KMP算法
一个神一样的算法,说实话,实际应用价值不大但是启发价值很大,不好理解,下面的内容是我的学习心得,其中包括了对无数人不能理解的“递归”的理解方式,应该还是不难的,但是别妄想一下子想明白。看了很多文章,感觉都没有讲到点子上,因此写下这篇博客。
首先,前提声明,KMP实际上就是一个DFA(确定有限状态自动机),关于其中的过程我不想过多阐述,我只想谈谈关于KMP算法的最难的也是最精辟的地方:如何求解所谓的回归状态?(换句话说,如何求解next数组)
首先我们要知道其中很重要的几点:
- 求解的过程本质是动态规划
- 回归状态和匹配的模式字符串还有当前对比的文本字符有关。
- 文本字符串的对比不会回退。
- 在匹配失败的时候,我们尽量要让匹配模式字符串在不浪费匹配机会的情况下尽量前移。(这句话就是KMP干的事情)
这里我尝试讲一下 n e x t next next数组的理解(下面的过程非常重要):
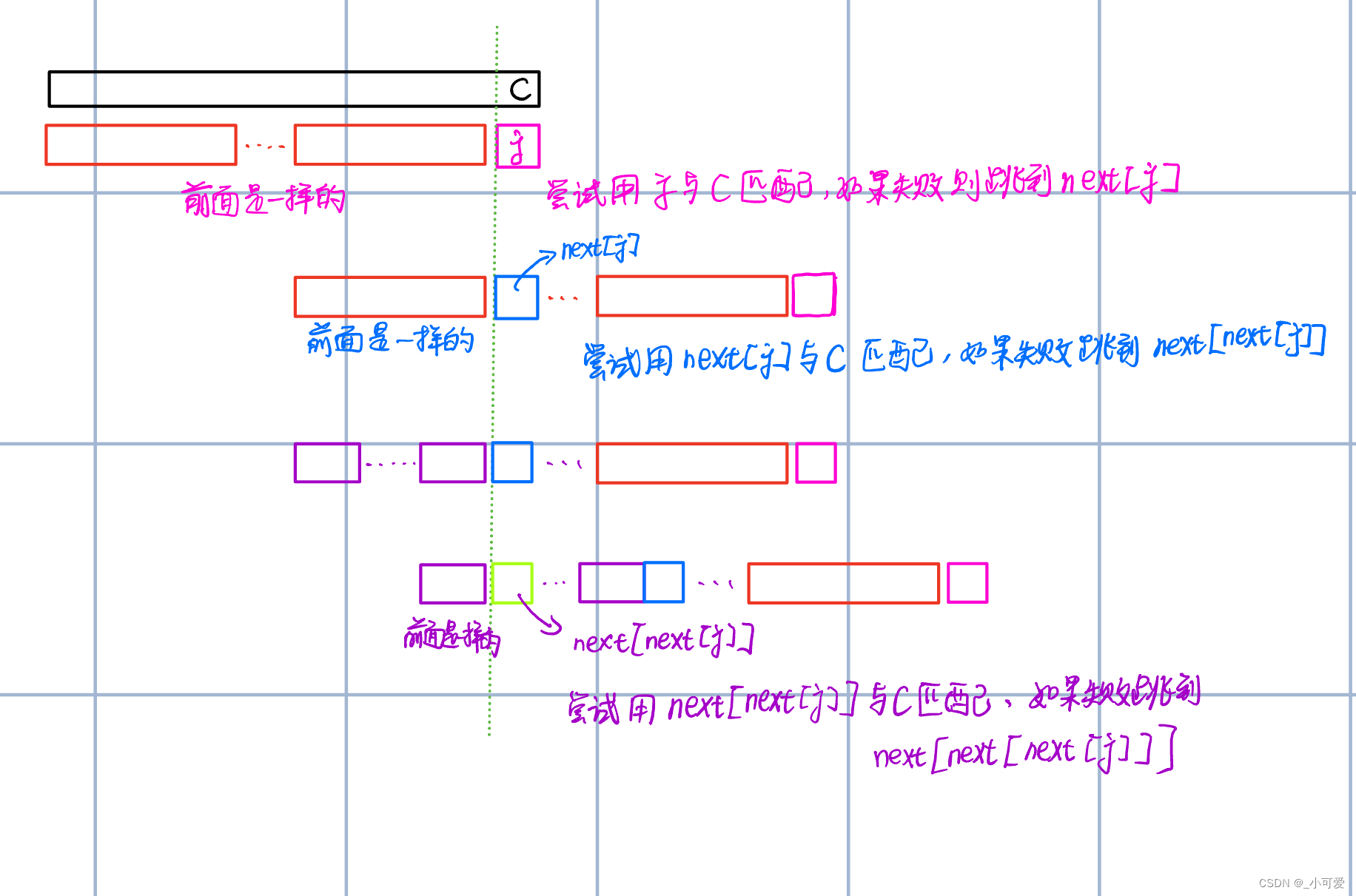
显然,我们发现这里存在一种子结构模式(前缀相同,对比下一个字符),那么我们为什么要直接往右边移动 n e x t [ j ] next[j] next[j]来匹配呢?
因为 n e x t [ j ] next[j] next[j]表示的是最大前后缀,我们不想浪费匹配的机会,那么最好的选择就是直接前进 n e x t [ j ] next[j] next[j],这样能够保证不浪费匹配机会的前提下前进最大距离。
好了,我们现在大概明白了KMP在干啥事情了,那么关键问题是如何求解 n e x t [ j ] next[j] next[j],实际上,这非常简单!很多人不理解这个过程,那是因为没有深刻理解KMP在干啥。如果你理解了上面的过程,有没有发现KMP干了啥事情?再来看看这张图:
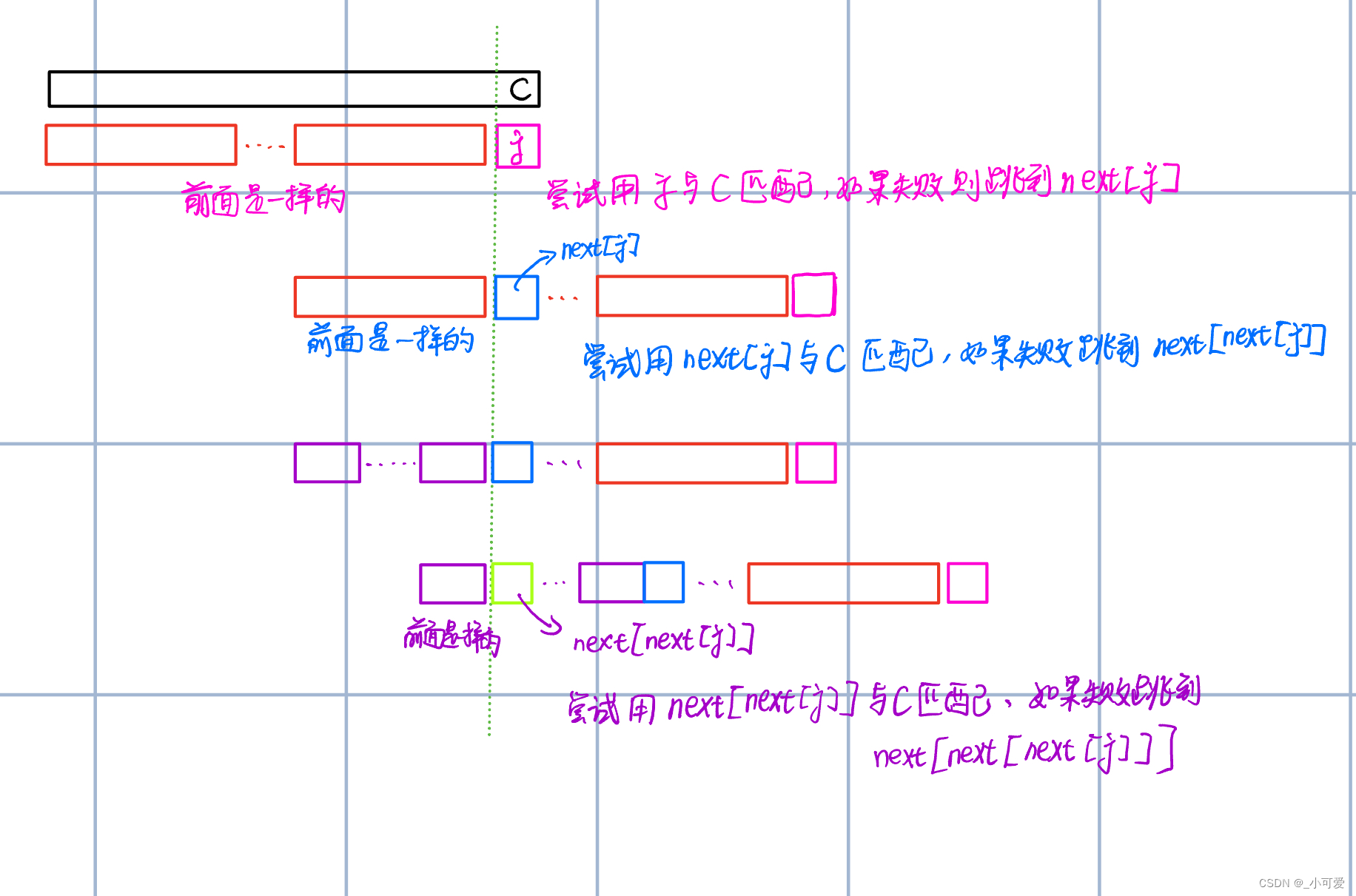
s [ j ] s[j] s[j]和文本字符C匹配失败了,那么可以看到它会一直重复执行刚才提到的子结构模式直到匹配(或者没有字符可以匹配)。这就是KMP干的事情。
从中我们就可以明白,有 n e x t [ j ] = n e x t [ n e x t [ j ] ] = n e x t [ n e x t [ n e x t [ j ] ] ] . . . next[j]=next[next[j]]=next[next[next[j]]]... next[j]=next[next[j]]=next[next[next[j]]]...这么一个过程。这里先有一个印象,下面你就会发现很巧妙的思路。
关于最大前后缀
那么具体上怎么得到关于给定模式匹配字符串的 n e x t [ ] next[] next[]数组中,我想读者应该知道,实际上它就是最大前后缀的位置+1,这里先告诉一个结论:最大前后缀的获得过程实际上就是字符串匹配的过程!!!想像一下字符串自己的另一个副本往右边移动直到自己的前缀和自己的后缀完全重叠——最大相同前后缀。
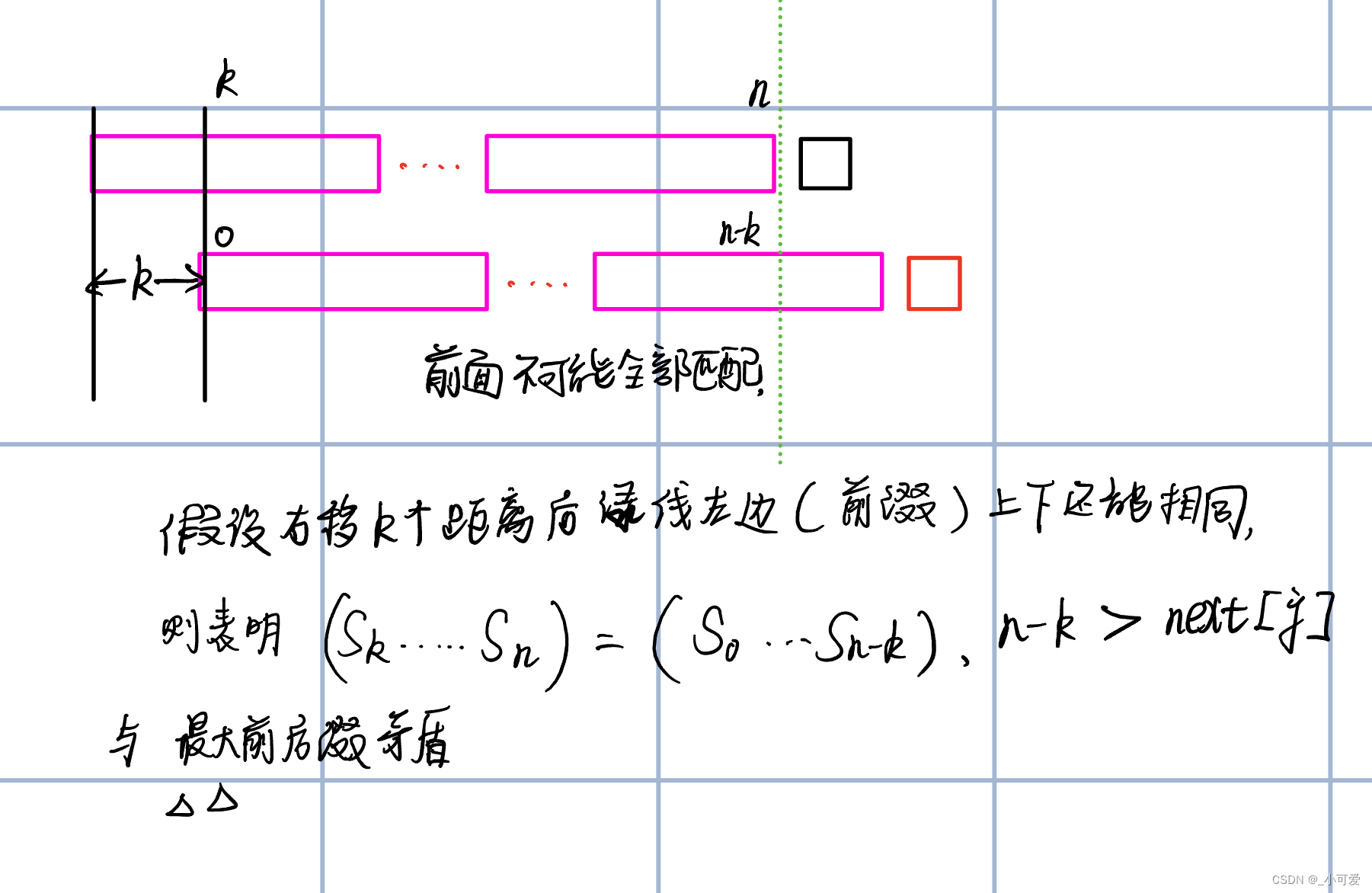
设 n e x t [ i ] ( 0 ≤ i ≤ j − 1 ) next[i](0\le i \le {j - 1}) next[i](0≤i≤j−1)均已知,那么我们可以往右边移动到 N − n e x t [ j − 1 ] N-next[j-1] N−next[j−1]的位置,可以保证之前不会出现更大的前后缀匹配,证明和上面的KMP一样:
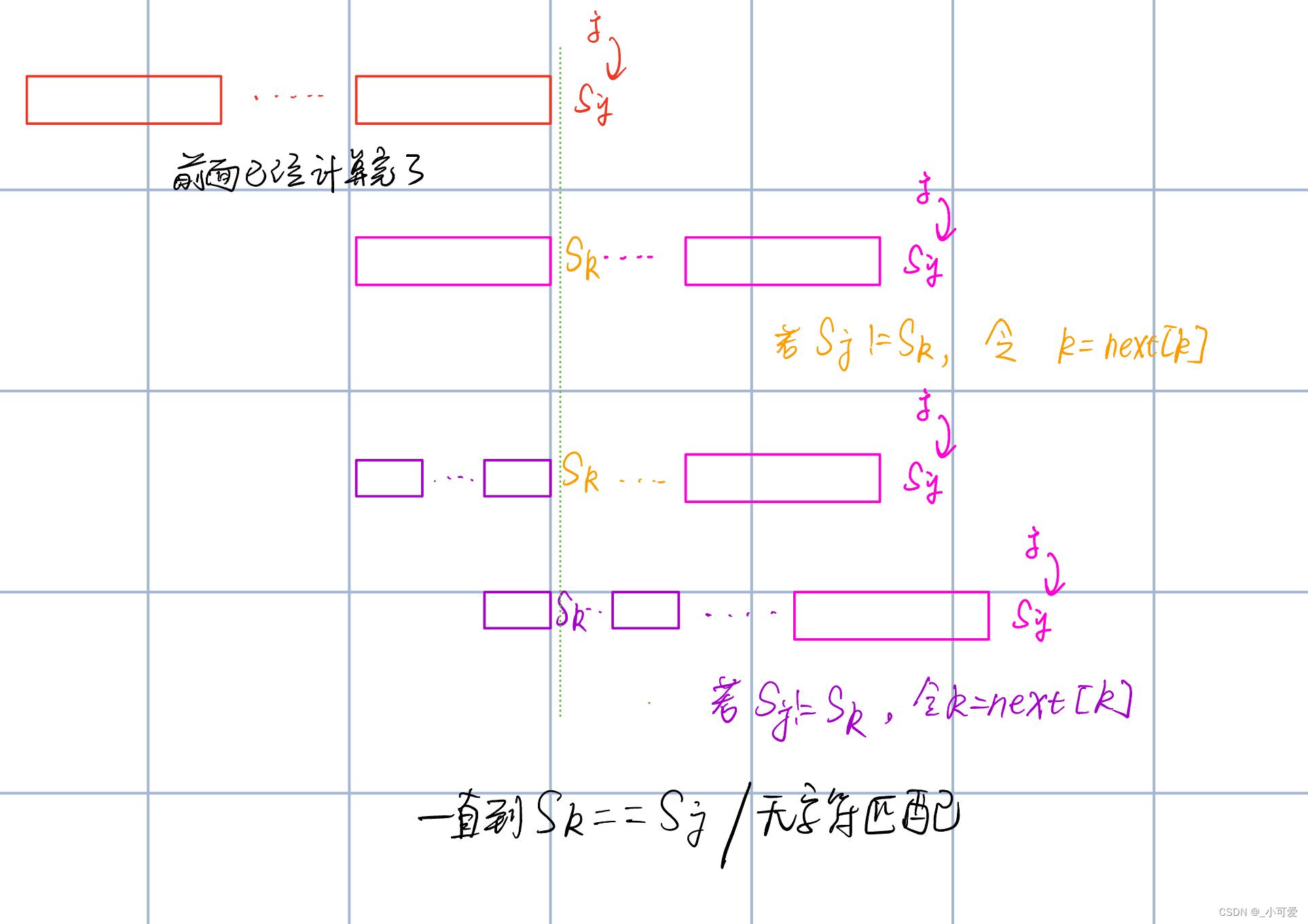
为了得到最大前后缀,我们的要求一定是匹配或者没有字符,这和KMP是一模一样的,我们就可以得到很重要的动态规划公式:
令 k = n e x t [ j − 1 ] n e x t [ j ] = k = n e x t [ k ] = n e x t [ n e x t [ k ] ] . . . u n t i l ( s j = = s k o r n o n e ) \text{令}k=next[j-1]\\ next[j]=k=next[k]=next[next[k]]...until(s_j==s_k \ or \ none) 令k=next[j−1]next[j]=k=next[k]=next[next[k]]...until(sj==sk or none)
这居然和KMP算法的过程一模一样!所以我们想要获得一个字符串的最大相同前后缀,让它自己匹配自己就可以了。 至此,我想你已经非常清楚KMP和 n e x t [ ] next[] next[]数组的关系了,但是为什么会如此精妙呢?
- KMP算法本身的运行需要 n e x t [ ] next[] next[]数组
- n e x t [ ] next[] next[]数组的产生用的又是KMP的过程。
如果你有点算法基础的话,这时候肯定已经感觉到了——这不就是自动机吗?
另外一种理解
如果从自动机的角度来看, n e x t [ ] next[] next[]数组就是状态机本身,而KMP算法阐述的其实就是状态机不断更新的过程。
《算法4》里面的讲解使用的就是DFA(确定有限状态自动机),如果从自动机的角度理解上面的两条精妙的地方,那其实就很容易看出来KMP在不断搜索文本字符在进行的一个事实:自己更新自己。
具体的内容请参考原著,这里就不在赘述了。