目录:缺失值的处理
一、总录
二、引言
业界广泛流传这样一句话:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
若没有好的数据,那么训练得到的模型效果也不会有所提高,可见数据质量对于数据分析而言是十分重要的。当我们下载或是抓取所需的数据时,不可避免的会遇到一些缺失数据,那么对这些缺失数据该如何处理呢?
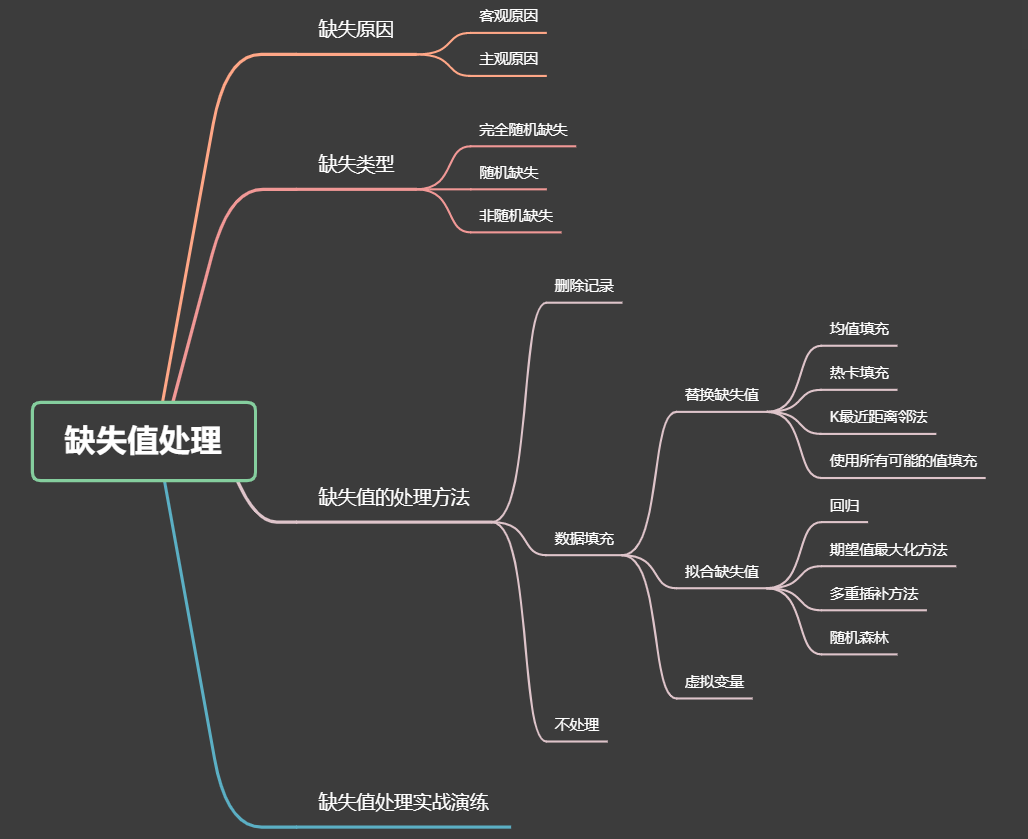
三、数据缺失的原因
在各种数据库中,属性值缺失的情况时有发生。造成数据缺失的原因是多方面的,小编认为主要可以分为以下两种:
- 客观原因:有些信息暂时无法提取,如在短时间无法获得的临床检验结果;某些属性值本身不存在,如未婚者的配偶姓名;获取某些信息的代价太大;系统实时性能要求较高,要求在得到这些信息前做出决策。
- 主观原因:数据在输入时由于人为因素被遗漏;被认为是无关紧要的信息。
总之,对于造成缺失值的原因,我们要明确一点:是因为工作人员疏忽造成的,还是数据本身就无法提取。只有明确数据缺失的原因,方能对症下药。
四、数据缺失的类型
明确两个概念:数据集中不含缺失值的变量称为完全变量,数据集中含有缺失值的变量称为不完全变量。从缺失的分布来看可以将缺失分为完全随机缺失,随机缺失和完全非随机缺失。
- 完全随机缺失:指数据的缺失是完全随机的,不依赖于任何不完全变量或完全变量,不影响样本的无偏性。如家庭地址缺失。
- 随机缺失:指数据的缺失不是完全随机的,即该类数据的缺失依赖于其他完全变量。如财务数据缺失,其与企业规模有关。
- 非随机缺失:指的是数据的缺失与不完全变量自身的取值有关。如高收入人群不愿意提供家庭收入。
数据缺失的类型关乎我们如何去处理缺失数据。对于后两种情况,直接删除记录是不合适的。随机缺失可以通过已知变量对缺失值进行估计,而非随机缺失的非随机性目前还没有很好的解决办法。
五、数据缺失的处理方法
数据处理的方法又有哪些呢?
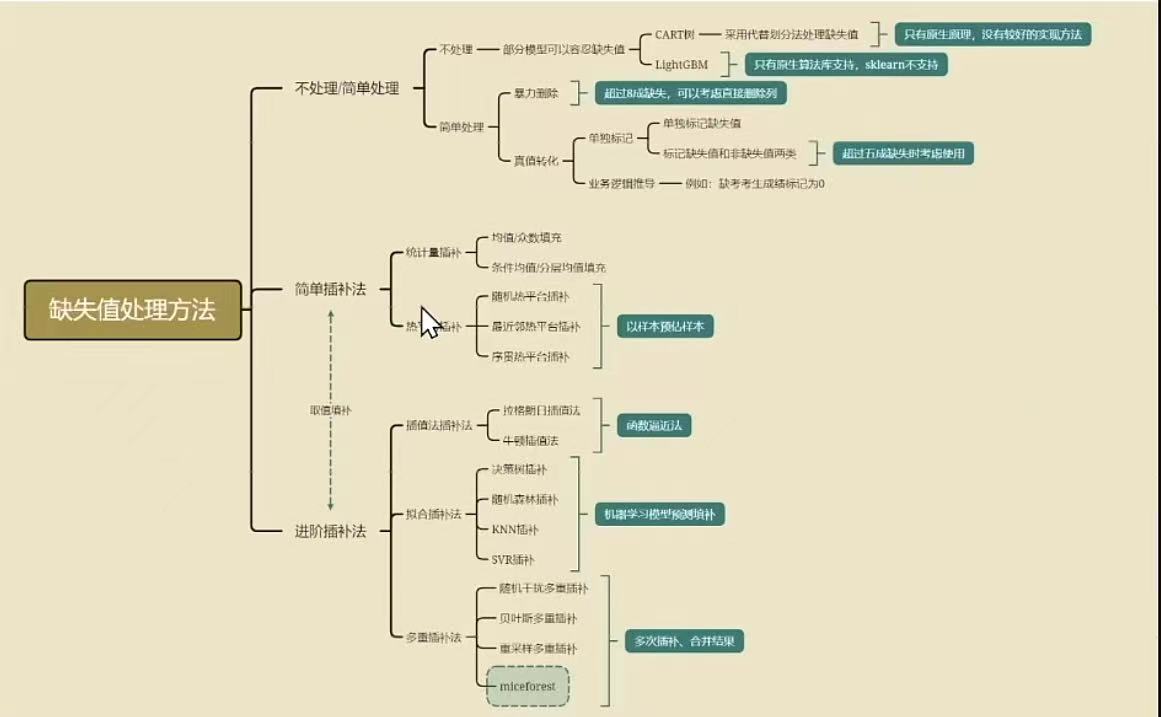
处理不完备的数据集主要分为以下三类:
- 删除记录
- 数据填充
- 不处理
5.1 删除记录
该方法方便快捷,简单粗暴。但其牺牲了大量数据,可能会丢失许多隐藏重要信息,尤其是在缺失数据占比较大时,可能会直接导致数据的分布发生变化,导致得出错误的结论。该方法适用于缺失数据相对样本数据来说很少的情况。可以使用pandas中的dropna直接删除有缺失值的特征。
# 直接删除含有缺失值的行
df.dropna(how='any',axis = 0)
df.dropna() # 等价形式
# 直接删除含有缺失值的列
df.dropna(how='any',axis = 1)
# 只删除全是缺失值的行
df.dropna(how = 'all')
5.2 数据填充
该方法是用一定值去填充空值,进而使数据完备。通常有以下三大类填充方法,分别为替换缺失值、拟合缺失值和虚拟变量。
5.2.1 替换缺失值
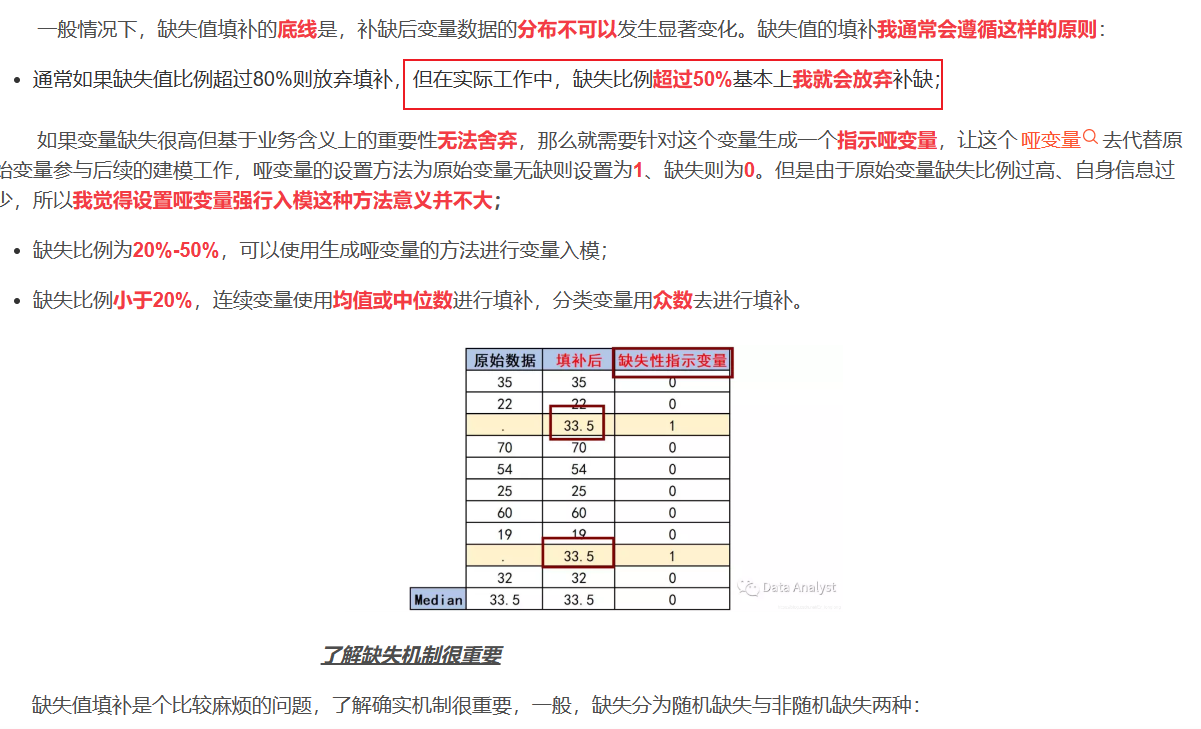
(1)均值填充。将所有属性划分为数值属性和非数值属性,若空值是定量的,则按该属性在其他所有对象取值的均值或中位数来填充;若空值是定性的,则用该属性在其他所有对象的众数来填充。此方法简单不够精准,可能会改变特征原有分布。
# 使用var1的均值/中位数对 NA进行填充
df['var1'].fillna(df['var1'].mean())
df['var1'].fillna(df['var1'].median())
(2)热卡填充。它的思想十分简单,即找一个与缺失值对象最相近的对象来进行填充。通常会找到不止一个相似对象,在所有匹配对象中没有最好的,而是从中随机挑选一个作为填充值。不同的问题可能会选用不同的标准来对相似进行判定,但定义相似标准较难,主观因素太多。
(3)K最近距离邻法。先根据欧氏距离或相关分析来确定距离具有缺失数据样本最近的K个样本,将这K个值加权平均来估计该样本的缺失数据。
(4)使用所有可能的值填充。该方法是用空缺属性值的所有可能的属性取值来填充,能得到较好的补齐效果。但当数据量较大、遗漏的属性值较多时,其计算代价较大。
5.2.2 拟合缺失值
(1)回归。基于完整的数据集,建立回归方程。对包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充。但缺点是当变量不是线性相关或预测变量高度相关时会导致有偏差的估计。
(2)期望值最大化方法。这里利用到了EM算法,分为E步和M步两个步骤,E步在给定完全数据和前一次迭代所得到的参数估计的情况下计算完全数据对应的对数似然函数的条件期望,M步是用极大化对数似然函数以确定参数的值,并用于下一步的迭代。算法在E步和M步之间不断迭代直至收敛。但该方法的缺点是可能会陷入局部极值,而且收敛速度不快,计算较为复杂。
(3)多重插补方法。该方法来源于贝叶斯估计,主要分为以下三个步骤:第一,为每个空值产生一套可能的填补值,这些值反映了无响应模型的不确定性,每个值都被用来填补数据集中的缺失值,产生若干个完整数据集合;第二,每个填补数据集合都用针对完整数据集的统计方法进行统计分析;第三,对来自各个填补数据集的结果进行综合,产生最终的统计推断,这一推断考虑到了由于数据填补而产生的不确定性。该方法将空缺值视为随机样本,这样计算出来的统计推断可能受到空缺值的不确定性的影响。该方法的缺点是计算复杂。
(4)随机森林。这是很多竞赛中大家经常使用的一种办法,同样是将缺失值作为目标变量。某案例代码如下:
# 导入随机森林模块
from sklearn.ensemble import RandomForestRegressor
# 定义函数
def set_missing_ages(df):
#把数值型特征都放到随机森林里面去
age_df=df[['Age','Fare','Parch','SibSp','Pclass']]
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
y=known_age[:,0] # y是年龄,第一列数据
x=known_age[:,1:] # x是特征属性值,后面几列
rfr=RandomForestRegressor(random_state=0,n_estimators=2000,n_jobs=-1)
#根据已有数据去拟合随机森林模型
rfr.fit(x,y)
#预测缺失值
predictedAges = rfr.predict(unknown_age[:,1:])
#填补缺失值
df.loc[(df.Age.isnull()),'Age'] = predictedAges
return df,rfr
5.2.3 虚拟变量
虚拟变量是缺失值的一种衍生变量。具体做法是通过判断特征值是否有缺失值来定义一个新的二分类变量。比如,特征为A含有缺失值,我们衍生出一个新的特征B,如果A中特征值有缺失,那么相应的B中的值为1,如果A中特征值没有缺失,那么相应的B中的值为0。某案例代码如下:
# 复制该列数据到 CabinCat
data_train['CabinCat'] = data_train['Cabin'].copy()
# 设置虚拟变量
data_train.loc[ (data_train.CabinCat.notnull()), 'CabinCat' ] = "No"
data_train.loc[ (data_train.CabinCat.isnull()), 'CabinCat' ] = "Yes"
# 查看
data_train[['Cabin','CabinCat']].head(10)
5.3 不处理
前两类方法仅仅是用我们的主观估计值填补未知值,我们或多或少地改变了原始的数据集。而且,对空值不正确的填充往往将新的噪声引入数据中,使挖掘任务产生错误的结果。因此,在许多情况下,我们还是希望在保持原始信息不发生变化的前提下对信息系统进行处理。另外,有一些模型本身就足以应对具有缺失值的数据,此时无需对数据进行处理,比如XGBoost等高级模型。
六、实证演练
以下通过一个案例来简单学习一下缺失值处理常用的几种方法:
import pandas as pd
# 导入数据集
df = pd.read_csv('Data.csv',encoding = 'gbk',na_values='Na') #为空数据赋值
df.dtypes
# 对里程数进行处理
def f(x):
if '$' in str(x):
x = str(x).strip('$')
x = str(x).replace(',','')
else:
x = str(x).replace(',','')
return float(x)
df['Mileage'] = df['Mileage'].apply(f)
# 显示各变量缺失比例
df.apply(lambda x: sum(x.isnull())/len(x),axis= 0)
# 直接删除法——删除'Condition','Price','Mileage'三个变量含有缺失值的行
df.dropna(axis = 0,how='any',subset=['Condition','Price','Mileage'])
# 里程用均值填补
df.Mileage.fillna(df.Mileage.mean())
# 用众数填补
df.Exterior_Color.fillna(df.Exterior_Color.mode()[0])
# 婚姻状况使用众数填补,年龄使用均值填补,农户家庭人数使用中位数填补
df.fillna(value = {
'Exterior_Color':df.Exterior_Color.mode()[0],'Mileage':df.Mileage.mean()})
# 虚拟变量法
df['Watch_Count1'] = df['Watch_Count'].copy()
df.loc[ (df.Watch_Count.notnull()), 'Watch_Count1' ] = "No"
df.loc[ (df.Watch_Count.isnull()), 'Watch_Count1' ] = "Yes"
df[['Watch_Count','Watch_Count1']].head(10)
七、小结
总的来说,大部分数据挖掘的预处理都会使用比较方便的方法来处理缺失值,比如均值法,但是效果上并一定好,因此还是需要根据不同的需要选择合适的方法,并没有万能方法。具体方法还是要从多方面考虑。