PaddleDetection/pphuman_mot.md at release/2.6 · PaddlePaddle/PaddleDetection · GitHubObject Detection toolkit based on PaddlePaddle. It supports object detection, instance segmentation, multiple object tracking and real-time multi-person keypoint detection. - PaddleDetection/pphuman_mot.md at release/2.6 · PaddlePaddle/PaddleDetection https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.6/deploy/pipeline/docs/tutorials/pphuman_mot.mdGitHub - JialeCao001/PedSurvey: From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021)From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021) - GitHub - JialeCao001/PedSurvey: From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021)https://github.com/JialeCao001/PedSurvey行人检测综述_denghe1122的博客-CSDN博客PART Ifrom: http://www.cnblogs.com/molakejin/p/5708791.html行人检测具有极其广泛的应用:智能辅助驾驶,智能监控,行人分析以及智能机器人等领域。从2005年以来行人检测进入了一个快速的发展阶段,但是也存在很多问题还有待解决,主要还是在性能和速度方面还不能达到一个权衡。近年,以谷歌为首的自动驾驶技术的研发正如火如荼的进行,这也迫
https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.6/deploy/pipeline/docs/tutorials/pphuman_mot.mdGitHub - JialeCao001/PedSurvey: From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021)From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021) - GitHub - JialeCao001/PedSurvey: From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021)https://github.com/JialeCao001/PedSurvey行人检测综述_denghe1122的博客-CSDN博客PART Ifrom: http://www.cnblogs.com/molakejin/p/5708791.html行人检测具有极其广泛的应用:智能辅助驾驶,智能监控,行人分析以及智能机器人等领域。从2005年以来行人检测进入了一个快速的发展阶段,但是也存在很多问题还有待解决,主要还是在性能和速度方面还不能达到一个权衡。近年,以谷歌为首的自动驾驶技术的研发正如火如荼的进行,这也迫https://blog.csdn.net/denghecsdn/article/details/77987627基于FairMOT实现人流量统计 - 飞桨AI Studio本项目基于PaddleDetection FairMOT实现动态场景和静态场景下的人流量统计,提供从 “模型选择→模型优化→模型部署” 的全流程指导,模型可以直接或经过少量数据微调后用于相关任务。 - 飞桨AI Studio
 https://aistudio.baidu.com/aistudio/projectdetail/2421822?channelType=0&channel=0VOC-COCO-MOT20 - 飞桨AI StudioVOC-COCO-MOT20 - 飞桨AI Studiohttps://aistudio.baidu.com/aistudio/datasetdetail/47128
https://aistudio.baidu.com/aistudio/projectdetail/2421822?channelType=0&channel=0VOC-COCO-MOT20 - 飞桨AI StudioVOC-COCO-MOT20 - 飞桨AI Studiohttps://aistudio.baidu.com/aistudio/datasetdetail/47128
时耕科技-中国领先的商业数智化服务提供商 - 时耕科技时耕科技-中国领先的商业数智化服务提供商https://www.timework.cn/col.jsp?id=157YOLOv5训练自己的数据集(超详细)_yolo数据集_AI追随者的博客-CSDN博客一、准备深度学习环境本人的笔记本电脑系统是:Windows10首先进入YOLOv5开源网址,手动下载zip或是git clone 远程仓库,本人下载的是YOLOv5的5.0版本代码,代码文件夹中会有requirements.txt文件,里面描述了所需要的安装包。本文最终安装的pytorch版本是1.8.1,torchvision版本是0.9.1,python是3.7.10,其他的依赖库按照requirements.txt文件安装即可。...
https://blog.csdn.net/qq_40716944/article/details/118188085
本项目来源于明厨亮灶这样一个背景的视频监控项目,对厨房中是否存在有人场景做一个识别,打算使用yolov5算法。
1.数据集
目前行人检测的数据集包括coco_person,voc_person,mot20/16、17,CrowdHuman , HIEVE,Caltech Pedestrian,CityPersons, CHUK-SYSU,PRW,ETHZ。
2.数据处理
采用coco-voc-mot20数据集,一共是41856张图,其中训练数据37736张图,验证数据3282张图,测试数据838张。
2.1 将上述数据中的train/val/test转成包含图片的txt。
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='/home/imcs/local_disk/D0011/Annotations', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='dataSet', type=str, help='output txt label path')
opt = parser.parse_args([])
trainval_percent = 0.98 # 剩下的0.02就是测试集
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in tqdm(list_index):
# import pdb;pdb.set_trace()
name = Path(total_xml[i]).stem + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
2.2 将xml数据转成yolo数据格式
sets = ['train', 'val', 'test']
classes = ["person"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open(abs_path+'/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open(abs_path+'/Yolo/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
try:
difficult = obj.find('Difficult').text
except:
difficult = 0
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in tqdm(sets):
image_ids = [line.strip() for line in open('./dataSet/%s.txt' % (image_set)).readlines()]
list_file = open('%s_yolo.txt' % (image_set), 'w')
for image_id in image_ids:
try:
list_file.write(abs_path + '/JPEGImages/%s.jpg\n' % (image_id))
convert_annotation(image_id)
except:
continue
list_file.close()2.3 更改数据集名称
../datasets/coco128/images/im0.jpg # image ../datasets/coco128/labels/im0.txt # label
yolo会自动的把image换成labels,去找标签名,因此数据集名称要换成labels和images。
3.环境安装
python3.7 cuda10.1
pip install -r requirements
torch==1.8.1_cu101
torchvision==0.9.1_cu101
tqdm==4.64.0
thop==0.1.1
升级glic/libstdc++.so.6
4.模型
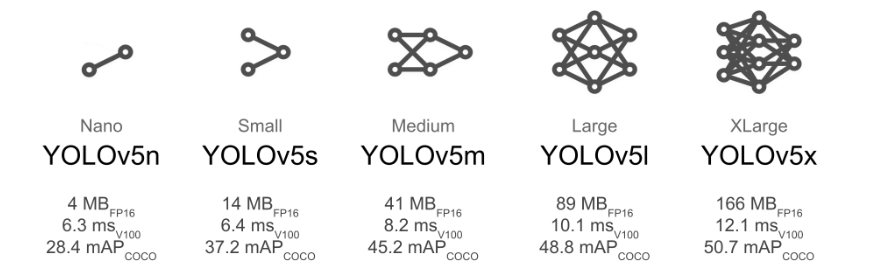
一般考虑在端侧部署的话就用yolov5s
4.1 在data下新建一个person.yaml
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/imcs/local_disk/D0011 # dataset root dir
train: train_yolo.txt # train images (relative to 'path') 118287 images
val: val_yolo.txt # val images (relative to 'path') 5000 images
test: test_yolo.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
nc: 1 # number of classes
names: ['person'] # class names4.2 在models更新yolov5s.yaml中,把nc改成类别。
4.3 分布式训练
python -m torch.distributed.launch --nproc_per_node 4 train.pybatch_size=32,yolov5的代码这块写的很好,即便在k80上也不需要很大的改动。
5. 测试