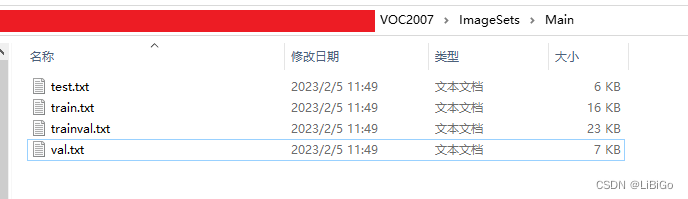
训练集、验证集、测试集按比例精确划分
创建py文件,将下属代码放入所创建的文件里,VOC2007数据集与py文件在同一目录下
# 数据集划分
import os
import random
root_dir = './VOC2007/'
## trainval_percent为 train 与 val在整个数据集中的比例
trainval_percent = 0.8
# train_percent 为 train在整个数据集中的比例
train_percent = 0.7
# 因此上述配置得到
## 0.7train 0.1val 0.2test
xmlfilepath = root_dir + 'Annotations'
txtsavepath = root_dir + 'ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml) # 100
list = range(num)
tv = int(num * trainval_percent) # 80
tr = int(tv * train_percent) # 80*0.7=56
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(root_dir + 'ImageSets/Main/trainval.txt', 'w')
ftest = open(root_dir + 'ImageSets/Main/test.txt', 'w')
ftrain = open(root_dir + 'ImageSets/Main/train.txt', 'w')
fval = open(root_dir + 'ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
实验结果