文章目录
通过套接字进行单机管理
可以在mon或者osd节点通过ceph命令进行单机管理本机的mon或osd服务
节点上需要存在keyring认证文件
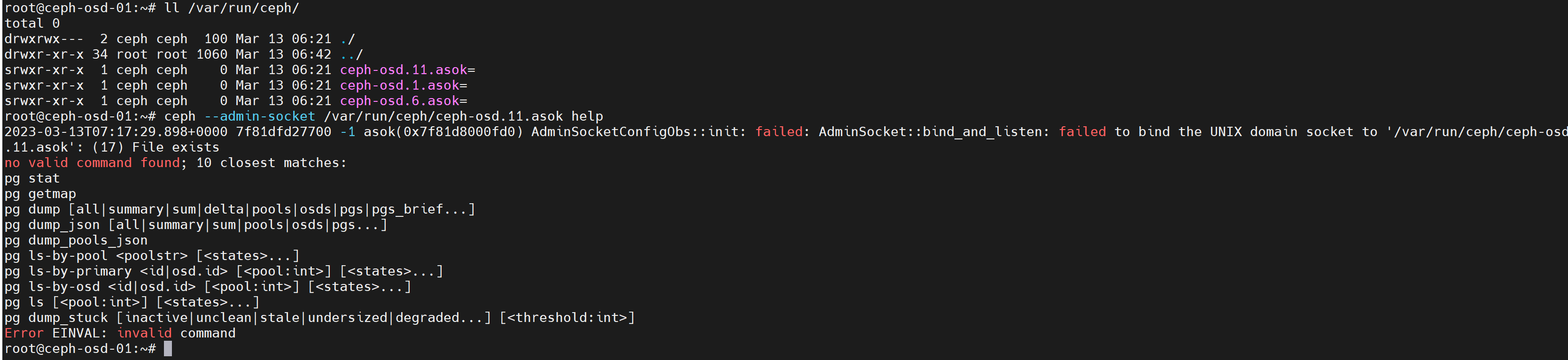
#通过socket文件连接osd服务,执行操作
ceph --admin-socket /var/run/ceph/ceph-osd.11.asok help #帮查看助
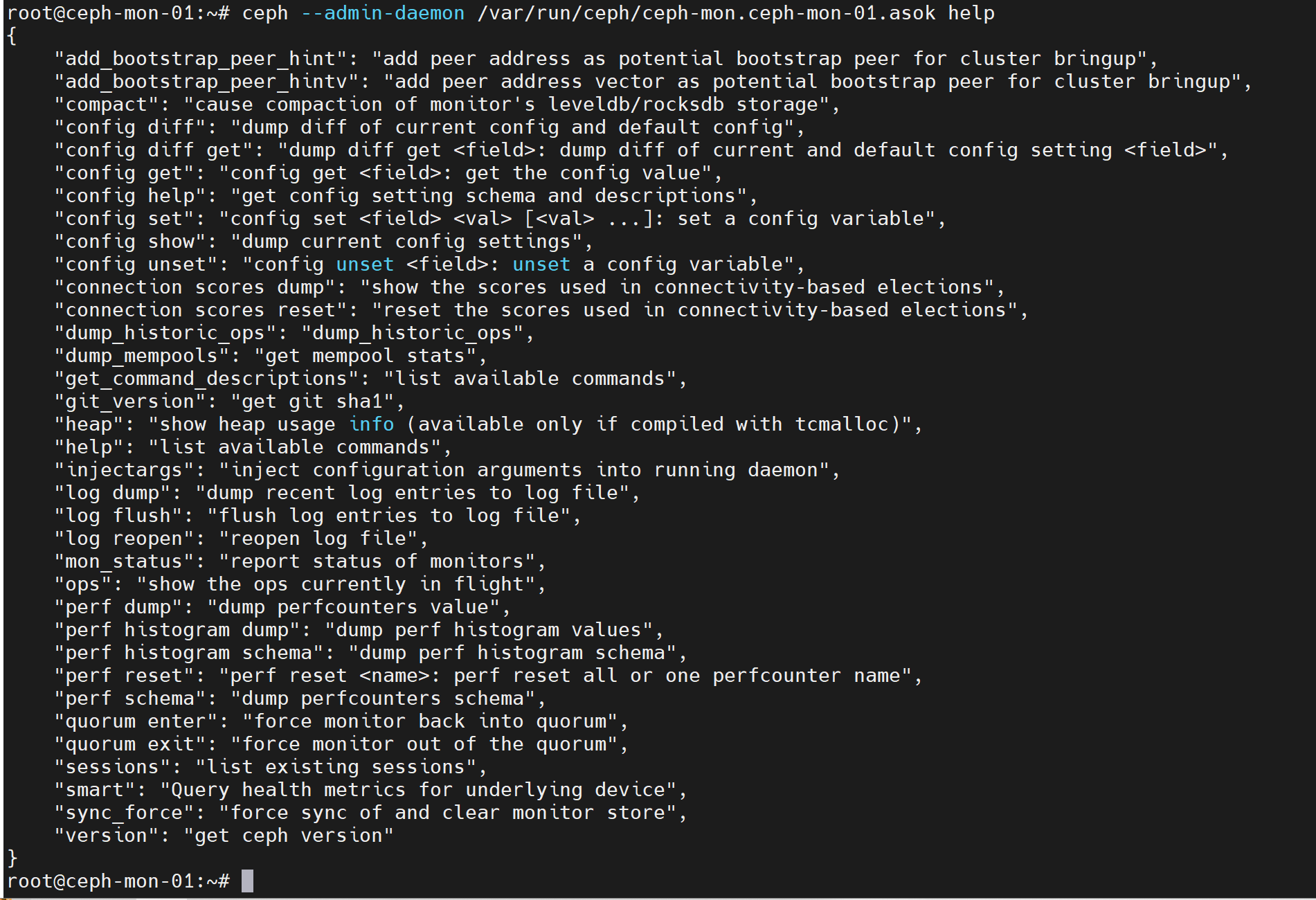
--admin-daemon #在mon节点通过socket文件获取daemon服务帮助
ceph --admin-daemon /var/run/ceph/ceph-mon.ceph-mon-01.asok help #查看帮助
ceph --admin-daemon /var/run/ceph/ceph-mon.ceph-mon-01.asok config show #查看配置信息
集群启停
关闭集群之前,要提前设置ceph集群不要将osd标记为out,避免节点关闭之后osd状态转变为out产生数据迁移
ceph osd set noout #关闭集群前设置noout
ceph osd unset noout #集群启动后取消noout
集群关闭顺序:
- 关闭集群前设置noout标记
- 关闭存储客户端,停止读写数据
- 如果使用了RGW,关闭RGW
- 关闭cephfs元数据服务
- 关闭osd
- 关闭mgr
- 关闭mon
集群启动顺序:
- 启动mon
- 启动mgr
- 启动osd
- 启动mds
- 启动rgw服务
- 启动存储客户端
- 取消noout标记
移除节点
移除节点之前,要逐个把节点上的osd停止并从ceph集群删除。具体步骤可以参考如下:
- 设置osd为out,然后等待数据迁移完成
- 节点上停止osd进程
- 从集群中删除所有待移除节点上的osd,ceph osd purge
- 待移除主机上的其它osd重复以上操作
- 全部操作完成后下线主机
- 从集群中删除该节点,ceph osd crush remove <node-name>
ceph配置文件
ceph的主要配置文件是/etc/ceph/ceph.conf,ceph服务在启动时会检查ceph.conf,分号;和#在配置文件中都表示注释。ceph.conf主要由以下配置段组成:
[global] #全局配置
[osd] #osd专用配置,可以使用osd.N来表示某一个osd专用配置,N为osd编号,如0、1、2等
[mon] #mon专用配置,可以使用mon.A来为某一个monitor节点做专用配置,其中A表示节点名称,例如ceph-mon-01,可以使用ceph mon dump获取到节点名称
[client] #客户端专用配置
ceph配置文件加载顺序:
- $CEPH_CONF环境变量指定的文件
- -c选项指定的文件
- /etc/ceph/ceph.conf
- ~/.ceph/ceph.conf 当前用户家目录下.ceph目录下的ceph.conf
- ./ceph.conf 当前目录下的ceph.conf
存储池分类
在ceph中,存储池有两种类型:副本池和纠删码池
- 副本池:replicated,定义每个对象在集群中保存为多个副本,默认为3个副本,副本池是默认的存储池类型
- 纠删码池:erasure code,把各对象分为N=K+M个块(chunk),其中K为数据块数量,M为编码块数量,因此存储池的总大小N=K+M。简单来说就是数据保存在K个数据块上,并提供M个冗余块提供数据高可用,那么最多能故障的块就是M个,实际的磁盘占用就是K+M块,因此相比副本池比较节省存储资源。一般采用8+4机制(默认2+2),即8个数据块+4个编码块,那么就是1/3的存储空间用于数据冗余,比副本池默认的3副本节省空间,但不能出现大于一定数据块的故障。需要注意,不是所有的应用都支持纠删码池,例如rbd只支持副本池,而rgw可以支持纠删码池
副本池IO
副本池将一个数据对象存储为多个副本
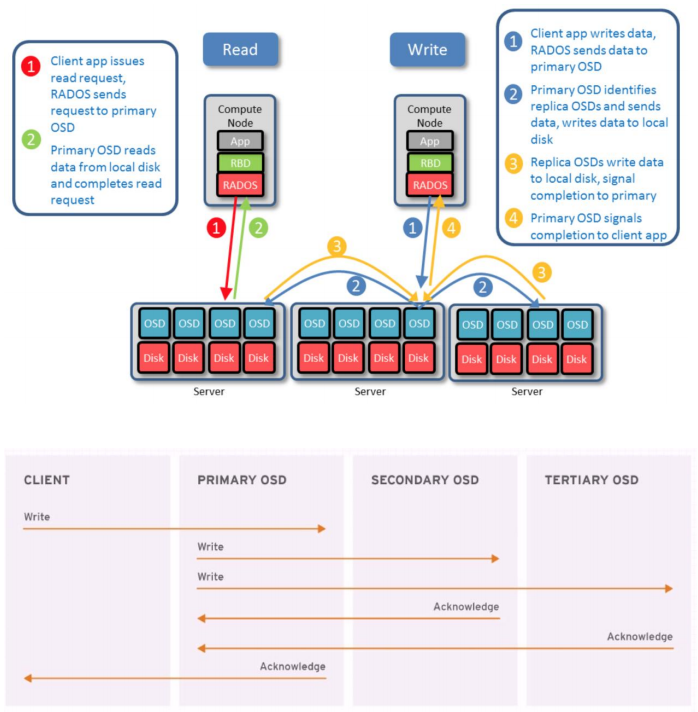
在客户端写入数据时,ceph使用CRUSH算法计算出对象所属的PG ID和PG对应的osd,然后向主osd写入数据,再由主osd将数据同步给辅助osd。
读取数据:
- 客户端向主osd发起读请求
- 主osd从本地磁盘读取数据并返回,最终完成读请求
写入数据:
- 客户端向主osd请求写入数据
- 主osd写入后,将数据发送至各辅助osd
- 辅助osd写入数据完成后,发送完成信号给主osd
- 主osd返回确认信息给客户端,完成写请求
纠删码池IO
ceph从F版本起开始支持纠删码,但不推荐在生产环境使用纠删码池。
纠删码池虽然降低了数据保存所需要占用的存储空间,但是读写数据占用的计算资源要比副本池高。
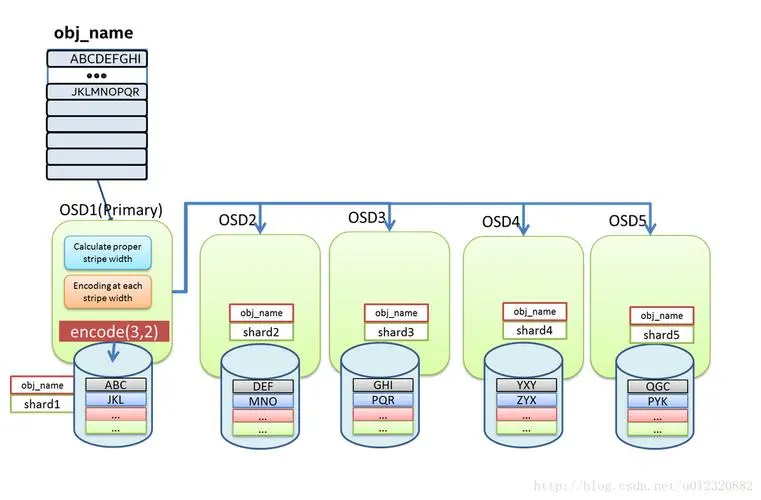
纠删码池写入数据:数据在主osd进行编码然后分发到相应的osd上
- 计算合适的数据块并进行编码
- 对每个数据块进行编码并写入osd
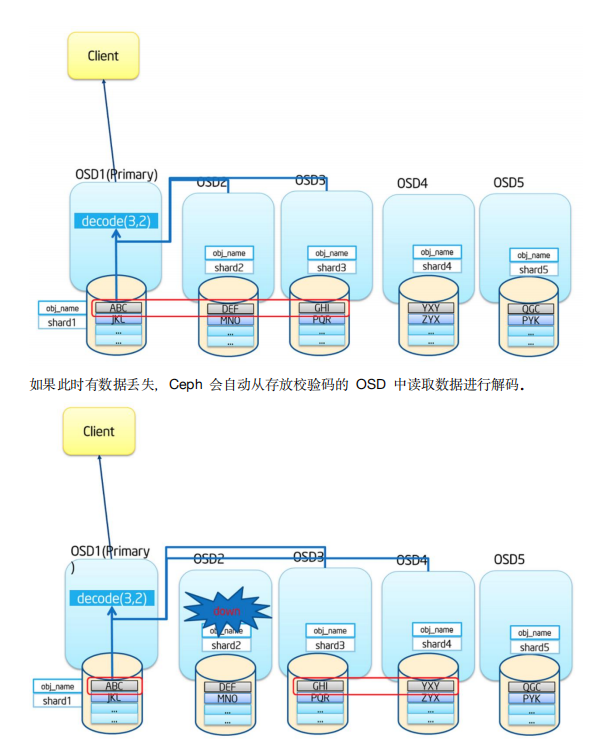
纠删码池读取数据:
1.从相应的osd中获取数据后进行解码
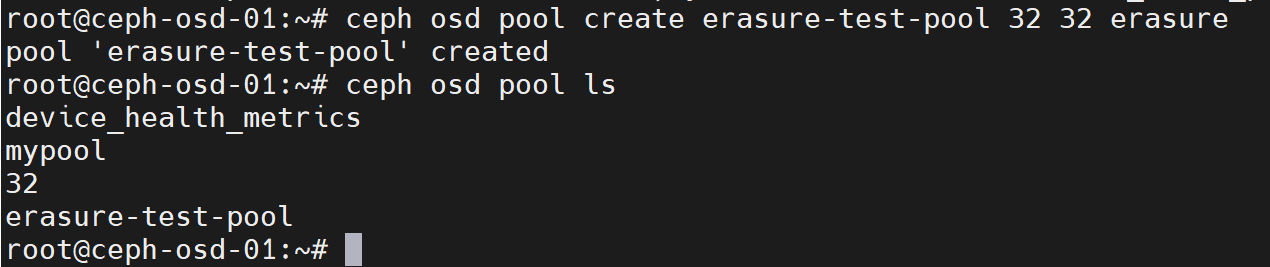
创建纠删码池
ceph osd pool create erasure-test-pool 32 32 erasure
查看默认的纠删码保存策略
ceph osd erasure-code-profile get default
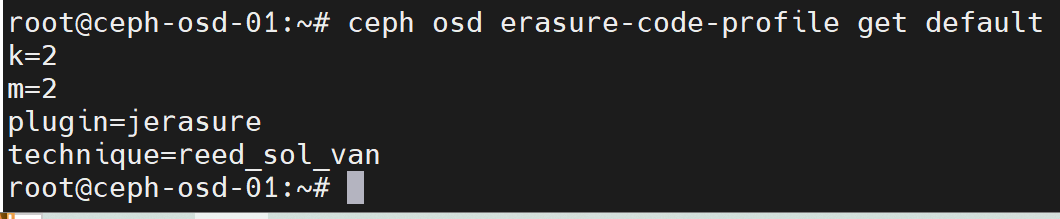
如上图,其中:
- k=2表示数据块的数量
- m=2表示编码块的数量
- plugin=jerasure 默认的纠删码池插件
验证数据的存储方式
rados put testfile /var/log/syslog -p erasure-test-pool #上传测试对象
ceph osd map erasure-test-pool test-file #查看测试对象保存位置
rados get test-file ./a.log -p erasure-test-pool #下载测试对象

如上图所示,可以看到每个object所属的pg对应4个osd,其中两个保存数据块,另外两个保存编码块,正好是K+M
PG与PGP
PG表示归置组,PGP表示归置组的组合,pgp相当于pg对应osd的逻辑排列组合关系(不同的pg使用不同组合关系的osd)
例如创建存储池时设置PG=32 PGP=32,那么:存储池中有32个pg,pg会写入到有32中组合关系(pgp)的osd上。如下图:
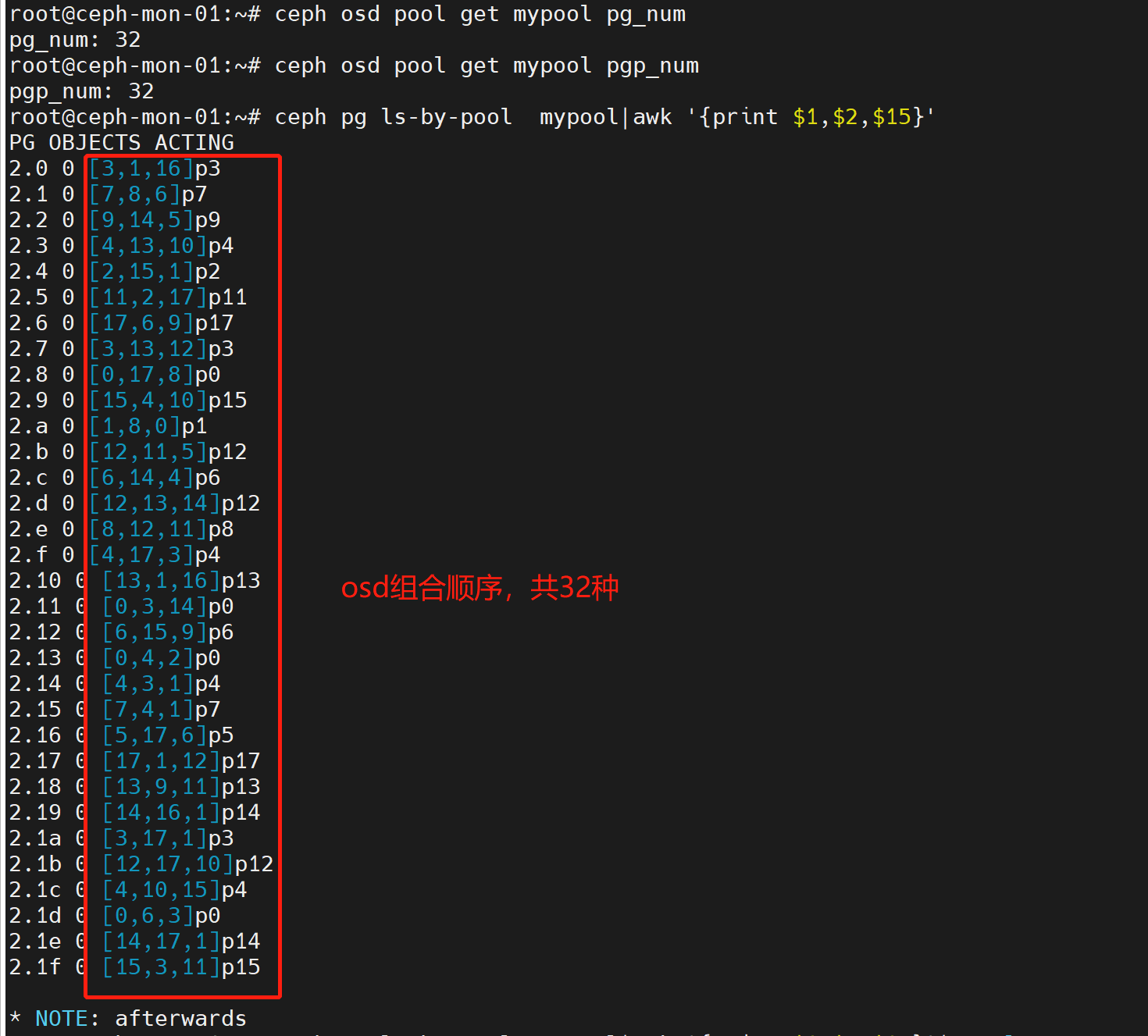
PG是用于跨osd将数据存储在每个存储池中的内部数据结构。它在osd和客户端之前生成了一个逻辑中间层,CRUSH算法负责将每个对象动态映射至一个PG,然后再将每个PG映射至一组osd,从而能够支持在新的osd设备上线时进行数据重新均衡。
可以自定义存储池中PG的数量。
ceph处于规模性伸缩及性能方面的考虑,将存储池分为多个PG,把对象映射到PG上,并为PG分配一个主osd。
存储池由一系列PG组成,而CRUSH算法则根据集群运行图和集群状态,将PG均匀的、伪随机(基于hash映射,每次的计算结果都一样)的分布到集群的osd之上。
如果单个OSD失败或需要对集群进行重新平衡,ceph只需要移动或复制PG即可,而不需要单独对每个对象进行操作。
为什么不直接将对象映射到osd,而是添加一个中间层PG?假设将object直接映射到osd,那么在osd出现故障后,需要对osd上的每个对象都重新计算存储位置,这会大量占用计算资源
PG数量计算
PG的数量是由管理员在创建存储池时指定的,然后由CRUSH负责创建和使用,PGd的梳理为2的N次方,每个osd上的PG不要超过250个,官方建议是每个osd上50-100个PG左右:https://docs.ceph.com/en/quincy/rados/operations/placement-groups/#choosing-the-number-of-placement-groups
通常,PG的数量应该是数据的合理粒度的子集。例如一个包含256个PG的存储池,每个PG包含大约1/256的存储池数据
当需要将PG从一个OSD移动到另一个OSD的时候,PG的数量会对性能产生影响。如果PG过少,每个PG承载的数据就会变多,那么ceph同步数据的时候产生的网络负载就会对集群性能输出产生一定影响。如果PG过多,ceph将会占用较多的计算资源来记录PG的状态信息。
在所有OSD之间进行数据持久存储以及完成数据分布会需要较多的归置组,但是它们的数量应该减少到实现ceph最大性能所需的最小PG数量值,以节省cpu和内存资源。
一般来说,对于有着超过50个OSD的集群,建议每个osd大约有50-100个PG以平衡资源使用及取得更好的数据持久性和数据分布,而在更大的集群上,每个OSD可以有100-200个PG。
集群中总的PG数量可以通过下面的公式进行计算,将得到的值四舍五入取最近的2的N次幂。
osd总数 ✖ 每个osd的PG数 ➗ 副本数量 => PG总数
例如:
集群有100个osd,每个osd计划承载100个PG,使用3副本,那么总的PG数量就等于
100 * 100 / 3 = 3333 ->向上取2的整次幂 = 4096
至于每个pool应该使用多少PG,应该根据pool所存储的数据占集群存储空间的比例来设置。
另外目前ceph支持根据存储池数据量自动调整存储池PG数量,可以参考官方文档进行设置:https://docs.ceph.com/en/quincy/rados/operations/placement-groups/#pg-autoscaler
PG常见状态
PG的常见状态如下:
-
Peering
正在同步状态,同一个PG中的osd需要将数据同步一致,而Peering就是osd同步过程中的状态
-
Activating
Peering已经完成,PG正在等待所有PG实例Peering的结果
-
Clean
干净态,PG当前不存在修复的对象,并且大小等于存储池的副本数,即PG的活动集(Acting Set)和上行集(Up Set)为同一组OSD且内容一致
什么是上行集和活动集?在某一个osd故障后,需要将故障的osd更换为可用的osd,并将PG所对应的主osd上的数据同步到新的osd上,例如刚开始pg对应osd1、osd2和osd3,当osd3故障后需要用osd4替换osd3,那么osd1、osd2、osd3就是上行集,替换后osd1、osd2、osd4就是活动集,osd替换完成后活动集最终要替换上行集,即活动集和上行集要保持一致
-
Active
就绪状态,Active表示主osd和备osd均处于正常状态,此时PG可以处理来自客户端的读写请求,正常的PG默认就是Active+Clean状态
-
Degraded
降级状态,一般出现于osd被标记为down之后,映射到此osd的PG都会转到降级状态。
如果此osd还能重新启动完成并完成Peering操作后,那么此osd上的PG会恢复为clean状态。
如果此osd被标记为down的时间超过5分钟还没恢复,那么此osd会被ceph标记为out,然后ceph会对被降级的PG启动恢复操作,直到因此osd故障而被降级的PG重新恢复为clean状态。
恢复数据会从PG所属的主osd恢复,如果是主osd故障,那么会在备用的osd中选择一个作为主osd。
-
Stable
过期状态,正常情况下每个主osd都要周期性的向mon报告其所持有PG的最新统计数据,因任何原因导致某个OSD无法正常向mon发送汇报信息的、或者由其它osd报告某个osd已经down的时候,则所有以此osd为主osd的PG会被标记为stable状态,即它们的主osd持有的已经不是最新数据了
-
undersized
PG当前副本数小于其存储池定义的值时,PG会转换为undersized状态
-
Scrubing
scrub是ceph对数据的清洗状态,用来保证数据完整性的机制,ceph的osd定期启动scrub线程来扫描部分PG,通过与其它副本比对来发现是否一致,如果存在不一致,抛出异常提示用户手动解决,scrub以PG为单位,对于每一个PG,ceph分析该PG中的所有object,产生一个类似于元数据信息摘要的数据结构,如对象大小、属性等,叫scrubmap,通过比较不同副本的scrubmap,来保证是不是有object丢失或不匹配,扫描分为轻量级扫描(light scrubs)和深度扫描(deep scrubs)。
轻量级扫描比较object-size和属性,深度扫描读取数据部分,并通过checksum算法对比数据的一致性,深度扫描过程中的PG会处于scrubing+deep状态
-
Recovering
正在恢复状态,集群正在执行迁移或同步PG它们的副本,这可能是由于添加了一个新的OSD到集群中或者某个osd故障后,PG可能被CRUSH算法重新分配到不同的osd上,而由于osd更换导致PG发生内部数据同步的过程中的PG会标记为Recovering
-
Backfilling
正在后台填充态,backfill是recovery的一种特殊场景,指peering完成后,如果基于当前权威日志无法对Up Set当中的某些PG实施增量同步(例如承载这些PG实例的osd离线太久,或者是新的osd加入集群导致的PG实例整体迁移)则通过完全拷贝当前主osd上PG对象的方式进行全量同步,此过程中的PG会处于backfilling
-
Backfill-toofull
某个需要被Backfill的PG实例,其所在的OSD可用空间不足,Backfill流程被挂起时的PG状态
存储池管理
创建存储池
ceph osd pool create <pool-name> pg-num pgp-num {replicated|erasure}
例如:
ceph osd pool create test-pool2 16 16 #默认是副本池

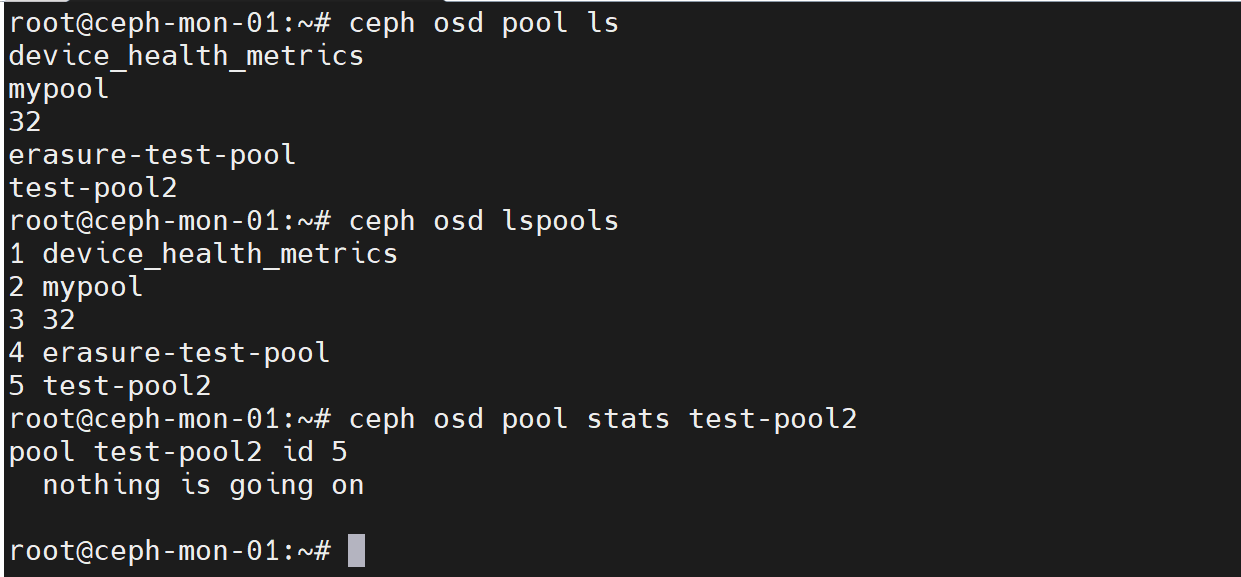
查看存储池
ceph osd pool ls #列出所有pool
ceph osd lspools #列出所有pool,返回信息带pool ID
ceph osd pool stats <pool-name> #查看指定pool的信息
删除存储池
删除存储池会把存储池内的数据全部删除,为了防止误删除操作,ceph设置了两个机制来防止误删除:
- 第一个是存储池的NODELETE标志
- 第二个是集群范围配置参数mon allow pool delete,即mon不允许删除存储池
首先设置pool的nodelete标志为false,false表示可以删除,true表示不能删除,不过默认就是false
ceph osd pool set test-pool2 nodelete false
ceph osd pool get test-pool2 nodelete

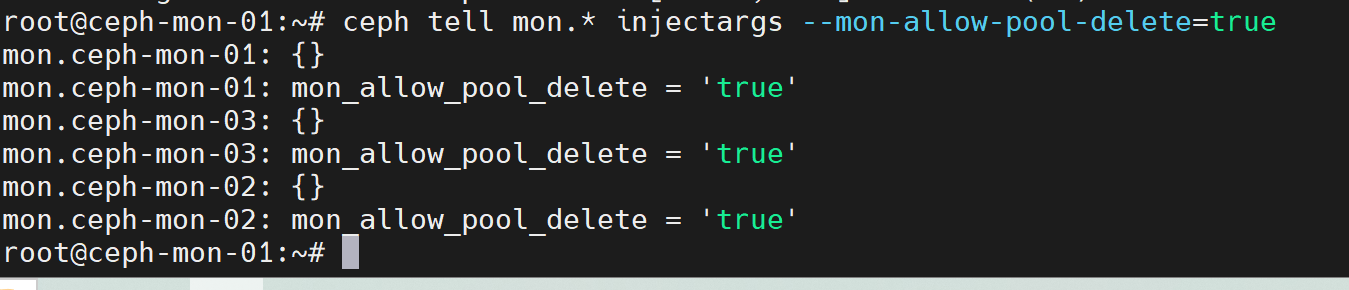
然后,通过ceph tell命令临时设置mon allow pool delete的参数为true,在删除指定的pool后再改为false
ceph tell mon.* injectargs --mon-allow-pool-delete=true
删除存储池
ceph osd pool rm <pool-name> <pool-name> --yes-i-really-really-mean-it #pool名字要重复两次
例如:
ceph osd pool rm test-pool2 test-pool2 --yes-i-really-really-mean-it

最后将mon allow pool delete重置为false
ceph tell mon.* injectargs --mon-allow-pool-delete=false
存储池配额
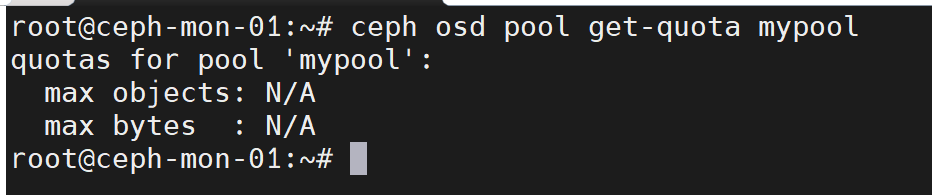
存储池可以从两个方面设置配额,一个是配置最大可用空间(max_bytes),另一个是配置最大可写入对象数量(max_objects)
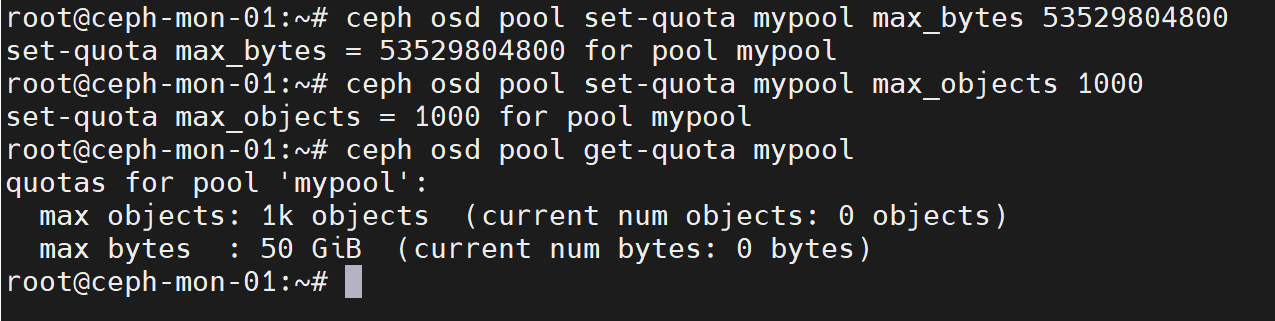
ceph osd pool get-quota mypool #查看mypool的配额
ceph osd pool set-quota mypool max_bytes 53529804800 #设置mypool最多可用50G空间
ceph osd pool set-quota mypool max_objects 1000 #设置mypool最多可以存储1000个object
存储池可用参数
一般都是通过ceph osd pool get <pool-name> <key-name>获取存储池某个参数的值,通过ceph osd pool set <pool-name> <key> <new-value>修改参数的值
常用的存储池参数如下:
size,存储池中pg的副本数量,默认是3
min_size,最小可用副本数,例如size为3,min_size为2,表示最少要有两个副本存在,PG才能对外提供读写
pg_num/pgp_num,pg数量和pgp数量
crush_rule,设置crush算法规则,默认为副本池
nodelete,控制是否可以删除,默认fasle,表示可以删除
nopgchange,控制是否可以更改存储池的pg_num和pgp_num
nosizechange,控制是否可以修改存储池的副本数,默认允许修改
noscrube,控制是否开启轻量级扫描,默认开启轻量级扫描
nodeep-scrub,控制是否开启深度扫描,默认开启深度扫描
scrub_min_interval,设置执行轻度扫描的最小时间间隔,默认未设置,可以通过配置文件中osd_min_scrub_interval参数指定
scrub_max_interval,设置执行轻度扫描的最大时间间隔,默认未设置,可以通过配置文件中osd_max_scrub_interval参数指定
dee_scrub_interval,设置执行深度扫描的时间间隔,默认未设置,可以通过配置文件中osd_deep_scrub_interval参数指定
其它参数可以通过help信息获取:

存储池快照
快照用于对存储池中的数据进行备份和还原,创建快照需要的时间和占用的存储空间取决于存储池中数据的大小。
创建快照
ceph osd pool mksnap mypool mypool-snap1
或者
rados -p mypool mksnap mypool-snap2

查看快照
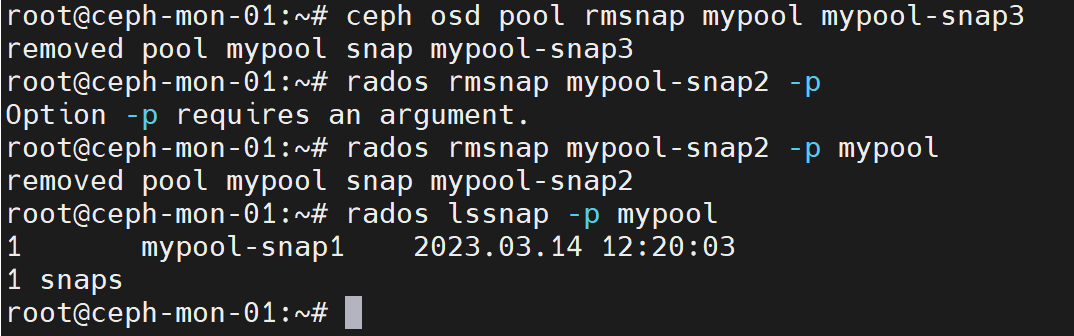
rados lssnap -p mypool

恢复快照
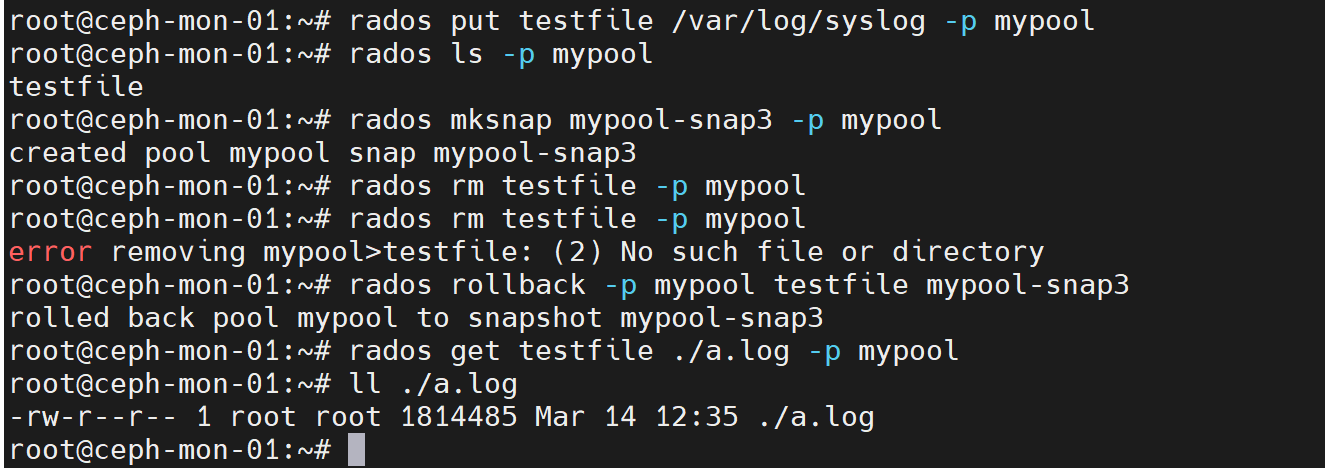
#先上传一个测试对象到mypool
rados put testfile /var/log/syslog -p mypool
#创建快照
rados mksnap mypool-snap3 -p mypool
#删除上传的测试对象,然后get测试对象验证是否已被删除
rados rm testfile -p mypool
rados get testfile ./a.log -p mypool
#通过快照恢复测试对象
rados rollback -p mypool testfile mypool-snap3
#再次get测试对象验证是否恢复
rados get testfile ./a.log -p mypool
删除快照
ceph osd pool rmsnap mypool mypool-snap3
或者
rados rmsnap mypool-snap2 -p mypool