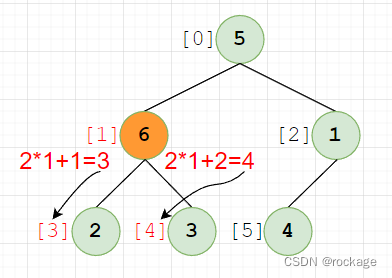
尽管现在完成了堆的建立,但是并没有完成排序。必须明确一个清晰的概念,建堆不等于排序,建堆只是让数据局部满足排序要求,整体而言数据还是无序的。
讲完建堆,按理说现在应该讲讲如何进行堆排序,但是别忘了之前我们还提到过另外一种建堆方法:下滤法。
✧ 1. 用 ”下滤法“ 建堆
使用下滤法建堆,最大的优势是效率较高,下面我们还是以 tree = [3, 2, 1, 5, 6, 4] 为例,看看下滤法是怎么工作的。
注意:所谓上滤法和下滤法,最大的区别就是操作的节点对象不同,上滤法每次操作的是子节点,而下滤法则是父节点。现在,还是和上例一样的数据开始分析吧:
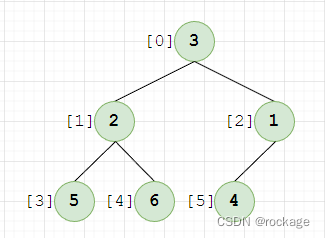
这次,我们并不是从数组的第一个元素开始,而是从最后一个子树,由节点【1】【4】组成,父节点(下标=2) < 4 ,不符合堆序性,现在我们需要将1和4的位置交换:
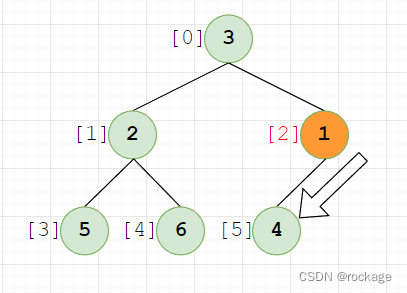
因为发生了数据交换,节点(值=1)还需要在下标[5]这个位置做一次递归调用,看看自己是不是当前子树下的老大:
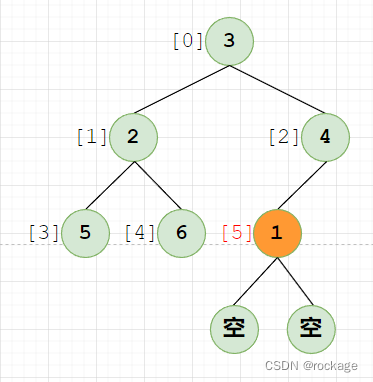
但是显然,已经不存在什么子树了,因为节点【1】已经是处于树的最底部,无法再下探。接着,我们来处理倒数第二个子树,即由节点【2】【5】【6】组成的这个子树,父节点(值=2)(下标=1):
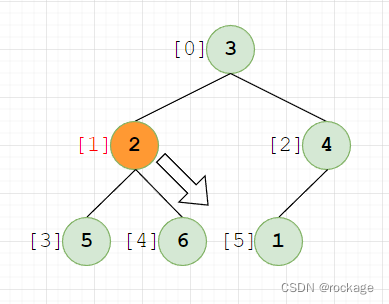
发现2 < 6 ,需要2和6需要交换位置,同理当2到达底部后,已是最后一行,无法再下探(这里就不再画图了)。回到主循环,处理子树:【3】【6】【4】,父节点(值=3)(下标=0),经过对比后,发现 3 < 6 需要和6交换位置:
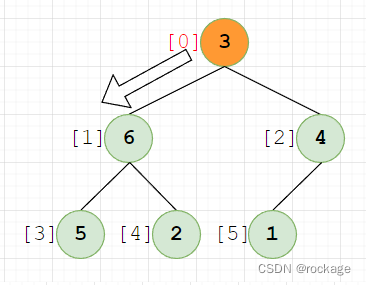
当节点【3】下调交换后,将它视为一个父节点,则又组成了一个新子树:【3】【5】【2】
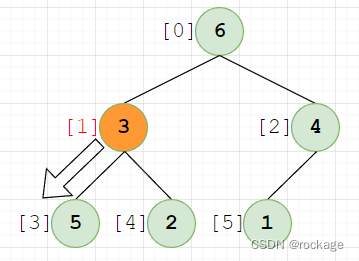
此时,再做一次对比,发现 3 < 5,需要与5做交换:
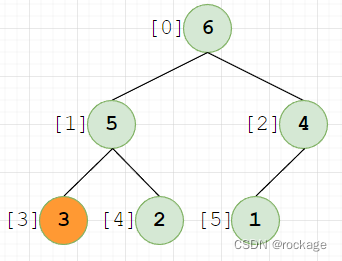
节点【3】已经达到最底部,无法再下探,此时整个建堆的过程也完成了。仔细观察,每一个父节点都比其子节点要大,所以满足了大根堆的条件。
用下滤法建堆的代码如下:
package main
import (
"fmt"
)
// 下滤建堆:
func percolate_down(tree []int, size int, parent_node int) {
left_node := 2*parent_node + 1 // 左子节点
right_node := 2*parent_node + 2 // 右子节点
// 找出最大节点
var max_node = parent_node
if left_node <= size && tree[left_node] > tree[parent_node] {
max_node = left_node
}
if right_node <= size && tree[right_node] > tree[max_node] {
max_node = right_node
}
if max_node != parent_node {
// 交换节点的值:
tree[parent_node], tree[max_node] = tree[max_node], tree[parent_node]
// 以当前值最大的子节点出发,继续向下递归执行下滤
percolate_down(tree, size, max_node)
}
}
func main() {
var tree = []int{
3, 2, 1, 5, 6, 4}
var n = len(tree) - 1
// 注意:(n-1)/2 总是为父节点
for i := (n - 1) / 2; i >= 0; i-- {
percolate_up(tree, n, i)
}
fmt.Println(tree)
}
通过流程分析可以看出,下滤的效率是要优于上滤的,同样的数据,上滤需要11个步骤才能整理完成,而下滤法只需要6步。
最后,思考一下为什么上滤法中,递归函数是这样调用的:
percolate_up(tree, size, parent_node)而下滤法是这样的:
percolate_down(tree, size, max_node)
因为前面说过,上滤是将操作节点视为子节点,因此如果发生了数据交换,较大的那个就是父节点(parent_node),下滤则相反,因为操作节点总是被视为父节点,因此如果发生了交换,较大值则一定是左右两个子节点的其中一个(也就是max_node),所以两种方法在进行递归调用的时候,出发位置是不同的。
✤ 堆排序(Heap Sort)
前面曾经提过,一维数组相当于一个完全二叉树,而一个完全二叉树还并不是堆,必须让父节点和子节点的值符合堆序性,才能称之为堆。而将一个乱序的一维数组转换为一个符合堆序性的一维数组的过程,则称为建堆。建堆有两种方法,上滤法和下滤法。
好了,一个堆建立完成后,对它进行排序操作就比较简单了。前面说过,一个大根堆,其最大值一定是最上层的根元素,那么,我们只需要将它与数组的最后一位互换,然后将换上去的节点做下滤操作。反复这个过程,不就相当于排序了吗?
现在来看看我们之前处理好的堆:
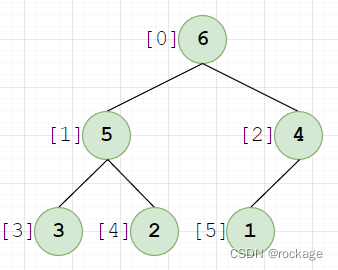
现在,我们将堆顶的根元素【6(下标为0)】,与最后一个元素【1(下标为5)】互换,变成了:
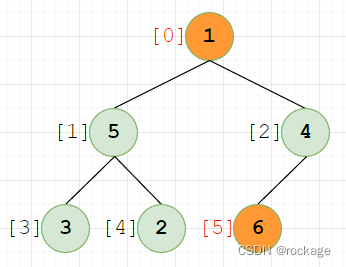
现在,将最大值【6】移出数组,对刚才交换上去的【1】进行下滤操作:
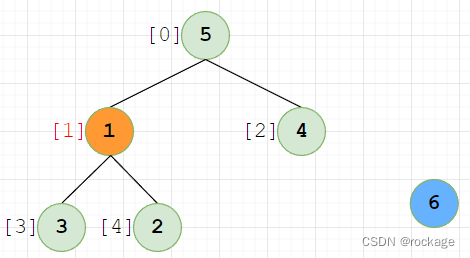
【1】下移之后,新形成的子树【1】【3】【2】还是不符合堆序性,【1】还得下调:
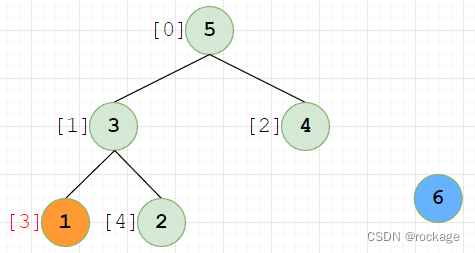
【1】已到最后一行,无法下调,现在回到主循环,将顶层元素【5】与最后一个元素【2】交换位置。因为逻辑与前面完全一样,下面的流程很容易理解。我只放图,不做文字讲解了:

完整代码如下:
package main
import (
"fmt"
)
// 下滤
func percolate_down(tree []int, size int, parent_node int) {
left_node := 2*parent_node + 1
right_node := 2*parent_node + 2
var max_node = parent_node
if left_node <= size && tree[left_node] > tree[parent_node] {
max_node = left_node
}
if right_node <= size && tree[right_node] > tree[max_node] {
max_node = right_node
}
if max_node != parent_node {
tree[parent_node], tree[max_node] = tree[max_node], tree[parent_node]
percolate_down(tree, size, max_node)
}
}
// 上滤
func percolate_up(tree []int, size int, child_node int) {
parent_node := (child_node - 1) / 2
left_node := 2*parent_node + 1
right_node := 2*parent_node + 2
var max_node = parent_node
if left_node <= size && tree[left_node] > tree[parent_node] {
max_node = left_node
}
if right_node <= size && tree[right_node] > tree[max_node] {
max_node = right_node
}
if max_node != parent_node {
tree[parent_node], tree[max_node] = tree[max_node], tree[parent_node]
percolate_up(tree, size, parent_node)
}
}
func main() {
var tree = []int{
3, 2, 1, 5, 6, 4}
var n = len(tree) - 1
// 两种建堆(heapify)法,效果一样,但方法2效率更高
// 方法1:上滤(percolate_up)
for i := 0; i <= n; i++ {
percolate_up(tree, n, i)
}
// 方法2:下滤(percolate_down)
for i := (n - 1) / 2; i >= 0; i-- {
percolate_down(tree, n, i)
}
// 堆排序heap sort:
for i := n; i >= 0; i-- {
// 首先将根节点与最后一个节点互换
tree[0], tree[i] = tree[i], tree[0]
// 然后再将根节点做一次下滤
percolate_down(tree, i-1, 0)
}
fmt.Println(tree)
}
✤ 后记
如果你坚持看到了这里,那么理解上面那段代码应该是不费吹灰之力的,尽管堆排序比起其他更直观的排序算法显得很麻烦,而且实际在数据量不大的情况下测试下来效率也不算高。其优势必须在数据量很大的时候才能显现出来,即便如此,通过学习堆这种数据结构,还是很有趣的。最后祝您刷题愉快,欢迎留言拍砖斧正!