1 前言
1.1 torch_geometric.data.Data
PyG 提供了torch_geometric.data.Data用于构建图,包括 5 个属性,每一个属性都不是必须的,可以为空。
Data(x, edge_index, edge_attr, y)
x: 存储每个节点的特征,形状是[num_nodes, num_node_features],一般是float tensor。
edge_index: 用于存储节点之间的边,形状是 [2, num_edges],一般是long tensor。
edge_attr: 表示边属性,shape: [num_edges, num_edge_features]
y: 存储样本标签。如果是每个节点都有标签,那么形状是[num_nodes, *];如果是整张图只有一个标签,那么形状是[1, *],一般是long tensor。
edge_attr: 存储边的特征。形状是[num_edges, num_edge_features]
pos: 存储节点的坐标,形状是[num_nodes, num_dimensions]
实际上,Data对象不仅仅限制于这些属性,我们可以通过data.face来扩展Data,以张量保存三维网格中三角形的连接性。
有了Data,我们可以创建自己的Dataset,读取并返回Data了。
1.2 torch_geometric.datasets 自带的数据集
PyG 的dataset继承自torch.utils.data.Dataset,自带了很多图数据集,我们以TUDataset为例,通过以下代码就可以加载数据集,root参数设置数据下载的位置。通过索引可以访问每一个数据。
from torch_geometric.datasets import TUDataset
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES')
data = dataset[0]
...
1.3 自定义数据集
除了使用benchmark数据集进行实验外,还可以自定义数据集,其方式与Pytorch类似,需要继承数据集类。PyG中提供了两个数据集抽象类:
torch_geometric.data.InMemoryDataset:用于构建内存数据集(小数据集),继承自Dataset,一次性加载所有数据到内存。
torch_geometric.data.Dataset:用于构建大型数据集(非内存数据集),分次加载到内存;
基于Data创建数据集的参数
root:string,保存数据集的路径。
transform:将Data类型的数据作为输入,并返回转换后的图。数据对象将在每次访问之前进行转换。
pre_transform:将Data类型的数据作为输入,并返回转换后的图。数据对象将在保存到硬盘之前进行转换。
pre_filter:将Data类型的数据作为输入,并返回布尔值。指示数据对象是否应包含在最终的数据集中。
2 继承InMemoryDataset构建内存数据集
2.1 需要实现的方法
在PyG中要构建自己的内存数据集需要先继承InMemoryDataset类,并实现如下方法:

raw_file_names():返回原始数据集的文件名列表,若self.raw_dir中没有该列表中的文件,则会通过download()进行下载;
processed_file_names():返回process()方法处理后的文件名列表,若self.processed_dir中没有确实该列表中的文件,则需要通过process()方法进行处理;
download():下载原始数据集到self.raw_dir中,在自定义数据集中一般pass掉。
process():写一个函数处理原始数据集成torch_geometric.data.Data的形式,并保存到processed_dir中,如果是图分类,还需要把多个图存成一个list。
注意:
①在前两个方法中,若只有单个文件,直接返回文件字符串即可,不一定要返回list对象。
②download和process只在第一次调用时会调用,之后会直接加载处理好的数据集。
以上4个方法并不都是需要的,例如如果你本地已经有了数据集,就不需要重写download()函数来下载原始数据集。
③self.raw_dir和self.processed_dir其实是两个方法,其源码为:
# 加上@property,可以使得方法像属性一样被调用
@property
def raw_dir(self) -> str:
return osp.join(self.root, 'raw')
@property
def processed_dir(self) -> str:
return osp.join(self.root, 'processed')
从源码可以看出,self.raw_dir和self.processed_dir是给定保存路径root下的原始数据文件夹和处理后的数据文件夹的路径。
2.2 例子
import torch
from torch_geometric.data import InMemoryDataset
class MyOwnDataset(InMemoryDataset):
def __init__(self, root, transform=None, pre_transform=None, pre_filter=None):
super(MyOwnDataset, self).__init__(root, transform, pre_transform, pre_filter)
self.data, self.slices = torch.load(self.processed_paths[0])
@property
def raw_file_names(self):
return ['some_file_1', 'some_file_2', ...]
@property
def processed_file_names(self):
return ['data.pt']
def download(self): # Download to `self.raw_dir`.
pass
def process(self):
# Read data into huge `Data` list.
data_list = [...]
if self.pre_filter is not None:
data_list = [data for data in data_list if self.pre_filter(data)]
if self.pre_transform is not None:
data_list = [self.pre_transform(data) for data in data_list]
# g = Data(edge_index=edge_index, num_nodes=4039)
# data, slices = self.collate([g])
data, slices = self.collate(data_list)
torch.save((data, slices), self.processed_paths[0])
注意
①如果需要在init里面初始化一些其他参数,如定义mask(划分训练集、验证集、测试集时),需要在super前继承参数,不然会失败无法传递到子函数里面。 举例:

②其余函数作用
data, slices = self.collate(data_list)
是通过self.collate把数据划分成不同slices去保存读取 (大数据块切成小块),便于后续生成batch。
所以即使只有一个graph写成了data, 在调用self.collate时,也要写成list形式:
data, slices = self.collate([data])
3 继承Dataset构建内存数据集
3.1 实现的方法
直接继承torch_geometric.data.Dataset,除了和InMemoryDataset相似的函数以外,需要多写两个函数
len():返回存储在 dataset 中的图的数目。
get():根据idx获取数据,即单个Data图。
注意:
①Dataset不会一次加载所有函数,而是分批,所有会把数据保存成好几个小数据包(.pt 文件),len() 就是说明有几个数据包,官方的写法:
def len(self):
return len(self.processed_file_names)
可以完全照搬,只需要改变processed_file_names的返回值,有几个数据包就写几个数据名。
②get()函数中的torch.load里的函数名要和processed_file_name()返回的函数名一致, idx就是数据包的遍历下标
def get(self, idx):
data = torch.load(osp.join(self.processed_dir, 'data_{}.pt'.format(idx)))
return data
3.2 例子
class MyOwnDataset(Dataset):
def __init__(self, root, transform=None, pre_transform=None, pre_filter=None):
super().__init__(root, transform, pre_transform, pre_filter)
@property
def raw_file_names(self):
return ['some_file_1', 'some_file_2', ...]
@property
def processed_file_names(self):
return ['data_1.pt', 'data_2.pt', ...]
def download(self):
# Download to `self.raw_dir`.
path = download_url(url, self.raw_dir)
...
def process(self):
idx = 0
for raw_path in self.raw_paths:
# Read data from `raw_path`.
data = Data(...)
if self.pre_filter is not None and not self.pre_filter(data):
continue
if self.pre_transform is not None:
data = self.pre_transform(data)
torch.save(data, osp.join(self.processed_dir, f'data_{
idx}.pt'))
idx += 1
def len(self):
return len(self.processed_file_names)
def get(self, idx):
data = torch.load(osp.join(self.processed_dir, f'data_{
idx}.pt'))
return data
3.3 几个容易出问题的地方
①继承InMemoryDataset时,在super继承之后,有一个读取数据的命令torch.load
由于继承Dataset, 在get()函数中实现torch.load数据,所以在super继承后不需要这条命令,否则会报错。
②不再调用self.collate()去划分数据包,也就没有data_list. 直接使用torch.save把一个个小数据包按照下标储存就好。

4 TUDataset自定义数据集实战
4.1 重新自定义TUDataset
运行内置数据TUDataset:
from torch_geometric.datasets import TUDataset
dataset = TUDataset('./', name="PROTEINS_full", use_node_attr=True)
next(iter(dataset)) # Data(edge_index=[2, 162], x=[42, 32], y=[1])
运行结束后,会生成以下文件:
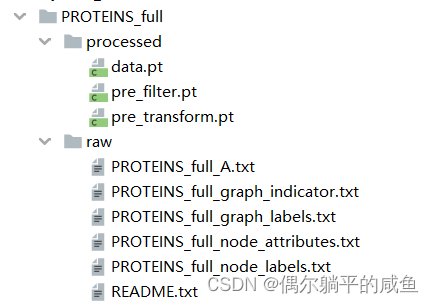
我们来分析一下数据
共1113个图,2个类别
_A.txt:(m,2);表示m条边 每行表示 (row, col) -> (node_id, node_id)
_graph_indicator.txt:(n,1),第 i 行表示第 i 个结点属于哪个图graph_id
_graph_labels.txt:(N,1),第 i 行表示第 i 个图的标签
_node_labels.txt:(n,1) 行, 第 i 行表示节点标签
_node_attributes.txt:(n, num_nodefeatures),第 i 行表示节点 i 的特征
根据以上数据,可以自定义数据集:
import torch
from torch_geometric.data import InMemoryDataset
from torch_geometric.io import read_tu_data
import os
class CustomDatset(InMemoryDataset):
def __init__(self, root='./PROTEINS_full', filepath='./PROTEINS_full/raw',
name='custom', use_edge_attr=True, transform=None,
pre_transform=None, pre_filter=None):
self.name = name
self.root = root
self.filepath = filepath
self.filenames = os.listdir(filepath)
self.use_edge_attr = use_edge_attr
self.pre_transform = pre_transform
self.pre_filter = pre_filter
super().__init__(root, transform, pre_transform, pre_filter)
self.data, self.slices = torch.load(self.processed_paths[0])
# self.slices:一个切片字典,用于从该对象重构单个示例
@property
def raw_dir(self):
"""默认也是self.root/raw"""
return self.filepath
@property
def processed_dir(self):
"""默认是self.root/processed"""
return os.path.join(self.root, self.name)
@property
def raw_file_names(self):
""""原始文件的文件名,如果存在则不会触发download"""
return self.filenames
@property
def processed_file_names(self):
"""处理后的文件名,如果在 processed_dir 中找到则跳过 process"""
return ['data.pt']
def download(self):
"""这里不需要下载"""
pass
def process(self):
"""主程序,对原始数据进行处理"""
self.data, self.slices, _ = read_tu_data(self.raw_dir, 'PROTEINS_full')
if self.pre_filter is not None:
data_list = [self.get(idx) for idx in range(len(self))]
data_list = [data for data in data_list if self.pre_filter(data)]
self.data = data_list
if self.pre_transform is not None:
data_list = [self.get(idx) for idx in range(len(self))]
data_list = [self.pre_transform(data) for data in data_list]
self.data = data_list
torch.save((self.data, self.slices), self.processed_paths[0])
运行:
if __name__ == '__main__':
dataset = CustomDatset()
print(dataset[0]) # Data(edge_index=[2, 162], x=[42, 32], y=[1])
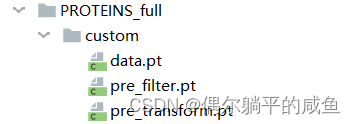
可以看到生成的数据保存到了processed_file文件夹下。
需要注意的是,我们根据原文件的txt形式调用函数read_tu_data()直接生成的(一般使用在图级别任务中),不同的原数据和任务有不同的处理方法,也可以在read_tu_data()直接进行修改。
4.2 DataLoader加载数据
通过torch_geometric.data.DataLoader可以方便地使用 mini-batch。
接着上面的例子:
from torch_geometric.data import DataLoader
from torch_scatter import scatter_mean
dataset = CustomDatset()
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for data in loader:
print(data) # DataBatch(edge_index=[2, 7268], x=[2001, 32], y=[32], batch=[2001], ptr=[33])
x = scatter_mean(data.x, data.batch, dim=0)
print(x.size()) # torch.Size([32, 32])
torch_geometric.data.Batch继承自torch_geometric.data.Data,并且多了一个属性:batch。batch是一个列向量,它将每个元素映射到每个 mini-batch 中的相应图。
我们可以使用它分别为每个图的节点维度计算平均的节点特征:
b a t c h = [ 0 , . . . , 0 , 1 , . . . , n − 2 , n − 1 , . . . , n − 1 ] T batch = [0, ..., 0, 1 ,...,n-2,n-1,...,n-1]^T batch=[0,...,0,1,...,n−2,n−1,...,n−1]T
4.3 模型训练
这里只是展示一个简单的 GCN 模型构造和训练过程,没有用到Dataset和DataLoader。
我们将使用一个简单的 GCN 层,我们依然使用上面定义好的数据集。
我们首先加载数据集:
from torch_geometric.data import DataLoader
# 1.load data
dataset = CustomDatset()
# 2. shuffle the data
dataset = dataset.shuffle()
# equal to
# perm = torch.randperm(len(dataset))
# dataset = dataset[perm]
# 3. 按照90/10 train/test 分割数据集
ld = int(len(dataset)*0.9)
train_set = dataset[:ld]
test_set = dataset[ld:]
train_loader = DataLoader(train_set, batch_size=128, shuffle=True)
test_loader = DataLoader(test_set, batch_size=128, shuffle=False)
然后定义用于图分类任务的 GCN:
import torch
from torch.nn import Linear
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.nn import global_mean_pool
class GCN(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super(GCN, self).__init__()
torch.manual_seed(12345)
self.conv1 = GCNConv(in_channels, hidden_channels)
self.conv2 = GCNConv(hidden_channels, hidden_channels)
self.conv3 = GCNConv(hidden_channels, hidden_channels)
self.lin = Linear(hidden_channels, out_channels)
def forward(self, x, edge_index, batch):
# 1. 获得节点嵌入
x = self.conv1(x, edge_index)
x = x.relu()
x = self.conv2(x, edge_index)
x = x.relu()
x = self.conv3(x, edge_index)
# 2. Readout layer
x = global_mean_pool(x, batch) # [batch_size, hidden_channels]
# 3. 分类器
x = F.dropout(x, p=0.5, training=self.training)
x = self.lin(x)
return x
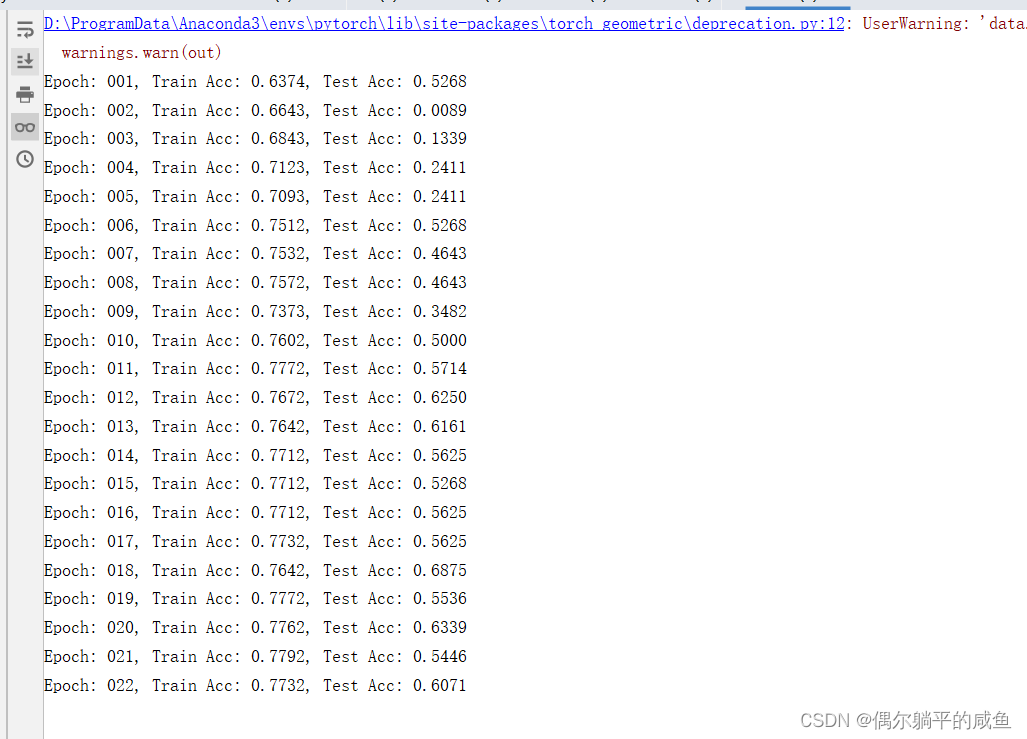
然后训练 200 个 epochs,并查看训练过程中的准确率。
input_dim = dataset.num_node_features
output_dim = dataset.num_classes
model = GCN(input_dim, 64, output_dim)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = nn.CrossEntropyLoss()
def train():
model.train()
for data in train_loader:
optimizer.zero_grad()
out = model(data.x, data.edge_index, data.batch)
loss = criterion(out, data.y)
loss.backward()
optimizer.step()
def test(loader):
model.eval()
correct = 0
for data in loader: # 批遍历测试集数据集。
out = model(data.x, data.edge_index, data.batch) # 一次前向传播
pred = out.argmax(dim=1) # 使用概率最高的类别
correct += int((pred == data.y).sum()) # 检查真实标签
return correct / len(loader.dataset)
for epoch in range(1, 121):
train()
train_acc = test(train_loader)
test_acc = test(test_loader)
print(f'Epoch: {
epoch:03d}, Train Acc: {
train_acc:.4f}, Test Acc: {
test_acc:.4f}')
5 其他
5.1 ransform、pre_transform和pre_filter
transforms在计算机视觉领域是一种很常见的数据增强。PyG 有自己的transforms,输出是Data类型,输出也是Data类型。可以使用torch_geometric.transforms.Compose封装一系列的transforms。我们以 ShapeNet 数据集 (包含 17000 个 point clouds,每个 point 分类为 16 个类别的其中一个) 为例,我们可以使用transforms从 point clouds 生成最近邻图:
import torch_geometric.transforms as T
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],
pre_transform=T.KNNGraph(k=6))
# dataset[0]: Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
还可以通过transform在一定范围内随机平移每个点,增加坐标上的扰动,做数据增强:
import torch_geometric.transforms as T
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],
pre_transform=T.KNNGraph(k=6),
transform=T.RandomTranslate(0.01))
# dataset[0]: Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
其中transform、pre_transform和pre_filter都是函数句柄,具体说明如下:
(1) transform接受参数类型为torch_geometric.data.Data,返回一个转换后的数据(数据类型不变),在每一次数据加载到程序之前都会默认调用进行数据转换。
(2)pre_transform接收参数类型为torch_geometric.data.Data,返回转换后的数据,在数据被存储到硬盘之前进行转换(只发生一次)。
(3)pre_filter接受参数类型为torch_geometric.data.Data,返回布尔类型结果,相当于对原始数据的一个mask。
可以看到InMemoryDataset中构造函数的参数,这三个函数参数都是None。如果要用pre_filter,就必须传递该参数,否则为None。