写在前面:北京冬残奥也已闭幕,雪容融也已经下班了。本届冬残奥会,中国体育代表团以18金、20银、23铜总计61枚奖牌排名金牌榜和奖牌榜榜首,实现了历史性超越。作为冬奥官方转播商,我们努力通过技术创新给观众带来更佳的观赛体验,前几期和大家分享了第三代数字音视频编解码技术(AVS3)、暖心的实时智能字幕、色彩鲜活灵动的HDR Vivid技术和超写实虚拟数字人技术,接下来跟大家介绍一下我们的智能推荐是如何捕获用户所想,精准地将用户喜爱冬奥节目传递给用户。
作者,李琳,单华琦,灯塔
背景
生产和消费是人类经济活动的主题,如何高效地将生产的内容投递到消费者,一直是经济活动的重要环节。内容供需关系的变化,决定了内容投递机制的变化。随着移动互联网的快速发展,我们进入了信息爆炸时代。一方面,信息过载,当前通过互联网提供服务的平台越来越多,相应提供的服务种类(购物,视频,新闻,音乐,婚恋,社交等)层出不穷,服务内容的种类也越来越多样,这么多的内容怎么让需要它的人找到它, 满足用户的各种需要成为了一个难题。另一方面,个性化需求,随着社会的发展和受教育程度的提升,表现自我个性的欲望不断提升。当前出现了很多表达自我个性的产品,如微信朋友圈,微博,抖音,快手等,每个人的个性喜好特长有了极大展示的空间。“长尾理论”也很好地解释了多样化物品中的非畅销品可以满足人们多样化的需求。
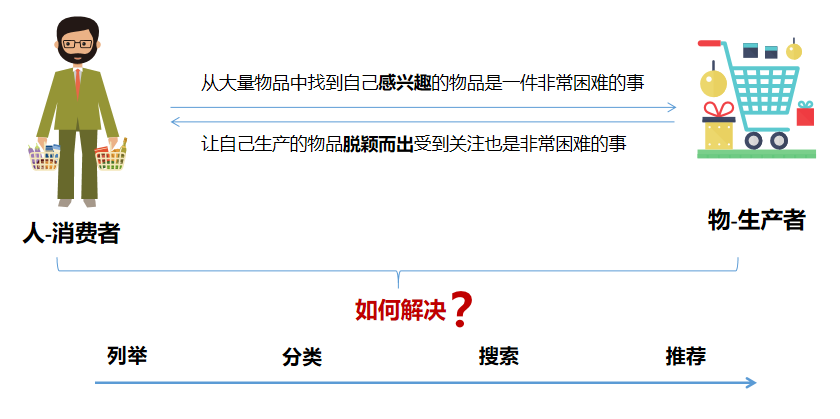
图1 智能推荐出现的背景
个性化的智能推荐就是为了解决了以上问题而出现的,如果说互联网的目标是连接一切,那么智能推荐系统的作用就是建立更加有效率的连接,因为它可以更有效率的连接用户与内容和服务,节约了大量的时间和成本。智能推荐是移动互联网时代非常成功的人工智能技术落地场景之一。
当前在广告、电商、长短视频分发等互联网业务场景中,推荐系统的推荐算法发挥着至关重要的作用。好的推荐算法能够把用户牢牢抓住。国外诸如Google、Facebook、亚马逊,国内诸如阿里巴巴、京东、腾讯等公司,都将推荐系统建设成为了公司的一项基础能力,足以证明一个成熟工业级的推荐系统在互联网产品中的重要性。
在这次冬奥会,咪咕视频因为王濛解说出圈,大量用户进入咪咕视频,但奥运赛事项目比赛多种多样,衍生出的短视频成千上万,我们就是通过智能推荐,将用户感兴趣的奥运赛事和娱乐内容精准展示给用户,取得了不错的效果。
本文结合我们的应用实践,基于目前主流的、在工业界最常用的推荐系统结构给大家介绍一下核心技术和算法。
关键技术
推荐系统技术,总体而言,与 NLP 和图像领域比,发展速度不算太快。不过最近两年,由于深度学习等一些新技术的引入,有了比较明显的提升。
工业推荐系统大致分为召回和排序两个阶段。首先是召回,主要根据用户部分特征,从海量的物品库里,快速找回一小部分用户潜在感兴趣的物品,然后交给排序环节,排序环节可以融入较多特征,使用复杂模型,精准地做个性化推荐。召回强调快,排序强调准。但是随着数据量级不断扩大,每个用户召回环节返回的物品数量还是太大,为了提升排序的效率将排序过程拆分成粗排、精排和重排三个环节。首先是粗排,就是通过少量用户和物品特征,简单模型,召回的结果进行个粗略的排序,在保证一定精准的前提下,进一步减少往后传送的物品数量,粗排是可选的,如果候选集已经较小可以不用。之后是精排环节,使用尽可能全的特征,可以选用系统极限所能承受的复杂模型,尽量精准地对物品进行个性化排序。最后是重排,通过各种技术实现产品营销策略或者改进用户体验,比如去已读、去重、打散、多样性保证、固定类型物品插入等等。
![]()
图2 推荐系统中的级联结构框架
接下来将逐一详细介绍结构中每个节点实现的关键技术以及具有代表性的算法。
召回
通常,待推荐的物品候选集达到千万级甚至上亿级,给每个⽤户计算推荐结果时,对全部物品挨个计算评分,那将是⼀场灾难。取⽽代之的是⽤⼀些策略和算法从全量的物品中筛选出⼀部分相关度较高的,这个过程就是召回。如何快速地从这些海量的候选集中寻找用户感兴趣的内容是召回环节需要解决的关键问题。召回环节涉及的相关算法经历了从热销排序、基于内容的召回、协同过滤、矩阵分解等统计学习方法的发展过程。如今,随着深度学习的发展,将深度学习技术引入到召回环节,成为了工业界最常用的做法。2019年,Google提出了一种基于“双塔”模型的深度神经网络算法,将用户和待推荐内容进行向量化,并通过向量检索技术进行召回实现。该方法目前是业界最流行的一种召回算法。下面介绍一下基于“双塔”模型召回系统的工作方式。
![]()
图3 双塔召回模型
首先介绍一下双塔模型的结构。模型正向推导时,将用户侧的特征喂入一个深度神经网络(DNN),见上图左侧塔,得到一个用户嵌入向量(user embedding)。将物品侧的特征喂入一个DNN,见上图右侧塔),得到一个物品嵌入向量(item embedding)。拿user embedding与item embedding,在“塔顶”做点积(欧几里得空间的标准内积)或求余弦距离(cosine),得到的值就可以代表user 和 item之间的匹配程度。通过构造合适的损失函数,在训练的时候经过神经网络的反馈传递方式减少损失函数的损失值,更新模型的参数,获得优化模型。
双塔模型最大的特点就是“双塔分离”,带来的最大好处在于将用户集和物品集分离。海量的item embedding,可以通过离线的方式,周期性、批量地生成数据集,然后存放到向量索引库中。等到需要为用户进行物品召回时,仅需要将用户特征转换成user embedding,到向量索引库进行检索即可。像这样,向量检索的召回方式提升了处理效率,降低实时处理的要求,从而降低工程实现的难度,大大减轻了线上服务的压力。
粗排
如前文提到的,当召回候选集数量太大的时要先经过粗排环节。为了提升排序效率,粗排选用简单模型,基于用户和物品少量特征快速输出候选集排序结果。实时推荐系统中,粗排仍然是效率优先,一般需要在10~20ms内完成。巨大的候选集以及严格的服务延时需求要求我们设计的粗排模型结构不能太复杂。粗排在工业界的发展历程可以分成下面几个阶段:
第一代粗排时依据静态质量分。根据业务目标,实时统计候选集的关键指标,如点击率、完播率、付费转化等物品侧的信息,以这些指标作为粗排序的依据。这种方式虽然表达能力有限,但是实现简单。
第二代粗排是以逻辑回归(Logistic Regression,LR)为代表的早期机器学习模型,模型结构简单,有一定的个性化表达能力,可以在线更新和服务。
当前应用最广泛的第三代粗排模型,是基于向量内积的深度模型。和召回一样,模型结构一般为双塔结构。模型训练阶段和召回环节无异,同样是通过离线的方式周期性、批量完成item embedding,将结果存放在键值对(KV)结构的存储中。线上接到粗排请求后,首先从KV存储中将候选集item embedding取出,然后和user embedding逐一做点积或求余弦距离得到用户和物品的匹配度得分,并根据得分降序排列,将TopN的候选集送入精排环节。
粗排模型的求解还有另外一种方式,就是利用知识蒸馏技术,将精排模型(teacher模型,结构复杂) 学习到的知识,通过知识迁移的方式传递给粗排模型(student模型,结构简单), 这样既能保证粗排模型拥有精排模型的预测能力,同时因为粗排模型结构简单,又能满足线上服务对效率的要求。
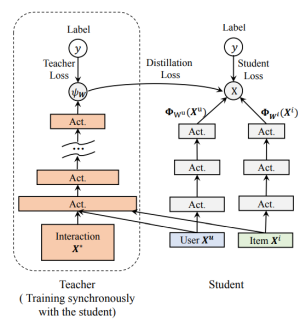
图4 知识蒸馏在粗排模型训练中的应用
精排
在粗排大大降低了候选集数量之后,精排阶段会建立相对精细的模型,根据用户的画像、偏好、上下文、结合业务目标进行精度更高的排序。排序的依据,通常是预测用户对于候选集物品是否点击的概率值。不同于上文所述的召回模型结构,精排模型通常从最底层用户和物品信息就需要开始产生交叉。用户信息必须与每一个候选集对象过一遍排序模型,为每一个对象计算一个排序分值。
精排模型的发展可以从不同角度来总结。从特征工程的角度,也就是从原始数据中筛选出更好的数据特征以提升模型的训练效果的角度,可以归纳为从简单的手工特征交叉到让模型可以自动学习特征交叉的过程。从用户行为序列特征表达角度,可以归纳为从静态特征到用户在时间维度上的行为序列、子序列、模糊序列的过程。从建模目标角度,可以归纳为从单一学习目标到多目标、多场景、多模块学习的过程。这里介绍目前团队中应用最为广泛的一种精排模型,DeepFM(Deep Factorization Machine,深度因式分解机)。
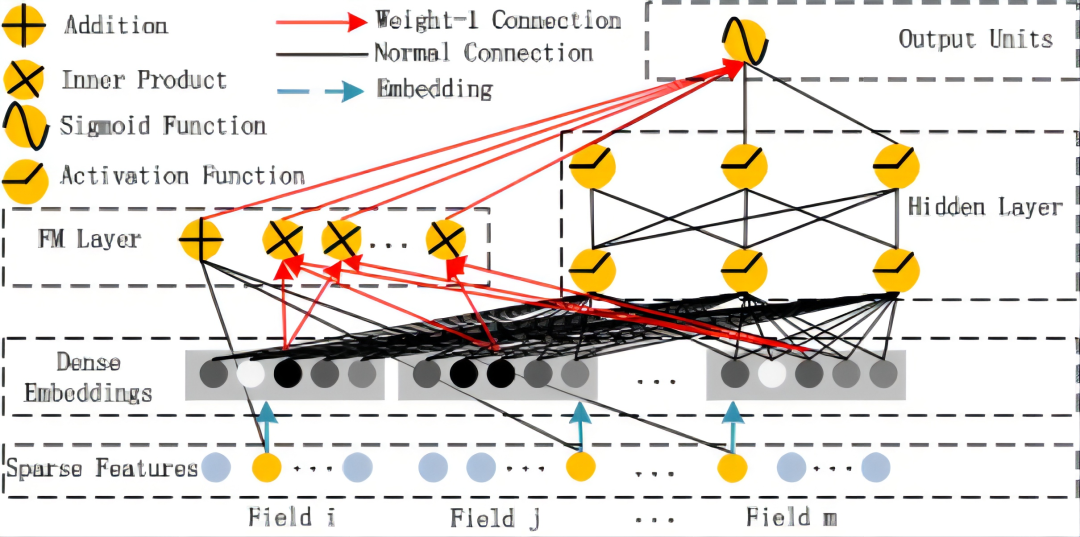
图5 DeepFM模型结构
DeepFM在结构将FM结构和DNN结构相结合。其中FM部分作为一种浅层结构,负责学习用户行为的隐式low-order特征,使得模型具备“记忆“的能力。同时它具备自动学习交叉特征的能力,减少了人工参与特征工程的工作。DNN部分通过多层神经网络交叉,学习到用户的隐式high-order特征,使得模型具备更强的”泛化“能力。
重排
精排模型通常学习的是物品单文档方法(pointwise)的得分,直接根据精排分数排序,无法考虑多个商品间的影响,同时物品同质化严重,这样会导致推荐出的物品缺少多样性、发现性,用户体验会较差。这就需要我们对精排序后的推荐结构进行重排序,让用户发现多种物品或者新的兴趣。
目前主流的多样性算法如下,有界贪心选择策略(Bounded Greedy Selection Strategy,BGS)、最大边际相关性算法(Maximal Marginal Relevance,MMR)、行列式点过程方法(Determinantal Point Process,DPP)、改进格拉姆施密特正交化方法(Modified Gram-Schmidt, MGS)等。这些算法基本都是围绕用户和物品的相关系数和物品和物品的相似系数,来进行多样性结果的生成。其中DPP最具有代表性,也是目前团队内主要使用的多样性结果生成算法,下面详细介绍一下DPP。
DPP是通过核矩阵(kernel matrix)的行列式计算每一个子集的概率。该概率可以理解为用户对推荐列表满意的概率,受到相关性与多样性两个因素的影响。我们使用最大后验概率推断,每次从候选集合中贪心的选择一个使得边际收益最大的商品加入的推荐列表中,直到满足停止条件。
我们的优化
一套经典算法的应用从来都不是一成不变的,针对特定场景下的特定业务问题,核心算法模块需要在前人的工作基础上做创新优化以适配新的业务目标。因此,我们在基础模型基础上结合自己的业务做了优化和创新。
首先,传统的”千人千面”推荐算法已经不能满足用户诉求,咪咕公司结合自身业务和技术特点,通过自研业界领先的多兴趣深度学习推荐模型咪咕长短期兴趣模型(MG-SDM)和咪咕多专家网络兴趣模型(MEMI),实现了推荐结果从”千人千面”到“千人万面”的提升。
其次,实现外部多方数据源融合的高价值内容挖掘。基于爬虫和流式处理技术实时获取外部热点,应用业界前沿的深度时序语言表征模型结合智能算法实现外部热点到端内高价值内容的精准匹配和智能分发。运用该技术实现了奥运热点内容如中国夺金相关内容的智能快速分发,较传统运营时效性提升10倍,有效提升用户体验。
产业应用
随着大数据和人工智能相关产业的发展,推荐系统领域的相关技术也得到了长足的进步。推荐系统广泛应用于各行各业,比如电商、长短视频、社交网络、金融保险、餐饮美食、旅游出行等各行各业。国内外大厂在相关技术领域投入了大量的人力物力,因为在足够大的流量基础上,千分位关键业务转化指标的提升,也可以带来足量的收益。
推荐系统的常见应用场景包括:电子商务、个性化广告、音乐和电影、求职等。电商领域的推荐系统有很广泛的应用场景。以淘宝为例,其主要推荐功能有:相关商品、店铺推荐、买了还买、看了还看、猜你喜欢等。在音乐行业如“私人FM”和“每日歌曲推荐”是综合了用户听歌记录、收藏的歌曲、歌单、歌手、收看的MV以及本地歌曲等多种因素,再经过多重计算之后给出的相关推荐结果。网易云音乐还设置了“每日推荐”条目,以便收集用户的每日行为数据,不断地完善和丰富用户画像。尤其在精准营销领域,围绕消费者用户标签进行,包含个性化推荐及智能广告营销。个性化推荐依靠推荐系统算法向消费者提供个性化的信息服务和决策支持,基于深度学习技术的推荐系统可以提高推荐质量,促进营销转化;智能广告营销主要包括广告精准投放和AI视频营销。
![]()
图6 智能推荐在精准营销领域应用
目前这些具有代表性的技术,我们已经应用在咪咕的多个业务,包括咪咕视频、咪咕音乐的内容分发,获得了不错的收益。在冬残奥期间,在冬残奥期间日均支撑咪咕视频超3千万次推荐请求,全场景曝光超1亿次,用户转化率高达85%,并成功将冬残奥期间多个爆款内容实时分发至感兴趣的用户,在满足用户体育赛事需求同时满足了用户影视综娱乐等其他多面性的需求,精准推荐了《冰球少年》、《运动者联濛》等娱乐内容,有效满足了用户在观赛之余的兴趣偏好延展性,实现内容价值的最大化。
图7 我们智能推荐的应用样例
展望
推荐系统作为一种高效的信息过滤工具,可以很好地解决用户精准高效获取信息的问题,也是非常重要甚至是不可或缺的一种手段,展望未来有着巨大的机会。
从主流技术上看,智能推荐的发展趋势如下。数据层面,分布式、流式计算的发展使得推荐系统能够更快地训练更多的数据;系统层面,随着各类深度学习框架的广泛应用,底层硬件技术的迭代,生产推荐模型的过程变得更加的高效;算法层面,随着人们对数据中蕴含丰富信息的深入理解,推荐相关算法也从基于矩阵的推荐算法,发展到了基于序列结构、图结构的相关算法,以及结合知识图谱、多模态信息融合等提升算法理解力。
从行业发展来看,随着国家政策,新业态、新场景的发展变化,推荐系统将会有更多新的发展方向和新的要求。近十年,云计算基础设施已经成熟,推荐系统建设将变得简单,创业公司利用云平台提供的各种SAAS服务就可以轻松搭建推荐系统各个模块,大大降低了推荐系统的准入门槛。这使得推荐系统将不仅可以服务于ToC端,也可以服务于ToB端。随着家庭、车载、VR、AR、MR等场景智能应用更加成熟,这些场景中的应用也可能需要借助推荐技术来进行信息的分发,而推荐系统的建设也会面临新的问题。比如在智能电视场景,推荐系统怎么更好地跟用户交互、怎么识别多人场景并提供精准推荐能力;再比如在基于VR、AR、MR的元宇宙应用场景,推荐系统如何进行跨域推荐,将虚拟域和现实域融合,使用户可以获得无缝的推荐体验。以上问题有待行业的从业者们努力探索和实践。
随着智能推荐新技术在各个行业的深度应用,也面临着挑战。2021年8月27日,互联网信息办发布《互联网信息服务算法推荐管理规定(征求意见稿)》并公开征求意见。目的是规范互联网算法推荐活动,治理“大数据杀熟”、“饭圈文化”等互联网乱象。明确了平台作为算法推荐内容的责任主体,旨在突破信息茧房,保障用户的选择权与知情权。当前美欧等西方国家也已经着手对谷歌等大型互联网公司的算法进行规范。面对这个形势,我们需要提升算法治理能力,让推荐系统的内部逻辑更为透明,不再被当作"黑匣子",让推荐结果有据可依。未来,用户可交互式的推荐系统是有价值的研究方向之一。