1. PyTorch常用函数
(1)路径相关的函数
假设我们数据集的目录结构如下:
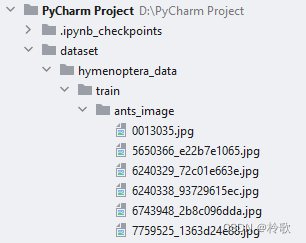
首先需要 import os,在 os 中常用的路径相关的函数有:
os.listdir(path):将path目录下的内容列成一个list。os.path.join(path1, path2):拼接路径:path1\path2。
例如:
import os
dir_path = 'dataset/hymenoptera_data/train/ants_image'
img_path_list = os.listdir(dir_path)
img_full_path = os.path.join(dir_path, img_path_list[0])
print(img_path_list) # ['0013035.jpg', '1030023514_aad5c608f9.jpg', ...]
print(img_full_path) # dataset/hymenoptera_data/train/ants_image\0013035.jpg
(2)辅助函数
dir():不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。help(func):查看函数func的使用说明。
例如:
import torch
print(dir(torch)) # ['AVG', 'AggregationType', ..., 'cuda', ...]
help(torch.cuda.is_available) # Help on function is_available in module torch.cuda: is_available() -> bool...
2. 数据加载
PyTorch 数据集(Dataset)的数据读取和预处理是进行机器学习的首要操作,PyTorch 提供了很多方法来完成数据的读取和预处理。
(1)Dataset:torch.utils.data.Dataset 是代表这一数据的抽象类。你可以自己定义你的数据类,继承和重写这个抽象类,非常简单,只需要定义 __len__ 和 __getitem__ 这个两个函数即可,例如:
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir + '_image')
self.img_path_list = os.listdir(self.path)
def __getitem__(self, idx):
img_path = self.img_path_list[idx]
img_full_path = os.path.join(self.root_dir, self.label_dir + '_image', img_path)
img = Image.open(img_full_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path_list)
root_dir = 'dataset/hymenoptera_data/train'
ants_label_dir = 'ants'
ants_data = MyData(root_dir, ants_label_dir)
img, label = ants_data[0]
print(img, label)
img.show()
通过上面的方式,可以定义我们需要的数据类,可以通过迭代的方式来获取每一个数据,但这样很难实现取 batch、shuffle 或者是多线程去读取数据。
(2)DataLoader:torch.utils.data.DataLoader 构建可迭代的数据装载器,我们在训练的时候,每一个 for 循环,每一次 iteration,就是从 DataLoader 中获取一个 batch_size 大小的数据的。打个比方如果 Dataset 是一副完整的扑克牌,那么 DataLoader 就是抽取几张组成的一部分扑克牌。
学习 DataLoader 之前需要先学一下 Transform:PyTorch学习笔记-Transform。
DataLoader 的参数很多,但我们常用的主要有以下几个:
dataset:Dataset 类,决定数据从哪读取以及如何读取。batch_size:批大小。num_works:是否多进程读取机制。shuffle:每个 Epoch 是否乱序。drop_last:当样本数不能被batch_size整除时,是否舍弃最后一批数据。
要理解这个 drop_last,首先,得先理解 Epoch、Iteration 和 Batch_size 的概念:
- Epoch:所有训练样本都已输入到模型中,称为一个 Epoch。
- Iteration:一批样本输入到模型中,称为一个 Iteration。
- Batch_size:一批样本的大小,决定一个 Epoch 有多少个 Iteration。
DataLoader 的作用就是构建一个数据装载器,根据我们提供的 batch_size 的大小,将数据样本分成一个个的 batch 去训练模型,而这个分的过程中需要把数据取到,这个就是借助 Dataset 的 __getitem__ 方法。
例如:
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir, transform):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir + '_image')
self.img_path_list = os.listdir(self.path)
self.transform = transform # transform 的方式
def __getitem__(self, idx):
img_path = self.img_path_list[idx]
img_full_path = os.path.join(self.root_dir, self.label_dir + '_image', img_path)
img = Image.open(img_full_path).convert('RGB') # 先将图片转换成三通道
if self.transform is not None:
img = self.transform(img)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path_list)
root_dir = 'dataset/hymenoptera_data/train'
ants_label_dir = 'ants'
trans_dataset = transforms.Compose([
transforms.Resize((83, 100)), # tensor 大小必须统一
transforms.ToTensor()
])
ants_data = MyData(root_dir, ants_label_dir, trans_dataset)
train_loader = DataLoader(dataset=ants_data, batch_size=10, shuffle=True, num_workers=0, drop_last=False)
for i, data in enumerate(train_loader):
img, label = data
print(type(img))
print(img[0])
print(label)
print(label[0])
以下即为一个 batch 的信息,img 中包含 batch_size 个图像,label 中包含 batch_size 个标签分别对应每个图像:

接下来使用 CIFAR10 数据集再展示一次 DataLoader 的用法,数据集的使用可以见:PyTorch学习笔记-Torchvision数据集使用方法:
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_set = datasets.CIFAR10(root='dataset/CIFAR10', train=False, transform=transforms.ToTensor())
test_loader = DataLoader(dataset=test_set, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
writer = SummaryWriter('logs')
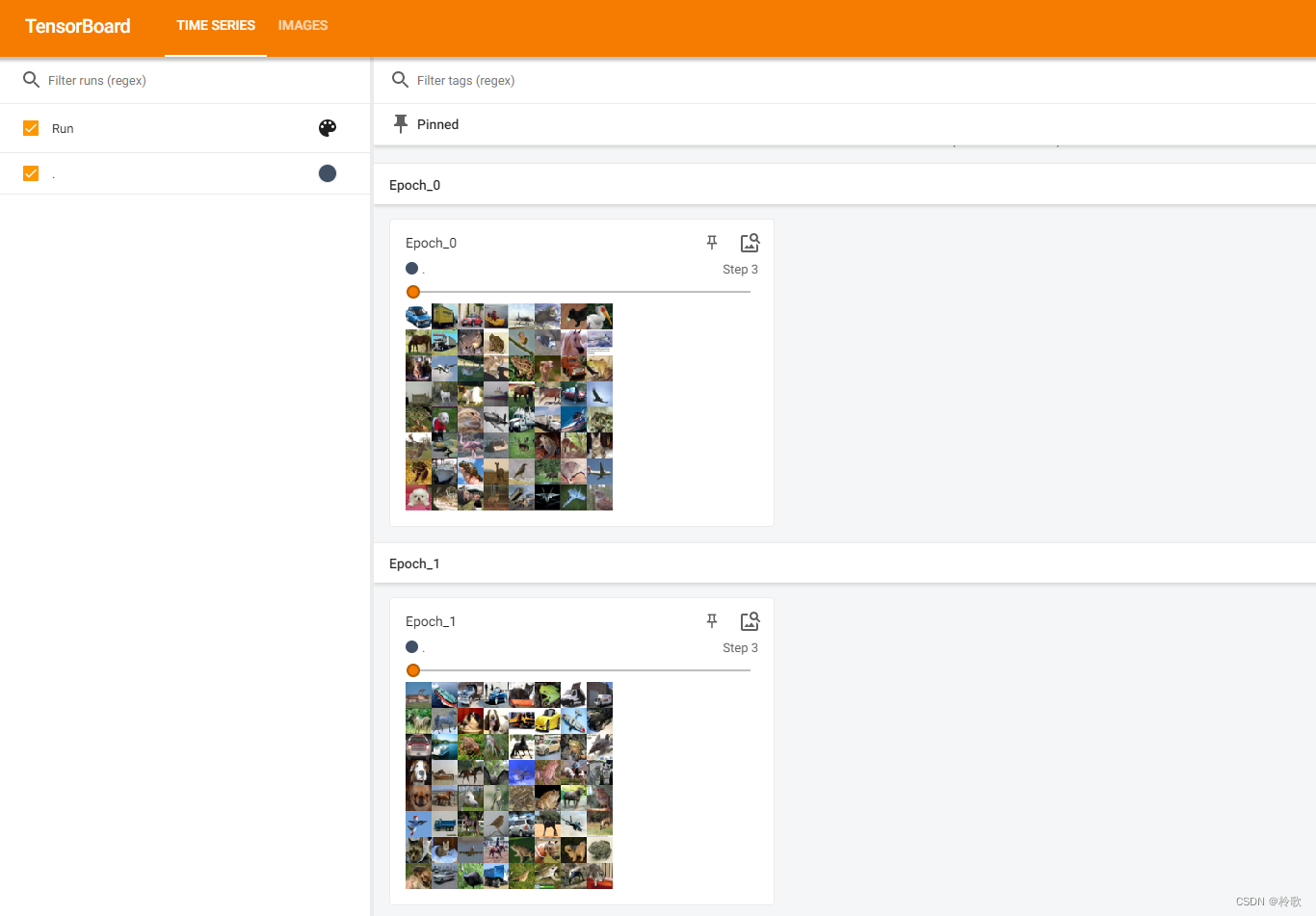
for epoch in range(2): # 循环两个 epoch
for step, data in enumerate(test_loader): # step 表示第几个 batch
imgs, targets = data
writer.add_images('Epoch_{}'.format(epoch), imgs, step) # 注意是 add_images,图像默认格式为 NCHW
writer.close()
以上代码循环了两个 epoch,即读取了两轮全部的数据集,每轮 epoch 用 for 循环读取 DataLoader 中的每一个 batch,将每一个 batch 作为一个步长将图像添加到 TensorBoard 中。
注意这里添加一个图像的集合时用的函数是 add_images 而不是 add_image,add_images 默认传入图像集合的 size 格式为 NCHW,即:[batch_size, channel, height, width],而 add_image 默认传入图像的 size 格式为 CHW。打开 TensorBoard 的网站可以看到以下结果: