人生苦短,我用python,今天来爬一下百度image。
目标
需求:百度image,输入关键字下载image

前置环境
1>python环境

2>安装requests包
python install requests
实现代码
步骤1:分析百度image是html页面获取数据还是ajax获取数据


从上面源码看,使用的是ajax方式实现,即:先发起异步请求获取数据,再使用js方式加载到页面。
打开F12, 验证一下:
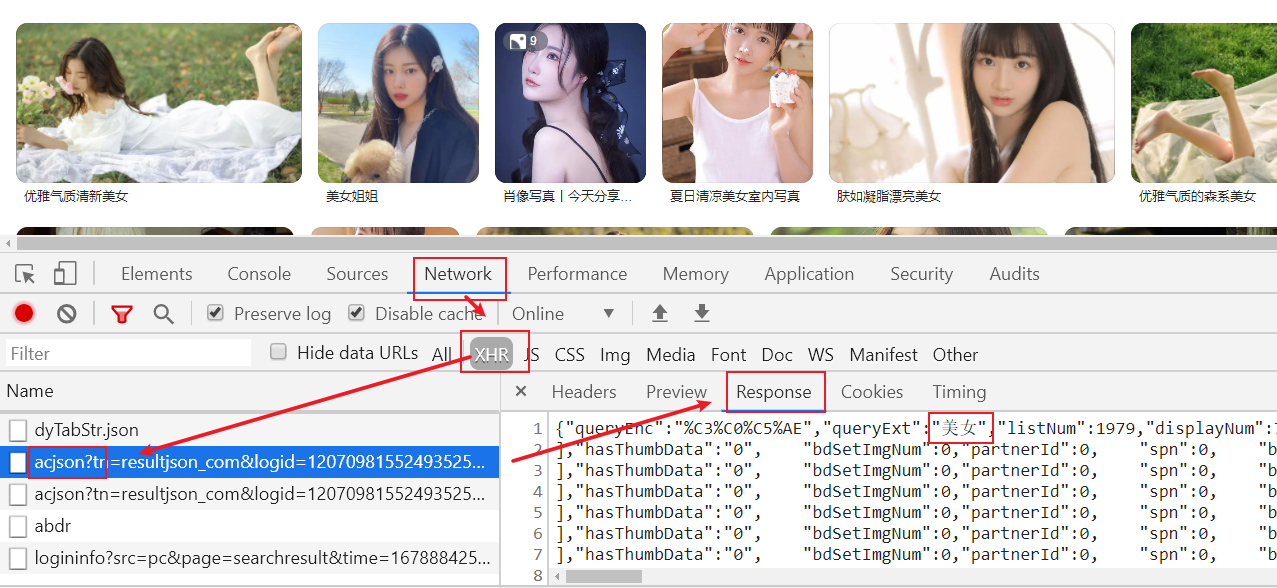
步骤2:分析ajax请求的规律
刷新页面,并滚动页面,发起多个ajax请求,分析请求规律
 涉及到
涉及到
关键字:word=美女&queryWord=美女
分页相关:pn为分页数据偏移量, rn表示当前页面显示30数据
第一页:&pn=30&rn=30
第二页:&pn=60&rn=30
第三页:&pn=90&rn=30
第四页:&pn=120&rn=30
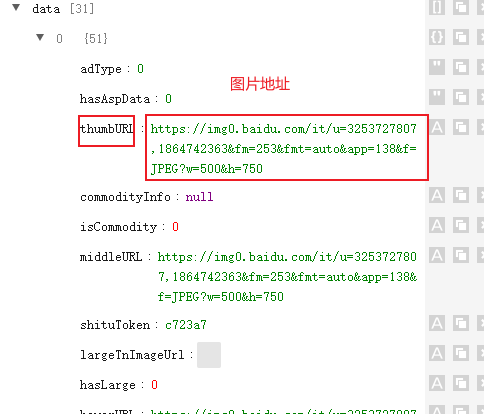
步骤3:分析响应数据规律
上面一次请求得到数据

选择data数据展开
步骤4:代码实现
思路:
1>定制要爬取图片种子url(分页路径)
2>通过种子url获取到图片json数据(分页数据-每页30条)
3>解析图片json数据
4>遍历下载图片,并保存
全部代码
#coding=utf-8
import requests
import time
import json
import uuid
import random
import os
# 定义类
class BaiduImage(object):
# 构造器, kw:关键字 page_no:抓几页图片 path:图片保存路径
def __init__(self, kw, page_no, path):
# 分页路径目标
url_template = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=9074274472030331556&ipn=rj&ct=201326592&is=&fp=result&fr=&word={}&cg=girl&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn={}&rn={}&gsm=1e&{}='
# 将需要抓取的分页url,一次性配置出来
self.urls = [url_template.format(kw, kw, i*30, 30, time.time()) for i in range(1, page_no+1)]
# 模拟浏览器访问
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
# 图片路径保存
self.path = path
# 判断路径是否存在,不存在创建
if not os.path.exists(path):
os.makedirs(path)
# 根据url获取数据
def get_data(self, url):
resp = requests.get(url, headers=self.headers)
return resp.content.decode()
# 解析ajax请求返回的图片json数据
def pasre_data(self, data):
# 解析json为dict
dict_data = json.loads(data)
data_list = []
# 遍历解析所有图片url,统一缓存在集合中
for img_data in dict_data['data']:
if 'thumbURL' in img_data:
# data_list.append(img_data['replaceUrl'][0]['ObjURL']) # 真实图片地址,不能保证能打开
data_list.append(img_data['thumbURL']) # 百度缓存地址,所见所得
return data_list
# 指定url地址图片,保存到指定目录夹中
def image_download(self, url):
# 写二进制文件,文件名使用uuid
with open(path + str(uuid.uuid1()) + ".jpg", 'wb') as f:
# 下载图片,写流
img = requests.get(url, headers=self.headers).content
f.write(img)
# 图片下载
def save_data(self, data_list):
for ul in data_list:
self.image_download(ul)
# 防止百度判定为爬虫,间隔时间发起请求
time.sleep(round(random.uniform(0.001, 0.01), 3))
# 执行
def run(self):
for num in range(len(self.urls)):
print(f'---------第{(num+1)}页图片-----------')
data = self.get_data(self.urls[num])
data_list = self.pasre_data(data)
self.save_data(data_list)
time.sleep(round(random.uniform(0.001, 0.01), 3))
# 程序入口
if __name__ == '__main__':
kw = '美女'
page_no = 10
path = "D:/images/"
baidu = BaiduImage(kw, page_no,path)
baidu.run()
运行结果