分布式共识(下):Multi Paxos、Raft与Gossip,分布式领域的基石
上篇文章提过的Basic Paxos 存在活锁问题,两个提案节点互不相让地提出自己的提案,抢占同一个值的修改权限,导致整个系统在持续性地“反复横跳”,从外部看就像是被锁住了。
分布式共识的复杂性,主要来源于网络的不可靠、请求的可并发,这两大因素。活锁问题和许多 Basic Paxos 异常场景中所遭遇的麻烦,都可以看作是源于任何一个提案节点都能够完全平等地、与其他节点并发地提出提案而带来的复杂问题。
为了解决此问题,Lamport提出了一种 Paxos 的改进版本“Multi Paxos”算法,希望能够找到一种两全其美的办法:既不破坏 Paxos 中“众节点平等”的原则,又能在提案节点中实现主次之分,限制每个节点都有不受控的提案权利。
这两个目标听起来似乎是矛盾的,但现实世界中的选举,就很符合这种在平等节点中挑选意见领袖的情景。
Multi Paxos
Multi Paxos 对 Basic Paxos 的核心改进是,增加了“选主”的过程:
- 提案节点会通过定时轮询(心跳),确定当前网络中的所有节点里是否存在一个主提案节点;
- 一旦没有发现主节点存在,节点就会在心跳超时后使用 Basic Paxos 中定义的准备、批准的两轮网络交互过程,向所有其他节点广播自己希望竞选主节点的请求,希望整个分布式系统对“由我作为主节点”这件事情协商达成一致共识;
- 如果得到了决策节点中多数派的批准,便宣告竞选成功。
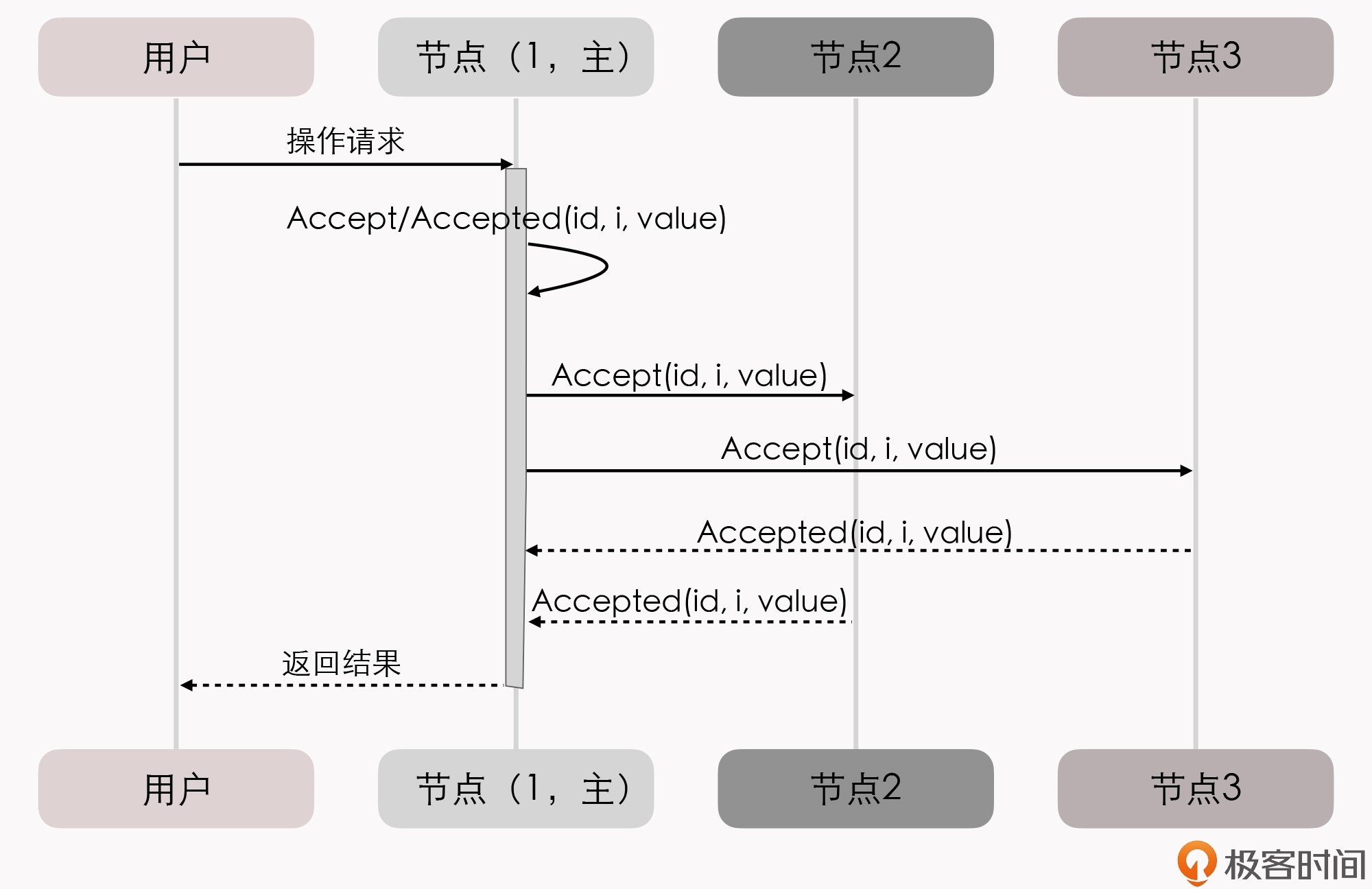
当选主完成之后,除非主节点失联会发起重新竞选,否则就只有主节点本身才能够提出提案。此时,无论哪个提案节点接收到客户端的操作请求,都会将请求转发给主节点来完成提案,而主节点提案的时候,也就无需再次经过准备过程,因为可以视作是经过选举时的那一次准备之后,后续的提案都是对相同提案 ID 的一连串的批准过程。
我们也可以通俗地理解为:选主过后,就不会再有其他节点与它竞争,相当于是处于无并发的环境当中进行的有序操作,所以此时系统中要对某个值达成一致,只需要进行一次批准的交互即可。具体如下序列所示:

你可能会注意到,二元组 (id, value) 已经变成了三元组 (id, i, value),这是因为需要给主节点增加一个“任期编号”,这个编号必须是严格单调递增的,以应付主节点陷入网络分区后重新恢复,但另外一部分节点仍然有多数派,且已经完成了重新选主的情况,此时必须以任期编号大的主节点为准。
说人话就是,轮训一下,有没有当老大的,没有我就用basic协议选老大,有就选最后选出来的那位当老大。除非老大失联了,否则小弟接到消息,先转给老大,然后老大依次广播,小弟们应答,超过一半小弟同意就形成共识,所有人按共识处理(相当于无并发)。
轮训一下,有没有当老大的,有多个老大,选最新的那个老大(任期编号大的主节点),小弟接到消息,先转给老大,然后老大依次广播,小弟们应答,超过一半小弟同意就形成共识,所有人按共识处理(相当于无并发)。
从整体来看,当节点有了选主机制的支持后,就可以进一步简化节点角色,不必区分提案节点、决策节点和记录节点了,可以统称为“节点”,节点只有主(Leader)和从(Follower)的区别。此时的协商共识的时序图如下:
在这个理解的基础上,我们换一个角度来重新思考“分布式系统中如何对某个值达成一致”这个问题,可以把它分为下面三个子问题来考虑:
- 如何选主(Leader Election)
- 如何把数据复制到各个节点上(Entity Replication)
- 如何保证过程是安全的(Safety)
当这三个问题同时被解决时,就等价于达成共识。
接下来,我们分别看下这三个子问题如何解决。
关于“如何选主”,虽然选主问题会涉及到许多工程上的细节,比如心跳、随机超时、并行竞选等,但从原理上来说,只要你能够理解 Paxos 算法的操作步骤,就不会有啥问题了。因为,选主问题的本质,仅仅是分布式系统对“谁来当主节点”这件事情的达成的共识而已。我们上篇的Basic Paxos,其实就已经解决了“分布式系统该如何对一件事情达成共识”这个问题。
我们继续来解决数据(Paxos 中的提案、Raft 中的日志)在网络各节点间的复制问题。
在正常情况下,当客户端向主节点发起一个操作请求后,比如提出“将某个值设置为 X”,数据复制的过程为:
1.主节点将 X 写入自己的变更日志,但先不提交,接着把变更 X 的信息在下一次心跳包中广播给所有的从节点,并要求从节点回复“确认收到”的消息;
2.从节点收到信息后,将操作写入自己的变更日志,然后给主节点发送“确认签收”的消息;
3.主节点收到过半数的签收消息后,提交自己的变更、应答客户端并且给从节点广播“可以提交”的消息;
4.从节点收到提交消息后提交自己的变更,数据在节点间的复制宣告完成。
那异常情况下的数据复制问题怎么解决呢?网络出现了分区,部分节点失联,但只要仍能正常工作的节点数量能够满足多数派(过半数)的要求,分布式系统就仍然可以正常工作。假设有 S1、S2、S3、S4 和 S5 共 5 个节点,我们来看下数据复制过程。
- 假设由于网络故障,形成了 S1、S2 和 S3、S4、S5 两个分区。
- 一段时间后,S3、S4、S5 三个节点中的某一个节点比如 S3,最先达到心跳超时的阈值,获知当前分区中已经不存在主节点了;于是,S3 向所有节点发出自己要竞选的广播,并收到了 S4、S5 节点的批准响应,加上自己一共三票,竞选成功。此时,系统中同时存在 S1 和 S3 两个主节点,但由于网络分区,它们都不知道对方的存在。
- 这种情况下,客户端发起操作请求的话,可能出现这么两种情况:
第一种,如果客户端连接到了 S1、S2 中的一个,都将由 S1 处理,但由于操作只能获得最多两个节点的响应,无法构成多数派的批准,所以任何变更都无法成功提交。
第二种,如果客户端连接到了 S3、S4、S5 中的一个,都将由 S3 处理,此时操作可以获得最多三个节点的响应,构成多数派的批准,变更就是有效的可以被提交,也就是说系统可以继续提供服务。
事实上,这两种“如果”的场景同时出现的机会非常少。为什么呢?网络分区是由软、硬件或者网络故障引起的,内部网络出现了分区,但两个分区都能和外部网络的客户端正常通讯的情况,极为少见。更多的场景是,算法能容忍网络里下线了一部分节点,针对咱们这个例子来说,如果下线了两个节点系统可以正常工作,但下线了三个节点的话,剩余的两个节点也不可能继续提供服务了。
- 假设现在故障恢复,分区解除,五个节点可以重新通讯了:
=============================================
S1 和 S3 都向所有节点发送心跳包,从它们的心跳中可以得知 S3 的任期编号更大、是最新的,所以五个节点均只承认 S3 是唯一的主节点。
S1、S2 回滚它们所有未被提交的变更。
S1、S2 从主节点发送的心跳包中获得它们失联期间发生的所有变更,将变更提交写入本地磁盘。
此时分布式系统各节点的状态达成最终一致。
=============================================
到这里,第二个问题“数据在网络节点间的复制问题”也就解决了。我们继续看第三个问题,如何保证过程是安全的。
以下部分了解即可
在专业资料中,Safety 和 Liveness 通常会被翻译为“协定性”和“终止性”。
还是以选主问题为例,Safety 保证了选主的结果一定是有且只有唯一的一个主节点,不可能同时出现两个主节点;而 Liveness 则要保证选主过程是一定可以在某个时刻能够结束的。
一些其他的变种
Paxos、Raft、ZAB 等分布式算法经常会被称作是“强一致性”的分布式共识协议,
一种典型而且非常常见的最终一致的分布式系统,就是DNS 系统,在各节点缓存的 TTL 到期之前,都有可能与真实的域名翻译结果存在不一致。
还有一种很有代表性的“最终一致性”的分布式共识协议,那就是 Gossip 协议。Gossip 协议,主要应用在比特币网络和许多重要的分布式框架(比如 Consul 的跨数据中心同步)中。
小结
对于普通开发者来说,分布式共识算法这两讲的内容理解起来还是有些困难的,因为算法更接近研究而不是研发的范畴。但是,理解 Paxos 算法对深入理解许多分布式工具,比如 HDFS、ZooKeeper、etcd、Consul 等的工作原理,是无可回避的基础。虽然 Paxos 不直接应用于工业界,但它的变体算法,比如我们今天学习的 Multi Paxos、Raft 算法,以及今天我们没有提到的 ZAB 等算法,都是分布式领域中的基石。