1.1 词典mdx文件资源下载
为实现搜索词的纠错的需求,我尝试维护本地的词典,从中寻找纠错替换词。
首先需要获取词典文件资源,将其下载到本地,给出两个词典资源的网址:
Index of /Recommend/汉英词典(第三版)/ (freemdict.com)
牛津 / 朗文 / 柯林斯 / 韦氏词典mdx词库文件 米斯特范工作室® (mrfan.org)
如果失效了可以自行搜索 寻找你所需要词典的mdx文件即可。
1.2 词典文件转文本
Python可以直接对mdx文件进行读取
但JAVA对mdx文件不便直接处理,我们利用转化工具,将其转变为txt文件。
工具名称叫做:GetDict
我把它放在了百度网盘里
链接: https://pan.baidu.com/s/1sM6qRIDYeofGef120E9rNQ?pwd=k6g7 提取码: k6g7
运行效果如下:
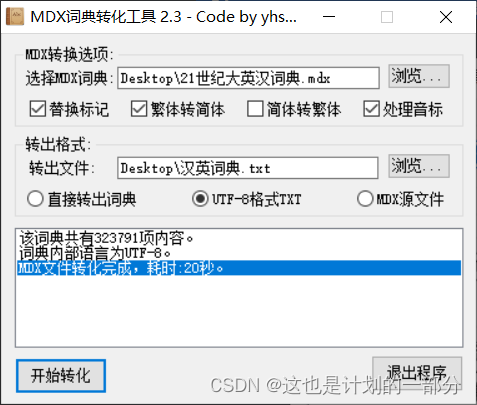
该文本文件规模较大,利用常规的 “记事本” “EXCEL” "Notepads"均无法正常打开。
1.3 词典大文本处理
使用Visual Studio Code 或者 EmEditor 都能够打开该大文本文件
Visual Studio Code - Code Editing. Redefined
不断点击下一步即可完成安装 打开文本后我们观察到如下界面:

利用替换功能 将HTML代码删除
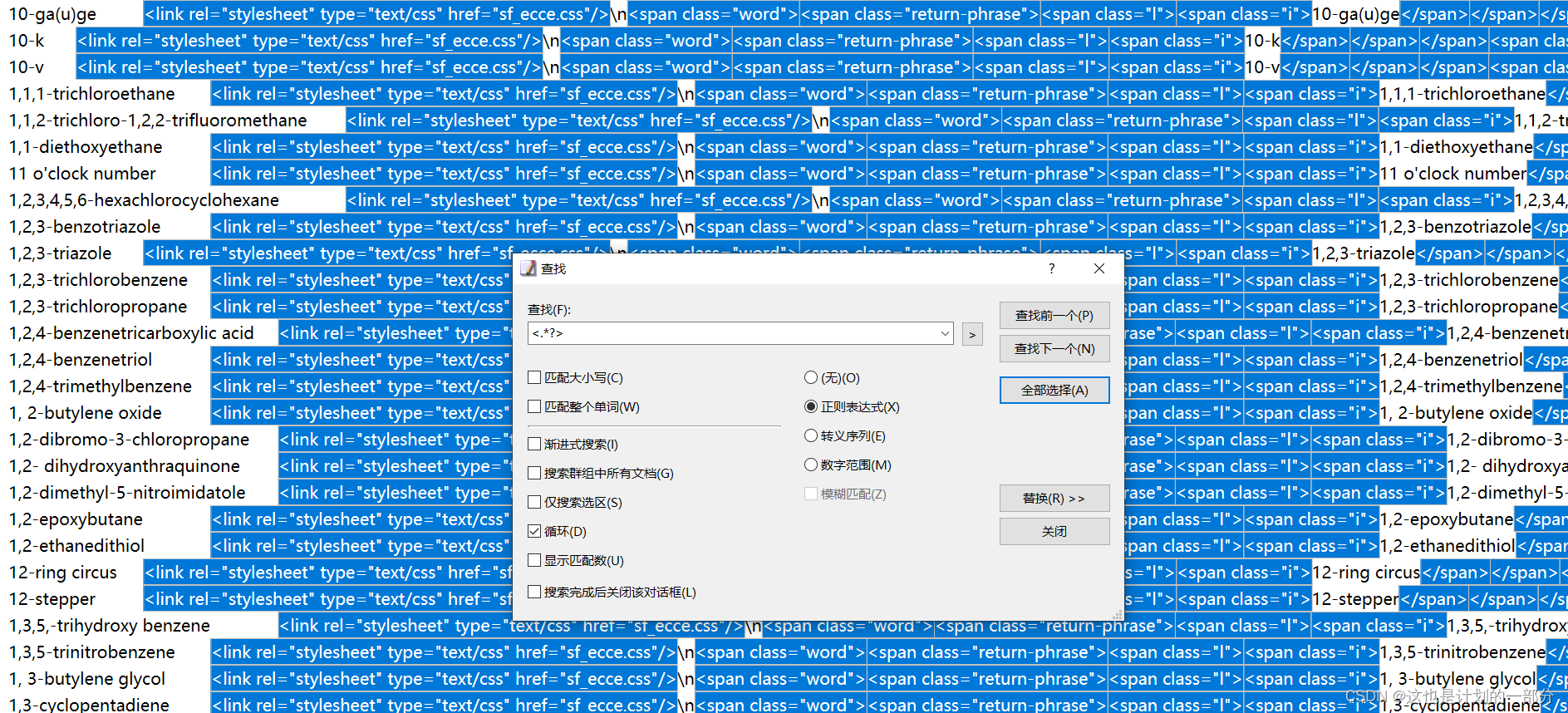
再次使用替换功能 去除换行符\n
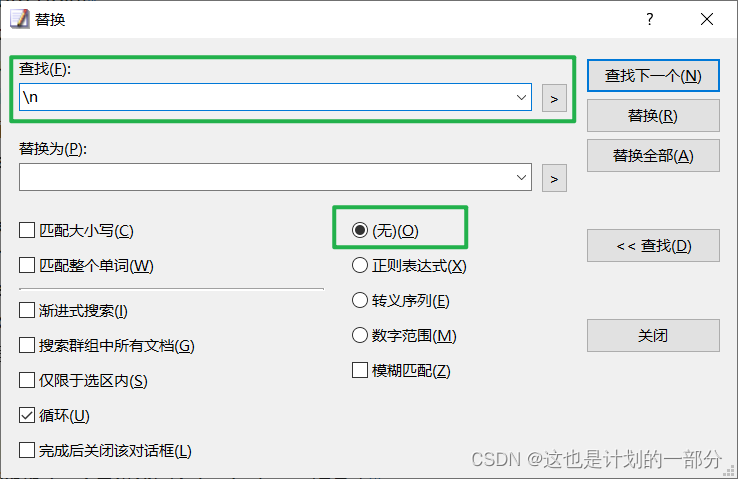
仅留下我们需要的英文单词及其释义。

1.4 词典文本转数据库
词典的行数较多 需要考虑查询速度的问题,因此我们不便直接查询文本文件 而需要建立数据库。
将混乱的文本转化为有逻辑组织的二维表也更助于我们之后的检错工作。
首先将上述词典文本文件的每个单词拆分各个组成部分

而后处理成SQL语句文件 便于快速建立数据库

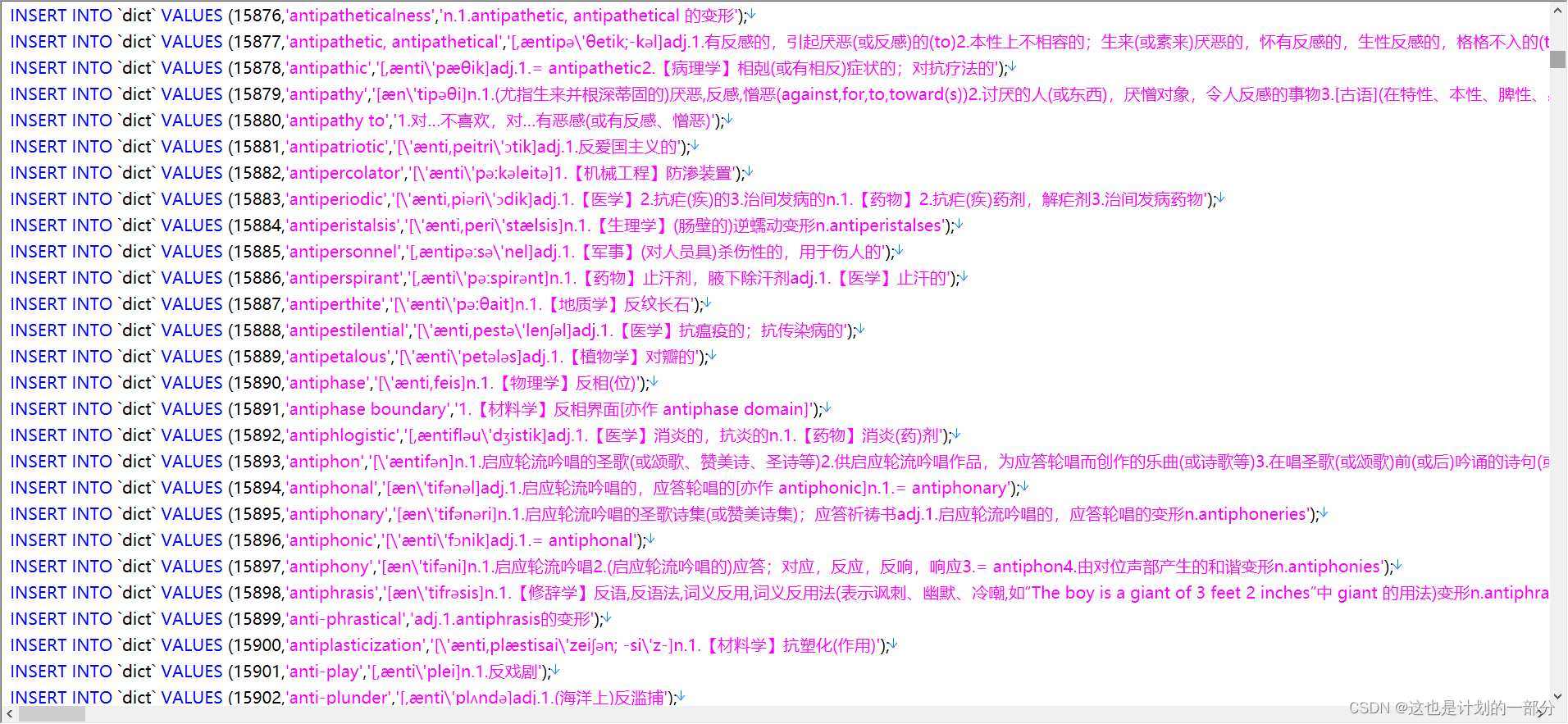
这部分处理的python代码 如下
# 处理词典文本文件 将其转化为数据库语句
fileHandler = open("21世纪大英汉词典.txt", "r", encoding="utf-8")
listOfLines = fileHandler.readlines()
fileHandler.close()
f = open("dict.sql", "a",encoding="utf-8")
i = 0
for line in listOfLines:
i = i + 1
word_list = line.strip().split("\t")
en = word_list[0]
ch = word_list[1].replace(en, "")
en = en.replace("'", "\\'")
ch = ch.replace("'", "\\'")
print("INSERT INTO `dict` VALUES (" + str(i) + ",'" + en + "','" + ch + "');",file=f)
f.close() # 关闭文件
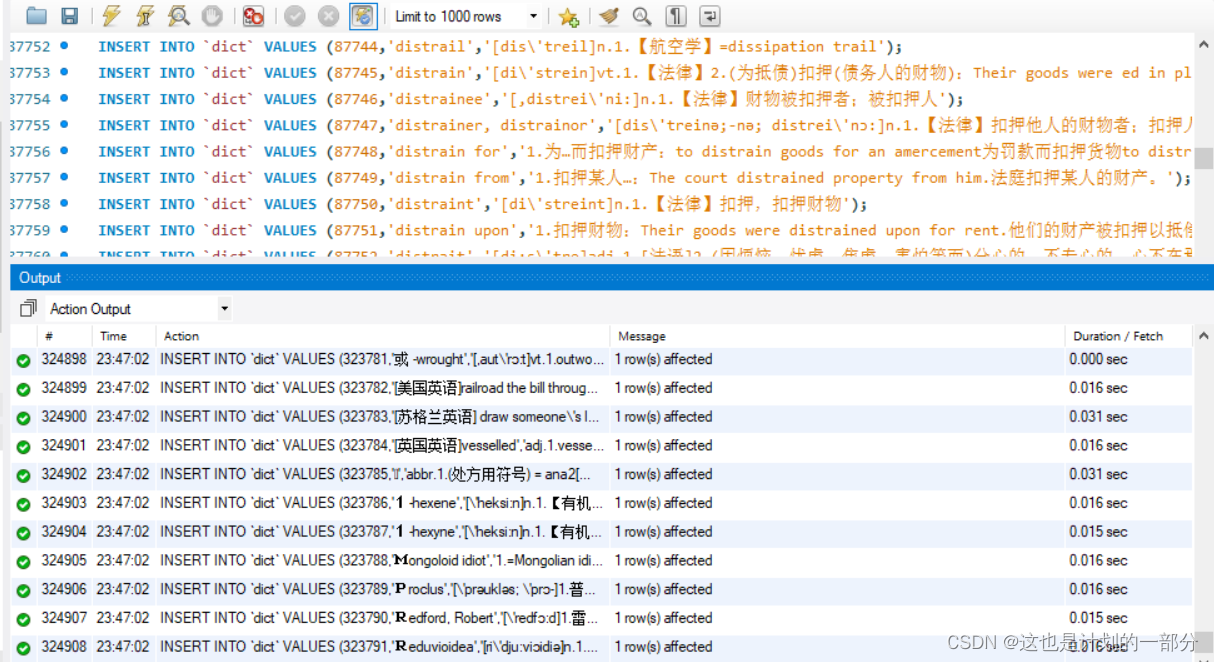
执行dict.sql里的语句即可完成词典表的建立,
这里时间较长,电脑慢的话40mins左右才能运行完。
或许用Python处理会快一些 我没有再进行尝试了。
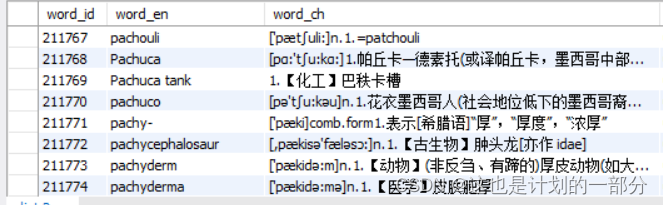
结果如下 共323791条记录:
1.5 词典数据库查询
建立数据库后 查询高效了许多
如查询所有字母p开头的单词/词组
SELECT * FROM `dict` where word_en like 'p%';