文章目录
Python判断对象是否相等(== 和 is)
Python中的对象包含三个基本要素,分别是:
- id:用来唯一标识一个对象,可以理解为内存地址;
- type:标识对象的类型;
- value:对象的值;
== :比较两个对象的内容是否相等,
即两个对象的 value 是否相等,无论 id 是否相等,默认会调用对象的 eq()方法。
is: 比较的是两个对象是不是完全相同,即他们的 id 要相等。也就是说如果 a is b 为 True,那么 a == b 也为True。
如何在Python中管理内存
Python内存由Python私有堆空间管理。所有Python对象和数据结构都位于私有堆空间中。程序员无法访问这个私有堆空间,解释器负责处理这个Python私有堆空间。Python内存管理器的Python堆空间的分配,核心API允许程序员使用一些工具来编写代码。Python还拥有一个内置的grabage收集器,它回收所有未使用的内存,并释放内存并使其可用到堆空间。
Python的内存管理机制可以从三个方面来讲:
(1)垃圾回收
(2)引用计数
(3)内存池机制
一、垃圾回收:
python不像C++,Java等语言一样,他们可以不用事先声明变量类型而直接对变量进行赋值。
对Python语言来讲,对象的类型和内存都是在运行时确定的。这也是为什么我们称Python语言为动态类型的原因(这里我们把动态类型可以简单的归结为对变量内存地址的分配是在运行时自动判断变量类型并对变量进行赋值)。
垃圾回收
-
1、当内存中有不再使用的部分时,垃圾收集器就会把他们清理掉。它会去检查那些引用计数为0的对象,
然后清除其在内存的空间。当然除了引用计数为0的会被清除,还有一种情况也会被垃圾收集器清掉:当两个对象相互引用时,他们本身其他的引用已经为0了。 -
2、垃圾回收机制还有一个循环垃圾回收器, 确保释放循环引用对象(a引用b, b引用a, 导致其引用计数永远不为0)。
二、引用计数:
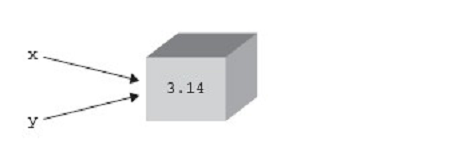
Python采用了类似Windows内核对象一样的方式来对内存进行管理。每一个对象,都维护这一个对指向该对象的引用的计数。如图所示(图片来自Python核心编程)
 、
、
x = 3.14
y = x
我们首先创建了一个对象3.14, 然后将这个浮点数对象的引用赋值给x,因为x是第一个引用,因此,这个浮点数对象的引用计数为1. 语句y = x创建了一个指向同一个对象的引用别名y,我们发现,并没有为Y创建一个新的对象,而是将Y也指向了x指向的浮点数对象,使其引用计数为2.
我们可以很容易就证明上述的观点:

变量a 和 变量b的id一致(我们可以将id值想象为C中变量的指针).
我们援引另一个网址的图片来说明问题:对于C语言来讲,我们创建一个变量A时就会为为该变量申请一个内存空间,并将变量值 放入该空间中,当将该变量赋给另一变量B时会为B申请一个新的内存空间,并将变量值放入到B的内存空间中,这也是为什么A和B的指针不一致的原因。如图:


int A = 1 int A = 2
而Python的情况却不一样,实际上,Python的处理方式和Javascript有点类似,如图所示,变量更像是附在对象上的标签(和引用的定义类似)。当变量被绑定在一个对象上的时候,该变量的引用计数就是1,(还有另外一些情况也会导致变量引用计数的增加),系统会自动维护这些标签,并定时扫描,当某标签的引用计数变为0的时候,该对就会被回收。



a = 1 a = 2 b = a
三、内存池机制
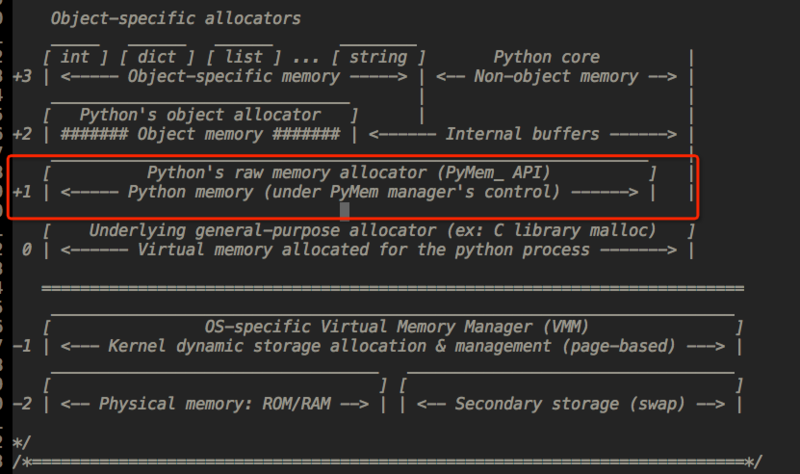
Python的内存机制以金字塔型,-1,-2层主要有操作系统进行操作,
第0层是C中的malloc,free等内存分配和释放函数进行操作;
第1层和第2层是内存池,有Python的接口函数PyMem_Malloc函数实现,当对象小于256K时有该层直接分配内存;
第3层是最上层,也就是我们对Python对象的直接操作;
在 C 中如果频繁的调用 malloc 与 free 时,是会产生性能问题的.再加上频繁的分配与释放小块的内存会产生内存碎片. Python 在这里主要干的工作有:
如果请求分配的内存在1~256字节之间就使用自己的内存管理系统,否则直接使用 malloc。这里还是会调用 malloc 分配内存,但每次会分配一块大小为256k的大块内存.
- 经由内存池登记的内存到最后还是会回收到内存池,并不会调用 C 的 free 释放掉.以便下次使用。对于简单的Python对象,例如数值、字符串,元组(tuple不允许被更改)采用的是复制的方式(深拷贝?),
也就是说当将另一个变量B赋值给变量A时,虽然A和B的内存空间仍然相同,但当A的值发生变化时,会重新给A分配空间,A和B的地址变得不再相同
内存管理
Python中的内存管理机制的层次结构提供了4层,其中最底层则是C运行的malloc和free接口,往上的三层才是由Python实现并且维护的。

-
Layer0层是C运行的malloc和free接口
-
Layer1层则是在Layer0层的基础之上对其提供的接口进行了统一的封装。
这是因为虽然不同的操作系统都提供标准定义的内存管理接口,但是对于某些特殊的情况不同的操作系统都不同的行为,比如说调用malloc(0),有的操作系统会返回NULL,表示内存申请失败;然而有的操作系统会返回一个貌似正常的指针,但是这个指针所指的内存并不是有效的。为了广泛的移植性,Python必须保证相同的语义一定代表相同的运行行为。
-
Layer2层为内存池。内存管理机制上,Python构建了更高抽象的内存管理策略。比如说一些常用对象,包括整数对象、字符串对象等等。
-
Layer3层主要是对象缓冲池机制,它是建立在Layer2基础上的。它有整数对象缓冲池、String对象缓冲池、List和Dict对象缓冲池
内存池机制
Python为了避免频繁的申请和删除内存所造成系统切换于用户态和核心态的开销,从而引入了内存池机制。
整个小块内存的内存池一共分为4层,从下至上分别是block、pool、arena和内存池,需要说明的是:block、pool和Arean都是代码中可以找到的实体,而最顶层的内存池只是一个概念上的东西,表示Python对于整个小块内存分配和释放行为的内存管理机制。
注意,python又分为大内存和小内存,内存大小以256字节为界限,大于256的大内存通过malloc进行分配,小于则通过内存池分配
block:
最小的内存单元,大小为8的整数倍。有很多种类block,不同种类的block都有不同的内存大小,申请内存的时候只需要找到适合自身大小的block即可,当然申请的内存也是存在一个上限,如果超过这个上限,则退化到使用最底层的malloc进行申请。
pool:一个pool管理着一堆有固定大小的内存块,其大小通常为一个系统内存页的大小。
arena:多个pool组合成一个arena。
内存池:一个整体的概念,用于随整个小块内存分配和释放
python 循环赋值_Python垃圾回收中引用计数、标记清除、分代回收机制详解

变量与对象
Python 作为一种动态类型的语言,其对象和引用分离。在 Python 中万物皆对象,因此Python 的存储问题等同于对象的存储问题,对于每个对象,Python 都会分配一块内存空间去存储它 。我们通过一个简单的赋值语句来理解 变量与对象,如下:

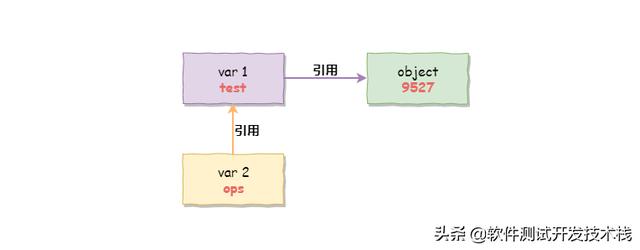
变量(testops),通过变量指针引用对象,变量指针指向具体对象的内存空间,取对象的值。对象 (9527),类型已知,每个对象都包含一个头部信息(类型标识符和引用计数器)。Python中变量名没有类型,类型属于对象,对象的类型决定了变量的类型。

如上,整数 9527 为一个对象, test 是一个变量。利用赋值语句,引用 test 指向对象 9527 。9527 对象存储在内存中,我们可以通过 id 函数,查看对象的内存地址,引用示意图如下:
对于整数和短小的字符等,会触发Python的缓存机制,即Python将这些对象进行缓存,不会为相同的对象分配不同的内存空间,如下:
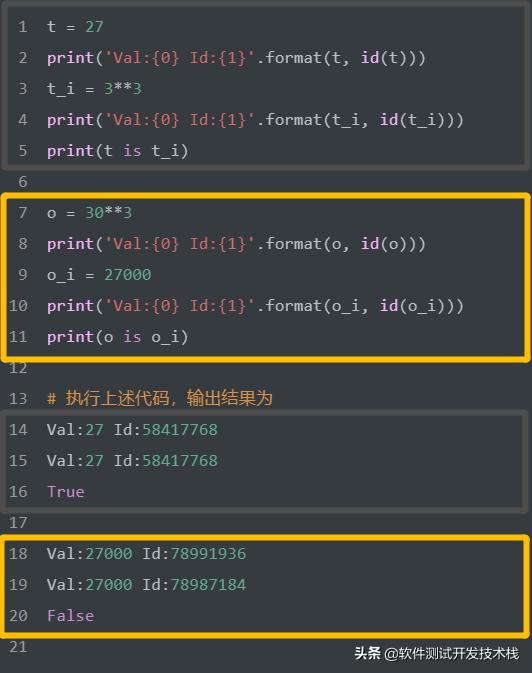
如上,我们使用 is 关键字判断两个引用所指的对象是否相同。可以看到,由于Python缓存了小整数(其实也缓存了短字符串,Python2),因此每个对象只存有一份,比如,使用赋值语句创建小整数,如 27,并没有创建出新的对象,而是创建了一个引用。而当使用赋值语句创建大的整数可以有多个相同的对象,如使用赋值语句创建大整数 27000,此时创建出多个对象。
引用计数

在Python中,每个对象都有指向该对象的引用总数,即引用计数(reference count)。一个对象会记录着引用自己的对象的个数,每增加1个引用,个数加1,每减少1个引用,个数减1。在垃圾回收过程中,利用引用计数器方法,在检测到对象引用个数为 0 时,对普通的对象进行释放内存的机制。
我们可以使用 sys.getrefcount 方法,来查看每个对象的引用计数。需要注意的是,当使用某个引用作为参数,传递给getrefcount方法时,参数实际上创建了一个临时的引用。因此,getrefcount 方法所得到的结果比期望的多1。
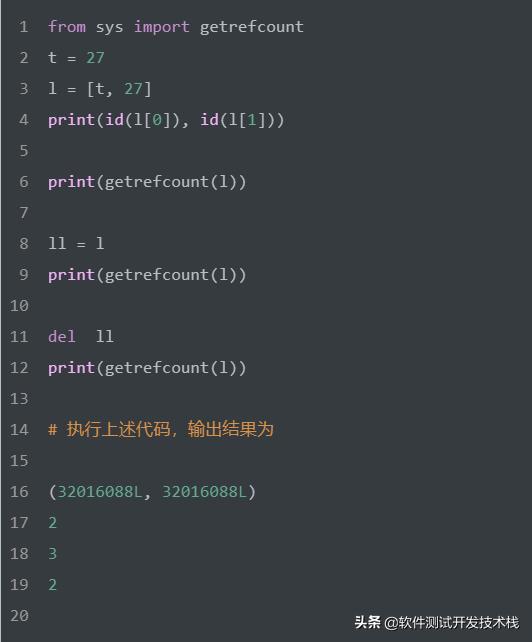
由上可见,l 中的 [t,27] 两个元素,都指向了同一个对象,实际上,容器对象(如,列表、字典等)中包含的并不是元素对象本身,是指向各个元素对象的引用。同时,l 的引用计数随着 ll 的创建和删除,引用计数也随着增加1和减少1。
导致引用计数增加的场景如下:
- 对象被创建:t = 27
- 其它的别名被创建:ll = l
- 作为参数传递给函数:getrefcount(l)
- 作为容器对象的一个元素:l = [t, 27]
导致引用计数减少的场景如下:
- 对象的别名被显式的销毁:del ll
- 对象的一个别名被赋值给其他对象:l = 789
- 对象所在的容器被销毁或从容器中删除对象 如,del ll 或 l.remove(t)。
- 一个本地引用离开了它的作用域,比如上面的 getrefcount(x) 函数结束时,x指向的对象引用减1。
引用计数中的循环引用

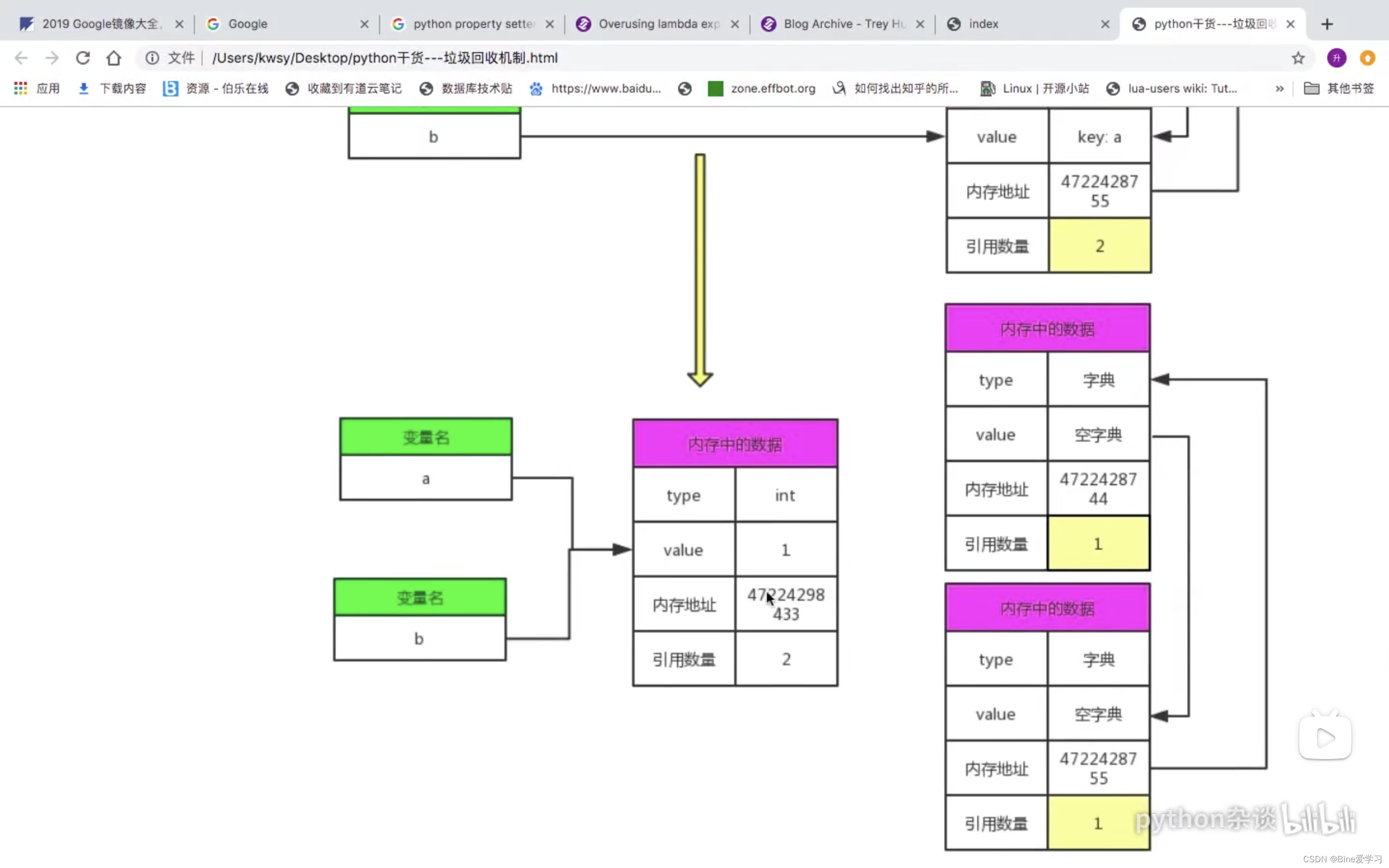
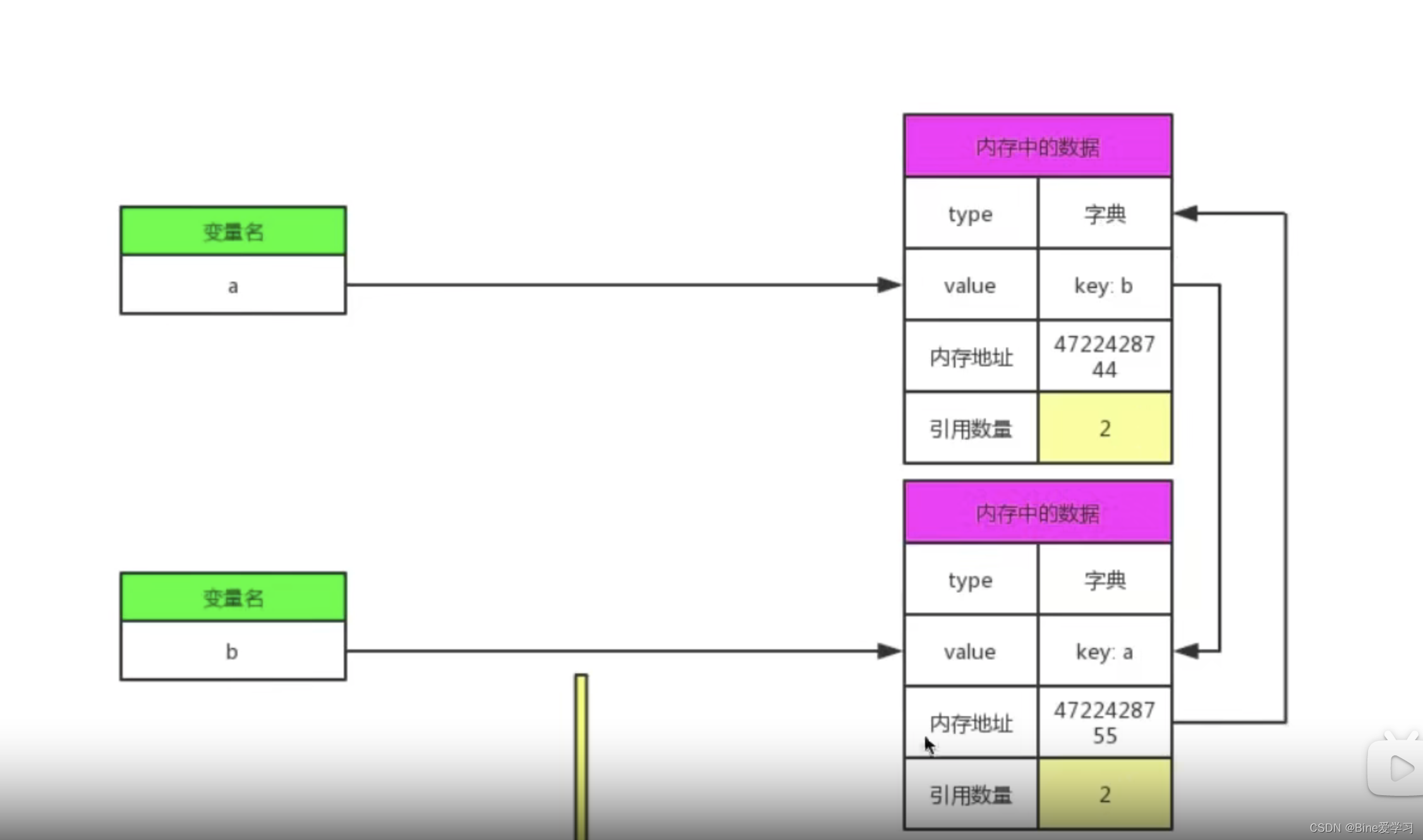
循环引用即对象之间进行相互引用,出现循环引用后,利用上述引用计数机制无法对循环引用中的对象进行释放空间,从而导致内存泄漏,这就是循环引用问题,如下:
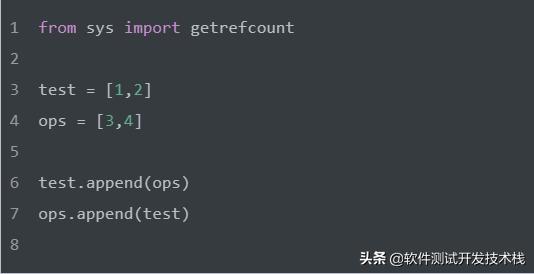
对象 test 中的元素引用 ops,而对象 ops 中元素同时来引用 test ,从而造成仅仅删除 test和 ops对象,无法释放其内存空间,因为他们依然在被引用(引用个数不为0)。进一步解释就是循环引用后,test 和 ops 被引用个数为2,删除 test 和 ops 对象后,两者被引用的个数变为1,并不是0,而Python只有在检查到一个对象的被引用个数为0时,才会自动释放其内存,所以这里无法释放 test 和 ops 的内存空间,因此这也是导致内存泄漏的原因之一。
垃圾回收

在Python中的对象越来越多,占用的内存越来越大,垃圾回收机制就是将没用的对象清除,释放内存。Python垃圾回收采用引用计数机制为主,标记-清除和分代回收机制为辅的策略,其中标记清除机制用来解决技术引用带来的循环引用而无法释放内存的问题,分代回收机制是为提升垃圾回收的效率。
当Python的对象的引用计数降为 0时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾。比如新建一个对象,被赋值给某个变量,则该对象的引用计数变为1。如果变量被删除,对象的引用计数为0,那么该对象就会被垃圾回收。
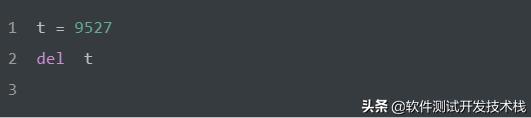
如上,执行 del t 后,已经没有任何引用指向之前建立的对象 9527,该对象引用计数变为0,用户不可能通过任何方式使用这个对象,当垃圾回收启动时,Python扫描到这个引用计数为0的对象,就将它所占用的内存进行回收。
标记-清除机制——解决循环引用问题

标记-清除机制顾名思义,首先标记对象(垃圾检测),然后清除垃圾(垃圾回收),标记清除用来解决引用计数机制产生的循环引用,进而导致内存泄漏的问题。循环引用只有在容器对象才会产生,比如字典,元组,列表等。首先为了追踪对象,需要每个容器对象维护两个额外的指针,用来将容器对象组成一个链表,指针分别指向前后两个容器对象,这样可以将对象的循环引用摘除,就可以得出两个对象的有效计数,我们通过如下示例,进一步了解一下。
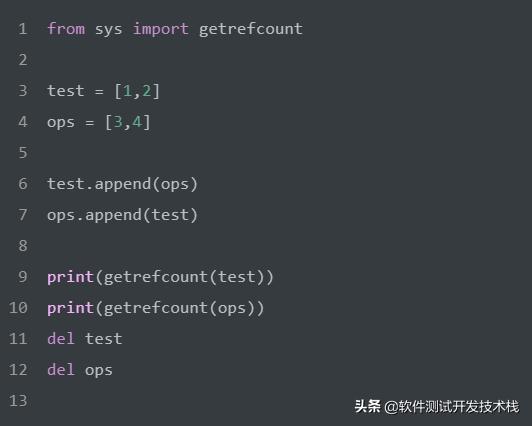
在 标记-清除机制中,存在root链表、unreachable链表,这里简单介绍一下。
如上,在未执行 del 语句时,test、ops的引用计数都为 2。但是在 del 执行完以后,test、ops 引用次数互相减 1。test、ops陷入循环引用中,此时标记清除机制来打破这种循环引用,找到其中一端 test 开始拆test、ops的引用环。即从 test 出发,因为它有一个对 ops的引用,则将 ops的引用计数减1,然后顺着引用达到 ops,因为 ops有一个对 test的引用,同样将 test的引用减1,如此就完成了循环引用对象间环摘除。引用环去掉以后发现,test、ops循环引用变为了0,所以test、ops就被添加到 unreachable链表 中直接被回收掉。
分代回收机制-提升垃圾回收效率

解决循环引用问题,引入的标记-清除机制,处理过程非常繁琐,需要处理每一个容器对象,因此Python考虑一种改善性能的做法,基于“对象存在时间越长,越不可能在后面的程序中变成垃圾”的假设,提出分代回收机制。出于信任和效率,对于这样一些“寿命长”的对象,我们相信它们的存在价值,所以降低在垃圾回收中扫描它们的频率,分代回收是一种以空间换时间的操作方式。我们可以通过 gc.get_threshold 方法,查看分代回收机制的参数阈值设置,如下:

Python将所有的对象分为年轻代(第0代)、中年代(第1代)、老年代(第2代)三代。所有的新建对象默认是 第0代对象。当某一代对象经历过垃圾回收,若依然存活,那么它就将被划分到下一代对象。垃圾回收启动时,会扫描所有的 第0代对象。如果 第0代经过一定次数垃圾回收,那么就触发对0代和1代的扫描清理。当第1代也经历了一定次数的垃圾回收后,那么会触发对 第0,1,2代,即对所有对象进行扫描。
如上,gc.get_threshold 方法返回的 (700, 10, 10),700即是垃圾回收启动的阈值,返回的两个10是指,每10次0代垃圾回收,会执行1次1代的垃圾回收;而每10次1代的垃圾回收,会执行1次的2代垃圾回收。
同样可以用 gc.set_threshold 来调整分代回收策略,比如对 第2代对象进行更频繁的扫描,如下:

通过此分代回收机制,循环引用中的内存回收处理过程就会得到很大的性能提升。
垃圾回收的时机

在以下三种情况下,会触发垃圾回收机制:
- **自动回收:**当gc模块的计数器达到阀值的时候,触发自动回收。
- 手动回收:使用gc模块中的collect 方法。
- 程序退出
接下来我们进一步了解一下 自动回收和手动回收 方式。
自动回收

垃圾回收时,Python不能运行其它的任务,频繁的垃圾回收将极大的降低Python的工作效率,当开启垃圾回收机制时(默认开启),在Python运行过程,会记录其中新增对象和释放对象的次数,当两者的差值高于某个阈值时,自动启动垃圾回收。
在Python中默认开启自动回收,其中涉及方法如下:
- gc.enable:开启垃圾回收机制(默认开启)。
- gc.disable:关闭垃圾回收机制。
- gc.isenabled:判定是否开启。
手动回收

使用 gc.collect 方法,手动执行分代回收机制。
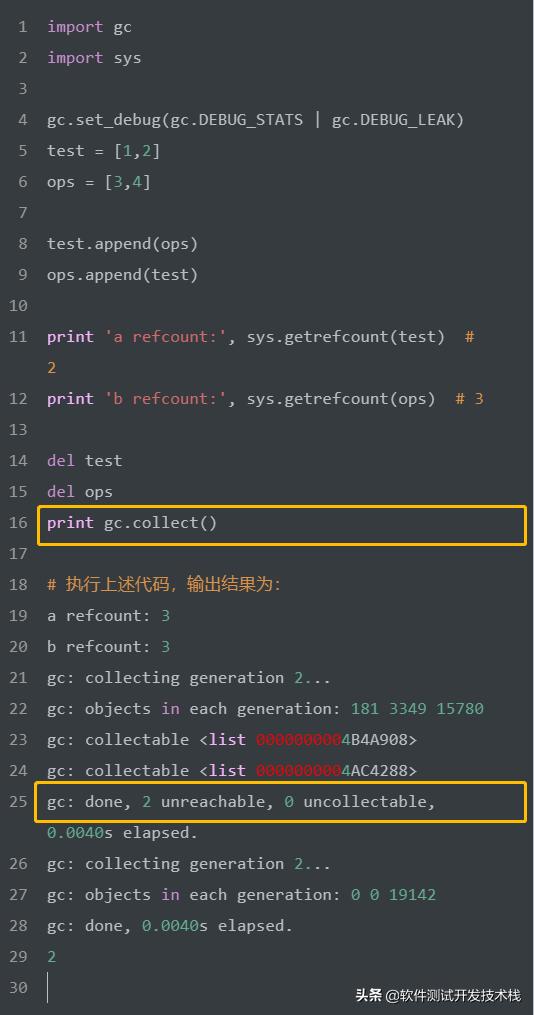
上面例子中test、ops为循环引用,通过 gc.collect 手动回收垃圾,实现了回收的两个test、ops的对象。此外,gc.collect 方法返回此次垃圾回收的unreachable(不可达)对象个数,上面例子中回收的两个都是unreachable对象,即清除 我们在标记-清除机制中提到的unreachable 链表中的对象。
https://blog.csdn.net/weixin_39875503/article/details/110098980
标记清除(mark-sweep)
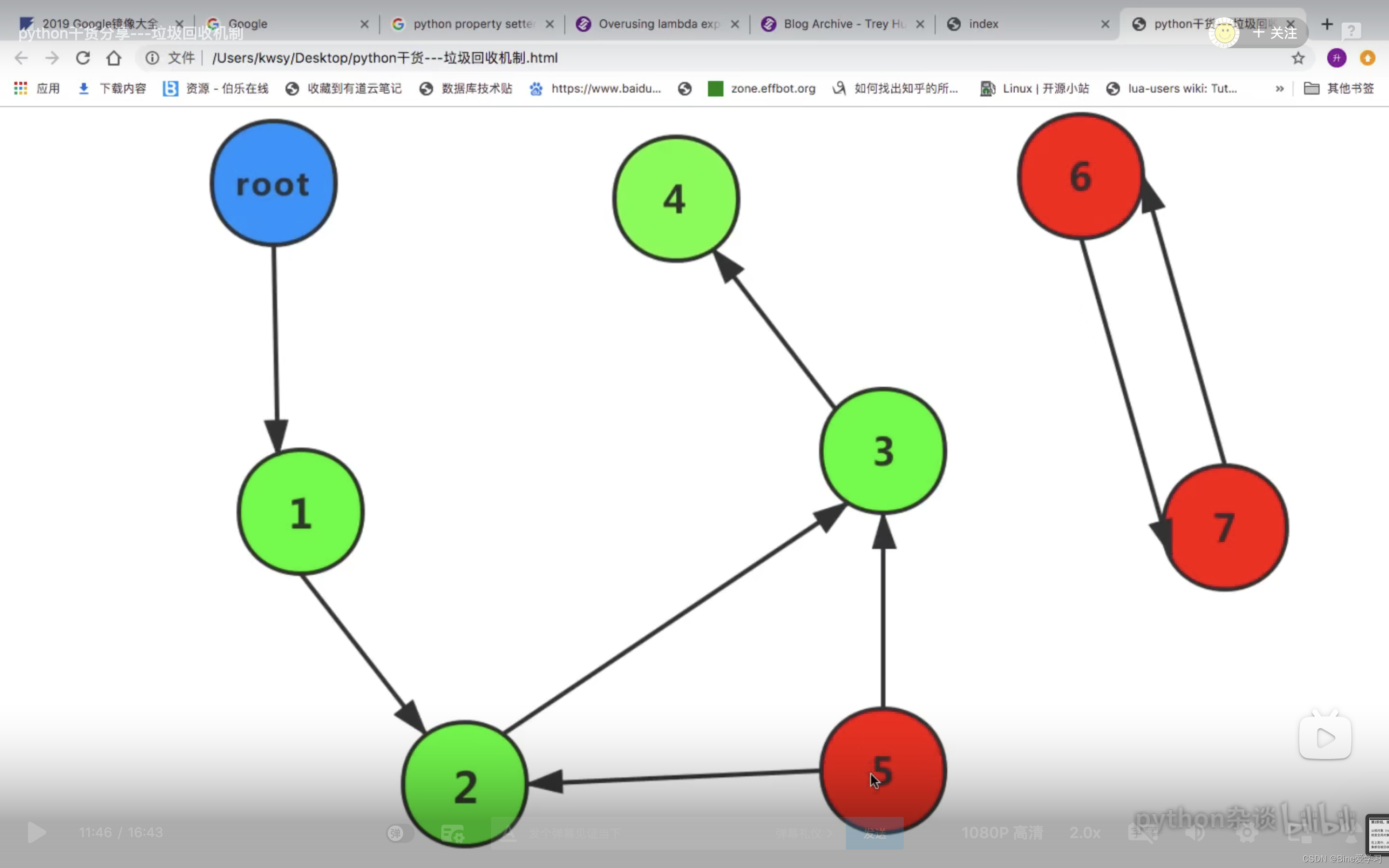
举例:对于一个有向图,如果从一个节点出发遍历,并标记每个经过的节点,那么在遍历结束后,所有没有被标记的节点,我们就称之为不可达节点。不可达节点会被回收。mark-sweep使用双向链表维护一个数据结构,并值考虑容器类对象。这里,我们介绍一种自动管理堆内存的算法:
Mark and Sweep Algorithm(标记清除算法)
Mark and Sweep Algorithm(标记清除算法)
一般而言,垃圾回收算法都会包含两个基本操作。
操作1,检测所有不可达对象;
步骤2,回收不可达对象所占用的堆内存。
Mark and Sweep Algorithm(标记清除算法)在下面两个阶段执行这两个操作:
1)Mark phase(标记阶段)
2)Sweep phase(清除阶段)
- Mark phase(标记阶段)
在对象创建时,设置它的标记位为0(false)。在Mark phase(标记阶段),我们设置所有可达对象的标记位为1。这一设置过程可以通过图遍历算法来完成,比如深度优先遍历算法。我们可以将每个对象看作图的一个结点,从每一个可达的结点出发,访问和它相连的没有被访问过的结点,并将这些结点标记为可达,然后递归访问与这些结点相连的没有被访问过的结点。
伪代码如下:
root变量引用了一个可以被局部变量直接访问的对象。这里我们假设只有一个root变量。
markedBit(obj)用来访问一个对象的标记位。
Mark(root)
If markedBit(root) = false then
markedBit(root) = true
For each v referenced by root
Mark(v)
提示:如果有多个root变量,对每个root变量调用Mark()即可。
- Sweep phase(清除阶段)
这一阶段将回收所有不可达对象所占用的堆内存。所有标记位为false的对象,会被清除,其余标记位为true的对象,会将其标记为设置为false。
伪代码如下:
Sweep()
For each object p in heap
If markedBit(p) = true then
markedBit(p) = false
else
heap.release(p)