相信大家吃饭的时候肯定是很苦恼打饭之慢,在自己饥肠辘辘的时候,面对自己喜欢吃的食物窗口却如同有百万大军虎视眈眈,自己内心的煎熬可想而知

有时候在想这么美味的食物,为什么窗口就只开一个呢?于是你告诉了你的爸爸(校长),“小kiss”,于是当天这家窗口又新增了3个窗口,你很喜欢、很满意

但是新问题又出现了,你想一天换着口味吃,但是总感觉一个窗口卖三种食物不是太好,于是你又...,校长的话怎么能不听,当天三个窗口就开始食物分离开来,自己只负责自己所卖的食物
这个故事告诉我们,(有个厉害的爸爸有多么重要)哈哈!!!
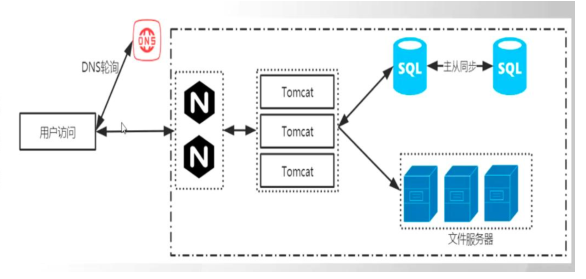
言归正传,当第一种情况,有且仅有一个窗口中不仅卖着面条、米饭还有炒面,当学生想吃这些食物的时候,就必须要在这个窗口进行排队,人少不影响,如果人多,厨师的手都快要炒断了(单体应用架构)

当第二种情况,当你的爸爸大显神通时,把窗口增加到了3个,对一个窗口业务进行了分担,解决了一些人流量大的问题(集群应用架构)
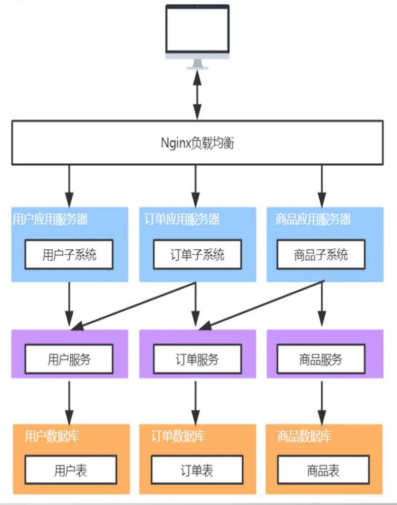
但是又发生了一些情况,当你想吃面条的时候,你去排队,结果你的前面都是准备买炒面、米饭的人,这时候你又受不了了,所以你又...,把食物按照食物种类进行分类(垂直应用架构)
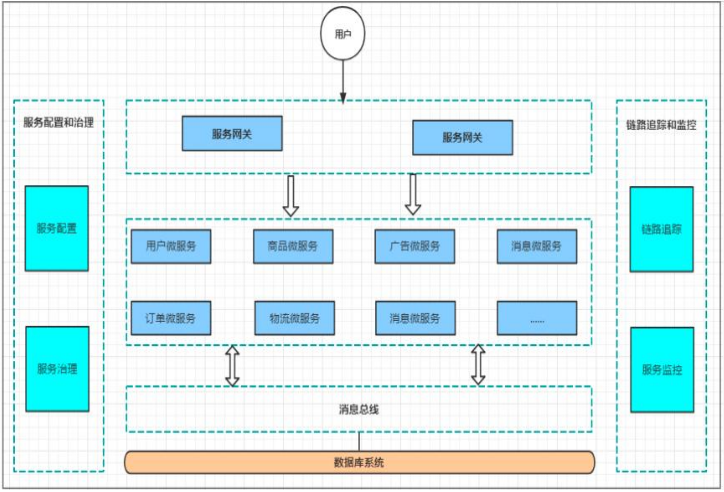
所以就有了微服务架构。
微服务架构
那么微服务架构有哪些优势呢?
独立开发:所有微服务都可以根据各自的功能进行开发
独立部署:基于其服务,可以在任何应用程序中单独部署它们
故障隔离:及时应用程序的一项服务起不来,系统仍然可以继续运行
混合技术栈:可以使用不同的 语言和技术来构建同一应用程序的不同服务
粒度缩放:单个组件可根据需要进行缩放,无需将组件缩放在一起
于是我们在idea中进行操作

在一个大的项目中,开了4个模块,一个模块是专门负责进行实体类的创建,一个模块是专门进行下单的模块,一个模块是专门进行查询产品的模块,最后一个模块是专门进行查询user的模块,将每个功能进行分离,那么每个模块和模块之间是怎么练习的呢?
我们是不是需要一个桥梁将它们进行某一种程度上的连接呢?
微服务中常见的概念
服务治理:对服务进行自动化管理,核心就是服务的自动注册以及发现
服务注册:服务实例将自身服务信息注册到服务 注册中心
服务发现:服务实例通过注册中心,获取到注册到其中的服务实例的信息,通过信息去请求它们进行提供服务
服务剔除:服务注册中心将问题的服务自动剔除到可用列表之外,使其不会被调用到
接下来我们一一进行演示操作
服务治理:

我们在这里用的是nacos(提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置等)
如何搭建nacos环境
安装nacos
https://github.com/alibaba/nacos/releases 下载解压并安装
在控制面板(CMD)启动nacos
进入nacos中的bin目录
startup.cmd -m standalone
访问nacos
打开网址 http://localhost:8848/nacos 默认密码是:nacos /nacos
将微服务进行注册
在所需要注册的模块中添加nacos的依赖
<!--nacos 客户端-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>在启动类中添加@EnableDiscoveryClient 注解
在配置中添加nacos的服务地址
#在spring中进行配置
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
然后对服务进行启动,在nacos中就可以监听到商品的微服务服务了
负载均衡
第一版本:
User user = restTemplate.getForObject("http://127.0.0.1:8091/user/finduser/"+uid,User.class);
Product product =restTemplate.getForObject("http://127.0.0.1:8081/product/findProduct/"+pid,Product.class);对模块进行访问(根据ip+端口),这种方式虽然可以访问到,但是这种访问是写死的,我们难道要每一次在访问的时候都要用这种方式进行访问未免太过于繁琐,于是我们想要动态将ip和端口显示出来,故有了第二版:
@Autowired
DiscoveryClient discoveryClient;
/*
在订单服务中,需要远程调用用户服务,和商品服务
*/
//获取服务列表
List<ServiceInstance> instance= discoveryClient.getInstances("service-user");
//随机生成索引
Integer index=new Random().nextInt(instance.size());
//获取服务
ServiceInstance userService=instance.get(index);
//获取服务地址
String url=userService.getHost()+":"+userService.getPort();
List<ServiceInstance> instance1= discoveryClient.getInstances("service-product");
//随机生成索引
Integer index1=new Random().nextInt(instance1.size());
//获取服务
ServiceInstance productuService=instance1.get(index1);
//获取服务地址
String url1=productuService.getHost()+":"+productuService.getPort();
User user = restTemplate.getForObject("http://"+url+"/user/finduser/"+uid,User.class);
Product product =restTemplate.getForObject("http://"+url1+"/product/findProduct/"+pid,Product.class);这种方式解决了把ip+端口写死的问题,但是又出现了一个新的问题,这种方式,如果存在两个服务实力,服务调用者只会调用第一个服务实例,另外一个服务实例将会被搁置,导致资源浪费,所以我们又出现了第三版:
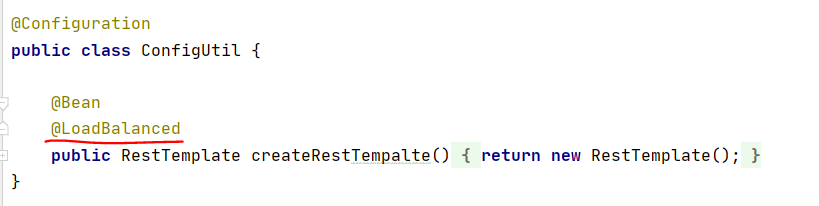
User user = restTemplate.getForObject("http://service-user/user/finduser/"+uid,User.class);
Product product =restTemplate.getForObject("http://service-product/product/findProduct/"+pid,Product.class);在yml中配置:
ribbon:
ConnectTimeout: 2000 # 请求连接的超时时间
ReadTimeout: 5000 # 请求处理的超时时间
service-product: # 调用的提供者的名称
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule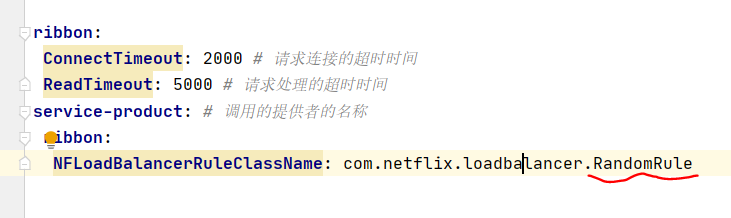
以下给大家介绍负载均衡的七种策略:
RoundRobinRule(轮询策略):按顺序来一人一次
WeightedResponseTimeRule(权重策略):根据响应时间分配权重,权重越高,被选的几率也就越高
RandomRule(随机策略):随机提供一个服务实例
BestAvailableRule(最小连接数策略):取到连接数最小的一个服务实例
RetryRule(重试策略):轮询策略进行获取,如果获取不到,反复进行重试进行获取,如若超过时间,则返回null
AvailabilityFilteringRule(可用敏感性策略):先过滤掉非健康的服务实例,再选择连接数较小的进行连接
ZoneAvoidanceRule(区域敏感策略):根据服务所在的区域的性能进行选择服务实例