对于同一个节点,React 会比较这个节点的ReactElement与FiberNode,生成子FiberNode。并根据比较的结果生成不同标记(插入、删除、移动...),对应不同宿主环境API的执行。

前言
通过学习,了解了Fiber是什么,知道了Fiber节点可以保存对应的DOM节点。Fiber节点构成的Fiber Tree会对应DOM Tree。
前面也提到Fiber是一种新的调和算法,那么它是如何更新DOM节点的呢?
单个节点的创建更新流程
对于同一个节点,React 会比较这个节点的ReactElement与FiberNode,生成子FiberNode。并根据比较的结果生成不同标记(插入、删除、移动...),对应不同宿主环境API的执行。

根据上面的Reconciler的工作流程,举一个例子:
比如:
mount阶段,挂载<div></div>。
- 先通过jsx("div")生成 React Element <div></div>。
- 生成的对应的fiberNode为null(由于是由于是挂载阶段,React还未构建组件树)。
- 生成子fiberNode(实际上就是这个div的fiber节点)。
- 生成Placement标记。
将<div></div>更新为<p></p>。
update阶段,更新将<div></div>更新为<p></p>。
- 先通过jsx("p")生成 React Element <p></p>。
- p与对应的fiberNode作比较(FiberNode {type: 'div'})。
- 生成子fiberNode为null。
- 生成对应标记Delement Placement。
用一张图解释上面的流程:
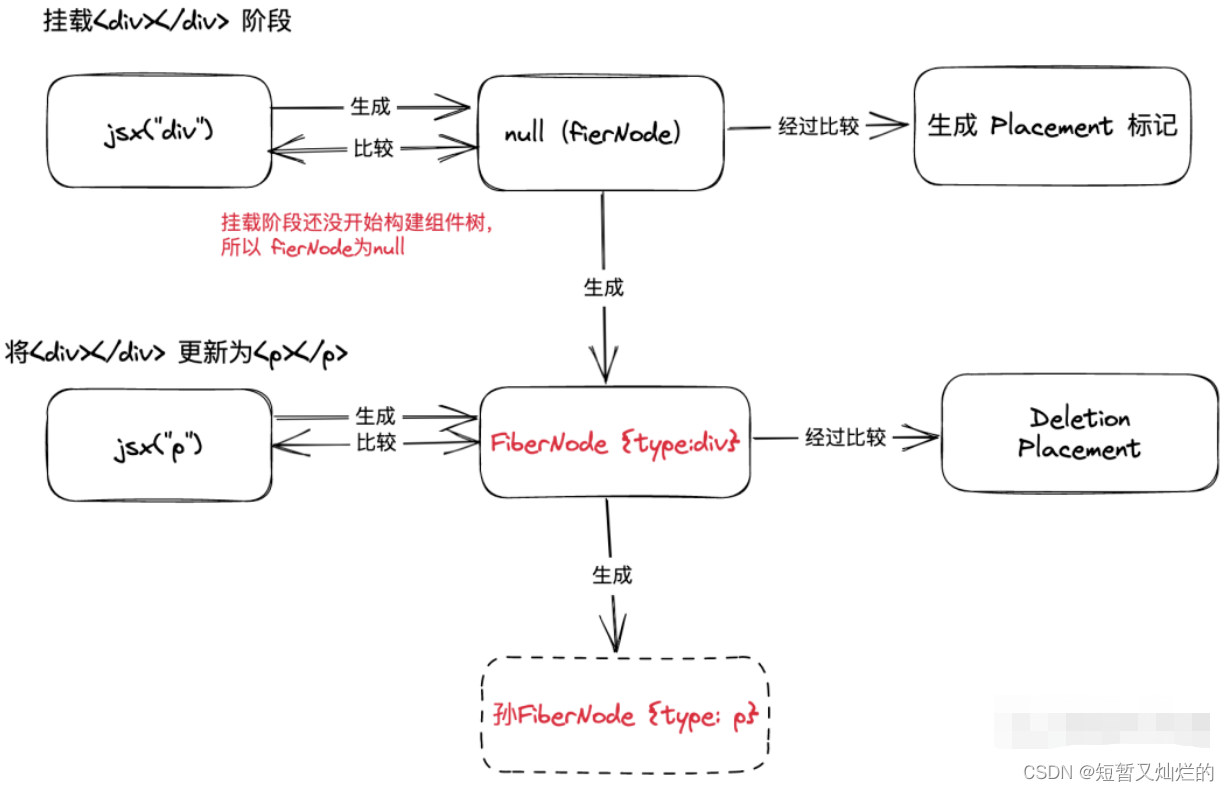
当所有的ReactElement比较完后,会生成一颗fiberNode Tree,一共会存在两棵fiberNode Tree。
- current:与视图中真实UI对应的fiberNode树。
- workInProgress:触发更新后,正在reconciler中计算的fiberNode Tree(用于下一次的视图更新,在下一次视图更新后,会变成current Tree)。
这就是React中的"双缓存树"技术。
什么是"双缓存"?
双缓存技术是一种计算机图形学中用于减少屏幕闪烁和提高渲染性能的技术。
就好像你是一个画家,你需要在一个画布上绘制一幅画。在没有双缓存技术的情况下,你会直接在画布上作画。当你绘制一条线或一个形状时,观众会立即看到这个过程。如果你的绘画速度较慢,观众可能会看到画面的闪烁和变化,这会导致视觉上的不舒适。
引入双缓存技术就好比你有两个画布:一个是主画布,观众可以看到它;另一个是隐藏画布,观众看不到它。在这种情况下,你会在隐藏画布上进行绘画。当你完成一个阶段性的绘制任务后,你将隐藏画布上的图像瞬间复制到主画布上。观众只能看到主画布上的图像,而看不到隐藏画布上的绘制过程。这样,即使你的绘画速度较慢,观众也不会看到画面的闪烁和变化,从而获得更流畅的视觉体验。
使用双缓存技术时,计算机会在一个隐藏的缓冲区(后台缓冲区)上进行绘制,然后将绘制好的图像一次性复制到屏幕上(前台缓冲区)。这样可以减少屏幕闪烁,并提高渲染性能。
这种在内存中构建并直接替换的技术叫作双缓存。
React 中使用"双缓存"来完成Fiber Tree的构建与替换,对应着DOM Tree的创建于与更新。
双缓存Fiber树
Fiber架构中同时存在两棵Fiber Tree,一颗是"真实UI对应的 Fiber Tree"可以理解为前缓冲区。另一课是"正在内存中构建的 Fiber Tree"可以理解为后缓冲区,这里值宿主环境(比如浏览器)。
当前屏幕上显示内容对应的Fiber树称为current Fiber树,正在内存中构建的Fiber树称为workInProgress Fiber树。
current Fiber树中的Fiber节点被称为current fiber,workInProgress Fiber树中的Fiber节点被称为workInProgress fiber,他们通过alternate属性连接。
双缓存树一个显著的特点就是两棵树之间会互相切换,通过alternate属性连接。
currentFiber.alternate === workInProgressFiber;
workInProgressFiber.alternate === currentFiber;双缓存树切换的规则
React应用的根节点通过current指针在不同Fiber树的HostRootFiber根节点(ReactDOM.render创建的根节点)间切换。
- 在 mount时(首次渲染),会根据jsx方法返回的React Element构建Fiber对象,形成Fiber树。
- 然后这棵Fiber树会作为current Fiber应用到真实DOM上。
- 在 update时(状态更新),会根据状态变更后的React Element和current Fiber作对比形成新的workInProgress Fiber树。
- 即当workInProgress Fiber树构建完成交给Renderer(渲染器)渲染在页面上后,应用根节点的current指针指向workInProgress Fiber树。
- 然后workInProgress Fiber切换成current Fiber应用到真实DOM上,这就达到了更新的目的。
这一切都是在内存中发生的,从而减少了对DOM的直接操作。
每次状态更新都会产生新的workInProgress Fiber树,通过current与workInProgress的替换,完成DOM更新,这就是React中用的双缓存树切换规则。
Renderer 是一个与特定宿主环境(如浏览器 DOM、服务器端渲染、React Native 等)相关的模块。Renderer 负责将 React 组件树转换为特定宿主环境下的实际 UI。从而使 React 能够在多个平台上运行。
上面的语言可能有些枯燥,我们来画个图演示一下。
比如有下面这样一段代码,点击元素把div切换成p元素:
function App() {
const [elementType, setElementType] = useState('div');
const handleClick = () => {
setElementType(prevElementType => {
return prevElementType === 'div' ? 'p' : 'div';
})
}
// 根据 elementType 的值动态创建对应的元素
const Element = elementType;
return (
<div>
<Element onClick={handleClick}>
点击我切换 div 和 p 标签
</Element>
</div>
)
}
const root = document.querySelector("#root");
ReactDOM.createRoot(root).render(<App />); 
接下来,我们分别从 mount(首次渲染)和 update(更新)两个角度讲解 Fiber 架构的工作原理。
mount 时 Fiber Tree的构建
mount 时有两种情况:
- 整个应用的首次渲染,这种情况发生首次进入页面时。
- 某个组件的首次渲染,当 isShow 为 true时,Btn 组件进入 mount 首次渲染流程。
{isShow ? <Btn /> : null}假如有这样一段代码:
function App() {
const [num, add] = useState(0);
return (
<p onClick={() => add(num + 1)}>{num}</p>
)
}
const root = document.querySelector("#root");
ReactDOM.createRoot(root).render(<App />)mount 时上面的Fiber树构建过程如下:
- 首次执行ReactDOM.createRoot(root)会创建fiberRootNode。
- 接着执行到render(<App />)时会创建HostRootFiber,实际上它是一个HostRoot节点。
fiberRootNode 是整个应用的根节点,HostRootFiber 是 <App /> 所在组件树的根节点。
- 从HostRootFiber开始,以DFS(深度优先搜索)的的顺序遍历子节点,以及生成对应的FiberNode。
- 在遍历过程中,为FiberNode标记"代表不同副作用的 flags",以便后续在宿主环境中渲染的使用。
在上面我们之所以要区分fiberRootNode和HostRootFiber是因为在整个React应用程序中开发者可以多次多次调用render方法渲染不同的组件树,它们会有不同的HostRootFiber,但是整个应用的根节点只有一个,那就是fiberRootNode。
执行 ReactDOM.createRoot 会创建如图所示结构:
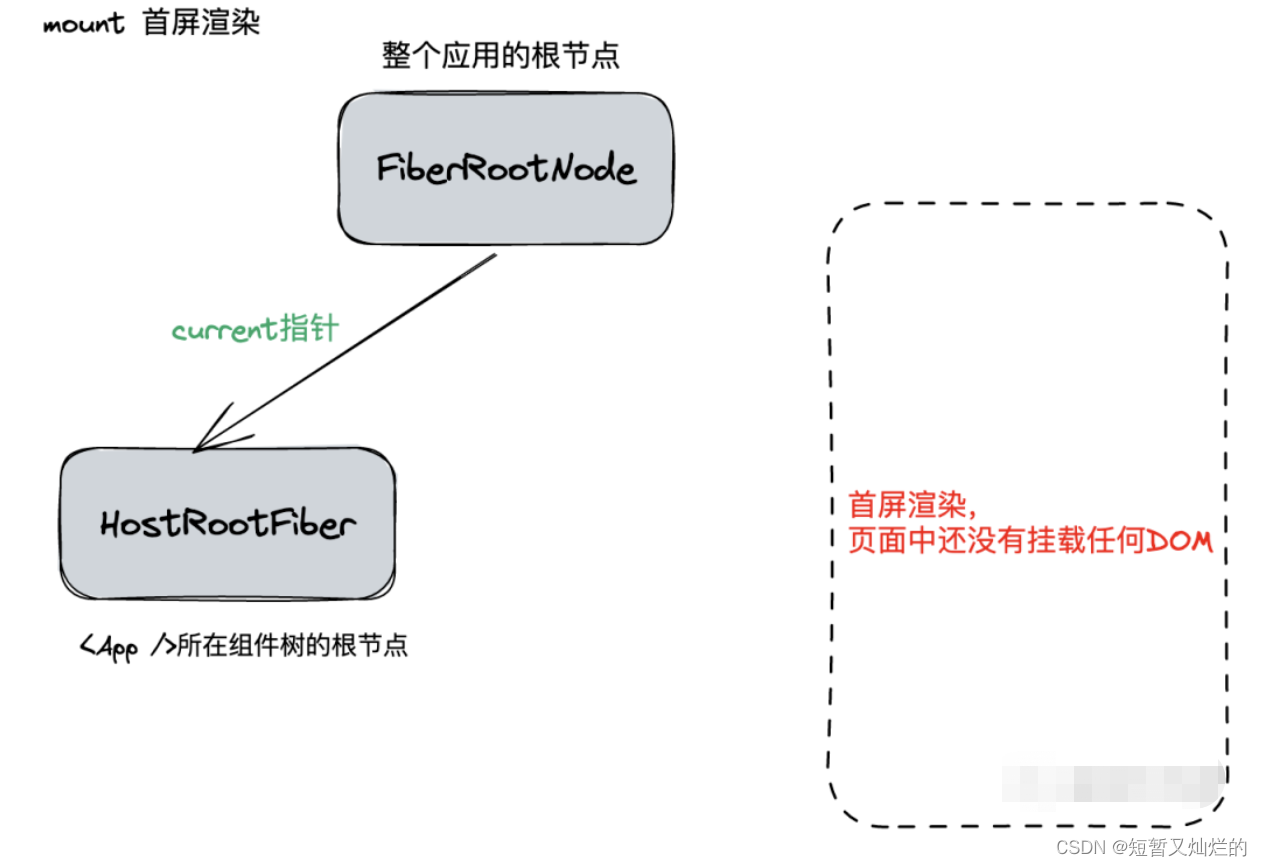
mount 首屏渲染阶段
由于是首屏渲染阶段,页面中还没有挂载任何DOM节点,所以fiberRootNode.current指向的HostRootFiber没有任何子Fiber节点(即current Fiber树为空)。
当前仅有一个HostRootFiber,对应"首屏渲染时只有根节点的空白画面"。
<body>
<div id="root"></div>
</body>render 生成workInProgress树阶段
接下来进入render阶段,根据组件返回的JSX在内存中依次构建创建Fiber节点并连接在一起构建Fiber树,被称为workInProgress Fiber树。
在构建workInProgress Fiber树时会尝试复用current Fiber树中已有的Fiber节点内的属性,(在首屏渲染时,只有HostRootFiber),也可以理解为首屏渲染时,它以自己的身份生成了一个workInProgress 树只不过还是HostRootFiber(HostRootFiber.alternate。
基于DFS(深度优先搜索)依次生成的workInProgress节点,并连接起来构成wip 树的过程如图所示:
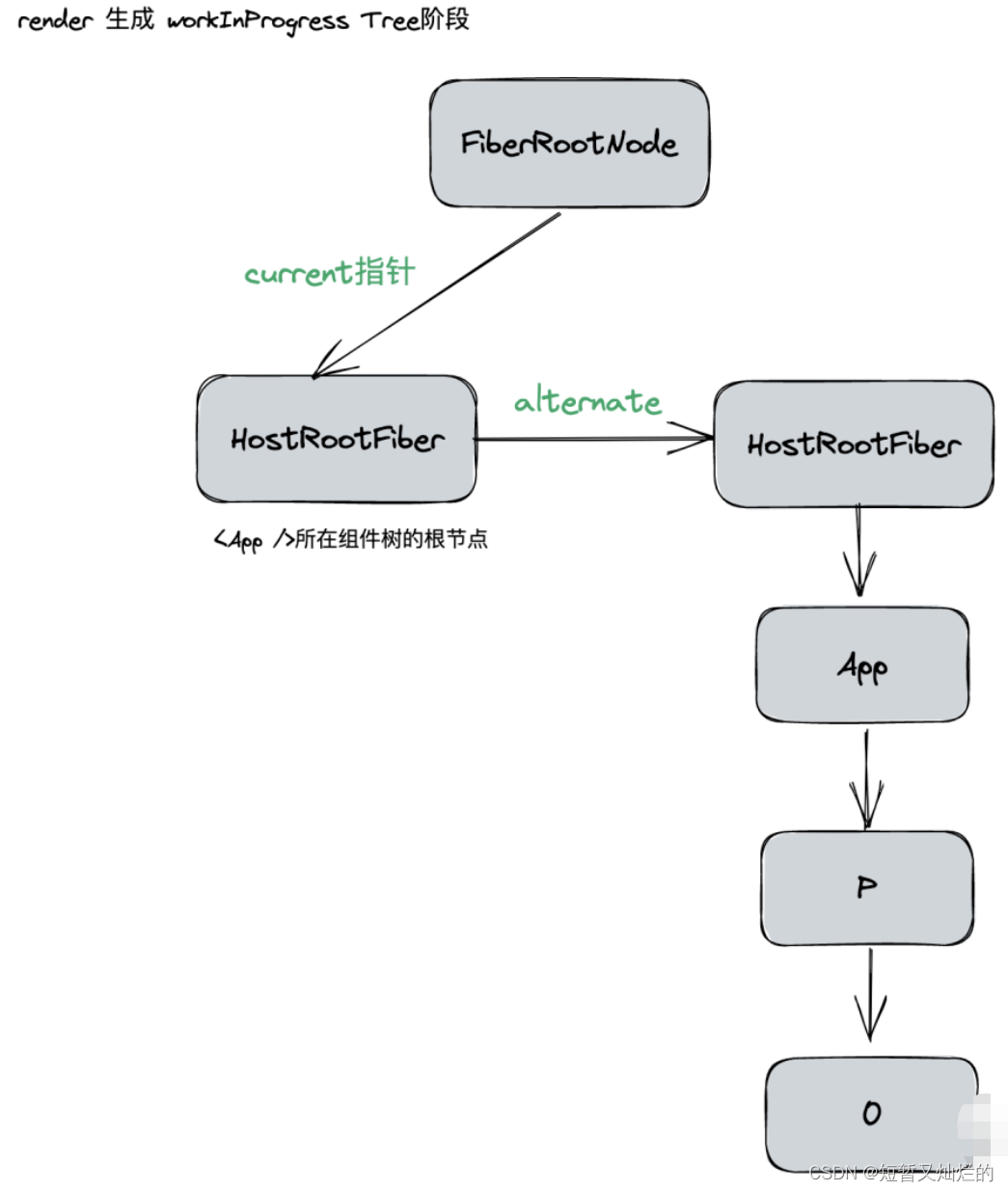
上图中已构建完的workInProgress Fiber树会在commit阶段被渲染到页面。
commit 阶段
等到页面渲染完成时,workInProgress Fiber树会替换之前的current Fiber树,进而fiberRootNode的current指针会指向新的current Fiber树。
完成双缓存树的切换工作,曾经的Wip Fiber树变为current Fiber树。
过程如图所示:
update 时 Fiber Tree的更迭
- 接下来我们点击p节点触发状态改变。这会开启一次新的render阶段并构建一课新的workInProgress Fiber树。
和mount时一样,workInProgress Fiber的创建可以复用current Fiber树对应节点的数据,这个决定是否服用的过程就是Diff算法, 后面章节会详细讲解。

- workInProgress Fiber树在render阶段完成构建后会进入commit阶段渲染到页面上。渲染完成后,workInProgress Fiber树变为current Fiber树。

render 阶段的流程
接下来,我们来看看用原理,在源码中它是如何实现的。
Reconciler工作的阶段在 React 内部被称为 render 阶段,ClassComponent 的render函数、Function Component函数本身也都在 render 阶段被调用。
根据Scheduler调度的结果不同,render阶段可能开始于performSyncWorkOnRoot或performConcurrentWorkOnRoot方法的调用。
也就是说React在执行render阶段的初期会依赖于Scheduler(调度器)的结果来判断执行哪个方法,比如Scheduler(调度器)会根据任务的优先级选择执行performSyncWorkOnRoot或performConcurrentWorkOnRoot方法。这取决于任务的类型和优先级。同步任务通常具有较高优先级,需要立即执行,而并发任务会在空闲时间段执行以避免阻塞主线程。
这里补充一下,调度器可能的执行结果,以用来判断执行什么入口函数:
如果不知道调度器的执行结构都有哪几类,可以跳过这段代码向下看:
现在还不需要学习这两个方法,只需要知道在这两个方法中会调用 performUnitOfWork方法就好。
// performSyncWorkOnRoot会调用该方法
function workLoopSync() {
while (workInProgress !== null) {
performUnitOfWork(workInProgress);
}
}
// performConcurrentWorkOnRoot会调用该方法
function workLoopConcurrent() {
while (workInProgress !== null && !shouldYield()) {
performUnitOfWork(workInProgress);
}
}可以看到,它们唯一的区别就是是否会调用shouldYield。如果当前浏览器帧没有剩余时间,shouldYield会终止循环,直到浏览器有空闲时间再继续遍历。
也就说当更新正在进行时,如果有 "更高优先级的更新" 产生,则会终端当前更新,优先处理高优先级更新。
高优先级的更新比如:"鼠标悬停","文本框输入"等用户更易感知的操作。
workInProgress代表当前正在工作的一个fiberNode,它是一个全局的指针,指向当前正在工作的 fiberNode,一般是workInProgress。
performUnitOfWork方法会创建下一个Fiber节点,并赋值给workInProgress,并将workInProgress与已经创建好的Fiber节点连接起来构成Fiber树。
这里为什么指向的是 workInProgress 呢? 因为在每次渲染更新时,即将展示到界面上的是 workInProgress 树,只有在首屏渲染的时候它才为空。
render阶段流程概览
Fiber Reconciler是从Stack Reconciler重构而来,通过递归遍历的方式实现可中断的递归。 因为可以把performUnitOfWork方法分为两部分:"递"和"归"。
"递" 阶段会从 HostRootFiber开始向下以 DFS 的方式遍历,为遍历到的每个fiberNode执行beginWork方法。该方法会根据传入的fiberNode创建下一级fiberNode。
当遍历到叶子元素(不包含子fiberNode)时,performUnitOfWork就会进入 "归" 的阶段。
"归" 阶段会调用completeWork方法处理fiberNode。当某个fiberNode执行完complete方法后,如果其存在兄弟fiberNode(fiberNode.sibling !== null),会进入其兄弟fiber的"递阶段"。如果不存在兄弟fiberNode,会进入父fiberNode的 "归" 阶段。
递阶段和归阶段会交错执行直至HostRootFiber的"归"阶段。到此,render阶段的工作就结束了。
举一个例子:
function App() {
return (
<div>
<p>1229</p>
jasonshu
</div>
)
}
const root = document.querySelector("#root");
ReactDOM.createRoot(root).render(<App />);当执行完深度优先搜索之后形成的workInProgress树。

图中的数组是遍历过程中的顺序,可以看到,遍历的过程中会从应用的根节点RootFiberNode开始,依次执行beginWork和completeWork,最后形成一颗Fiber树,每个节点以child和return项链。
注意:当遍历到只有一个子文本节点的Fiber时,该Fiber节点的子节点不会执行beginWork和completeWork,如图中的"jasonshu"文本节点。这是react的一种优化手段
刚刚提到:workInProgress代表当前正在工作的一个fiberNode,它是一个全局的指针,指向当前正在工作的 fiberNode,一般是workInProgress。
// 该函数用于调度和执行 FiberNode 树的更新和渲染过程
// 该函数的作用是处理 React 程序中更新请求,计算 FiberNode 树中的每个节点的变化,并把这些变化同步到浏览器的DOM中
function workLoop() {
while (workInProgress !== null) {
// 开始执行每个工作单元的工作
performUmitOfWork(workInProgress);
}
}知道了beginWork和completeWork它们是怎样的流程后,我们再来看它是如何实现的:
这段代码主要计算FiberNode节点的变化,更新workInProgress,beginWork函数的最初运行也是在下面这个函数中,同时它也完成递和归两个阶段的操作。
// 在这个函数中,React 会计算 FiberNode 节点的变化,并更新 workInProgress
function performUmitOfWork(fiber: FiberNode) {
// 如果有子节点,就一直遍历子节点
const next = beginWork(fiber);
// 递执行完之后,需要更新下工作单元的props
fiber.memoizedProps = fiber.pendingProps;
// 没有子节点的 FiberNode 了,代表递归到最深层了。
if (next === null) {
completeUnitOfWork(fiber);
} else {
// 如果有子节点的 FiberNode,则更新子节点为新的 fiberNode 继续执行
workInProgress = next;
}
}在下面的函数中主要进行归的操作:
// 主要进行归的过程,向上遍历父节点以及兄弟,更新它们节点的变化,并更新 workInProgress
function completeUnitOfWork(fiber: FiberNode) {
let node: FiberNode | null = fiber;
do {
// 归:没有子节点之后开始向上遍历父节点
completeWork(node);
const sibling = node.sibling;
if (sibling !== null) {
// 有兄弟节点时,将指针指到兄弟节点
workInProgress = sibling;
return;
}
// 兄弟节点不存在时,递归应该继续往上指到父亲节点
node = node.return;
workInProgress = node;
} while (node !== null);
}到此,Reconciler的工作架构架子我们就搭完了。