目录
1.生命周期
1.1 线程创建
线程创建后,内核初始化线程控制块以及线程堆栈尾部,线程其余部分通常不初始化。
如果指定的启动延时是 K_NO_WAIT,内核将立即启动线程。您也可以指定一个超时时间,让内核延迟启动该线程。例如,让线程需要使用的设备就绪后再启动线程。
如果延迟启动的线程还未启动,内核可以取消该线程。如果线程已经启动了,则内核在尝试取消它时不会有如何效果。如果延迟启动的线程被成功地取消了,它必须被再次创建后才能再次使用。
1.2.线程的正常结束
线程一旦启动,它通常会一直运行下去。不过,线程也可以从它的入口点函数中返回,从而同步结束执行。这种结束方式叫做 正常结束(terminaltion)。
正常结束的线程需要在返回前释放它所拥有的共享资源(例如互斥量、动态分配的内存)。内核 不会 自动回收这些资源。
在某些情况下,一个线程可能希望休眠,直到另一个线程终止。这可以通过k_thread_join() API来实现。这将一直阻止调用线程直到超时结束,目标线程自退出或目标线程中止(由于k_thread_abort()调用或触发致命错误)。
一旦线程终止,内核保证不会使用该线程结构。这样一个结构的内存可以被重用用于任何目的,包括生成一个新线程。注意,线程必须完全终止,这表示了竞争条件,即线程自己的逻辑信号完成,在内核处理完成之前被另一个线程看到完成。在正常情况下,应用程序代码应该使用k_thread_join()或k_thread_abort()来同步线程终止状态,而不依赖于来自应用程序逻辑内部的信号量。
1.3.线程的异常终止
线程可以通过 异常终止 (aborting) 异步结束其执行。如果线程触发了一个致命错误(例如引用了空指针),内核将自动终止该线程。
其它线程(或线程自己)可以调用 k_thread_abort() 终止一个线程。不过,更优雅的做法是向线程发送一个信号,让该线程自己结束执行。
线程终止时,内核不会自动回收该线程拥有的共享资源。
1.4.线程挂起
如果一个线程被挂起,它将在一段不确定的时间内暂停执行。函数 k_thread_suspend() 可以用于挂起包括调用线程在内的所有线程。对已经挂起的线程再次挂起时不会产生任何效果。
线程一旦被挂起,它将一直不能被调度,除非另一个线程调用 k_thread_resume() 取消挂起。
线程可以使用
k_sleep()睡眠一段指定的时间。不过,这与挂起不同,睡眠线程在睡眠时间完成后会自动运行。
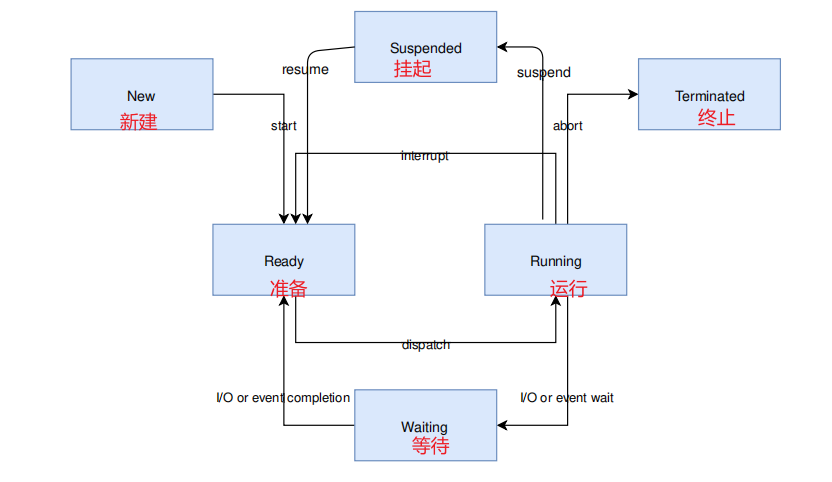
2. 线程状态
ready:没有其他因素影响线程执行,它处于准备状态。
unready具有一个或多个阻止其执行的因素的线程将被视为未准备好,并且不能被选择为当前线程。
以下因素会使线程未准备好:
- 该线程尚未启动。
- 该线程正在等待一个内核对象完成一个操作。(例如,该线程正在获取一个不可用的信号量。)
- 该线程正在等待超时时间的发生。
- 线程已挂起
- 该线程已终止或中止。
3.线程堆栈对象
每个线程都需要它自己的堆栈缓冲区,以便CPU推送上下文。根据配置的不同,必须满足若干约束条件:
- 可能需要为内存管理结构保留额外的内存
- 如果启用了基于保护的堆栈溢出检测,则必须在堆栈缓冲区之前有一个小的写保护内存管理区域以捕获溢出。
- 如果启用了用户空间,则必须保留一个单独的固定大小的特权提升堆栈来作为处理系统调用的私有内核堆栈。
- 如果启用了用户空间,线程的堆栈缓冲区必须有适当的大小和对齐,以便一个内存保护区域可以被编程到完全适合。
对齐约束可能是相当严格的,例如一些mpu要求它们的区域大小为2的幂,并与自己的大小对齐。
因此,可移植的代码不能简单地将任意的字符缓冲区传递给k_thread_create()。有一个特殊的宏来实例化堆栈,前缀为K_KERNEL_STACK和K_THREAD_STACK。
4. 仅内核堆栈
如果知道线程永远不会在用户模式下运行,或者堆栈被用于特殊上下文,如处理中断,最好使用K_KERNEL_STACK宏定义堆栈。这些堆栈节省了内存,因为MPU区域将永远不需要被编程来覆盖堆栈缓冲区本身,而且内核将不需要为特权提升堆栈或仅属于用户模式线程的内存管理数据结构预留额外的空间。
尝试从用户模式中使用以这种方式声明的堆栈将导致调用者出现致命错误。
如果未启用CONFIG_USERSPACE,则K_THREAD_STACK宏集与K_KERNEL_STACK宏具有相同的效果。
5.线程堆栈
如果已知堆栈需要托管用户线程,或者如果无法确定这一点,请使用K_THREAD_STACK宏定义堆栈。这可能会使用更多的内存,但堆栈对象适用于托管用户线程。
如果未启用CONFIG_USERSPACE,则K_THREAD_STACK宏集与K_KERNEL_STACK宏具有相同的效果。
6.线程优先级
线程的优先级是一个整数值,并且可以是负值或非负值。数值上较低的优先级优先于数值上较高的值。例如,调度器给予优先级4的线程A比优先级7的线程B更高的优先级;优先级-2的线程C比线程A和线程B具有更高的优先级。
调度程序根据每个线程的优先级来区分两类线程。
- 协作线程的优先级值为负。一旦成为当前线程的协作线程,协作线程将保持当前线程,直到执行使其未准备好的操作。
- 可抢占的线程具有非负的优先级值。一旦它成为当前线程,如果一个合作线程或一个更高或同等优先级的优先线程准备就绪,一个优先线程可能在任何时候被取代。
线程的初始优先级值可以在线程启动后进行向上或向下的更改。因此,通过改变优先级,抢占线程可能成为一个协作线程,反之亦然.
注意:调度程序不会做出重新排序线程的启发式决策。仅根据应用程序的请求才能设置和更改线程优先级。
该内核支持几乎无限数量的线程优先级级别。配置选项CONFIG_NUM_COOP_PRIORITIES和CONFIG_NUM_PREEMPT_PRIORITIES指定每个线程类的优先级数,从而产生以下可用的优先级范围:
- 协作线程:(-CONFIG_NUM_COOP_PRIORITIES)到-1
- 优先线程:0到(CONFIG_NUM_PREEMPT_PRIORITIES-1)

例如,配置5个合作优先级和10个优先级优先级分别导致范围为-5到-1和0到9。
Meta-IRQ 优先级
启用时(请参见CONFIG_NUM_METAIRQ_PRIORITIES),在优先级空间的最高(数值最低)端处有一个特殊的协作优先级子类:MetaIRQ线程。它们是根据它们的正常优先级进行调度的,但也具有特殊的优先级抢占所有其他线程(和其他元irq线程),即使这些线程是协作的和/或已经采取了调度程序锁定。然而,Meta-IRQ线程仍然是线程,并且仍然可以被任何硬件中断中断。
这种行为使得解除解除Meat-irq线程的行为(通过任何方式,例如创建它、调用k_sem_give()等。在低优先级线程完成时的同步系统调用,或者从真中断上下文完成时类似arm的“挂起的IRQ”。其目的是,该特性将用于实现驱动程序子系统中的中断“下半部分”处理和/或“小任务”特性。该线程一旦被唤醒,将保证在当前CPU返回到应用程序代码之前运行。
与其他操作系统中的类似特性不同,meta-IRQ线程是真正的线程,并且运行在它们自己的堆栈上(必须正常分配),而不是每个cpu的中断堆栈。支持在受支持的架构上使用IRQ堆栈的设计工作正在进行中。
请注意,因为这违背了ZephyrAPI对协作线程的承诺(即在当前线程故意阻塞之前操作系统不会调度其他线程),所以应该在应用程序代码中非常小心地使用它。这些都不是简单的非常高优先级的线程,也不应该这样使用。
6.线程选项
内核支持一系列 线程选项(thread options),以允许线程在特殊情况下被特殊对待。这些与线程关联的选项在线程创建时就被指定了。
不需要任何线程选项的线程的选项值是零。如果线程需要选项,您可以通过选项名指定。如果需要多个选项,使用符号 | 作为分隔符。(即按位或操作符)。
支持以下线程选项。
此选项会将该线程标记为一个基本的线程。这将指示内核将线程的终止或中止视为一个致命的系统错误。默认情况下,线程不被认为是基本线程。
这两个选项是 x86 相关的选项,分别表示线程使用 CPU 的浮点寄存器和 SSE 寄存器,指示内核在调度线程进行时需要采取额外的步骤来保存/恢复这些寄存器的上下文。
默认情况下,内核在调度线程时不会保存/恢复这些寄存器的上下文.
K_USER
如果启用了CONFIG_USERSPACE,这个线程将在用户模式下创建,并且将拥有减少的特权。请参见用户模式。否则,此标志将无任何作用。
K_INHERIT_PERMS
如果启用了CONFIG_USERSPACE,此线程将继承父线程拥有的所有内核对象权限,但父线程对象除外。请参见用户模式。
7.线程自定义数据
每个线程都有一个32位的自定义数据区域,只有线程本身可以访问,应用程序可以用于它选择的任何目的。线程的默认自定义数据值为零。
注意:isr不使用自定义数据支持,因为它们在单个共享内核中断处理上下文中操作。
默认情况下,将禁用线程自定义数据支持。配置选项CONFIG_THREAD_CUSTOM_DATA可用于启用支持。
k_thread_custom_data_set()和k_thread_custom_data_get()函数分别用于写入和读取线程的自定义数据。一个线程只能访问它自己的自定义数据,而不能访问其他线程的数据。
下面的代码使用自定义数据特性来记录每个线程调用一个特定例程的次数。
int call_tracking_routine(void) {
uint32_t call_count;
if (k_is_in_isr()) {
/* ignore any call made by an ISR */
} else {
call_count = (uint32_t)k_thread_custom_data_get();
call_count++;
k_thread_custom_data_set((void *)call_count);
}
/* do rest of routine's processing */
...
}使用线程自定义数据允许例程访问线程特定的信息,通过使用自定义数据作为指向线程拥有的数据结构的指针。
8.线程实现
创建一个线程
通过定义其堆栈区及其线程控制块,然后调用k_thread_create()来生成一个线程。栈区域是一个由字节构成的数组,且其大小必须等于 K_THREAD_SIZEOF 加上线程栈大小之和。
必须使用K_THREAD_STACK_DEFINE或K_KERNEL_STACK_DEFINE定义堆栈区域,以确保它在内存中正确设置。
堆栈的size参数必须为以下三个值之一:
- 最初请求的堆栈大小传递给堆栈K_THREAD_STACK或实例化宏的K_KERNEL_STACK族。
- 对于使用K_THREAD_STACK宏族定义的堆栈对象,该对象的返回值为K_THREAD_STACK_SIZEOF()。
- 对于使用K_KERNEL_STACK宏族定义的堆栈对象,该对象的返回值为K_KERNEL_STACK_SIZEOF()。
线程生成函数返回其线程id,可用于引用该线程。
下面的代码会生成一个立即启动的线程。
# define MY_STACK_SIZE 500
# define MY_PRIORITY 5
extern void my_entry_point(void *, void *, void *);
K_THREAD_STACK_DEFINE(my_stack_area, MY_STACK_SIZE);
struct k_thread my_thread_data;
k_tid_t my_tid = k_thread_create(&my_thread_data, my_stack_area,
K_THREAD_STACK_SIZEOF(my_stack_area),
my_entry_point,
NULL, NULL, NULL,
MY_PRIORITY, 0, K_NO_WAIT);或者,也可以通过在编译时调用K_THREAD_DEFINE来声明一个线程。请注意,宏会自动定义堆栈区域、控制块和线程id变量。
下面的代码与上面的代码段具有相同的效果。
# define MY_STACK_SIZE 500
# define MY_PRIORITY 5
extern void my_entry_point(void *, void *, void *);
K_THREAD_DEFINE(my_tid, MY_STACK_SIZE,
my_entry_point, NULL, NULL, NULL,
MY_PRIORITY, 0, 0);注意:k_thread_create()的延迟参数是一个k_timeout_t值,所以K_NO_WAIT意味着立即启动线程。与K_THREAD_DEFINE对应的参数是一个以积分毫秒为单位的持续时间,因此等效参数为0。
用户模式约束
此部分仅适用于启用CONFIG_USERSPACE,并且用户线程尝试创建新线程。k_thread_create()API仍然在使用,但是必须满足一些额外的约束,否则调用线程将被终止:
- 调用线程必须具有授予子线程和堆栈参数的权限;两者都由内核作为内核对象进行跟踪。
- 子线程和堆栈对象必须处于未初始化状态,即它当前没有运行,堆栈内存未使用。
- 子线程和堆栈对象必须处于未初始化状态,即它当前没有运行,堆栈内存未使用。
- 必须使用K_USER选项,因为用户线程只能创建其他用户线程。
- 不能使用K_ESSENTIAL选项,用户线程可能不能被认为是基本线程。
- 子线程的优先级必须是有效的优先级值,并且等于或低于父线程。
删除权限
如果启用了CONFIG_USERSPACE,那么在监控模式下运行的线程可以使用k_thread_user_mode_enter()API执行到用户模式的单向转换。这是一个单向的操作,它将重置和零的线程的堆栈内存。该螺纹将被标记为非必要的。
终止线程
一个线程通过从其入口点函数返回来终止自己。下面的代码说明了线程可以终止的方式
void my_entry_point(int unused1, int unused2, int unused3)
{
while (1) {
...
if (<some condition>) {
return; /* thread terminates from mid-entry point function */
}
...
}
/* thread terminates at end of entry point function */
}如果启用了CONFIG_USERSPACE,中止一个线程将另外将线程和堆栈对象标记为未初始化,以便它们可以被重用。
运行时统计信息
如果启用了CONFIG_THREAD_RUNTIME_STATS,则可以收集和检索线程运行时统计信息,例如,一个线程的执行周期的总数。
默认情况下,运行时统计信息是使用默认的内核计时器来收集的。对于某些架构、SoCs或板,有通过计时功能具有更高分辨率的计时器。使用这些计时器可以通过CONFIG_THREAD_RUNTIME_STATS_USE_TIMING_FUNCTIONS.来启用
下面是一个示例:
k_thread_runtime_stats_t rt_stats_thread;
k_thread_runtime_stats_get(k_current_get(), &rt_stats_thread);
printk("Cycles: %llu\n", rt_stats_thread.execution_cycles);建议的用途
使用线程来处理在ISR中无法处理的处理。
使用单独的线程来处理可以并行执行的逻辑上不同的处理操作。
配置选项
相关配置选项:
• CONFIG_MAIN_THREAD_PRIORITY
• CONFIG_MAIN_STACK_SIZE
• CONFIG_IDLE_STACK_SIZE
• CONFIG_THREAD_CUSTOM_DATA
• CONFIG_NUM_COOP_PRIORITIES
• CONFIG_NUM_PREEMPT_PRIORITIES
• CONFIG_TIMESLICING
• CONFIG_TIMESLICE_SIZE
• CONFIG_TIMESLICE_PRIORITY
• CONFIG_USERSPACE9.API参考
宏定义
参数说明:thread-授予对象访问权限的线程...-内核对象指针的列表
K_THREAD_DEFINE(name, stack_size, entry, p1, p2, p3, prio, options, delay)
静态地定义和初始化一个线程。
线程可能被计划立即执行或延迟启动。
线程选项是特定于架构的,可以包括K_ESSENTIAL、K_FP_REGS和K_SSE_REGS。可以通过使用“|”(逻辑OR运算符)来分离它们来指定多个选项。
线程的ID可以使用:
参数说明
• name – 线程名称• stack_size – 堆栈大小.• entry – 线程的输入功能• p1 – 第一个入口指针参数.• p2 –第二个输入指针参数.• p3 –第三个输入指针参数.• prio – 线程优先级• options –线程选项.• delay –调度延迟或者零延迟
Typedefs
typedef void (*k_thread_user_cb_t)(const struct k_thread *thread, void *user_data)