一、案例分析
-
如图研究的是这个请求对应的数据,也就是详情页的数据, 案例网址:aHR0cHM6Ly9zcy5jb2RzLm9yZy5jbi9tb2JpbGUvc2hhcmVEZXRhaWwvYmE4Yzc0YmJiODY4Nzc1NjM4NGExMDkyMzdlN2NjNmYvNGQ=

-
该案例是
某验反爬,关于某验的js逆向,在这篇文章已经介绍过,重复部分不再介绍了。无感就是点击按钮直接校验通过,不会弹出其它的验证码再次校验。该篇是个实际滑块应用案例,非官网测试案例,所以会补充一些之前遗漏的坑(感谢时光大佬在研究过程中对坑的排查给的思路测试建议) -
大概的请求流程分析如图:
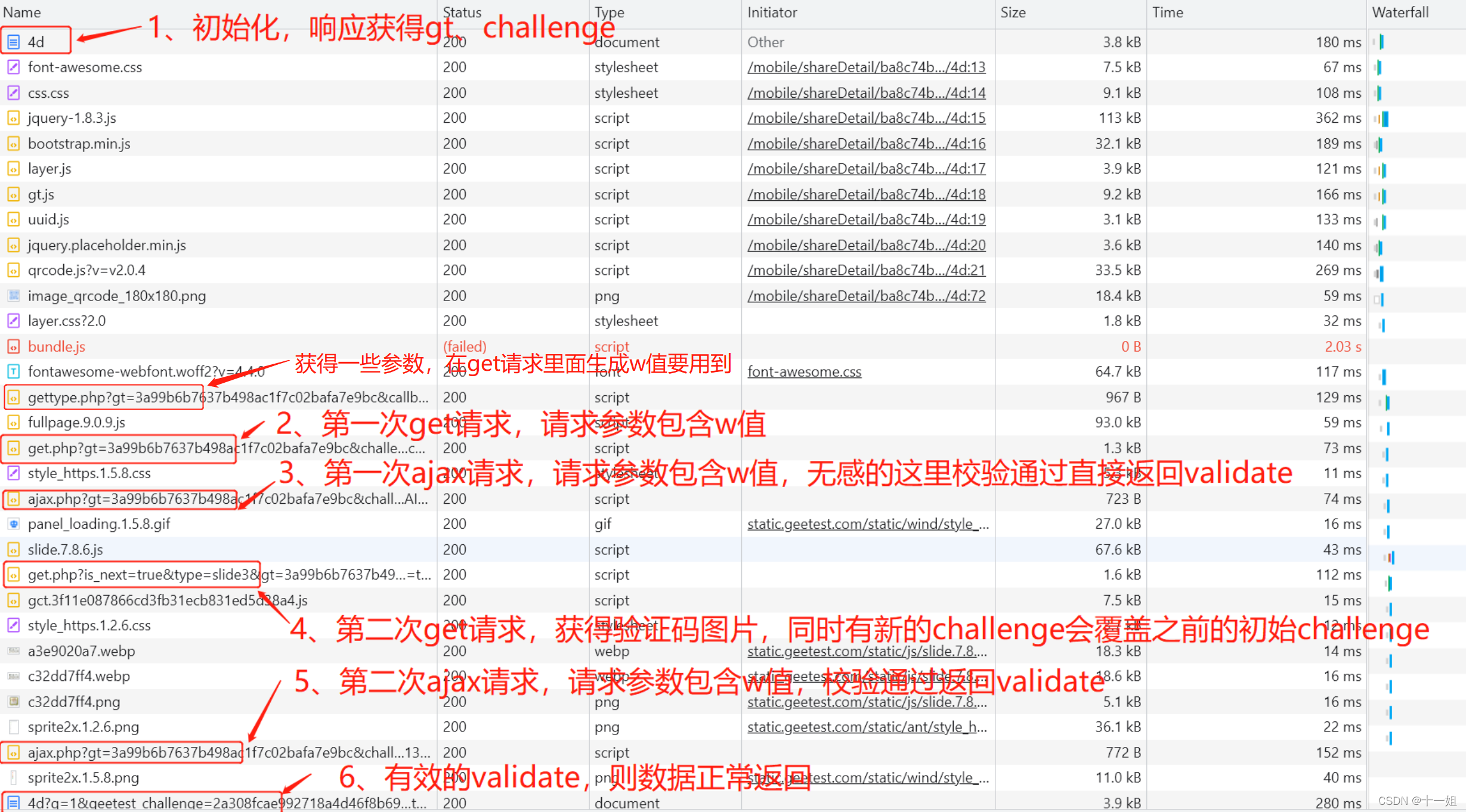

-
可能大多数人只在官网demo测试通过拿到validate了,但是这个案例校验比较严格,它会出现一个现象就是,如果你没有完整的按上图获取3个w值,而是取巧将第一次ajax的w值置空,试图跳过无感,直接走滑块的逻辑,也能拿到validate,
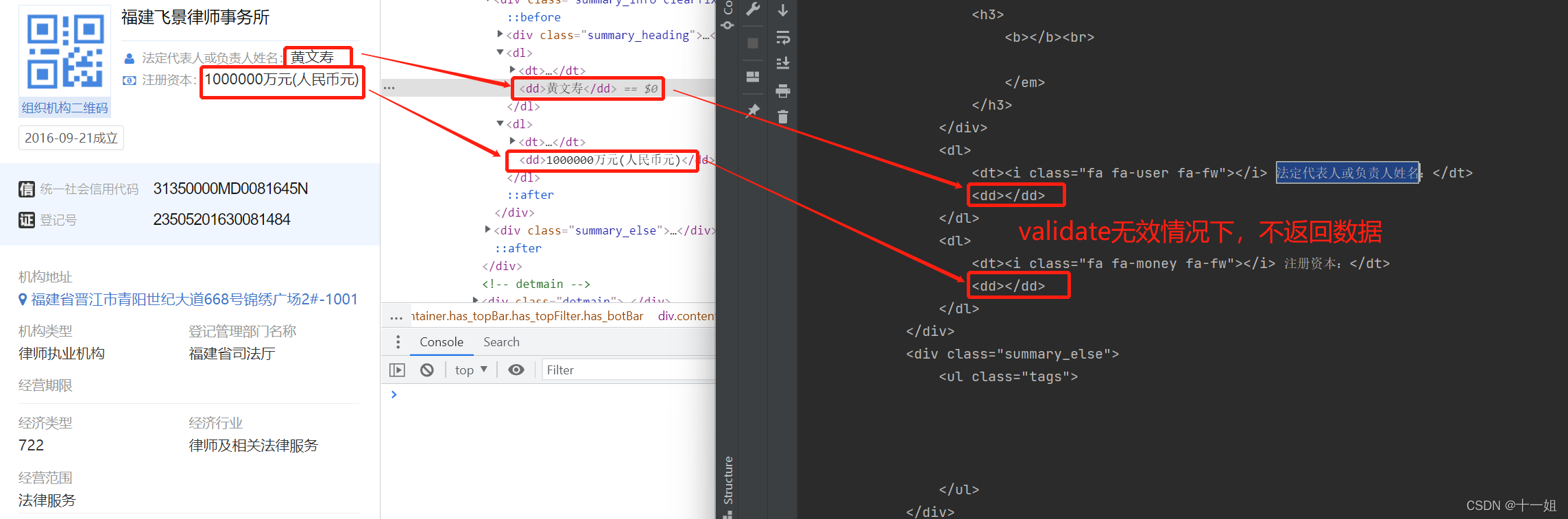
但是!你可能会发现一个困惑,为什么有validate了,却拿不到数据? -
拿不到数据指的是图中情况,生成的validate有值能拿到响应结果,但是响应结果里面并没有值
-
经多次测试大概有这几个坑:
- ① 3个w值只生成了最后一个w值,前面的w值流程未走,其实是
aes_key贯穿3个w起了关键作用,也就是aes_key必须在第一次get请求里面携带w值进行一个激活过程 - ② 第二个w加密参数里面有参数叫captcha_token(无感校验这一步的请求),第一次ajax接口的那个请求中的w值便和这个
captcha_token有关,而captcha_token和fullpage.js文件代码有关(根据这个文件中的某些代码来生成的),由于是根据js文件代码来生成的,所以理论上一个版本的captcha_token是固定的 - ③ 第三个w加密参数里面有个随机值不能写死,如
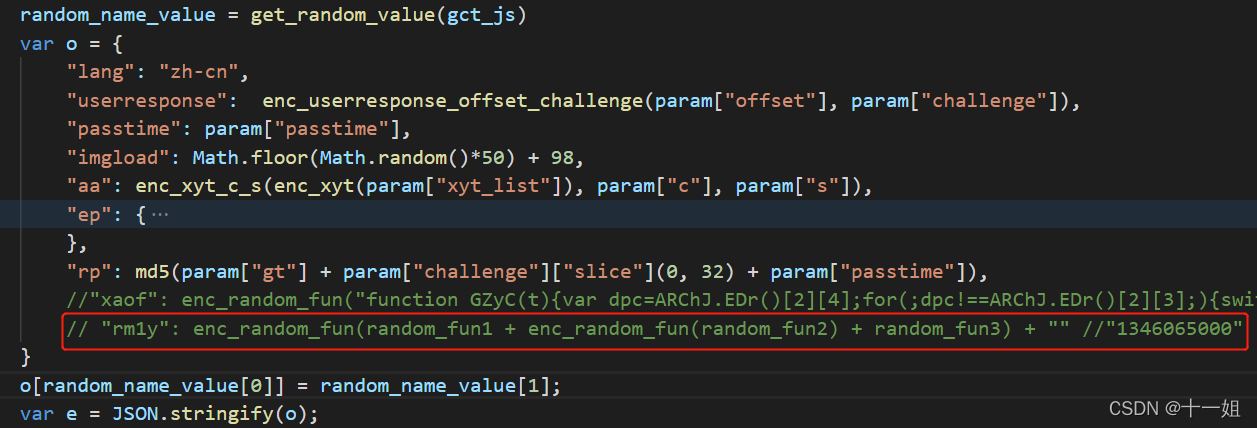
{"rm1y":"1346065000"},它的name和value是动态变化的,因为gct.js文件代码是动态变化的,所以每天这个随机值也会不一样
- ① 3个w值只生成了最后一个w值,前面的w值流程未走,其实是
二、ast还原混淆
- 还原混淆的原因:硬刚扣代码是可以的,但是时间会长一些,基于网上也有现成的还原混淆的代码,所以我们直接用,这样分析速度会更快些,推荐ast解混淆文章
- 由于前辈的ast代码运行的时候有点小问题会报错,在下面的第二张图随意猜测了,加了部分代码作为解决方案
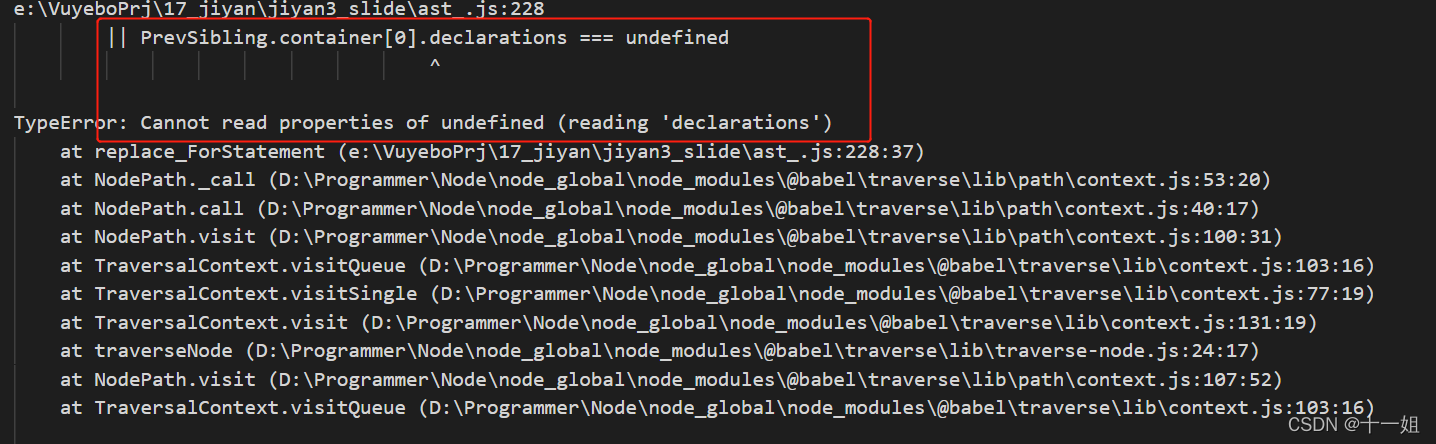
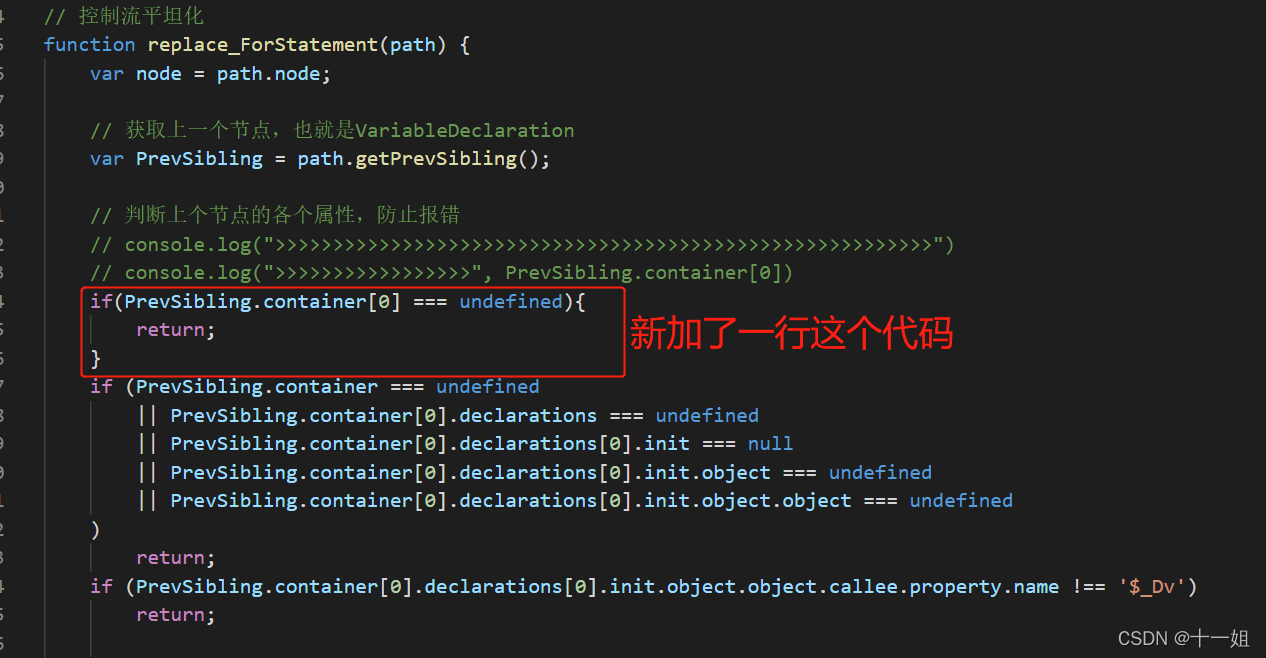
- 按前辈ast解混淆的逻辑,大致流程如图,首先准备一份需要解混淆的js,然后将如下框出的部分进行相应的替换改动即可,进而可以还原出
fullpage.9.0.9.js

- 当然还原出的fullpage9.0.9.js这个用fiddler
替换到网页上是没法校验通过的,因为第一次ajax的w值captcha_token的加密是将函数代码转字符串加密的,所以你还原后替换的js,改变了原有的代码结构,因此会一直校验失败弹出滑块


- 解决方法就是按如图改下
fullpage.js把这一部分的加密值写成正确的,再替换到网页上就可以校验通过了

- 到此ast解混淆js已结束,其中其它的slide.js/clcik.js/gct.js还原的逻辑是一致的
三、3个w值位置
-
第一个w值,是第一个get请求里面携带的
-
第一个w值,在fullpage.9.0.9.js生成,搜索"\u0077":可以定位到,加密参数来自gettype请求的响应值,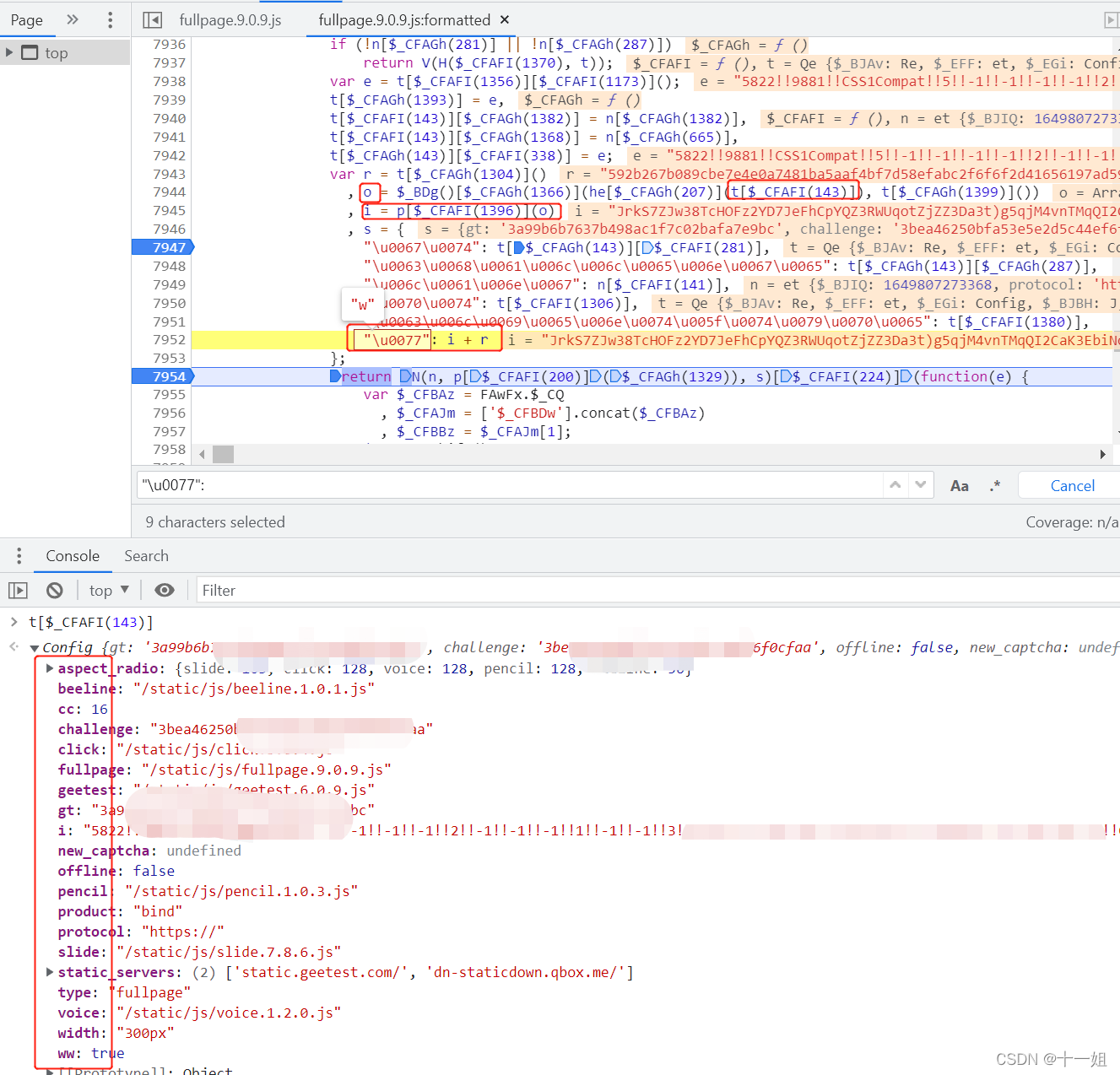
-
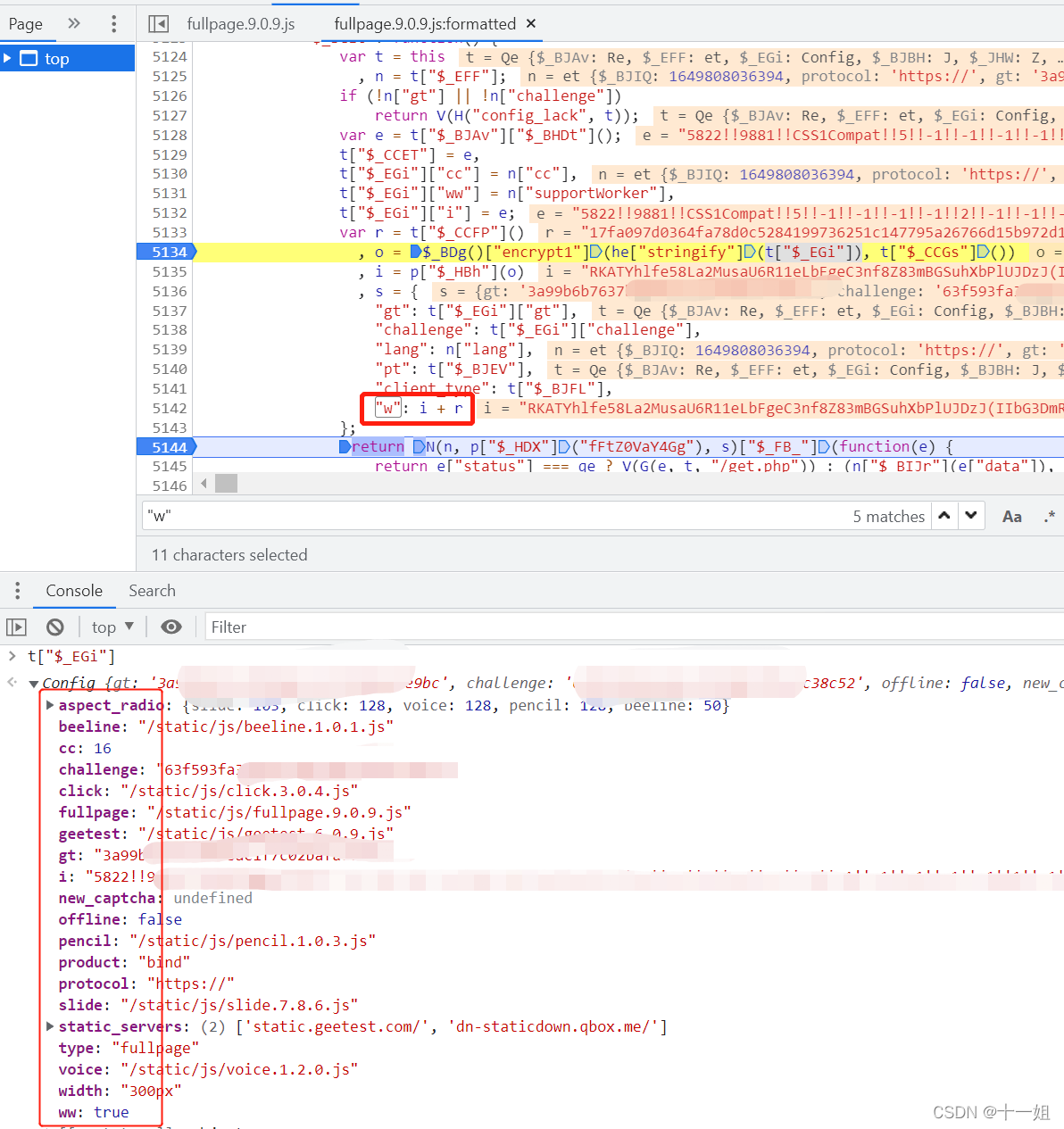
第一个w值,用解混淆后的js,直接搜索"w"即可定位到
-
第一个w值,效果差不多是如下截图这个样子

-
第二个w值,是第一个ajax请求里面的,请求参数依赖第一个get请求里面的响应参数
-
第二个w值,在fullpage.9.0.9.js生成,差不多是如图位置,是取得1432这个

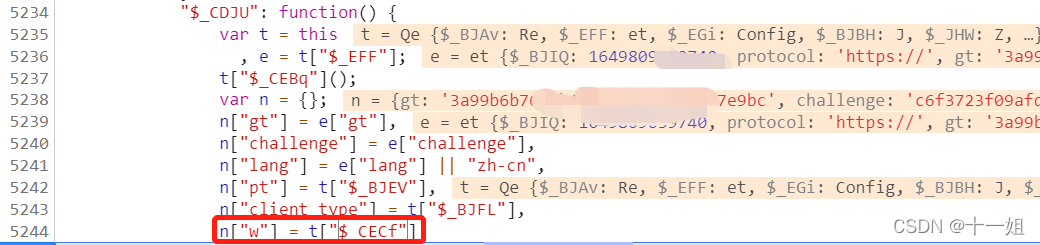
-
第二个w值,搜索(), new Date()),或者直接搜索1432可以定位到1432的位置,加密参数来自第一个get请求的响应值
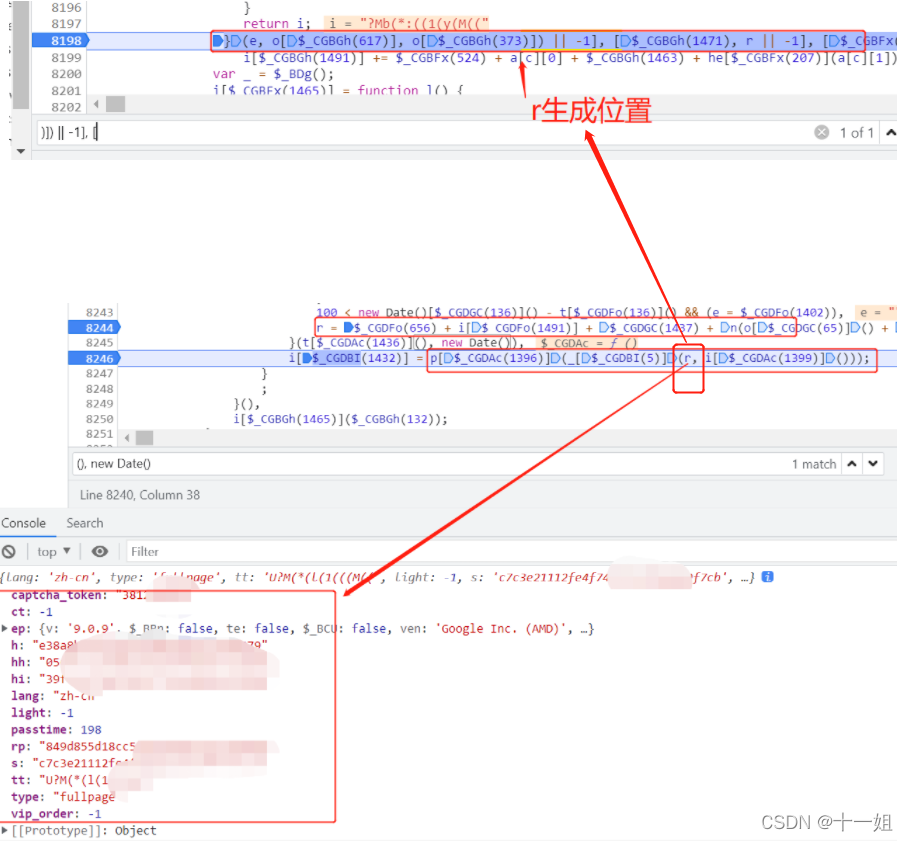
-
第二个w值,用解混淆后的js,直接搜索"captcha_token"即可定位到
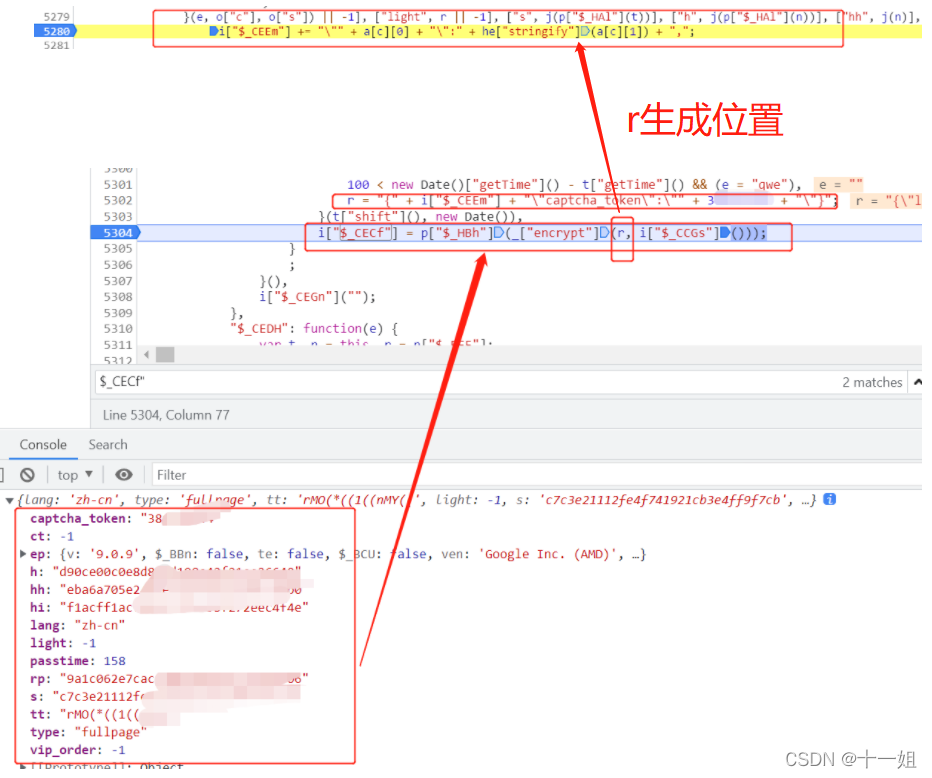
-
第二个w值,captcha_token加密关键代码部分,注意这里加密结果要用非混淆的去看,图片中的还原后的js加密出来的结果是错误值,因为captcha_token加密是将非格式化的函数代码转字符串加密的

-
第二个w值,效果差不多是如下截图这个样子,这里有个captcha_token是和fullpage.9.0.9.js代码有关,一般不改版可以写死
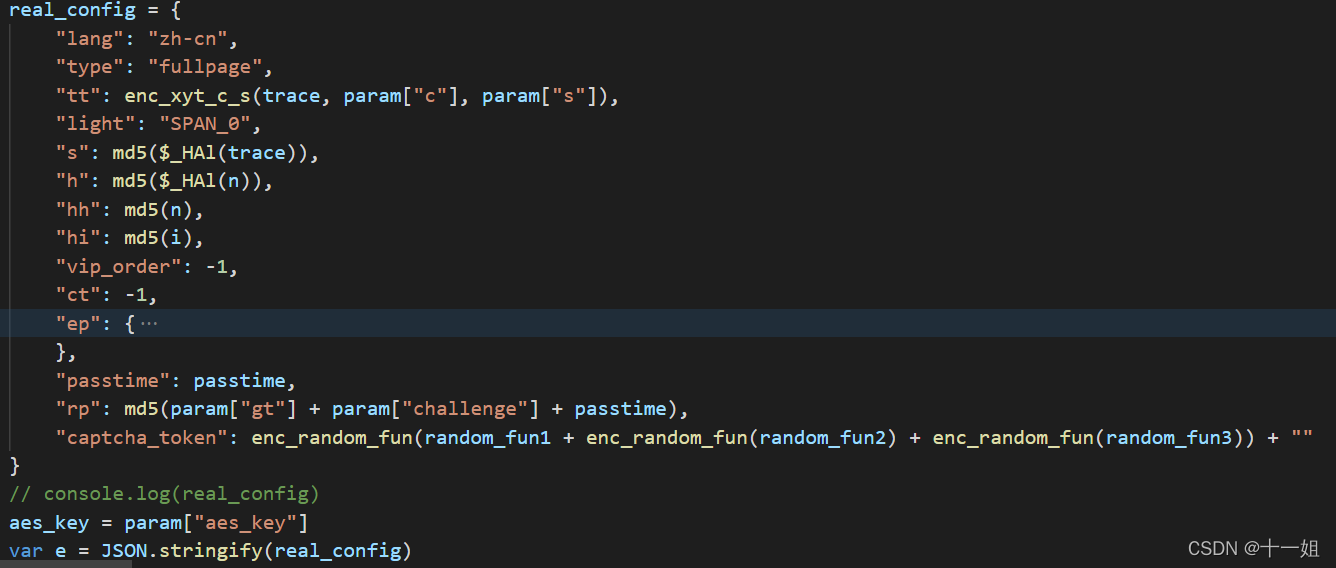
-
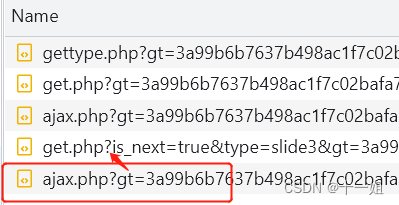
第三个w值_滑块,是第二个ajax请求里面的,请求参数依赖第二个get请求里面的响应参数
-
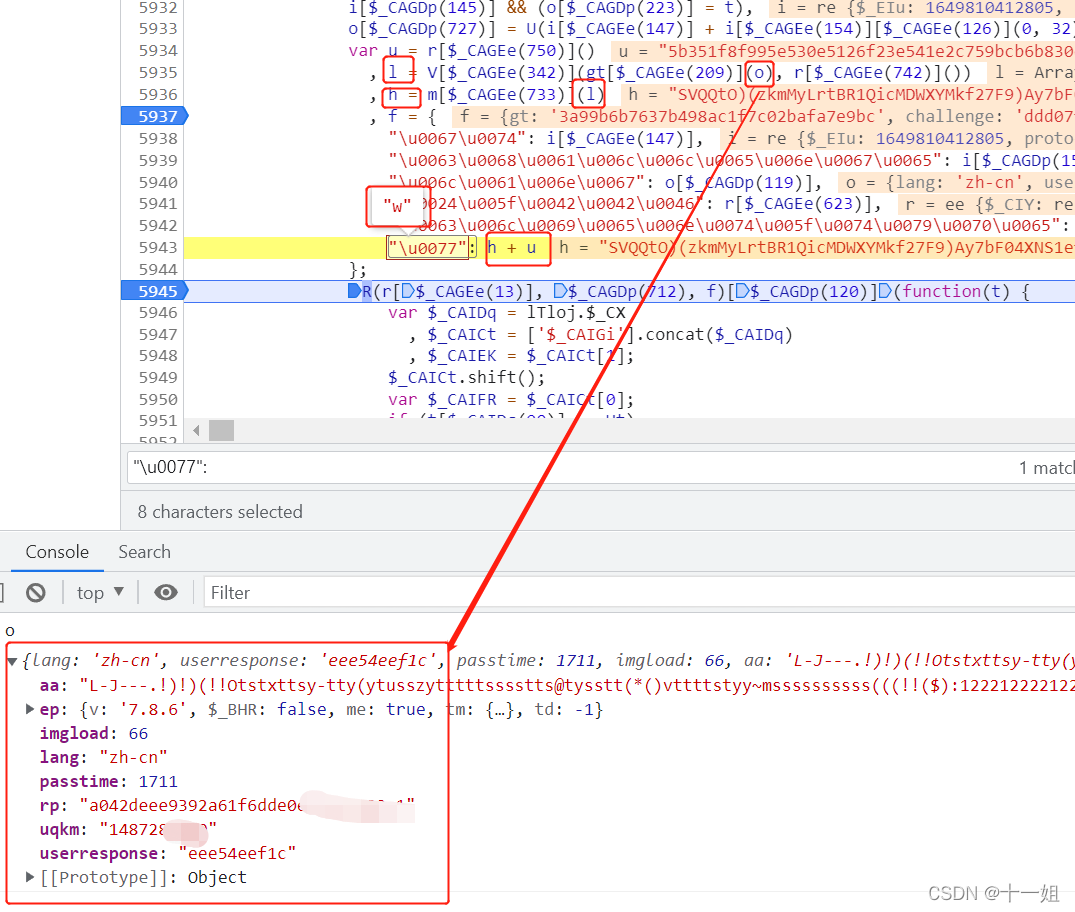
第三个w值_滑块,在slide.7.8.6.js生成,搜索"\u0077":可以定位到,加密参数来自第二个get请求的响应值
-
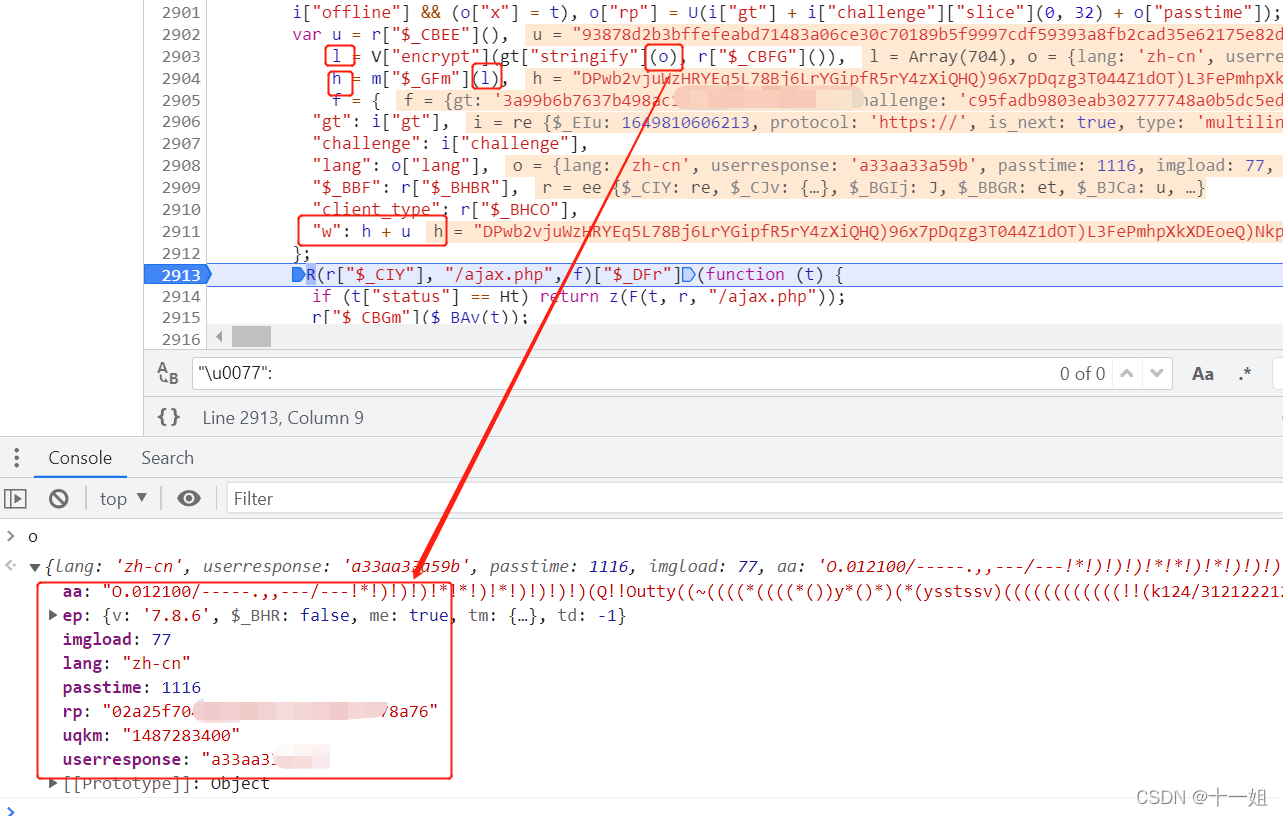
第三个w值_滑块,用解混淆后的js,直接搜索"w"即可定位到
-
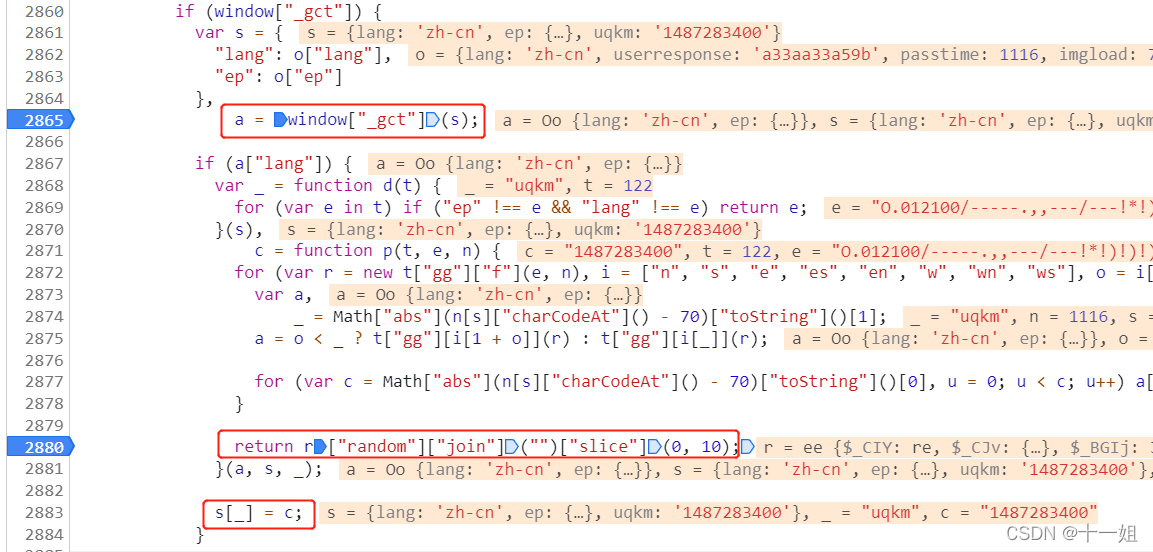
第三个w值_滑块,随机值生成位置的关键代码部分如下
-
第三个w值_滑块,效果差不多是如下截图这个样子,这里有个随机值rm1y也有可能是xaof,每天的key名和value都是变的,不能简单的写死,否则会导致没有数据,主要和gct_js的代码有关
-
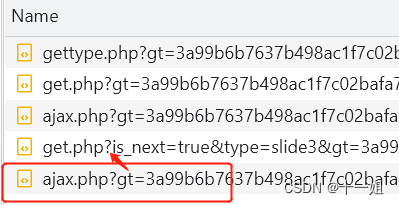
第三个w值_点选,是第二个ajax请求里面的,请求参数依赖第二个get请求里面的响应参数
-
第三个w值_点选,在click.3.0.4.js生成,搜索"\u0077":可以定位到,加密参数来自第二个get请求的响应值

-
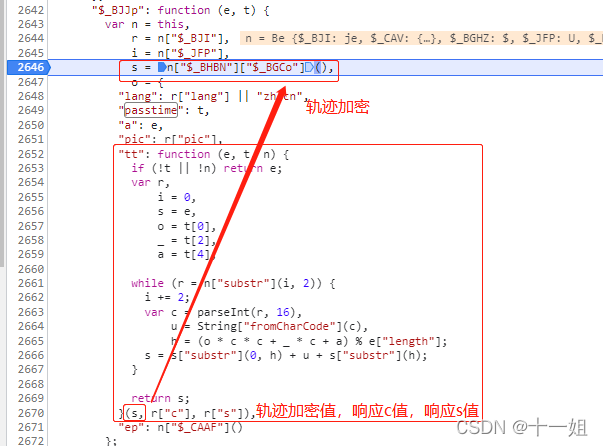
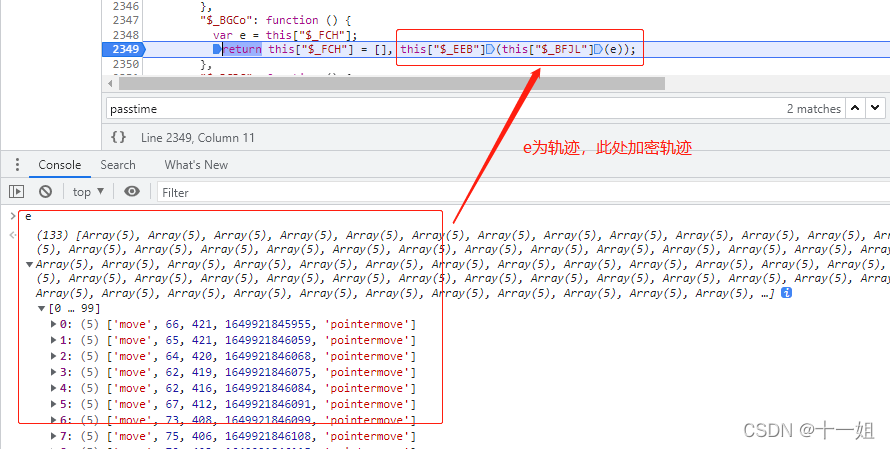
第三个w值_点选,轨迹生成位置的关键代码部分如下,s为加密轨迹后的值
-
第三个w值_点选,随机值生成位置的关键代码部分如下
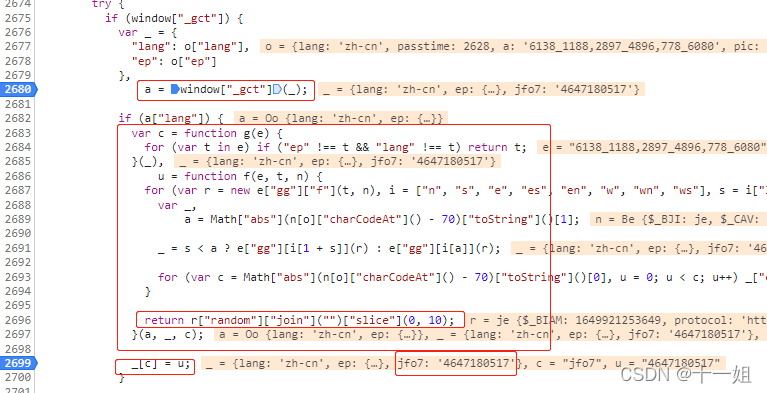
-
第三个w值_点选,效果差不多是如下截图这个样子,这里有个随机值fp0u也有可能是qs48,每天的key名和value都是变的,不能简单的写死,否则会导致没有数据,主要和gct_js的代码有关
四、动态字体woff.2解析
-
前面分析的是app端的分享网址,而对应的网页端网址:aHR0cHM6Ly93d3cuY29kcy5vcmcuY24v,列表页是有字体反爬的,详情页没有的,所以列表页的字体反爬影响不大,此次只是体验一下该字体反爬如何处理,如图,汉字有一套字体反爬,数字字母有另一套字体反爬
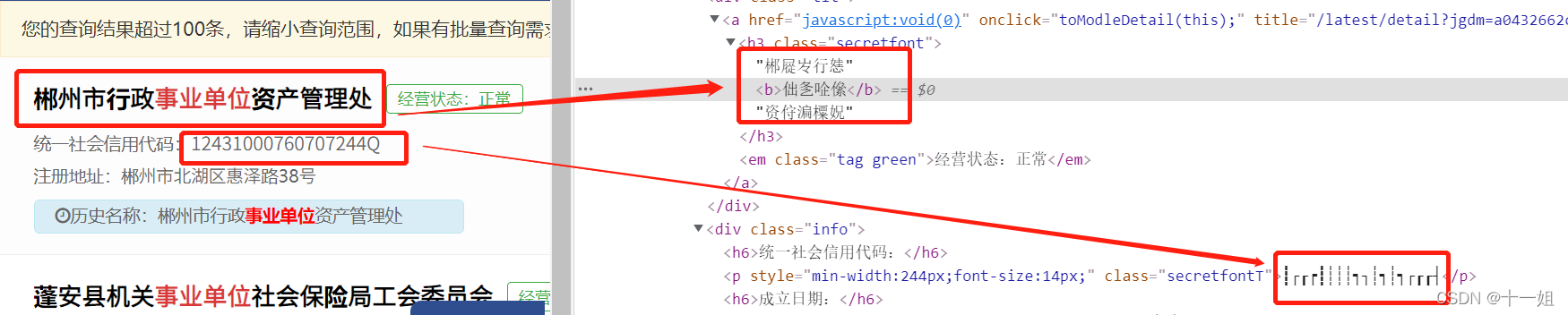
-
如图字体反爬是woff.2的格式,从图中可以发现汉字字体woff2是是静态文件,而数字字母woff2是个动态的文件
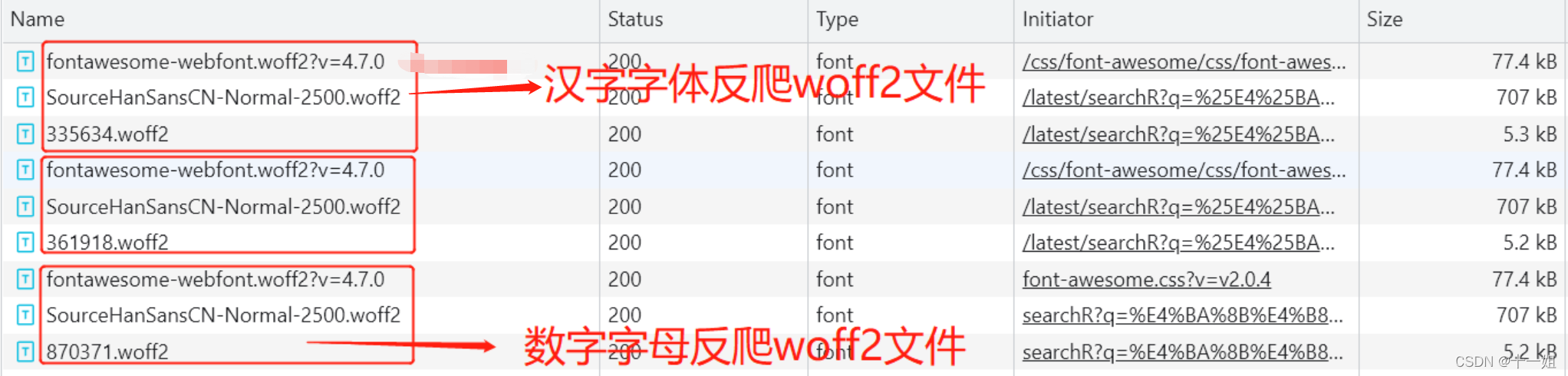
-
对于woff.2的文件格式,直接下载下来到 在线FontEditor工具是打不开的 ,需要先将woff2转ttf,然后再到 在线FontEditor工具打开
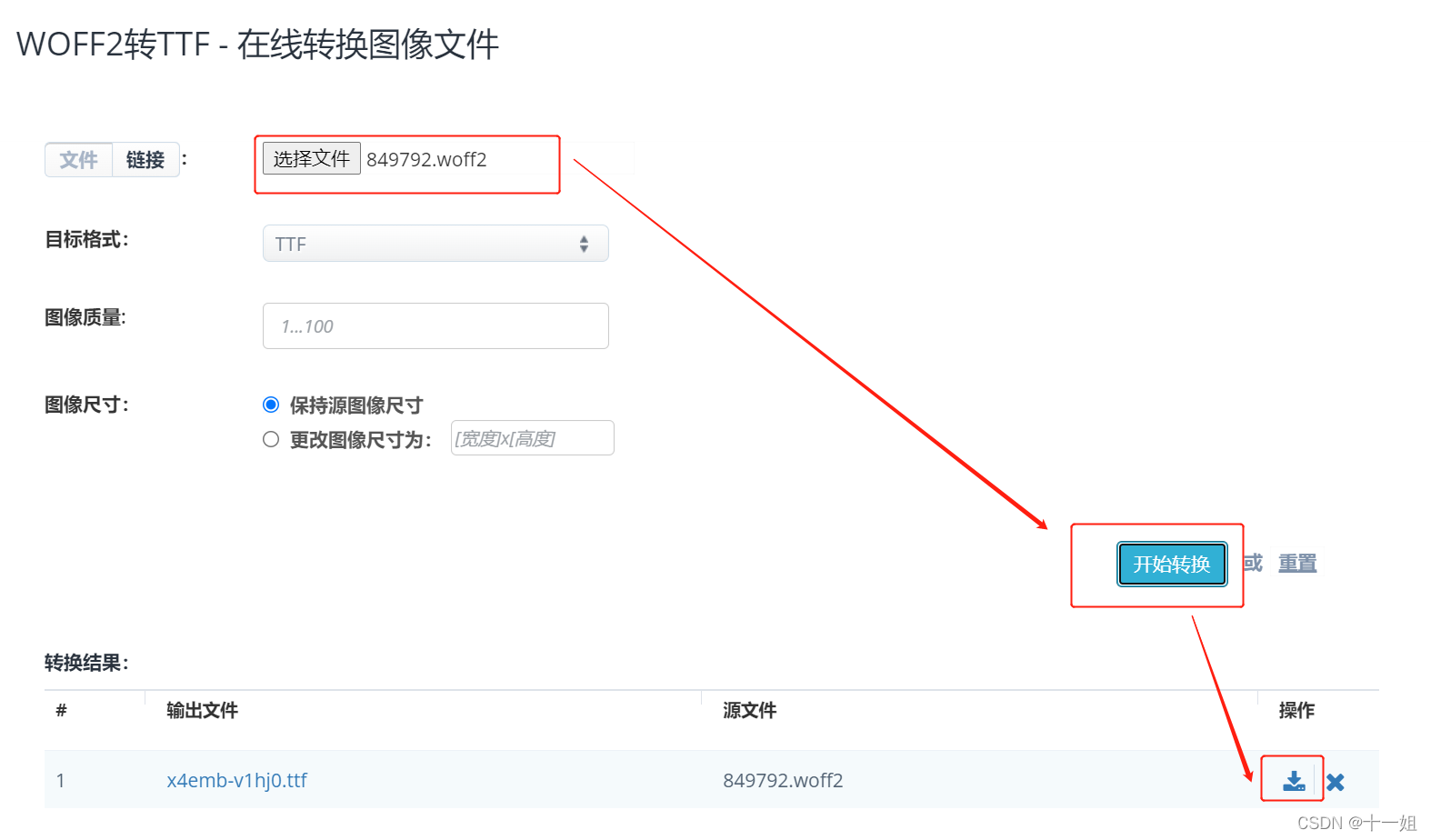

-
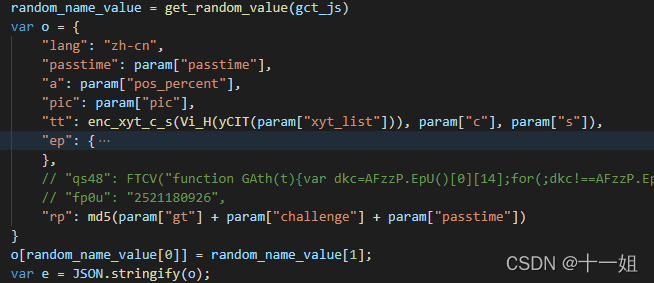
而
python解析woff.2后缀的字体文件,可以先导包from fontTools.ttLib.woff2 import decompress,即可将woff.2文件转换成ttf文件,关于fontTools的详细使用,包括下面图片中用的代码都在这篇文章中from fontTools.ttLib import TTFont from fontTools.ttLib.woff2 import decompress woff2_path = "./woff/704224.woff2" ttf_path = './woff/704224.ttf' xml_path = './woff/704224.xml' decompress(woff2_path, ttf_path) # 将woff2文件转成ttf文件 font = TTFont(ttf_path) font.saveXML(xml_path) -
汉字字体ttf分析:对于本案例的字体反爬,我们解决方法如下,直接用乱码到对应的ttf文件去找字体结果,并转换成图片

-
汉字字体ttf分析通用的识别方案:加个ocr识别图片中的文字,但ocr识别可能会出现错误,所以后续可以做个对识别的结果先做个映射校对,收集字体等
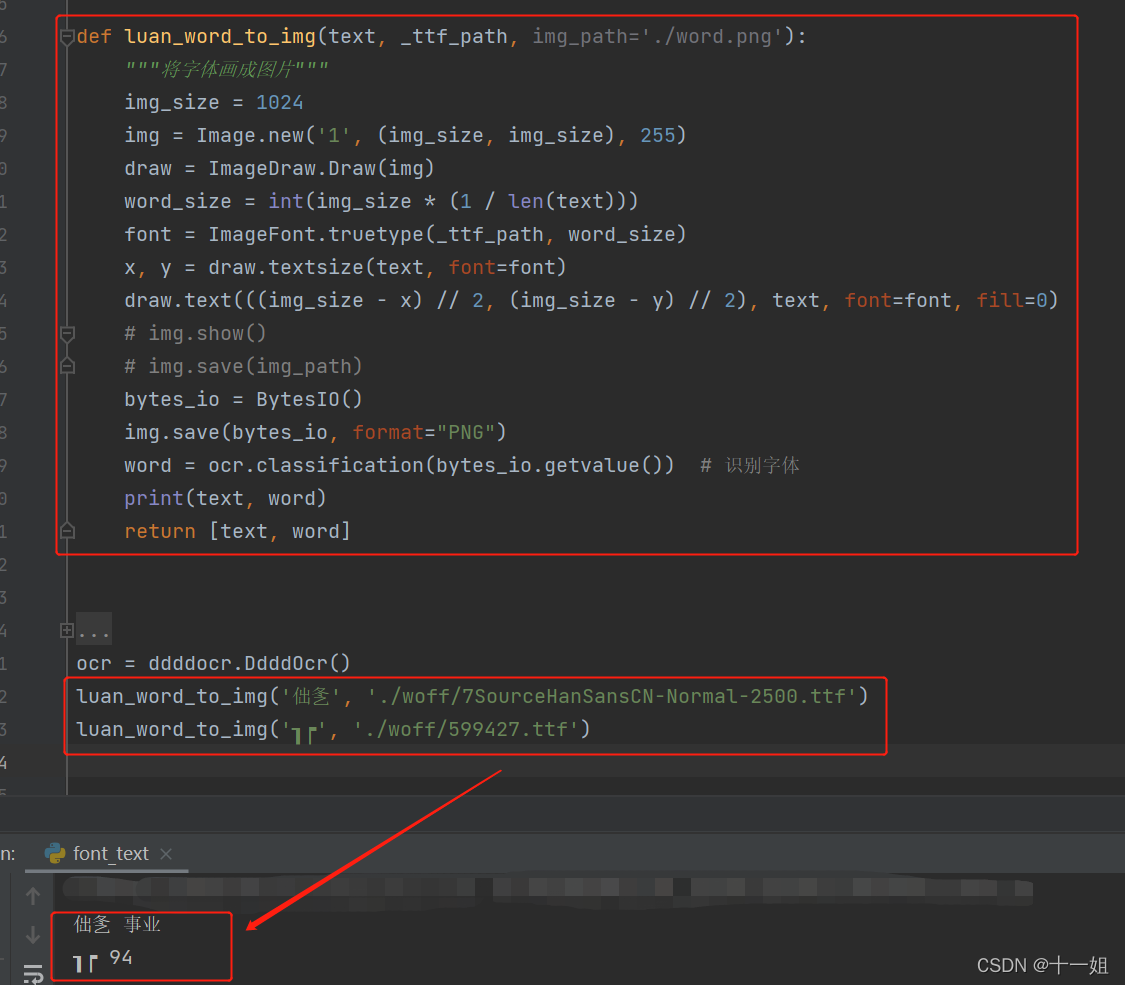
-
本案例通过观察有个特别的方案,如图
事其实对应的是乱码串㑁,而ord('㑁')结果其实就是13377,而13377其实就是ttf里面识别出来的cmap_code码;也就是说cmap_code码=ord('㑁'),网页上看到的乱码汉字都是chr(cmap_code)码转换而得
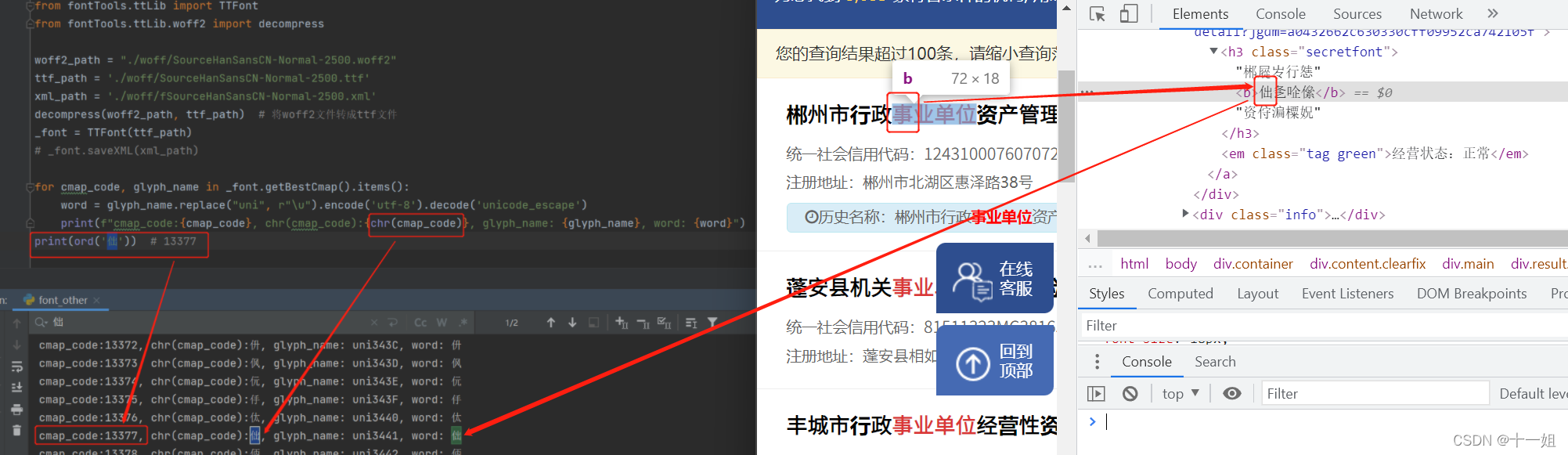
-
此案例看ttf文件,会发现ttf文件里面不仅存了乱码的字,还存了真实的字,真实字在后半部分,乱码字在前半部分,所以即使ttf文件是动态的,这个方法也是能匹配到对应的真实值的
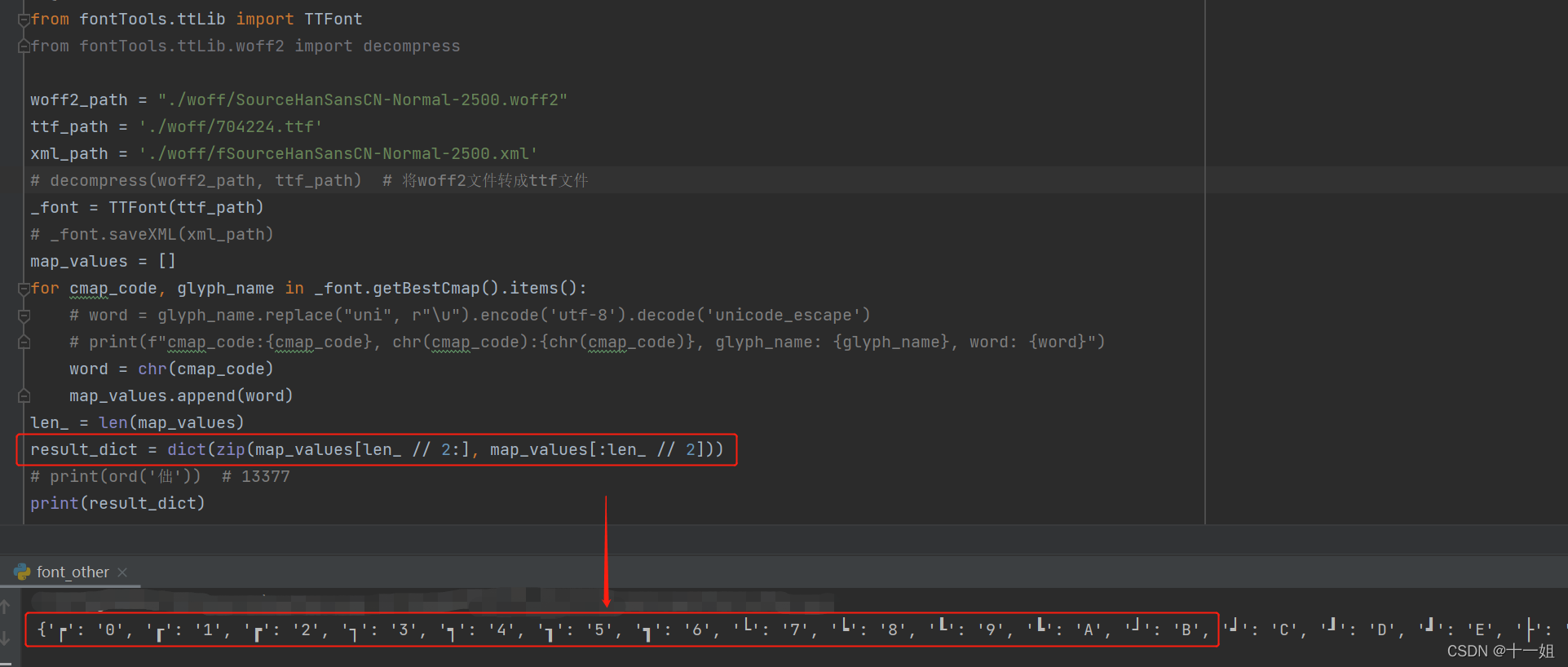
-
后面只要源码response.text替换下,即可得到如下识别结果
