zstarling
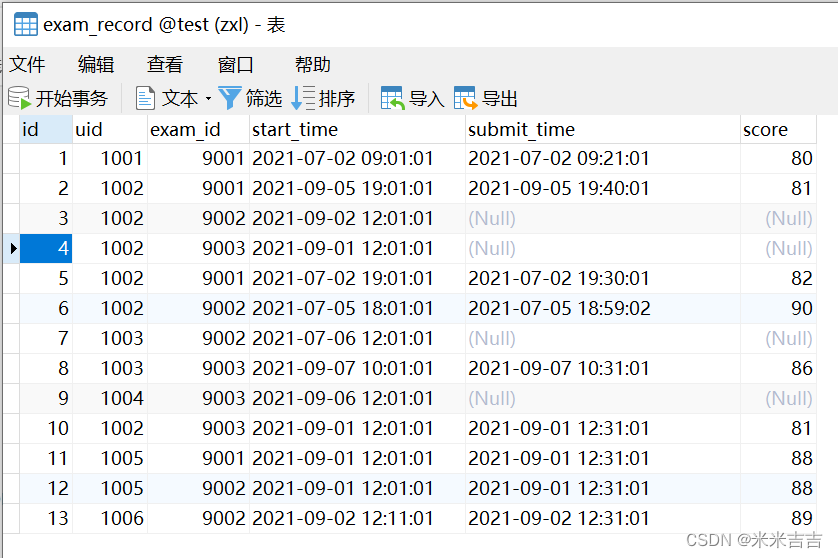
表数据
drop table if exists examination_info,exam_record;
CREATE TABLE exam_record (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int NOT NULL COMMENT '用户ID',
exam_id int NOT NULL COMMENT '试卷ID',
start_time datetime NOT NULL COMMENT '开始时间',
submit_time datetime COMMENT '提交时间',
score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1001, 9001, '2021-07-02 09:01:01', null, null),
(1002, 9003, '2021-09-01 12:01:01', '2021-09-01 12:21:01', 60),
(1002, 9002, '2021-09-02 12:01:01', '2021-09-02 12:31:01', 70),
(1002, 9001, '2021-09-05 19:01:01', '2021-09-05 19:40:01', 81),
(1002, 9002, '2021-07-06 12:01:01', null, null),
(1003, 9003, '2021-09-07 10:01:01', '2021-09-07 10:31:01', 86),
(1003, 9003, '2021-09-08 12:01:01', '2021-09-08 12:11:01', 40),
(1003, 9001, '2021-09-08 13:01:01', null, null),
(1003, 9002, '2021-09-08 14:01:01', null, null),
(1003, 9003, '2021-09-08 15:01:01', null, null),
(1005, 9001, '2021-09-01 12:01:01', '2021-09-01 12:31:01', 88),
(1005, 9002, '2021-09-01 12:01:01', '2021-09-01 12:31:01', 88),
(1005, 9002, '2021-09-02 12:11:01', '2021-09-02 12:31:01', 89);
共计13行,表建立语句可点击
基本语法
- 执行顺序是先partition by 后再对组内的值进行order By,然后在组内根据range(并入计算)\rows(非并入计算)依次从上到下或者从下到上(由preceding和following决定)的聚合函数解。
- 窗口函数的执行顺序是在where子句或者group by之后。
function(expression)
over (
partition by column
order by column ASC/DESC
rows/range [...]
)
function函数
SELECT
*,
-- 排序
Row_NUMBER() over ( PARTITION BY uid ORDER BY score ) AS rn,
Rank() over ( PARTITION BY uid ORDER BY score ) AS rk,
DENSE_RANK() over ( PARTITION BY uid ORDER BY score ) AS drk,
-- 聚合
sum(score) over ( PARTITION BY uid ) AS sum1,
sum(score) over ( PARTITION BY uid ORDER BY score ) AS sum2,
sum(score) over ( PARTITION BY uid ORDER BY score RANGE BETWEEN unbounded preceding and current row) AS sum3,
sum(score) over ( PARTITION BY uid ORDER BY score ROWs BETWEEN unbounded preceding and current row) AS sum4,
sum(score) over ( PARTITION BY uid ORDER BY score DESC) AS sum5,
-- sum(score) over ( PARTITION BY uid ORDER BY score RANGE BETWEEN current row AND ubounded following) AS sum6,
-- sum(score) over ( PARTITION BY uid ORDER BY score desc ubounded preceding and current row) AS sum7,
-- 向前向后取整
LOG(score) over (PARTITION by uid ORDER BY score) lag1,
LOG(score,1,0) over (PARTITION by uid ORDER BY score) lag1,
lead(score) over (PARTITION by uid ORDER BY score) lead1,
-- FIRST_VALUE(expr),LAST_VALUE(expr)
FIRST_VALUE(score) over (PARTITION by uid ORDER BY score) as first,
last_VALUE(score) over (PARTITION by uid ORDER BY score rows BETWEEN unbounded preceding and unbounded following) as last,
-- 分析函數
AVG(score) over (PARTITION by uid ORDER BY score) avg1,
count(uid) over (PARTITION by uid ORDER BY score) ct1,
count(*) over (PARTITION by uid ORDER BY score) ct2,
max(score) over (PARTITION by uid ORDER BY score) max1,
min(score) over (PARTITION by uid ORDER BY score) min1,
median() over (PARTITION by uid ORDER BY score) median1
FROM
exam_record;
上述仅仅作为函数展示,若是全部运行会因为排序紊乱报错。故验证时可只保留一个函数验证,或者对排序做主次之分。
排序
SELECT
uid,
score,
-- ROW_NUMBER() over () AS rn1, -- 默认显示原始表的位置
ROW_NUMBER() over ( ORDER BY score ) AS rn2,-- 不分组整体排序
ROW_NUMBER() over ( PARTITION BY uid ORDER BY score ) AS rn3,
RANK() over ( PARTITION BY uid ORDER BY score ) AS rk,
DENSE_RANK() over ( PARTITION BY uid ORDER BY score ) AS drk
FROM
exam_record;
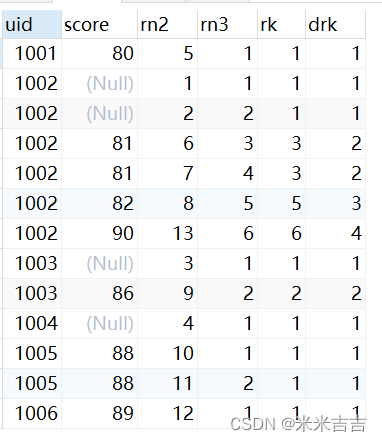
ROW_NUMBER():值相同时,不同名次。
RANK() :值相同时,同名次且不连续
DENSE_RANK() :值相同时,同名次且连续
上述三个()均不含参数
partition by 和group by区别
SELECT
uid,
SUM( score )
FROM
exam_record
GROUP BY
uid;
SELECT
uid,
SUM( score ) over ( PARTITION BY uid )
FROM
exam_record;
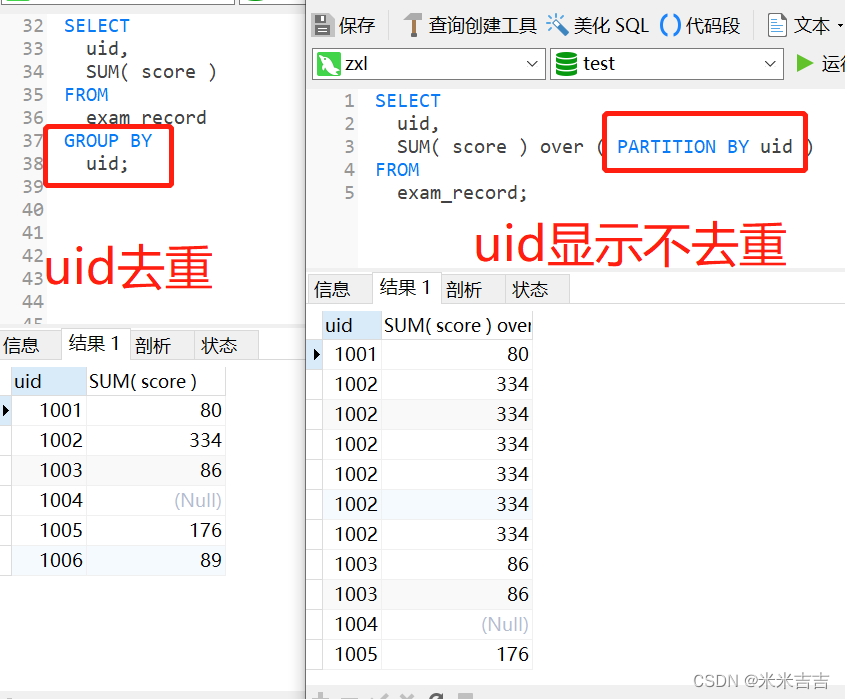
左表仅显示去重后的6行,右表显示全部的13行(图片未截全结果显示)
上述可以看出group by会显示去重后的分组列(分组列结果显示行值是唯一值),而partition by 会显示每一个元素的值(多少个元素还是多少个行)。
窗口函数与聚合函数的区别:聚合函数会将一组数据聚合后仅显示一个结果,但是窗口函数会显示每一行的聚合结果。
partition by 示例
SELECT
uid,
SUM( score ) over ()
FROM
exam_record;
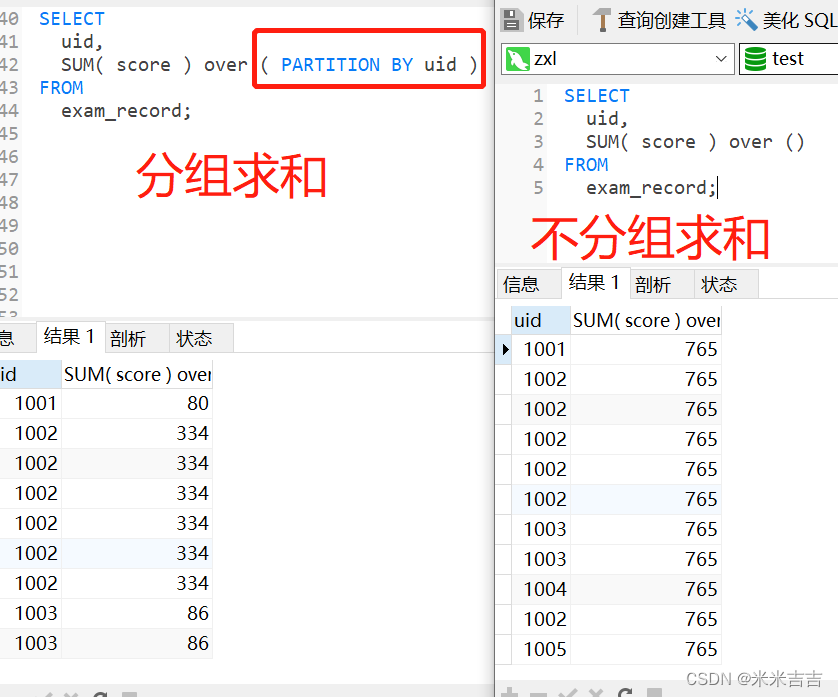
左表和右表显示全部的13行(图片未截全结果显示),区别在与左表为分组后的组内值的和,右表为所有值的和。
order by
会依据order by后字段的值是否相同决定计算方法,若为range ,则执行字段内相同值时会并入计算,不同值时会累计计算的原则。
综上下述三个对比(由于默认是range,故以下均为range计算原则),可发现执行顺序是先partition by 后再对组内的值进行order By,然后在组内依次累计和并入求聚合函数解。
max,min
SELECT *,
max(score) over (PARTITION by uid ORDER BY uid DESC) max1,
max(score) over (PARTITION by uid ORDER BY score DESC) max2,
max(score) over (PARTITION by uid ORDER BY score ) max3
from exam_record;
order后不同列字段uid和score对比1
](https://img-blog.csdnimg.cn/3b05d9aa2e4f452abf91638fb44ada27.png)
part1与part2结果相同,但是计算方式不同:
左表按照uid降序排列,由于uid值相同,故组内并入计算,整体(81,82,90,81)求max90;
右表按照score降序排序,(90)max为90,(90,82)max为90,两个81值相同,并入计算(90,82,81,81)max为90,两个空值,(90,82,81,81,)max为90。
order后列字段相同时(例uid)升降序的对比2

part1与part2结果相同,但是左表按照uid升序排列,右表按照uid降序排列。由于uid的值无区别,故结果相同。
order后列字段相同,列值不同时(例score)升降序的对比3
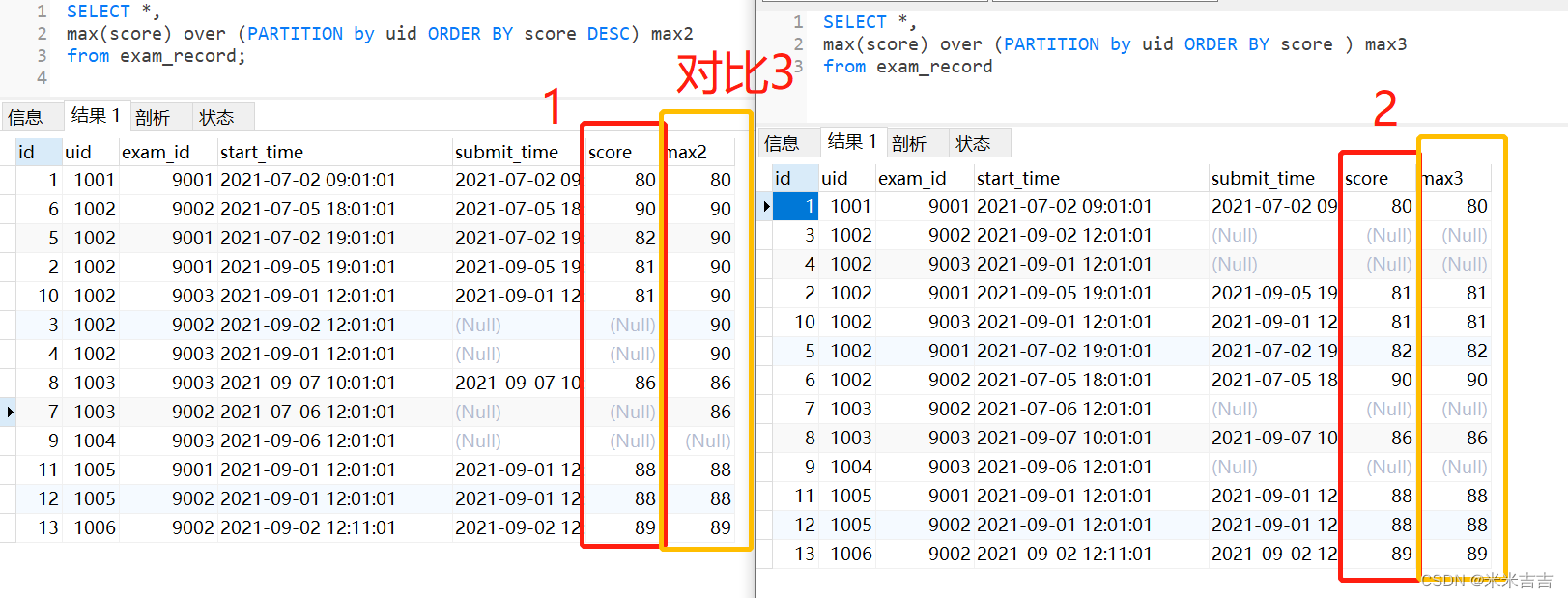
part1与part2结果不同,但是左表按照score降序排列,右表按照score升序排列。由于score的值不同,此时的结果受order by后的列值升降序的影响。两者都可以理解为在各个uid组内,进行了累计求最大值,但是由于升降序的问题,part2部分中uid=1002的升序排列时,两个81,并入计算(81,81)max为81,(81,81,82)max为82,(81,81,82,90)max为90,此时才是组内最大值。
整体对比
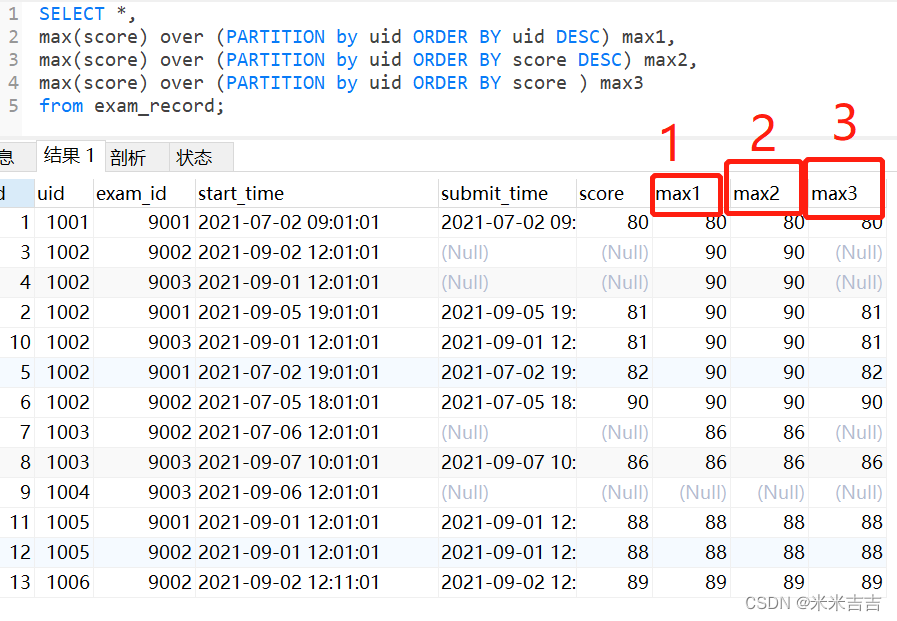
score的排序以最后一次(part3)的排序为准,所以part3的结果与其他部分不同。
avg
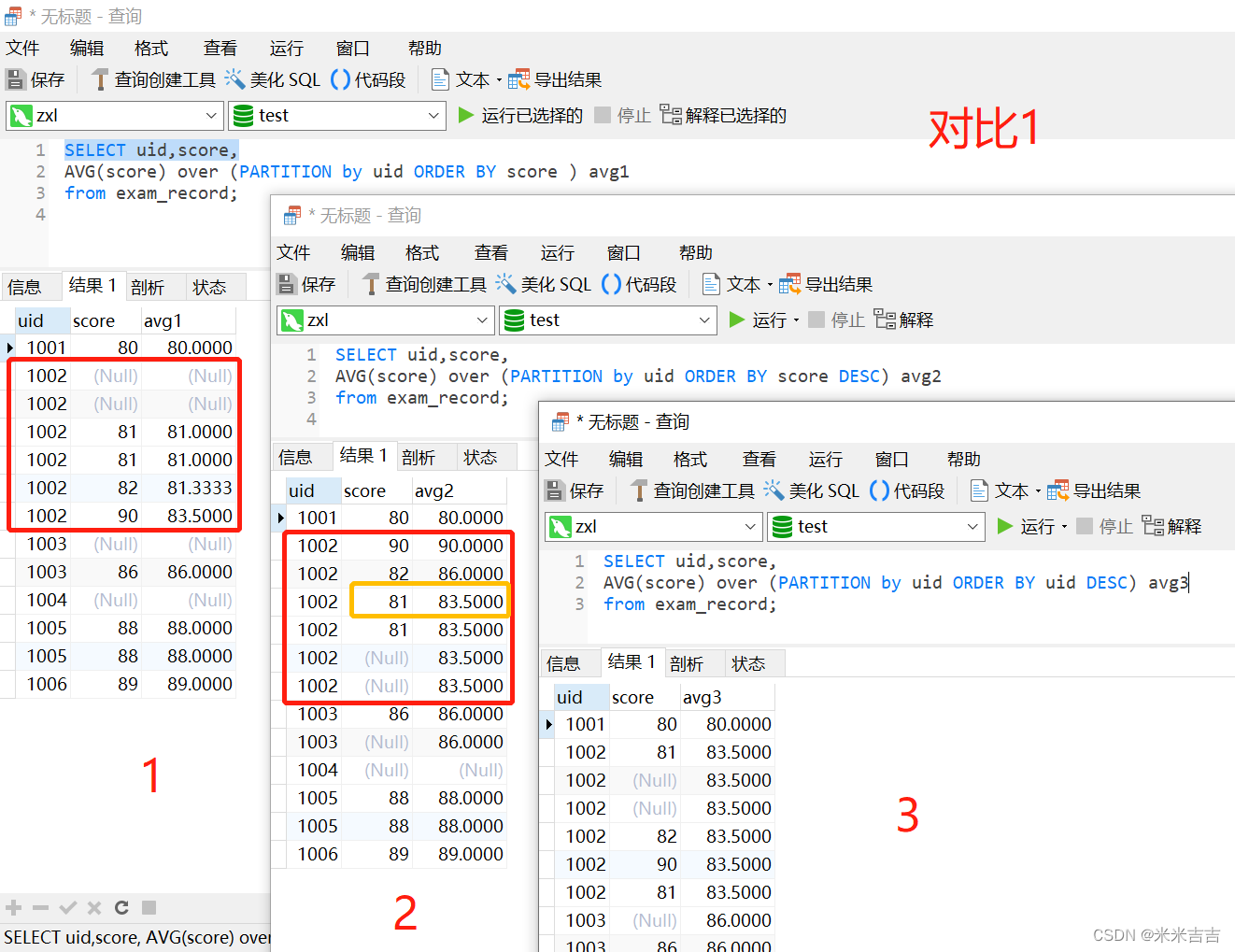
part1:先依据uid分组,再根据order by后的列score升序排序,对分组后uid的所有score累计求avg。
part2:先依据uid分组,再根据order by后的列score降序排序,对分组后uid的score依次累计求avg,但是黄框部分由于81出现两次,并非是(90,82,81)的avg值84.333。而是并入计算(90,82,81,81)的avg值83.5。
part3:先依据uid分组,再根据order by后的列uid排序,由于组内uid相同,故对分组后uid的所有score求avg值相同。
sum
SELECT
uid,
score,
SUM(score) over ( ORDER BY score ) AS sum1,
SUM(score) over ( PARTITION BY uid ORDER BY score DESC ) AS sum2,
SUM(score) over ( PARTITION BY uid ORDER BY score ) AS sum3,
SUM(score) over ( PARTITION BY uid ORDER BY uid ) AS sum4
FROM
exam_record;
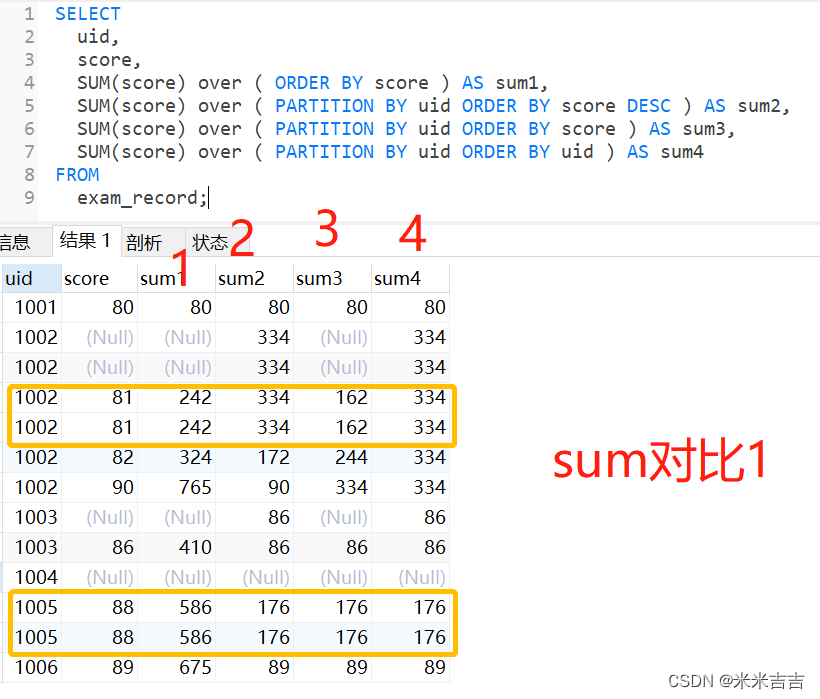
score按照最后一次求和执行的升序排列。
part1,不分组求和,相同值时会并入计算,不同值时累计计算。
part2,分组降序求和,score相同值时会并入计算,不同值时累计计算。
part3,分组升序求和,score相同值时会并入计算,不同值时累计计算。
part4,分组整体求和,uid值相同,并入计算。
rows/range
默认值与二者区别
SELECT
uid,
score,
sum( score ) over ( PARTITION BY uid ) AS sum1,
sum( score ) over ( PARTITION BY uid ORDER BY score ) AS sum2,
sum( score ) over ( PARTITION BY uid ORDER BY score RANGE BETWEEN unbounded preceding AND current ROW ) AS sum3,
sum( score ) over ( PARTITION BY uid ORDER BY score ROWs BETWEEN unbounded preceding AND current ROW ) AS sum4
FROM
exam_record;
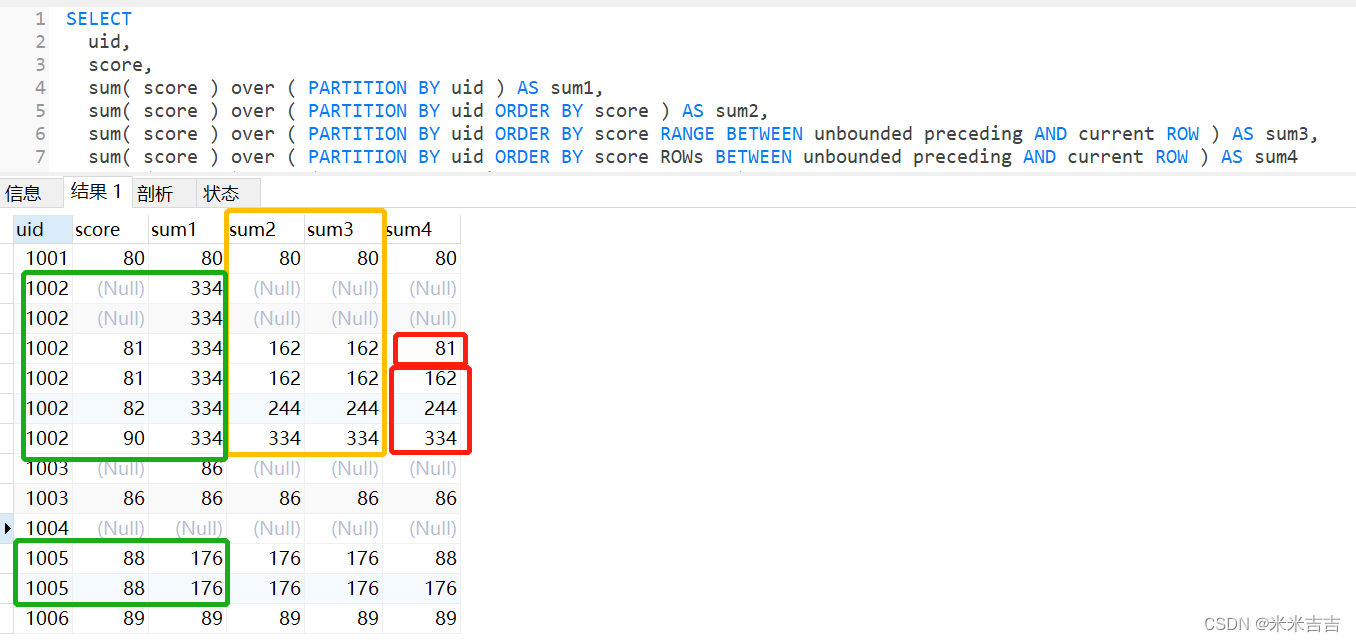
绿框sum1,uid值相同,组内并入计算。
黄框结果相同,表示默认值是range between unbounded preceding and current row。
红框对比range和rows的区分,range会并入计算,row不并入计算,依次按照累计值计算。
unbounde,preceding,following含义
语法:
- CURRENT ROW:当前行,偏移量为0
- n PRECEDING:当前行往前n行数据 N为:相对当前行向前的偏移量
- n FOLLOWING:当前行往后n行数据 N为:相对当前行向后的偏移量
- UNBOUNDED:起点,也可以解释为无界限
- UNBOUNDED PRECEDING 表示从第一行的起点
- UNBOUNDED FOLLOWING表示到最后一行的终点
- BETWEEN unbounded preceding AND current ROW:从起点到终点(eg:sum6,sum8)
- BETWEEN current ROW AND unbounded following:从终点到起点。(eg:sum7,sum9)
起点到终点,终点到起点
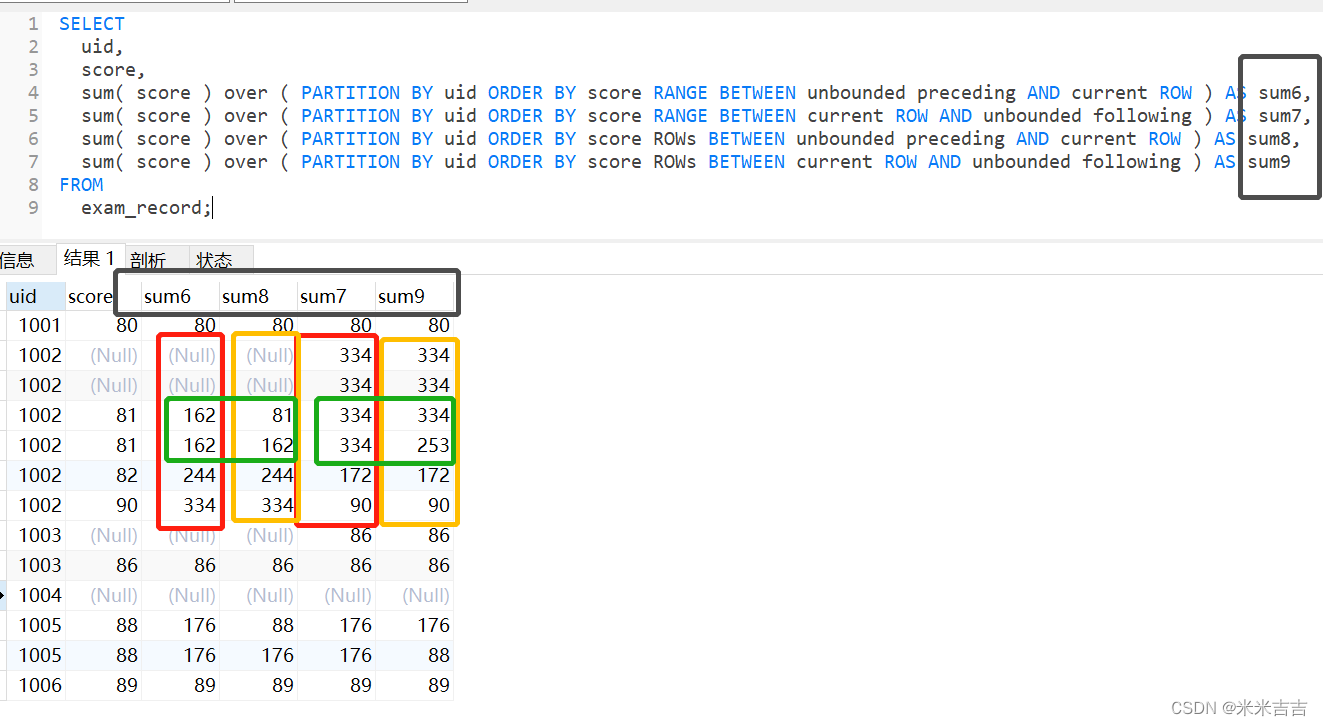
- 红框和黄框表示在score排序方式不变的情况下,针对range和rows各自从上到下和从下到上的计算方式。左边为从上到下的计算,右边为从下到上的计算。
- 绿框验证了range和rows的不同。
- 注意:上述字段顺序和SQL中的执行顺序有所调整,需要对照字段名解读。
指定行数
SELECT
uid,
score,
sum( score ) over ( PARTITION BY uid ORDER BY score Rows 1 preceding ) AS sum10,
-- sum( score ) over ( PARTITION BY uid ORDER BY score Rows 1 following ) AS sum11,
sum( score ) over ( PARTITION BY uid ORDER BY score Rows BETWEEN 1 preceding AND 1 following ) AS sum12
FROM
exam_record;
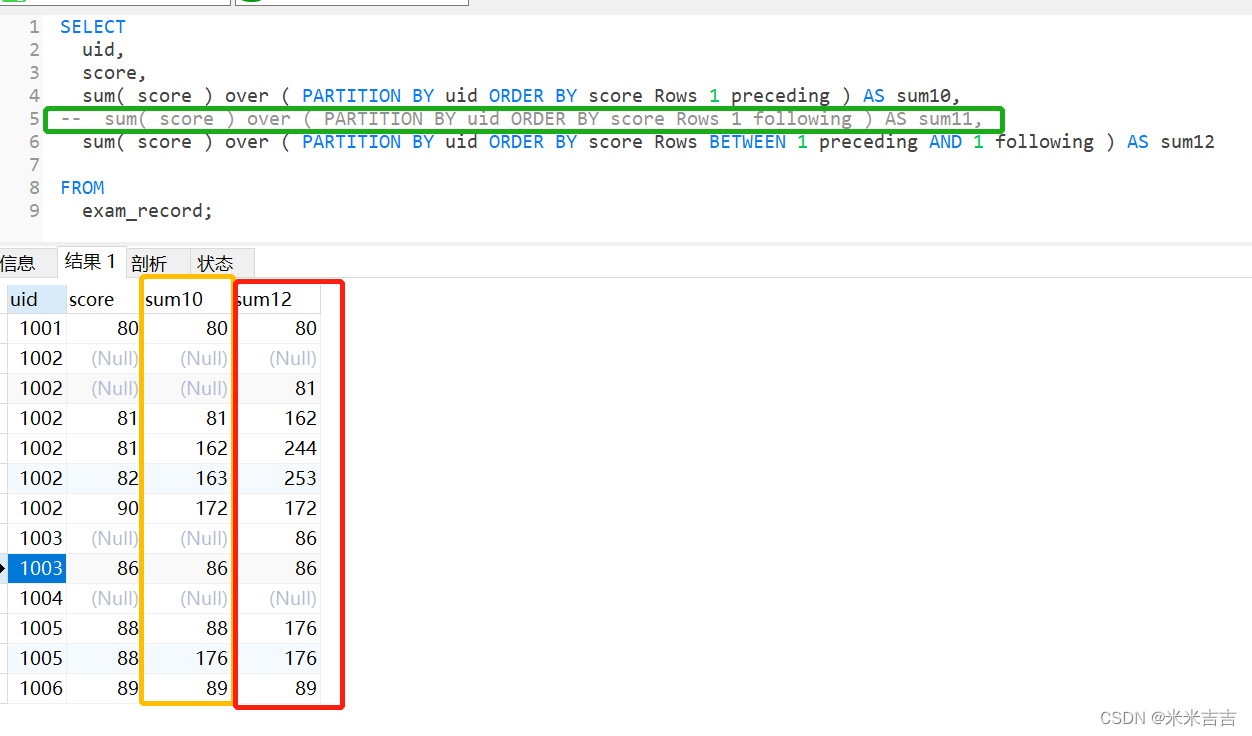
- sum10为当前行与前一行之和,即sum(n-1,n)
- sum12为指定当前行的前后1行之和,即sum(n-1,n,n+1)
- sum11的写法报错。说明following只适用于between…and…句型。原因可参考下面大佬的解释。

等价写法
SELECT
uid,
score,
sum( score ) over ( PARTITION BY uid ORDER BY score ) AS sum2,
sum( score ) over ( PARTITION BY uid ORDER BY score DESC ) AS sum5,
sum( score ) over ( PARTITION BY uid ORDER BY score DESC RANGE BETWEEN unbounded preceding AND current ROW ) AS sum6,
sum( score ) over ( PARTITION BY uid ORDER BY score RANGE BETWEEN current ROW AND unbounded following ) AS sum7
FROM
exam_record;
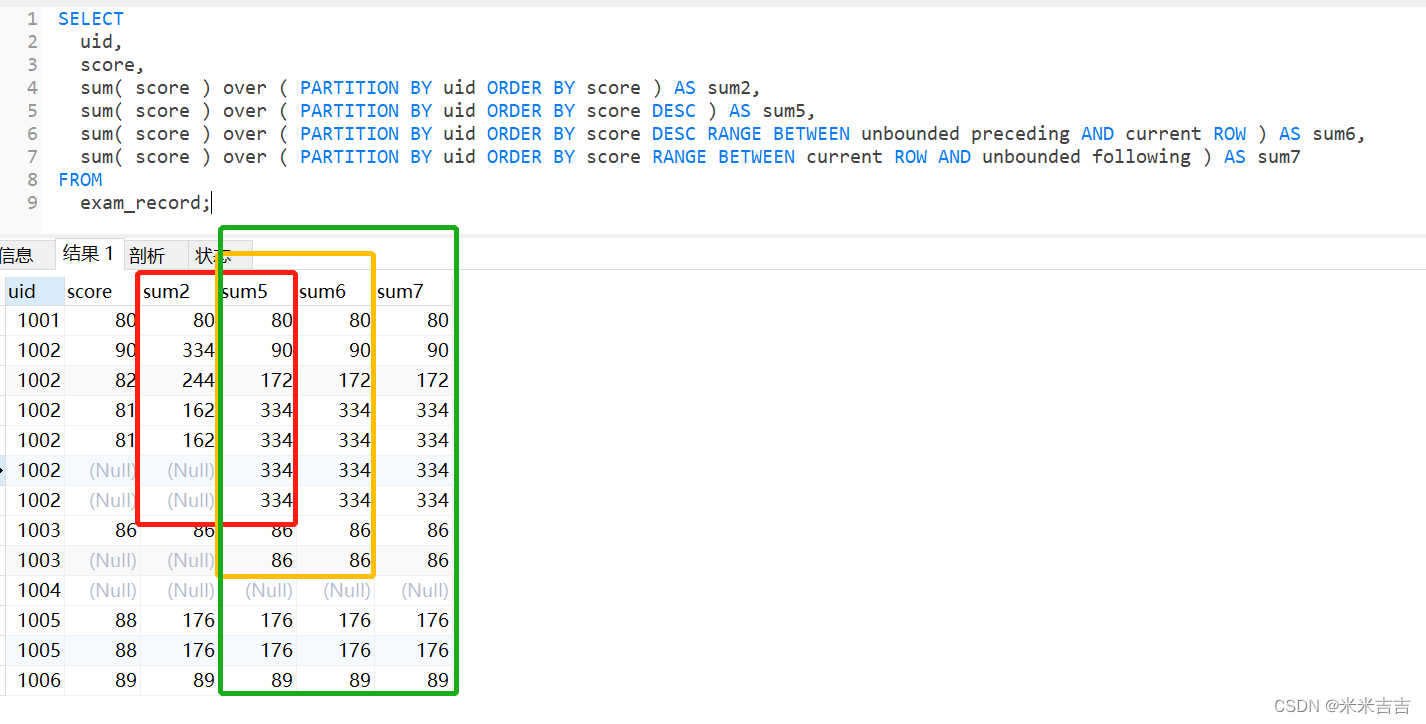
红框为score 升降序的不同结果。
黄框验证了 默认值是range between unbounded preceding and current row。
绿框表示了三种不同形式的写法,三者之间等价。