阿里云盘搜索引擎项目架构图
本项目存属于个人项目,因此考虑因素侧重方向不同于企业产品,会更倾向于节省成本方向,尽量保证稳定性。

为了完成这个项目,其实考虑了不止下面两个方案,这里包括:
- 搜索引擎选择: 尝试过 玩具版的meiliSearch / 直接用MongoDB 和最终选择的Elasticsearch
- 爬虫代理池的构建: 必须是高匿名的,否则爬着爬着IP请求就会被限制,而且代理池的节点IP量越多并发就越多,爬取数据就越快。
接下来,就简单的说下两个备选方案.
方案一
处于数据稳定性考虑,增加了MongoDB作为数据持久化方案。
- 数据持久化: mongo复制集(三节点)
- 搜索引擎: Elasticsearch集群(三节点)
- 爬虫服务缓存: Redis缓存爬虫结果数据,之后通过Transfer服务同步至MongoDB。
架构图如下:
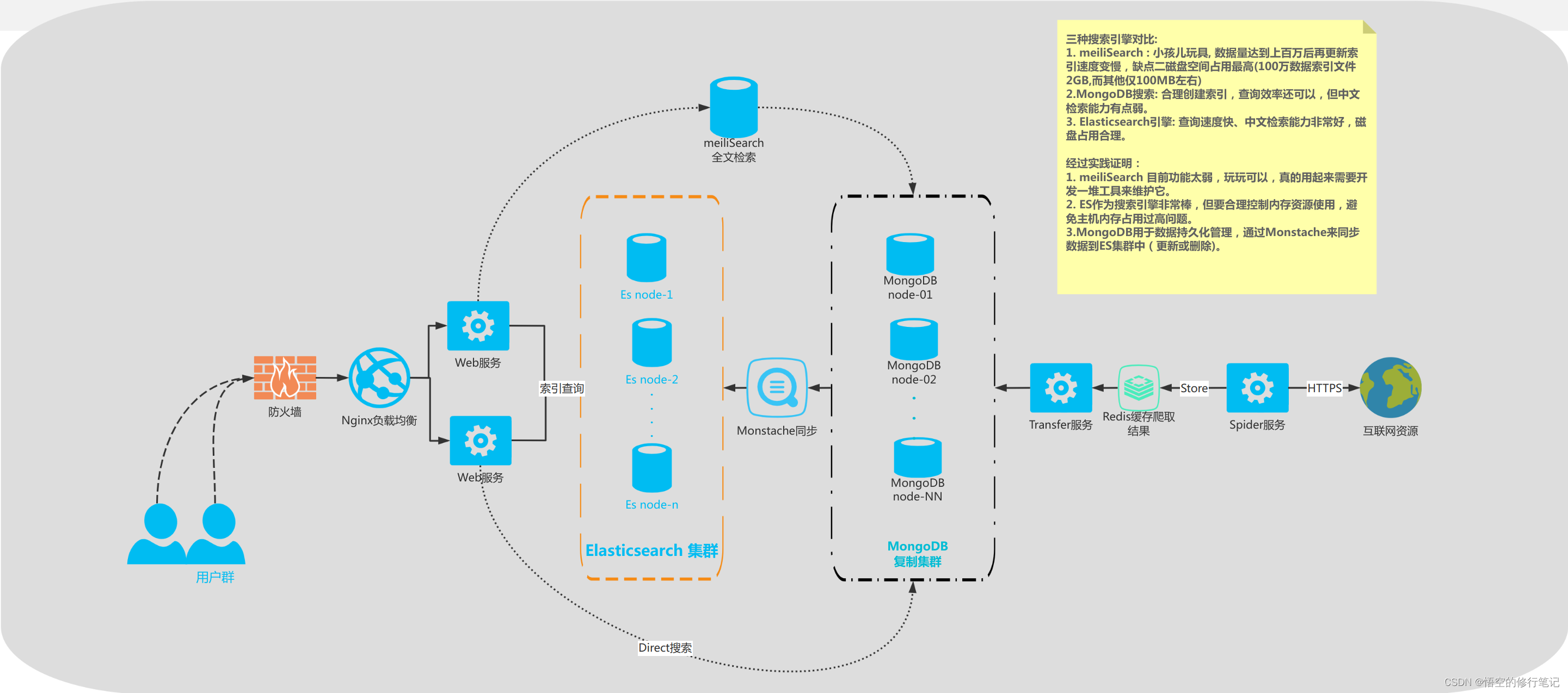
此方案评价:
- 数据更稳定安全, 数据操作都在MongoDB上完成后自动Monstache同步到ES集群中。
- 由于增加了MongoDB集群,对硬件资源要求会更多,因此部署成本更高。
方案二
为了节省成本,本方案省略了MongoDB集群,直接同步数据至ES集群,相当于上面的架构图中删掉了 Monstache和MongoDB复制集。
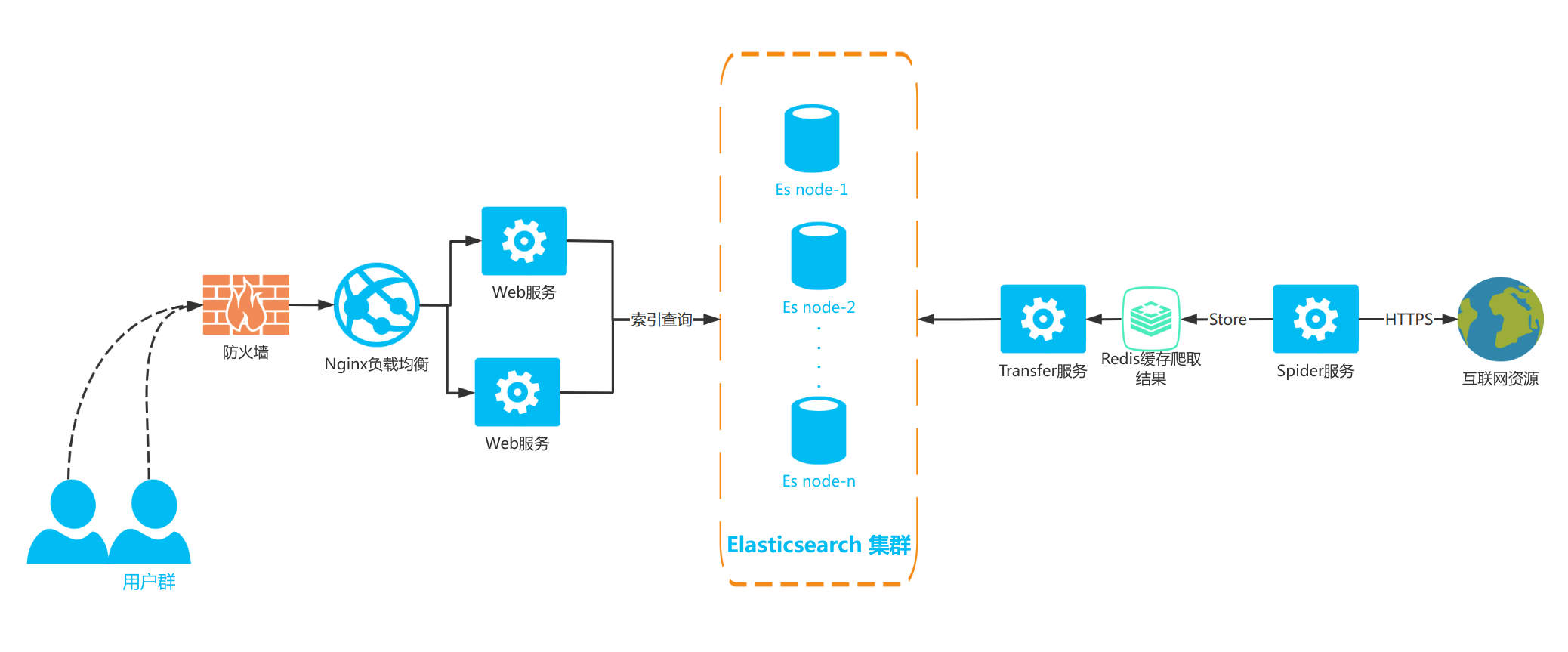
此方案更为简单直接,对硬件资源要求减少了很多,相对而言,更适合个人项目使用。
至于数据的持久化可以选择文件方式存储,删除操作的数据只保留删除记录的id信息即可,恢复数据选择全量导入后再通过删除失效的id列表即可。
结尾
目前是选择方案一实现的,但集群部署成本比较高,因此可以将 MongoDB集群 和 爬虫相关服务放在家庭个人服务器上运行(没啥成本),仅将ES集群和Web服务放在云服务器上(烧码内money的地方),再加上慢如蜗牛的CloudflareCDN服务,这样就可以基本上可以稳定运行了。
目前Web服务使用Golang开发的,没有Resfull API接口, 正考虑用Vue实现Web前端,通过Resful API接口进行数据交互,但这必然会导致数据被爬的风险, 我也是在不断的学习过程中,最终,这些眼前的问题都会被解决的。
如果喜欢这个项目,可以一键三连,持续关注我哦。