1. 标记清除算法:
算法分为标记和清除两个阶段,首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象

从图中可以看出这种算法的缺点在于,垃圾被回收以后造成了大量不连续的内存碎片。碎片太多可能会导致以后需要分配较大对象时,无法找到连续的足够内存从而频繁触发垃圾收集,降低系统效率。
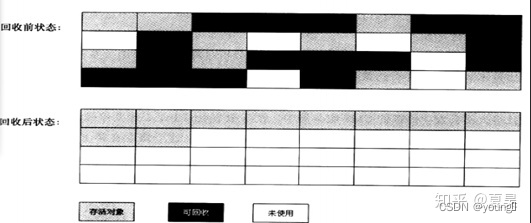
2. 复制算法:
为了解决“标记,清除”算法的问题一种被称为复制的算法出现了,它将内存平均分为两块,每次只使用其中一块,当这一块存满时触发垃圾收集,将还存活的对象复制到另一块内存,然后将这块内存清掉,这样就不会存在内存碎片的问题。
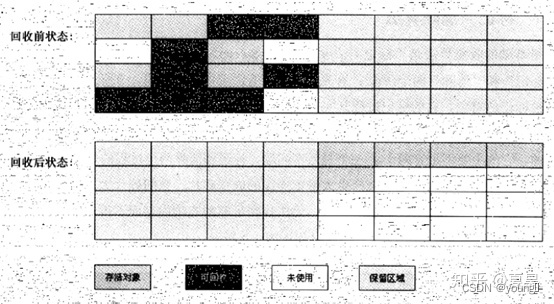
3. 标记整理算法:
复制算法在存活对象较多的时候需要复制的操作也较多,最关键的是只能利用一半的内存,标记整理算法可以解决这个问题,标记整理算法中的标记和标记清除算法一样,要被回收的对象找出来以后让所有存活的对象向一端移动,然后将内存的剩余部分直接清理掉。
4. 分代收集算法:
分代收集算法将内存分为新生代和老年代,新生代又分为:较大的Eden区(占80%)和两块Survivor区(各占10%),刚刚创建的对象存放在新生代的Eden区。
因为绝大多数的对象(98%)都是朝生夕死的,当Eden区没有足够的空间的时候虚拟机会发起一次Minor Gc,Minor Gc之后,存活对象会进入其中的一块Suvivor区,Eden区被清空,如果Suvivor区内存不够则直接进入老年代。下一次Minor Gc会将Eden和该Suvivor区的存活对象复制到另一块Suvivor区,并将Eden区和该Suvivor区清空。
在这里我们可以看到相比复制算法,被浪费的空间只有10%。但是前提是绝大部分(90%)的对象在Mino Gc的时候会被回收,如果不满足这个条件Suvivor区大小不够,则存活的对象直接进入老年代。
为什么需要Survivor区?
试想一下如果没有Survior区,每次进行Minor Gc,存活的对象直接进入老年代,老年代内存被占满会发生Major Gc,Major Gc执行的速度比Minor Gc慢十倍以上,当有了Survivor区,存活的对象在两块Survior区中倒腾,在新生代存活了一定次数的对象(通过参数可以配置),才会被放入老年代。这样就减少了Major Gc发生的频次。
为什么需要两块Survivor区?
为了避免内存碎片化的问题,大家想想复制算法是如何解决标记清除算法的内存碎片化问题的,将内存分为大小相等的两块,将存活的对象复制到另一块内存,这里也是一样的道理。
老年代:
因为老年代中对象的生命力比较顽强,如果采用复制算法那些存活的对象需要被复制很多次,所以老年代采用的是标记整理算法。
什么样的对象会进入老年代呢?
1. 大对象会直接进入老年代:
所谓的大对象就是指需要大量连续内存空间的对象,典型的大对象就是很长的字符串和数组,如果大对象直接在Eden区分配内存空间会导致Eden和Survior之间的大量内存复制,很消耗性能,所以它会直接进入老年代。
2. 长期存活的对象会进入老年代
所谓长期存活的对象就是前面所述,在新生代存活了一定次数的对象(通过参数可以配置)。