今天看到一个很有意思的高频面试题,其中的内容确确实实很有意思,下面我们来聊聊,先来看几道面试题,试试水平;
目录
目前来看,关于 new String("xxx") 创建对象个数的答案有 3 种:
面试题类型1:
分别执行下面代码:请回答执行他们的过程中总共创建了几个字符串对象?
代码一:new String("xxx");//一个或两个
代码二:String str = "abc" + "def";//0个或一个
代码三:String s=new String(“xxx”);//一个或两个
代码四:String str = "abc" + new String("xxx");//5个
面试题类型2:
回答如果执行下列代码,分别返回的结果都是什么?
String s1 = "Java";
String s2 = "Java";
System.out.println(s1 == s2);//trueString s1 = "abc";
String s2 = new String("abc");
System.out.println(s==s1);//false
String s1 = new String("javaer-wang");
String s2 = new String("javaer-wang");
System.out.println(s1 == s2);//falseString s1 = "abc";
String s2 = new String("def");
String s3 = s1 + s2;
String s4 = "abcdef";
System.out.println(s3==s4); //false解释:
接下来我们一边解释面试题,一边总结相关知识点;
目前来看,关于 new String("xxx") 创建对象个数的答案有 3 种:
- 有人说创建了 1 个对象;
- 有人说创建了 2 个对象;
- 有人说创建了 1 个或 2 个对象。
而出现多个答案的关键争议点在 【字符串常量池 】上,有的说 new 字符串的方式会在常量池创建一个字符串对象,有人说 new 字符串的时候并不会去字符串常量池创建对象,而是在调用 intern() 方法时,才会去字符串常量池检测并创建字符串,那么实际情况是怎样的呢?我们接下来慢慢聊。。。。
首先回顾「字符串常量池」:
- 字符串的分配和其他的对象分配一样,需要耗费高昂的时间和空间为代价,如果需要大量频繁的创建字符串,会极大程度地影响程序的性能,因此 JVM 为了提高性能和减少内存开销引入了字符串常量池(Constant Pool Table)的概念。
- 字符串常量池相当于给字符串开辟一个常量池空间类似于缓存区,对于直接赋值的字符串(String s="xxx")来说,在每次创建字符串时优先使用已经存在字符串常量池的字符串,如果字符串常量池没有相关的字符串,会先在字符串常量池中创建该字符串,然后将引用地址返回变量,如下图:
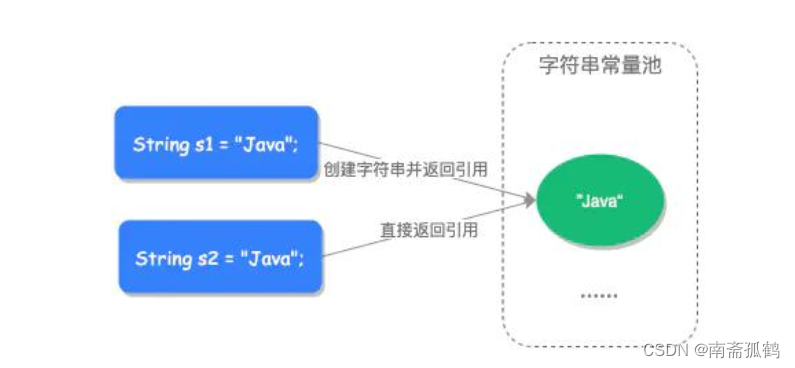
下面我们看看JVM是如何处理面试题类型一中的前两个代码的:
JVM如何执行String s="abc";
JVM在执行String s="abc"时,会先在常量池中查找是否存在"abc"这个字符串,如果存在,则将s1指向该字符串;如果不存在,则在常量池中创建一个新的字符串"abc",然后将s指向该字符串。如果在后续的代码中使用了相同的字符串字面量,JVM会重用之前创建的String对象,而不是创建新的对象。
JVM如何执行new String("abc");
当执行 new String("abc") 时,JVM 会首先在常量池中查找是否已经存在 "abc" 这个字符串,如果存在,则直接返回该字符串的引用;如果不存在,则在堆中创建一个新的 String 对象,并将 "abc" 这个字符串的引用赋值给该对象。同时,该对象会被添加到常量池中,以便下次使用时直接返回该对象的引用。
你也可以这样理解;new String("abc")相当于new String(String s1="abc"),即先要执行String s1="abc",然后再在堆区new一个String对象。
因此,现在可以解答本文的标题了,String s=new String("abc")创建了1或2个对象,String s="abc"创建了0或1个对象。
我在博客上看到一位博主对以上执行过程分析为:
String s="abc"会先从字符串常量池(下文简称常量池)中查找,如果常量池中已经存在"abc",而"abc"必定指向堆区的某个String对象,那么直接将s指向这个String对象即可;
我并不认可这句话(仅仅代表我的观点),下面我们用例子来证明我的观点;
按照以上说法;下列代码返回的值应该为true,我们实际执行看结果;
String s2="abc";
String s1=new String("abc");
String s3=new String("abc");
System.out.println(s1==s2);//false
System.out.println(s1==s3);//false我们再次通过一个例子更加贴切的理解一下该过程(我们在看一个例子):
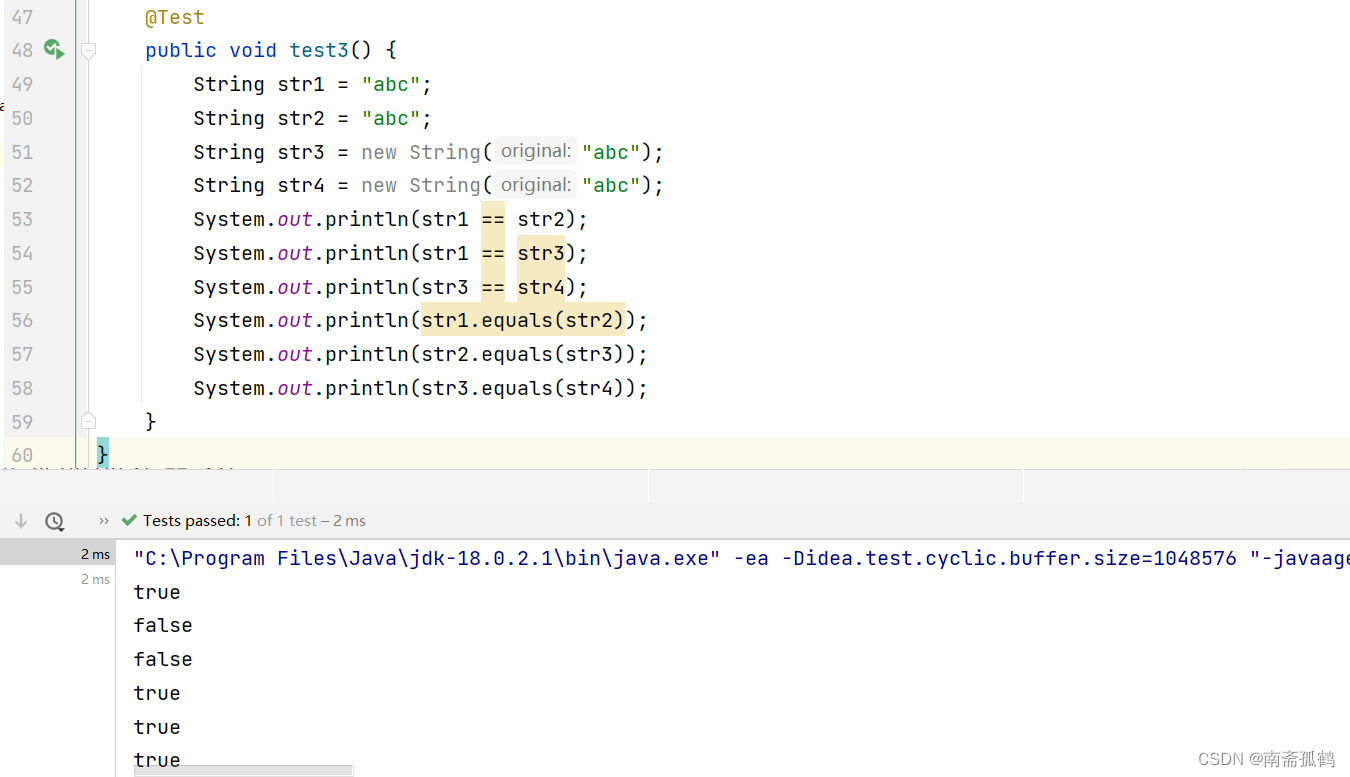
底层原理图与原理我们用画图来解释;

String类型的数据都存放在常量池,堆中的属性只存放常量池中值的地址!
① String str1 = "abc";语句是直接创建了字符串,是构造字符串最常用的方式。这种直接赋值的方式,并没有用new关键字在堆中开辟新的地址,而是在常量池中开辟了地址。所以引用str1的内容是常量池中abc字符串的地址0x01。
② String str2 = "abc";也是直接创建了字符串。但是因为String是特殊的引用类型,其存放在常量池的内容是不可变的。在创建一个字符串对象时,会先在常量池中查询是否已存在,若不存在则再开辟新的存储空间。此时str2所引用的对象abc和str1是一样的,所以这是常量池中已经存在的内容。Str2会直接引用常量池中这个已经存在的字符串对象。所以str2的内容也是常量池中abc字符串的地址0x01。
③ String str3 = new String("abc");语句用new在堆中开辟了空间,是通过创建对象来创建字符串的。str3指向堆中一个新的空间的地址0x02,此空间中存放String对象的属性值。同样的,此属性值在赋值为"abc"时,会先在常量池中查询是否已存在此内容。此时常量池中已经存在了abc,所以属性值存储的是常量池中abc的地址0x01。
④ String str4 = new String("abc");语句也是用nuw在堆中开辟了空间,利用创建新对象来创建字符串。str4指向堆中一个新的空间的地址0x03,此空间中存放String对象的属性值。同样的,此属性值在赋值为"abc"时,会先在常量池中查询是否已存在此内容。此时常量池中已经存在了abc,所以属性值存储的是常量池中abc的地址0x01。
⑤ 如果通过创建新的对象来创建字符串,发现常量池中没有已存在的字符串;那么JVM会继续在常量池中开辟一个新的空间并把值存放在其中,而堆中的属性值为此空间的地址。
然后我们来解释一下一下代码:
代码二:String str = "abc" + "def";//0个或一个
代码四:String str = "abc" + new String("xxx");//5个
对于代码二中,如果你不知道他的底层实现,你估计会首先想到String str = "abc" + "def"执行过程中首先创建了两个对象“abc”和“def”然后在进行拼接最后构成第三个对象str;然而实际并不是这样,对于我们的JVM频繁的创建对象是很浪费内存和时间的,那么JVM是如何处理使用“+”进行的字符串拼接的呢?
底层实现:用+操作符拼接字符串,会产生一个中间对象,如果是线程安全的环境,我们会用StringBuffer拼接字符串,线程不安全的环境则使用StringBuilder。
总结:上面的问题涉及到字符串常量重载“+”的问题,当一个字符串由多个字符串常量拼接成一个字符串时,它自己也肯定是字符串常量。字符串常量的“+”号连接Java虚拟机会在程序编译期将其优化为连接后的值。就上面的示例而言,在编译时已经被合并成“abcdef”字符串,因此,只会创建1个对象(你也可以说是两个,因为还可以加上stringbuffer或stringbuilder)。并没有创建临时字符串对象abc和def,这样减轻了垃圾收集器的压力 ;
引入一个知识点:
JVM在编译我们自己写的代码时,会将我们写的代码进行优化
理解了上述例子,那么第四个例子也就好理解了:
上述的代码Java虚拟机在编译的时候同样会优化,会创建一个StringBuilder来进行字符串的拼接,实际效果类似:
String s = new String("def");
new StringBuilder().append("abc").append(s).toString();很显然,多出了一个StringBuilder对象,那就应该是5个对象。
此时,你也或许有这样的疑问,StringBuilder最后toString()之后的“abcdef”难道不在常量池存一份吗?这个还真没有存,我们来看一下这段代码:
String s1 = "abc";
String s2 = new String("def");
String s3 = s1 + s2;
String s4 = "abcdef";
System.out.println(s3==s4); // false按照上面的分析,如果s1+s2的结果在常量池中存了一份,那么s3中的value引用应该和s4中value的引用是一样的才对。但是结果却大相径庭,他并没有存到常量池中而是存到了堆内存中,上述代码会证明此观点;
为什么会这样呢?我们记以下概念:
仅有使用引号包含文本的方式创建的string对象之间使用“+”连接的新对象才会被加入到字符串常量池中,而对于包含new string()或null“+”字符串的连接方式产生的新对象不会被添加到字符串常量池中;
验证上述概念:
/*
String s5="qwe"+"asd";
String s6="qweasd";
System.out.println(s5==s6);//true
*/
String s5="qwe"+new String("asd");
String s6="qweasd";
System.out.println(s5==s6);//false继续总结:
String的两种初始化形式是有本质区别的。
String str1 = "abc"; // 在常量池中
String str2 = new String("abc"); // 在堆上
新知识引入:
使用+拼接字符串的实现原理
前面提到过,使用+拼接字符串,其实只是Java提供的一个语法糖,看看他的内部原理到底是如何实现的。还是这样一段代码。我们把他生成的字节码进行反编译,看看结果。
String a = "Hello";
String b = "world";
String c = a + "," + b;反编译后的内容如下:
String a = "Hello";
String b = "world";
String c = (new StringBuilder()).append(a).append(",").append(b).toString();通过查看反编译以后的代码,我们可以发现,原来字符串常量在拼接过程中,是将String转成了StringBuilder后,使用其append方法进行处理的。也就是说 +和StringBuilder的append等价,
也就是说使用+拼接字符串的实现原理就是使用StringBuilder.append。
其实偶尔看看Java知识点的底层实现也是很有意思的,希望大家在学习中能够拥有刨根问底的学习精神;
我很清楚自己想要什么,想成为什么,该怎么做,如何做。但我无法打败自己,所以迄今为止我还是我;
——