Java程序基础
一,安装开发环境
安装JDK
-
从ORACLE官网下载
找到下载界面window
- 下载x64 Installer
设置环境变量
https://www.cnblogs.com/happyone/p/11938883.html)
二,Hello, world!
1.public class Hello
public class Hello {
public static void main(String[] args) {
System.out.println("Hello, world!");
}
}
Hello是类的名字,按照习惯,首字母H要大写。
class用来定义一个类
public表示这个类是公开的
而花括号{}中间则是类的定义
public、class都是Java的关键字,必须小写,Hello是类的名字,按照习惯,首字母H要大写
| 快捷键 | 作用 | 快捷键 | 作用 |
|---|---|---|---|
| Ctrl+1 | 一阶标题 | Ctrl+B | 字体加粗 |
| Ctrl+2 | 二阶标题 | Ctrl+I | 字体倾斜 |
| Ctrl+3 | 三阶标题 | Ctrl+U | 下划线 |
| Ctrl+4 | 四阶标题 | Ctrl+Home | 返回Typora顶部 |
| Ctrl+5 | 五阶标题 | Ctrl+End | 返回Typora底部 |
| Ctrl+6 | 六阶标题 | Ctrl+T | 创建表格 |
| Ctrl+L | 选中某句话 | Ctrl+K | 创建超链接 |
| Ctrl+D | 选中某个单词 | Ctrl+F | 搜索 |
| Ctrl+E | 选中相同格式的文字 | Ctrl+H | 搜索并替换 |
| Alt+Shift+5 | 删除线 | Ctrl+Shift+I | 插入图片 |
2.定义一个名为main的方法
public class Hello {
public static void main(String[] args) {
System.out.println("Hello, world!");
}
}
在类的定义中,我们定义了一个名为main的方法:
方法是可执行的代码块,一个方法除了方法名main,还有用()括起来的方法参数,这里的main方法有一个参数,
参数类型是 String[],
参数名是 args,
public、static 用来修饰方法,
这里表示它是一个公开的静态方法,void是方法的返回类型,而花括号{}中间的就是方法的代码。
3.输出Hello, world!
方法的代码每一行用 ; 结束
这里只有一行代码,就是:
System.out.println(“Hello, world!”);
它用来打印一个字符串到屏幕上。
Java规定,某个类定义的public static void main(String[] args)是Java程序的固定入口方法,因此,Java程序总是从main方法开始执行。
注意Java源码的缩进不是必须的,但是用缩进后,格式好看,很容易看出代码块的开始和结束,缩进一般是4个空格或者一个tab。
4.保存
最后,把代码保存为文件时,
- 文件名必须是Hello.java
- 文件名也要注意大小写,因为要和我们定义的类名Hello完全保持一致
三,Java基本结构
/**
* 可以用来自动创建文档的注释
*/
public class Hello {
public static void main(String[] args) {
// 向屏幕输出文本:
System.out.println("Hello, world!");
/* 多行注释开始
注释内容
注释结束 */
}
} // class定义结束
因为Java是面向对象的语言,
一个程序的基本单位就是 class,class 是关键字,这里定义的 class 名字就是 Hello
public class Hello { // 类名是Hello
} // class定义结束
类名是Hello
1.类名要求
- 类名必须以英文字母开头,后接字母,数字和下划线的组合
- 习惯以大写字母开头
要注意遵守命名习惯,好的类命名:
- Hello
- NoteBook
- VRPlayer
不好的类命名:
- hello
- Good123
- Note_Book
- _World
2.定义一个名为main的方法
public class Hello {
public static void main(String[] args) { // 方法名是main
// 方法代码...
} // 方法定义结束
}
注意小方法:
第一行:
注意到public是访问修饰符,表示该class是公开的。
不写public,也能正确编译,但是这个类将无法从命令行执行。
在class内部,可以定义若干方法(method):
第二行:
-
方法名是main,返回值是void
-
public除了可以修饰class外,也可以修饰方法。而关键字static是另一个修饰符,它表示静态方法
3.方法名
方法名也有命名规则,命名和 class 一样,但是首字母小写:
好的方法命名:
- main
- goodMorning
- playVR
不好的方法命名:
-
Main
-
good123
-
good_morning
-
_playVR
4.执行代码
public class Hello {
public static void main(String[] args) {
System.out.println("Hello, world!"); // 语句
}
}
在方法内部,语句才是真正的执行代码。
Java的每一行语句必须以分号结束
5.注释
共三种
one,单行注释
以双斜线开头,直到这一行的结尾结束:
// 这是注释...
two,多行注释
以**/*星号开头,以*/**结束,可以有多行:
/*
这是注释
blablabla...
这也是注释
*/
three,特殊的多行注释
以**/*开头,以*/**结束,如果有多行,每行通常以星号开头:
/**
* 可以用来自动创建文档的注释
*
*
*/
public class Hello {
public static void main(String[] args) {
System.out.println("Hello, world!");
}
}
这种特殊的多行注释需要写在类和方法的定义处,可以用于自动创建文档
四,变量
1.给变量赋值
Java中,变量必须先定义后使用
在定义变量的时候,可以给它一个初始值。
例如:
int x = 1;
上述语句定义了一个整型int类型的变量
名称为x,初始值为1。
不写初始值,就相当于给它指定了默认值
默认值总是0。
eg:
定义变量,然后打印变量值:
public class Main {
public static void main(String[] args) {
int x = 100; // 定义int类型变量x,并赋予初始值100
System.out.println(x); // 打印该变量的值
}
}
结果:
100
2.重新赋值
变量的一个重要特点是可以重新赋值。
eg:
对变量x,先赋值100,再赋值200
public class Main {
public static void main(String[] args) {
int x = 100; // 定义int类型变量x,并赋予初始值100
System.out.println(x); // 打印该变量的值,观察是否为100
x = 200; // 重新赋值为200
System.out.println(x); // 打印该变量的值,观察是否为200
}
}
结果:
100
200
3.!!!综上总结!!!!:
注意
第一次定义变量x的时候,需要指定变量类型int,因此使用语句int x = 100;
而第二次重新赋值的时候,变量x已经存在了,不能再重复定义,因此不能指定变量类型int
必须使用语句x = 200
变量不但可以重新赋值,还可以赋值给其他变量。
eg:
public class Main {
public static void main(String[] args) {
int n = 100; // 定义变量n,同时赋值为100
System.out.println("n = " + n); // 打印n的值
n = 200; // 变量n赋值为200
System.out.println("n = " + n); // 打印n的值
int x = n;
// 变量x赋值为n(n的值为200,因此赋值后x的值也是200)
System.out.println("x = " + x); // 打印x的值
x = x + 100;
// 变量x赋值为x+100(x的值为200,因此赋值后x的值是200+100=300)
System.out.println("x = " + x); // 打印x的值
System.out.println("n = " + n); // 再次打印n的值
}
}
结果:
n = 100
n = 200
x = 200
x = 300
n = 200
代码流程分析
五,基本数据类型
前言:计算机内存的基本结构
- 整数类型:byte,short,int,long
- 浮点数类型:float,double
- 字符类型:char
- 布尔类型:boolean
计算机内存的最小存储单元是字节(byte)
一个字节就是一个8位二进制数,即8个bit
它的二进制表示范围从00000000~11111111
换算成十进制是0~255
换算成十六进制是00~ff
内存单元从0开始编号,称为内存地址
每个内存单元可以看作一间房间,内存地址就是门牌号
0 1 2 3 4 5 6 ...
┌───┬───┬───┬───┬───┬───┬───┐
│ │ │ │ │ │ │ │...
└───┴───┴───┴───┴───┴───┴───┘
一个字节是1byte,1024字节是1K,1024K是1M,1024M是1G,1024G是1T。
一个拥有4T内存的计算机的字节数量就是:
4T = 4 x 1024G
= 4 x 1024 x 1024M
= 4 x 1024 x 1024 x 1024K
= 4 x 1024 x 1024 x 1024 x 1024
= 4398046511104
不同的数据类型占用的字节数不一样。我们看一下Java基本数据类型占用的字节数:
┌───┐
byte │ │
└───┘
┌───┬───┐
short │ │ │
└───┴───┘
┌───┬───┬───┬───┐
int │ │ │ │ │
└───┴───┴───┴───┘
┌───┬───┬───┬───┬───┬───┬───┬───┐
long │ │ │ │ │ │ │ │ │
└───┴───┴───┴───┴───┴───┴───┴───┘
┌───┬───┬───┬───┐
float │ │ │ │ │
└───┴───┴───┴───┘
┌───┬───┬───┬───┬───┬───┬───┬───┐
double │ │ │ │ │ │ │ │ │
└───┴───┴───┴───┴───┴───┴───┴───┘
┌───┬───┐
char │ │ │
└───┴───┘
byte恰好就是一个字节,而long和double需要8个字节。
1.整数类型:
byte,short,int,long
对于整型类型,Java只定义了带符号的整型,
因此,最高位的bit表示符号位(0表示正数,1表示负数)。
各种整型能表示的最大范围如下:
- byte:-128 ~ 127
- short: -32768 ~ 32767
- int: -2147483648 ~ 2147483647
- long: -9223372036854775808 ~ 9223372036854775807
如下定义整型的例子:
public class Main {
public static void main(String[] args) {
int i = 2147483647;
int i2 = -2147483648;
int i3 = 2_000_000_000; // 加下划线更容易识别
int i4 = 0xff0000; // 十六进制表示的16711680
int i5 = 0b1000000000; // 二进制表示的512
long l = 9000000000000000000L; // long型的结尾需要加L
}
}
2.浮点数类型:
float,double
浮点类型的数就是小数,因为小数用科学计数法表示的时候,小数点是可以“浮动”的,如1234.5可以表示成12.345x102,也可以表示成1.2345x103,所以称为浮点数。
下面是定义浮点数的例子:
float f1 = 3.14f;
float f2 = 3.14e38f; // 科学计数法表示的3.14x10^38
double d = 1.79e308;
double d2 = -1.79e308;
double d3 = 4.9e-324; // 科学计数法表示的4.9x10^-324
注意
对于 float 类 型,需要加上 f 后缀。
浮点数可表示的范围非常大,float类型可最大表示3.4x1038,而double类型可最大表示1.79x10308。
3.字符类型:
char
字符类型 char 表示一个字符。
Java的 char 类型除了可表示标准的 ASCII 外,还可以表示一个 Unicode 字符:
eg:
public class Main {
public static void main(String[] args) {
char a = 'A';
char zh = '中';
System.out.println(a);
System.out.println(zh);
}
}
结果:
A
中
注意char类型使用单引号 ’ ,且仅有一个字符,要和双引号 " 的字符串类型区分开。
4.布尔类型:
boolean
布尔类型boolean只有true和false两个值,布尔类型总是关系运算的计算结果:
boolean b1 = true;
boolean b2 = false;
boolean isGreater = 5 > 3; // 计算结果为true
int age = 12;
boolean isAdult = age >= 18; // 计算结果为false
Java语言对布尔类型的存储并没有做规定,因为理论上存储布尔类型只需要1 bit,但是通常JVM内部会把boolean表示为4字节整数。
5.引用类型
除了上述基本类型的变量,剩下的都是引用类型。例如,引用类型最常用的就是String字符串:
String s = "hello";
引用类型的变量类似于C语言的指针,它内部存储一个“地址”,指向某个对象在内存的位置,后续我们介绍类的概念时会详细讨论。
6.常量
定义变量的时候,如果加上 final 修饰符,这个变量就变成了常量:
final double PI = 3.14; // PI是一个常量
double r = 5.0;
double area = PI * r * r;
PI = 300; // compile error!
常量在定义时进行初始化后就不可再次赋值,再次赋值会导致编译错误。
常量的作用是用有意义的变量名来避免魔术数字(Magic number),例如,不要在代码中到处写 3.14 ,而是定义一个常量。如果将来需要提高计算精度,我们只需要在常量的定义处修改,例如,改成 3.1416,而不必在所有地方替换 3.14。
根据习惯,常量名通常全部大写。
7.var关键字
有些时候,类型的名字太长,写起来比较麻烦。例如:
StringBuilder sb = new StringBuilder();
这个时候,如果想省略变量类型,可以使用var关键字:
var sb = new StringBuilder();
编译器会根据赋值语句自动推断出变量sb的类型是StringBuilder。对编译器来说,语句:
var sb = new StringBuilder();
实际上会自动变成:
StringBuilder sb = new StringBuilder();
因此,使用var定义变量,仅仅是少写了变量类型而已。
8.变量的作用范围
在Java中,多行语句用{ }括起来。很多控制语句,例如条件判断和循环,都以{ }作为它们自身的范围,例如:
if (...) { // if开始
...
while (...) { // while 开始
...
if (...) { // if开始
...
} // if结束
...
} // while结束
...
} // if结束
只要正确地嵌套这些{ },编译器就能识别出语句块的开始和结束。而在语句块中定义的变量,它有一个作用域,就是从定义处开始,到语句块结束。超出了作用域引用这些变量,编译器会报错。举个例子:
{
...
int i = 0; // 变量i从这里开始定义
...
{
...
int x = 1; // 变量x从这里开始定义
...
{
...
String s = "hello"; // 变量s从这里开始定义
...
} // 变量s作用域到此结束
...
// 注意,这是一个新的变量s,它和上面的变量同名,
// 但是因为作用域不同,它们是两个不同的变量:
String s = "hi";
...
} // 变量x和s作用域到此结束
...
} // 变量i作用域到此结束
定义变量时,要遵循作用域最小化原则,尽量将变量定义在尽可能小的作用域,并且,不要重复使用变量名。
总结:
Java提供了两种变量类型:
基本类型和引用类型
基本类型包括
整型,浮点型,布尔型,字符型。
变量可重新赋值,等号是赋值语句,不是数学意义的等号。
常量在初始化后不可重新赋值,使用常量便于理解程序意图。
六,整数运算
1.四则运算
Java的整数运算遵循四则运算规则,可以使用任意嵌套的小括号。四则运算规则和初等数学一致
public class Main {
public static void main(String[] args) {
int i = (100 + 200) * (99 - 88); // 3300
int n = 7 * (5 + (i - 9)); // 23072
System.out.println(i);
System.out.println(n);
}
}
结果:
3300
23072
整数的数值表示不但是精确的,而且整数运算永远是精确的,即使是除法也是精确的,因为两个整数相除只能得到结果的整数部分:
int x = 12345 / 67; // 184
结果:
184
求余运算使用%:
int y = 12345 % 67; // 12345÷67的余数是17
17
特别注意:整数的除法对于除数为0时运行时将报错,但编译不会报错。
2.溢出
要特别注意,整数由于存在范围限制,如果计算结果超出了范围,就会产生溢出,而溢出不会出错,却会得到一个奇怪的结果:
public class Main {
public static void main(String[] args) {
int x = 2147483640;
int y = 15;
int sum = x + y;
System.out.println(sum); // -2147483641
}
}
结果:
-2147483641
要解释上述结果,我们把整数2147483640和15换成二进制做加法:
0111 1111 1111 1111 1111 1111 1111 1000
+ 0000 0000 0000 0000 0000 0000 0000 1111
-----------------------------------------
1000 0000 0000 0000 0000 0000 0000 0111
由于最高位计算结果为1,因此,加法结果变成了一个负数。
要解决上面的问题,可以把int换成long类型,由于long可表示的整型范围更大,所以结果就不会溢出:
long x = 2147483640;
long y = 15;
long sum = x + y;
System.out.println(sum); // 2147483655
结果:
2147483655
3.简写运算符
+=,
-=
*=
/=
n += 100; // 3409, 相当于 n = n + 100;
n -= 100; // 3309, 相当于 n = n - 100;
4.自增/自减
Java还提供了++运算和--运算,它们可以对一个整数进行加1和减1的操作:
public class Main {
public static void main(String[] args) {
int n = 3300;
n++; // 3301, 相当于 n = n + 1;
n--; // 3300, 相当于 n = n - 1;
int y = 100 + (++n); // 不要这么写
System.out.println(y);
}
}
结果:
3401
注意++写在前面和后面计算结果是不同的,
++n表示先加1再引用n,
n++表示先引用n再加1。
不建议把++运算混入到常规运算中,容易自己把自己搞懵了。
5.移位运算
在计算机中,整数总是以二进制的形式表示。例如,int类型的整数7使用4字节表示的二进制如下:
00000000 0000000 0000000 00000111
可以对整数进行移位运算。对整数7左移1位将得到整数14,左移两位将得到整数28:
int n = 7; // 00000000 00000000 00000000 00000111 = 7
int a = n << 1; // 00000000 00000000 00000000 00001110 = 14
int b = n << 2; // 00000000 00000000 00000000 00011100 = 28
int c = n << 28; // 01110000 00000000 00000000 00000000 = 1879048192
int d = n << 29; // 11100000 00000000 00000000 00000000 = -536870912
左移29位时,由于最高位变成1,因此结果变成了负数。
类似的,对整数28进行右移,结果如下:
int n = 7; // 00000000 00000000 00000000 00000111 = 7
int a = n >> 1; // 00000000 00000000 00000000 00000011 = 3
int b = n >> 2; // 00000000 00000000 00000000 00000001 = 1
int c = n >> 3; // 00000000 00000000 00000000 00000000 = 0
如果对一个负数进行右移,最高位的1不动,结果仍然是一个负数:
int n = -536870912;
int a = n >> 1; // 11110000 00000000 00000000 00000000 = -268435456
int b = n >> 2; // 11111000 00000000 00000000 00000000 = -134217728
int c = n >> 28; // 11111111 11111111 11111111 11111110 = -2
int d = n >> 29; // 11111111 11111111 11111111 11111111 = -1
还有一种无符号的右移运算,使用>>>,它的特点是不管符号位,右移后高位总是补0,因此,对一个负数进行>>>右移,它会变成正数,原因是最高位的1变成了0:
int n = -536870912;
int a = n >>> 1; // 01110000 00000000 00000000 00000000 = 1879048192
int b = n >>> 2; // 00111000 00000000 00000000 00000000 = 939524096
int c = n >>> 29; // 00000000 00000000 00000000 00000111 = 7
int d = n >>> 31; // 00000000 00000000 00000000 00000001 = 1
对byte和short类型进行移位时,会首先转换为int再进行位移。
仔细观察可发现,左移实际上就是不断地×2,右移实际上就是不断地÷2。
6.位运算
位运算是按位进行与、或、非和异或的运算。
与运算的规则是,必须两个数同时为1,结果才为1:
n = 0 & 0; // 0
n = 0 & 1; // 0
n = 1 & 0; // 0
n = 1 & 1; // 1
或运算的规则是,只要任意一个为1,结果就为1:
n = 0 | 0; // 0
n = 0 | 1; // 1
n = 1 | 0; // 1
n = 1 | 1; // 1
非运算的规则是,0和1互换:
n = ~0; // 1
n = ~1; // 0
异或运算的规则是,如果两个数不同,结果为1,否则为0:
n = 0 ^ 0; // 0
n = 0 ^ 1; // 1
n = 1 ^ 0; // 1
n = 1 ^ 1; // 0
对两个整数进行位运算,实际上就是按位对齐,然后依次对每一位进行运算。例如:
public class Main {
public static void main(String[] args) {
int i = 167776589; // 00001010 00000000 00010001 01001101
int n = 167776512; // 00001010 00000000 00010001 00000000
System.out.println(i & n); // 167776512
}
}
7.运算优先级
在Java的计算表达式中,运算优先级从高到低依次是:
()!~++--*/%+-<<>>>>>&|+=-=*=/=
8.类型自动提升与强制转型
public class Main {
public static void main(String[] args) {
short s = 1234;
int i = 123456;
int x = s + i; // s自动转型为int
short y = s + i; // 编译错误!
}
}
在运算过程中,如果参与运算的两个数类型不一致
那么计算结果为较大类型的整型。例如,short和int计算,结果总是int,原因是short首先自动被转型为int
public class Main {
public static void main(String[] args) {
short s = 1234;
int i = 123456;
int x = s + i; // s自动转型为int
short y = s + i; // 编译错误!
}
}
结果:
Main.java:7: error: incompatible types: possible lossy conversion from int to short
short y = s + i; // 编译错误!
^
1 error
error: compilation failed
也可以将结果强制转型,即将大范围的整数转型为小范围的整数。强制转型使用(类型),例如,将int强制转型为short:
int i = 12345;
short s = (short) i; // 12345
要注意,超出范围的强制转型会得到错误的结果,原因是转型时,int的两个高位字节直接被扔掉,仅保留了低位的两个字节:
public class Main {
public static void main(String[] args) {
int i1 = 1234567;
short s1 = (short) i1; // -10617
System.out.println(s1);
int i2 = 12345678;
short s2 = (short) i2; // 24910
System.out.println(s2);
}
}
七,浮点数运算
1.误差
浮点数0.1在计算机中就无法精确表示,因为十进制的0.1换算成二进制是一个无限循环小数,很显然,无论使用float还是double,都只能存储一个0.1的近似值。但是,0.5这个浮点数又可以精确地表示。
eg:
因为浮点数常常无法精确表示,因此,浮点数运算会产生误差:
public class Main {
public static void main(String[] args) {
double x = 1.0 / 10;
double y = 1 - 9.0 / 10;
// 观察x和y是否相等:
System.out.println(x);
System.out.println(y);
}
}
结果:
0.1
0.09999999999999998
由于浮点数存在运算误差,所以比较两个浮点数是否相等常常会出现错误的结果。正确的比较方法是判断两个浮点数之差的绝对值是否小于一个很小的数:
// 比较x和y是否相等,先计算其差的绝对值:
double r = Math.abs(x - y);
// 再判断绝对值是否足够小:
if (r < 0.00001) {
// 可以认为相等
} else {
// 不相等
}
*浮点数在内存的表示方法和整数比更加复杂。Java的浮点数完全遵循**IEEE-754*标准,这也是绝大多数计算机平台都支持的浮点数标准表示方法。
2.类型提升
如果参与运算的两个数其中一个是整型,那么整型可以自动提升到浮点型:
public class Main {
public static void main(String[] args) {
int n = 5;
double d = 1.2 + 24.0 / n; // 6.0
System.out.println(d);
}
}
结果:
6.0
需要特别注意,在一个复杂的四则运算中,两个整数的运算不会出现自动提升的情况。例如:
double d = 1.2 + 24 / 5; // 5.2
5.2
计算结果为5.2,原因是编译器计算24 / 5这个子表达式时,按两个整数进行运算,结果仍为整数4
3.溢出
整数运算在除数为0时会报错,而浮点数运算在除数为0时,不会报错,但会返回几个特殊值:
NaN表示Not a NumberInfinity表示无穷大-Infinity表示负无穷大
例如:
double d1 = 0.0 / 0; // NaN
double d2 = 1.0 / 0; // Infinity
double d3 = -1.0 / 0; // -Infinity
这三种特殊值在实际运算中很少碰到,我们只需要了解即可。
4.强制转型
可以将浮点数强制转型为整数。在转型时,浮点数的小数部分会被丢掉。如果转型后超过了整型能表示的最大范围,将返回整型的最大值。例如:
int n1 = (int) 12.3; // 12
int n2 = (int) 12.7; // 12
int n2 = (int) -12.7; // -12
int n3 = (int) (12.7 + 0.5); // 13
int n4 = (int) 1.2e20; // 2147483647
如果要进行四舍五入,可以对浮点数加上0.5再强制转型:
public class Main {
public static void main(String[] args) {
double d = 2.6;
int n = (int) (d + 0.5);
System.out.println(n);
}
}
结果:
3
八,布尔运算
对于布尔类型boolean,永远只有true和false两个值。
1.布尔运算
布尔运算是一种关系运算,包括以下几类:
- 比较运算符:
>,>=,<,<=,==,!= - 与运算
&& - 或运算
|| - 非运算
!
下面是一些示例:
boolean isGreater = 5 > 3; // true
int age = 12;
boolean isZero = age == 0; // false
boolean isNonZero = !isZero; // true
boolean isAdult = age >= 18; // false
boolean isTeenager = age >6 && age <18; // true
关系运算符的优先级从高到低依次是:
-
! -
>,>=,<,<= -
==,!= -
&& -
||
2.短路运算
布尔运算的一个重要特点是短路运算。如果一个布尔运算的表达式能提前确定结果,则后续的计算不再执行,直接返回结果。
因为false && x的结果总是false,无论x是true还是false,因此,与运算在确定第一个值为false后,不再继续计算,而是直接返回false。
我们考察以下代码:
public class Main {
public static void main(String[] args) {
boolean b = 5 < 3;
boolean result = b && (5 / 0 > 0);
System.out.println(result);
}
}
结果:
false
如果没有短路运算,&&后面的表达式会由于除数为0而报错,但实际上该语句并未报错,原因在于与运算是短路运算符,提前计算出了结果false。
如果变量b的值为true,则表达式变为true && (5 / 0 > 0)。因为无法进行短路运算,该表达式必定会由于除数为0而报错,可以自行测试。
类似的,对于||运算,只要能确定第一个值为true,后续计算也不再进行,而是直接返回true:
boolean result = true || (5 / 0 > 0); // true
3.三元运算符
java还提供一个三元运算符b ? x : y,它根据第一个布尔表达式的结果,分别返回后续两个表达式之一的计算结果。示例
public class Main {
public static void main(String[] args) {
int n = -100;
int x = n >= 0 ? n : -n;
System.out.println(x);
}
}
结果:
100
上述语句的意思是,判断n >= 0是否成立,如果为true,则返回n,否则返回-n。这实际上是一个求绝对值的表达式。
注意到三元运算b ? x : y会首先计算b,如果b为true,则只计算x,否则,只计算y。此外,x和y的类型必须相同,因为返回值不是boolean,而是x和y之一。
九,字符
字符类型char是基本数据类型,它是character的缩写。一个char保存一个Unicode字符:
char c1 = 'A';
char c2 = '中';
因为Java在内存中总是使用Unicode表示字符,所以,一个英文字符和一个中文字符都用一个char类型表示,它们都占用两个字节。要显示一个字符的Unicode编码,只需将char类型直接赋值给int类型即可:
int n1 = 'A'; // 字母“A”的Unicodde编码是65
int n2 = '中'; // 汉字“中”的Unicode编码是20013
还可以直接用转义字符\u+Unicode编码来表示一个字符:
// 注意是十六进制:
char c3 = '\u0041'; // 'A',因为十六进制0041 = 十进制65
char c4 = '\u4e2d'; // '中',因为十六进制4e2d = 十进制20013
十,字符串
1.字符串类型
和char类型不同,字符串类型String是引用类型,我们用双引号"..."表示字符串。一个字符串可以存储0个到任意个字符:
String s = ""; // 空字符串,包含0个字符
String s1 = "A"; // 包含一个字符
String s2 = "ABC"; // 包含3个字符
String s3 = "中文 ABC"; // 包含6个字符,其中有一个空格
因为字符串使用双引号"..."表示开始和结束,那如果字符串本身恰好包含一个"字符怎么表示?例如,"abc"xyz",编译器就无法判断中间的引号究竟是字符串的一部分还是表示字符串结束。这个时候,我们需要借助转义字符\:
String s = "abc\"xyz"; // 包含7个字符: a, b, c, ", x, y, z
因为\是转义字符,所以,两个\\表示一个\字符:
String s = "abc\\xyz"; // 包含7个字符: a, b, c, \, x, y, z
常见的转义字符
包括:
\"表示字符"\'表示字符'\\表示字符\\n表示换行符\r表示回车符\t表示Tab\u####表示一个Unicode编码的字符
例如:
String s = "ABC\n\u4e2d\u6587"; // 包含6个字符: A, B, C, 换行符, 中, 文
2.字符串连接
Java的编译器对字符串做了特殊照顾,可以使用+连接任意字符串和其他数据类型,这样极大地方便了字符串的处理。例如:
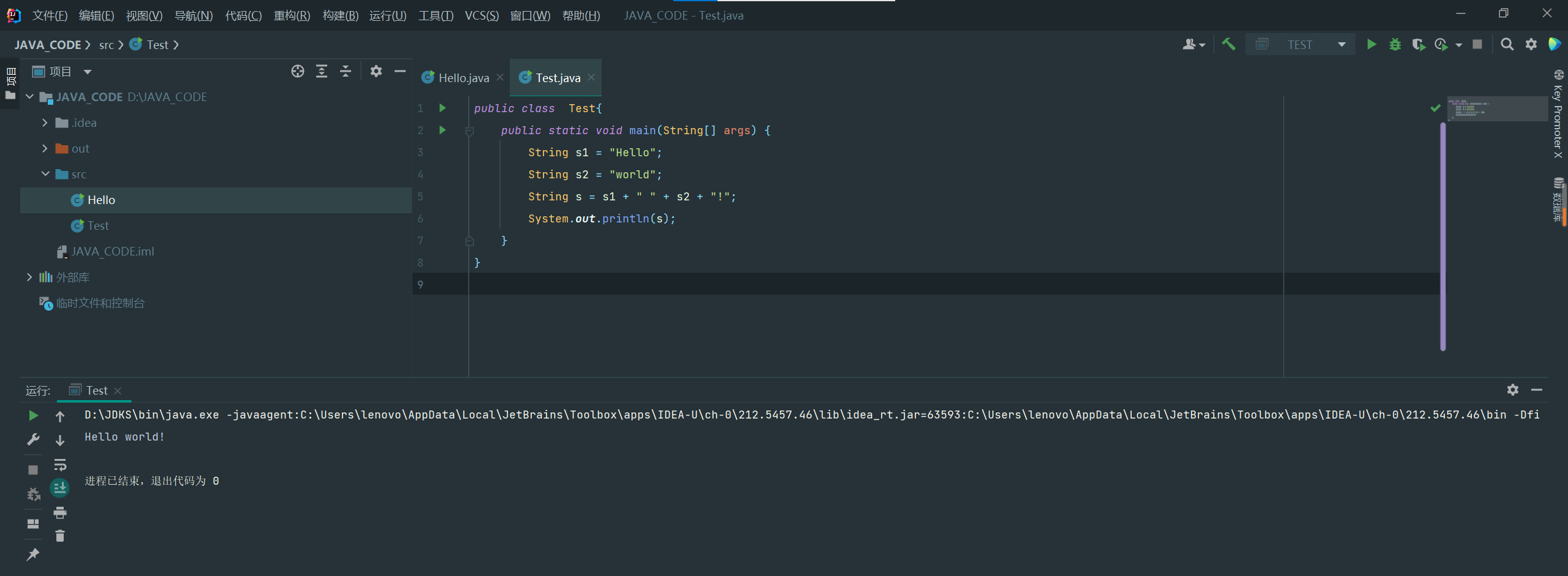
public class Main {
public static void main(String[] args) {
String s1 = "Hello";
String s2 = "world";
String s = s1 + " " + s2 + "!";
System.out.println(s);
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ISJwEa56-1676946013306)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
如果用+连接字符串和其他数据类型,会将其他数据类型先自动转型为字符串,再连接:
public class Main {
public static void main(String[] args) {
int age = 25;
String s = "age is " + age;
System.out.println(s);
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mjlx9Fkh-1676946013307)(https://ycc123666.oss-cn-beijing.aliyuncs.com/img/a6714b072c490d3ff49c3306b7ea34c3.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IAAnXLHw-1676946013307)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
3.多行字符串
如果我们要表示多行字符串,使用+号连接会非常不方便:
String s = "first line \n"
+ "second line \n"
+ "end";
从Java 13开始,字符串可以用"""..."""表示多行字符串(Text Blocks)了
eg:
public class Main {
public static void main(String[] args) {
String s = """
SELECT * FROM
users
WHERE id > 100
ORDER BY name DESC
""";
System.out.println(s);
}
}
上述多行字符串实际上是5行,在最后一个DESC后面还有一个\n。如果我们不想在字符串末尾加一个\n,就需要这么写:
String s = """
SELECT * FROM
users
WHERE id > 100
ORDER BY name DESC""";
还需要注意到,多行字符串前面共同的空格会被去掉,即:
String s = """
...........SELECT * FROM
........... users
...........WHERE id > 100
...........ORDER BY name DESC
...........""";
用.标注的空格都会被去掉。
如果多行字符串的排版不规则,那么,去掉的空格就会变成这样:
String s = """
......... SELECT * FROM
......... users
.........WHERE id > 100
......... ORDER BY name DESC
......... """;
即总是以最短的行首空格为基准。
4.不可变特性
Java的字符串除了是一个引用类型外,还有个重要特点,就是字符串不可变。考察以下代码:
public class Main {
public static void main(String[] args) {
String s = "hello";
System.out.println(s); // 显示 hello
s = "world";
System.out.println(s); // 显示 world
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Kc47RqaO-1676946013308)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
原理
观察执行结果,难道字符串s变了吗?其实变的不是字符串,而是变量s的“指向”。
执行String s = "hello";时,JVM虚拟机先创建字符串"hello",然后,把字符串变量s指向它:
s
│
▼
┌───┬───────────┬───┐
│ │ "hello" │ │
└───┴───────────┴───┘
紧接着,执行s = "world";时,JVM虚拟机先创建字符串"world",然后,把字符串变量s指向它:
s ──────────────┐
│
▼
┌───┬───────────┬───┬───────────┬───┐
│ │ "hello" │ │ "world" │ │
└───┴───────────┴───┴───────────┴───┘
原来的字符串"hello"还在,只是我们无法通过变量s访问它而已。因此,字符串的不可变是指字符串内容不可变。
理解了引用类型的“指向”后,试解释下面的代码输出:
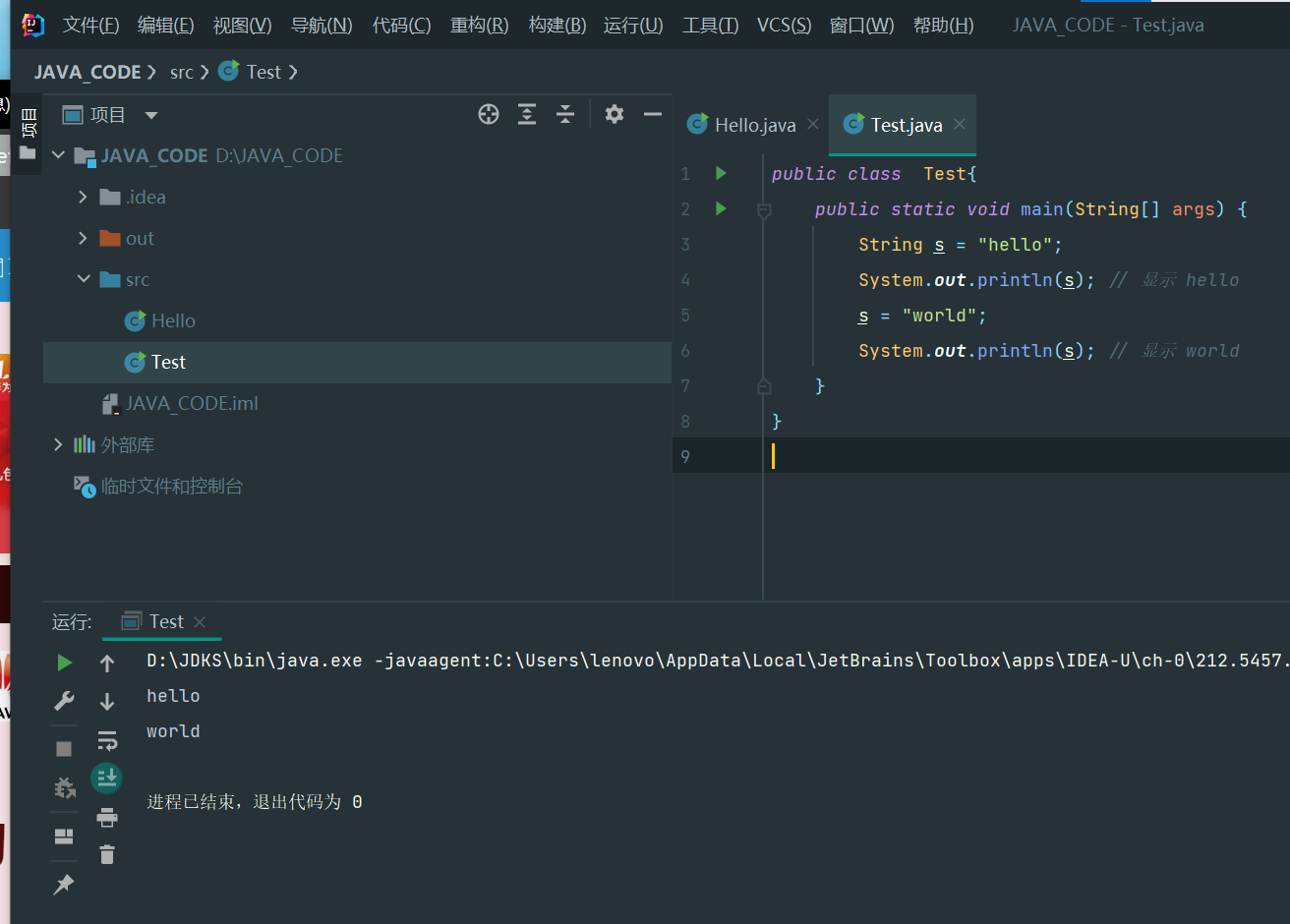
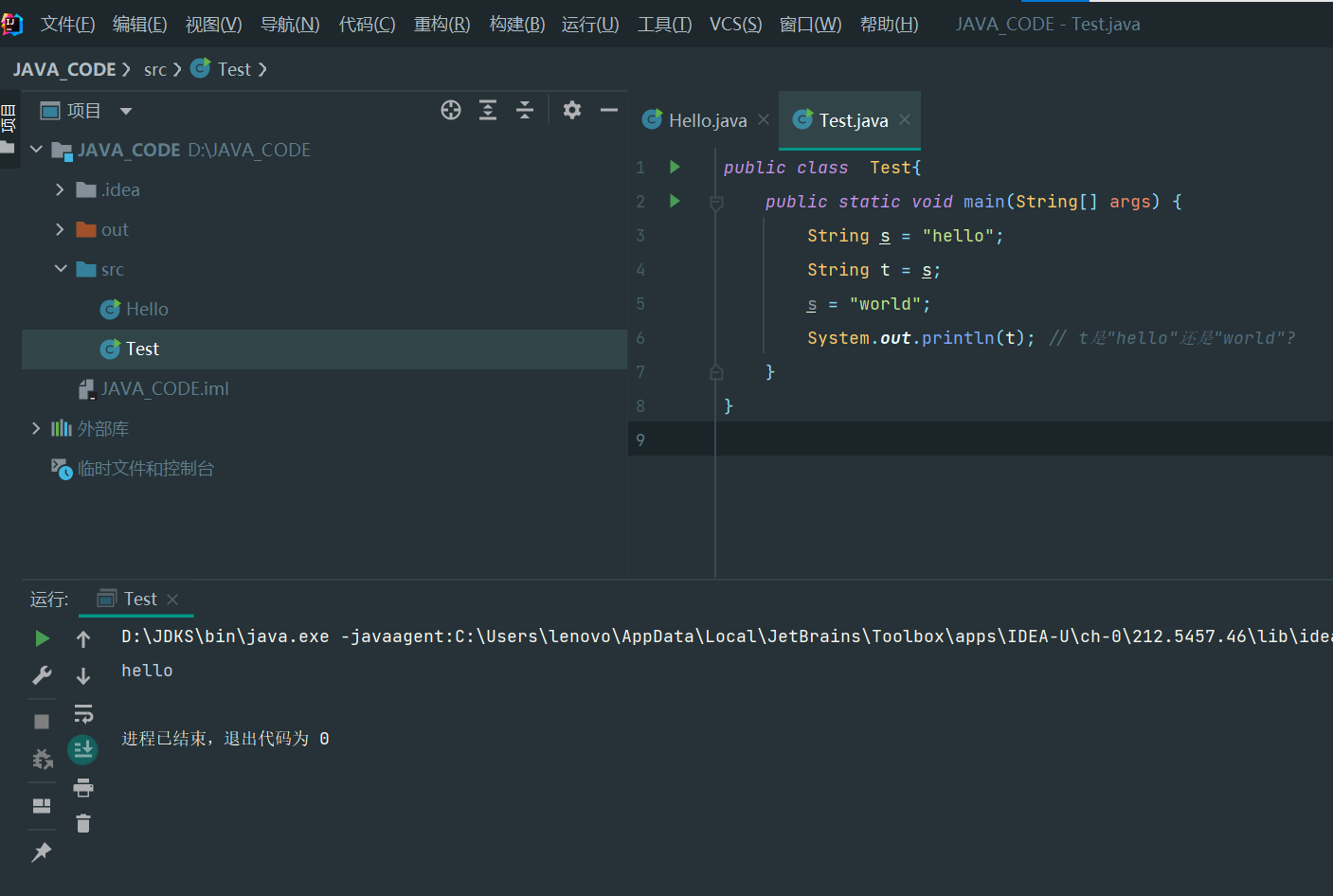
public class Main {
public static void main(String[] args) {
String s = "hello";
String t = s;
s = "world";
System.out.println(t); // t是"hello"还是"world"?
}
}
//hello
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oJYNQhA8-1676946013308)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
空值null
引用类型的变量可以指向一个空值null,它表示不存在,即该变量不指向任何对象。例如:
String s1 = null; // s1是null
String s2; // 没有赋初值值,s2也是null
String s3 = s1; // s3也是null
String s4 = ""; // s4指向空字符串,不是null
注意要区分空值null和空字符串"",空字符串是一个有效的字符串对象,它不等于null。
十一,数组类型
简介
如果我们有一组类型相同的变量,例如,5位同学的成绩,可以这么写:
public class Main {
public static void main(String[] args) {
// 5位同学的成绩:
int n1 = 68;
int n2 = 79;
int n3 = 91;
int n4 = 85;
int n5 = 62;
}
}
但其实没有必要定义5个int变量。可以使用数组来表示“一组”int类型。代码如下:
public class Main {
public static void main(String[] args) {
// 5位同学的成绩:
int[] ns = new int[5];
ns[0] = 68;
ns[1] = 79;
ns[2] = 91;
ns[3] = 85;
ns[4] = 62;
}
}
定义一个数组类型的变量,使用数组类型“类型[]”,例如,int[]。
和单个基本类型变量不同
数组变量初始化必须使用new int[5]表示创建一个可容纳5个int元素的数组。
Java的数组有几个特点:
- 数组所有元素初始化为默认值,整型都是
0,浮点型是0.0,布尔型是false; - 数组一旦创建后,大小就不可改变。
要访问数组中的某一个元素,需要使用索引。数组索引从0开始,例如,5个元素的数组,索引范围是0~4。
可以修改数组中的某一个元素,使用赋值语句,例如,ns[1] = 79;。
可以用数组变量.length获取数组大小:
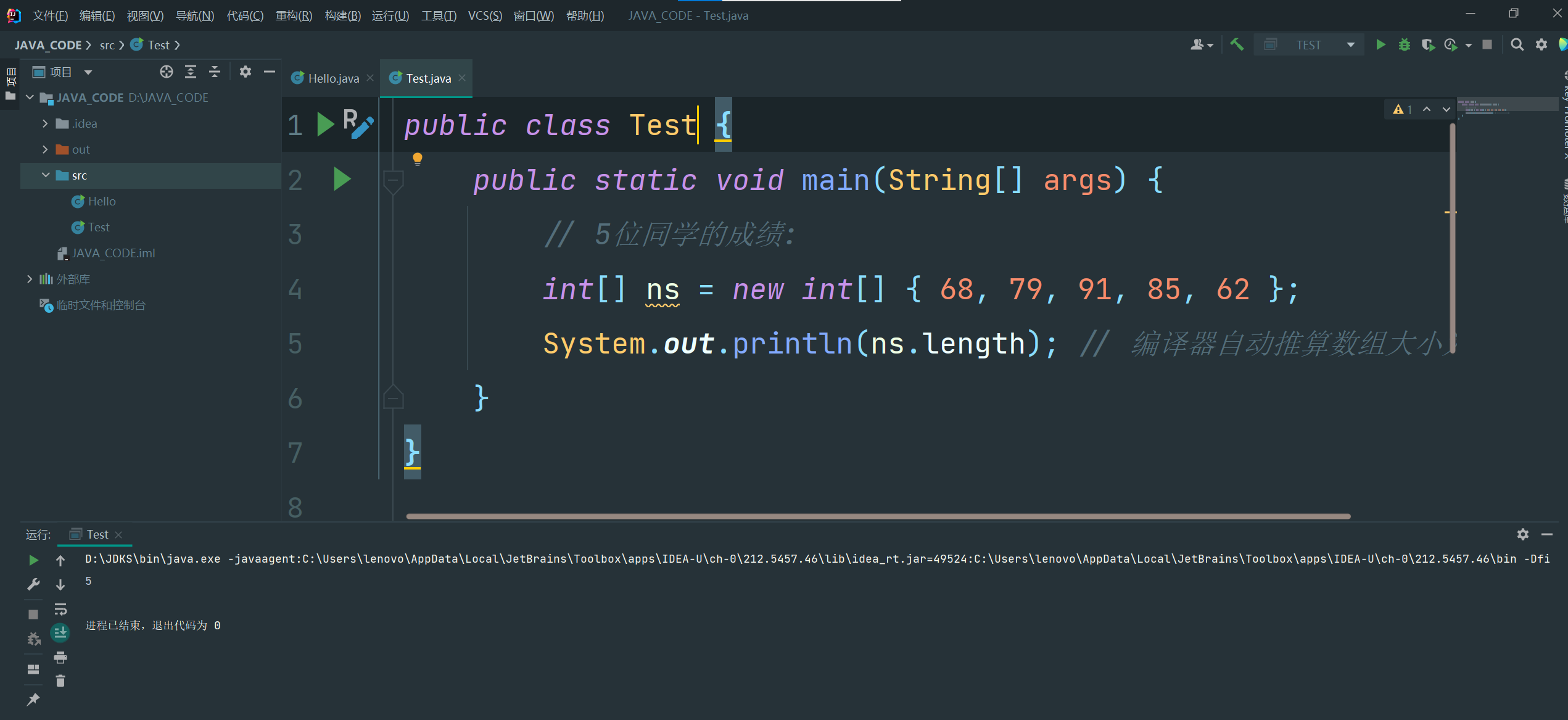
public class Main {
public static void main(String[] args) {
// 5位同学的成绩:
int[] ns = new int[5];
System.out.println(ns.length); // 5
}
}
结果:
5
数组是引用类型,在使用索引访问数组元素时,如果索引超出范围,运行时将报错:
public class Main {
public static void main(String[] args) {
// 5位同学的成绩:
int[] ns = new int[5];
int n = 5;
System.out.println(ns[n]); // 索引n不能超出范围
}
}
也可以在定义数组时直接指定初始化的元素,这样就不必写出数组大小,而是由编译器自动推算数组大小。例如:
public class Main {
public static void main(String[] args) {
// 5位同学的成绩:
int[] ns = new int[] { 68, 79, 91, 85, 62 };
System.out.println(ns.length); // 编译器自动推算数组大小为5
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-egBGwoLk-1676946013309)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
还可以进一步简写为:
int[] ns = { 68, 79, 91, 85, 62 };
注意数组是引用类型,并且数组大小不可变。我们观察下面的代码:
public class Main {
public static void main(String[] args) {
// 5位同学的成绩:
int[] ns;
ns = new int[] { 68, 79, 91, 85, 62 };
System.out.println(ns.length); // 5
ns = new int[] { 1, 2, 3 };
System.out.println(ns.length); // 3
}
}

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cQRHRJ3b-1676946013310)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
原理
数组大小变了吗?看上去好像是变了,但其实根本没变。
对于数组ns来说,执行ns = new int[] { 68, 79, 91, 85, 62 };时,它指向一个5个元素的数组:
ns
│
▼
┌───┬───┬───┬───┬───┬───┬───┐
│ │68 │79 │91 │85 │62 │ │
└───┴───┴───┴───┴───┴───┴───┘
执行ns = new int[] { 1, 2, 3 };时,它指向一个新的3个元素的数组:
ns ──────────────────────┐
│
▼
┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐
│ │68 │79 │91 │85 │62 │ │ 1 │ 2 │ 3 │ │
└───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘
但是,原有的5个元素的数组并没有改变,只是无法通过变量ns引用到它们而已。
字符串数组
如果数组元素不是基本类型,而是一个引用类型,那么,修改数组元素会有哪些不同?
字符串是引用类型,因此我们先定义一个字符串数组:
String[] names = {
"ABC", "XYZ", "zoo"
};
对于String[]类型的数组变量names,它实际上包含3个元素,但每个元素都指向某个字符串对象:
┌─────────────────────────┐
names │ ┌─────────────────────┼───────────┐
│ │ │ │ │
▼ │ │ ▼ ▼
┌───┬───┬─┴─┬─┴─┬───┬───────┬───┬───────┬───┬───────┬───┐
│ │░░░│░░░│░░░│ │ "ABC" │ │ "XYZ" │ │ "zoo" │ │
└───┴─┬─┴───┴───┴───┴───────┴───┴───────┴───┴───────┴───┘
│ ▲
└─────────────────┘
对names[1]进行赋值,例如names[1] = "cat";,效果如下:
┌─────────────────────────────────────────────────┐
names │ ┌─────────────────────────────────┐ │
│ │ │ │ │
▼ │ │ ▼ ▼
┌───┬───┬─┴─┬─┴─┬───┬───────┬───┬───────┬───┬───────┬───┬───────┬───┐
│ │░░░│░░░│░░░│ │ "ABC" │ │ "XYZ" │ │ "zoo" │ │ "cat" │ │
└───┴─┬─┴───┴───┴───┴───────┴───┴───────┴───┴───────┴───┴───────┴───┘
│ ▲
└─────────────────┘
这里注意到原来names[1]指向的字符串"XYZ"并没有改变,仅仅是将names[1]的引用从指向"XYZ"改成了指向"cat",其结果是字符串"XYZ"再也无法通过names[1]访问到了。
对“指向”有了更深入的理解后,试解释如下代码:
public class Main {
public static void main(String[] args) {
String[] names = {"ABC", "XYZ", "zoo"};
String s = names[1];
names[1] = "cat";
System.out.println(s); // s是"XYZ"还是"cat"?
}
}
答:
XYZ

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zxUt7e2K-1676946013310)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
十二,输入和输出
1.输出
在前面的代码中,我们总是使用System.out.println()来向屏幕输出一些内容。
println是print line的缩写,表示输出并换行。
因此,如果输出后不想换行,可以用print():
public class Test {
public static void main(String[] args) {
System.out.print("A,");
System.out.print("B,");
System.out.print("C.");
System.out.println();
System.out.println("END");
}
}

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0krOL3p7-1676946013311)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
2.格式化输出
Java还提供了格式化输出的功能。为什么要格式化输出?因为计算机表示的数据不一定适合人来阅读:
public class Test {
public static void main(String[] args) {
double d = 12900000;
System.out.println(d); // 1.29E7
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i9HmY175-1676946013311)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
如果要把数据显示成我们期望的格式,就需要使用格式化输出的功能。
格式化输出使用System.out.printf(),通过使用占位符%?,
printf()可以把后面的参数格式化成指定格式:
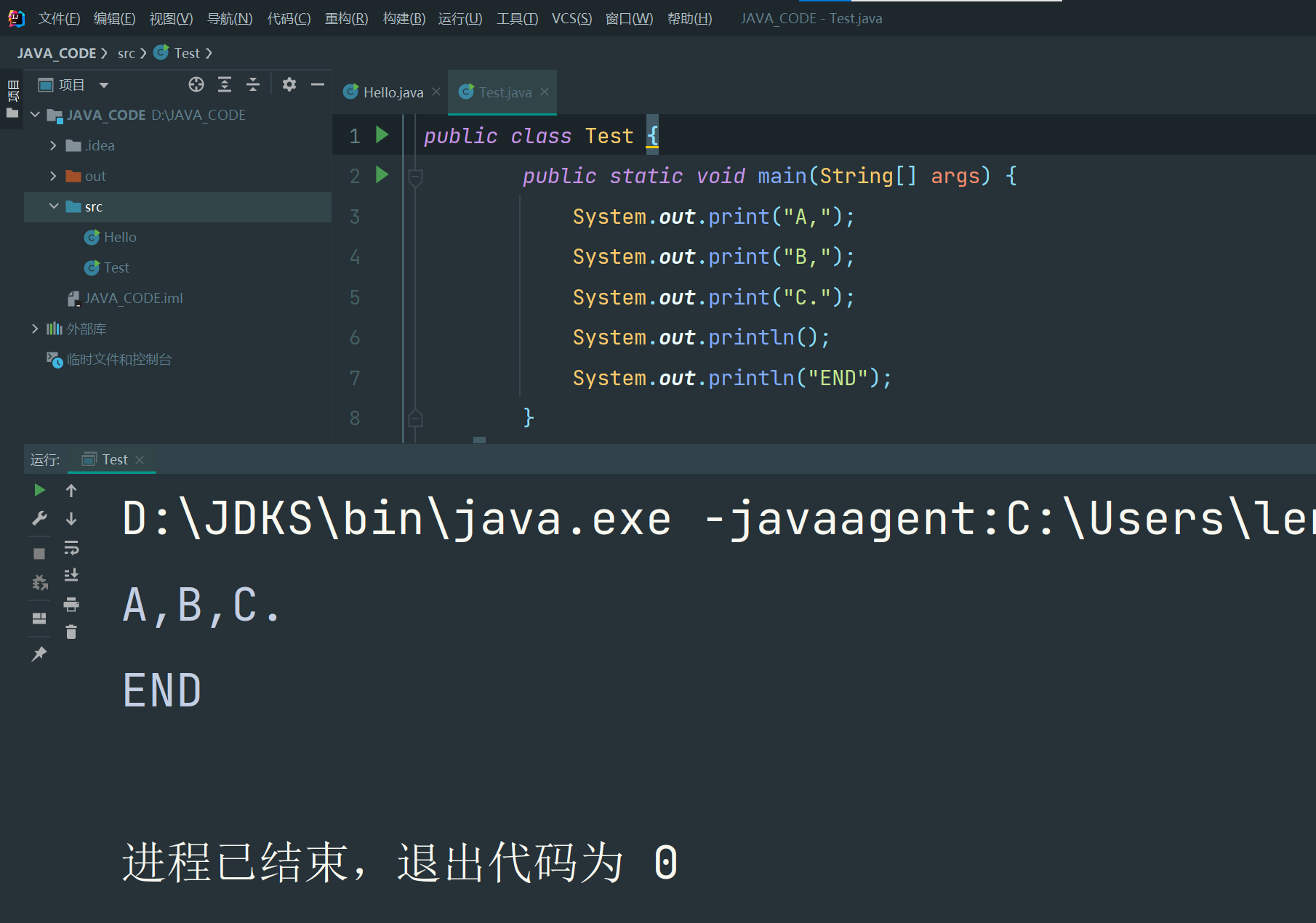
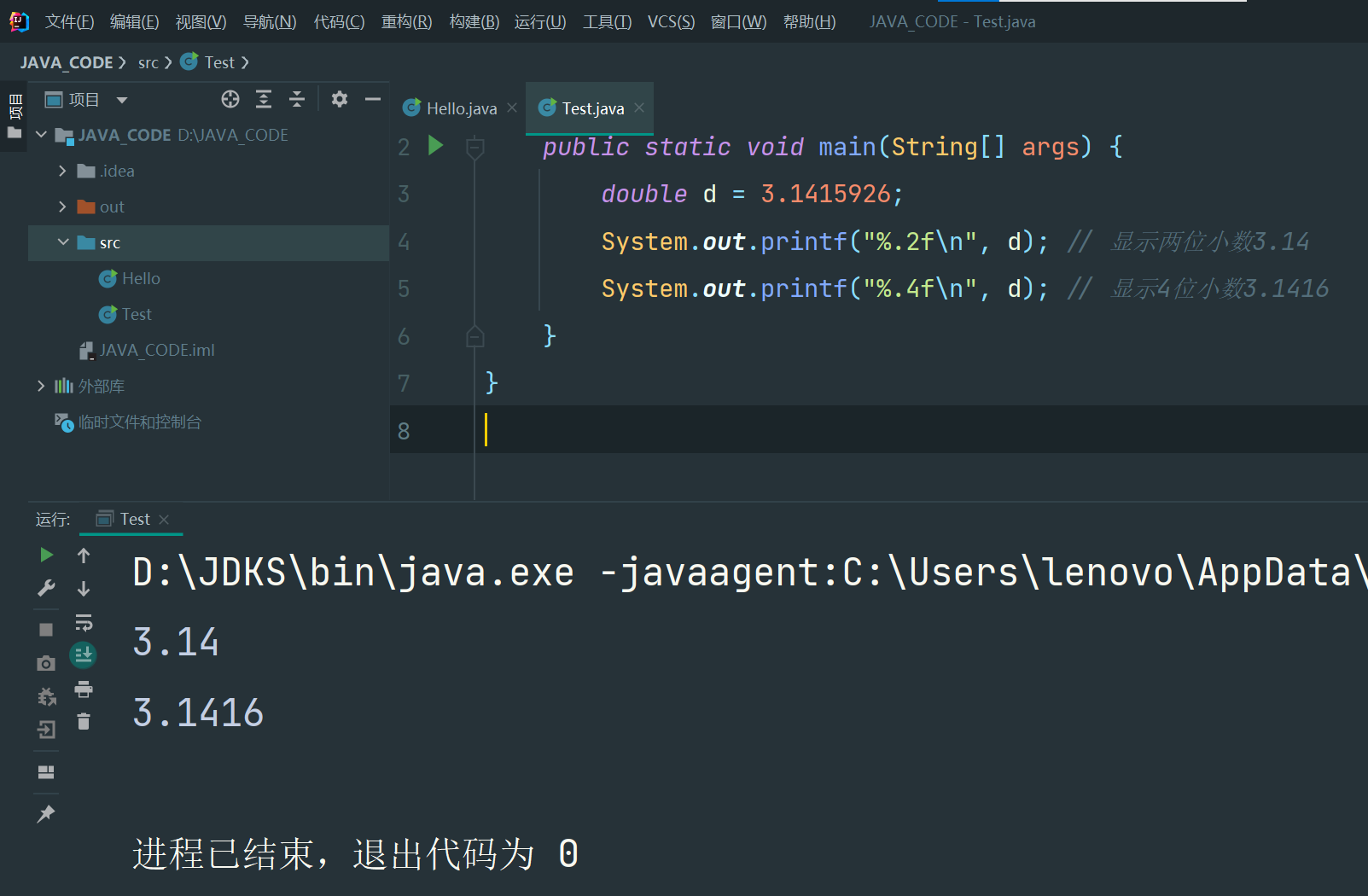
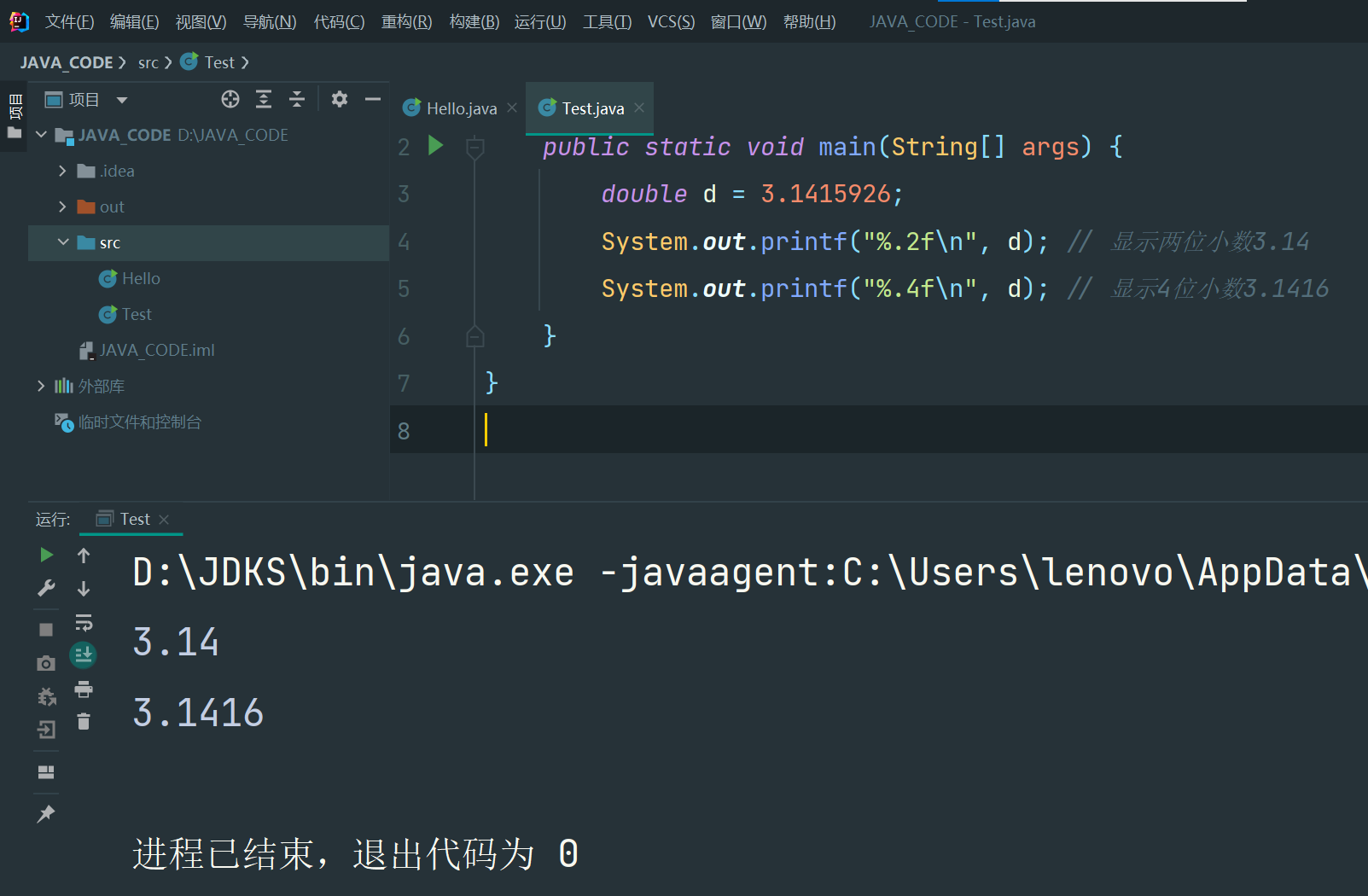
public class Main {
public static void main(String[] args) {
double d = 3.1415926;
System.out.printf("%.2f\n", d); // 显示两位小数3.14
System.out.printf("%.4f\n", d); // 显示4位小数3.1416
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jMVJN0Vv-1676946013312)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
Java的格式化功能提供了多种占位符,可以把各种数据类型“格式化”成指定的字符串:
| 占位符 | 说明 |
|---|---|
| %d | 格式化输出整数 |
| %x | 格式化输出十六进制整数 |
| %f | 格式化输出浮点数 |
| %e | 格式化输出科学计数法表示的浮点数 |
| %s | 格式化字符串 |
注意,由于%表示占位符,因此,连续两个%%表示一个%字符本身。
占位符本身还可以有更详细的格式化参数。下面的例子把一个整数格式化成十六进制,并用0补足8位:
public class Main {
public static void main(String[] args) {
int n = 12345000;
System.out.printf("n=%d, hex=%08x", n, n); // 注意,两个%占位符必须传入两个数
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t1iIWiad-1676946013312)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
3.输入
和输出相比,Java的输入就要复杂得多。
我们先看一个从控制台读取一个字符串和一个整数的例子:
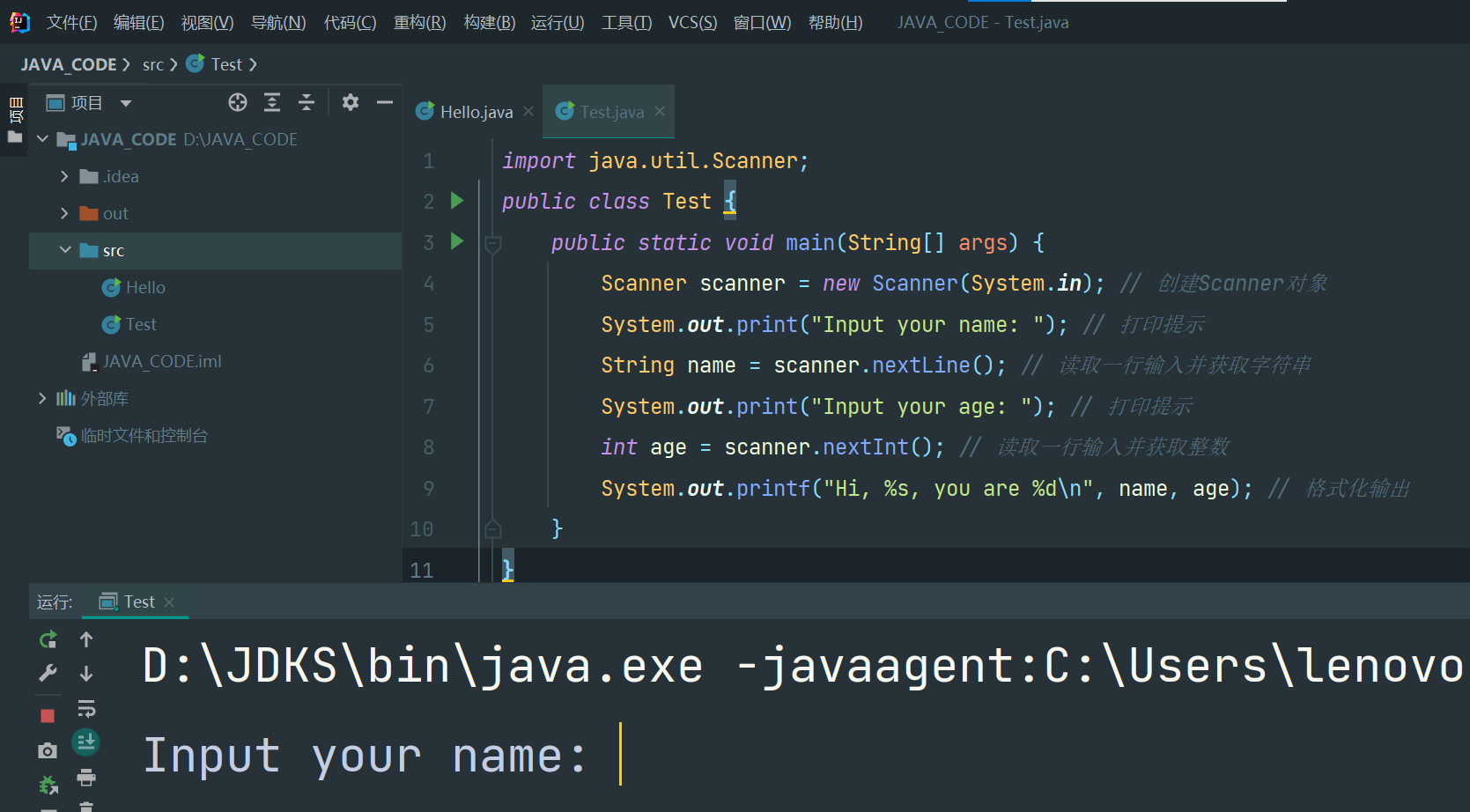
import java.util.Scanner;
public class Test {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in); // 创建Scanner对象
System.out.print("Input your name: "); // 打印提示
String name = scanner.nextLine(); // 读取一行输入并获取字符串
System.out.print("Input your age: "); // 打印提示
int age = scanner.nextInt(); // 读取一行输入并获取整数
System.out.printf("Hi, %s, you are %d\n", name, age); // 格式化输出
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yaixCQ3e-1676946013313)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
猪猪猪:
当通过new Scanner(System.in) ***创建***一个Scanner,控制台 会一直等待输入,,直到敲 回车键结束,把所输入的内容 传给Scanner,作为扫描对象。
如果要 获取输入的内容,则只需要调用Scanner的nextLine()方法即可。
- 首先,我们通过import语句导入java.util.Scanner
- import是导入某个类的语句,必须放到Java源代码的开头,后面我们在Java的package中会详细讲解如何使用import。
- 然后,创建Scanner对象并传入System.in。
- System.out代表标准输出流,
- System.in代表标准输入流。
- 直接使用System.in读取用户输入虽然是可以的,但需要更复杂的代码,而通过Scanner就可以简化后续的代码。
- 有了Scanner对象后,要读取用户输入的字符串,使用scanner.nextLine(),要读取用户输入的整数,
- 使用scanner.nextInt()。Scanner会自动转换数据类型,因此不必手动转换。
要测试输入,我们不能在线运行它,因为输入必须从命令行读取,因此,需要走编译、执行的流程:
$ javac Main.java
这个程序编译时如果有警告,可以暂时忽略它,在后面学习IO的时候再详细解释。编译成功后,执行:
$ java Main
Input your name: Bob
Input your age: 12
Hi, Bob, you are 12
根据提示分别输入一个字符串和整数后,我们得到了格式化的输出。
总结
Java提供的输出包括:
System.out.println()
print()
printf()
其中printf()可以格式化输出;
Java提供Scanner对象来方便输入
读取对应的类型可以使用:
scanner.nextLine() /
nextInt() /
nextDouble() / …
十三,if判断
要根据条件来决定是否执行某一段代码
1.if基本语法
if语句的基本语法是:
if (条件) {
// 条件满足时执行
}
根据if的计算结果(true还是false)JVM决定是否执行if语句块(即花括号{}包含的所有语句)
eg:
public class Test {
public static void main(String[] args) {
int n = 70;
if (n >= 60) {
System.out.println("及格了");
System.out.println("恭喜你");
}
System.out.println("END");
}
}
当条件n >= 60计算结果为true时,if语句块被执行,将打印"及格了"
否则,if语句块将被跳过。
修改n的值可以看到执行效果。
注意到if语句包含的块可以包含多条语句:
public class Test {
public static void main(String[] args) {
int n = 70;
if (n >= 60) {
System.out.println("及格了");
System.out.println("恭喜你");
}
System.out.println("END");
}
}
当if语句块只有一行语句时,可以省略花括号{}:
public class Main {
public static void main(String[] args) {
int n = 70;
if (n >= 60)
System.out.println("及格了");
System.out.println("END");
}
}
2.else
if语句还可以编写一个else { … },
当条件判断为false时
将执行else的语句块
public class Main {
public static void main(String[] args) {
int n = 70;
if (n >= 60) {
System.out.println("及格了");
} else {
System.out.println("挂科了");
}
System.out.println("END");
}
}
修改上述代码n的值
观察if条件为true或false时
程序执行的语句块。
注意,else不是必须的。
还可以用多个if … else if …串联。
例如:
public class Main {
public static void main(String[] args) {
int n = 70;
if (n >= 90) {
System.out.println("优秀");
} else if (n >= 60) {
System.out.println("及格了");
} else {
System.out.println("挂科了");
}
System.out.println("END");
}
}
3.误差
使用if时,还要特别注意边界条件。例如:
public class Main {
public static void main(String[] args) {
int n = 90;
if (n > 90) {
System.out.println("优秀");
} else if (n >= 60) {
System.out.println("及格了");
} else {
System.out.println("挂科了");
}
}
}
假设我们期望90分或更高为“优秀”,上述代码输出的却是“及格”,原因是>和>=效果是不同的。
前面讲过了浮点数在计算机中常常无法精确表示,并且计算可能出现误差,因此,判断浮点数相等用==判断不靠谱:
public class Main {
public static void main(String[] args) {
double x = 1 - 9.0 / 10;
if (x == 0.1) {
System.out.println("x is 0.1");
} else {
System.out.println("x is NOT 0.1");
}
}
}
正确的方法是利用差值小于某个临界值来判断:
public class Main {
public static void main(String[] args) {
double x = 1 - 9.0 / 10;
if (Math.abs(x - 0.1) < 0.00001) {
System.out.println("x is 0.1");
} else {
System.out.println("x is NOT 0.1");
}
}
}
4.判断引用类型相等
1.判断值类型的变量是否相等
在Java中,判断值类型的变量是否相等,可以使用==运算符。
但是,判断引用类型的变量是否相等,表示“引用是否相等”,或者说,是否指向同一个对象。例如,下面的两个String类型,它们的内容是相同的,但是,分别指向不同的对象,用判断,结果为false:
public class Main {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "HELLO".toLowerCase();
System.out.println(s1);
System.out.println(s2);
if (s1 == s2) {
System.out.println("s1 == s2");
} else {
System.out.println("s1 != s2");
}
}
}
2.判断引用类型的变量内容是否相等
要判断引用类型的变量内容是否相等,必须使用equals()方法:
public class Main {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "HELLO".toLowerCase();
System.out.println(s1);
System.out.println(s2);
if (s1.equals(s2)) {
System.out.println("s1 equals s2");
} else {
System.out.println("s1 not equals s2");
}
}
}
3.注意易错
注意:
执行语句s1.equals(s2)时,如果变量s1为null,会报NullPointerException:
public class Main {
public static void main(String[] args) {
String s1 = null;
if (s1.equals("hello")) {
System.out.println("hello");
}
}
}
要避免NullPointerException错误,可以利用短路运算符&&:
public class Main {
public static void main(String[] args) {
String s1 = null;
if (s1 != null && s1.equals("hello")) {
System.out.println("hello");
}
}
}
还可以把一定不是null的对象"hello"放到前面:例如:if ("hello".equals(s)) { ... }。
十四,switch多重选择
简介
除了if语句外,还有一种条件判断,是根据某个表达式的结果,分别去执行不同的分支。
例如,在游戏中,让用户选择选项:
- 单人模式
- 多人模式
- 退出游戏
这时,switch语句就派上用场了。
switch语句根据switch (表达式)计算的结果,跳转到匹配的case结果,然后继续执行后续语句,直到遇到break结束执行。
public class Main {
public static void main(String[] args) {
int option = 1;
switch (option) {
case 1:
System.out.println("Selected 1");
break;
case 2:
System.out.println("Selected 2");
break;
case 3:
System.out.println("Selected 3");
break;
}
}
}
修改option的值分别为1、2、3,观察执行结果。
如果option的值没有匹配到任何case,例如option = 99,那么,switch语句不会执行任何语句。这时,可以给switch语句加一个default,当没有匹配到任何case时,执行default:
public class Main {
public static void main(String[] args) {
int option = 99;
switch (option) {
case 1:
System.out.println("Selected 1");
break;
case 2:
System.out.println("Selected 2");
break;
case 3:
System.out.println("Selected 3");
break;
default:
System.out.println("Not selected");
break;
}
}
}
如果把switch语句翻译成if语句,那么上述的代码相当于:
if (option == 1) {
System.out.println("Selected 1");
} else if (option == 2) {
System.out.println("Selected 2");
} else if (option == 3) {
System.out.println("Selected 3");
} else {
System.out.println("Not selected");
}
对于多个==判断的情况,使用switch结构更加清晰。
同时注意,上述“翻译”只有在switch语句中对每个case正确编写了break语句才能对应得上。
使用switch时,注意case语句并没有花括号{},而且,case语句具有“*穿透性*”,漏写break将导致意想不到的结果:
public class Main {
public static void main(String[] args) {
int option = 2;
switch (option) {
case 1:
System.out.println("Selected 1");
case 2:
System.out.println("Selected 2");
case 3:
System.out.println("Selected 3");
default:
System.out.println("Not selected");
}
}
}
当option = 2时,将依次输出"Selected 2"、"Selected 3"、"Not selected",原因是从匹配到case 2开始,后续语句将全部执行,直到遇到break语句。因此,任何时候都不要忘记写break。
如果有几个case语句执行的是同一组语句块,可以这么写:
public class Main {
public static void main(String[] args) {
int option = 2;
switch (option) {
case 1:
System.out.println("Selected 1");
break;
case 2:
case 3:
System.out.println("Selected 2, 3");
break;
default:
System.out.println("Not selected");
break;
}
}
}
使用switch语句时,只要保证有break,case的顺序不影响程序逻辑:
switch (option) {
case 3:
...
break;
case 2:
...
break;
case 1:
...
break;
}
但是仍然建议按照自然顺序排列,便于阅读。
switch语句还可以匹配字符串。字符串匹配时,是比较“内容相等”。例如:
public class Main {
public static void main(String[] args) {
String fruit = "apple";
switch (fruit) {
case "apple":
System.out.println("Selected apple");
break;
case "pear":
System.out.println("Selected pear");
break;
case "mango":
System.out.println("Selected mango");
break;
default:
System.out.println("No fruit selected");
break;
}
}
}
编译检查
使用IDE时,可以自动检查是否漏写了break语句和default语句,方法是打开IDE的编译检查。
在Eclipse中,选择Preferences - Java - Compiler - Errors/Warnings - Potential programming problems,将以下检查标记为Warning:
- ‘switch’ is missing ‘default’ case
- ‘switch’ case fall-through
在Idea中,选择Preferences - Editor - Inspections - Java - Control flow issues,将以下检查标记为Warning:
- Fallthrough in ‘switch’ statement
- ‘switch’ statement without ‘default’ branch
当switch语句存在问题时,即可在IDE中获得警告提示。
switch表达式
使用switch时,如果遗漏了break,就会造成严重的逻辑错误,而且不易在源代码中发现错误。从Java 12开始,switch语句升级为更简洁的表达式语法,使用类似模式匹配(Pattern Matching)的方法,保证只有一种路径会被执行,并且不需要break语句:
public class Main {
public static void main(String[] args) {
String fruit = "apple";
switch (fruit) {
case "apple" -> System.out.println("Selected apple");
case "pear" -> System.out.println("Selected pear");
case "mango" -> {
System.out.println("Selected mango");
System.out.println("Good choice!");
}
default -> System.out.println("No fruit selected");
}
}
}
注意新语法使用->,如果有多条语句,需要用{}括起来。不要写break语句,因为新语法只会执行匹配的语句,没有穿透效应。
很多时候,我们还可能用switch语句给某个变量赋值。例如
int opt;
switch (fruit) {
case "apple":
opt = 1;
break;
case "pear":
case "mango":
opt = 2;
break;
default:
opt = 0;
break;
}
使用新的switch语法,不但不需要break,还可以直接返回值。把上面的代码改写如下:
int opt;
switch (fruit) {
case "apple":
opt = 1;
break;
case "pear":
case "mango":
opt = 2;
break;
default:
opt = 0;
break;
}
使用新的switch语法,不但不需要break,还可以直接返回值。把上面的代码改写如下:
public class Main {
public static void main(String[] args) {
String fruit = "apple";
int opt = switch (fruit) {
case "apple" -> 1;
case "pear", "mango" -> 2;
default -> 0;
}; // 注意赋值语句要以;结束
System.out.println("opt = " + opt);
}
}
yield
大多数时候,在switch表达式内部,我们会返回简单的值。
但是,如果需要复杂的语句,我们也可以写很多语句,放到{...}里,然后,用yield返回一个值作为switch语句的返回值:
public class Main {
public static void main(String[] args) {
String fruit = "orange";
int opt = switch (fruit) {
case "apple" -> 1;
case "pear", "mango" -> 2;
default -> {
int code = fruit.hashCode();
yield code; // switch语句返回值
}
};
System.out.println("opt = " + opt);
}
}
十五,while循环
环语句就是让计算机根据条件做循环计算,在条件满足时继续循环,条件不满足时退出循环。
例如,计算从1到100的和:
1 + 2 + 3 + 4 + … + 100 = ?
除了用数列公式外,完全可以让计算机做100次循环累加。因为计算机的特点是计算速度非常快,我们让计算机循环一亿次也用不到1秒,所以很多计算的任务,人去算是算不了的,但是计算机算,使用循环这种简单粗暴的方法就可以快速得到结果。
我们先看Java提供的while条件循环。它的基本用法是:
while (条件表达式) {
循环语句
}
// 继续执行后续代码
while循环在每次循环开始前,首先判断条件是否成立。如果计算结果为true,就把循环体内的语句执行一遍,如果计算结果为false,那就直接跳到while循环的末尾,继续往下执行。
我们用while循环来累加1到100,可以这么写:
public class Main {
public static void main(String[] args) {
int sum = 0; // 累加的和,初始化为0
int n = 1;
while (n <= 100) { // 循环条件是n <= 100
sum = sum + n; // 把n累加到sum中
n ++; // n自身加1
}
System.out.println(sum); // 5050
}
}
注意到while循环是先判断循环条件,再循环,因此,有可能一次循环都不做。
对于循环条件判断,以及自增变量的处理,要特别注意边界条件。思考一下下面的代码为何没有获得正确结果:
public class Main {
public static void main(String[] args) {
int sum = 0;
int n = 0;
while (n <= 100) {
n ++;
sum = sum + n;
}
System.out.println(sum);
}
}
如果循环条件永远满足,那这个循环就变成了死循环。死循环将导致100%的CPU占用,用户会感觉电脑运行缓慢,所以要避免编写死循环代码。
如果循环条件的逻辑写得有问题,也会造成意料之外的结果:
public class Main {
public static void main(String[] args) {
int sum = 0;
int n = 1;
while (n > 0) {
sum = sum + n;
n ++;
}
System.out.println(n); // -2147483648
System.out.println(sum);
}
}
表面上看,上面的while循环是一个死循环,但是,Java的int类型有最大值,达到最大值后,再加1会变成负数,结果,意外退出了while循环
十六,do while循环
在Java中,while循环是先判断循环条件,再执行循环。而另一种do while循环则是先执行循环,再判断条件,条件满足时继续循环,条件不满足时退出。它的用法是:
do {
执行循环语句
} while (条件表达式);
可见,do while循环会至少循环一次。
我们把对1到100的求和用do while循环改写一下:
public class Main {
public static void main(String[] args) {
int sum = 0;
int n = 1;
do {
sum = sum + n;
n ++;
} while (n <= 100);
System.out.println(sum);
}
}
使用do while循环时,同样要注意循环条件的判断
十七,for循环
除了while和do while循环,Java使用最广泛的是for循环。
for循环的功能非常强大,它使用计数器实现循环。for循环会先初始化计数器,然后,在每次循环前检测循环条件,在每次循环后更新计数器。计数器变量通常命名为i。
我们把1到100求和用for循环改写一下:
public class Main {
public static void main(String[] args) {
int sum = 0;
for (int i=1; i<=100; i++) {
sum = sum + i;
}
System.out.println(sum);
}
}
在for循环执行前,会先执行初始化语句int i=1,它定义了计数器变量i并赋初始值为1,然后,循环前先检查循环条件i<=100,循环后自动执行i++,因此,和while循环相比,for循环把更新计数器的代码统一放到了一起。在for循环的循环体内部,不需要去更新变量i。
因此,for循环的用法是:
for (初始条件; 循环检测条件; 循环后更新计数器) {
// 执行语句
}
如果我们要对一个整型数组的所有元素求和,可以用for循环实现:
public class Main {
public static void main(String[] args) {
int[] ns = { 1, 4, 9, 16, 25 };
int sum = 0;
for (int i=0; i<ns.length; i++) {
System.out.println("i = " + i + ", ns[i] = " + ns[i]);
sum = sum + ns[i];
}
System.out.println("sum = " + sum);
}
}
上面代码的循环条件是i<ns.length。因为ns数组的长度是5,因此,当循环5次后,i的值被更新为5,就不满足循环条件,因此for循环结束。
注意for循环的初始化计数器总是会被执行,并且for循环也可能循环0次。
使用for循环时,千万不要在循环体内修改计数器!在循环体中修改计数器常常导致莫名其妙的逻辑错误。对于下面的代码:
public class Main {
public static void main(String[] args) {
int[] ns = { 1, 4, 9, 16, 25 };
for (int i=0; i<ns.length; i++) {
System.out.println(ns[i]);
i = i + 1;
}
}
}
虽然不会报错,但是,数组元素只打印了一半,原因是循环内部的i = i + 1导致了计数器变量每次循环实际上加了2(因为for循环还会自动执行i++)。因此,在for循环中,不要修改计数器的值。计数器的初始化、判断条件、每次循环后的更新条件统一放到for()语句中可以一目了然。
如果希望只访问索引为奇数的数组元素,应该把for循环改写为:
int[] ns = { 1, 4, 9, 16, 25 };
for (int i=0; i<ns.length; i=i+2) {
System.out.println(ns[i]);
}
通过更新计数器的语句i=i+2就达到了这个效果,从而避免了在循环体内去修改变量i。
使用for循环时,计数器变量i要尽量定义在for循环中:
int[] ns = { 1, 4, 9, 16, 25 };
for (int i=0; i<ns.length; i++) {
System.out.println(ns[i]);
}
// 无法访问i
int n = i; // compile error!
如果变量i定义在for循环外:
int[] ns = { 1, 4, 9, 16, 25 };
int i;
for (i=0; i<ns.length; i++) {
System.out.println(ns[i]);
}
// 仍然可以使用i
int n = i;
那么,退出for循环后,变量i仍然可以被访问,这就破坏了变量应该把访问范围缩到最小的原则。
灵活使用for循环
for循环还可以缺少初始化语句、循环条件和每次循环更新语句,例如:
// 不设置结束条件:
for (int i=0; ; i++) {
...
}
// 不设置结束条件和更新语句:
for (int i=0; ;) {
...
}
// 什么都不设置:
for (;;) {
...
}
通常不推荐这样写,但是,某些情况下,是可以省略for循环的某些语句的。
for each循环
for循环经常用来遍历数组,因为通过计数器可以根据索引来访问数组的每个元素:
int[] ns = { 1, 4, 9, 16, 25 };
for (int i=0; i<ns.length; i++) {
System.out.println(ns[i]);
}
但是,很多时候,我们实际上真正想要访问的是数组每个元素的值。Java还提供了另一种for each循环,它可以更简单地遍历数组:
public class Main {
public static void main(String[] args) {
int[] ns = { 1, 4, 9, 16, 25 };
for (int n : ns) {
System.out.println(n);
}
}
}
和for循环相比,for each循环的变量n不再是计数器,而是直接对应到数组的每个元素。for each循环的写法也更简洁。但是,for each循环无法指定遍历顺序,也无法获取数组的索引。
除了数组外,for each循环能够遍历所有“可迭代”的数据类型,包括后面会介绍的List、Map等。
十八,break和continue
无论是while循环还是for循环,有两个特别的语句可以使用,就是break语句和continue语句。
1.break
在循环过程中,可以使用break语句跳出当前循环。我们来看一个例子:
public class Main {
public static void main(String[] args) {
int sum = 0;
for (int i=1; ; i++) {
sum = sum + i;
if (i == 100) {
break;
}
}
System.out.println(sum);
}
}
使用for循环计算从1到100时,我们并没有在for()中设置循环退出的检测条件。但是,在循环内部,我们用if判断,如果i==100,就通过break退出循环。
因此,break语句通常都是配合if语句使用。要特别注意,break语句总是跳出自己所在的那一层循环。例如:
public class Main {
public static void main(String[] args) {
for (int i=1; i<=10; i++) {
System.out.println("i = " + i);
for (int j=1; j<=10; j++) {
System.out.println("j = " + j);
if (j >= i) {
break;
}
}
// break跳到这里
System.out.println("breaked");
}
}
}
上面的代码是两个for循环嵌套。因为break语句位于内层的for循环,因此,它会跳出内层for循环,但不会跳出外层for循环。
2.continue
break会跳出当前循环,也就是整个循环都不会执行了。而continue则是提前结束本次循环,直接继续执行下次循环。我们看一个例子:
public class Main {
public static void main(String[] args) {
int sum = 0;
for (int i=1; i<=10; i++) {
System.out.println("begin i = " + i);
if (i % 2 == 0) {
continue; // continue语句会结束本次循环
}
sum = sum + i;
System.out.println("end i = " + i);
}
System.out.println(sum); // 25
}
}
注意观察continue语句的效果。当i为奇数时,完整地执行了整个循环,因此,会打印begin i=1和end i=1。在i为偶数时,continue语句会提前结束本次循环,因此,会打印begin i=2但不会打印end i = 2。
在多层嵌套的循环中,continue语句同样是结束本次自己所在的循环。
小结
break语句可以跳出当前循环;
break语句通常配合if,在满足条件时提前结束整个循环;
break语句总是跳出最近的一层循环;
continue语句可以提前结束本次循环;
continue语句通常配合if,在满足条件时提前结束本次循环。
十九,数组
1.遍历数组
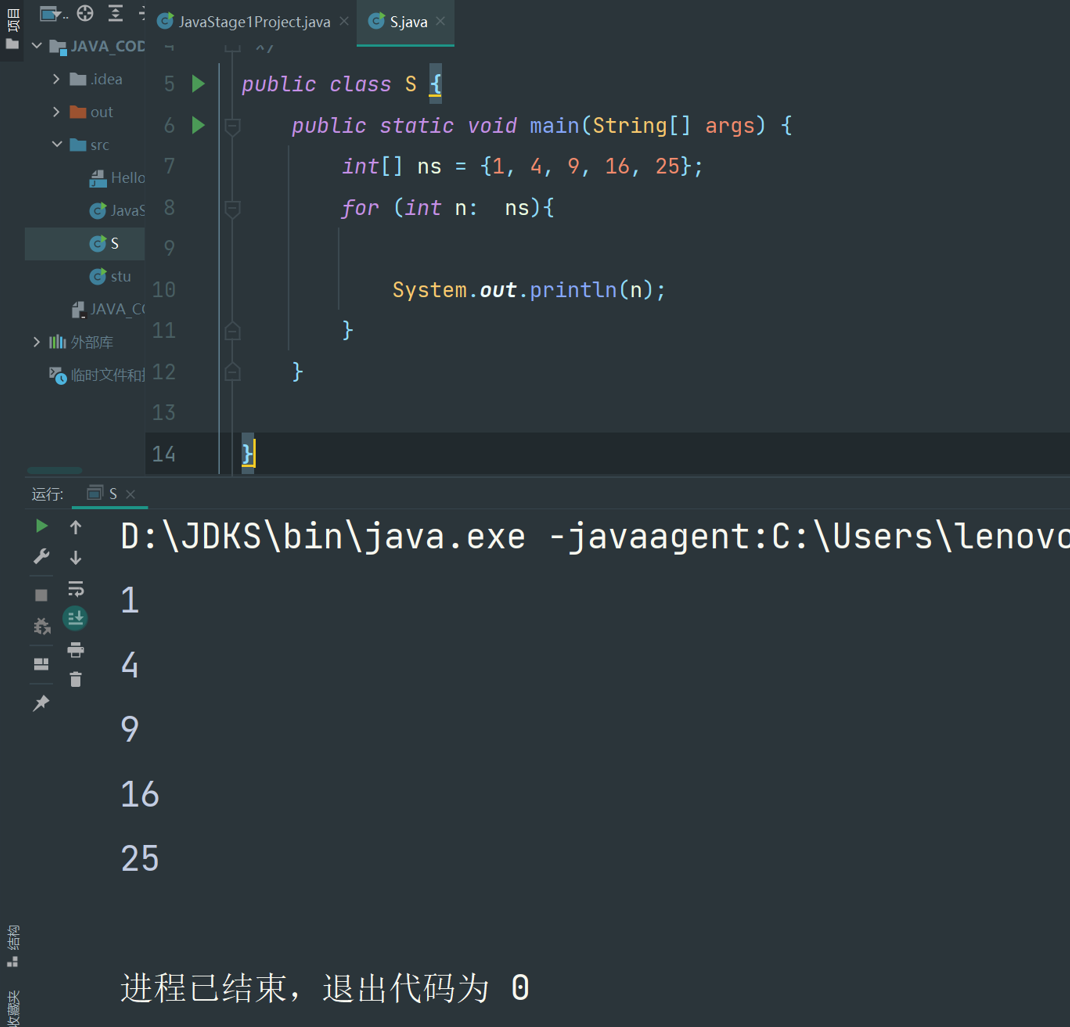
通过 for 循环就可以遍历数组。因为数组的每个元素都可以通过索引来访问,因此,使用标准的 for 循环可以完成一个数组的遍历:
public class S {
public static void main(String[] args) {
int[] ns = { 1, 4, 9, 16, 25 };
for (int i=0; i<ns.length; i++) {
int n = ns[i];
System.out.println(n);
}
}
}
为了实现 for 循环遍历,初始条件为i=0,因为索引总是从0开始,继续循环的条件为 i<ns.length ,因为当 i=ns.length 时,i已经超出了索引范围(索引范围是0 ~ ns.length-1),每次循环后, i++。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8kYkwQLY-1676946013314)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
第二种方式是使用for each循环,直接迭代数组的每个元素:
public class S {
public static void main(String[] args) {
int[] ns = {1, 4, 9, 16, 25};
for (int n: ns){
System.out.println(n);
}
}
}
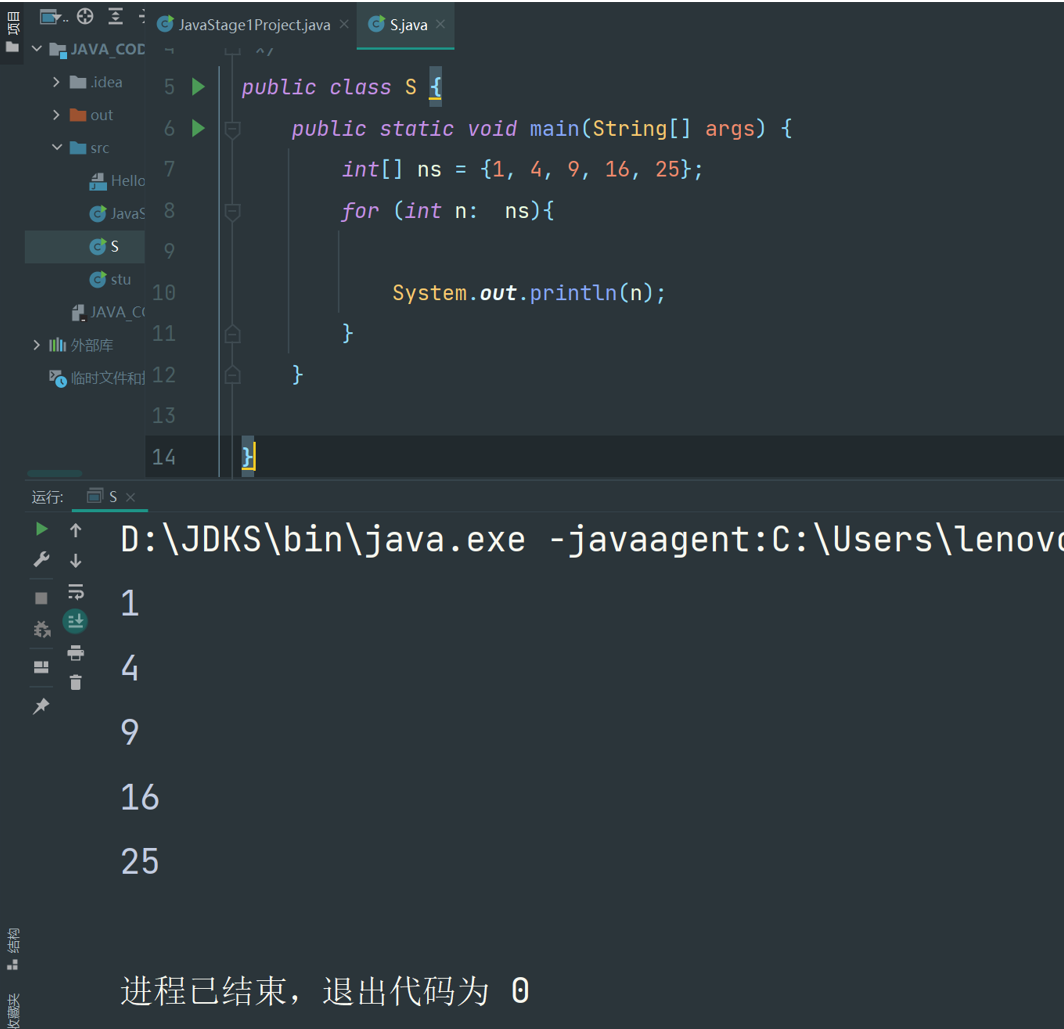
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mt8DHA7g-1676946013314)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
注意:在for (int n : ns)循环中,变量n直接拿到ns数组的元素,而不是索引。
显然for each循环更加简洁。但是,for each循环无法拿到数组的索引,因此,到底用哪一种for循环,取决于我们的需要。
2.打印数组内容
直接打印数组变量,得到的是数组在JVM中的引用地址:
int[] ns = { 1, 1, 2, 3, 5, 8 };
System.out.println(ns);
这并没有什么意义,因为我们希望打印的数组的元素内容。因此,使用for each循环来打印它:
int[] ns = { 1, 1, 2, 3, 5, 8 };
for (int n : ns) {
System.out.print(n + ", ");
}
3.快速打印数组内容Arrays.toString()
使用for each循环打印也很麻烦。幸好Java标准库提供了Arrays.toString(),可以快速打印数组内容:
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] ns = { 1, 1, 2, 3, 5, 8 };
System.out.println(Arrays.toString(ns));
}
}
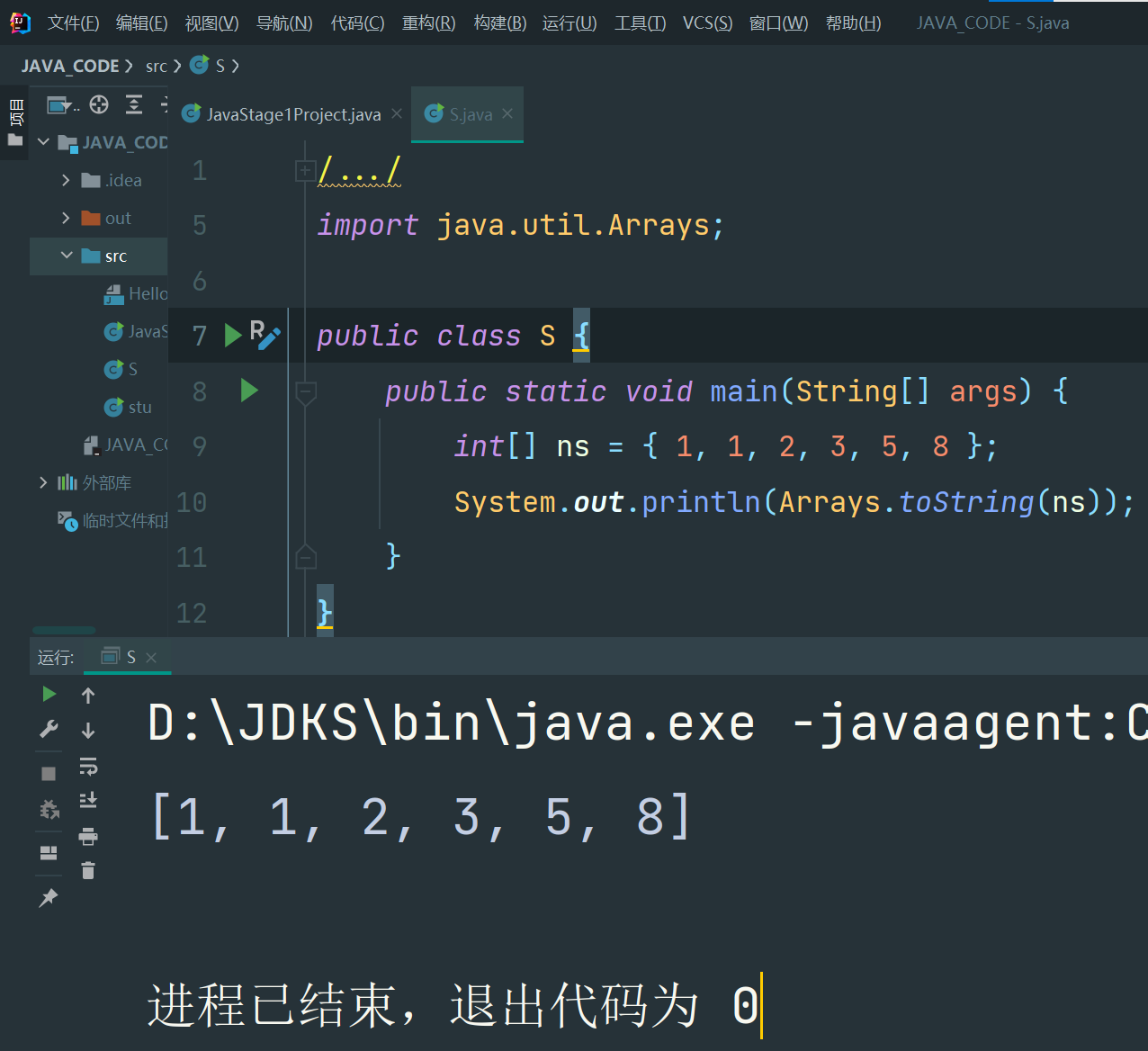
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iwtXbKA7-1676946013315)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
4.数组排序
对数组进行排序是程序中非常基本的需求。常用的排序算法有冒泡排序、插入排序和快速排序等。
我们来看一下如何使用冒泡排序算法对一个整型数组从小到大进行排序:
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] ns = { 28, 12, 89, 73, 65, 18, 96, 50, 8, 36 };
// 排序前:
System.out.println(Arrays.toString(ns));
for (int i = 0; i < ns.length - 1; i++) {
for (int j = 0; j < ns.length - i - 1; j++) {
if (ns[j] > ns[j+1]) {
// 交换ns[j]和ns[j+1]:
int tmp = ns[j];
ns[j] = ns[j+1];
ns[j+1] = tmp;
}
}
}
// 排序后:
System.out.println(Arrays.toString(ns));
}
}
冒泡排序的特点是,每一轮循环后,最大的一个数被交换到末尾,因此,下一轮循环就可以“刨除”最后的数,每一轮循环都比上一轮循环的结束位置靠前一位。
另外,注意到交换两个变量的值必须借助一个临时变量。像这么写是错误的:
int x = 1;
int y = 2;
x = y; // x现在是2
y = x; // y现在还是2
正确的写法是:
int x = 1;
int y = 2;
int t = x; // 把x的值保存在临时变量t中, t现在是1
x = y; // x现在是2
y = t; // y现在是t的值1
5.排序功能Arrays.sort()
实际上,Java的标准库已经内置了排序功能,我们只需要调用JDK提供的Arrays.sort()就可以排序:
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] ns = { 28, 12, 89, 73, 65, 18, 96, 50, 8, 36 };
Arrays.sort(ns);
System.out.println(Arrays.toString(ns));
}
}
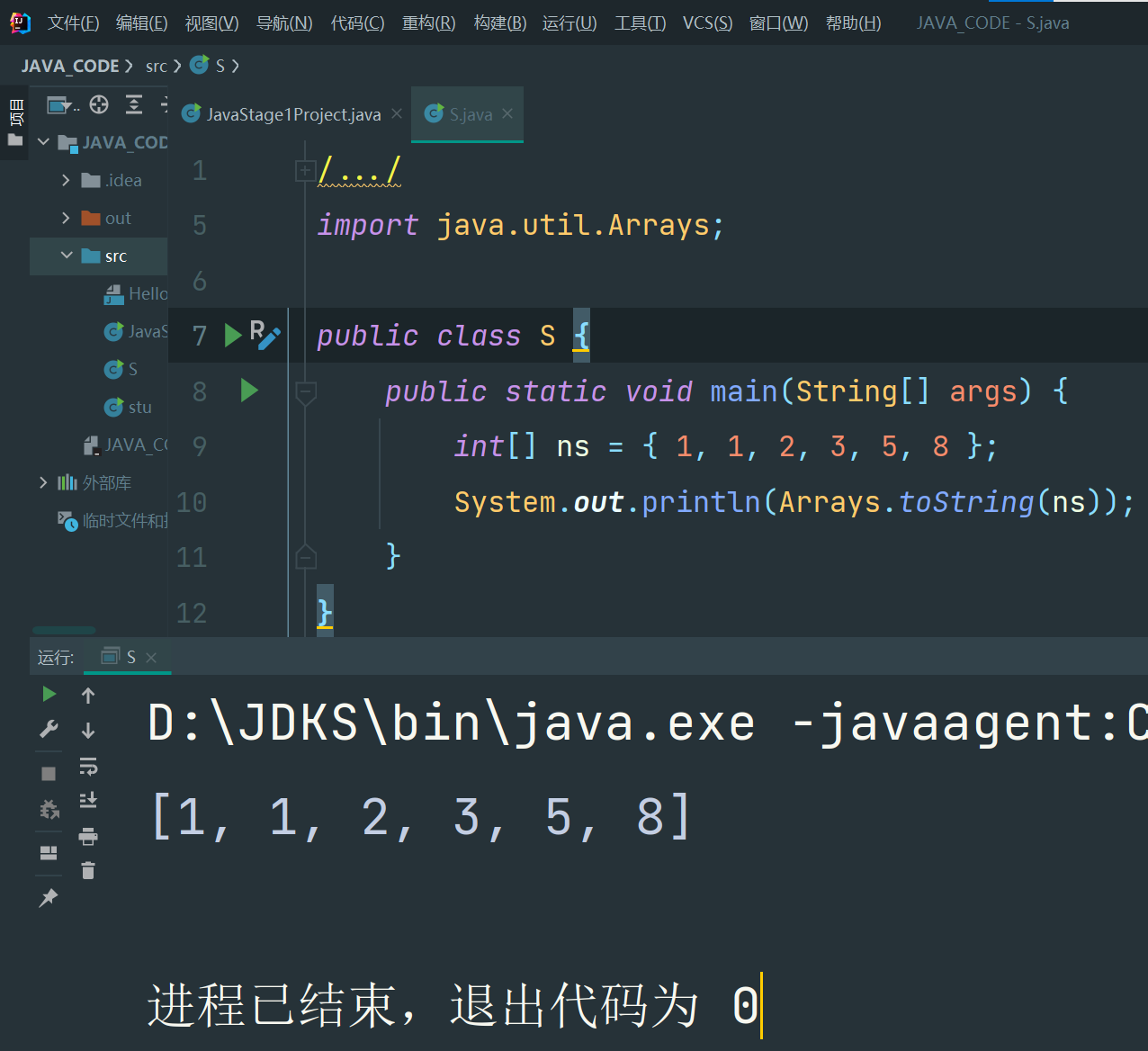
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4nRYYSUK-1676946013315)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
6.原理:
必须注意,对数组排序实际上修改了数组本身。例如,排序前的数组是:
int[] ns = { 9, 3, 6, 5 };
在内存中,这个整型数组表示如下:
┌───┬───┬───┬───┐
ns───>│ 9 │ 3 │ 6 │ 5 │
└───┴───┴───┴───┘
当我们调用Arrays.sort(ns);后,这个整型数组在内存中变为:
┌───┬───┬───┬───┐
ns───>│ 3 │ 5 │ 6 │ 9 │
└───┴───┴───┴───┘
即变量ns指向的数组内容已经被改变了。
如果对一个字符串数组进行排序,例如:
String[] ns = { "banana", "apple", "pear" };
排序前,这个数组在内存中表示如下:
┌──────────────────────────────────┐
┌───┼──────────────────────┐ │
│ │ ▼ ▼
┌───┬─┴─┬─┴─┬───┬────────┬───┬───────┬───┬──────┬───┐
ns ─────>│░░░│░░░│░░░│ │"banana"│ │"apple"│ │"pear"│ │
└─┬─┴───┴───┴───┴────────┴───┴───────┴───┴──────┴───┘
│ ▲
└─────────────────┘
调用Arrays.sort(ns);排序后,这个数组在内存中表示如下:
┌──────────────────────────────────┐
┌───┼──────────┐ │
│ │ ▼ ▼
┌───┬─┴─┬─┴─┬───┬────────┬───┬───────┬───┬──────┬───┐
ns ─────>│░░░│░░░│░░░│ │"banana"│ │"apple"│ │"pear"│ │
└─┬─┴───┴───┴───┴────────┴───┴───────┴───┴──────┴───┘
│ ▲
└──────────────────────────────┘
原来的3个字符串在内存中均没有任何变化,但是ns数组的每个元素指向变化了。
7.小结
常用的排序算法有冒泡排序、插入排序和快速排序等;
冒泡排序使用两层for循环实现排序;
交换两个变量的值需要借助一个临时变量。
可以直接使用Java标准库提供的Arrays.sort()进行排序;
对数组排序会直接修改数组本身。
二十,二维数组
1.介绍:
二维数组就是数组的数组。定义一个二维数组如下:
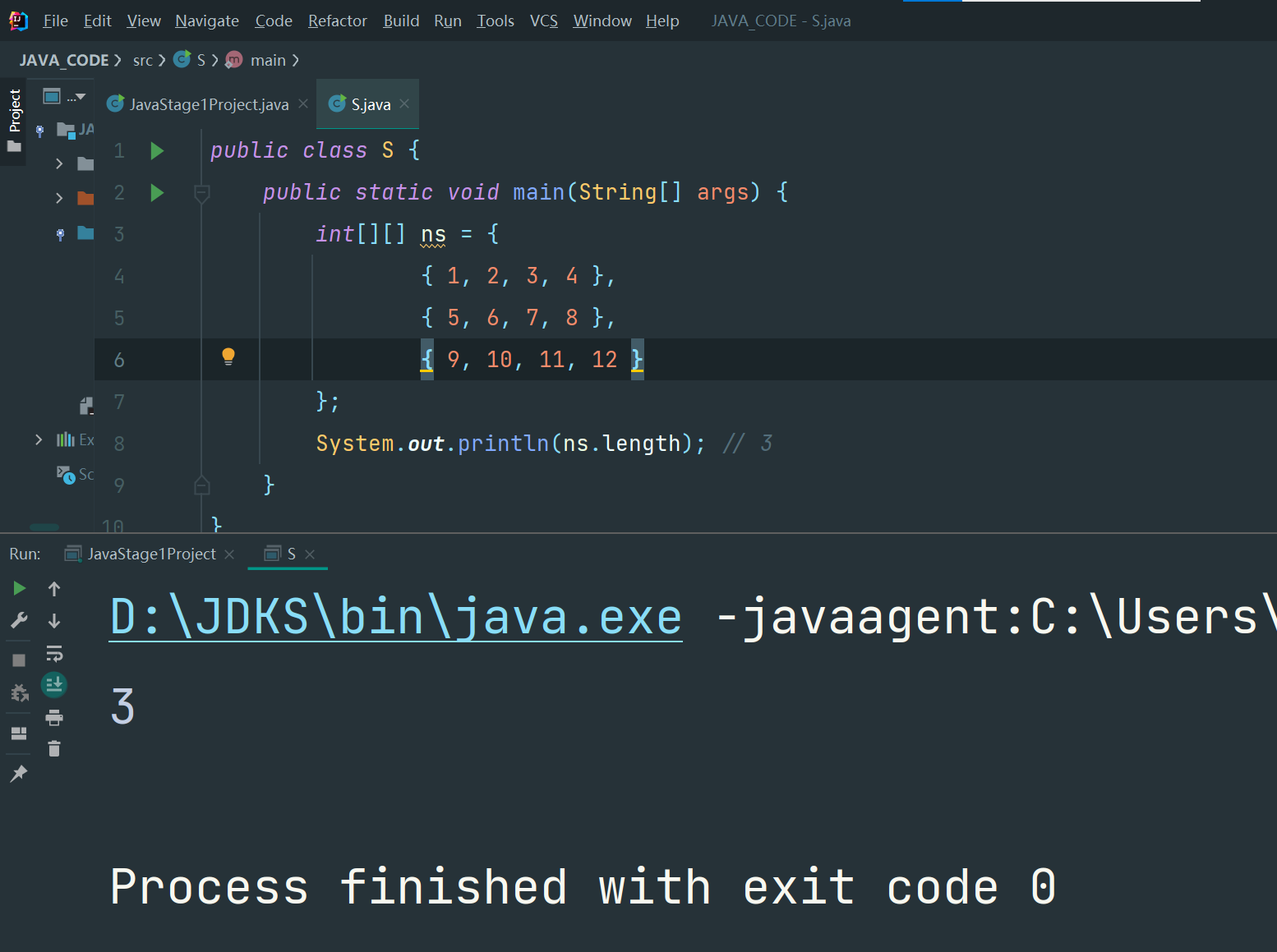
public class Main {
public static void main(String[] args) {
int[][] ns = {
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 }
};
System.out.println(ns.length); // 3
}
}
运算结果
3
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wTiq6a5V-1676946013316)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
因为ns包含3个数组,因此,ns.length为3。实际上ns在内存中的结构如下:
┌───┬───┬───┬───┐
┌───┐ ┌──>│ 1 │ 2 │ 3 │ 4 │
ns ─────>│░░░│──┘ └───┴───┴───┴───┘
├───┤ ┌───┬───┬───┬───┐
│░░░│─────>│ 5 │ 6 │ 7 │ 8 │
├───┤ └───┴───┴───┴───┘
│░░░│──┐ ┌───┬───┬───┬───┐
└───┘ └──>│ 9 │10 │11 │12 │
└───┴───┴───┴───┘
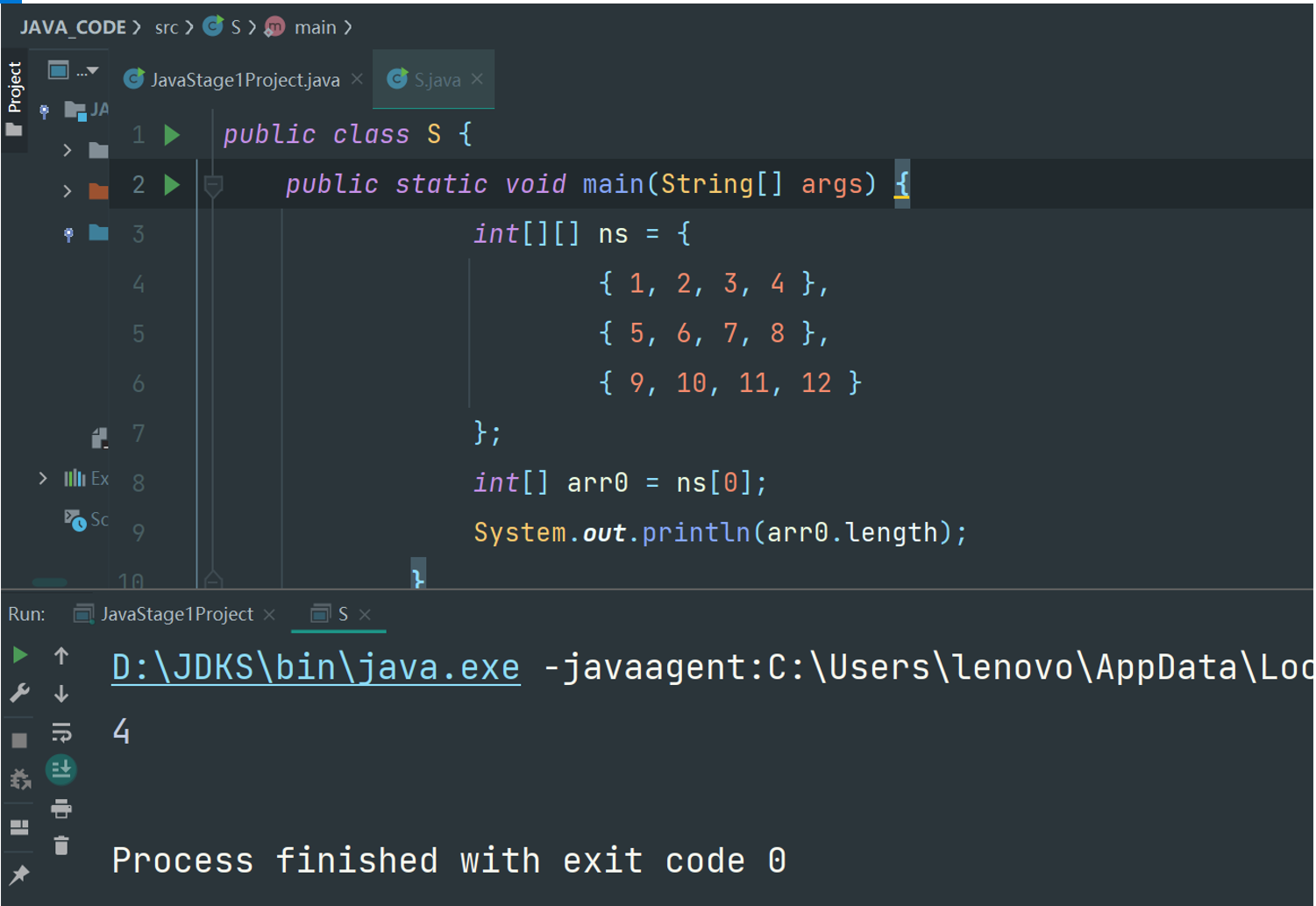
如果我们定义一个普通数组arr0,然后把ns[0]赋值给它:
public class Main {
public static void main(String[] args) {
int[][] ns = {
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 }
};
int[] arr0 = ns[0];
System.out.println(arr0.length);
}
}
运算结果
4
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7kdjh3oM-1676946013316)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
实际上arr0就获取了ns数组的第0个元素。因为ns数组的每个元素也是一个数组,因此,arr0指向的数组就是{ 1, 2, 3, 4 }。在内存中,结构如下:
arr0 ─────┐
▼
┌───┬───┬───┬───┐
┌───┐ ┌──>│ 1 │ 2 │ 3 │ 4 │
ns ─────>│░░░│──┘ └───┴───┴───┴───┘
├───┤ ┌───┬───┬───┬───┐
│░░░│─────>│ 5 │ 6 │ 7 │ 8 │
├───┤ └───┴───┴───┴───┘
│░░░│──┐ ┌───┬───┬───┬───┐
└───┘ └──>│ 9 │10 │11 │12 │
└───┴───┴───┴───┘
访问二维数组的某个元素需要使用array[row][col],例如:
System.out.println(ns[1][2]); // 7

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VRtxDSc8-1676946013317)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
二维数组的每个数组元素的长度并不要求相同,例如,可以这么定义ns数组:
int[][] ns = {
{ 1, 2, 3, 4 },
{ 5, 6 },
{ 7, 8, 9 }
};
这个二维数组在内存中的结构如下:
┌───┬───┬───┬───┐
┌───┐ ┌──>│ 1 │ 2 │ 3 │ 4 │
ns ─────>│░░░│──┘ └───┴───┴───┴───┘
├───┤ ┌───┬───┐
│░░░│─────>│ 5 │ 6 │
├───┤ └───┴───┘
│░░░│──┐ ┌───┬───┬───┐
└───┘ └──>│ 7 │ 8 │ 9 │
└───┴───┴───┘
2.打印二维数组------for循环
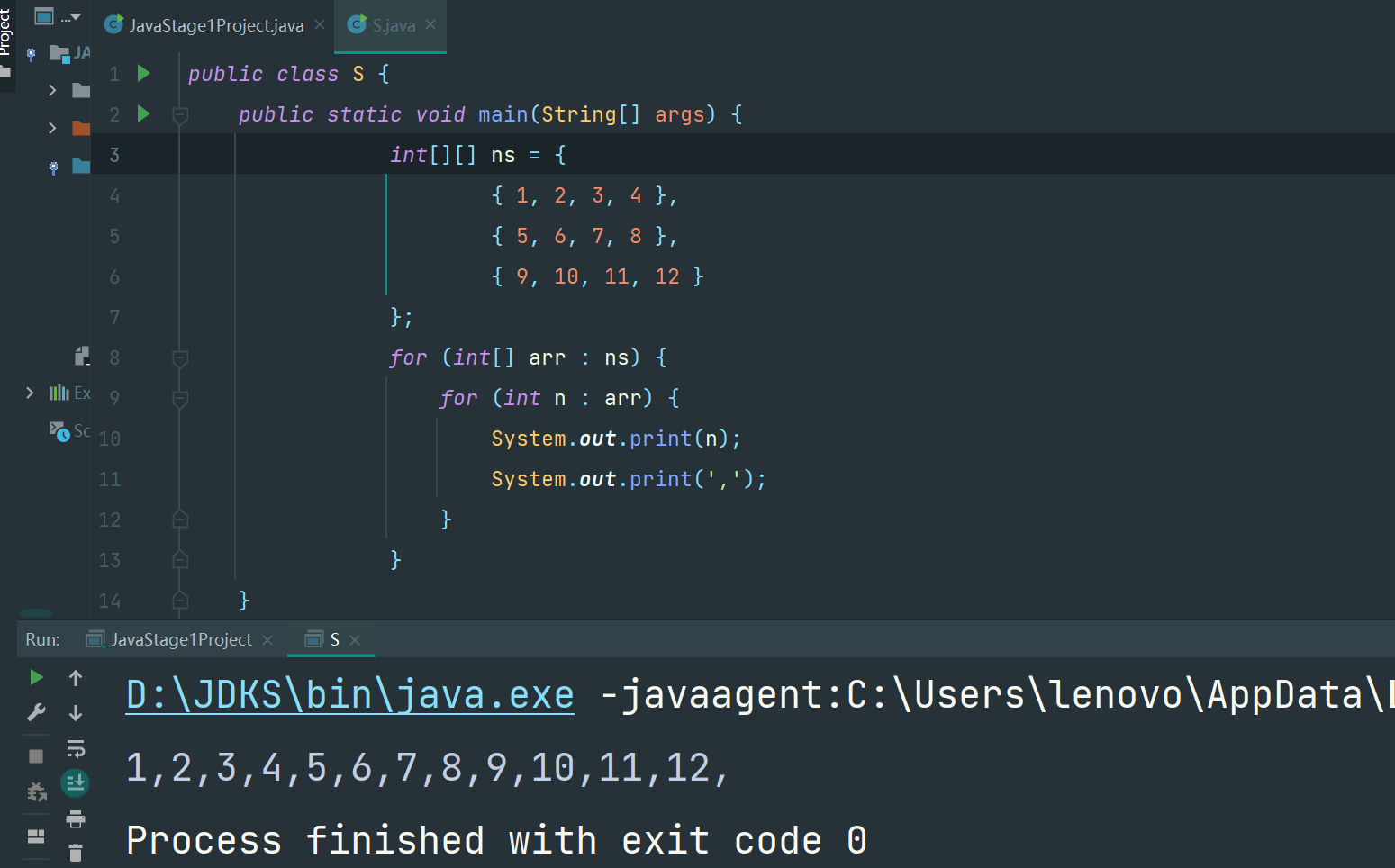
要打印一个二维数组,可以使用两层嵌套的for循环:
public class S {
public static void main(String[] args) {
int[][] ns = {
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 }
};
for (int[] arr : ns) {
for (int n : arr) {
System.out.print(n);
System.out.print(',');
}
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mGJyGP0R-1676946013317)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
3.打印二维数组------Arrays.deepToString()
或者使用Java标准库的Arrays.deepToString()
但是输出的话会和上面方法一的格式有些差别
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[][] ns = {
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 }
};
System.out.println(Arrays.deepToString(ns));
}
}

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r2SlL95n-1676946013318)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
二十一,三维数组
三维数组就是二维数组的数组。可以这么定义一个三维数组:
int[][][] ns = {
{
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
},
{
{10, 11},
{12, 13}
},
{
{14, 15, 16},
{17, 18}
}
};
它在内存中的结构如下:
┌───┬───┬───┐
┌───┐ ┌──>│ 1 │ 2 │ 3 │
┌──>│░░░│──┘ └───┴───┴───┘
│ ├───┤ ┌───┬───┬───┐
│ │░░░│─────>│ 4 │ 5 │ 6 │
│ ├───┤ └───┴───┴───┘
│ │░░░│──┐ ┌───┬───┬───┐
┌───┐ │ └───┘ └──>│ 7 │ 8 │ 9 │
ns ────>│░░░│──┘ └───┴───┴───┘
├───┤ ┌───┐ ┌───┬───┐
│░░░│─────>│░░░│─────>│10 │11 │
├───┤ ├───┤ └───┴───┘
│░░░│──┐ │░░░│──┐ ┌───┬───┐
└───┘ │ └───┘ └──>│12 │13 │
│ └───┴───┘
│ ┌───┐ ┌───┬───┬───┐
└──>│░░░│─────>│14 │15 │16 │
├───┤ └───┴───┴───┘
│░░░│──┐ ┌───┬───┐
└───┘ └──>│17 │18 │
└───┴───┘
如果我们要访问三维数组的某个元素,例如,n[2] [0] [1],只需要顺着定位找到对应的最终元素15即可。**
理论上,我们可以定义任意的N维数组。但在实际应用中,除了二维数组在某些时候还能用得上,更高维度的数组很少使用。
二十三,命令行参数
Java程序的入口是main方法,而main方法可以接受一个命令行参数,它是一个String[]数组。
这个命令行参数由JVM接收用户输入并传给main方法:
public class Main {
public static void main(String[] args) {
for (String arg : args) {
System.out.println(arg);
}
}
}
我们可以利用接收到的命令行参数,根据不同的参数执行不同的代码。例如,实现一个-version参数,打印程序版本号:
public class Main {
public static void main(String[] args) {
for (String arg : args) {
if ("-version".equals(arg)) {
System.out.println("v 1.0");
break;
}
}
}
}
上面这个程序必须在命令行执行,我们先编译它:
$ javac Main.java
然后,执行的时候,给它传递一个-version参数:
$ java Main -version
v 1.0
这样,程序就可以根据传入的命令行参数,作出不同的响应。
面向对象基础
一,面向对象基础
1.简介
面向对象编程,是一种通过对象的方式,把现实世界映射到计算机模型的一种编程方法。
现实世界中,我们定义了“人”这种抽象概念,而具体的人则是“小明”、“小红”、“小军”等一个个具体的人。所以,“人”可以定义为一个类(class),而具体的人则是实例(instance):
| 现实世界 | 计算机模型 | Java代码 |
|---|---|---|
| 人 | 类 / class | class Person { } |
| 小明 | 实例 / ming | Person ming = new Person() |
| 小红 | 实例 / hong | Person hong = new Person() |
| 小军 | 实例 / jun | Person jun = new Person() |
同样的,“书”也是一种抽象的概念,所以它是类,而《Java核心技术》、《Java编程思想》、《Java学习笔记》则是实例:
| 现实世界 | 计算机模型 | Java代码 |
|---|---|---|
| 书 | 类 / class | class Book { } |
| Java核心技术 | 实例 / book1 | Book book1 = new Book() |
| Java编程思想 | 实例 / book2 | Book book2 = new Book() |
| Java学习笔记 | 实例 / book3 | Book book3 = new Book() |
2.class和instance
所以,只要理解了class和instance的概念,基本上就明白了什么是面向对象编程。
class是一种对象模版,它定义了如何创建实例,因此,class本身就是一种数据类型:

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tdmzpsrK-1676946013318)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
而instance是对象实例,instance是根据class创建的实例,可以创建多个instance,每个instance类型相同,但各自属性可能不相同:

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-saocGQTo-1676946013319)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
3.定义class
在Java中,创建一个类,例如,给这个类命名为Person,就是定义一个class:
class Person {
public String name;
public int age;
}
一个class可以包含多个字段(field),字段用来描述一个类的特征。上面的Person类,我们定义了两个字段,一个是String类型的字段,命名为name,一个是int类型的字段,命名为age。因此,通过class,把一组数据汇集到一个对象上,实现了数据封装。
public是用来修饰字段的,它表示这个字段可以被外部访问。
我们再看另一个Book类的定义:
class Book {
public String name;
public String author;
public String isbn;
public double price;
}
4.创建实例
定义了class,只是定义了对象模版,而要根据对象模版创建出真正的对象实例,必须用new操作符。
new操作符可以创建一个实例,然后,我们需要定义一个引用类型的变量来指向这个实例:
Person ming = new Person();
上述代码创建了一个Person类型的实例,并通过变量ming指向它。
注意区分Person ming是定义Person类型的变量ming,而new Person()是创建Person实例。
有了指向这个实例的变量,我们就可以通过这个变量来操作实例。访问实例变量可以用变量.字段,例如:
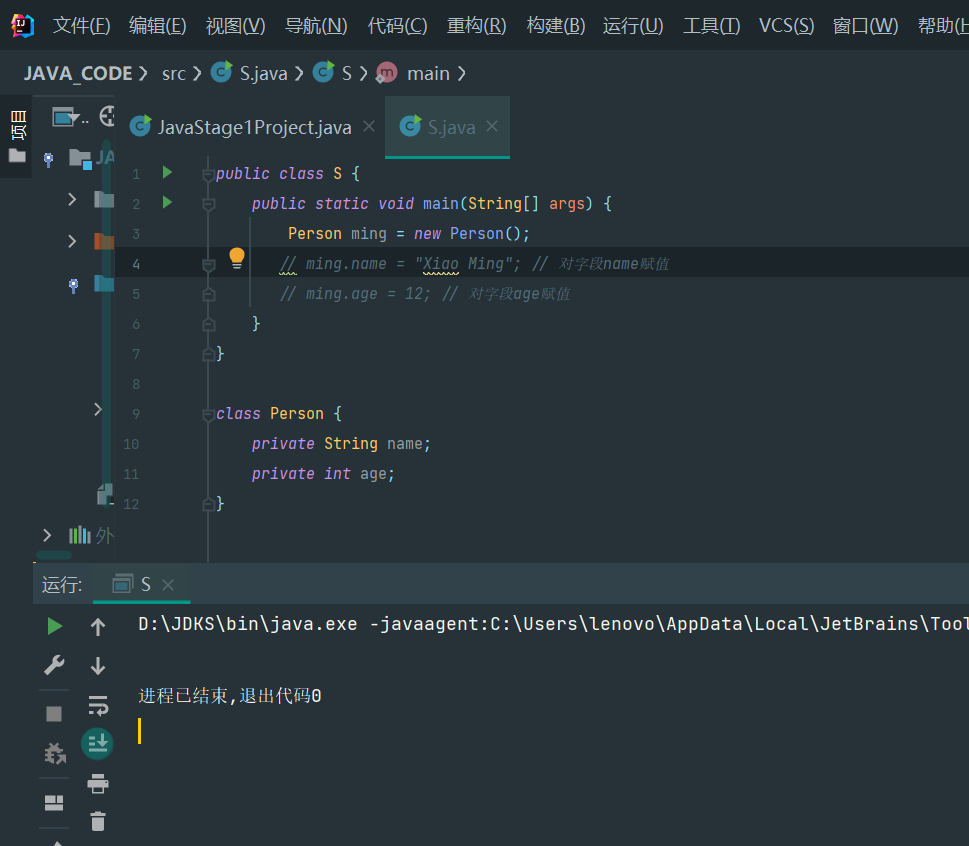
ming.name = "Xiao Ming"; // 对字段name赋值
ming.age = 12; // 对字段age赋值
System.out.println(ming.name); // 访问字段name
Person hong = new Person();
hong.name = "Xiao Hong";
hong.age = 15;
上述两个变量分别指向两个不同的实例,它们在内存中的结构如下:
┌──────────────────┐
ming ──────>│Person instance │
├──────────────────┤
│name = "Xiao Ming"│
│age = 12 │
└──────────────────┘
┌──────────────────┐
hong ──────>│Person instance │
├──────────────────┤
│name = "Xiao Hong"│
│age = 15 │
└──────────────────┘
两个instance拥有class定义的name和age字段,且各自都有一份独立的数据,互不干扰。
二,方法
1.简介
一个class可以包含多个field,例如,我们给Person类就定义了两个field:
class Person {
public String name;
public int age;
}
但是,直接把field用public暴露给外部可能会破坏封装性。比如,代码可以这样写:
Person ming = new Person();
ming.name = "Xiao Ming";
ming.age = -99; // age设置为负数
显然,直接操作field,容易造成逻辑混乱。为了避免外部代码直接去访问field,我们可以用private修饰field,拒绝外部访问:
class Person {
private String name;
private int age;
}
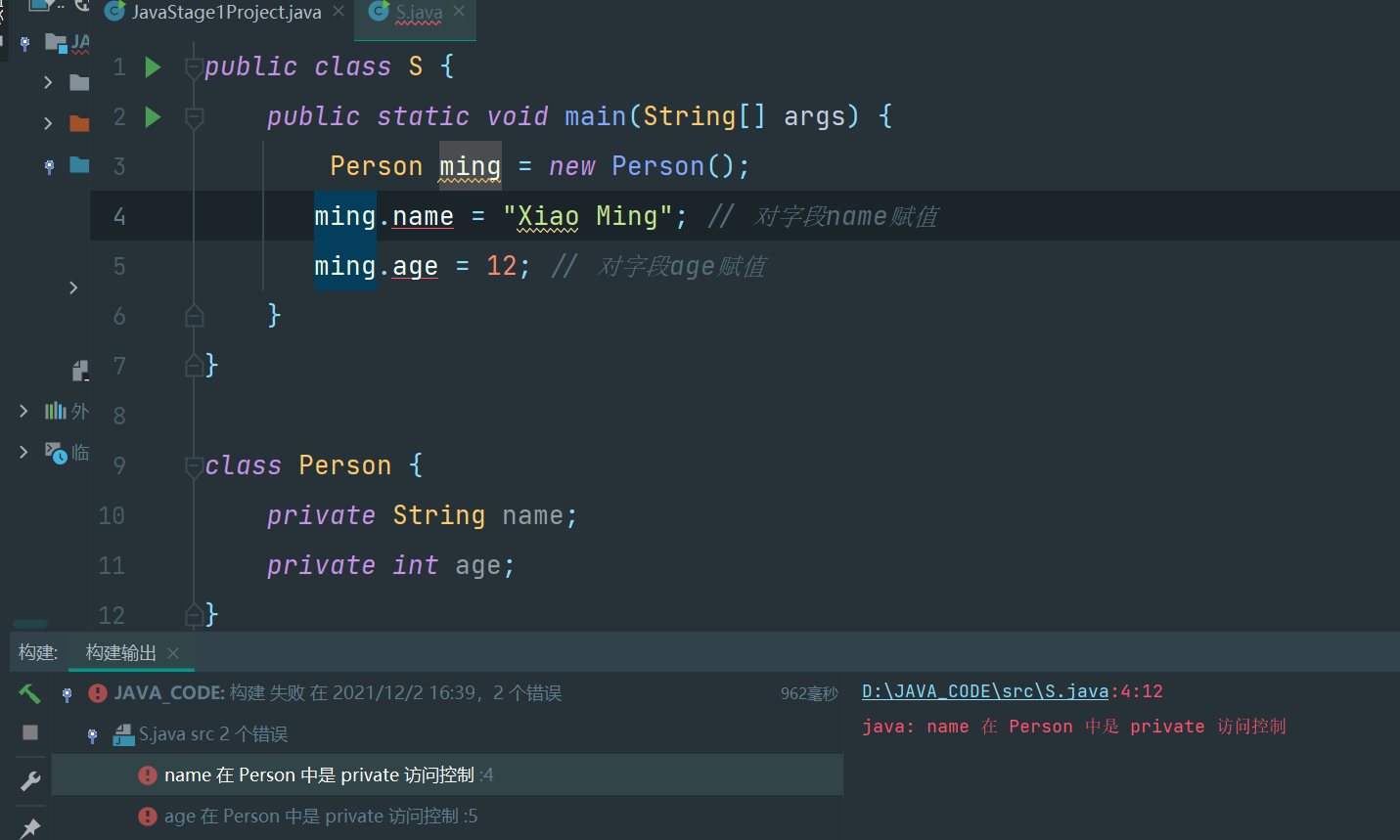
试试private修饰的field有什么效果:
public class Main {
public static void main(String[] args) {
Person ming = new Person();
ming.name = "Xiao Ming"; // 对字段name赋值
ming.age = 12; // 对字段age赋值
}
}
class Person {
private String name;
private int age;
}
是不是编译报错?把访问field的赋值语句去了就可以正常编译了
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G8lRt0CZ-1676946013319)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v7v3mEMB-1676946013320)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
把field从public改成private,外部代码不能访问这些field,
那我们定义这些field有什么用?
怎么才能给它赋值?
怎么才能读取它的值?
所以我们需要使用方法(method)来让外部代码可以间接修改field:
public class Main {
public static void main(String[] args) {
Person ming = new Person();
ming.setName("Xiao Ming"); // 设置name
ming.setAge(12); // 设置age
System.out.println(ming.getName() + ", " + ming.getAge());
}
}
class Person {
private String name;
private int age;
public String getName() {
return this.name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return this.age;
}
public void setAge(int age) {
if (age < 0 || age > 100) {
throw new IllegalArgumentException("invalid age value");
}
this.age = age;
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Oo3pa0eZ-1676946013321)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
虽然外部代码不能直接修改private字段,但是,外部代码可以调用方法setName()和setAge()来间接修改private字段。在方法内部,我们就有机会检查参数对不对。比如,setAge()就会检查传入的参数,参数超出了范围,直接报错。这样,外部代码就没有任何机会把age设置成不合理的值。
对setName()方法同样可以做检查,例如,不允许传入null和空字符串:
public void setName(String name) {
if (name == null || name.isBlank()) {
throw new IllegalArgumentException("invalid name");
}
this.name = name.strip(); // 去掉首尾空格
}
同样,外部代码不能直接读取private字段,
但可以通过getName()和getAge()间接获取private字段的值。
所以,一个类通过定义方法,就可以给外部代码暴露一些操作的接口,同时,内部自己保证逻辑一致性。
调用方法的语法是实例变量.方法名(参数);。一个方法调用就是一个语句,所以不要忘了在末尾加;。例如:ming.setName(“Xiao Ming”);。
2.定义方法
从上面的代码可以看出,定义方法的语法是:
修饰符 方法返回类型 方法名(方法参数列表) {
若干方法语句;
return 方法返回值;
}
方法返回值通过return语句实现,如果没有返回值,返回类型设置为void,可以省略return。
3.private方法
有public方法,自然就有private方法。和private字段一样,private方法不允许外部调用,那我们定义private方法有什么用?
定义private方法的理由是内部方法是可以调用private方法的。例如:
public class Main {
public static void main(String[] args) {
Person ming = new Person();
ming.setBirth(2008);
System.out.println(ming.getAge());
}
}
class Person {
private String name;
private int birth;
public void setBirth(int birth) {
this.birth = birth;
}
public int getAge() {
return calcAge(2019); // 调用private方法
}
// private方法:
private int calcAge(int currentYear) {
return currentYear - this.birth;
}
}
观察上述代码,calcAge()是一个private方法,外部代码无法调用,但是,内部方法getAge()可以调用它。
此外,我们还注意到,这个Person类只定义了birth字段,没有定义age字段,获取age时,通过方法getAge()返回的是一个实时计算的值,并非存储在某个字段的值。这说明方法可以封装一个类的对外接口,调用方不需要知道也不关心Person实例在内部到底有没有age字段。
4.this变量
在方法内部,可以使用一个隐含的变量this,它始终指向当前实例。因此,通过this.field就可以访问当前实例的字段。
如果没有命名冲突,可以省略this。例如:
class Person {
private String name;
public String getName() {
return name; // 相当于this.name
}
}
但是,如果有局部变量和字段重名,那么局部变量优先级更高,就必须加上this:
class Person {
private String name;
public void setName(String name) {
this.name = name; // 前面的this不可少,少了就变成局部变量name了
}
}
5.方法参数
方法可以包含0个或任意个参数。方法参数用于接收传递给方法的变量值。调用方法时,必须严格按照参数的定义一一传递。例如:
class Person {
...
public void setNameAndAge(String name, int age) {
...
}
}
调用这个setNameAndAge()方法时,必须有两个参数,且第一个参数必须为String,第二个参数必须为int:
Person ming = new Person();
ming.setNameAndAge("Xiao Ming"); // 编译错误:参数个数不对
ming.setNameAndAge(12, "Xiao Ming"); // 编译错误:参数类型不对
6.可变参数
可变参数用类型...定义,可变参数相当于数组类型:
class Group {
private String[] names;
public void setNames(String... names) {
this.names = names;
}
}
上面的setNames()就定义了一个可变参数。调用时,可以这么写:
Group g = new Group();
g.setNames("Xiao Ming", "Xiao Hong", "Xiao Jun"); // 传入3个String
g.setNames("Xiao Ming", "Xiao Hong"); // 传入2个String
g.setNames("Xiao Ming"); // 传入1个String
g.setNames(); // 传入0个String
完全可以把可变参数改写为String[]类型:
class Group {
private String[] names;
public void setNames(String[] names) {
this.names = names;
}
}
但是,调用方需要自己先构造String[],比较麻烦。例如:
Group g = new Group();
g.setNames(new String[] {"Xiao Ming", "Xiao Hong", "Xiao Jun"}); // 传入1个String[]
另一个问题是,调用方可以传入null:
Group g = new Group();
g.setNames(null);
而可变参数可以保证无法传入null,因为传入0个参数时,接收到的实际值是一个空数组而不是null。
7.参数绑定
调用方把参数传递给实例方法时,调用时传递的值会按参数位置一一绑定。
那什么是参数绑定?
我们先观察一个基本类型参数的传递:
public class Main {
public static void main(String[] args) {
Person p = new Person();
int n = 15; // n的值为15
p.setAge(n); // 传入n的值
System.out.println(p.getAge()); // 15
n = 20; // n的值改为20
System.out.println(p.getAge()); // 15还是20?
}
}
class Person {
private int age;
public int getAge() {
return this.age;
}
public void setAge(int age) {
this.age = age;
}
}
运行代码,从结果可知,修改外部的局部变量n,不影响实例p的age字段,原因是setAge()方法获得的参数,复制了n的值,因此,p.age和局部变量n互不影响。
结论:基本类型参数的传递,是调用方值的复制。双方各自的后续修改,互不影响。
我们再看一个传递引用参数的例子:
public class Main {
public static void main(String[] args) {
Person p = new Person();
String[] fullname = new String[] { "Homer", "Simpson" };
p.setName(fullname); // 传入fullname数组
System.out.println(p.getName()); // "Homer Simpson"
fullname[0] = "Bart"; // fullname数组的第一个元素修改为"Bart"
System.out.println(p.getName()); // "Homer Simpson"还是"Bart Simpson"?
}
}
class Person {
private String[] name;
public String getName() {
return this.name[0] + " " + this.name[1];
}
public void setName(String[] name) {
this.name = name;
}
}
注意到setName()的参数现在是一个数组。一开始,把fullname数组传进去,然后,修改fullname数组的内容,结果发现,实例p的字段p.name也被修改了!
结论:引用类型参数的传递,调用方的变量,和接收方的参数变量,指向的是同一个对象。双方任意一方对这个对象的修改,都会影响对方(因为指向同一个对象嘛)。
有了上面的结论,我们再看一个例子:
public class Main {
public static void main(String[] args) {
Person p = new Person();
String bob = "Bob";
p.setName(bob); // 传入bob变量
System.out.println(p.getName()); // "Bob"
bob = "Alice"; // bob改名为Alice
System.out.println(p.getName()); // "Bob"还是"Alice"?
}
}
class Person {
private String name;
public String getName() {
return this.name;
}
public void setName(String name) {
this.name = name;
}
}
三,构造方法
1.简介
创建实例的时候,我们经常需要同时初始化这个实例的字段,例如:
Person ming = new Person();
ming.setName("小明");
ming.setAge(12);
初始化对象实例需要3行代码,而且,如果忘了调用setName()或者setAge(),这个实例内部的状态就是不正确的。
能否在创建对象实例时就把内部字段全部初始化为合适的值?
完全可以。
这时,我们就需要构造方法。
建实例的时候,实际上是通过构造方法来初始化实例的。我们先来定义一个构造方法,能在创建Person实例的时候,一次性传入name和age,完成初始化:
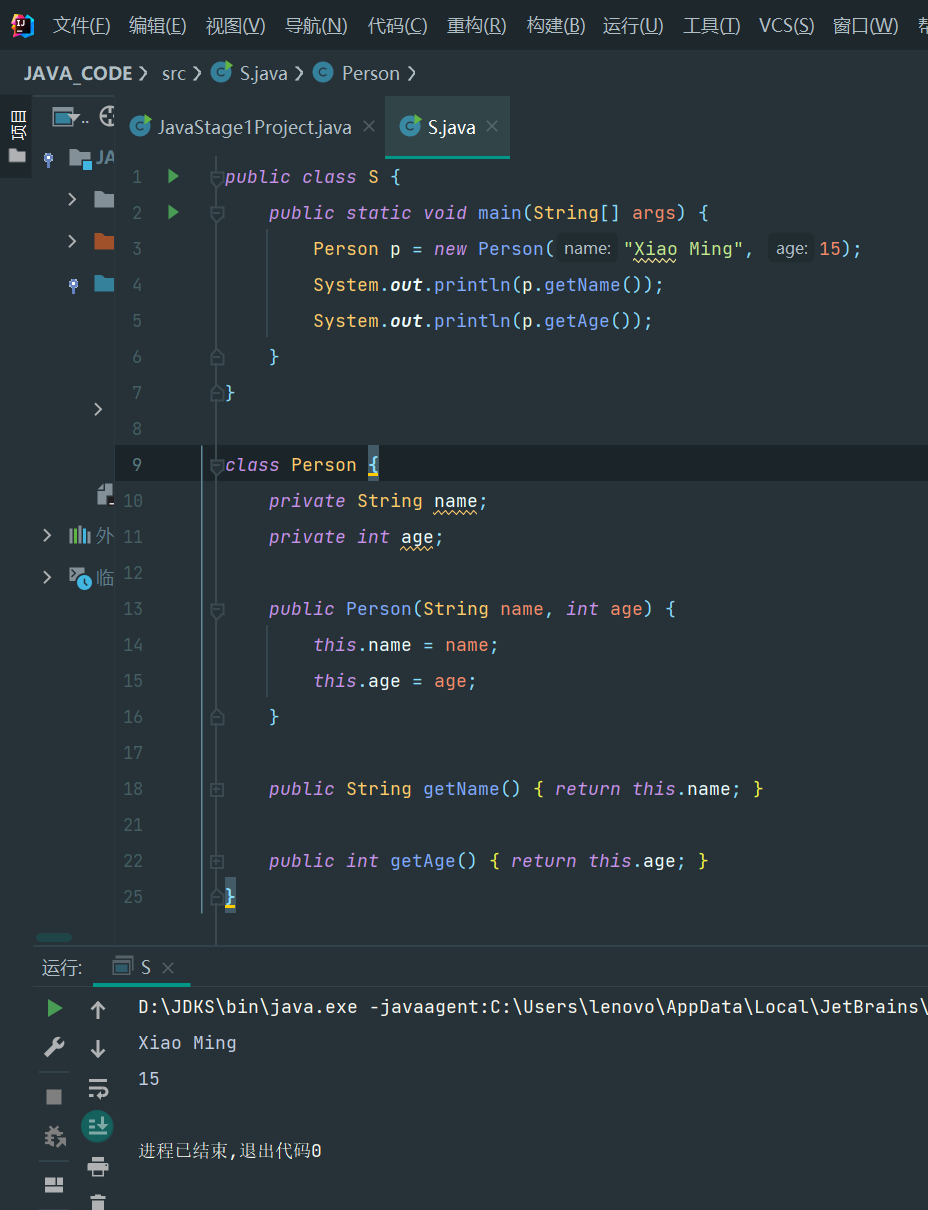
public class Main {
public static void main(String[] args) {
Person p = new Person("Xiao Ming", 15);
System.out.println(p.getName());
System.out.println(p.getAge());
}
}
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return this.name;
}
public int getAge() {
return this.age;
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xkl4Hv9P-1676946013321)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
由于构造方法是如此特殊,所以构造方法的名称就是类名。构造方法的参数没有限制,在方法内部,也可以编写任意语句。但是,和普通方法相比,构造方法没有返回值(也没有void),调用构造方法,必须用new操作符。
2.默认构造方法
是不是任何class都有构造方法?是的。
那前面我们并没有为Person类编写构造方法,为什么可以调用new Person()?
原因是如果一个类没有定义构造方法,编译器会自动为我们生成一个默认构造方法,它没有参数,也没有执行语句,类似这样:
class Person {
public Person() {
}
}
要特别注意的是,如果我们自定义了一个构造方法,那么,编译器就不再自动创建默认构造方法:
public class Main {
public static void main(String[] args) {
Person p = new Person(); // 编译错误:找不到这个构造方法
}
}
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return this.name;
}
public int getAge() {
return this.age;
}
}
如果既要能使用带参数的构造方法,又想保留不带参数的构造方法,那么只能把两个构造方法都定义出来:
public class Main {
public static void main(String[] args) {
Person p1 = new Person("Xiao Ming", 15); // 既可以调用带参数的构造方法
Person p2 = new Person(); // 也可以调用无参数构造方法
}
}
class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return this.name;
}
public int getAge() {
return this.age;
}
}
没有在构造方法中初始化字段时,引用类型的字段默认是null,数值类型的字段用默认值,int类型默认值是0,布尔类型默认值是false:
class Person {
private String name; // 默认初始化为null
private int age; // 默认初始化为0
public Person() {
}
}
也可以对字段直接进行初始化:
class Person {
private String name = "Unamed";
private int age = 10;
}
那么问题来了:既对字段进行初始化,又在构造方法中对字段进行初始化:
class Person {
private String name = "Unamed";
private int age = 10;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
当我们创建对象的时候,new Person("Xiao Ming", 12)得到的对象实例,字段的初始值是啥?
在Java中,创建对象实例的时候,按照如下顺序进行初始化:
- 先初始化字段,例如,
int age = 10;表示字段初始化为10,double salary;表示字段默认初始化为0,String name;表示引用类型字段默认初始化为null; - 执行构造方法的代码进行初始化。
因此,构造方法的代码由于后运行,所以,new Person("Xiao Ming", 12)的字段值最终由构造方法的代码确定。
3.多构造方法
可以定义多个构造方法,在通过new操作符调用的时候,编译器通过构造方法的参数数量、位置和类型自动区分:
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public Person(String name) {
this.name = name;
this.age = 12;
}
public Person() {
}
}
如果调用new Person("Xiao Ming", 20);,会自动匹配到构造方法public Person(String, int)。
如果调用new Person("Xiao Ming");,会自动匹配到构造方法public Person(String)。
如果调用new Person();,会自动匹配到构造方法public Person()。
一个构造方法可以调用其他构造方法,这样做的目的是便于代码复用。调用其他构造方法的语法是this(…):
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public Person(String name) {
this(name, 18); // 调用另一个构造方法Person(String, int)
}
public Person() {
this("Unnamed"); // 调用另一个构造方法Person(String)
}
}
四,方法重载
在一个类中,我们可以定义多个方法。如果有一系列方法,它们的功能都是类似的,只有参数有所不同,那么,可以把这一组方法名做成同名方法。例如,在Hello类中,定义多个hello()方法:
class Hello {
public void hello() {
System.out.println("Hello, world!");
}
public void hello(String name) {
System.out.println("Hello, " + name + "!");
}
public void hello(String name, int age) {
if (age < 18) {
System.out.println("Hi, " + name + "!");
} else {
System.out.println("Hello, " + name + "!");
}
}
}
这种方法名相同,但各自的参数不同,称为方法重载(Overload)。
注意:方法重载的返回值类型通常都是相同的。
方法重载的目的是,功能类似的方法使用同一名字,更容易记住,因此,调用起来更简单。
举个例子,String类提供了多个重载方法indexOf(),可以查找子串:
int indexOf(int ch):根据字符的Unicode码查找;int indexOf(String str):根据字符串查找;int indexOf(int ch, int fromIndex):根据字符查找,但指定起始位置;int indexOf(String str, int fromIndex)根据字符串查找,但指定起始位置。
public class S {
public static void main(String[] args) {
String s = "Test string";
int n1 = s.indexOf('t');
int n2 = s.indexOf("st");
int n3 = s.indexOf("st", 4);
System.out.println(n1);
System.out.println(n2);
System.out.println(n3);
}
}
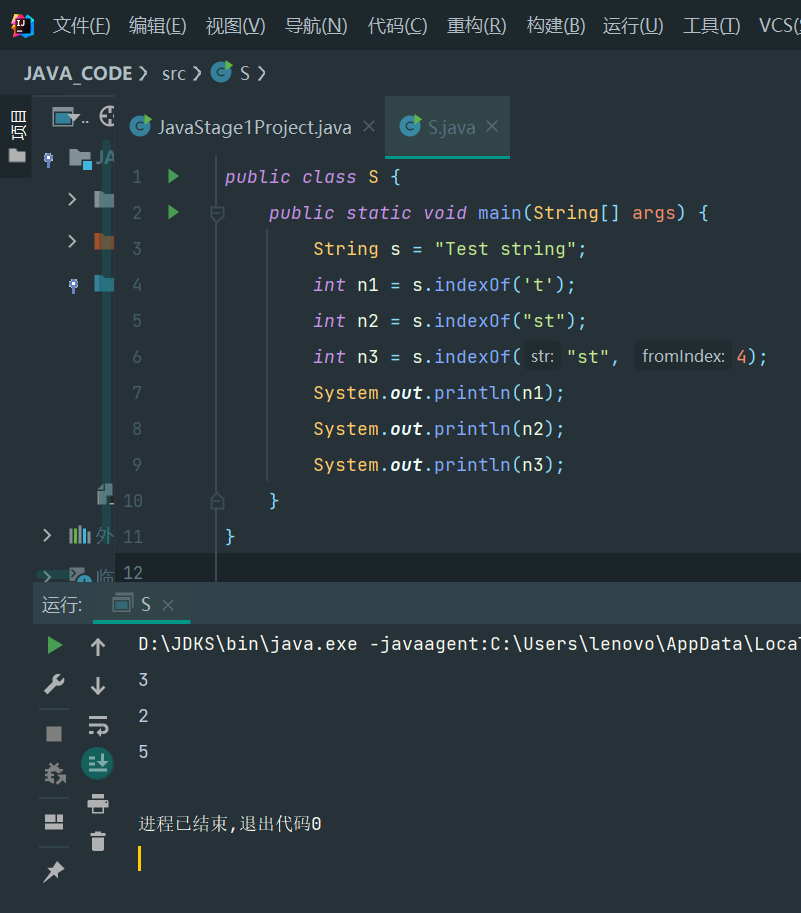
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DaqKk2X4-1676946013322)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
)
五,继承
1.简介:
在前面的章节中,我们已经定义了Person类:
class Person {
private String name;
private int age;
public String getName() {...}
public void setName(String name) {...}
public int getAge() {...}
public void setAge(int age) {...}
}
现在,假设需要定义一个Student类,字段如下:
class Student {
private String name;
private int age;
private int score;
public String getName() {...}
public void setName(String name) {...}
public int getAge() {...}
public void setAge(int age) {...}
public int getScore() { … }
public void setScore(int score) { … }
}
仔细观察,发现Student类包含了Person类已有的字段和方法,只是多出了一个score字段和相应的getScore()、setScore()方法。
能不能在Student中不要写重复的代码?
这个时候,继承就派上用场了。
继承是面向对象编程中非常强大的一种机制,它首先可以复用代码。当我们让Student从Person继承时,Student就获得了Person的所有功能,我们只需要为Student编写新增的功能。
Java使用extends关键字来实现继承:
class Person {
private String name;
private int age;
public String getName() {...}
public void setName(String name) {...}
public int getAge() {...}
public void setAge(int age) {...}
}
class Student extends Person {
// 不要重复name和age字段/方法,
// 只需要定义新增score字段/方法:
private int score;
public int getScore() { … }
public void setScore(int score) { … }
}
可见,通过继承,Student只需要编写额外的功能,不再需要重复代码。
在OOP的术语中,我们把Person称为超类(super class),父类(parent class),基类(base class),把Student称为子类(subclass),扩展类(extended class)。
2.继承树
注意到我们在定义Person的时候,没有写extends。在Java中,没有明确写extends的类,编译器会自动加上extends Object。所以,任何类,除了Object,都会继承自某个类。下图是Person、Student的继承树:
┌───────────┐
│ Object │
└───────────┘
▲
│
┌───────────┐
│ Person │
└───────────┘
▲
│
┌───────────┐
│ Student │
└───────────┘
Java只允许一个class继承自一个类,因此,一个类有且仅有一个父类。只有Object特殊,它没有父类。
类似的,如果我们定义一个继承自Person的Teacher,它们的继承树关系如下:
┌───────────┐
│ Object │
└───────────┘
▲
│
┌───────────┐
│ Person │
└───────────┘
▲ ▲
│ │
│ │
┌───────────┐ ┌───────────┐
│ Student │ │ Teacher │
└───────────┘ └───────────┘
3.protected
继承有个特点,就是子类无法访问父类的private字段或者private方法。例如,Student类就无法访问Person类的name和age字段:
class Person {
private String name;
private int age;
}
class Student extends Person {
public String hello() {
return "Hello, " + name; // 编译错误:无法访问name字段
}
}
这使得继承的作用被削弱了。为了让子类可以访问父类的字段,我们需要把private改为protected。用protected修饰的字段可以被子类访问:
class Person {
protected String name;
protected int age;
}
class Student extends Person {
public String hello() {
return "Hello, " + name; // OK!
}
}
因此,protected关键字可以把字段和方法的访问权限控制在继承树内部,一个protected字段和方法可以被其子类,以及子类的子类所访问,后面我们还会详细讲解。
4.super
super关键字表示父类(超类)。子类引用父类的字段时,可以用super.fieldName。例如:
class Student extends Person {
public String hello() {
return "Hello, " + super.name;
}
}
实际上,这里使用super.name,或者this.name,或者name,效果都是一样的。编译器会自动定位到父类的name字段。
但是,在某些时候,就必须使用super。我们来看一个例子:
public class Main {
public static void main(String[] args) {
Student s = new Student("Xiao Ming", 12, 89);
}
}
class Person {
protected String name;
protected int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
class Student extends Person {
protected int score;
public Student(String name, int age, int score) {
this.score = score;
}
}
运行上面的代码,会得到一个编译错误,大意是在Student的构造方法中,无法调用Person的构造方法。
这是因为在Java中,任何class的构造方法,第一行语句必须是调用父类的构造方法。如果没有明确地调用父类的构造方法,编译器会帮我们自动加一句super();,所以,Student类的构造方法实际上是这样:
class Student extends Person {
protected int score;
public Student(String name, int age, int score) {
super(); // 自动调用父类的构造方法
this.score = score;
}
}
但是,Person类并没有无参数的构造方法,因此,编译失败。
解决方法是调用Person类存在的某个构造方法。例如:
class Student extends Person {
protected int score;
public Student(String name, int age, int score) {
super(name, age); // 调用父类的构造方法Person(String, int)
this.score = score;
}
}
这样就可以正常编译了!
因此我们得出结论:如果父类没有默认的构造方法,子类就必须显式调用super()并给出参数以便让编译器定位到父类的一个合适的构造方法。
这里还顺带引出了另一个问题:即子类不会继承任何父类的构造方法。子类默认的构造方法是编译器自动生成的,不是继承的。
5.阻止继承
正常情况下,只要某个class没有final修饰符,那么任何类都可以从该class继承。
从Java 15开始,允许使用sealed修饰class,并通过permits明确写出能够从该class继承的子类名称。
例如,定义一个Shape类:
public sealed class Shape permits Rect, Circle, Triangle {
...
}
上述Shape类就是一个sealed类,它只允许指定的3个类继承它。如果写:
public final class Rect extends Shape {...}
是没问题的,因为Rect出现在Shape的permits列表中。但是,如果定义一个Ellipse就会报错:
public final class Ellipse extends Shape {...}
// Compile error: class is not allowed to extend sealed class: Shape
原因是Ellipse并未出现在Shape的permits列表中。这种sealed类主要用于一些框架,防止继承被滥用。
sealed类在Java 15中目前是预览状态,要启用它,必须使用参数--enable-preview和--source 15。
6.向上转型
如果一个引用变量的类型是Student,那么它可以指向一个Student类型的实例:
Student s = new Student();
如果一个引用类型的变量是Person,那么它可以指向一个Person类型的实例:
Person p = new Person();
现在问题来了:如果Student是从Person继承下来的,那么,一个引用类型为Person的变量,能否指向Student类型的实例?
Person p = new Student(); // ???
测试一下就可以发现,这种指向是允许的!
这是因为Student继承自Person,因此,它拥有Person的全部功能。Person类型的变量,如果指向Student类型的实例,对它进行操作,是没有问题的!
这种把一个子类类型安全地变为父类类型的赋值,被称为向上转型(upcasting)。
向上转型实际上是把一个子类型安全地变为更加抽象的父类型:
Student s = new Student();
Person p = s; // upcasting, ok
Object o1 = p; // upcasting, ok
Object o2 = s; // upcasting, ok
注意到继承树是Student > Person > Object,所以,可以把Student类型转型为Person,或者更高层次的Object。
7.向下转型
和向上转型相反,如果把一个父类类型强制转型为子类类型,就是向下转型(downcasting)。例如:
Person p1 = new Student(); // upcasting, ok
Person p2 = new Person();
Student s1 = (Student) p1; // ok
Student s2 = (Student) p2; // runtime error! ClassCastException!
如果测试上面的代码,可以发现:
Person类型p1实际指向Student实例,Person类型变量p2实际指向Person实例。在向下转型的时候,把p1转型为Student会成功,因为p1确实指向Student实例,把p2转型为Student会失败,因为p2的实际类型是Person,不能把父类变为子类,因为子类功能比父类多,多的功能无法凭空变出来。
因此,向下转型很可能会失败。失败的时候,Java虚拟机会报ClassCastException。
为了避免向下转型出错,Java提供了instanceof操作符,可以先判断一个实例究竟是不是某种类型:
Person p = new Person();
System.out.println(p instanceof Person); // true
System.out.println(p instanceof Student); // false
Student s = new Student();
System.out.println(s instanceof Person); // true
System.out.println(s instanceof Student); // true
Student n = null;
System.out.println(n instanceof Student); // false
instanceof实际上判断一个变量所指向的实例是否是指定类型,或者这个类型的子类。如果一个引用变量为null,那么对任何instanceof的判断都为false。
利用instanceof,在向下转型前可以先判断:
Person p = new Student();
if (p instanceof Student) {
// 只有判断成功才会向下转型:
Student s = (Student) p; // 一定会成功
}
从Java 14开始,判断instanceof后,可以直接转型为指定变量,避免再次强制转型。例如,对于以下代码:
Object obj = "hello";
if (obj instanceof String) {
String s = (String) obj;
System.out.println(s.toUpperCase());
}
这种使用instanceof的写法更加简洁。
8.区分继承和组合
在使用继承时,我们要注意逻辑一致性。
考察下面的Book类:
class Book {
protected String name;
public String getName() {...}
public void setName(String name) {...}
}
这个Book类也有name字段,那么,我们能不能让Student继承自Book呢?
class Student extends Book {
protected int score;
}
显然,从逻辑上讲,这是不合理的,Student不应该从Book继承,而应该从Person继承。
究其原因,是因为Student是Person的一种,它们是is关系,而Student并不是Book。实际上Student和Book的关系是has关系。
具有has关系不应该使用继承,而是使用组合,即Student可以持有一个Book实例:
class Student extends Person {
protected Book book;
protected int score;
}
因此,继承是is关系,组合是has关系。
六,多态
在继承关系中,子类如果定义了一个与父类方法签名完全相同的方法,被称为覆写(Override)。
例如,在Person类中,我们定义了run()方法:
class Person {
public void run() {
System.out.println("Person.run");
}
}
在子类Student中,覆写这个run()方法:
class Student extends Person {
@Override
public void run() {
System.out.println("Student.run");
}
}
Override和Overload不同的是,如果方法签名不同,就是Overload,Overload方法是一个新方法;如果方法签名相同,并且返回值也相同,就是Override。
注意:方法名相同,方法参数相同,但方法返回值不同,也是不同的方法。在Java程序中,出现这种情况,编译器会报错。
class Person {
public void run() { … }
}
class Student extends Person {
// 不是Override,因为参数不同:
public void run(String s) { … }
// 不是Override,因为返回值不同:
public int run() { … }
}
加上@Override可以让编译器帮助检查是否进行了正确的覆写。希望进行覆写,但是不小心写错了方法签名,编译器会报错。
但是@Override不是必需的。
在上一节中,我们已经知道,引用变量的声明类型可能与其实际类型不符,例如:
Person p = new Student();
现在,我们考虑一种情况,如果子类覆写了父类的方法:
public class Main {
public static void main(String[] args) {
Person p = new Student();
p.run(); // 应该打印Person.run还是Student.run?
}
}
class Person {
public void run() {
System.out.println("Person.run");
}
}
class Student extends Person {
@Override
public void run() {
System.out.println("Student.run");
}
}
那么,一个实际类型为Student,引用类型为Person的变量,调用其run()方法,调用的是Person还是Student的run()方法?
运行一下上面的代码就可以知道,实际上调用的方法是Student的run()方法。因此可得出结论:
Java的实例方法调用是基于运行时的实际类型的动态调用,而非变量的声明类型。
这个非常重要的特性在面向对象编程中称之为多态。它的英文拼写非常复杂:Polymorphic。
多态
多态是指,针对某个类型的方法调用,其真正执行的方法取决于运行时期实际类型的方法。例如:
Person p = new Student();
p.run(); // 无法确定运行时究竟调用哪个run()方法
有童鞋会问,从上面的代码一看就明白,肯定调用的是Student的run()方法啊。
但是,假设我们编写这样一个方法:
public void runTwice(Person p) {
p.run();
p.run();
}
它传入的参数类型是Person,我们是无法知道传入的参数实际类型究竟是Person,还是Student,还是Person的其他子类,因此,也无法确定调用的是不是Person类定义的run()方法。
所以,多态的特性就是,运行期才能动态决定调用的子类方法。对某个类型调用某个方法,执行的实际方法可能是某个子类的覆写方法。这种不确定性的方法调用,究竟有什么作用?
我们还是来举栗子。
假设我们定义一种收入,需要给它报税,那么先定义一个Income类:
class Income {
protected double income;
public double getTax() {
return income * 0.1; // 税率10%
}
}
对于工资收入,可以减去一个基数,那么我们可以从Income派生出SalaryIncome,并覆写getTax():
class Salary extends Income {
@Override
public double getTax() {
if (income <= 5000) {
return 0;
}
return (income - 5000) * 0.2;
}
}
如果你享受国务院特殊津贴,那么按照规定,可以全部免税:
class StateCouncilSpecialAllowance extends Income {
@Override
public double getTax() {
return 0;
}
}
现在,我们要编写一个报税的财务软件,对于一个人的所有收入进行报税,可以这么写:
public double totalTax(Income... incomes) {
double total = 0;
for (Income income: incomes) {
total = total + income.getTax();
}
return total;
}
public class Main {
public static void main(String[] args) {
// 给一个有普通收入、工资收入和享受国务院特殊津贴的小伙伴算税:
Income[] incomes = new Income[] {
new Income(3000),
new Salary(7500),
new StateCouncilSpecialAllowance(15000)
};
System.out.println(totalTax(incomes));
}
public static double totalTax(Income... incomes) {
double total = 0;
for (Income income: incomes) {
total = total + income.getTax();
}
return total;
}
}
class Income {
protected double income;
public Income(double income) {
this.income = income;
}
public double getTax() {
return income * 0.1; // 税率10%
}
}
class Salary extends Income {
public Salary(double income) {
super(income);
}
@Override
public double getTax() {
if (income <= 5000) {
return 0;
}
return (income - 5000) * 0.2;
}
}
class StateCouncilSpecialAllowance extends Income {
public StateCouncilSpecialAllowance(double income) {
super(income);
}
@Override
public double getTax() {
return 0;
}
}
观察totalTax()方法:利用多态,totalTax()方法只需要和Income打交道,它完全不需要知道Salary和StateCouncilSpecialAllowance的存在,就可以正确计算出总的税。如果我们要新增一种稿费收入,只需要从Income派生,然后正确覆写getTax()方法就可以。把新的类型传入totalTax(),不需要修改任何代码。
可见,多态具有一个非常强大的功能,就是允许添加更多类型的子类实现功能扩展,却不需要修改基于父类的代码。
多态
阅读: 17145662
在继承关系中,子类如果定义了一个与父类方法签名完全相同的方法,被称为覆写(Override)。
例如,在Person类中,我们定义了run()方法:
class Person {
public void run() {
System.out.println("Person.run");
}
}
在子类Student中,覆写这个run()方法:
class Student extends Person {
@Override
public void run() {
System.out.println("Student.run");
}
}
Override和Overload不同的是,如果方法签名不同,就是Overload,Overload方法是一个新方法;如果方法签名相同,并且返回值也相同,就是Override。
注意:方法名相同,方法参数相同,但方法返回值不同,也是不同的方法。在Java程序中,出现这种情况,编译器会报错。
class Person {
public void run() { … }
}
class Student extends Person {
// 不是Override,因为参数不同:
public void run(String s) { … }
// 不是Override,因为返回值不同:
public int run() { … }
}
加上@Override可以让编译器帮助检查是否进行了正确的覆写。希望进行覆写,但是不小心写错了方法签名,编译器会报错。
// override
Run
但是@Override不是必需的。
在上一节中,我们已经知道,引用变量的声明类型可能与其实际类型不符,例如:
Person p = new Student();
现在,我们考虑一种情况,如果子类覆写了父类的方法:
// override
Run
那么,一个实际类型为Student,引用类型为Person的变量,调用其run()方法,调用的是Person还是Student的run()方法?
运行一下上面的代码就可以知道,实际上调用的方法是Student的run()方法。因此可得出结论:
Java的实例方法调用是基于运行时的实际类型的动态调用,而非变量的声明类型。
这个非常重要的特性在面向对象编程中称之为多态。它的英文拼写非常复杂:Polymorphic。
多态
多态是指,针对某个类型的方法调用,其真正执行的方法取决于运行时期实际类型的方法。例如:
Person p = new Student();
p.run(); // 无法确定运行时究竟调用哪个run()方法
有童鞋会问,从上面的代码一看就明白,肯定调用的是Student的run()方法啊。
但是,假设我们编写这样一个方法:
public void runTwice(Person p) {
p.run();
p.run();
}
它传入的参数类型是Person,我们是无法知道传入的参数实际类型究竟是Person,还是Student,还是Person的其他子类,因此,也无法确定调用的是不是Person类定义的run()方法。
所以,多态的特性就是,运行期才能动态决定调用的子类方法。对某个类型调用某个方法,执行的实际方法可能是某个子类的覆写方法。这种不确定性的方法调用,究竟有什么作用?
我们还是来举栗子。
假设我们定义一种收入,需要给它报税,那么先定义一个Income类:
class Income {
protected double income;
public double getTax() {
return income * 0.1; // 税率10%
}
}
对于工资收入,可以减去一个基数,那么我们可以从Income派生出SalaryIncome,并覆写getTax():
class Salary extends Income {
@Override
public double getTax() {
if (income <= 5000) {
return 0;
}
return (income - 5000) * 0.2;
}
}
如果你享受国务院特殊津贴,那么按照规定,可以全部免税:
class StateCouncilSpecialAllowance extends Income {
@Override
public double getTax() {
return 0;
}
}
现在,我们要编写一个报税的财务软件,对于一个人的所有收入进行报税,可以这么写:
public double totalTax(Income... incomes) {
double total = 0;
for (Income income: incomes) {
total = total + income.getTax();
}
return total;
}
来试一下:
// Polymorphic
Run
观察totalTax()方法:利用多态,totalTax()方法只需要和Income打交道,它完全不需要知道Salary和StateCouncilSpecialAllowance的存在,就可以正确计算出总的税。如果我们要新增一种稿费收入,只需要从Income派生,然后正确覆写getTax()方法就可以。把新的类型传入totalTax(),不需要修改任何代码。
可见,多态具有一个非常强大的功能,就是允许添加更多类型的子类实现功能扩展,却不需要修改基于父类的代码。
覆写Object方法
因为所有的class最终都继承自Object,而Object定义了几个重要的方法:
toString():把instance输出为String;equals():判断两个instance是否逻辑相等;hashCode():计算一个instance的哈希值。
在必要的情况下,我们可以覆写Object的这几个方法。例如:
class Person {
...
// 显示更有意义的字符串:
@Override
public String toString() {
return "Person:name=" + name;
}
// 比较是否相等:
@Override
public boolean equals(Object o) {
// 当且仅当o为Person类型:
if (o instanceof Person) {
Person p = (Person) o;
// 并且name字段相同时,返回true:
return this.name.equals(p.name);
}
return false;
}
// 计算hash:
@Override
public int hashCode() {
return this.name.hashCode();
}
}
调用super
在子类的覆写方法中,如果要调用父类的被覆写的方法,可以通过super来调用。例如:
class Person {
protected String name;
public String hello() {
return "Hello, " + name;
}
}
Student extends Person {
@Override
public String hello() {
// 调用父类的hello()方法:
return super.hello() + "!";
}
}
final
继承可以允许子类覆写父类的方法。如果一个父类不允许子类对它的某个方法进行覆写,可以把该方法标记为final。用final修饰的方法不能被Override:
class Person {
protected String name;
public final String hello() {
return "Hello, " + name;
}
}
Student extends Person {
// compile error: 不允许覆写
@Override
public String hello() {
}
}
如果一个类不希望任何其他类继承自它,那么可以把这个类本身标记为final。用final修饰的类不能被继承:
final class Person {
protected String name;
}
// compile error: 不允许继承自Person
Student extends Person {
}
对于一个类的实例字段,同样可以用final修饰。用final修饰的字段在初始化后不能被修改。例如:
class Person {
public final String name = "Unamed";
}
对final字段重新赋值会报错:
Person p = new Person();
p.name = "New Name"; // compile error!
可以在构造方法中初始化final字段:
class Person {
public final String name;
public Person(String name) {
this.name = name;
}
}
这种方法更为常用,因为可以保证实例一旦创建,其final字段就不可修改。
小结
- 子类可以覆写父类的方法(Override),覆写在子类中改变了父类方法的行为;
- Java的方法调用总是作用于运行期对象的实际类型,这种行为称为多态;
final修饰符有多种作用:final修饰的方法可以阻止被覆写;final修饰的class可以阻止被继承;final修饰的field必须在创建对象时初始化,随后不可修改。
七,抽象类
1.简介
由于多态的存在,每个子类都可以覆写父类的方法,例如:
class Person {
public void run() { … }
}
class Student extends Person {
@Override
public void run() { … }
}
class Teacher extends Person {
@Override
public void run() { … }
}
从Person类派生的Student和Teacher都可以覆写run()方法。
如果父类Person的run()方法没有实际意义,能否去掉方法的执行语句?
class Person {
public void run(); // Compile Error!
}
答案是不行,会导致编译错误,因为定义方法的时候,必须实现方法的语句。
能不能去掉父类的run()方法?
答案还是不行,因为去掉父类的run()方法,就失去了多态的特性。例如,runTwice()就无法编译:
public void runTwice(Person p) {
p.run(); // Person没有run()方法,会导致编译错误
p.run();
}
如果父类的方法本身不需要实现任何功能,仅仅是为了定义方法签名,目的是让子类去覆写它,那么,可以把父类的方法声明为抽象方法:
class Person {
public abstract void run();
}
把一个方法声明为abstract,表示它是一个抽象方法,本身没有实现任何方法语句。因为这个抽象方法本身是无法执行的,所以,Person类也无法被实例化。编译器会告诉我们,无法编译Person类,因为它包含抽象方法。
必须把Person类本身也声明为abstract,才能正确编译它:
abstract class Person {
public abstract void run();
}
2.抽象类
如果一个class定义了方法,但没有具体执行代码,这个方法就是抽象方法,抽象方法用abstract修饰。
因为无法执行抽象方法,因此这个类也必须申明为抽象类(abstract class)。
使用abstract修饰的类就是抽象类。我们无法实例化一个抽象类:
Person p = new Person(); // 编译错误
无法实例化的抽象类有什么用?
因为抽象类本身被设计成只能用于被继承,因此,抽象类可以强迫子类实现其定义的抽象方法,否则编译会报错。因此,抽象方法实际上相当于定义了“规范”。
例如,Person类定义了抽象方法run(),那么,在实现子类Student的时候,就必须覆写run()方法:
public class Main {
public static void main(String[] args) {
Person p = new Student();
p.run();
}
}
abstract class Person {
public abstract void run();
}
class Student extends Person {
@Override
public void run() {
System.out.println("Student.run");
}
}
面向抽象编程
当我们定义了抽象类Person,以及具体的Student、Teacher子类的时候,我们可以通过抽象类Person类型去引用具体的子类的实例:
Person s = new Student();
Person t = new Teacher();
这种引用抽象类的好处在于,我们对其进行方法调用,并不关心Person类型变量的具体子类型:
// 不关心Person变量的具体子类型:
s.run();
t.run();
同样的代码,如果引用的是一个新的子类,我们仍然不关心具体类型:
// 同样不关心新的子类是如何实现run()方法的:
Person e = new Employee();
e.run();
这种尽量引用高层类型,避免引用实际子类型的方式,称之为面向抽象编程。
面向抽象编程的本质就是:
- 上层代码只定义规范(例如:
abstract class Person); - 不需要子类就可以实现业务逻辑(正常编译);
- 具体的业务逻辑由不同的子类实现,调用者并不关心。
八,接口
1.简介
在抽象类中,抽象方法本质上是定义接口规范:即规定高层类的接口,从而保证所有子类都有相同的接口实现,这样,多态就能发挥出威力。
如果一个抽象类没有字段,所有方法全部都是抽象方法:
abstract class Person {
public abstract void run();
public abstract String getName();
}
就可以把该抽象类改写为接口:interface。
在Java中,使用interface可以声明一个接口:
interface Person {
void run();
String getName();
}
所谓interface,就是比抽象类还要抽象的纯抽象接口,因为它连字段都不能有。因为接口定义的所有方法默认都是public abstract的,所以这两个修饰符不需要写出来(写不写效果都一样)。
当一个具体的class去实现一个interface时,需要使用implements关键字。举个例子:
class Student implements Person {
private String name;
public Student(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println(this.name + " run");
}
@Override
public String getName() {
return this.name;
}
}
我们知道,在Java中,一个类只能继承自另一个类,不能从多个类继承。但是,一个类可以实现多个interface,例如:
class Student implements Person, Hello { // 实现了两个interface
...
}
2.术语
注意区分术语:
Java的接口特指interface的定义,表示一个接口类型和一组方法签名,而编程接口泛指接口规范,如方法签名,数据格式,网络协议等。
抽象类和接口的对比如下:
| abstract class | interface | |
|---|---|---|
| 继承 | 只能extends一个class | 可以implements多个interface |
| 字段 | 可以定义实例字段 | 不能定义实例字段 |
| 抽象方法 | 可以定义抽象方法 | 可以定义抽象方法 |
| 非抽象方法 | 可以定义非抽象方法 | 可以定义default方法 |
3.接口继承
一个interface可以继承自另一个interface。interface继承自interface使用extends,它相当于扩展了接口的方法。例如:
interface Hello {
void hello();
}
interface Person extends Hello {
void run();
String getName();
}
此时,Person接口继承自Hello接口,因此,Person接口现在实际上有3个抽象方法签名,其中一个来自继承的Hello接口。
4.继承关系
合理设计interface和abstract class的继承关系,可以充分复用代码。一般来说,公共逻辑适合放在abstract class中,具体逻辑放到各个子类,而接口层次代表抽象程度。可以参考Java的集合类定义的一组接口、抽象类以及具体子类的继承关系:
┌───────────────┐
│ Iterable │
└───────────────┘
▲ ┌───────────────────┐
│ │ Object │
┌───────────────┐ └───────────────────┘
│ Collection │ ▲
└───────────────┘ │
▲ ▲ ┌───────────────────┐
│ └──────────│AbstractCollection │
┌───────────────┐ └───────────────────┘
│ List │ ▲
└───────────────┘ │
▲ ┌───────────────────┐
└──────────│ AbstractList │
└───────────────────┘
▲ ▲
│ │
│ │
┌────────────┐ ┌────────────┐
│ ArrayList │ │ LinkedList │
└────────────┘ └────────────┘
在使用的时候,实例化的对象永远只能是某个具体的子类,但总是通过接口去引用它,因为接口比抽象类更抽象:
List list = new ArrayList(); // 用List接口引用具体子类的实例
Collection coll = list; // 向上转型为Collection接口
Iterable it = coll; // 向上转型为Iterable接口
5.default方法
在接口中,可以定义default方法。例如,把Person接口的run()方法改为default方法:
public class Main {
public static void main(String[] args) {
Person p = new Student("Xiao Ming");
p.run();
}
}
interface Person {
String getName();
default void run() {
System.out.println(getName() + " run");
}
}
class Student implements Person {
private String name;
public Student(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
}
实现类可以不必覆写default方法。default方法的目的是,当我们需要给接口新增一个方法时,会涉及到修改全部子类。如果新增的是default方法,那么子类就不必全部修改,只需要在需要覆写的地方去覆写新增方法。
default方法和抽象类的普通方法是有所不同的。因为interface没有字段,default方法无法访问字段,而抽象类的普通方法可以访问实例字段。
九,静态字段和静态方法
1.静态字段
在一个class中定义的字段,我们称之为实例字段。实例字段的特点是,每个实例都有独立的字段,各个实例的同名字段互不影响。
还有一种字段,是用static修饰的字段,称为静态字段:static field。
实例字段在每个实例中都有自己的一个独立“空间”,但是静态字段只有一个共享“空间”,所有实例都会共享该字段。举个例子:
class Person {
public String name;
public int age;
// 定义静态字段number:
public static int number;
}
我们来看看下面的代码:
public class Main {
public static void main(String[] args) {
Person ming = new Person("Xiao Ming", 12);
Person hong = new Person("Xiao Hong", 15);
ming.number = 88;
System.out.println(hong.number);
hong.number = 99;
System.out.println(ming.number);
}
}
class Person {
public String name;
public int age;
public static int number;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
对于静态字段,无论修改哪个实例的静态字段,效果都是一样的:所有实例的静态字段都被修改了,原因是静态字段并不属于实例:
┌──────────────────┐
ming ──>│Person instance │
├──────────────────┤
│name = "Xiao Ming"│
│age = 12 │
│number ───────────┼──┐ ┌─────────────┐
└──────────────────┘ │ │Person class │
│ ├─────────────┤
├───>│number = 99 │
┌──────────────────┐ │ └─────────────┘
hong ──>│Person instance │ │
├──────────────────┤ │
│name = "Xiao Hong"│ │
│age = 15 │ │
│number ───────────┼──┘
└──────────────────┘
虽然实例可以访问静态字段,但是它们指向的其实都是Person class的静态字段。所以,所有实例共享一个静态字段。
因此,不推荐用实例变量.静态字段去访问静态字段,因为在Java程序中,实例对象并没有静态字段。在代码中,实例对象能访问静态字段只是因为编译器可以根据实例类型自动转换为类名.静态字段来访问静态对象。
推荐用类名来访问静态字段。可以把静态字段理解为描述class本身的字段(非实例字段)。对于上面的代码,更好的写法是:
Person.number = 99;
System.out.println(Person.number);
静态方法
有静态字段,就有静态方法。用static修饰的方法称为静态方法。
调用实例方法必须通过一个实例变量,而调用静态方法则不需要实例变量,通过类名就可以调用。静态方法类似其它编程语言的函数。例如:
public class Main {
public static void main(String[] args) {
Person.setNumber(99);
System.out.println(Person.number);
}
}
class Person {
public static int number;
public static void setNumber(int value) {
number = value;
}
}
因为静态方法属于class而不属于实例,因此,静态方法内部,无法访问this变量,也无法访问实例字段,它只能访问静态字段。
通过实例变量也可以调用静态方法,但这只是编译器自动帮我们把实例改写成类名而已。
通常情况下,通过实例变量访问静态字段和静态方法,会得到一个编译警告。
静态方法经常用于工具类。例如:
- Arrays.sort()
- Math.random()
静态方法也经常用于辅助方法。注意到Java程序的入口main()也是静态方法。
接口的静态字段
因为interface是一个纯抽象类,所以它不能定义实例字段。但是,interface是可以有静态字段的,并且静态字段必须为final类型:
public interface Person {
public static final int MALE = 1;
public static final int FEMALE = 2;
}
实际上,因为interface的字段只能是public static final类型,所以我们可以把这些修饰符都去掉,上述代码可以简写为:
public interface Person {
// 编译器会自动加上public statc final:
int MALE = 1;
int FEMALE = 2;
}
编译器会自动把该字段变为public static final类型。
Java核心类
一,字符串和编码
1.String
在Java中,String是一个引用类型,它本身也是一个class。但是,Java编译器对String有特殊处理,即可以直接用"..."来表示一个字符串:
String s1 = "Hello!";
实际上字符串在String内部是通过一个char[]数组表示的,因此,按下面的写法也是可以的:
String s2 = new String(new char[] {'H', 'e', 'l', 'l', 'o', '!'});
因为String太常用了,所以Java提供了"..."这种字符串字面量表示方法。
Java字符串的一个重要特点就是字符串不可变。这种不可变性是通过内部的private final char[]字段,以及没有任何修改char[]的方法实现的。
我们来看一个例子:
public class Main {
public static void main(String[] args) {
String s = "Hello";
System.out.println(s);
s = s.toUpperCase();
System.out.println(s);
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JrP2gNBH-1676946013323)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
2.字符串比较
当我们想要比较两个字符串是否相同时,要特别注意,我们实际上是想比较字符串的内容是否相同。必须使用equals()方法而不能用==。
我们看下面的例子:
public class Main {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "hello";
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nWTUqsAm-1676946013323)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
从表面上看,两个字符串用==和equals()比较都为true,但实际上那只是Java编译器在编译期,会自动把所有相同的字符串当作一个对象放入常量池,自然s1和s2的引用就是相同的。
所以,这种==比较返回true纯属巧合。换一种写法,==比较就会失败:
public class Main {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "HELLO".toLowerCase();
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}
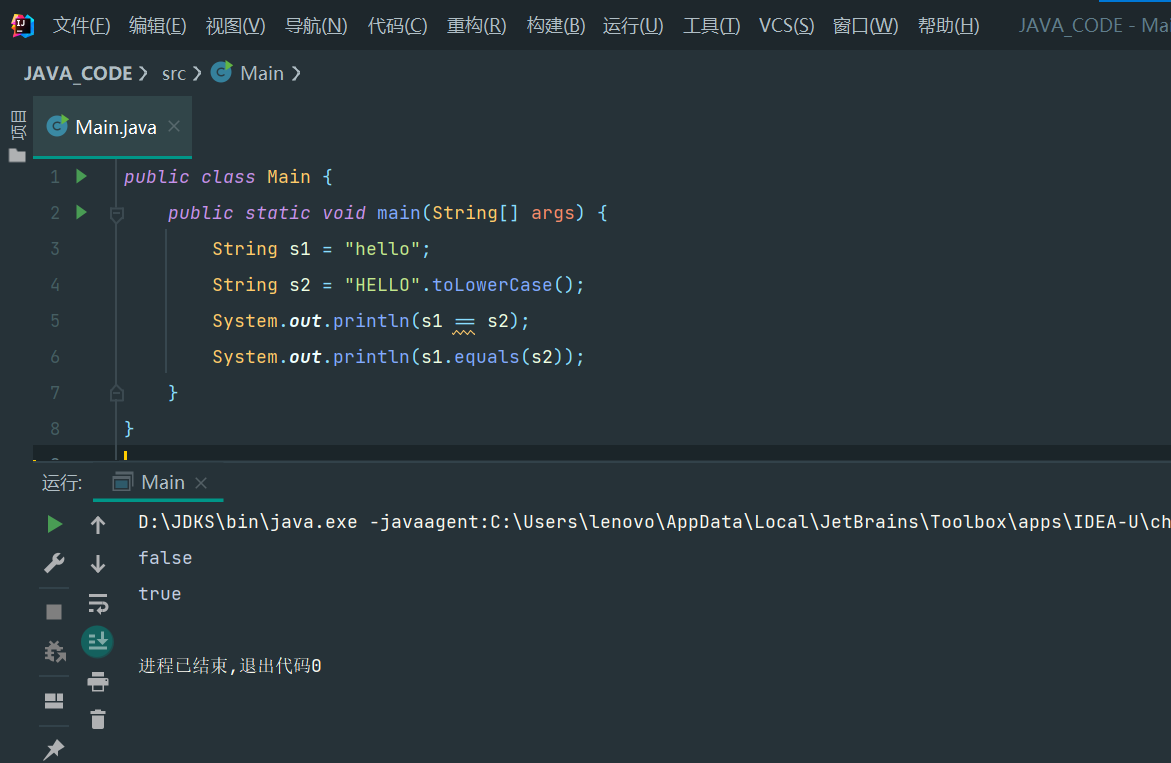
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-018XaFf2-1676946013324)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
结论:两个字符串比较,必须总是使用equals()方法。
要忽略大小写比较,使用equalsIgnoreCase()方法。
String类还提供了多种方法来搜索子串、提取子串。常用的方法有:
// 是否包含子串:
"Hello".contains("ll"); // true
注意到contains()方法的参数是CharSequence而不是String,因为CharSequence是String的父类。
搜索子串的更多的例子:
"Hello".indexOf("l"); // 2
"Hello".lastIndexOf("l"); // 3
"Hello".startsWith("He"); // true
"Hello".endsWith("lo"); // true
提取子串的例子:
"Hello".substring(2); // "llo"
"Hello".substring(2, 4); "ll"
注意索引号是从0开始的。
3.去除首尾空白字符
使用trim()方法可以移除字符串首尾空白字符。空白字符包括空格,\t,\r,\n:
注意:
- \t \r \n\f均是转义字符
- \t 的意思是 :水平制表符。将当前位置移到下一个tab位置。
- \r 的意思是: 回车。将当前位置移到本行的开头。
- \n 的意思是:回车换行。将当前位置移到下一行的开头。
- \f的意思是:换页。将当前位置移到下一页的开头。
" \tHello\r\n ".trim(); // "Hello"
注意:trim()并没有改变字符串的内容,而是返回了一个新字符串。
另一个strip()方法也可以移除字符串首尾空白字符。它和trim()不同的是,类似中文的空格字符\u3000也会被移除:
"\u3000Hello\u3000".strip(); // "Hello"
" Hello ".stripLeading(); // "Hello "
" Hello ".stripTrailing(); // " Hello"
4.判断字符串是否为空和空白字符串:
String还提供了isEmpty()和isBlank()来判断字符串是否为空和空白字符串:
"".isEmpty(); // true,因为字符串长度为0
" ".isEmpty(); // false,因为字符串长度不为0
" \n".isBlank(); // true,因为只包含空白字符
" Hello ".isBlank(); // false,因为包含非空白字符
5.替换子串s.replace
要在字符串中替换子串,有两种方法。一种是根据字符或字符串替换:
String s = "hello";
s.replace('l', 'w'); // "hewwo",所有字符'l'被替换为'w'
s.replace("ll", "~~"); // "he~~o",所有子串"ll"被替换为"~~"
另一种是通过正则表达式替换:
String s = "A,,B;C ,D";
s.replaceAll("[\\,\\;\\s]+", ","); // "A,B,C,D"
上面的代码通过正则表达式,把匹配的子串统一替换为","。关于正则表达式的用法我们会在后面详细讲解。
6.分割字符串
要分割字符串,使用split()方法,并且传入的也是正则表达式:
String s = "A,B,C,D";
String[] ss = s.split("\\,"); // {"A", "B", "C", "D"}
7.拼接字符串
拼接字符串使用静态方法join(),它用指定的字符串连接字符串数组:
String[] arr = {"A", "B", "C"};
String s = String.join("***", arr); // "A***B***C"
8.格式化字符串
字符串提供了formatted()方法和format()静态方法,可以传入其他参数,替换占位符,然后生成新的字符串:
public class Main {
public static void main(String[] args) {
String s = "Hi %s, your score is %d!";
System.out.println(s.formatted("Alice", 80));
System.out.println(String.format("Hi %s, your score is %.2f!", "Bob", 59.5));
}
}
运行结果:
Hi Alice, your score is 80!
Hi Bob, your score is 59.50!
有几个占位符,后面就传入几个参数。参数类型要和占位符一致。我们经常用这个方法来格式化信息。常用的占位符有:
%s:显示字符串;%d:显示整数;%x:显示十六进制整数;%f:显示浮点数。
占位符还可以带格式,例如%.2f表示显示两位小数。如果你不确定用啥占位符,那就始终用%s,因为%s可以显示任何数据类型。要查看完整的格式化语法,请参考JDK文档。
9.类型转换
要把任意基本类型或引用类型转换为字符串,可以使用静态方法valueOf()。这是一个重载方法,编译器会根据参数自动选择合适的方法:
String.valueOf(123); // "123"
String.valueOf(45.67); // "45.67"
String.valueOf(true); // "true"
String.valueOf(new Object()); // 类似java.lang.Object@636be97c
要把字符串转换为其他类型,就需要根据情况。例如,把字符串转换为int类型:
int n1 = Integer.parseInt("123"); // 123
int n2 = Integer.parseInt("ff", 16); // 按十六进制转换,255
把字符串转换为boolean类型:
boolean b1 = Boolean.parseBoolean("true"); // true
boolean b2 = Boolean.parseBoolean("FALSE"); // false
要特别注意,Integer有个getInteger(String)方法,它不是将字符串转换为int,而是把该字符串对应的系统变量转换为Integer:
Integer.getInteger("java.version"); // 版本号,11
10.转换为char[]
String和char[]类型可以互相转换,方法是:
char[] cs = "Hello".toCharArray(); // String -> char[]
String s = new String(cs); // char[] -> String
如果修改了char[]数组,String并不会改变:
public class Main {
public static void main(String[] args) {
char[] cs = "Hello".toCharArray();
String s = new String(cs);
System.out.println(s);
cs[0] = 'X';
System.out.println(s);
}
}
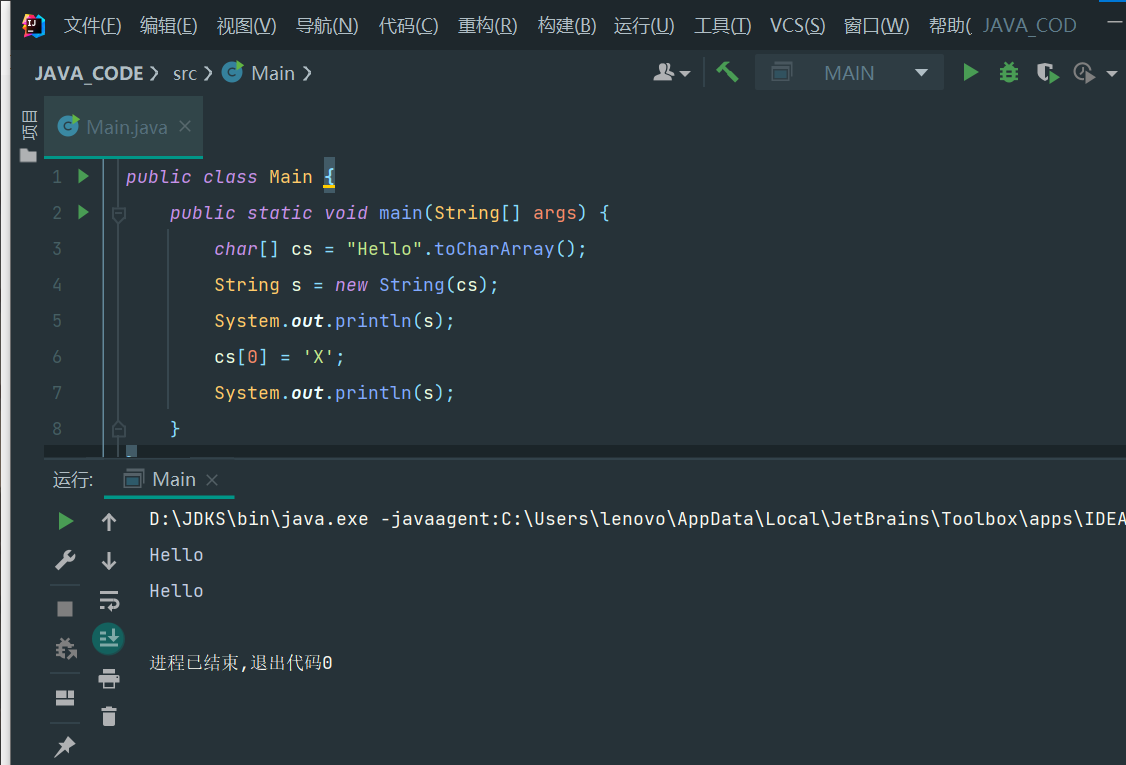
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RnyjIPEk-1676946013324)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
这是因为通过new String(char[])创建新的String实例时,它并不会直接引用传入的char[]数组,而是会复制一份,所以,修改外部的char[]数组不会影响String实例内部的char[]数组,因为这是两个不同的数组。
从String的不变性设计可以看出,如果传入的对象有可能改变,我们需要复制而不是直接引用。
例如,下面的代码设计了一个Score类保存一组学生的成绩:
public class Main {
public static void main(String[] args) {
int[] scores = new int[] { 88, 77, 51, 66 };
Score s = new Score(scores);
s.printScores();
scores[2] = 99;
s.printScores();
}
}
class Score {
private int[] scores;
public Score(int[] scores) {
this.scores = scores;
}
public void printScores() {
System.out.println(Arrays.toString(scores));
}
}
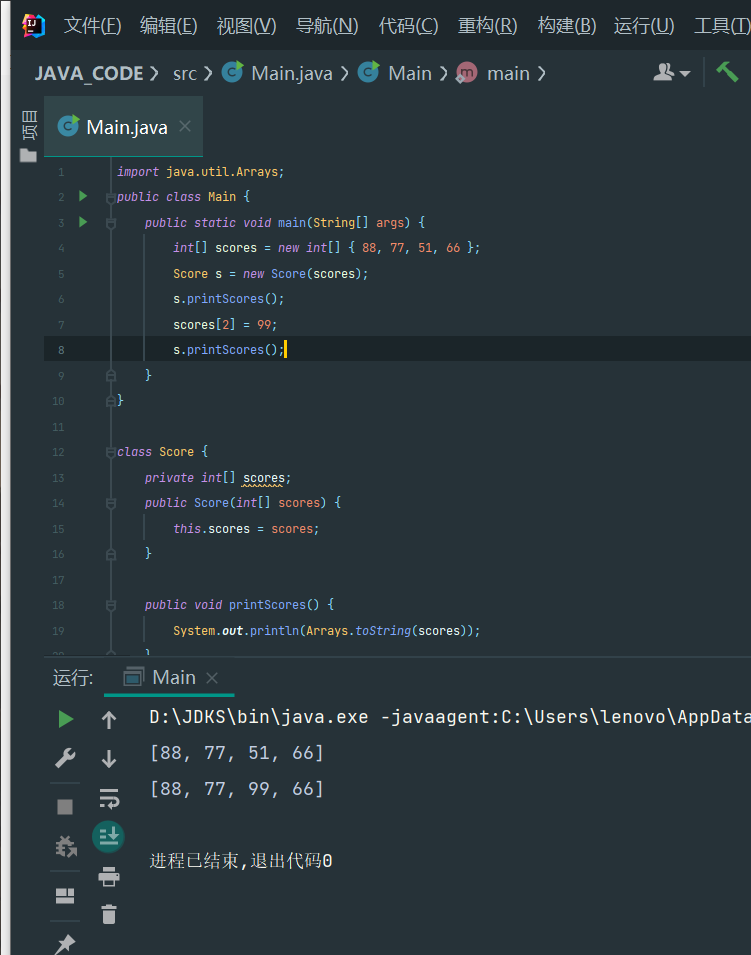
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z736gecd-1676946013325)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
观察两次输出,由于Score内部直接引用了外部传入的int[]数组,这会造成外部代码对int[]数组的修改,影响到Score类的字段。如果外部代码不可信,这就会造成安全隐患。
请修复Score的构造方法,使得外部代码对数组的修改不影响Score实例的int[]字段。
11.字符编码
在早期的计算机系统中,为了给字符编码,美国国家标准学会(American National Standard Institute:ANSI)制定了一套英文字母、数字和常用符号的编码,它占用一个字节,编码范围从0到127,最高位始终为0,称为ASCII编码。例如,字符'A'的编码是0x41,字符'1'的编码是0x31。
如果要把汉字也纳入计算机编码,很显然一个字节是不够的。GB2312标准使用两个字节表示一个汉字,其中第一个字节的最高位始终为1,以便和ASCII编码区分开。例如,汉字'中'的GB2312编码是0xd6d0。
类似的,日文有Shift_JIS编码,韩文有EUC-KR编码,这些编码因为标准不统一,同时使用,就会产生冲突。
为了统一全球所有语言的编码,全球统一码联盟发布了Unicode编码,它把世界上主要语言都纳入同一个编码,这样,中文、日文、韩文和其他语言就不会冲突。
Unicode编码需要两个或者更多字节表示,我们可以比较中英文字符在ASCII、GB2312和Unicode的编码:
英文字符'A'的ASCII编码和Unicode编码:
┌────┐
ASCII: │ 41 │
└────┘
┌────┬────┐
Unicode: │ 00 │ 41 │
└────┴────┘
英文字符的Unicode编码就是简单地在前面添加一个00字节。
中文字符'中'的GB2312编码和Unicode编码:
┌────┬────┐
GB2312: │ d6 │ d0 │
└────┴────┘
┌────┬────┐
Unicode: │ 4e │ 2d │
└────┴────┘
那我们经常使用的UTF-8又是什么编码呢?因为英文字符的Unicode编码高字节总是00,包含大量英文的文本会浪费空间,所以,出现了UTF-8编码,它是一种变长编码,用来把固定长度的Unicode编码变成1~4字节的变长编码。通过UTF-8编码,英文字符'A'的UTF-8编码变为0x41,正好和ASCII码一致,而中文'中'的UTF-8编码为3字节0xe4b8ad。
UTF-8编码的另一个好处是容错能力强。如果传输过程中某些字符出错,不会影响后续字符,因为UTF-8编码依靠高字节位来确定一个字符究竟是几个字节,它经常用来作为传输编码。
在Java中,char类型实际上就是两个字节的Unicode编码。如果我们要手动把字符串转换成其他编码,可以这样做:
byte[] b1 = "Hello".getBytes(); // 按系统默认编码转换,不推荐
byte[] b2 = "Hello".getBytes("UTF-8"); // 按UTF-8编码转换
byte[] b2 = "Hello".getBytes("GBK"); // 按GBK编码转换
byte[] b3 = "Hello".getBytes(StandardCharsets.UTF_8); // 按UTF-8编码转换
注意:转换编码后,就不再是char类型,而是byte类型表示的数组。
如果要把已知编码的byte[]转换为String,可以这样做:
byte[] b = ...
String s1 = new String(b, "GBK"); // 按GBK转换
String s2 = new String(b, StandardCharsets.UTF_8); // 按UTF-8转换
始终牢记:Java的String和char在内存中总是以Unicode编码表示。
12.延伸阅读
对于不同版本的JDK,String类在内存中有不同的优化方式。具体来说,早期JDK版本的String总是以char[]存储,它的定义如下:
public final class String {
private final char[] value;
private final int offset;
private final int count;
}
而较新的JDK版本的String则以byte[]存储:如果String仅包含ASCII字符,则每个byte存储一个字符,否则,每两个byte存储一个字符,这样做的目的是为了节省内存,因为大量的长度较短的String通常仅包含ASCII字符:
public final class String {
private final byte[] value;
private final byte coder; // 0 = LATIN1, 1 = UTF16
对于使用者来说,String内部的优化不影响任何已有代码,因为它的public方法签名是不变的。
*****小结*
- Java字符串
String是不可变对象; - 字符串操作不改变原字符串内容,而是返回新字符串;
- 常用的字符串操作:提取子串、查找、替换、大小写转换等;
- Java使用Unicode编码表示
String和char; - 转换编码就是将
String和byte[]转换,需要指定编码; - 转换为
byte[]时,始终优先考虑UTF-8编码。
二,StringBuilder
Java编译器对String做了特殊处理,使得我们可以直接用+拼接字符串。
考察下面的循环代码:
String s = "";
for (int i = 0; i < 1000; i++) {
s = s + "," + i;
}
虽然可以直接拼接字符串,但是,在循环中,每次循环都会创建新的字符串对象,然后扔掉旧的字符串。这样,绝大部分字符串都是临时对象,不但浪费内存,还会影响GC效率。
为了能高效拼接字符串,Java标准库提供了StringBuilder,它是一个可变对象,可以预分配缓冲区,这样,往StringBuilder中新增字符时,不会创建新的临时对象:
StringBuilder sb = new StringBuilder(1024);
for (int i = 0; i < 1000; i++) {
sb.append(',');
sb.append(i);
}
String s = sb.toString();
StringBuilder还可以进行链式操作:
public class Main {
public static void main(String[] args) {
var sb = new StringBuilder(1024);
sb.append("Mr ")
.append("Bob")
.append("!")
.insert(0, "Hello, ");
System.out.println(sb.toString());
}
}
常用工具类
1.Math
.1.求绝对值:
Math.abs(-100); // 100
Math.abs(-7.8); // 7.8
.2.取最大或最小值:
Math.max(100, 99); // 100
Math.min(1.2, 2.3); // 1.2
.3.计算xy次方:
Math.pow(2, 10); // 2的10次方=1024
.4.计算√x:
Math.sqrt(2); // 1.414...
.5.计算ex次方:
Math.exp(2); // 7.389...
.6.计算以e为底的对数:
Math.log(4); // 1.386...
.7.计算以10为底的对数:
Math.log10(100); // 2
三角函数:
Math.sin(3.14); // 0.00159...
Math.cos(3.14); // -0.9999...
Math.tan(3.14); // -0.0015...
Math.asin(1.0); // 1.57079...
Math.acos(1.0); // 0.0
数学常量PI,e,sinx:
double pi = Math.PI; // 3.14159...
double e = Math.E; // 2.7182818...
Math.sin(Math.PI / 6); // sin(π/6) = 0.5
生成一个随机数x,x的范围是0 <= x < 1:
Math.random(); // 0.53907... 每次都不一样
eg
如果我们要生成一个区间在[MIN, MAX)的随机数,可以借助Math.random()实现,计算如下:
// 区间在[MIN, MAX)的随机数
public class Main {
public static void main(String[] args) {
double x = Math.random(); // x的范围是[0,1)
double min = 10;
double max = 50;
double y = x * (max - min) + min; // y的范围是[10,50)
long n = (long) y; // n的范围是[10,50)的整数
System.out.println(y);
System.out.println(n);
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KTzUzKD5-1676946013325)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
运行结果1.
26.98111293356738
26
运行结果2.
25.67075129984012
25
运行结果3.
11.507725121648168
11
注:
Java标准库还提供了一个StrictMath,它提供了和Math几乎一模一样的方法。这两个类的区别在于,由于浮点数计算存在误差,不同的平台(例如x86和ARM)计算的结果可能不一致(指误差不同),因此,StrictMath保证所有平台计算结果都是完全相同的,而Math会尽量针对平台优化计算速度,所以,绝大多数情况下,使用Math就足够了。
2.Random
Random用来创建伪随机数。所谓伪随机数,是指只要给定一个初始的种子,产生的随机数序列是完全一样的。
要生成一个随机数,可以使用nextInt()、nextLong()、nextFloat()、nextDouble():
Random r = new Random();
r.nextInt(); // 2071575453,每次都不一样
r.nextInt(10); // 5,生成一个[0,10)之间的int
r.nextLong(); // 8811649292570369305,每次都不一样
r.nextFloat(); // 0.54335...生成一个[0,1)之间的float
r.nextDouble(); // 0.3716...生成一个[0,1)之间的double
有童鞋问,每次运行程序,生成的随机数都是不同的,没看出伪随机数的特性来。
这是因为我们创建Random实例时,如果不给定种子,就使用系统当前时间戳作为种子,因此每次运行时,种子不同,得到的伪随机数序列就不同。
如果我们在创建Random实例时指定一个种子,就会得到完全确定的随机数序列:
import java.util.Random;
public class Main {
public static void main(String[] args) {
Random r = new Random(12345);
for (int i = 0; i < 10; i++) {
System.out.println(r.nextInt(100));
}
// 51, 80, 41, 28, 55...
}
}
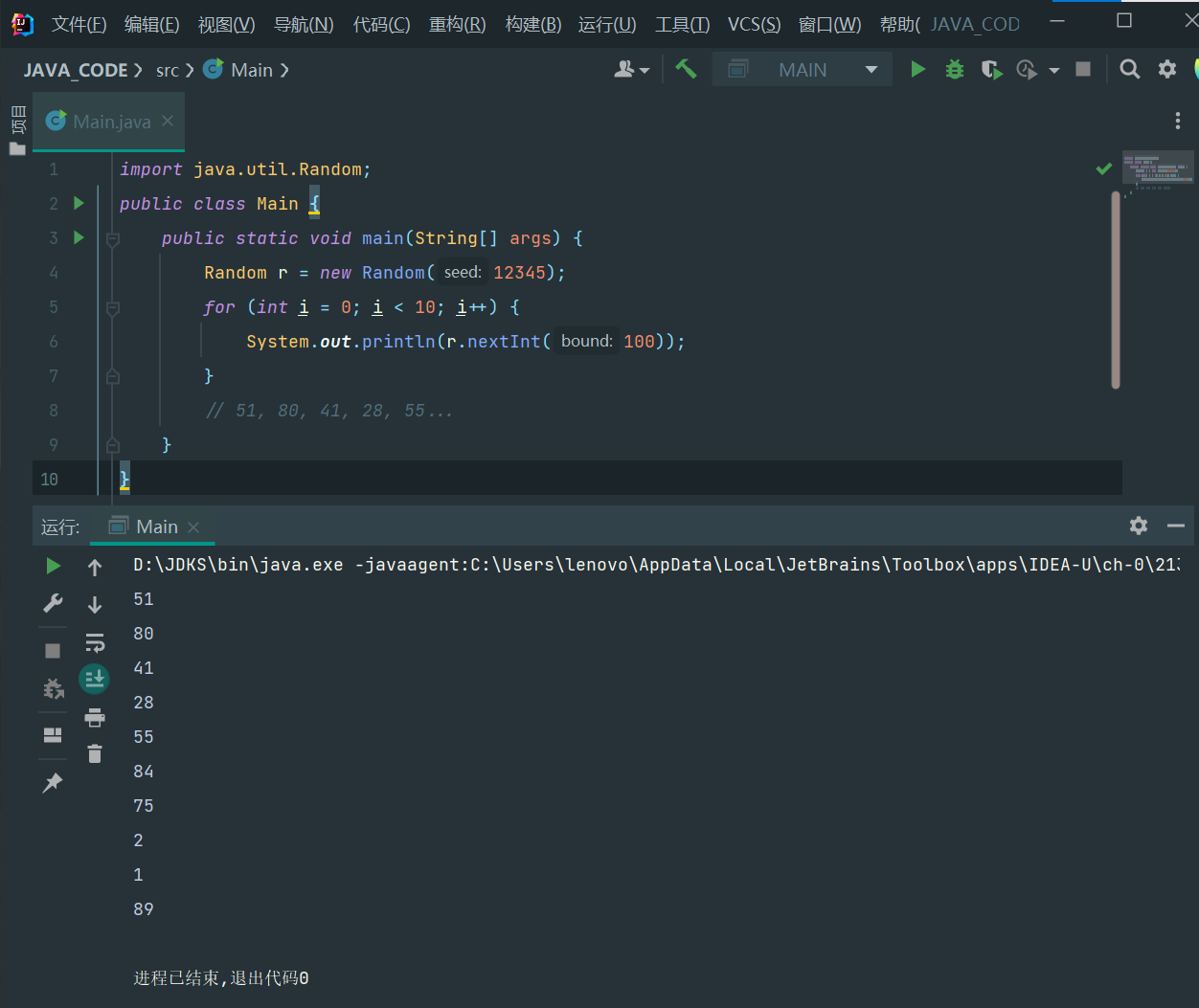
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UfzfLGGk-1676946013326)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]编辑
前面我们使用的Math.random()实际上内部调用了Random类,所以它也是伪随机数,只是我们无法指定种子。
3.SecureRandom
有伪随机数,就有真随机数。实际上真正的真随机数只能通过量子力学原理来获取,而我们想要的是一个不可预测的安全的随机数,SecureRandom就是用来创建安全的随机数的:
SecureRandom sr = new SecureRandom();
System.out.println(sr.nextInt(100));
SecureRandom无法指定种子,它使用RNG(random number generator)算法。JDK的SecureRandom实际上有多种不同的底层实现,有的使用安全随机种子加上伪随机数算法来产生安全的随机数,有的使用真正的随机数生成器。实际使用的时候,可以优先获取高强度的安全随机数生成器,如果没有提供,再使用普通等级的安全随机数生成器:
import java.util.Arrays;
import java.security.SecureRandom;
import java.security.NoSuchAlgorithmException;
public class Main {
public static void main(String[] args) {
SecureRandom sr = null;
try {
sr = SecureRandom.getInstanceStrong(); // 获取高强度安全随机数生成器
} catch (NoSuchAlgorithmException e) {
sr = new SecureRandom(); // 获取普通的安全随机数生成器
}
byte[] buffer = new byte[16];
sr.nextBytes(buffer); // 用安全随机数填充buffer
System.out.println(Arrays.toString(buffer));
}
}
SecureRandom的安全性是通过操作系统提供的安全的随机种子来生成随机数。这个种子是通过CPU的热噪声、读写磁盘的字节、网络流量等各种随机事件产生的“熵”。
在密码学中,安全的随机数非常重要。如果使用不安全的伪随机数,所有加密体系都将被攻破。因此,时刻牢记必须使用SecureRandom来产生安全的随机数。
Java提供的常用工具类有:
- Math:数学计算
- Random:生成伪随机数
- SecureRandom:生成安全的随机数
异常
一,Java的异常
在计算机程序运行的过程中,总是会出现各种各样的错误。
有一些错误是用户造成的,比如,希望用户输入一个int类型的年龄,但是用户的输入是abc:
// 假设用户输入了abc:
String s = "abc";
int n = Integer.parseInt(s); // NumberFormatException!
程序想要读写某个文件的内容,但是用户已经把它删除了:
// 用户删除了该文件:
String t = readFile("C:\\abc.txt"); // FileNotFoundException!
还有一些错误是随机出现,并且永远不可能避免的。比如:
- 网络突然断了,连接不到远程服务器;
- 内存耗尽,程序崩溃了;
- 用户点“打印”,但根本没有打印机;
- ……
所以,一个健壮的程序必须处理各种各样的错误。
所谓错误,就是程序调用某个函数的时候,如果失败了,就表示出错。
调用方如何获知调用失败的信息?有两种方法:
方法一:约定返回错误码。
例如,处理一个文件,如果返回0,表示成功,返回其他整数,表示约定的错误码:
int code = processFile("C:\\test.txt");
if (code == 0) {
// ok:
} else {
// error:
switch (code) {
case 1:
// file not found:
case 2:
// no read permission:
default:
// unknown error:
}
}
因为使用int类型的错误码,想要处理就非常麻烦。这种方式常见于底层C函数。
方法二:在语言层面上提供一个异常处理机制。
Java内置了一套异常处理机制,总是使用异常来表示错误。
异常是一种class,因此它本身带有类型信息。异常可以在任何地方抛出,但只需要在上层捕获,这样就和方法调用分离了:
try {
String s = processFile(“C:\\test.txt”);
// ok:
} catch (FileNotFoundException e) {
// file not found:
} catch (SecurityException e) {
// no read permission:
} catch (IOException e) {
// io error:
} catch (Exception e) {
// other error:
}
因为Java的异常是class,它的继承关系如下:
┌───────────┐
│ Object │
└───────────┘
▲
│
┌───────────┐
│ Throwable │
└───────────┘
▲
┌─────────┴─────────┐
│ │
┌───────────┐ ┌───────────┐
│ Error │ │ Exception │
└───────────┘ └───────────┘
▲ ▲
┌───────┘ ┌────┴──────────┐
│ │ │
┌─────────────────┐ ┌─────────────────┐┌───────────┐
│OutOfMemoryError │... │RuntimeException ││IOException│...
└─────────────────┘ └─────────────────┘└───────────┘
▲
┌───────────┴─────────────┐
│ │
┌─────────────────────┐ ┌─────────────────────────┐
│NullPointerException │ │IllegalArgumentException │...
└─────────────────────┘ └─────────────────────────┘
从继承关系可知:Throwable是异常体系的根,它继承自Object。Throwable有两个体系:Error和Exception,Error表示严重的错误,程序对此一般无能为力,例如:
OutOfMemoryError:内存耗尽NoClassDefFoundError:无法加载某个ClassStackOverflowError:栈溢出
而Exception则是运行时的错误,它可以被捕获并处理。
某些异常是应用程序逻辑处理的一部分,应该捕获并处理。例如:
NumberFormatException:数值类型的格式错误FileNotFoundException:未找到文件SocketException:读取网络失败
还有一些异常是程序逻辑编写不对造成的,应该修复程序本身。例如:
NullPointerException:对某个null的对象调用方法或字段IndexOutOfBoundsException:数组索引越界
Exception又分为两大类:
RuntimeException以及它的子类;- 非
RuntimeException(包括IOException、ReflectiveOperationException等等)
Java规定:
- 必须捕获的异常,包括
Exception及其子类,但不包括RuntimeException及其子类,这种类型的异常称为Checked Exception。 - 不需要捕获的异常,包括
Error及其子类,RuntimeException及其子类。
注意:编译器对RuntimeException及其子类不做强制捕获要求,不是指应用程序本身不应该捕获并处理RuntimeException。是否需要捕获,具体问题具体分析。
捕获异常
捕获异常使用try...catch语句,把可能发生异常的代码放到try {...}中,然后使用catch捕获对应的Exception及其子类:
// try...catch import java.io.UnsupportedEncodingException; import java.util.Arrays; Run
如果我们不捕获UnsupportedEncodingException,会出现编译失败的问题:
// try...catch import java.io.UnsupportedEncodingException; import java.util.Arrays; Run
编译器会报错,错误信息类似:unreported exception UnsupportedEncodingException; must be caught or declared to be thrown,并且准确地指出需要捕获的语句是return s.getBytes("GBK");。意思是说,像UnsupportedEncodingException这样的Checked Exception,必须被捕获。
这是因为String.getBytes(String)方法定义是:
public byte[] getBytes(String charsetName) throws UnsupportedEncodingException {
...
}
在方法定义的时候,使用throws Xxx表示该方法可能抛出的异常类型。调用方在调用的时候,必须强制捕获这些异常,否则编译器会报错。
在toGBK()方法中,因为调用了String.getBytes(String)方法,就必须捕获UnsupportedEncodingException。我们也可以不捕获它,而是在方法定义处用throws表示toGBK()方法可能会抛出UnsupportedEncodingException,就可以让toGBK()方法通过编译器检查:
// try...catch import java.io.UnsupportedEncodingException; import java.util.Arrays; Run
上述代码仍然会得到编译错误,但这一次,编译器提示的不是调用return s.getBytes("GBK");的问题,而是byte[] bs = toGBK("中文");。因为在main()方法中,调用toGBK(),没有捕获它声明的可能抛出的UnsupportedEncodingException。
修复方法是在main()方法中捕获异常并处理:
// try...catch import java.io.UnsupportedEncodingException; import java.util.Arrays; Run
可见,只要是方法声明的Checked Exception,不在调用层捕获,也必须在更高的调用层捕获。所有未捕获的异常,最终也必须在main()方法中捕获,不会出现漏写try的情况。这是由编译器保证的。main()方法也是最后捕获Exception的机会。
如果是测试代码,上面的写法就略显麻烦。如果不想写任何try代码,可以直接把main()方法定义为throws Exception:
// try...catch import java.io.UnsupportedEncodingException; import java.util.Arrays; Run
因为main()方法声明了可能抛出Exception,也就声明了可能抛出所有的Exception,因此在内部就无需捕获了。代价就是一旦发生异常,程序会立刻退出。
还有一些童鞋喜欢在toGBK()内部“消化”异常:
static byte[] toGBK(String s) {
try {
return s.getBytes("GBK");
} catch (UnsupportedEncodingException e) {
// 什么也不干
}
return null;
这种捕获后不处理的方式是非常不好的,即使真的什么也做不了,也要先把异常记录下来:
static byte[] toGBK(String s) {
try {
return s.getBytes("GBK");
} catch (UnsupportedEncodingException e) {
// 先记下来再说:
e.printStackTrace();
}
return null;
所有异常都可以调用printStackTrace()方法打印异常栈,这是一个简单有用的快速打印异常的方法。
小结
Java使用异常来表示错误,并通过try ... catch捕获异常;
Java的异常是class,并且从Throwable继承;
Error是无需捕获的严重错误,Exception是应该捕获的可处理的错误;
RuntimeException无需强制捕获,非RuntimeException(Checked Exception)需强制捕获,或者用throws声明;
不推荐捕获了异常但不进行任何处理。
二,捕获异常
在Java中,凡是可能抛出异常的语句,都可以用try ... catch捕获。把可能发生异常的语句放在try { ... }中,然后使用catch捕获对应的Exception及其子类。
1.多catch语句
可以使用多个catch语句,每个catch分别捕获对应的Exception及其子类。JVM在捕获到异常后,会从上到下匹配catch语句,匹配到某个catch后,执行catch代码块,然后不再继续匹配。
简单地说就是:多个catch语句只有一个能被执行。例如:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException e) {
System.out.println(e);
} catch (NumberFormatException e) {
System.out.println(e);
}
}
存在多个catch的时候,catch的顺序非常重要:子类必须写在前面。例如:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException e) {
System.out.println("IO error");
} catch (UnsupportedEncodingException e) { // 永远捕获不到
System.out.println("Bad encoding");
}
}
对于上面的代码,UnsupportedEncodingException异常是永远捕获不到的,因为它是IOException的子类。当抛出UnsupportedEncodingException异常时,会被catch (IOException e) { ... }捕获并执行。
因此,正确的写法是把子类放到前面:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (UnsupportedEncodingException e) {
System.out.println("Bad encoding");
} catch (IOException e) {
System.out.println("IO error");
}
}
2.finally语句
无论是否有异常发生,如果我们都希望执行一些语句,例如清理工作,怎么写?
可以把执行语句写若干遍:正常执行的放到try中,每个catch再写一遍。例如:
public static void main(String[] args) {
try {
process1();
process2();
process3();
System.out.println("END");
} catch (UnsupportedEncodingException e) {
System.out.println("Bad encoding");
System.out.println("END");
} catch (IOException e) {
System.out.println("IO error");
System.out.println("END");
}
}
上述代码无论是否发生异常,都会执行System.out.println("END");这条语句。
那么如何消除这些重复的代码?Java的try ... catch机制还提供了finally语句,finally语句块保证有无错误都会执行。上述代码可以改写如下:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (UnsupportedEncodingException e) {
System.out.println("Bad encoding");
} catch (IOException e) {
System.out.println("IO error");
} finally {
System.out.println("END");
}
}
注意finally有几个特点:
finally语句不是必须的,可写可不写;finally总是最后执行。
如果没有发生异常,就正常执行try { ... }语句块,然后执行finally。如果发生了异常,就中断执行try { ... }语句块,然后跳转执行匹配的catch语句块,最后执行finally。
可见,finally是用来保证一些代码必须执行的。
某些情况下,可以没有catch,只使用try ... finally结构。例如:
void process(String file) throws IOException {
try {
...
} finally {
System.out.println("END");
}
}
因为方法声明了可能抛出的异常,所以可以不写catch。
3.捕获多种异常
如果某些异常的处理逻辑相同,但是异常本身不存在继承关系,那么就得编写多条catch子句:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException e) {
System.out.println("Bad input");
} catch (NumberFormatException e) {
System.out.println("Bad input");
} catch (Exception e) {
System.out.println("Unknown error");
}
}
因为处理IOException和NumberFormatException的代码是相同的,所以我们可以把它两用|合并到一起:
public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException | NumberFormatException e) { // IOException或NumberFormatException
System.out.println("Bad input");
} catch (Exception e) {
System.out.println("Unknown error");
}
}
三,抛出异常
1.异常的传播
当某个方法抛出了异常时,如果当前方法没有捕获异常,异常就会被抛到上层调用方法,直到遇到某个try ... catch被捕获为止:
public class Main {
public static void main(String[] args) {
try {
process1();
} catch (Exception e) {
e.printStackTrace();
}
}
static void process1() {
process2();
}
static void process2() {
Integer.parseInt(null); // 会抛出NumberFormatException
}
}
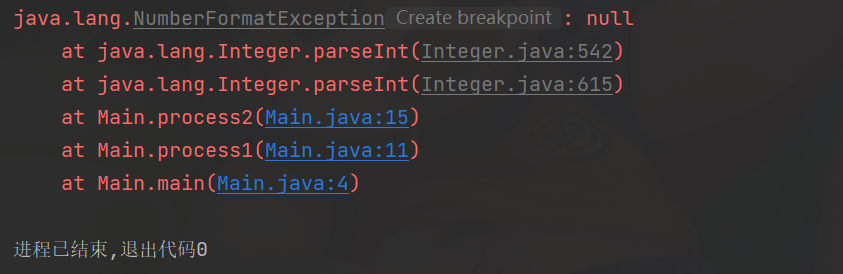
通过printStackTrace()可以打印出方法的调用栈,类似:
java.lang.NumberFormatException: null
at java.base/java.lang.Integer.parseInt(Integer.java:614)
at java.base/java.lang.Integer.parseInt(Integer.java:770)
at Main.process2(Main.java:16)
at Main.process1(Main.java:12)
at Main.main(Main.java:5)
printStackTrace()对于调试错误非常有用,上述信息表示:NumberFormatException是在java.lang.Integer.parseInt方法中被抛出的,从下往上看,调用层次依次是:
main()调用process1();process1()调用process2();process2()调用Integer.parseInt(String);Integer.parseInt(String)调用Integer.parseInt(String, int)。
查看Integer.java源码可知,抛出异常的方法代码如下:
public static int parseInt(String s, int radix) throws NumberFormatException {
if (s == null) {
throw new NumberFormatException("null");
}
...
}
并且,每层调用均给出了源代码的行号,可直接定位。
2.抛出异常
当发生错误时,例如,用户输入了非法的字符,我们就可以抛出异常。
如何抛出异常?参考Integer.parseInt()方法,抛出异常分两步:
- 创建某个
Exception的实例; - 用
throw语句抛出。
下面是一个例子:
void process2(String s) {
if (s==null) {
NullPointerException e = new NullPointerException();
throw e;
}
}
实际上,绝大部分抛出异常的代码都会合并写成一行:
void process2(String s) {
if (s==null) {
throw new NullPointerException();
}
}
如果一个方法捕获了某个异常后,又在catch子句中抛出新的异常,就相当于把抛出的异常类型“转换”了:
void process1(String s) {
try {
process2();
} catch (NullPointerException e) {
throw new IllegalArgumentException();
}
}
void process2(String s) {
if (s==null) {
throw new NullPointerException();
}
}
当process2()抛出NullPointerException后,被process1()捕获,然后抛出IllegalArgumentException()。
如果在main()中捕获IllegalArgumentException,我们看看打印的异常栈:
public class Main {
public static void main(String[] args) {
try {
process1();
} catch (Exception e) {
e.printStackTrace();
}
}
static void process1() {
try {
process2();
} catch (NullPointerException e) {
throw new IllegalArgumentException();
}
}
static void process2() {
throw new NullPointerException();
}
}
打印出的异常栈类似:
java.lang.IllegalArgumentException
at Main.process1(Main.java:15)
at Main.main(Main.java:5)
这说明新的异常丢失了原始异常信息,我们已经看不到原始异常NullPointerException的信息了。
为了能追踪到完整的异常栈,在构造异常的时候,把原始的Exception实例传进去,新的Exception就可以持有原始Exception信息。对上述代码改进如下:
public class Main {
public static void main(String[] args) {
try {
process1();
} catch (Exception e) {
e.printStackTrace();
}
}
static void process1() {
try {
process2();
} catch (NullPointerException e) {
throw new IllegalArgumentException(e);
}
}
static void process2() {
throw new NullPointerException();
}
}
运行上述代码,打印出的异常栈类似:
java.lang.IllegalArgumentException: java.lang.NullPointerException
at Main.process1(Main.java:15)
at Main.main(Main.java:5)
Caused by: java.lang.NullPointerException
at Main.process2(Main.java:20)
at Main.process1(Main.java:13)
注意到Caused by: Xxx,说明捕获的IllegalArgumentException并不是造成问题的根源,根源在于NullPointerException,是在Main.process2()方法抛出的。
在代码中获取原始异常可以使用Throwable.getCause()方法。如果返回null,说明已经是“根异常”了。
有了完整的异常栈的信息,我们才能快速定位并修复代码的问题。
捕获到异常并再次抛出时,一定要留住原始异常,否则很难定位第一案发现场!
如果我们在try或者catch语句块中抛出异常,finally语句是否会执行?例如:
public class Main {
public static void main(String[] args) {
try {
Integer.parseInt("abc");
} catch (Exception e) {
System.out.println("catched");
throw new RuntimeException(e);
} finally {
System.out.println("finally");
}
}
}
上述代码执行结果如下:
catched
finally
Exception in thread "main" java.lang.RuntimeException: java.lang.NumberFormatException: For input string: "abc"
at Main.main(Main.java:8)
Caused by: java.lang.NumberFormatException: For input string: "abc"
at ...
第一行打印了catched,说明进入了catch语句块。第二行打印了finally,说明执行了finally语句块。
因此,在catch中抛出异常,不会影响finally的执行。JVM会先执行finally,然后抛出异常。
3.异常屏蔽
如果在执行finally语句时抛出异常,那么,catch语句的异常还能否继续抛出?例如:
public class Main {
public static void main(String[] args) {
try {
Integer.parseInt("abc");
} catch (Exception e) {
System.out.println("catched");
throw new RuntimeException(e);
} finally {
System.out.println("finally");
throw new IllegalArgumentException();
}
}
}
执行上述代码,发现异常信息如下:
catched
finally
Exception in thread "main" java.lang.IllegalArgumentException
at Main.main(Main.java:11)
这说明finally抛出异常后,原来在catch中准备抛出的异常就“消失”了,因为只能抛出一个异常。没有被抛出的异常称为“被屏蔽”的异常(Suppressed Exception)。
在极少数的情况下,我们需要获知所有的异常。如何保存所有的异常信息?方法是先用origin变量保存原始异常,然后调用Throwable.addSuppressed(),把原始异常添加进来,最后在finally抛出:
public class Main {
public static void main(String[] args) throws Exception {
Exception origin = null;
try {
System.out.println(Integer.parseInt("abc"));
} catch (Exception e) {
origin = e;
throw e;
} finally {
Exception e = new IllegalArgumentException();
if (origin != null) {
e.addSuppressed(origin);
}
throw e;
}
}
当catch和finally都抛出了异常时,虽然catch的异常被屏蔽了,但是,finally抛出的异常仍然包含了它:
Exception in thread "main" java.lang.IllegalArgumentException
at Main.main(Main.java:11)
Suppressed: java.lang.NumberFormatException: For input string: "abc"
at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.base/java.lang.Integer.parseInt(Integer.java:652)
at java.base/java.lang.Integer.parseInt(Integer.java:770)
at Main.main(Main.java:6)
通过Throwable.getSuppressed()可以获取所有的Suppressed Exception。
绝大多数情况下,在finally中不要抛出异常。因此,我们通常不需要关心Suppressed Exception。
4.提问时贴出异常
异常打印的详细的栈信息是找出问题的关键,许多初学者在提问时只贴代码,不贴异常,相当于只报案不给线索,福尔摩斯也无能为力。
四,自定义异常
Java标准库定义的常用异常包括:
Exception
│
├─ RuntimeException
│ │
│ ├─ NullPointerException
│ │
│ ├─ IndexOutOfBoundsException
│ │
│ ├─ SecurityException
│ │
│ └─ IllegalArgumentException
│ │
│ └─ NumberFormatException
│
├─ IOException
│ │
│ ├─ UnsupportedCharsetException
│ │
│ ├─ FileNotFoundException
│ │
│ └─ SocketException
│
├─ ParseException
│
├─ GeneralSecurityException
│
├─ SQLException
│
└─ TimeoutException
当我们在代码中需要抛出异常时,尽量使用JDK已定义的异常类型。例如,参数检查不合法,应该抛出IllegalArgumentException:
static void process1(int age) {
if (age <= 0) {
throw new IllegalArgumentException();
}
}
在一个大型项目中,可以自定义新的异常类型,但是,保持一个合理的异常继承体系是非常重要的。
一个常见的做法是自定义一个BaseException作为“根异常”,然后,派生出各种业务类型的异常。
BaseException需要从一个适合的Exception派生,通常建议从RuntimeException派生:
public class BaseException extends RuntimeException {
}
其他业务类型的异常就可以从BaseException派生:
public class UserNotFoundException extends BaseException {
}
public class LoginFailedException extends BaseException {
}
...
自定义的BaseException应该提供多个构造方法:
public class BaseException extends RuntimeException {
public BaseException() {
super();
}
public BaseException(String message, Throwable cause) {
super(message, cause);
}
public BaseException(String message) {
super(message);
}
public BaseException(Throwable cause) {
super(cause);
}
}
上述构造方法实际上都是原样照抄RuntimeException。这样,抛出异常的时候,就可以选择合适的构造方法。通过IDE可以根据父类快速生成子类的构造方法。
五,NullPointerException
在所有的RuntimeException异常中,Java程序员最熟悉的恐怕就是NullPointerException了。
NullPointerException即空指针异常,俗称NPE。如果一个对象为null,调用其方法或访问其字段就会产生NullPointerException,这个异常通常是由JVM抛出的,例如:
public class Main {
public static void main(String[] args) {
String s = null;
System.out.println(s.toLowerCase());
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BiO7djum-1676946013327)(C:\Users\28955\AppData\Roaming\Typora\typora-user-images\image-20230112211009895.png)]
指针这个概念实际上源自C语言,Java语言中并无指针。我们定义的变量实际上是引用,Null Pointer更确切地说是Null Reference,不过两者区别不大。
1.处理NullPointerException
如果遇到NullPointerException,我们应该如何处理?首先,必须明确,NullPointerException是一种代码逻辑错误,遇到NullPointerException,遵循原则是早暴露,早修复,严禁使用catch来隐藏这种编码错误:
// 错误示例: 捕获NullPointerException
try {
transferMoney(from, to, amount);
} catch (NullPointerException e) {
}
好的编码习惯可以极大地降低NullPointerException的产生,例如:
成员变量在定义时初始化:
public class Person {
private String name = "";
}
使用空字符串""而不是默认的null可避免很多NullPointerException,编写业务逻辑时,用空字符串""表示未填写比null安全得多。
返回空字符串""、空数组而不是null:
public String[] readLinesFromFile(String file) {
if (getFileSize(file) == 0) {
// 返回空数组而不是null:
return new String[0];
}
...
}
这样可以使得调用方无需检查结果是否为null。
如果调用方一定要根据null判断,比如返回null表示文件不存在,那么考虑返回Optional<T>:
public Optional<String> readFromFile(String file) {
if (!fileExist(file)) {
return Optional.empty();
}
...
}
这样调用方必须通过Optional.isPresent()判断是否有结果。
2.定位NullPointerException
如果产生了NullPointerException,例如,调用a.b.c.x()时产生了NullPointerException,原因可能是:
a是null;a.b是null;a.b.c是null;
确定到底是哪个对象是null以前只能打印这样的日志:
System.out.println(a);
System.out.println(a.b);
System.out.println(a.b.c);
从Java 14开始,如果产生了NullPointerException,JVM可以给出详细的信息告诉我们null对象到底是谁。我们来看例子:
public class Main {
public static void main(String[] args) {
Person p = new Person();
System.out.println(p.address.city.toLowerCase());
}
}
class Person {
String[] name = new String[2];
Address address = new Address();
}
class Address {
String city;
String street;
String zipcode;
}
可以在NullPointerException的详细信息中看到类似... because "<local1>.address.city" is null,意思是city字段为null,这样我们就能快速定位问题所在。
这种增强的NullPointerException详细信息是Java 14新增的功能,但默认是关闭的,我们可以给JVM添加一个-XX:+ShowCodeDetailsInExceptionMessages参数启用它:
java -XX:+ShowCodeDetailsInExceptionMessages Main.java
小结
NullPointerException是Java代码常见的逻辑错误,应当早暴露,早修复;
可以启用Java 14的增强异常信息来查看NullPointerException的详细错误信息。
六,断言
断言(Assertion)是一种调试程序的方式。在Java中,使用assert关键字来实现断言。
我们先看一个例子:
public static void main(String[] args) {
double x = Math.abs(-123.45);
assert x >= 0;
System.out.println(x);
}
语句assert x >= 0;即为断言,断言条件x >= 0预期为true。如果计算结果为false,则断言失败,抛出AssertionError。
使用assert语句时,还可以添加一个可选的断言消息:
assert x >= 0 : "x must >= 0";
这样,断言失败的时候,AssertionError会带上消息x must >= 0,更加便于调试。
Java断言的特点是:断言失败时会抛出AssertionError,导致程序结束退出。因此,断言不能用于可恢复的程序错误,只应该用于开发和测试阶段。
对于可恢复的程序错误,不应该使用断言。例如:
void sort(int[] arr) {
assert arr != null;
}
应该抛出异常并在上层捕获:
void sort(int[] arr) {
if (arr == null) {
throw new IllegalArgumentException("array cannot be null");
}
}
当我们在程序中使用assert时,例如,一个简单的断言:
断言x必须大于0,实际上x为-1,断言肯定失败。执行上述代码,发现程序并未抛出AssertionError,而是正常打印了x的值。
这是怎么肥四?为什么assert语句不起作用?
这是因为JVM默认关闭断言指令,即遇到assert语句就自动忽略了,不执行。
要执行assert语句,必须给Java虚拟机传递-enableassertions(可简写为-ea)参数启用断言。所以,上述程序必须在命令行下运行才有效果:
$ java -ea Main.java
Exception in thread "main" java.lang.AssertionError
at Main.main(Main.java:5)
还可以有选择地对特定地类启用断言,命令行参数是:-ea:com.itranswarp.sample.Main,表示只对com.itranswarp.sample.Main这个类启用断言。
或者对特定地包启用断言,命令行参数是:-ea:com.itranswarp.sample...(注意结尾有3个.),表示对com.itranswarp.sample这个包启动断言。
实际开发中,很少使用断言。更好的方法是编写单元测试,后续我们会讲解JUnit的使用。
小结
断言是一种调试方式,断言失败会抛出AssertionError,只能在开发和测试阶段启用断言;
对可恢复的错误不能使用断言,而应该抛出异常;
断言很少被使用,更好的方法是编写单元测试。
七,使用JDK Logging
在编写程序的过程中,发现程序运行结果与预期不符,怎么办?当然是用System.out.println()打印出执行过程中的某些变量,观察每一步的结果与代码逻辑是否符合,然后有针对性地修改代码。
代码改好了怎么办?当然是删除没有用的System.out.println()语句了。
如果改代码又改出问题怎么办?再加上System.out.println()。
反复这么搞几次,很快大家就发现使用System.out.println()非常麻烦。
怎么办?
解决方法是使用日志。
那什么是日志?日志就是Logging,它的目的是为了取代System.out.println()。
输出日志,而不是用System.out.println(),有以下几个好处:
- 可以设置输出样式,避免自己每次都写
"ERROR: " + var; - 可以设置输出级别,禁止某些级别输出。例如,只输出错误日志;
- 可以被重定向到文件,这样可以在程序运行结束后查看日志;
- 可以按包名控制日志级别,只输出某些包打的日志;
- 可以……
总之就是好处很多啦。
那如何使用日志?
因为Java标准库内置了日志包java.util.logging,我们可以直接用。先看一个简单的例子:
import java.util.logging.Logger;
public class Hello {
public static void main(String[] args) {
Logger logger = Logger.getGlobal();
logger.info("start process...");
logger.warning("memory is running out...");
logger.fine("ignored.");
logger.severe("process will be terminated...");
}
}
对比可见,使用日志最大的好处是,它自动打印了时间、调用类、调用方法等很多有用的信息。
再仔细观察发现,4条日志,只打印了3条,logger.fine()没有打印。这是因为,日志的输出可以设定级别。JDK的Logging定义了7个日志级别,从严重到普通:
- SEVERE
- WARNING
- INFO
- CONFIG
- FINE
- FINER
- FINEST
因为默认级别是INFO,因此,INFO级别以下的日志,不会被打印出来。使用日志级别的好处在于,调整级别,就可以屏蔽掉很多调试相关的日志输出。
使用Java标准库内置的Logging有以下局限:
Logging系统在JVM启动时读取配置文件并完成初始化,一旦开始运行main()方法,就无法修改配置;
配置不太方便,需要在JVM启动时传递参数-Djava.util.logging.config.file=<config-file-name>。
因此,Java标准库内置的Logging使用并不是非常广泛。更方便的日志系统我们稍后介绍。
练习
使用logger.severe()打印异常:
import java.io.UnsupportedEncodingException;
import java.util.logging.Logger;
public class Main {
public static void main(String[] args) {
Logger logger = Logger.getLogger(Main.class.getName());
logger.info("Start process...");
try {
"".getBytes("invalidCharsetName");
} catch (UnsupportedEncodingException e) {
// TODO: 使用logger.severe()打印异常
}
logger.info("Process end.");
}
}
小结
日志是为了替代System.out.println(),可以定义格式,重定向到文件等;
日志可以存档,便于追踪问题;
日志记录可以按级别分类,便于打开或关闭某些级别;
可以根据配置文件调整日志,无需修改代码;
Java标准库提供了java.util.logging来实现日志功能。
八,使用Log4j
前面介绍了Commons Logging,可以作为“日志接口”来使用。而真正的“日志实现”可以使用Log4j。
Log4j是一种非常流行的日志框架,最新版本是2.x。
Log4j是一个组件化设计的日志系统,它的架构大致如下:
log.info("User signed in.");
│
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
├──>│ Appender │───>│ Filter │───>│ Layout │───>│ Console │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘
│
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
├──>│ Appender │───>│ Filter │───>│ Layout │───>│ File │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘
│
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
└──>│ Appender │───>│ Filter │───>│ Layout │───>│ Socket │
└──────────┘ └──────────┘ └──────────┘ └──────────┘
当我们使用Log4j输出一条日志时,Log4j自动通过不同的Appender把同一条日志输出到不同的目的地。例如:
- console:输出到屏幕;
- file:输出到文件;
- socket:通过网络输出到远程计算机;
- jdbc:输出到数据库
在输出日志的过程中,通过Filter来过滤哪些log需要被输出,哪些log不需要被输出。例如,仅输出ERROR级别的日志。
最后,通过Layout来格式化日志信息,例如,自动添加日期、时间、方法名称等信息。
上述结构虽然复杂,但我们在实际使用的时候,并不需要关心Log4j的API,而是通过配置文件来配置它。
以XML配置为例,使用Log4j的时候,我们把一个log4j2.xml的文件放到classpath下就可以让Log4j读取配置文件并按照我们的配置来输出日志。下面是一个配置文件的例子:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration>
<Properties>
<!-- 定义日志格式 -->
<Property name="log.pattern">%d{MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36}%n%msg%n%n</Property>
<!-- 定义文件名变量 -->
<Property name="file.err.filename">log/err.log</Property>
<Property name="file.err.pattern">log/err.%i.log.gz</Property>
</Properties>
<!-- 定义Appender,即目的地 -->
<Appenders>
<!-- 定义输出到屏幕 -->
<Console name="console" target="SYSTEM_OUT">
<!-- 日志格式引用上面定义的log.pattern -->
<PatternLayout pattern="${log.pattern}" />
</Console>
<!-- 定义输出到文件,文件名引用上面定义的file.err.filename -->
<RollingFile name="err" bufferedIO="true" fileName="${file.err.filename}" filePattern="${file.err.pattern}">
<PatternLayout pattern="${log.pattern}" />
<Policies>
<!-- 根据文件大小自动切割日志 -->
<SizeBasedTriggeringPolicy size="1 MB" />
</Policies>
<!-- 保留最近10份 -->
<DefaultRolloverStrategy max="10" />
</RollingFile>
</Appenders>
<Loggers>
<Root level="info">
<!-- 对info级别的日志,输出到console -->
<AppenderRef ref="console" level="info" />
<!-- 对error级别的日志,输出到err,即上面定义的RollingFile -->
<AppenderRef ref="err" level="error" />
</Root>
</Loggers>
</Configuration>
虽然配置Log4j比较繁琐,但一旦配置完成,使用起来就非常方便。对上面的配置文件,凡是INFO级别的日志,会自动输出到屏幕,而ERROR级别的日志,不但会输出到屏幕,还会同时输出到文件。并且,一旦日志文件达到指定大小(1MB),Log4j就会自动切割新的日志文件,并最多保留10份。
有了配置文件还不够,因为Log4j也是一个第三方库,我们需要从这里下载Log4j,解压后,把以下3个jar包放到classpath中:
- log4j-api-2.x.jar
- log4j-core-2.x.jar
- log4j-jcl-2.x.jar
因为Commons Logging会自动发现并使用Log4j,所以,把上一节下载的commons-logging-1.2.jar也放到classpath中。
要打印日志,只需要按Commons Logging的写法写,不需要改动任何代码,就可以得到Log4j的日志输出,类似:
03-03 12:09:45.880 [main] INFO com.itranswarp.learnjava.Main
Start process...
最佳实践
在开发阶段,始终使用Commons Logging接口来写入日志,并且开发阶段无需引入Log4j。如果需要把日志写入文件, 只需要把正确的配置文件和Log4j相关的jar包放入classpath,就可以自动把日志切换成使用Log4j写入,无需修改任何代码。
小结
通过Commons Logging实现日志,不需要修改代码即可使用Log4j;
使用Log4j只需要把log4j2.xml和相关jar放入classpath;
如果要更换Log4j,只需要移除log4j2.xml和相关jar;
只有扩展Log4j时,才需要引用Log4j的接口(例如,将日志加密写入数据库的功能,需要自己开发)。
九,使用SLF4J和Logback
前面介绍了Commons Logging和Log4j这一对好基友,它们一个负责充当日志API,一个负责实现日志底层,搭配使用非常便于开发。
有的童鞋可能还听说过SLF4J和Logback。这两个东东看上去也像日志,它们又是啥?
其实SLF4J类似于Commons Logging,也是一个日志接口,而Logback类似于Log4j,是一个日志的实现。
为什么有了Commons Logging和Log4j,又会蹦出来SLF4J和Logback?这是因为Java有着非常悠久的开源历史,不但OpenJDK本身是开源的,而且我们用到的第三方库,几乎全部都是开源的。开源生态丰富的一个特定就是,同一个功能,可以找到若干种互相竞争的开源库。
因为对Commons Logging的接口不满意,有人就搞了SLF4J。因为对Log4j的性能不满意,有人就搞了Logback。
我们先来看看SLF4J对Commons Logging的接口有何改进。在Commons Logging中,我们要打印日志,有时候得这么写:
int score = 99;
p.setScore(score);
log.info("Set score " + score + " for Person " + p.getName() + " ok.");
拼字符串是一个非常麻烦的事情,所以SLF4J的日志接口改进成这样了:
int score = 99;
p.setScore(score);
logger.info("Set score {} for Person {} ok.", score, p.getName());
我们靠猜也能猜出来,SLF4J的日志接口传入的是一个带占位符的字符串,用后面的变量自动替换占位符,所以看起来更加自然。
如何使用SLF4J?它的接口实际上和Commons Logging几乎一模一样:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
class Main {
final Logger logger = LoggerFactory.getLogger(getClass());
}
对比一下Commons Logging和SLF4J的接口:
| Commons Logging | SLF4J |
|---|---|
| org.apache.commons.logging.Log | org.slf4j.Logger |
| org.apache.commons.logging.LogFactory | org.slf4j.LoggerFactory |
不同之处就是Log变成了Logger,LogFactory变成了LoggerFactory。
使用SLF4J和Logback和前面讲到的使用Commons Logging加Log4j是类似的,先分别下载SLF4J和Logback,然后把以下jar包放到classpath下:
- slf4j-api-1.7.x.jar
- logback-classic-1.2.x.jar
- logback-core-1.2.x.jar
然后使用SLF4J的Logger和LoggerFactory即可。和Log4j类似,我们仍然需要一个Logback的配置文件,把logback.xml放到classpath下,配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
<file>log/output.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.FixedWindowRollingPolicy">
<fileNamePattern>log/output.log.%i</fileNamePattern>
</rollingPolicy>
<triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy">
<MaxFileSize>1MB</MaxFileSize>
</triggeringPolicy>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
<appender-ref ref="FILE" />
</root>
</configuration>
运行即可获得类似如下的输出:
13:15:25.328 [main] INFO com.itranswarp.learnjava.Main - Start process...
从目前的趋势来看,越来越多的开源项目从Commons Logging加Log4j转向了SLF4J加Logback。
反射
什么是反射?
反射就是Reflection,Java的反射是指程序在运行期可以拿到一个对象的所有信息。
正常情况下,如果我们要调用一个对象的方法,或者访问一个对象的字段,通常会传入对象实例:
// Main.java
import com.itranswarp.learnjava.Person;
public class Main {
String getFullName(Person p) {
return p.getFirstName() + " " + p.getLastName();
}
}
但是,如果不能获得Person类,只有一个Object实例,比如这样:
String getFullName(Object obj) {
return ???
}
怎么办?有童鞋会说:强制转型啊!
String getFullName(Object obj) {
Person p = (Person) obj;
return p.getFirstName() + " " + p.getLastName();
}
强制转型的时候,你会发现一个问题:编译上面的代码,仍然需要引用Person类。不然,去掉import语句,你看能不能编译通过?
所以,反射是为了解决在运行期,对某个实例一无所知的情况下,如何调用其方法。
一,Class类
除了int等基本类型外,Java的其他类型全部都是class(包括interface)。例如:
StringObjectRunnableException- …
仔细思考,我们可以得出结论:class(包括interface)的本质是数据类型(Type)。无继承关系的数据类型无法赋值:
Number n = new Double(123.456); // OK
String s = new Double(123.456); // compile error!
而class是由JVM在执行过程中动态加载的。JVM在第一次读取到一种class类型时,将其加载进内存。
每加载一种class,JVM就为其创建一个Class类型的实例,并关联起来。注意:这里的Class类型是一个名叫Class的class。它长这样:
public final class Class {
private Class() {}
}
以String类为例,当JVM加载String类时,它首先读取String.class文件到内存,然后,为String类创建一个Class实例并关联起来:
Class cls = new Class(String);
这个Class实例是JVM内部创建的,如果我们查看JDK源码,可以发现Class类的构造方法是private,只有JVM能创建Class实例,我们自己的Java程序是无法创建Class实例的。
所以,JVM持有的每个Class实例都指向一个数据类型(class或interface):
┌───────────────────────────┐
│ Class Instance │──────> String
├───────────────────────────┤
│name = "java.lang.String" │
└───────────────────────────┘
┌───────────────────────────┐
│ Class Instance │──────> Random
├───────────────────────────┤
│name = "java.util.Random" │
└───────────────────────────┘
┌───────────────────────────┐
│ Class Instance │──────> Runnable
├───────────────────────────┤
│name = "java.lang.Runnable"│
└───────────────────────────┘
一个Class实例包含了该class的所有完整信息:
┌───────────────────────────┐
│ Class Instance │──────> String
├───────────────────────────┤
│name = "java.lang.String" │
├───────────────────────────┤
│package = "java.lang" │
├───────────────────────────┤
│super = "java.lang.Object" │
├───────────────────────────┤
│interface = CharSequence...│
├───────────────────────────┤
│field = value[],hash,... │
├───────────────────────────┤
│method = indexOf()... │
└───────────────────────────┘
由于JVM为每个加载的class创建了对应的Class实例,并在实例中保存了该class的所有信息,包括类名、包名、父类、实现的接口、所有方法、字段等,因此,如果获取了某个Class实例,我们就可以通过这个Class实例获取到该实例对应的class的所有信息。
这种通过Class实例获取class信息的方法称为反射(Reflection)。
如何获取一个class的Class实例?有三个方法:
方法一:直接通过一个class的静态变量class获取:
Class cls = String.class;
方法二:如果我们有一个实例变量,可以通过该实例变量提供的getClass()方法获取:
String s = "Hello";
Class cls = s.getClass();
方法三:如果知道一个class的完整类名,可以通过静态方法Class.forName()获取:
Class cls = Class.forName("java.lang.String");
因为Class实例在JVM中是唯一的,所以,上述方法获取的Class实例是同一个实例。可以用==比较两个Class实例:
Class cls1 = String.class;
String s = "Hello";
Class cls2 = s.getClass();
boolean sameClass = cls1 == cls2; // true
注意一下Class实例比较和instanceof的差别:
Integer n = new Integer(123);
boolean b1 = n instanceof Integer; // true,因为n是Integer类型
boolean b2 = n instanceof Number; // true,因为n是Number类型的子类
boolean b3 = n.getClass() == Integer.class; // true,因为n.getClass()返回Integer.class
boolean b4 = n.getClass() == Number.class; // false,因为Integer.class!=Number.class
用instanceof不但匹配指定类型,还匹配指定类型的子类。而用==判断class实例可以精确地判断数据类型,但不能作子类型比较。
通常情况下,我们应该用instanceof判断数据类型,因为面向抽象编程的时候,我们不关心具体的子类型。只有在需要精确判断一个类型是不是某个class的时候,我们才使用==判断class实例。
因为反射的目的是为了获得某个实例的信息。因此,当我们拿到某个Object实例时,我们可以通过反射获取该Object的class信息:
void printObjectInfo(Object obj) {
Class cls = obj.getClass();
}
要从Class实例获取获取的基本信息,参考下面的代码:
public class Main {
public static void main(String[] args) {
printClassInfo("".getClass());
printClassInfo(Runnable.class);
printClassInfo(java.time.Month.class);
printClassInfo(String[].class);
printClassInfo(int.class);
}
static void printClassInfo(Class cls) {
System.out.println("Class name: " + cls.getName());
System.out.println("Simple name: " + cls.getSimpleName());
if (cls.getPackage() != null) {
System.out.println("Package name: " + cls.getPackage().getName());
}
System.out.println("is interface: " + cls.isInterface());
System.out.println("is enum: " + cls.isEnum());
System.out.println("is array: " + cls.isArray());
System.out.println("is primitive: " + cls.isPrimitive());
}
}
注意到数组(例如String[])也是一种类,而且不同于String.class,它的类名是[Ljava.lang.String;。此外,JVM为每一种基本类型如int也创建了Class实例,通过int.class访问。
如果获取到了一个Class实例,我们就可以通过该Class实例来创建对应类型的实例:
// 获取String的Class实例:
Class cls = String.class;
// 创建一个String实例:
String s = (String) cls.newInstance();
上述代码相当于new String()。通过Class.newInstance()可以创建类实例,它的局限是:只能调用public的无参数构造方法。带参数的构造方法,或者非public的构造方法都无法通过Class.newInstance()被调用。
1.动态加载
JVM在执行Java程序的时候,并不是一次性把所有用到的class全部加载到内存,而是第一次需要用到class时才加载。例如:
// Main.java
public class Main {
public static void main(String[] args) {
if (args.length > 0) {
create(args[0]);
}
}
static void create(String name) {
Person p = new Person(name);
}
}
当执行Main.java时,由于用到了Main,因此,JVM首先会把Main.class加载到内存。然而,并不会加载Person.class,除非程序执行到create()方法,JVM发现需要加载Person类时,才会首次加载Person.class。如果没有执行create()方法,那么Person.class根本就不会被加载。
这就是JVM动态加载class的特性。
动态加载class的特性对于Java程序非常重要。利用JVM动态加载class的特性,我们才能在运行期根据条件加载不同的实现类。例如,Commons Logging总是优先使用Log4j,只有当Log4j不存在时,才使用JDK的logging。利用JVM动态加载特性,大致的实现代码如下:
// Commons Logging优先使用Log4j:
LogFactory factory = null;
if (isClassPresent("org.apache.logging.log4j.Logger")) {
factory = createLog4j();
} else {
factory = createJdkLog();
}
boolean isClassPresent(String name) {
try {
Class.forName(name);
return true;
} catch (Exception e) {
return false;
}
}
这就是为什么我们只需要把Log4j的jar包放到classpath中,Commons Logging就会自动使用Log4j的原因。
2.小结
JVM为每个加载的class及interface创建了对应的Class实例来保存class及interface的所有信息;
获取一个class对应的Class实例后,就可以获取该class的所有信息;
通过Class实例获取class信息的方法称为反射(Reflection);
JVM总是动态加载class,可以在运行期根据条件来控制加载class。
二,访问字段
对任意的一个Object实例,只要我们获取了它的Class,就可以获取它的一切信息。
我们先看看如何通过Class实例获取字段信息。Class类提供了以下几个方法来获取字段:
- Field getField(name):根据字段名获取某个public的field(包括父类)
- Field getDeclaredField(name):根据字段名获取当前类的某个field(不包括父类)
- Field[] getFields():获取所有public的field(包括父类)
- Field[] getDeclaredFields():获取当前类的所有field(不包括父类)
我们来看一下示例代码:
// reflection Run
上述代码首先获取Student的Class实例,然后,分别获取public字段、继承的public字段以及private字段,打印出的Field类似:
public int Student.score
public java.lang.String Person.name
private int Student.grade
一个Field对象包含了一个字段的所有信息:
getName():返回字段名称,例如,"name";getType():返回字段类型,也是一个Class实例,例如,String.class;getModifiers():返回字段的修饰符,它是一个int,不同的bit表示不同的含义。
以String类的value字段为例,它的定义是:
public final class String {
private final byte[] value;
}
我们用反射获取该字段的信息,代码如下:
Field f = String.class.getDeclaredField("value");
f.getName(); // "value"
f.getType(); // class [B 表示byte[]类型
int m = f.getModifiers();
Modifier.isFinal(m); // true
Modifier.isPublic(m); // false
Modifier.isProtected(m); // false
Modifier.isPrivate(m); // true
Modifier.isStatic(m); // false
1.获取字段值
利用反射拿到字段的一个Field实例只是第一步,我们还可以拿到一个实例对应的该字段的值。
例如,对于一个Person实例,我们可以先拿到name字段对应的Field,再获取这个实例的name字段的值:
// reflection
import java.lang.reflect.Field;
public class Main {
public static void main(String[] args) throws Exception {
Object p = new Person("Xiao Ming");
Class c = p.getClass();
Field f = c.getDeclaredField("name");
Object value = f.get(p);
System.out.println(value); // "Xiao Ming"
}
}
class Person {
private String name;
public Person(String name) {
this.name = name;
}
}
上述代码先获取Class实例,再获取Field实例,然后,用Field.get(Object)获取指定实例的指定字段的值。
运行代码,如果不出意外,会得到一个IllegalAccessException,这是因为name被定义为一个private字段,正常情况下,Main类无法访问Person类的private字段。要修复错误,可以将private改为public,或者,在调用Object value = f.get(p);前,先写一句:
f.setAccessible(true);
调用Field.setAccessible(true)的意思是,别管这个字段是不是public,一律允许访问。
可以试着加上上述语句,再运行代码,就可以打印出private字段的值。
有童鞋会问:如果使用反射可以获取private字段的值,那么类的封装还有什么意义?
答案是正常情况下,我们总是通过p.name来访问Person的name字段,编译器会根据public、protected和private决定是否允许访问字段,这样就达到了数据封装的目的。
而反射是一种非常规的用法,使用反射,首先代码非常繁琐,其次,它更多地是给工具或者底层框架来使用,目的是在不知道目标实例任何信息的情况下,获取特定字段的值。
此外,setAccessible(true)可能会失败。如果JVM运行期存在SecurityManager,那么它会根据规则进行检查,有可能阻止setAccessible(true)。例如,某个SecurityManager可能不允许对java和javax开头的package的类调用setAccessible(true),这样可以保证JVM核心库的安全。
2.设置字段值
通过Field实例既然可以获取到指定实例的字段值,自然也可以设置字段的值。
设置字段值是通过Field.set(Object, Object)实现的,其中第一个Object参数是指定的实例,第二个Object参数是待修改的值。示例代码如下:
// reflection
import java.lang.reflect.Field;
public class Main {
public static void main(String[] args) throws Exception {
Person p = new Person("Xiao Ming");
System.out.println(p.getName()); // "Xiao Ming"
Class c = p.getClass();
Field f = c.getDeclaredField("name");
f.setAccessible(true);
f.set(p, "Xiao Hong");
System.out.println(p.getName()); // "Xiao Hong"
}
}
class Person {
private String name;
public Person(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
}

运行上述代码,打印的name字段从Xiao Ming变成了Xiao Hong,说明通过反射可以直接修改字段的值。
同样的,修改非public字段,需要首先调用setAccessible(true)。
3.小结
Java的反射API提供的Field类封装了字段的所有信息:
通过Class实例的方法可以获取Field实例:getField(),getFields(),getDeclaredField(),getDeclaredFields();
通过Field实例可以获取字段信息:getName(),getType(),getModifiers();
通过Field实例可以读取或设置某个对象的字段,如果存在访问限制,要首先调用setAccessible(true)来访问非public字段。
通过反射读写字段是一种非常规方法,它会破坏对象的封装。
三,调用方法
我们已经能通过Class实例获取所有Field对象,同样的,可以通过Class实例获取所有Method信息。Class类提供了以下几个方法来获取Method:
Method getMethod(name, Class...):获取某个public的Method(包括父类)Method getDeclaredMethod(name, Class...):获取当前类的某个Method(不包括父类)Method[] getMethods():获取所有public的Method(包括父类)Method[] getDeclaredMethods():获取当前类的所有Method(不包括父类)
我们来看一下示例代码:
// reflection
public class Main {
public static void main(String[] args) throws Exception {
Class stdClass = Student.class;
// 获取public方法getScore,参数为String:
System.out.println(stdClass.getMethod("getScore", String.class));
// 获取继承的public方法getName,无参数:
System.out.println(stdClass.getMethod("getName"));
// 获取private方法getGrade,参数为int:
System.out.println(stdClass.getDeclaredMethod("getGrade", int.class));
}
}
class Student extends Person {
public int getScore(String type) {
return 99;
}
private int getGrade(int year) {
return 1;
}
}
class Person {
public String getName() {
return "Person";
}
}
上述代码首先获取Student的Class实例,然后,分别获取public方法、继承的public方法以及private方法,打印出的Method类似:
public int Student.getScore(java.lang.String)
public java.lang.String Person.getName()
private int Student.getGrade(int)
一个Method对象包含一个方法的所有信息:
getName():返回方法名称,例如:"getScore";getReturnType():返回方法返回值类型,也是一个Class实例,例如:String.class;getParameterTypes():返回方法的参数类型,是一个Class数组,例如:{String.class, int.class};getModifiers():返回方法的修饰符,它是一个int,不同的bit表示不同的含义。
1.调用方法
当我们获取到一个Method对象时,就可以对它进行调用。我们以下面的代码为例:
String s = "Hello world";
String r = s.substring(6); // "world"
如果用反射来调用substring方法,需要以下代码:
// reflection
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws Exception {
// String对象:
String s = "Hello world";
// 获取String substring(int)方法,参数为int:
Method m = String.class.getMethod("substring", int.class);
// 在s对象上调用该方法并获取结果:
String r = (String) m.invoke(s, 6);
// 打印调用结果:
System.out.println(r);
}
}
注意到substring()有两个重载方法,我们获取的是String substring(int)这个方法。思考一下如何获取String substring(int, int)方法。
对Method实例调用invoke就相当于调用该方法,invoke的第一个参数是对象实例,即在哪个实例上调用该方法,后面的可变参数要与方法参数一致,否则将报错。
2.调用静态方法
如果获取到的Method表示一个静态方法,调用静态方法时,由于无需指定实例对象,所以invoke方法传入的第一个参数永远为null。我们以Integer.parseInt(String)为例:
// reflection
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws Exception {
// 获取Integer.parseInt(String)方法,参数为String:
Method m = Integer.class.getMethod("parseInt", String.class);
// 调用该静态方法并获取结果:
Integer n = (Integer) m.invoke(null, "12345");
// 打印调用结果:
System.out.println(n);
}
}
3.调用非public方法
和Field类似,对于非public方法,我们虽然可以通过Class.getDeclaredMethod()获取该方法实例,但直接对其调用将得到一个IllegalAccessException。为了调用非public方法,我们通过Method.setAccessible(true)允许其调用:
// reflection
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws Exception {
Person p = new Person();
Method m = p.getClass().getDeclaredMethod("setName", String.class);
m.setAccessible(true);
m.invoke(p, "Bob");
System.out.println(p.name);
}
}
class Person {
String name;
private void setName(String name) {
this.name = name;
}
}
此外,setAccessible(true)可能会失败。如果JVM运行期存在SecurityManager,那么它会根据规则进行检查,有可能阻止setAccessible(true)。例如,某个SecurityManager可能不允许对java和javax开头的package的类调用setAccessible(true),这样可以保证JVM核心库的安全。
4.多态
我们来考察这样一种情况:一个Person类定义了hello()方法,并且它的子类Student也覆写了hello()方法,那么,从Person.class获取的Method,作用于Student实例时,调用的方法到底是哪个?
// reflection
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws Exception {
// 获取Person的hello方法:
Method h = Person.class.getMethod("hello");
// 对Student实例调用hello方法:
h.invoke(new Student());
}
}
class Person {
public void hello() {
System.out.println("Person:hello");
}
}
class Student extends Person {
public void hello() {
System.out.println("Student:hello");
}
}
运行上述代码,发现打印出的是Student:hello,因此,使用反射调用方法时,仍然遵循多态原则:即总是调用实际类型的覆写方法(如果存在)。上述的反射代码:
Method m = Person.class.getMethod("hello");
m.invoke(new Student());
实际上相当于:
Person p = new Student();
p.hello();
5.小结
Java的反射API提供的Method对象封装了方法的所有信息:
通过Class实例的方法可以获取Method实例:getMethod(),getMethods(),getDeclaredMethod(),getDeclaredMethods();
通过Method实例可以获取方法信息:getName(),getReturnType(),getParameterTypes(),getModifiers();
通过Method实例可以调用某个对象的方法:Object invoke(Object instance, Object... parameters);
通过设置setAccessible(true)来访问非public方法;
通过反射调用方法时,仍然遵循多态原则。
四,调用构造方法
我们通常使用new操作符创建新的实例:
Person p = new Person();
如果通过反射来创建新的实例,可以调用Class提供的newInstance()方法:
Person p = Person.class.newInstance();
调用Class.newInstance()的局限是,它只能调用该类的public无参数构造方法。如果构造方法带有参数,或者不是public,就无法直接通过Class.newInstance()来调用。
为了调用任意的构造方法,Java的反射API提供了Constructor对象,它包含一个构造方法的所有信息,可以创建一个实例。Constructor对象和Method非常类似,不同之处仅在于它是一个构造方法,并且,调用结果总是返回实例:
import java.lang.reflect.Constructor;
public class Main {
public static void main(String[] args) throws Exception {
// 获取构造方法Integer(int):
Constructor cons1 = Integer.class.getConstructor(int.class);
// 调用构造方法:
Integer n1 = (Integer) cons1.newInstance(123);
System.out.println(n1);
// 获取构造方法Integer(String)
Constructor cons2 = Integer.class.getConstructor(String.class);
Integer n2 = (Integer) cons2.newInstance("456");
System.out.println(n2);
}
}
通过Class实例获取Constructor的方法如下:
getConstructor(Class...):获取某个public的Constructor;getDeclaredConstructor(Class...):获取某个Constructor;getConstructors():获取所有public的Constructor;getDeclaredConstructors():获取所有Constructor。
注意Constructor总是当前类定义的构造方法,和父类无关,因此不存在多态的问题。
调用非public的Constructor时,必须首先通过setAccessible(true)设置允许访问。setAccessible(true)可能会失败。
五,获取继承关系
当我们获取到某个Class对象时,实际上就获取到了一个类的类型:
Class cls = String.class; // 获取到String的Class
还可以用实例的getClass()方法获取:
String s = "";
Class cls = s.getClass(); // s是String,因此获取到String的Class
最后一种获取Class的方法是通过Class.forName(""),传入Class的完整类名获取:
Class s = Class.forName("java.lang.String");
这三种方式获取的Class实例都是同一个实例,因为JVM对每个加载的Class只创建一个Class实例来表示它的类型。
1.获取父类的Class
有了Class实例,我们还可以获取它的父类的Class:
// reflection
public class Main {
public static void main(String[] args) throws Exception {
Class i = Integer.class;
Class n = i.getSuperclass();
System.out.println(n);
Class o = n.getSuperclass();
System.out.println(o);
System.out.println(o.getSuperclass());
}
}
运行上述代码,可以看到,Integer的父类类型是Number,Number的父类是Object,Object的父类是null。除Object外,其他任何非interface的Class都必定存在一个父类类型。
2.获取interface
由于一个类可能实现一个或多个接口,通过Class我们就可以查询到实现的接口类型。例如,查询Integer实现的接口:
// reflection
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws Exception {
Class s = Integer.class;
Class[] is = s.getInterfaces();
for (Class i : is) {
System.out.println(i);
}
}
}
运行上述代码可知,Integer实现的接口有:
- java.lang.Comparable
- java.lang.constant.Constable
- java.lang.constant.ConstantDesc
要特别注意:getInterfaces()只返回当前类直接实现的接口类型,并不包括其父类实现的接口类型:
// reflection
import java.lang.reflect.Method;
public class Main {
public static void main(String[] args) throws Exception {
Class s = Integer.class.getSuperclass();
Class[] is = s.getInterfaces();
for (Class i : is) {
System.out.println(i);
}
}
}
Integer的父类是Number,Number实现的接口是java.io.Serializable。
此外,对所有interface的Class调用getSuperclass()返回的是null,获取接口的父接口要用getInterfaces():
System.out.println(java.io.DataInputStream.class.getSuperclass()); // java.io.FilterInputStream,因为DataInputStream继承自FilterInputStream
System.out.println(java.io.Closeable.class.getSuperclass()); // null,对接口调用getSuperclass()总是返回null,获取接口的父接口要用getInterfaces()
如果一个类没有实现任何interface,那么getInterfaces()返回空数组。
3.继承关系
当我们判断一个实例是否是某个类型时,正常情况下,使用instanceof操作符:
Object n = Integer.valueOf(123);
boolean isDouble = n instanceof Double; // false
boolean isInteger = n instanceof Integer; // true
boolean isNumber = n instanceof Number; // true
boolean isSerializable = n instanceof java.io.Serializable; // true
如果是两个Class实例,要判断一个向上转型是否成立,可以调用isAssignableFrom():
// Integer i = ?
Integer.class.isAssignableFrom(Integer.class); // true,因为Integer可以赋值给Integer
// Number n = ?
Number.class.isAssignableFrom(Integer.class); // true,因为Integer可以赋值给Number
// Object o = ?
Object.class.isAssignableFrom(Integer.class); // true,因为Integer可以赋值给Object
// Integer i = ?
Integer.class.isAssignableFrom(Number.class); // false,因为Number不能赋值给Integer
4.小结
通过Class对象可以获取继承关系:
Class getSuperclass():获取父类类型;Class[] getInterfaces():获取当前类实现的所有接口。
通过Class对象的isAssignableFrom()方法可以判断一个向上转型是否可以实现。
六,动态代理
我们来比较Java的class和interface的区别:
- 可以实例化
class(非abstract); - 不能实例化
interface。
所有interface类型的变量总是通过某个实例向上转型并赋值给接口类型变量的:
CharSequence cs = new StringBuilder();
有没有可能不编写实现类,直接在运行期创建某个interface的实例呢?
这是可能的,因为Java标准库提供了一种动态代理(Dynamic Proxy)的机制:可以在运行期动态创建某个interface的实例。
什么叫运行期动态创建?听起来好像很复杂。所谓动态代理,是和静态相对应的。我们来看静态代码怎么写:
定义接口:
public interface Hello {
void morning(String name);
}
编写实现类:
public class HelloWorld implements Hello {
public void morning(String name) {
System.out.println("Good morning, " + name);
}
}
创建实例,转型为接口并调用:
Hello hello = new HelloWorld();
hello.morning("Bob");
这种方式就是我们通常编写代码的方式。
还有一种方式是动态代码,我们仍然先定义了接口Hello,但是我们并不去编写实现类,而是直接通过JDK提供的一个Proxy.newProxyInstance()创建了一个Hello接口对象。这种没有实现类但是在运行期动态创建了一个接口对象的方式,我们称为动态代码。JDK提供的动态创建接口对象的方式,就叫动态代理。
一个最简单的动态代理实现如下:
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class Main {
public static void main(String[] args) {
InvocationHandler handler = new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println(method);
if (method.getName().equals("morning")) {
System.out.println("Good morning, " + args[0]);
}
return null;
}
};
Hello hello = (Hello) Proxy.newProxyInstance(
Hello.class.getClassLoader(), // 传入ClassLoader
new Class[] { Hello.class }, // 传入要实现的接口
handler); // 传入处理调用方法的InvocationHandler
hello.morning("Bob");
}
}
interface Hello {
void morning(String name);
}
在运行期动态创建一个interface实例的方法如下:
-
定义一个
InvocationHandler实例,它负责实现接口的方法调用; -
通过
Proxy.newProxyInstance()创建
interface实例,它需要3个参数:
- 使用的
ClassLoader,通常就是接口类的ClassLoader; - 需要实现的接口数组,至少需要传入一个接口进去;
- 用来处理接口方法调用的
InvocationHandler实例。
- 使用的
-
将返回的
Object强制转型为接口。
动态代理实际上是JVM在运行期动态创建class字节码并加载的过程,它并没有什么黑魔法,把上面的动态代理改写为静态实现类大概长这样:
public class HelloDynamicProxy implements Hello {
InvocationHandler handler;
public HelloDynamicProxy(InvocationHandler handler) {
this.handler = handler;
}
public void morning(String name) {
handler.invoke(
this,
Hello.class.getMethod("morning", String.class),
new Object[] { name });
}
}
其实就是JVM帮我们自动编写了一个上述类(不需要源码,可以直接生成字节码),并不存在可以直接实例化接口的黑魔法。
小结
Java标准库提供了动态代理功能,允许在运行期动态创建一个接口的实例;
动态代理是通过Proxy创建代理对象,然后将接口方法“代理”给InvocationHandler完成的。
注解
一,定义注解
Java语言使用@interface语法来定义注解(Annotation),它的格式如下:
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}
注解的参数类似无参数方法,可以用default设定一个默认值(强烈推荐)。最常用的参数应当命名为value。
1.元注解
有一些注解可以修饰其他注解,这些注解就称为元注解(meta annotation)。Java标准库已经定义了一些元注解,我们只需要使用元注解,通常不需要自己去编写元注解。
@Target
最常用的元注解是@Target。使用@Target可以定义Annotation能够被应用于源码的哪些位置:
- 类或接口:
ElementType.TYPE; - 字段:
ElementType.FIELD; - 方法:
ElementType.METHOD; - 构造方法:
ElementType.CONSTRUCTOR; - 方法参数:
ElementType.PARAMETER。
例如,定义注解@Report可用在方法上,我们必须添加一个@Target(ElementType.METHOD):
@Target(ElementType.METHOD)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}
定义注解@Report可用在方法或字段上,可以把@Target注解参数变为数组{ ElementType.METHOD, ElementType.FIELD }:
@Target({
ElementType.METHOD,
ElementType.FIELD
})
public @interface Report {
...
}
实际上@Target定义的value是ElementType[]数组,只有一个元素时,可以省略数组的写法。
@Retention
另一个重要的元注解@Retention定义了Annotation的生命周期:
- 仅编译期:
RetentionPolicy.SOURCE; - 仅class文件:
RetentionPolicy.CLASS; - 运行期:
RetentionPolicy.RUNTIME。
如果@Retention不存在,则该Annotation默认为CLASS。因为通常我们自定义的Annotation都是RUNTIME,所以,务必要加上@Retention(RetentionPolicy.RUNTIME)这个元注解:
@Retention(RetentionPolicy.RUNTIME)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}
@Repeatable
使用@Repeatable这个元注解可以定义Annotation是否可重复。这个注解应用不是特别广泛。
@Repeatable(Reports.class)
@Target(ElementType.TYPE)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}
@Target(ElementType.TYPE)
public @interface Reports {
Report[] value();
}
经过@Repeatable修饰后,在某个类型声明处,就可以添加多个@Report注解:
@Report(type=1, level="debug")
@Report(type=2, level="warning")
public class Hello {
}
@Inherited
使用@Inherited定义子类是否可继承父类定义的Annotation。@Inherited仅针对@Target(ElementType.TYPE)类型的annotation有效,并且仅针对class的继承,对interface的继承无效:
@Inherited
@Target(ElementType.TYPE)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}
在使用的时候,如果一个类用到了@Report:
@Report(type=1)
public class Person {
}
则它的子类默认也定义了该注解:
public class Student extends Person {
}
2.如何定义Annotation
我们总结一下定义Annotation的步骤:
第一步,用@interface定义注解:
public @interface Report {
}
第二步,添加参数、默认值:
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}
把最常用的参数定义为value(),推荐所有参数都尽量设置默认值。
第三步,用元注解配置注解:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}
其中,必须设置@Target和@Retention,@Retention一般设置为RUNTIME,因为我们自定义的注解通常要求在运行期读取。一般情况下,不必写@Inherited和@Repeatable。
小结
Java使用@interface定义注解:
可定义多个参数和默认值,核心参数使用value名称;
必须设置@Target来指定Annotation可以应用的范围;
应当设置@Retention(RetentionPolicy.RUNTIME)便于运行期读取该Annotation。
二,处理注解
Java的注解本身对代码逻辑没有任何影响。根据@Retention的配置:
SOURCE类型的注解在编译期就被丢掉了;CLASS类型的注解仅保存在class文件中,它们不会被加载进JVM;RUNTIME类型的注解会被加载进JVM,并且在运行期可以被程序读取。
如何使用注解完全由工具决定。SOURCE类型的注解主要由编译器使用,因此我们一般只使用,不编写。CLASS类型的注解主要由底层工具库使用,涉及到class的加载,一般我们很少用到。只有RUNTIME类型的注解不但要使用,还经常需要编写。
因此,我们只讨论如何读取RUNTIME类型的注解。
因为注解定义后也是一种class,所有的注解都继承自java.lang.annotation.Annotation,因此,读取注解,需要使用反射API。
Java提供的使用反射API读取Annotation的方法包括:
判断某个注解是否存在于Class、Field、Method或Constructor:
Class.isAnnotationPresent(Class)Field.isAnnotationPresent(Class)Method.isAnnotationPresent(Class)Constructor.isAnnotationPresent(Class)
例如:
// 判断@Report是否存在于Person类:
Person.class.isAnnotationPresent(Report.class);
使用反射API读取Annotation:
Class.getAnnotation(Class)Field.getAnnotation(Class)Method.getAnnotation(Class)Constructor.getAnnotation(Class)
例如:
// 获取Person定义的@Report注解:
Report report = Person.class.getAnnotation(Report.class);
int type = report.type();
String level = report.level();
使用反射API读取Annotation有两种方法。方法一是先判断Annotation是否存在,如果存在,就直接读取:
Class cls = Person.class;
if (cls.isAnnotationPresent(Report.class)) {
Report report = cls.getAnnotation(Report.class);
...
}
第二种方法是直接读取Annotation,如果Annotation不存在,将返回null:
Class cls = Person.class;
Report report = cls.getAnnotation(Report.class);
if (report != null) {
...
}
读取方法、字段和构造方法的Annotation和Class类似。但要读取方法参数的Annotation就比较麻烦一点,因为方法参数本身可以看成一个数组,而每个参数又可以定义多个注解,所以,一次获取方法参数的所有注解就必须用一个二维数组来表示。例如,对于以下方法定义的注解:
public void hello(@NotNull @Range(max=5) String name, @NotNull String prefix) {
}
要读取方法参数的注解,我们先用反射获取Method实例,然后读取方法参数的所有注解:
// 获取Method实例:
Method m = ...
// 获取所有参数的Annotation:
Annotation[][] annos = m.getParameterAnnotations();
// 第一个参数(索引为0)的所有Annotation:
Annotation[] annosOfName = annos[0];
for (Annotation anno : annosOfName) {
if (anno instanceof Range) { // @Range注解
Range r = (Range) anno;
}
if (anno instanceof NotNull) { // @NotNull注解
NotNull n = (NotNull) anno;
}
}
使用注解
注解如何使用,完全由程序自己决定。例如,JUnit是一个测试框架,它会自动运行所有标记为@Test的方法。
我们来看一个@Range注解,我们希望用它来定义一个String字段的规则:字段长度满足@Range的参数定义:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface Range {
int min() default 0;
int max() default 255;
}
在某个JavaBean中,我们可以使用该注解:
public class Person {
@Range(min=1, max=20)
public String name;
@Range(max=10)
public String city;
}
但是,定义了注解,本身对程序逻辑没有任何影响。我们必须自己编写代码来使用注解。这里,我们编写一个Person实例的检查方法,它可以检查Person实例的String字段长度是否满足@Range的定义:
void check(Person person) throws IllegalArgumentException, ReflectiveOperationException {
// 遍历所有Field:
for (Field field : person.getClass().getFields()) {
// 获取Field定义的@Range:
Range range = field.getAnnotation(Range.class);
// 如果@Range存在:
if (range != null) {
// 获取Field的值:
Object value = field.get(person);
// 如果值是String:
if (value instanceof String) {
String s = (String) value;
// 判断值是否满足@Range的min/max:
if (s.length() < range.min() || s.length() > range.max()) {
throw new IllegalArgumentException("Invalid field: " + field.getName());
}
}
}
}
}
这样一来,我们通过@Range注解,配合check()方法,就可以完成Person实例的检查。注意检查逻辑完全是我们自己编写的,JVM不会自动给注解添加任何额外的逻辑。
小结
可以在运行期通过反射读取RUNTIME类型的注解,注意千万不要漏写@Retention(RetentionPolicy.RUNTIME),否则运行期无法读取到该注解。
可以通过程序处理注解来实现相应的功能:
- 对JavaBean的属性值按规则进行检查;
- JUnit会自动运行
@Test标记的测试方法。
泛型
一,什么是泛型
在讲解什么是泛型之前,我们先观察Java标准库提供的ArrayList,它可以看作“可变长度”的数组,因为用起来比数组更方便。
实际上ArrayList内部就是一个Object[]数组,配合存储一个当前分配的长度,就可以充当“可变数组”:
public class ArrayList {
private Object[] array;
private int size;
public void add(Object e) {...}
public void remove(int index) {...}
public Object get(int index) {...}
}
如果用上述ArrayList存储String类型,会有这么几个缺点:
- 需要强制转型;
- 不方便,易出错。
例如,代码必须这么写:
ArrayList list = new ArrayList();
list.add("Hello");
// 获取到Object,必须强制转型为String:
String first = (String) list.get(0);
很容易出现ClassCastException,因为容易“误转型”:
list.add(new Integer(123));
// ERROR: ClassCastException:
String second = (String) list.get(1);
要解决上述问题,我们可以为String单独编写一种ArrayList:
public class StringArrayList {
private String[] array;
private int size;
public void add(String e) {...}
public void remove(int index) {...}
public String get(int index) {...}
}
这样一来,存入的必须是String,取出的也一定是String,不需要强制转型,因为编译器会强制检查放入的类型:
StringArrayList list = new StringArrayList();
list.add("Hello");
String first = list.get(0);
// 编译错误: 不允许放入非String类型:
list.add(new Integer(123));
问题暂时解决。
然而,新的问题是,如果要存储Integer,还需要为Integer单独编写一种ArrayList:
public class IntegerArrayList {
private Integer[] array;
private int size;
public void add(Integer e) {...}
public void remove(int index) {...}
public Integer get(int index) {...}
}
实际上,还需要为其他所有class单独编写一种ArrayList:
- LongArrayList
- DoubleArrayList
- PersonArrayList
- …
这是不可能的,JDK的class就有上千个,而且它还不知道其他人编写的class。
为了解决新的问题,我们必须把ArrayList变成一种模板:ArrayList<T>,代码如下:
public class ArrayList<T> {
private T[] array;
private int size;
public void add(T e) {...}
public void remove(int index) {...}
public T get(int index) {...}
}
T可以是任何class。这样一来,我们就实现了:编写一次模版,可以创建任意类型的ArrayList:
// 创建可以存储String的ArrayList:
ArrayList<String> strList = new ArrayList<String>();
// 创建可以存储Float的ArrayList:
ArrayList<Float> floatList = new ArrayList<Float>();
// 创建可以存储Person的ArrayList:
ArrayList<Person> personList = new ArrayList<Person>();
因此,泛型就是定义一种模板,例如ArrayList<T>,然后在代码中为用到的类创建对应的ArrayList<类型>:
ArrayList<String> strList = new ArrayList<String>();
由编译器针对类型作检查:
strList.add("hello"); // OK
String s = strList.get(0); // OK
strList.add(new Integer(123)); // compile error!
Integer n = strList.get(0); // compile error!
这样一来,既实现了编写一次,万能匹配,又通过编译器保证了类型安全:这就是泛型。
向上转型
在Java标准库中的ArrayList<T>实现了List<T>接口,它可以向上转型为List<T>:
public class ArrayList<T> implements List<T> {
...
}
List<String> list = new ArrayList<String>();
即类型ArrayList<T>可以向上转型为List<T>。
要特别注意:不能把ArrayList<Integer>向上转型为ArrayList<Number>或List<Number>。
这是为什么呢?假设ArrayList<Integer>可以向上转型为ArrayList<Number>,观察一下代码:
// 创建ArrayList<Integer>类型:
ArrayList<Integer> integerList = new ArrayList<Integer>();
// 添加一个Integer:
integerList.add(new Integer(123));
// “向上转型”为ArrayList<Number>:
ArrayList<Number> numberList = integerList;
// 添加一个Float,因为Float也是Number:
numberList.add(new Float(12.34));
// 从ArrayList<Integer>获取索引为1的元素(即添加的Float):
Integer n = integerList.get(1); // ClassCastException!
我们把一个ArrayList<Integer>转型为ArrayList<Number>类型后,这个ArrayList<Number>就可以接受Float类型,因为Float是Number的子类。但是,ArrayList<Number>实际上和ArrayList<Integer>是同一个对象,也就是ArrayList<Integer>类型,它不可能接受Float类型, 所以在获取Integer的时候将产生ClassCastException。
实际上,编译器为了避免这种错误,根本就不允许把ArrayList<Integer>转型为ArrayList<Number>。
ArrayList和ArrayList两者完全没有继承关系。
小结
泛型就是编写模板代码来适应任意类型;
泛型的好处是使用时不必对类型进行强制转换,它通过编译器对类型进行检查;
注意泛型的继承关系:可以把ArrayList<Integer>向上转型为List<Integer>(T不能变!),但不能把ArrayList<Integer>向上转型为ArrayList<Number>(T不能变成父类)。
二,使用泛型
使用ArrayList时,如果不定义泛型类型时,泛型类型实际上就是Object:
// 编译器警告:
List list = new ArrayList();
list.add("Hello");
list.add("World");
String first = (String) list.get(0);
String second = (String) list.get(1);
此时,只能把<T>当作Object使用,没有发挥泛型的优势。
当我们定义泛型类型<String>后,List<T>的泛型接口变为强类型List<String>:
// 无编译器警告:
List<String> list = new ArrayList<String>();
list.add("Hello");
list.add("World");
// 无强制转型:
String first = list.get(0);
String second = list.get(1);
当我们定义泛型类型<Number>后,List<T>的泛型接口变为强类型List<Number>:
List<Number> list = new ArrayList<Number>();
list.add(new Integer(123));
list.add(new Double(12.34));
Number first = list.get(0);
Number second = list.get(1);
编译器如果能自动推断出泛型类型,就可以省略后面的泛型类型。例如,对于下面的代码:
List<Number> list = new ArrayList<Number>();
编译器看到泛型类型List<Number>就可以自动推断出后面的ArrayList<T>的泛型类型必须是ArrayList<Number>,因此,可以把代码简写为:
// 可以省略后面的Number,编译器可以自动推断泛型类型:
List<Number> list = new ArrayList<>();
泛型接口
除了ArrayList<T>使用了泛型,还可以在接口中使用泛型。例如,Arrays.sort(Object[])可以对任意数组进行排序,但待排序的元素必须实现Comparable<T>这个泛型接口:
public interface Comparable<T> {
/**
* 返回负数: 当前实例比参数o小
* 返回0: 当前实例与参数o相等
* 返回正数: 当前实例比参数o大
*/
int compareTo(T o);
}
可以直接对String数组进行排序:
三,编写泛型
编写泛型类比普通类要复杂。通常来说,泛型类一般用在集合类中,例如ArrayList<T>,我们很少需要编写泛型类。
如果我们确实需要编写一个泛型类,那么,应该如何编写它?
可以按照以下步骤来编写一个泛型类。
首先,按照某种类型,例如:String,来编写类:
public class Pair {
private String first;
private String last;
public Pair(String first, String last) {
this.first = first;
this.last = last;
}
public String getFirst() {
return first;
}
public String getLast() {
return last;
}
}
然后,标记所有的特定类型,这里是String:
public class Pair {
private String first;
private String last;
public Pair(String first, String last) {
this.first = first;
this.last = last;
}
public String getFirst() {
return first;
}
public String getLast() {
return last;
}
}
最后,把特定类型String替换为T,并申明<T>:
public class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
熟练后即可直接从T开始编写。
静态方法
编写泛型类时,要特别注意,泛型类型<T>不能用于静态方法。例如:
public class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() { ... }
public T getLast() { ... }
// 对静态方法使用<T>:
public static Pair<T> create(T first, T last) {
return new Pair<T>(first, last);
}
}
上述代码会导致编译错误,我们无法在静态方法create()的方法参数和返回类型上使用泛型类型T。
有些同学在网上搜索发现,可以在static修饰符后面加一个<T>,编译就能通过:
public class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() { ... }
public T getLast() { ... }
// 可以编译通过:
public static <T> Pair<T> create(T first, T last) {
return new Pair<T>(first, last);
}
}
但实际上,这个<T>和Pair<T>类型的<T>已经没有任何关系了。
对于静态方法,我们可以单独改写为“泛型”方法,只需要使用另一个类型即可。对于上面的create()静态方法,我们应该把它改为另一种泛型类型,例如,<K>:
public class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() { ... }
public T getLast() { ... }
// 静态泛型方法应该使用其他类型区分:
public static <K> Pair<K> create(K first, K last) {
return new Pair<K>(first, last);
}
}
这样才能清楚地将静态方法的泛型类型和实例类型的泛型类型区分开。
多个泛型类型
泛型还可以定义多种类型。例如,我们希望Pair不总是存储两个类型一样的对象,就可以使用类型<T, K>:
public class Pair<T, K> {
private T first;
private K last;
public Pair(T first, K last) {
this.first = first;
this.last = last;
}
public T getFirst() { ... }
public K getLast() { ... }
}
使用的时候,需要指出两种类型:
Pair<String, Integer> p = new Pair<>("test", 123);
Java标准库的Map<K, V>就是使用两种泛型类型的例子。它对Key使用一种类型,对Value使用另一种类型。
小结
编写泛型时,需要定义泛型类型<T>;
静态方法不能引用泛型类型<T>,必须定义其他类型(例如<K>)来实现静态泛型方法;
泛型可以同时定义多种类型,例如Map<K, V>。
四,擦拭法
泛型是一种类似”模板代码“的技术,不同语言的泛型实现方式不一定相同。
Java语言的泛型实现方式是擦拭法(Type Erasure)。
所谓擦拭法是指,虚拟机对泛型其实一无所知,所有的工作都是编译器做的。
例如,我们编写了一个泛型类Pair<T>,这是编译器看到的代码:
public class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
而虚拟机根本不知道泛型。这是虚拟机执行的代码:
public class Pair {
private Object first;
private Object last;
public Pair(Object first, Object last) {
this.first = first;
this.last = last;
}
public Object getFirst() {
return first;
}
public Object getLast() {
return last;
}
}
因此,Java使用擦拭法实现泛型,导致了:
- 编译器把类型
<T>视为Object; - 编译器根据
<T>实现安全的强制转型。
使用泛型的时候,我们编写的代码也是编译器看到的代码:
Pair<String> p = new Pair<>("Hello", "world");
String first = p.getFirst();
String last = p.getLast();
而虚拟机执行的代码并没有泛型:
Pair p = new Pair("Hello", "world");
String first = (String) p.getFirst();
String last = (String) p.getLast();
所以,Java的泛型是由编译器在编译时实行的,编译器内部永远把所有类型T视为Object处理,但是,在需要转型的时候,编译器会根据T的类型自动为我们实行安全地强制转型。
了解了Java泛型的实现方式——擦拭法,我们就知道了Java泛型的局限:
局限一:<T>不能是基本类型,例如int,因为实际类型是Object,Object类型无法持有基本类型:
Pair<int> p = new Pair<>(1, 2); // compile error!
局限二:无法取得带泛型的Class。观察以下代码:
public class Main {
public static void main(String[] args) {
Pair<String> p1 = new Pair<>("Hello", "world");
Pair<Integer> p2 = new Pair<>(123, 456);
Class c1 = p1.getClass();
Class c2 = p2.getClass();
System.out.println(c1==c2); // true
System.out.println(c1==Pair.class); // true
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
因为T是Object,我们对Pair<String>和Pair<Integer>类型获取Class时,获取到的是同一个Class,也就是Pair类的Class。
换句话说,所有泛型实例,无论T的类型是什么,getClass()返回同一个Class实例,因为编译后它们全部都是Pair<Object>。
局限三:无法判断带泛型的类型:
Pair<Integer> p = new Pair<>(123, 456);
// Compile error:
if (p instanceof Pair<String>) {
}
原因和前面一样,并不存在Pair<String>.class,而是只有唯一的Pair.class。
局限四:不能实例化T类型:
public class Pair<T> {
private T first;
private T last;
public Pair() {
// Compile error:
first = new T();
last = new T();
}
}
上述代码无法通过编译,因为构造方法的两行语句:
first = new T();
last = new T();
擦拭后实际上变成了:
first = new Object();
last = new Object();
这样一来,创建new Pair<String>()和创建new Pair<Integer>()就全部成了Object,显然编译器要阻止这种类型不对的代码。
要实例化T类型,我们必须借助额外的Class<T>参数:
public class Pair<T> {
private T first;
private T last;
public Pair(Class<T> clazz) {
first = clazz.newInstance();
last = clazz.newInstance();
}
}
上述代码借助Class<T>参数并通过反射来实例化T类型,使用的时候,也必须传入Class<T>。例如:
Pair<String> pair = new Pair<>(String.class);
因为传入了Class<String>的实例,所以我们借助String.class就可以实例化String类型。
不恰当的覆写方法
有些时候,一个看似正确定义的方法会无法通过编译。例如:
public class Pair<T> {
public boolean equals(T t) {
return this == t;
}
}
这是因为,定义的equals(T t)方法实际上会被擦拭成equals(Object t),而这个方法是继承自Object的,编译器会阻止一个实际上会变成覆写的泛型方法定义。
换个方法名,避开与Object.equals(Object)的冲突就可以成功编译:
public class Pair<T> {
public boolean same(T t) {
return this == t;
}
}
泛型继承
一个类可以继承自一个泛型类。例如:父类的类型是Pair<Integer>,子类的类型是IntPair,可以这么继承:
public class IntPair extends Pair<Integer> {
}
使用的时候,因为子类IntPair并没有泛型类型,所以,正常使用即可:
IntPair ip = new IntPair(1, 2);
前面讲了,我们无法获取Pair<T>的T类型,即给定一个变量Pair<Integer> p,无法从p中获取到Integer类型。
但是,在父类是泛型类型的情况下,编译器就必须把类型T(对IntPair来说,也就是Integer类型)保存到子类的class文件中,不然编译器就不知道IntPair只能存取Integer这种类型。
在继承了泛型类型的情况下,子类可以获取父类的泛型类型。例如:IntPair可以获取到父类的泛型类型Integer。获取父类的泛型类型代码比较复杂:
import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
public class Main {
public static void main(String[] args) {
Class<IntPair> clazz = IntPair.class;
Type t = clazz.getGenericSuperclass();
if (t instanceof ParameterizedType) {
ParameterizedType pt = (ParameterizedType) t;
Type[] types = pt.getActualTypeArguments(); // 可能有多个泛型类型
Type firstType = types[0]; // 取第一个泛型类型
Class<?> typeClass = (Class<?>) firstType;
System.out.println(typeClass); // Integer
}
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
class IntPair extends Pair<Integer> {
public IntPair(Integer first, Integer last) {
super(first, last);
}
}
因为Java引入了泛型,所以,只用Class来标识类型已经不够了。实际上,Java的类型系统结构如下:
┌────┐
│Type│
└────┘
▲
│
┌────────────┬────────┴─────────┬───────────────┐
│ │ │ │
┌─────┐┌─────────────────┐┌────────────────┐┌────────────┐
│Class││ParameterizedType││GenericArrayType││WildcardType│
└─────┘└─────────────────┘└────────────────┘└────────────┘
小结
Java的泛型是采用擦拭法实现的;
擦拭法决定了泛型<T>:
- 不能是基本类型,例如:
int; - 不能获取带泛型类型的
Class,例如:Pair<String>.class; - 不能判断带泛型类型的类型,例如:
x instanceof Pair<String>; - 不能实例化
T类型,例如:new T()。
泛型方法要防止重复定义方法,例如:public boolean equals(T obj);
子类可以获取父类的泛型类型<T>。
五,extends通配符
我们前面已经讲到了泛型的继承关系:Pair<Integer>不是Pair<Number>的子类。
假设我们定义了Pair<T>:
public class Pair<T> { ... }
然后,我们又针对Pair<Number>类型写了一个静态方法,它接收的参数类型是Pair<Number>:
public class PairHelper {
static int add(Pair<Number> p) {
Number first = p.getFirst();
Number last = p.getLast();
return first.intValue() + last.intValue();
}
}
上述代码是可以正常编译的。使用的时候,我们传入:
int sum = PairHelper.add(new Pair<Number>(1, 2));
注意:传入的类型是Pair<Number>,实际参数类型是(Integer, Integer)。
既然实际参数是Integer类型,试试传入Pair<Integer>:
public class Main {
public static void main(String[] args) {
Pair<Integer> p = new Pair<>(123, 456);
int n = add(p);
System.out.println(n);
}
static int add(Pair<Number> p) {
Number first = p.getFirst();
Number last = p.getLast();
return first.intValue() + last.intValue();
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
直接运行,会得到一个编译错误:
incompatible types: Pair<Integer> cannot be converted to Pair<Number>
原因很明显,因为Pair<Integer>不是Pair<Number>的子类,因此,add(Pair<Number>)不接受参数类型Pair<Integer>。
但是从add()方法的代码可知,传入Pair<Integer>是完全符合内部代码的类型规范,因为语句:
Number first = p.getFirst();
Number last = p.getLast();
实际类型是Integer,引用类型是Number,没有问题。问题在于方法参数类型定死了只能传入Pair<Number>。
有没有办法使得方法参数接受Pair<Integer>?办法是有的,这就是使用Pair<? extends Number>使得方法接收所有泛型类型为Number或Number子类的Pair类型。我们把代码改写如下:
public class Main {
public static void main(String[] args) {
Pair<Integer> p = new Pair<>(123, 456);
int n = add(p);
System.out.println(n);
}
static int add(Pair<? extends Number> p) {
Number first = p.getFirst();
Number last = p.getLast();
return first.intValue() + last.intValue();
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
这样一来,给方法传入Pair<Integer>类型时,它符合参数Pair<? extends Number>类型。这种使用<? extends Number>的泛型定义称之为上界通配符(Upper Bounds Wildcards),即把泛型类型T的上界限定在Number了。
除了可以传入Pair<Integer>类型,我们还可以传入Pair<Double>类型,Pair<BigDecimal>类型等等,因为Double和BigDecimal都是Number的子类。
如果我们考察对Pair<? extends Number>类型调用getFirst()方法,实际的方法签名变成了:
<? extends Number> getFirst();
即返回值是Number或Number的子类,因此,可以安全赋值给Number类型的变量:
Number x = p.getFirst();
然后,我们不可预测实际类型就是Integer,例如,下面的代码是无法通过编译的:
Integer x = p.getFirst();
这是因为实际的返回类型可能是Integer,也可能是Double或者其他类型,编译器只能确定类型一定是Number的子类(包括Number类型本身),但具体类型无法确定。
我们再来考察一下Pair<T>的set方法:
public class Main {
public static void main(String[] args) {
Pair<Integer> p = new Pair<>(123, 456);
int n = add(p);
System.out.println(n);
}
static int add(Pair<? extends Number> p) {
Number first = p.getFirst();
Number last = p.getLast();
p.setFirst(new Integer(first.intValue() + 100));
p.setLast(new Integer(last.intValue() + 100));
return p.getFirst().intValue() + p.getFirst().intValue();
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
public void setFirst(T first) {
this.first = first;
}
public void setLast(T last) {
this.last = last;
}
}
不出意外,我们会得到一个编译错误:
incompatible types: Integer cannot be converted to CAP#1
where CAP#1 is a fresh type-variable:
CAP#1 extends Number from capture of ? extends Number
编译错误发生在p.setFirst()传入的参数是Integer类型。有些童鞋会问了,既然p的定义是Pair<? extends Number>,那么setFirst(? extends Number)为什么不能传入Integer?
原因还在于擦拭法。如果我们传入的p是Pair<Double>,显然它满足参数定义Pair<? extends Number>,然而,Pair<Double>的setFirst()显然无法接受Integer类型。
这就是<? extends Number>通配符的一个重要限制:方法参数签名setFirst(? extends Number)无法传递任何Number的子类型给setFirst(? extends Number)。
这里唯一的例外是可以给方法参数传入null:
p.setFirst(null); // ok, 但是后面会抛出NullPointerException
p.getFirst().intValue(); // NullPointerException
extends通配符的作用
如果我们考察Java标准库的java.util.List<T>接口,它实现的是一个类似“可变数组”的列表,主要功能包括:
public interface List<T> {
int size(); // 获取个数
T get(int index); // 根据索引获取指定元素
void add(T t); // 添加一个新元素
void remove(T t); // 删除一个已有元素
}
现在,让我们定义一个方法来处理列表的每个元素:
int sumOfList(List<? extends Integer> list) {
int sum = 0;
for (int i=0; i<list.size(); i++) {
Integer n = list.get(i);
sum = sum + n;
}
return sum;
}
为什么我们定义的方法参数类型是List<? extends Integer>而不是List<Integer>?从方法内部代码看,传入List<? extends Integer>或者List<Integer>是完全一样的,但是,注意到List<? extends Integer>的限制:
- 允许调用
get()方法获取Integer的引用; - 不允许调用
set(? extends Integer)方法并传入任何Integer的引用(null除外)。
因此,方法参数类型List<? extends Integer>表明了该方法内部只会读取List的元素,不会修改List的元素(因为无法调用add(? extends Integer)、remove(? extends Integer)这些方法。换句话说,这是一个对参数List<? extends Integer>进行只读的方法(恶意调用set(null)除外)。
使用extends限定T类型
在定义泛型类型Pair<T>的时候,也可以使用extends通配符来限定T的类型:
public class Pair<T extends Number> { ... }
现在,我们只能定义:
Pair<Number> p1 = null;
Pair<Integer> p2 = new Pair<>(1, 2);
Pair<Double> p3 = null;
因为Number、Integer和Double都符合<T extends Number>。
非Number类型将无法通过编译:
Pair<String> p1 = null; // compile error!
Pair<Object> p2 = null; // compile error!
因为String、Object都不符合<T extends Number>,因为它们不是Number类型或Number的子类。
小结
使用类似<? extends Number>通配符作为方法参数时表示:
- 方法内部可以调用获取
Number引用的方法,例如:Number n = obj.getFirst();; - 方法内部无法调用传入
Number引用的方法(null除外),例如:obj.setFirst(Number n);。
即一句话总结:使用extends通配符表示可以读,不能写。
使用类似<T extends Number>定义泛型类时表示:
- 泛型类型限定为
Number以及Number的子类。
六,uper通配符
我们前面已经讲到了泛型的继承关系:Pair<Integer>不是Pair<Number>的子类。
考察下面的set方法:
void set(Pair<Integer> p, Integer first, Integer last) {
p.setFirst(first);
p.setLast(last);
}
传入Pair<Integer>是允许的,但是传入Pair<Number>是不允许的。
和extends通配符相反,这次,我们希望接受Pair<Integer>类型,以及Pair<Number>、Pair<Object>,因为Number和Object是Integer的父类,setFirst(Number)和setFirst(Object)实际上允许接受Integer类型。
我们使用super通配符来改写这个方法:
void set(Pair<? super Integer> p, Integer first, Integer last) {
p.setFirst(first);
p.setLast(last);
}
注意到Pair<? super Integer>表示,方法参数接受所有泛型类型为Integer或Integer父类的Pair类型。
下面的代码可以被正常编译:
public class Main {
public static void main(String[] args) {
Pair<Number> p1 = new Pair<>(12.3, 4.56);
Pair<Integer> p2 = new Pair<>(123, 456);
setSame(p1, 100);
setSame(p2, 200);
System.out.println(p1.getFirst() + ", " + p1.getLast());
System.out.println(p2.getFirst() + ", " + p2.getLast());
}
static void setSame(Pair<? super Integer> p, Integer n) {
p.setFirst(n);
p.setLast(n);
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
public void setFirst(T first) {
this.first = first;
}
public void setLast(T last) {
this.last = last;
}
}
考察Pair<? super Integer>的setFirst()方法,它的方法签名实际上是:
void setFirst(? super Integer);
因此,可以安全地传入Integer类型。
再考察Pair<? super Integer>的getFirst()方法,它的方法签名实际上是:
? super Integer getFirst();
这里注意到我们无法使用Integer类型来接收getFirst()的返回值,即下面的语句将无法通过编译:
Integer x = p.getFirst();
因为如果传入的实际类型是Pair<Number>,编译器无法将Number类型转型为Integer。
注意:虽然Number是一个抽象类,我们无法直接实例化它。但是,即便Number不是抽象类,这里仍然无法通过编译。此外,传入Pair<Object>类型时,编译器也无法将Object类型转型为Integer。
唯一可以接收getFirst()方法返回值的是Object类型:
Object obj = p.getFirst();
因此,使用<? super Integer>通配符表示:
- 允许调用
set(? super Integer)方法传入Integer的引用; - 不允许调用
get()方法获得Integer的引用。
唯一例外是可以获取Object的引用:Object o = p.getFirst()。
换句话说,使用<? super Integer>通配符作为方法参数,表示方法内部代码对于参数只能写,不能读。
对比extends和super通配符
我们再回顾一下extends通配符。作为方法参数,<? extends T>类型和<? super T>类型的区别在于:
<? extends T>允许调用读方法T get()获取T的引用,但不允许调用写方法set(T)传入T的引用(传入null除外);<? super T>允许调用写方法set(T)传入T的引用,但不允许调用读方法T get()获取T的引用(获取Object除外)。
一个是允许读不允许写,另一个是允许写不允许读。
先记住上面的结论,我们来看Java标准库的Collections类定义的copy()方法:
public class Collections {
// 把src的每个元素复制到dest中:
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
for (int i=0; i<src.size(); i++) {
T t = src.get(i);
dest.add(t);
}
}
}
它的作用是把一个List的每个元素依次添加到另一个List中。它的第一个参数是List<? super T>,表示目标List,第二个参数List<? extends T>,表示要复制的List。我们可以简单地用for循环实现复制。在for循环中,我们可以看到,对于类型<? extends T>的变量src,我们可以安全地获取类型T的引用,而对于类型<? super T>的变量dest,我们可以安全地传入T的引用。
这个copy()方法的定义就完美地展示了extends和super的意图:
copy()方法内部不会读取dest,因为不能调用dest.get()来获取T的引用;copy()方法内部也不会修改src,因为不能调用src.add(T)。
这是由编译器检查来实现的。如果在方法代码中意外修改了src,或者意外读取了dest,就会导致一个编译错误:
public class Collections {
// 把src的每个元素复制到dest中:
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
...
T t = dest.get(0); // compile error!
src.add(t); // compile error!
}
}
这个copy()方法的另一个好处是可以安全地把一个List<Integer>添加到List<Number>,但是无法反过来添加:
// copy List<Integer> to List<Number> ok:
List<Number> numList = ...;
List<Integer> intList = ...;
Collections.copy(numList, intList);
// ERROR: cannot copy List<Number> to List<Integer>:
Collections.copy(intList, numList);
而这些都是通过super和extends通配符,并由编译器强制检查来实现的。
PECS原则
何时使用extends,何时使用super?为了便于记忆,我们可以用PECS原则:Producer Extends Consumer Super。
即:如果需要返回T,它是生产者(Producer),要使用extends通配符;如果需要写入T,它是消费者(Consumer),要使用super通配符。
还是以Collections的copy()方法为例:
public class Collections {
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
for (int i=0; i<src.size(); i++) {
T t = src.get(i); // src是producer
dest.add(t); // dest是consumer
}
}
}
需要返回T的src是生产者,因此声明为List<? extends T>,需要写入T的dest是消费者,因此声明为List<? super T>。
无限定通配符
我们已经讨论了<? extends T>和<? super T>作为方法参数的作用。实际上,Java的泛型还允许使用无限定通配符(Unbounded Wildcard Type),即只定义一个?:
void sample(Pair<?> p) {
}
因为<?>通配符既没有extends,也没有super,因此:
- 不允许调用
set(T)方法并传入引用(null除外); - 不允许调用
T get()方法并获取T引用(只能获取Object引用)。
换句话说,既不能读,也不能写,那只能做一些null判断:
static boolean isNull(Pair<?> p) {
return p.getFirst() == null || p.getLast() == null;
}
大多数情况下,可以引入泛型参数<T>消除<?>通配符:
static <T> boolean isNull(Pair<T> p) {
return p.getFirst() == null || p.getLast() == null;
}
<?>通配符有一个独特的特点,就是:Pair<?>是所有Pair<T>的超类:
public class Main {
public static void main(String[] args) {
Pair<Integer> p = new Pair<>(123, 456);
Pair<?> p2 = p; // 安全地向上转型
System.out.println(p2.getFirst() + ", " + p2.getLast());
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
public void setFirst(T first) {
this.first = first;
}
public void setLast(T last) {
this.last = last;
}
}
上述代码是可以正常编译运行的,因为Pair<Integer>是Pair<?>的子类,可以安全地向上转型。
小结
使用类似<? super Integer>通配符作为方法参数时表示:
- 方法内部可以调用传入
Integer引用的方法,例如:obj.setFirst(Integer n);; - 方法内部无法调用获取
Integer引用的方法(Object除外),例如:Integer n = obj.getFirst();。
即使用super通配符表示只能写不能读。
使用extends和super通配符要遵循PECS原则。
无限定通配符<?>很少使用,可以用<T>替换,同时它是所有<T>类型的超类。
七,泛型和反射
Java的部分反射API也是泛型。例如:Class<T>就是泛型:
// compile warning:
Class clazz = String.class;
String str = (String) clazz.newInstance();
// no warning:
Class<String> clazz = String.class;
String str = clazz.newInstance();
调用Class的getSuperclass()方法返回的Class类型是Class<? super T>:
Class<? super String> sup = String.class.getSuperclass();
构造方法Constructor<T>也是泛型:
Class<Integer> clazz = Integer.class;
Constructor<Integer> cons = clazz.getConstructor(int.class);
Integer i = cons.newInstance(123);
我们可以声明带泛型的数组,但不能用new操作符创建带泛型的数组:
Pair<String>[] ps = null; // ok
Pair<String>[] ps = new Pair<String>[2]; // compile error!
必须通过强制转型实现带泛型的数组:
@SuppressWarnings("unchecked")
Pair<String>[] ps = (Pair<String>[]) new Pair[2];
使用泛型数组要特别小心,因为数组实际上在运行期没有泛型,编译器可以强制检查变量ps,因为它的类型是泛型数组。但是,编译器不会检查变量arr,因为它不是泛型数组。因为这两个变量实际上指向同一个数组,所以,操作arr可能导致从ps获取元素时报错,例如,以下代码演示了不安全地使用带泛型的数组:
Pair[] arr = new Pair[2];
Pair<String>[] ps = (Pair<String>[]) arr;
ps[0] = new Pair<String>("a", "b");
arr[1] = new Pair<Integer>(1, 2);
// ClassCastException:
Pair<String> p = ps[1];
String s = p.getFirst();
要安全地使用泛型数组,必须扔掉arr的引用:
@SuppressWarnings("unchecked")
Pair<String>[] ps = (Pair<String>[]) new Pair[2];
上面的代码中,由于拿不到原始数组的引用,就只能对泛型数组ps进行操作,这种操作就是安全的。
带泛型的数组实际上是编译器的类型擦除:
Pair[] arr = new Pair[2];
Pair<String>[] ps = (Pair<String>[]) arr;
System.out.println(ps.getClass() == Pair[].class); // true
String s1 = (String) arr[0].getFirst();
String s2 = ps[0].getFirst();
所以我们不能直接创建泛型数组T[],因为擦拭后代码变为Object[]:
// compile error:
public class Abc<T> {
T[] createArray() {
return new T[5];
}
}
必须借助Class<T>来创建泛型数组:
T[] createArray(Class<T> cls) {
return (T[]) Array.newInstance(cls, 5);
}
我们还可以利用可变参数创建泛型数组T[]:
public class ArrayHelper {
@SafeVarargs
static <T> T[] asArray(T... objs) {
return objs;
}
}
String[] ss = ArrayHelper.asArray("a", "b", "c");
Integer[] ns = ArrayHelper.asArray(1, 2, 3);
谨慎使用泛型可变参数
在上面的例子中,我们看到,通过:
static <T> T[] asArray(T... objs) {
return objs;
}
似乎可以安全地创建一个泛型数组。但实际上,这种方法非常危险。以下代码来自《Effective Java》的示例:
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
String[] arr = asArray("one", "two", "three");
System.out.println(Arrays.toString(arr));
// ClassCastException:
String[] firstTwo = pickTwo("one", "two", "three");
System.out.println(Arrays.toString(firstTwo));
}
static <K> K[] pickTwo(K k1, K k2, K k3) {
return asArray(k1, k2);
}
static <T> T[] asArray(T... objs) {
return objs;
}
}
直接调用asArray(T...)似乎没有问题,但是在另一个方法中,我们返回一个泛型数组就会产生ClassCastException,原因还是因为擦拭法,在pickTwo()方法内部,编译器无法检测K[]的正确类型,因此返回了Object[]。
如果仔细观察,可以发现编译器对所有可变泛型参数都会发出警告,除非确认完全没有问题,才可以用@SafeVarargs消除警告。
如果在方法内部创建了泛型数组,最好不要将它返回给外部使用。
更详细的解释请参考《Effective Java》“Item 32: Combine generics and varargs judiciously”。
小结
部分反射API是泛型,例如:Class<T>,Constructor<T>;
可以声明带泛型的数组,但不能直接创建带泛型的数组,必须强制转型;
可以通过Array.newInstance(Class<T>, int)创建T[]数组,需要强制转型;
同时使用泛型和可变参数时需要特别小心。
集合
一,Java集合简介
什么是集合(Collection)?集合就是“由若干个确定的元素所构成的整体”。例如,5只小兔构成的集合:
┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐
│ (\_(\ (\_/) (\_/) (\_/) (\(\ │
( -.-) (•.•) (>.<) (^.^) (='.')
│ C(")_(") (")_(") (")_(") (")_(") O(_")") │
└ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┘
在数学中,我们经常遇到集合的概念。例如:
- 有限集合:
- 一个班所有的同学构成的集合;
- 一个网站所有的商品构成的集合;
- …
- 无限集合:
- 全体自然数集合:1,2,3,……
- 有理数集合;
- 实数集合;
- …
为什么要在计算机中引入集合呢?这是为了便于处理一组类似的数据,例如:
- 计算所有同学的总成绩和平均成绩;
- 列举所有的商品名称和价格;
- ……
在Java中,如果一个Java对象可以在内部持有若干其他Java对象,并对外提供访问接口,我们把这种Java对象称为集合。很显然,Java的数组可以看作是一种集合:
String[] ss = new String[10]; // 可以持有10个String对象
ss[0] = "Hello"; // 可以放入String对象
String first = ss[0]; // 可以获取String对象
既然Java提供了数组这种数据类型,可以充当集合,那么,我们为什么还需要其他集合类?这是因为数组有如下限制:
- 数组初始化后大小不可变;
- 数组只能按索引顺序存取。
因此,我们需要各种不同类型的集合类来处理不同的数据,例如:
- 可变大小的顺序链表;
- 保证无重复元素的集合;
- …
Collection
Java标准库自带的java.util包提供了集合类:Collection,它是除Map外所有其他集合类的根接口。Java的java.util包主要提供了以下三种类型的集合:
List:一种有序列表的集合,例如,按索引排列的Student的List;Set:一种保证没有重复元素的集合,例如,所有无重复名称的Student的Set;Map:一种通过键值(key-value)查找的映射表集合,例如,根据Student的name查找对应Student的Map。
Java集合的设计有几个特点:一是实现了接口和实现类相分离,例如,有序表的接口是List,具体的实现类有ArrayList,LinkedList等,二是支持泛型,我们可以限制在一个集合中只能放入同一种数据类型的元素,例如:
List<String> list = new ArrayList<>(); // 只能放入String类型
最后,Java访问集合总是通过统一的方式——迭代器(Iterator)来实现,它最明显的好处在于无需知道集合内部元素是按什么方式存储的。
由于Java的集合设计非常久远,中间经历过大规模改进,我们要注意到有一小部分集合类是遗留类,不应该继续使用:
Hashtable:一种线程安全的Map实现;Vector:一种线程安全的List实现;Stack:基于Vector实现的LIFO的栈。
还有一小部分接口是遗留接口,也不应该继续使用:
Enumeration<E>:已被Iterator<E>取代。
二,使用List
在集合类中,List是最基础的一种集合:它是一种有序列表。
List的行为和数组几乎完全相同:List内部按照放入元素的先后顺序存放,每个元素都可以通过索引确定自己的位置,List的索引和数组一样,从0开始。
数组和List类似,也是有序结构,如果我们使用数组,在添加和删除元素的时候,会非常不方便。例如,从一个已有的数组{'A', 'B', 'C', 'D', 'E'}中删除索引为2的元素:
┌───┬───┬───┬───┬───┬───┐
│ A │ B │ C │ D │ E │ │
└───┴───┴───┴───┴───┴───┘
│ │
┌───┘ │
│ ┌───┘
│ │
▼ ▼
┌───┬───┬───┬───┬───┬───┐
│ A │ B │ D │ E │ │ │
└───┴───┴───┴───┴───┴───┘
这个“删除”操作实际上是把'C'后面的元素依次往前挪一个位置,而“添加”操作实际上是把指定位置以后的元素都依次向后挪一个位置,腾出来的位置给新加的元素。这两种操作,用数组实现非常麻烦。
因此,在实际应用中,需要增删元素的有序列表,我们使用最多的是ArrayList。实际上,ArrayList在内部使用了数组来存储所有元素。例如,一个ArrayList拥有5个元素,实际数组大小为6(即有一个空位):
size=5
┌───┬───┬───┬───┬───┬───┐
│ A │ B │ C │ D │ E │ │
└───┴───┴───┴───┴───┴───┘
当添加一个元素并指定索引到ArrayList时,ArrayList自动移动需要移动的元素:
size=5
┌───┬───┬───┬───┬───┬───┐
│ A │ B │ │ C │ D │ E │
└───┴───┴───┴───┴───┴───┘
然后,往内部指定索引的数组位置添加一个元素,然后把size加1:
size=6
┌───┬───┬───┬───┬───┬───┐
│ A │ B │ F │ C │ D │ E │
└───┴───┴───┴───┴───┴───┘
继续添加元素,但是数组已满,没有空闲位置的时候,ArrayList先创建一个更大的新数组,然后把旧数组的所有元素复制到新数组,紧接着用新数组取代旧数组:
size=6
┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐
│ A │ B │ F │ C │ D │ E │ │ │ │ │ │ │
└───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘
现在,新数组就有了空位,可以继续添加一个元素到数组末尾,同时size加1:
size=7
┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐
│ A │ B │ F │ C │ D │ E │ G │ │ │ │ │ │
└───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘
可见,ArrayList把添加和删除的操作封装起来,让我们操作List类似于操作数组,却不用关心内部元素如何移动。
我们考察List<E>接口,可以看到几个主要的接口方法:
- 在末尾添加一个元素:
boolean add(E e) - 在指定索引添加一个元素:
boolean add(int index, E e) - 删除指定索引的元素:
E remove(int index) - 删除某个元素:
boolean remove(Object e) - 获取指定索引的元素:
E get(int index) - 获取链表大小(包含元素的个数):
int size()
但是,实现List接口并非只能通过数组(即ArrayList的实现方式)来实现,另一种LinkedList通过“链表”也实现了List接口。在LinkedList中,它的内部每个元素都指向下一个元素:
┌───┬───┐ ┌───┬───┐ ┌───┬───┐ ┌───┬───┐
HEAD ──>│ A │ ●─┼──>│ B │ ●─┼──>│ C │ ●─┼──>│ D │ │
└───┴───┘ └───┴───┘ └───┴───┘ └───┴───┘
我们来比较一下ArrayList和LinkedList:
| ArrayList | LinkedList | |
|---|---|---|
| 获取指定元素 | 速度很快 | 需要从头开始查找元素 |
| 添加元素到末尾 | 速度很快 | 速度很快 |
| 在指定位置添加/删除 | 需要移动元素 | 不需要移动元素 |
| 内存占用 | 少 | 较大 |
通常情况下,我们总是优先使用ArrayList。
List的特点
使用List时,我们要关注List接口的规范。List接口允许我们添加重复的元素,即List内部的元素可以重复:
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("apple"); // size=1
list.add("pear"); // size=2
list.add("apple"); // 允许重复添加元素,size=3
System.out.println(list.size());
}
}
List还允许添加null:
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("apple"); // size=1
list.add(null); // size=2
list.add("pear"); // size=3
String second = list.get(1); // null
System.out.println(second);
}
}
创建List—of()方法
注意:of()方法是在jdk9版本的新特性,所以在jdk9之后的才能使用(包括jdk9)
除了使用ArrayList和LinkedList,我们还可以通过List接口提供的of()方法,根据给定元素快速创建List:
List<Integer> list = List.of(1, 2, 5);
但是List.of()方法不接受null值,如果传入null,会抛出NullPointerException异常。
遍历List
和数组类型,我们要遍历一个List,完全可以用for循环根据索引配合get(int)方法遍历:
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = List.of("apple", "pear", "banana");
for (int i=0; i<list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
}
}
但这种方式并不推荐,一是代码复杂,二是因为get(int)方法只有ArrayList的实现是高效的,换成LinkedList后,索引越大,访问速度越慢。
所以我们要始终坚持使用迭代器Iterator来访问List。Iterator本身也是一个对象,但它是由List的实例调用iterator()方法的时候创建的。Iterator对象知道如何遍历一个List,并且不同的List类型,返回的Iterator对象实现也是不同的,但总是具有最高的访问效率。
Iterator对象有两个方法:boolean hasNext()判断是否有下一个元素,E next()返回下一个元素。因此,使用Iterator遍历List代码如下:
import java.util.Iterator;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = List.of("apple", "pear", "banana");
for (Iterator<String> it = list.iterator(); it.hasNext(); ) {
String s = it.next();
System.out.println(s);
}
}
}
有童鞋可能觉得使用Iterator访问List的代码比使用索引更复杂。但是,要记住,通过Iterator遍历List永远是最高效的方式。并且,由于Iterator遍历是如此常用,所以,Java的for each循环本身就可以帮我们使用Iterator遍历。把上面的代码再改写如下:
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = List.of("apple", "pear", "banana");
for (String s : list) {
System.out.println(s);
}
}
}
上述代码就是我们编写遍历List的常见代码。
实际上,只要实现了Iterable接口的集合类都可以直接用for each循环来遍历,Java编译器本身并不知道如何遍历集合对象,但它会自动把for each循环变成Iterator的调用,原因就在于Iterable接口定义了一个Iterator<E> iterator()方法,强迫集合类必须返回一个Iterator实例。
List和Array转换
把List变为Array有三种方法,第一种是调用toArray()方法直接返回一个Object[]数组:
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = List.of("apple", "pear", "banana");
Object[] array = list.toArray();
for (Object s : array) {
System.out.println(s);
}
}
}
这种方法会丢失类型信息,所以实际应用很少。
第二种方式是给toArray(T[])传入一个类型相同的Array,List内部自动把元素复制到传入的Array中:
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> list = List.of(12, 34, 56);
Integer[] array = list.toArray(new Integer[3]);
for (Integer n : array) {
System.out.println(n);
}
}
}
注意到这个toArray(T[])方法的泛型参数<T>并不是List接口定义的泛型参数<E>,所以,我们实际上可以传入其他类型的数组,例如我们传入Number类型的数组,返回的仍然是Number类型:
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> list = List.of(12, 34, 56);
Number[] array = list.toArray(new Number[3]);
for (Number n : array) {
System.out.println(n);
}
}
}
但是,如果我们传入类型不匹配的数组,例如,String[]类型的数组,由于List的元素是Integer,所以无法放入String数组,这个方法会抛出ArrayStoreException。
如果我们传入的数组大小和List实际的元素个数不一致怎么办?根据List接口的文档,我们可以知道:
如果传入的数组不够大,那么List内部会创建一个新的刚好够大的数组,填充后返回;如果传入的数组比List元素还要多,那么填充完元素后,剩下的数组元素一律填充null。
实际上,最常用的是传入一个“恰好”大小的数组:
Integer[] array = list.toArray(new Integer[list.size()]);
最后一种更简洁的写法是通过List接口定义的T[] toArray(IntFunction<T[]> generator)方法:
Integer[] array = list.toArray(Integer[]::new);
这种函数式写法我们会在后续讲到。
反过来,把Array变为List就简单多了,通过List.of(T...)方法最简单:
Integer[] array = { 1, 2, 3 };
List<Integer> list = List.of(array);
对于JDK 11之前的版本,可以使用Arrays.asList(T...)方法把数组转换成List。
要注意的是,返回的List不一定就是ArrayList或者LinkedList,因为List只是一个接口,如果我们调用List.of(),它返回的是一个只读List:
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> list = List.of(12, 34, 56);
list.add(999); // UnsupportedOperationException
}
}
对只读List调用add()、remove()方法会抛出UnsupportedOperationException。
练习
给定一组连续的整数,例如:10,11,12,……,20,但其中缺失一个数字,试找出缺失的数字:
import java.util.*;
public class Main {
public static void main(String[] args) {
// 构造从start到end的序列:
final int start = 10;
final int end = 20;
List<Integer> list = new ArrayList<>();
for (int i = start; i <= end; i++) {
list.add(i);
}
// 随机删除List中的一个元素:
int removed = list.remove((int) (Math.random() * list.size()));
int found = findMissingNumber(start, end, list);
System.out.println(list.toString());
System.out.println("missing number: " + found);
System.out.println(removed == found ? "测试成功" : "测试失败");
}
static int findMissingNumber(int start, int end, List<Integer> list) {
return 0;
}
增强版:和上述题目一样,但整数不再有序,试找出缺失的数字:
import java.util.*;
public class Main {
public static void main(String[] args) {
// 构造从start到end的序列:
final int start = 10;
final int end = 20;
List<Integer> list = new ArrayList<>();
for (int i = start; i <= end; i++) {
list.add(i);
}
// 洗牌算法shuffle可以随机交换List中的元素位置:
Collections.shuffle(list);
// 随机删除List中的一个元素:
int removed = list.remove((int) (Math.random() * list.size()));
int found = findMissingNumber(start, end, list);
System.out.println(list.toString());
System.out.println("missing number: " + found);
System.out.println(removed == found ? "测试成功" : "测试失败");
}
static int findMissingNumber(int start, int end, List<Integer> list) {
return 0;
}
小结
List是按索引顺序访问的长度可变的有序表,优先使用ArrayList而不是LinkedList;
可以直接使用for each遍历List;
List可以和Array相互转换。
md文档来啦:拿到的记得点赞收藏~~~~~~!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
链接:https://pan.baidu.com/s/1L4dNrG_50mEETYLEo01m9g?pwd=z8h5
提取码:z8h5