前言
我相信很多刚学爬虫的新手,在学习过程中都会碰到验证码这块,其实这块也算是反爬这一块了。因为你运行代码抓取会一定程度对网站造成一系列的负担。所以此案例只用于学习交流。
在很久之前,分享过一次Python代码实现验证码识别的办法。
当时采用的是pillow+pytesseract,优点是免费,较为易用。但其识别精度一般,若想要更高要求的验证码识别,初学者就只能去选择使用百度API接口了。
但其实百度API接口和pytesseract其实都需要进行前期配置,对于初学者来说就不太友好了。
而且百度API必须要联网,对于某些机器不能联网的朋友而言,就得pass了
最近群里有位群友分享了一个新库,试用一下发现非常实用,特意今天分享给大家。
Github地址:关注公众号:Python顾木子即可获取。
该库名也是非常有趣 —— ddddocr(谐音带带弟弟OCR)
环境要求:
python >= 3.8 Windows/Linux/Macox..
可以通过以下命令安装
pip install ddddocr
参数说明:

在网上随机寻找了一个验证码图片,使用这个库来实战一下。

来源:百度搜索
import ddddocr
ocr = ddddocr.DdddOcr()
with open('1.png', 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
print(res)

成功识别出来了验证码文字!
而且优点也非常明显:首先代码非常精简,对比前文提到的两种方法,不需要额外设置环境变量等等,5行代码即可轻松识别验证码图片。另一方面,我们使用魔法命令%%time也测试出来吗,这段代码识别速度非常快。
下面用更多的验证码图片继续测试:
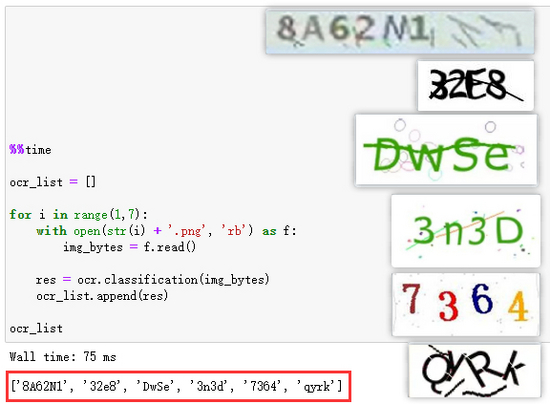
我又找了6个验证码图片来测试,观察结果,发现这类简单的验证码基本可以进行快速识别。但也有部分结果有问题——字母大小写没有进行区分(比如第6张图片)。
总而言之,如果你需要进行验证码识别,且对精度要求不是过高。
肯定有好多人说你这都是直接用的别人家的库,没有库你咋个办呢?其实Python这门语言就是调用各大模块和框架的。不用重复造轮子又能达到想要的效果还是很不错的呢
记得关注公众号:Python顾木子, 获取完整项目代码哦