简介
Redis作为重要的缓存数据库在高并发的解决方案中起着重要作用。为了系统的学习Redis,也为了秋招(美团比较关注Redis 的掌握),计划编写该系列博客,也是为了整理知识点。
本篇主要介绍了Redis的基础知识与原理。之后将更新Redis的分布式相关知识和实际使用会用到的操作。希望读完这三篇文章可以完全掌握Redis的使用!
NoSQL
Not Only SQL的简称。NoSQL是解决传统的RDBMS在应对某些问题时比较乏力而提出的。具体的表现如下:
- RDBMS依赖的表结构扩展性差,当表很多时,修改表结构的成本会很高;
- IO较慢:虽然引入了索引,但是还是会存在索引失效的问题;
- 海量数据处理乏力:由于1和2,导致了3。
关系型数据库和NoSQL数据库的关系从来都不是谁取代谁,而是在一个复杂的高并发系统中相互增益,共同为系统提供可用性。
主流分支
- KV数据库
- Redis:KV主存数据库,所有的操作在主存中。并 定期异步地将数据进行持久化。但是数据库提供 性能会受主存大小的影响,主存成本高。
- 列族数据库 HBASE就是列族数据库,虽然没有改变传统的数据库结构,但是其对数据分析的支持会更好。
- Cassandra:是Facebook的分布式数据库。其优点是 1)该数据库的设计模式非常灵活,不需要先 设计数据库模式,添加或删除字段非常方便;2)支持范围查询,即可以对键进行范围查询;3)高可扩展 性:单点故障不影响整个集群,支持线性扩展。
- Hypertable:也是一个开源的分布式数据库,其使用的是bigtable。面向的是大规模的分布式集 群,比如HDFS和KFS。
- 文档数据库
文档数据库并不关心高性能的读写并发,而是保证大数据的存储和良好的查询性能。
- MongoDB:介于关系型数据库和 非关系型数据库之间,支持许多数据格式和高速访存。
- CouchDB:支持JSON和AtomPub。为了确保数据一致性,CouchDB符合ACID属性。
Redis简介
Remote Dictionary Server的简称。特点是在主存中存储数据。主存的特点是:IO快,易失性,成本高。
这个特点使得:
- Redis不适合存储大文件;
- 不适合存储需要持久化的文件;
- 适合存储热点数据(要求快速IO);
- 适合存储具有一定生命周期的数据(当生命周期结束就被销毁或者持久化到磁盘上)。
在Redis中, 数据的存储有两种格式:RDB和AOF。RDB记录的是真实的数据,AOF记录的对数据的操作,且在Redis中会对操作进行重写(对可以合并和简化的操作进行重写)。AOF的效率更好,但是RDB采用压缩存储,存储效率高。
Redis数据类型
Redis是KV数据库,所有的Key都是字符串且唯一,数据类型指的是value的类型。
| redis | java |
|---|---|
| string | String |
| hash | HashMap |
| list | LinkedList |
| set | HashSet |
| sorted_set | TreeSet |
Redis有16个数据库可以使用。默认使用的是0号数据库。使用select index的方式切换数据库。
key的命名规则
key的操作
1. 基本操作操作
在分布式的场景下,保证多个节点存储的key不冲突是一个很关键的点。
#删除
del key
# 获取
get key
# 模糊查询 ?表示一个占位符 *表示任意长度任意字符 []指定若干字符
keys pattern
#类型
type key
# 自增操作
incr key increment
incrbyfloat key increment
由于key是一个字符串,所以在进行操作时会转化成数值来进行计算。由于Redis是单线程的,命令的执行是先后顺序的,所以不用担心并发引发的数据一致性问题。
2. 设置生命周期
由于redis是采用主存存储,因此通常存储的是具有一定生命周期的数据。
# 设置生命周期
expire key seconds
pexpire key milliseconds
expireat key timestamp
pexpireat key milliseconds-timestamp
# 获取生命周期
ttl key
pttl key #时间戳
# 持久化
persist key
String类型
String类型是一种一对一的映射关系。
| key | value |
|---|---|
| name | 咸鱼突刺 |
| age | 18 |
操作:
# 添加数据
set key value
# 获取
get key
# 删除
del key
# 添加多个
mset key1 value1 key2 value2...
# 获取多个
mget key1 key2 ...
# 获取字符串长度
strlen key1
# 在字符串后追加字符串
append key value
Hash类型
如果我们需要一个key对应多个value时就需要使用hash结构。相当于在string的基础上嵌套了多个结构。Hash的value 中只能存储字符串,且每个键值对的存储上限是 2^32 -1。
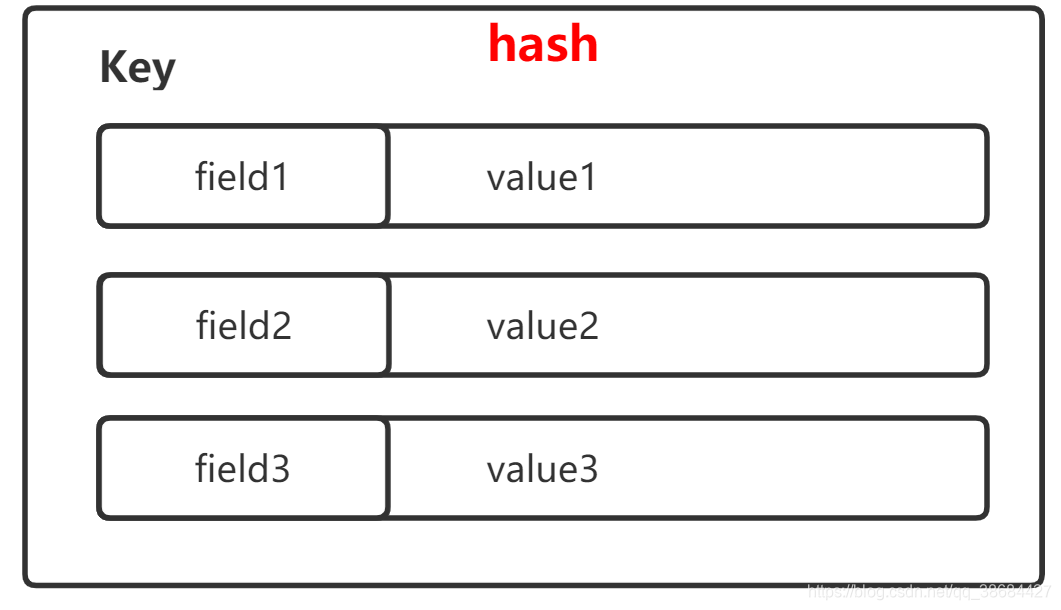
如果filed数据较少,底层的存储结构采用数组的方式,如果较多采用HashMap的形式。
# 新增数据
hset key field value
hmset key field1 value1 field2 value2...
hsetnx key field value
# 获取数据
hget key field
hgetall key
hkeys key
hvals key
# 删除数据
hedel key field1 field2....
# 获取字段的数量
hlen key
# 判断是否存在
hexists key field
list类型
list是序列结构,即各个元素之间有位置上的关系。redis中的list实现是 双向链表,逻辑结构为队列。根据队列的特点,不难猜出对list的操作应该包括在双端的操作。key相当于是一个指针。
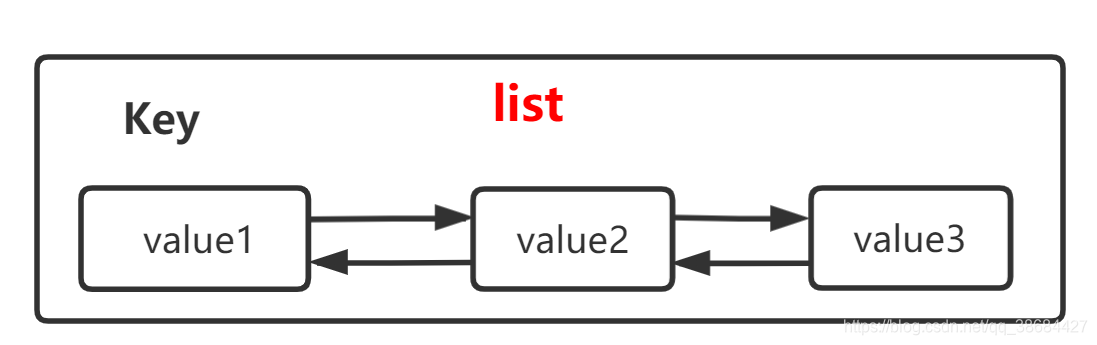
# 添加数据
lpush key value1 value2
rpush key value1 value2
# 获取数据
lrange key start stop
# 获取指定位置的value
lindex key index
# 获取长度
llen key
# 获取并移除
lpop key
lpop key
# 规定时间内获取并移除数据
blpop key1 [key2] timeout
brpop key1 [key2] timeout
# 移除指定数据
lrem key count value
set类型
set的定位和数学中的集合一致。set的查询效率高,且可以存大量的 数据。其存储结构和Hash结构完全 一致,但是其value的值为空。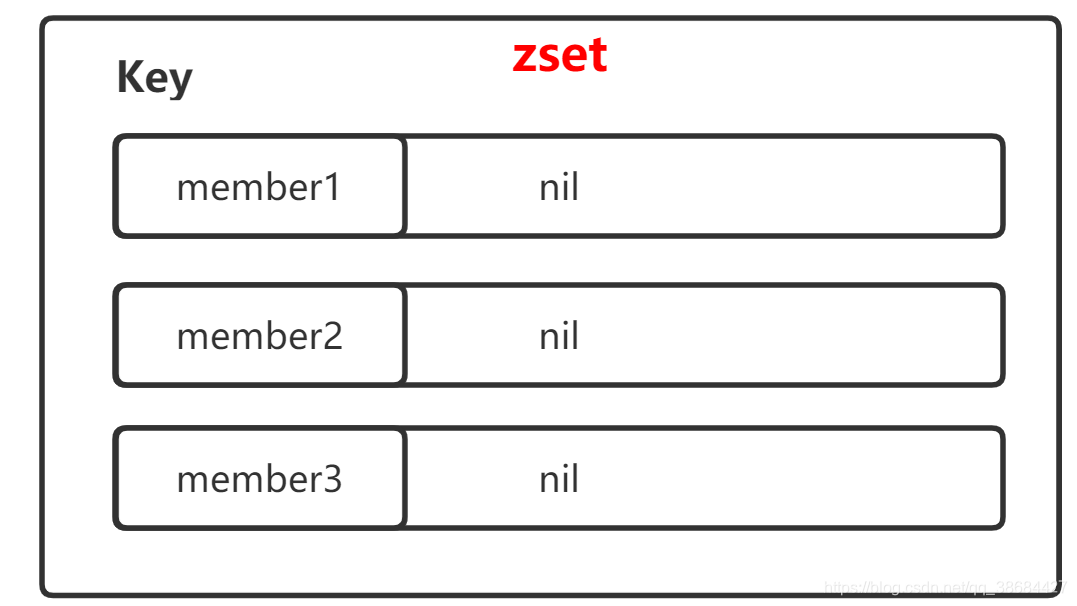
常用来解决:
- 数据的快速过滤和查找;
- 存储用户的权限等对顺序没有要求的内容。
# 添加数据
sadd key member1 [member2]
# 获取全部数据
smembers key
# 删除数据
srem key member1 [member2]
# 获取数据量
scard key
# 是否包含某个member
sismember key member
# 随机获取指定数量的数据
srandmember key [count]
# 随机获取一个数据并移除
spop key
# 集合运算
sinter key1 [key2]
sunion key1 [key2]
sdiff key1 [key2]
# 集合运算并保存结果
sinterstore destSet key1 [key2]
sunionstore destSet key1 [key2]
sdiffstore destSet key1 [key2]
# 将指定数据从原始集合移动到目标集合
smove source dest member
zset类型
是一种有序的数据结构。score就是判断的规则。sorted_set在set的基础上加入了一个score字段,按照这个字段排序。

# 添加数据
zadd key score1 member1 [score2 member2]
# 获取全部数据
zrange key start end [withscore]
zrevrange key start end [withscore]
# 删除数据
zrem key member
# 按条件查找数据 limit指定是个数
zrangebyscore key min max [withscore] [limit]
zrevrangebyscore key max min [withscore] [limit]
# 获取数据对应的索引
zrank key member
zrevrank key member
# 获取score值
zscore key member
zincrby key increment memeber
# 按照条件删除数据
zremrangebyrank key start end
zremreangebyscore key min max
# 获取集合总量
zcard key
zcount key min max
# 集合操作:交集会将key相同的score相加
zinterstore destSet numkeys key1 [key2]
zunionstore destSet numkeys key1 [key2]
Redis的持久化
持久化就将数据存储在本地磁盘,为了数据的恢复。通常的方式有:AOF和RDB。

RDB详解
开启RDB的指令有两种:
save指令 ,一旦执行,CPU会立刻去对数据进行持久化 ,但是由于Redis是单线程的,当数据量很大,会导致长时间的阻塞;bgsave指令,一旦执行Redis会在CPU空闲时执行持久化 操作。

RDB配置
AOF(Append Only File)
记录的是对数据的操作。读操作不用记录,修改操作记录。 AOF之所以效率高,是因为其采用指令重新写机制,将可以合并且简化得到指令重写,大大减少了文件体积。比如用户的单个插入会被整合成mset的形式。
AOF三种写策略:
-
always:每次发生变化就写一次,效率低
-
everysec:每秒将缓冲区的指令同步到缓冲区,准确率高,性能好。
-
no:系统控制,不建议使用。
AOF功能开启
# 开启AOF
appendonly yes|no
# AOF写数据策略
appendfsync always|everysec|no
# 日志文件名
appendfilename filename
# 地址
dir path
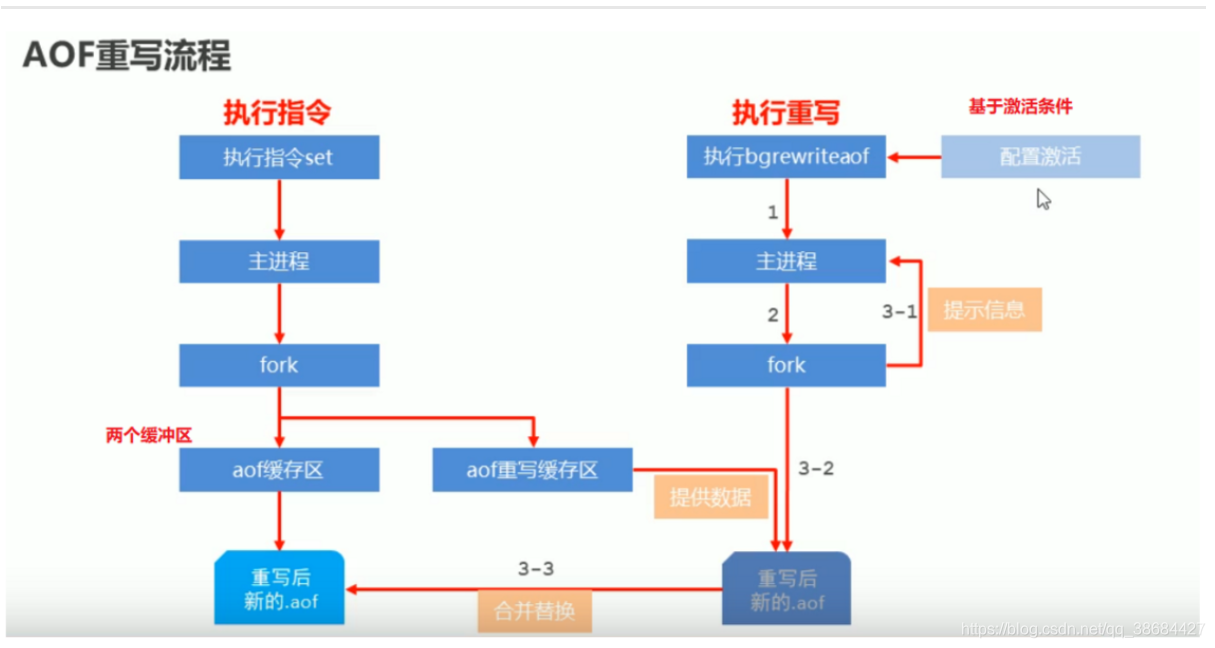
AOF重写
AOF重写是为了压缩AOF文件的大小。通过指令重拍和组合来减少不必要的操作。
- 手动重写
bgrewriteaof - 自动重写
auto-aof-rewrite-min-size size auto-aof-rewrite-min-percentage percentage
AOF与RDB的比较
| 持久化方式 | RDB | AOF |
|---|---|---|
| 占用空间 | 小(数据压缩) | 大(指令重写) |
| 存储速度 | 慢 | 快 |
| 恢复速度 | 快 | 慢 |
| 资源消耗 | 高 | 低 |
| 启动优先级 | 低 | 高 |
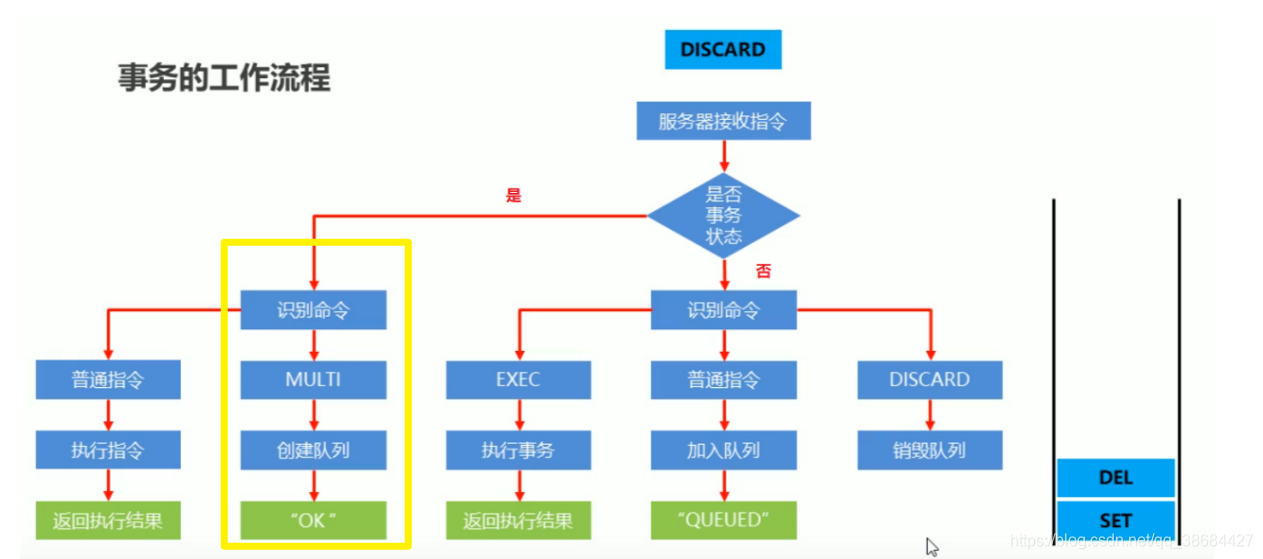
Redis事务
# 开始事务,之后的所有指令都是属于该事务的
multi
# 取消事务
discard
#执行事务
exec
Redis锁
为了在事务过程中保持数据的操作不出错,redis中引入了锁的概念。这个锁就是设置一个string,对某个字段column设 锁就是setnx lock-column value,这个value设置的就是我们操作的数值,每个业务进入之后就对这个value进行修改。
同时还需要配合expire防止程序卡死导致锁无法释放。
注意:Redis中setnx操作是原子性操作。
# 监听key
watch key1 key2..
# 取消监听
unwatch
Redis删除策略
Redis所占内存成本太高,要求定期移过期数据,以缓解内存的压力。有以下几种删除策略。
-
定时删除:设置一个定时器,对过期的数据定期清洗。虽然可以保证内存中没有过期的数据 ,但是会对CPU造成巨大压力。
-
惰性删除:当我们使用一个数据的时候再去判断是否过期。这样虽然减少了CPU的压力但是会造成数据的堆积,加重了内存的压力。
-
定期删除:让CPU定期删除是一个折中策略。通过配置信息指定定期删除的条件(是一种随机抽检的方式)。 使用较多。
Redis的逐出策略
redis在存储数据时,会先调用freeMemoryNeeded()函数检测内存是否充足。当内存已满,且无法清出足够的空间存放新的 数据就会使用数据逐出,其实这和OS中的页面交换算法思想一致。选择用处最小的数据放出。
相关配置
# 最大可用内存
maxmemory
# 每次选择待删除的据个数
maxmemory-samples
# 删除策略
maxmemory-policy
策略有:
1. lru:最近最少使用的数据淘汰
2. lfu:使用次数最少的数据淘汰
3. ttl:快过期的数据淘汰
4. random:随机挑选数据淘汰
检测范围:
5. 检测易失性数据:volatile-xxx eg:volatile-lru
6. 检测全库数据:allkeys-xxx
7. 放弃使用数据驱逐:no-envitction