一、Elastic介绍
Elastic有一条完整的产品线及解决方案:Elasticsearch、Kibana、Logstash等,前面说的三个就是大家常说的ELK技术栈。实现企业海量日志的处理分析的解决方案。大数据领域的重要一份子。
Elastic官网:https://www.elastic.co/cn/
文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.6/index.html

二、下载
我们只需要用到elasticsearch和kibana,es还需要中文的处理插件ik分词器,我们选择讲解的版本是7.6.2的,kibana、elasticsearch和IK分词器的版本号要一致,否则可能带来兼容性问题。另外,es需要jdk1.8以上的环境(虚拟机中必须安装jdk并配置了环境变量)
下载地址如下:
elasticsearch:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
kibana地址:https://www.elastic.co/cn/downloads/past-releases#kibana
ik中文分词器地址:https://github.com/medcl/elasticsearch-analysis-ik/tags
三、安装elasticsearch
1. 资料拷贝到虚拟机/usr/local/elastic目录下
mkdir elastic
2. 安装 elasticsearch
rpm -ivh elasticsearch-7.6.2-x86_64.rpm
安装成功后,警告:需要JDK11,而虚拟机准备的是JDK1.8
3. elasticsearch配置jdk
解决JDK问题:使用 elasticsearch 自带的JDK
vim /etc/sysconfig/elasticsearch修改内容 JAVA_HOME=/usr/share/elasticsearch/jdk

4. elasticsearch配置
切换到 /etc/elasticsearch/ 目录下,看到两个配置文件 jvm.options 和 elasticsearch.yml
① 首先修改jvm.options
elasticsearch默认占用所有内存,导致虚拟机很慢,可以改的小一点。
vim /etc/elasticsearch/jvm.options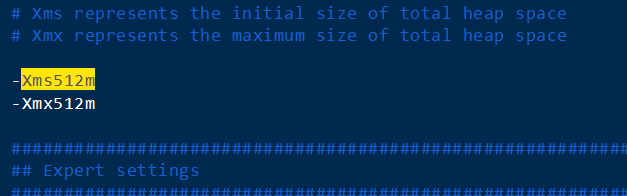
② 再修改elasticsearch.yml
修改yml配置的注意事项:每行必须顶格,不能有空格, ":"后面必须有一个空格
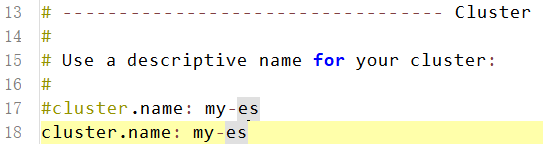
vim /etc/elasticsearch/elasticsearch.yml(1)集群名称,同一集群名称必须相同(集群配置)
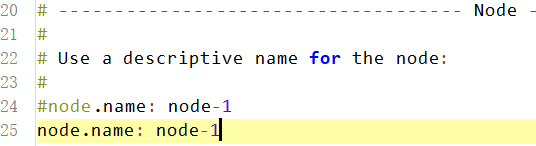
(2)单个节点名称 (集群配置)
(3)如果配置集群了,一定要设置当前节点为主节点

(4)保存es数据和日志文件的目录(不修改,使用默认的)
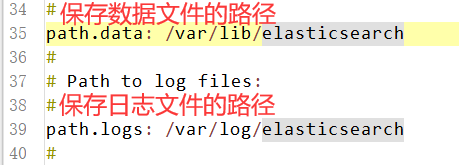
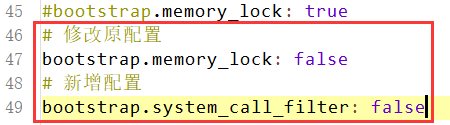
(5)把bootstrap自检程序关掉(提高启动速度)
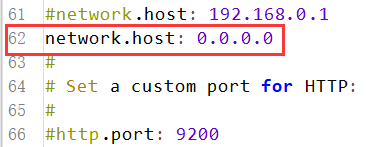
(6)默认只允许本机访问,修改为0.0.0.0后则可以远程访问;端口使用默认:9200
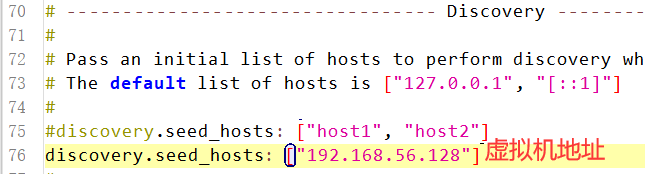
(7)配置集群列表,这里只有一个。可以配置计算机名,也可以配置ip,推荐ip主机名是你计算机名,一定不可以写错!!
(8)elasticsearch服务器硬盘剩余空间不足5%,会抛出cluster_block_exception异常,在elasticsearch.yml最后配置取消硬盘检查:(新增)

③ 设置es访问配置文件的权限
chmod -R 777 /etc/elasticsearch/ 5. 启动elasticsearch
cd /etc/elasticsearch/systemctl start elasticsearch.servicesystemctl status elasticsearch.service -l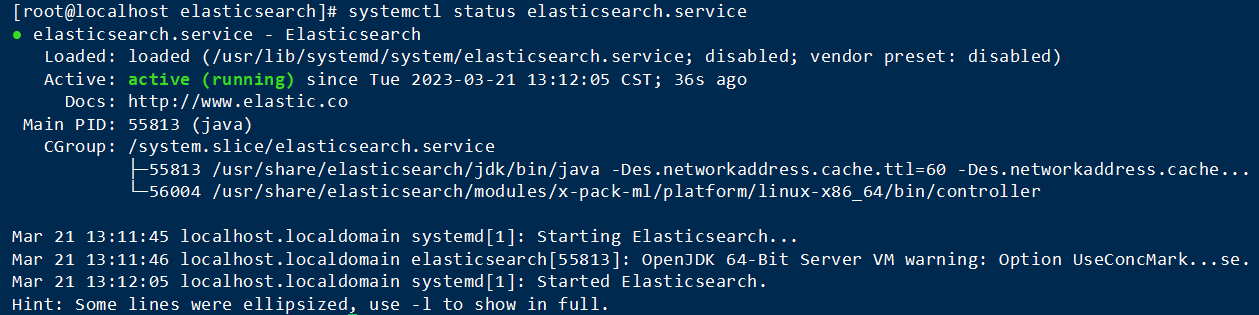
如果启动未成功,请去查看相关日志 cat /var/log/elasticsearch/{cluster-name}.log
例如:这里cluster-name配置的是my-es,那么就是指:
cat /var/log/elasticsearch/my-es.logtail -n行数 -f 日志文件名
一般是配置文件的错误,按照上面的配置检查一遍
6. 测试
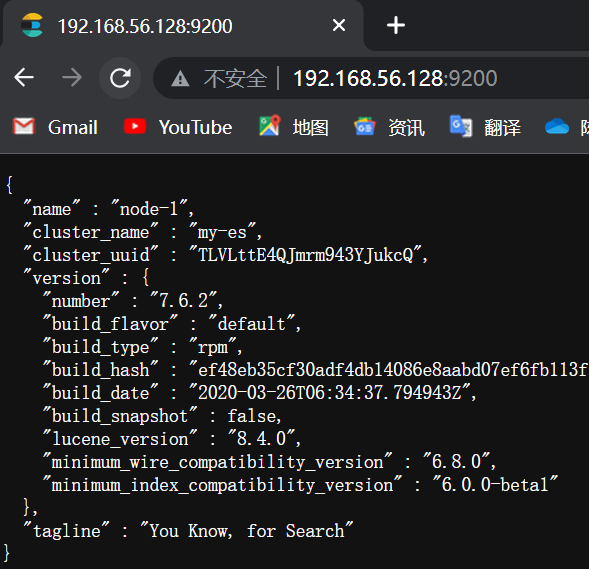
如果访问失败:
原因1:防火墙可能没有关闭
原因2:配置文件 network.hosts 修改错误或者 集群节点主机名配置错误
四、安装kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。
1. 进入压缩包存放目录
cd /usr/local/elastic/2. 解压缩
tar -zxvf kibana-7.6.2-linux-x86_64.tar.gz3. 重命名
mv kibana-7.6.2-linux-x86_64 kibana
4. 切换进config目录配置
cd kibana/config/vim kibana.yml① 默认端口号:5601(不更改)
② 修改配置文件为虚拟机IP地址,允许访问的ip地址

③ 配置elasticsearch服务器列表

④ 设置中文简体:打开页面是中文

⑤ 启动:切换到kibana的bin目录下
cd ..
cd /bin(1) 会输出日志,并独占当前窗口(--allow-root表示允许使用root用户启动)
./kibana --allow-root 
(2) 后台启动
nohup ./kibana --allow-root &注意:不要使用
ps -ef|grep kibana查询kibana进程,因为kibana的进程不叫kibana解决:
ps -ef|grep node
5. 启动测试
必须先启动 elasticSearch后,再启动kibana才可以访问
通过浏览器访问 kibana:http://192.168.56.128:5601/


五、安装ik中文分词器
1. 进入资料存放的目录
cd /usr/local/elastic/2. 将其移动到指定目录下
mv elasticsearch-analysis-ik-7.6.2.zip /usr/share/elasticsearch/plugins/3. 进入到指定目录下
cd /usr/share/elasticsearch/plugins/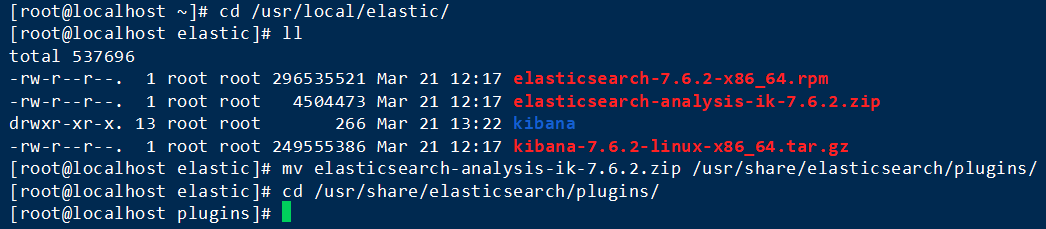
4. 解压文件
没有unzip命令执行下面命令进行下载
yum install unzip -yunzip elasticsearch-analysis-ik-7.6.2.zip -d ik-analyzer解压完成后,删除压缩包!
rm -vf elasticsearch-analysis-ik-7.6.2.zip
5. 重启elasticsearch
systemctl restart elasticsearch.service六、配置ik自定义词库
1. 进入ik分词器根目录的config目录
cd /usr/share/elasticsearch/plugins/ik-analyzer/config/2. 打开该配置文件
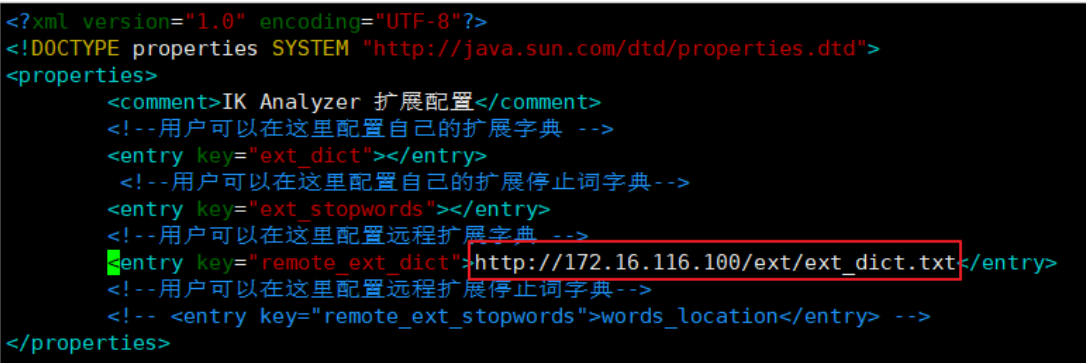
vim IKAnalyzer.cfg.xml 这里有两种方式配置扩展词典和停用词典:
本地方式:ext_dict配置扩展词典,ext_stopwords配置停用词典。
远程方式:tomcat或者nginx
第一种方式每次修改词典都要重启搜索服务,不推荐。
推荐使用nginx的方式,并发量大,修改内容不需要重启。

3. 第一步:利用nginx搭建远程词库
vim /usr/local/nginx/conf/nginx.conf
4. 需要在nginx根目录下创建对应的elasticsearch目录
mkdir -p /usr/local/nginx/elasticsearch/ext
# 创建扩展字典文件
vim /usr/local/nginx/elasticsearch/ext/ext_dict.txt

5. 添加扩展词典,每行一个关键词
鸡你太美
咖喱人
你真老六
碉堡了
喜大普奔
6. 访问地址测试
7. 第二步:在ik分词器中引用远程词库
进入ik分词器的conf目录:cd /usr/share/elasticsearch/plugins/ik-analyzer/config/
vim /usr/share/elasticsearch/plugins/ik-analyzer/config/IKAnalyzer.cfg.xml