目录
程序的编译和执行环境
c/c++不同于其他跑在虚拟机上的程序语言,c/c++在编写完代码,点击运行时,这段代码在编译器内先经过预编译,编译,汇编,链接等过程生成可执行程序文件,后缀为.exe,然后将可执行文件写入内存中,实行程序的运行。这篇文章我们简单探讨一下这几个过程究竟发生了什么事,最终的可执行程序是如何形成的。
预编译
在预编译过程,编辑器首先会删掉代码中的注释,因为注释是给程序使用者看的,代码文件不需要这些。删除注释之后,编辑器会将程序包含的头文件的声明的内容导入到该程序中,,然后将预定义的符号完成替换,如将 #define中的内容替换,这些工作完成之后,就会生成一个后缀为 .obj 的文件
编译
在编译这个阶段,会将前面预编译处理好的代码进行词法分析,语法分析,符号汇总,语义分析,分析完成后,再将分析完成的代码转换成汇编代码。汇编代码与机器码是一一对应的,无论哪种编程语言,都要在其编译器上将要执行的代码转换成汇编代码,然后再将汇编代码转换成机器码。不过在编译这个阶段,还没有将汇编代码转换成机器码,这是汇编阶段该做的事。
汇编
在汇编这个阶段,就是将前面编译阶段形成的汇编代码转换成机器码,并且将前面的符号汇总表示成一张符号表,到这里,对代码的处理工作就算是完成了,接下来就剩下链接这个阶段,下面一张图能更好的理解链接阶段。

链接
在一般开发项目中,会有多个源文件,每个源文件都难免会包含一些相同的头文件,而链接这个阶段就是将前面处理好的源文件进行一个汇总,将不同源文件中的符号表进行汇总,去除相同的只保留一个有效的,然后再去链接库抽取需要的代码,最终形成可执行文件。为什么说是去链接库抽取呢,如果是我们完全自己实现的头文件,就不需要像链接库抽取,但像引用了标准头文件,例如<stdio.h>里的printf,scanf等,这些函数的代码是放在链接库的,只有去链接抽取,才能够使用。当然这个过程是没有那么简单的,这里只是简单描述一下,想更深入的了解可以参考书籍《程序是怎样跑起来的》,《程序员的自我修养》
预定义
简单介绍一下程序的可执行文件是如何生成的,接下来我们回到预定义
预定义符号


以上是基本的预定义符号,不过编译器已经定义好了,我们无需重复定义,拿着用即可,上面的预定义符在写日志的时候会用到
预定义宏
在定义宏时的命名规定是宏名一般用大写字母表示,区别于其他符号
宏的本质是替换,因此在使用宏定义时,稍有不慎就会产生歧义,为了避免产生歧义,就要多使用括号,来分配优先级。
看下面一个例子
#define SQARE(x) x*x
int main()
{
int r = SQARE(5+1)
}
#define SQARE(x) ((x)*(x))
int main()
{
int r = SQARE(5+1)
}
//仔细看上面的代码,算一下它们各自的值是多少
为什么会这样呢?预定义的本质是替换,我们把数值替换过去试试
第一个 m = 5 + 1 * 5 + 1
第二个 n = ((5+1) * (5+1))
替换后再进行运算就发现了问题,第一个在进行替换后,因为运算优先级的问题,产生了歧义,导致程序未达到我们想要的结果,因此在预定义时不要吝啬括号。
尝试写一个宏,用来计算结构体某成员相对于起始位置的偏移量
想一想再看下面的代码
#include<stdio.h>
#define STRUCTSIZE(STRUCTTYPE, MBERNAME) \
(int)&(((STRUCTTYPE *)0)->MBERNAME) //宏定义的实现
struct S
{
char a;
int b;
float c;
} s;
int main()
{
printf("%d", STRUCTSIZE(struct S, b));
return 0;
}
//思路:首先就是将数字0强制转化成要求的结构体的指针类型
那么这个0就是该结构体指针类型的0地址,结构体每个成员的偏移量,本质上就是相对于结构体起始位置的地址差,我们用这个起始地址为0的结构体指针解引用其内部成员,然后取出该成员的地址再强制转换成int 类型,就表示出了偏移量#与##的用法
#的作用就是将要传的参数以字符串的形式表示
举个例子
//在这之前需要了解
printf("hello ""word\n");
printf("hello world\n");
//这两种写法是等价的,printf会将多组字符串合并成一串
#include<stdio.h>
#define PRINT(FORMAT, VALUE) \ //这里'\'的作用是抵消换行
printf("the value is "FORMAT, VALUE)
int main()
{
int a = 1;
int b = 2;
printf("the value is %d\n", a);
printf("the value is %d\n", b);
PRINT("%d\n", a);
PRINT("%d\n", b);
return 0;
}
//该代码段的程序起铺垫作用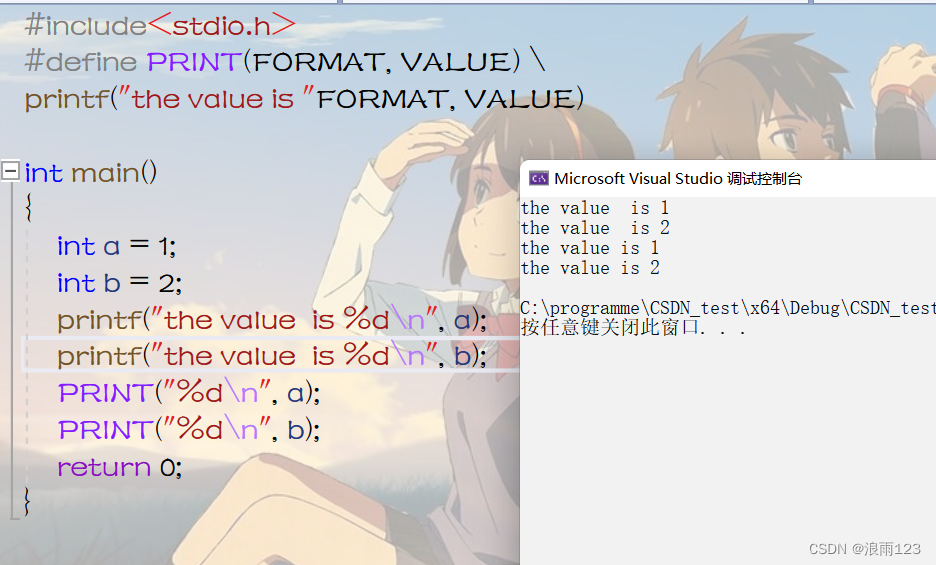
#include<stdio.h>
int main()
{
int a = 1;
int b = 2;
printf("the value of a is %d\n", a);
printf("the value of b is %d\n", b);
return 0;
}
//看上面的程序,除了a,b的不同,其他都是相同的,因此我们能不能把
printf("the value of a is %d\n", a);
printf("the value of b is %d\n", b);
//封装成一个函数,只需要输入一个参数就能实现同样的输出
//但事实上,函数是无法实现的,因为函数没有办法表示出"the value of a is %d\n"中的 a,
"the value of b is %d\n"中的 b ,而用宏定义可以实现,#就派上了用场
#include<stdio.h>
#define PRINT(VALUE) \
printf("the value of "#VALUE" is %d\n", VALUE)
int main()
{
int a = 1;
int b = 2;
PRINT(a);
PRINT(b);
return 0;
}
//#会将要替换的参数以字符串的形式表示
//以上程序的替换结果如下
1.第一个将参数 VALUE 替换成a
printf("the value of "#VALUE" is %d\n", VALUE)
printf("the value of " "a" " is %d\n", a)
2.第二个将参数 VALUE 替换成b
printf("the value of "#VALUE" is %d\n", VALUE)
printf("the value of " "b" " is %d\n", b) ##的作用是将##两边的字符串连接在一起
举个栗子
#include<stdio.h>
#define FUN(VALUE1, value2) VALUE1##VALUE2
int main()
{
int langyu = 10;
printf("%d ", FUN(lang, yu));
return 0;
}
//FUN会将lang 和 yu结合在一起,形成langyu,程序最终的结果会打印10函数与预定义的区别
#include<stdio.h>
#define SQARE(x) ((x)*(x))
int Sqare(int m)
{
return m*m ;
}
int main()
{
int r = SQARE(5+1);
int n = Sqare(5+1);
printf("%d %d", r, n);
return 0;
}1.宏定义在处理时是直接替换,而函数的定义在处理时要在内存上开辟一处栈空间,所占用的内存远多于宏定义
2.函数栈帧的创建,理论上要执行更多的指令,在运行速度上宏定义也胜一筹
3.宏定义可以使用其他宏定义的符号,但是不能够递归调用,也就是不能够自己调用自己
4.对于实现较为复杂的功能,使用函数更为方便,但是有一些功能函数没有办法实现的,而预定义可以很好的实现,参考上面的#的使用
5.宏定义不会对参数进行检查,函数对参数检查较为严格,不容易出错
6.宏是没法调试的
条件编译
在编写代码时,可能有一段代码是用来测试结果的,如果不删,感觉有些碍事,但是删了的话下次调试又要重写,这个时候可以考虑使用条件编译,满足条件就参加编译,不满足条件就不参加编译,下面列出一些常见的条件编译
1.单支条件编译
#if 常量表达式
//...
#endif //如果常量表达式为真,则中间的代码参与编译,若为假,则不参加编译
2.多分支条件编译
#if 常量表达式
//...
#elif 常量表达式
//...
#else
//...
#endif //哪一个分支的常量表达式为真,那个分支下的代码就参与编译
3.判断是否被定义
#define X 10
#if define(X) //#ifdf X 这种写法可以平替
//...
#endif //如果X被定义了,那么中间的代码就参与编译,如果X未被定义,则不参与编译
#if !define(X) //#ifndf 这种写法可以平替
//...
#endif //如果X未被定义,则运行中间的代码,若被定义了,则不运行
4.嵌套指令
#if defined(X)
#ifdef OPTION1
//...
#endif
#ifdef OPTION2
//...
#endif
#elif defined(Y)
#ifdef OPTION2
//...
#endif
#endif
//条件预定义符可以嵌套使用文件包含
在进行头文件包含时,我们通常有两种包含方式,一种是用 " " 来包含
两一种是用< > 来包含,那么这两种包含形式有什么区别呢?
这两种包含方式的主要区别是查找文件的策略不同
" " 这种包含方式编译器会首先查找该程序目录下的文件,如果查找不到就去库目录查
<>这种包含方式编译器会直接去库目录下查找
例如,标准库文件stdio.h就用<>来包含,编译器会直接去库文件查找
包含头文件后,编译器会在预编译阶段就去查找头文件,将包含信息替换成文件里的内容,此时若重复包含头文件,会造成包含内容的多次重复,无效代码量就增多
可能你会觉得自己怎么可能会重复包含某个头文件,重复包含的情况多出在多人开发上
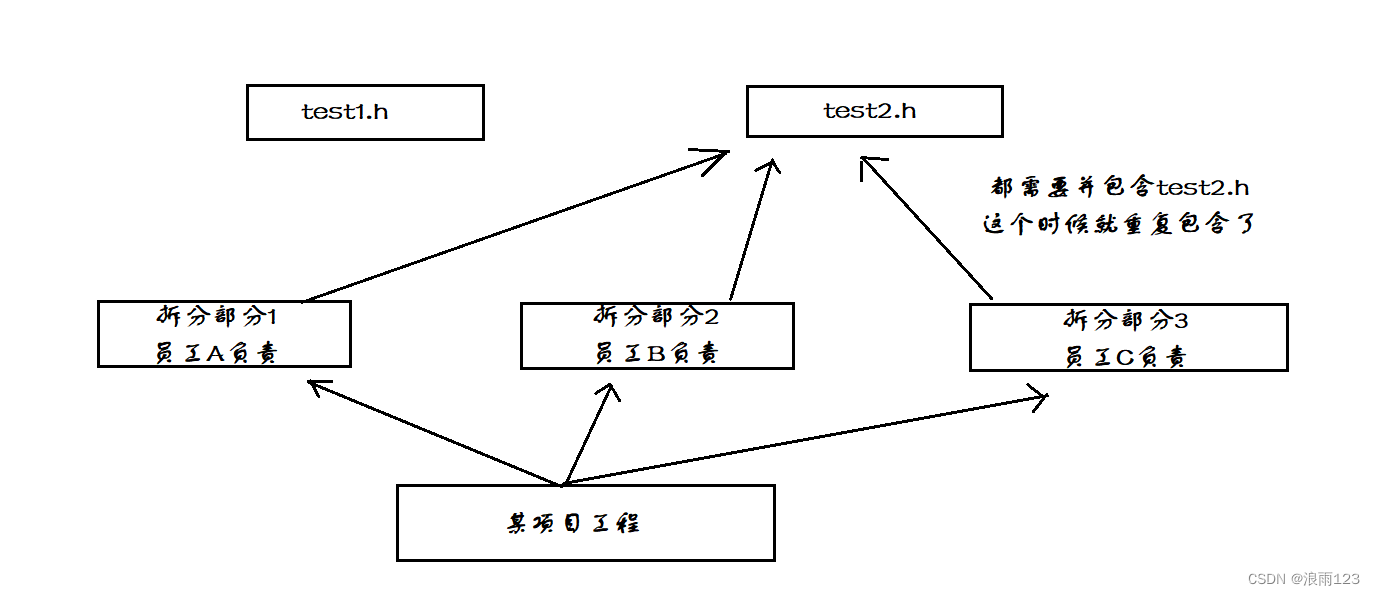
那么该怎么避免重复包含的情况呢
有两种方法
1.较为繁杂
2.较为简便
方法一
#ifndef __TEST_H__
#define __TEST_H__
//头文件的内容
#endif //__TEST_H__
//把要包含的头文件放到中间注释区域
方法二
#pragma once
//在文件的开始位置写上即可