目录
EVM基本信息
以太坊是一种基于栈的虚拟机,基于栈的虚拟机数据的存取为先进先出,在后面介绍EVM指令的时候会看到这个特性。同时基于栈的虚拟机实现简单,移植性也不错,这也是以太坊选择基于栈的虚拟机的原因。
EVM采用了32字节(256bit)的字长,最多可以容纳2014个字,字为最小的操作单位。
数据管理
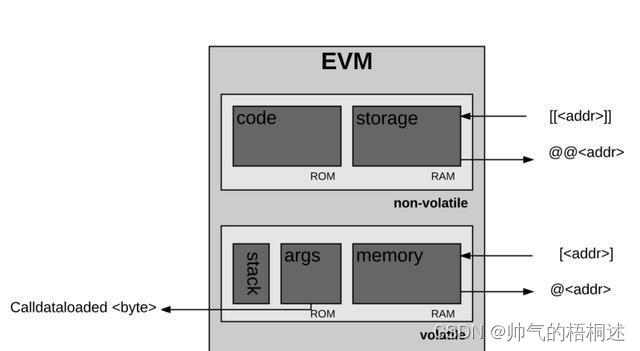
可以看到code和storage里存储的数据是非易失的,而stack,args,memory里存储的数据是易失的,其中code的数据是智能合约的二进制源码,是非易失的很好理解,部署合约的时候data字段也就是合约内容会存储在EVM的code中。
如果要操作这些存储结构里的数据,就需要用到EVM指令,由于EVM的操作码被限制在一个字以内,所以EVM最多容纳256条指令,目前EVM已经定义了约142条指令,还有100多条用于以后的扩展。这142条指令包括了算法运算,密码学计算,栈操作,memory,storage操作等。
接下来看一下各个存储位置的含义;
Stack
stack可以免费使用,没有gas消耗,用来保存函数的局部变量,数量被限制在了16个,当在合约里中声明的局部变量超过16个时,再编译合约就会遇到Stack too deep, try removing local variables错误。
介绍几个EVM操作栈的指令,在后面分析合约的时候会用到;
- Pop指令(操作码0x50)用来从栈顶弹出一个元素;
- PushX指令用来把紧跟在后面的1-32字节元素推入栈顶,Push指令一共32条,从Push1(0x60)到Push32(0x7A),因为栈的一个
字是256bit,一个字节8bit,所以Push指令最多可以把其后32字节的元素放入栈中而不溢出。 - DupX指令用来复制从栈顶开始的第1-16个元素,复制后把元素在推入栈顶,Dup指令一共16条,从Dup1(0x80)到Dup16(0x8A)。
- SwapX指令把栈顶元素和从栈顶开始数的第1-16个元素进行交换,Swap指令一共16条,从Swap1(0x01)一直到Swap16(0x9A)。
Args
args也叫calldata,是一段只读的可寻址的保存函数调用参数的空间,与栈不同的地方的是,如果要使用calldata里面的数据,必须手动指定偏移量和读取的字节数。
EVM提供的用于操作calldata的指令有三个:
calldatasize返回calldata的大小。calldataload从calldata中加载32bytes到stack中。calldatacopy拷贝一些字节到内存中。
通过一个合约来看一下如何使用calldata,假如我们要写一个合约,合约有一个add的方法,用来把传入的两个参数相加,通常会这样写。
pragma solidity ^0.5.1;
contract Calldata {
function add(uint256 a, uint256 b) public view returns (uint256) {
return a + b;
}
}转换成内联汇编的形式:
contract Calldata {
function add(uint256 a, uint256 b) public view returns (uint256) {
assembly {
let a := mload(0x40)
let b := add(a, 32)
calldatacopy(a, 4, 32)
calldatacopy(b, add(4, 32), 32)
result := add(mload(a), mload(b))
}
}
} 首先我们我们加载了0x40这个地址,这个地址EVM存储空闲memory的指针,然后我们用a重命名了这个地址,接着我们用b重命名了a偏移32字节以后的空余地址,到目前为止这个地址所指向的内容还是空的。
calldatacopy(a, 4, 32)这行代码把calldata的从第4字节到第36字节的数据拷贝到了a中,同样calldatacopy(b, add(4, 32), 32)把36到68字节的数据拷贝到了b中,接着add(mload(a), mload(b))把栈中的a,b加载到内存中相加。最后的结果等价于第一个合约。
而为什么calldatacopy(a, 4, 32)的偏移要从4开始呢?在EVM中,前四位是存储函数指纹的,计算公式是bytes4(keccak256(“add(uint256, uint256)”)),从第四位开始才是args。
Memory
Memory是一个易失性的可以读写修改的空间,主要是在运行期间存储数据,将参数传递给内部函数。内存可以在字节级别寻址,一次可以读取32字节。
EVM提供的用于操作memory的指令有三个:
- Mload加载一个字从stack到内存;
- Mstore存储一个值到指定的内存地址,格式mstore(p,v),存储v到地址p;
- Mstore8存储一个byte到指定地址 ;
当我们操作内存的时候,总是需要加载0x40,因为这个地址保存了空闲内存的指针,避免了覆盖已有的数据。
Storage
Storage是一个可以读写修改的持久存储的空间,也是每个合约持久化存储数据的地方。Storage是一个巨大的map,一共2^256个插槽,一个插糟有32byte。
EVM提供的用于操作storage的指令有两个:
- Sload用于加载一个字到stack中;
- Sstore用于存储一个字到storage中;
solidity将定义的状态变量,映射到插糟内,对于静态大小的变量从0开始连续布局,对于动态数组和map则采用了其他方法。
固定长度的值
对于已知拥有固定长度的值,通常的方法是在存储空间给他们分配一个预留的位置存储值。
contract StorageTest {
uint256 a;
uint256[2] b;
struct Entry {
uint256 id;
uint256 value;
}
Entry c;
}对于上面的代码:
a存储在slot 0(在solidity属于中,存储空间中的每一个位置称为“slot”)b存储在slot 1和2中(因为b是一个数组,且数组长度为2)c存储位置从slot 3开始,消耗两个slot,因为Entry结构体存储了两个32字节长度的值
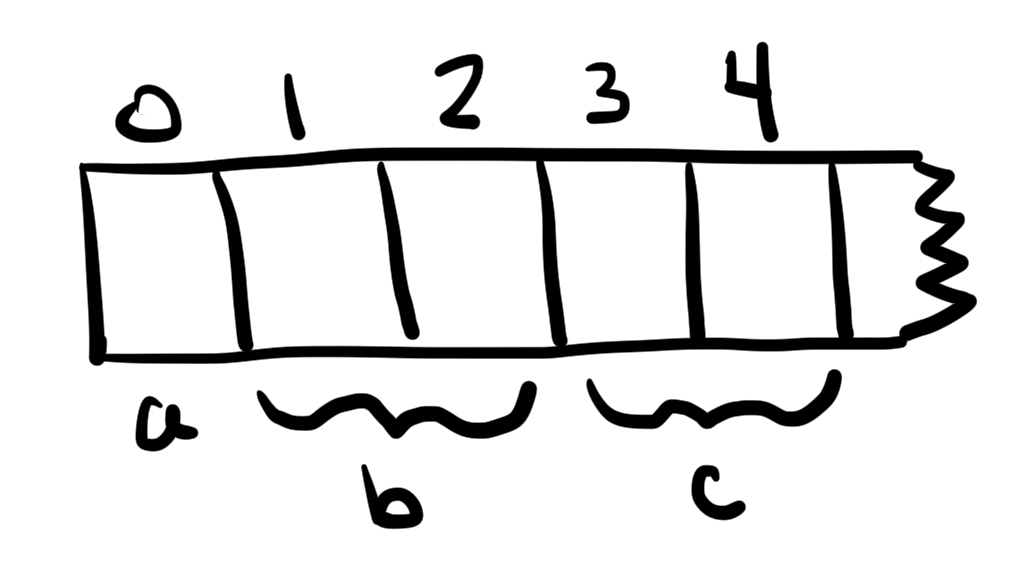
这些slot位置在合约编译的时候就确定了,并且严格按照变量在合约中的定义顺序确定的。
动态长度数组
动态长度的数组需要一个位置来存储数组的长度和数组中的所有元素。
contract StorageTest {
uint256 a; // slot 0
uint256[2] b; // slots 1-2
struct Entry {
uint256 id;
uint256 value;
}
Entry c; // slots 3-4
Entry[] d;
}对于上面的代码:
- 动态数组
d存储在slot 5位置中,但slot 5中存储的值是数组d的长度,数组中的元素连续存储在以hash(5)开始的位置中。即通过对动态数组d的slot进行hash运算,求出数组中的元素存储位置。
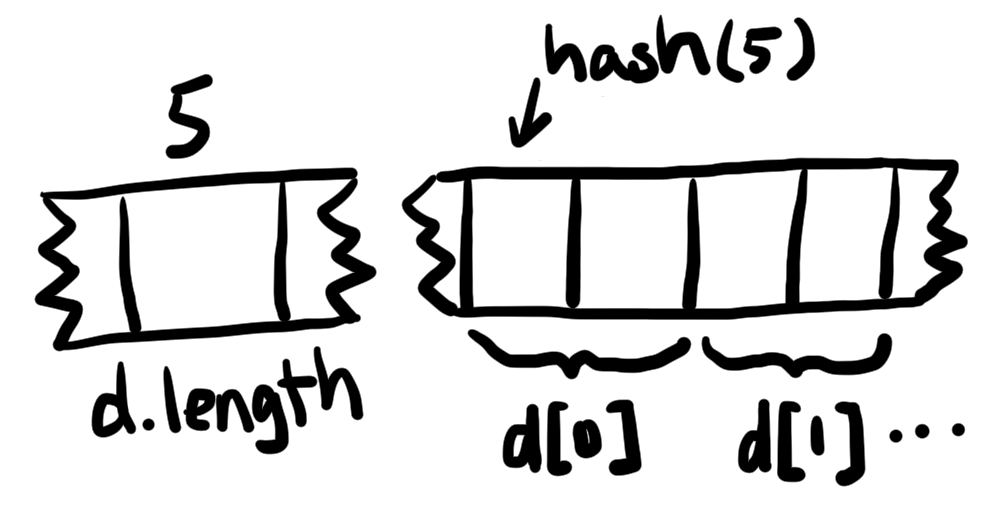
下面一段solidity代码用来计算动态数组中元素的位置:
function arrLocation(uint256 slot, uint256 index, uint256 elementSize)
public
pure
returns (uint256)
{
return uint256(keccak256(slot)) + (index * elementSize);
}Mappings
映射需要找到与给定键对应的位置的有效方法。散列键是一个好的开始,但是必须注意确保不同的映射生成不同的位置。
mapping需要一个有效的方法通过给定的key找到相应的存储位置,通过对mapping的key进行hash运算是一个不错的方法,但需要确保针对不同的mapping对象的相同的key生成不同的存储位置。
contract StorageTest {
uint256 a; // slot 0
uint256[2] b; // slots 1-2
struct Entry {
uint256 id;
uint256 value;
}
Entry c; // slots 3-4
Entry[] d; // slot 5 for length, keccak256(5)+ for data
mapping(uint256 => uint256) e;
mapping(uint256 => uint256) f;
}对于以上代码:
e的slot是6,f的slot是7,但在这两个位置中并没有存储任何值,因为mapping没有长度值需要存储
要寻找mapping中的值的位置,需要将key与mapping的slot一起进行hash运算。
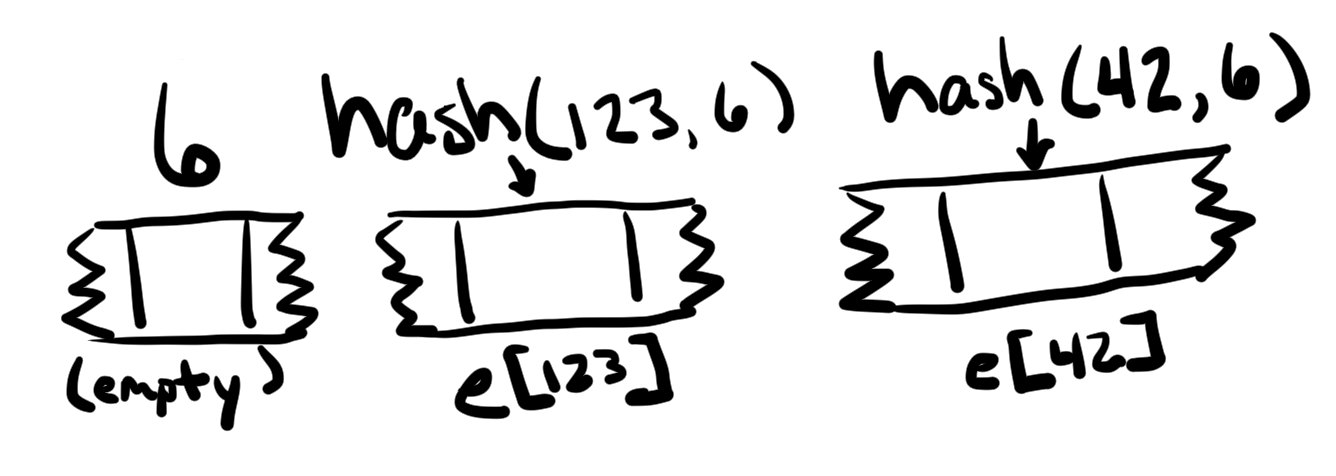
下面的solidity函数用于计算mapping中值的存储位置:
function mapLocation(uint256 slot, uint256 key) public pure returns (uint256) {
return uint256(keccak256(key, slot));
} 注意:当传入多个参数到keccak256方法时,首先会将这些参数进行连接,然后在进行hash运算。因为是将mapping的slot值与key值同时进行的hash运算,所以不同mapping之间是不会存在冲突的。
复杂类型的组合
动态大小的数组与mapping可以相互嵌套在一起,当这种情况发生时,可以通过递归的方式找到值的存储位置。
contract StorageTest {
uint256 a; // slot 0
uint256[2] b; // slots 1-2
struct Entry {
uint256 id;
uint256 value;
}
Entry c; // slots 3-4
Entry[] d; // slot 5 for length, keccak256(5)+ for data
mapping(uint256 => uint256) e; // slot 6, data at h(k . 6)
mapping(uint256 => uint256) f; // slot 7, data at h(k . 7)
mapping(uint256 => uint256[]) g; // slot 8
mapping(uint256 => uint256)[] h; // slot 9
}要寻找这些复杂类型中的值的存储位置可以使用上面定义的函数:
- arrLocation
- mapLocation
例:寻找g[123][0]的存储位置:
// 首先找到g[123]的位置,g是mapping,g的slot是8,key是123,用mapLocation计算存储位置
arrLoc = mapLocation(8, 123); // g is at slot 8
// 然后 查找arr[0]
itemLoc = arrLocation(arrLoc, 0, 1);例:寻找 h[2][456]的存储位置:
// 首先查找h[2]位置,h是动态数组,h的slot是9
mapLoc = arrLocation(9, 2, 1); // h is at slot 9
// 然后查找 map[456]位置
itemLoc = mapLocation(mapLoc, 456);总结
- 每个智能合约中的
storage都是以2^256长度的数组形式存在的,并且数组中的所有元素的初始值为0 - 0值是不会被显示存储的,所以当给一个对象赋值0时,就相当于生命回收相应的存储空间
- 对与固定长度的值,solidity是通过预分配的方式分配存储位置的
- 对于动态长度类型的值,Solidity通过hash运算的方法动态确定存储位置
下表展示了如何计算不同类型的存储位置。slot表示在合约中定义的变量的位置。
| Kind | Declaration | Value | Location |
|---|---|---|---|
| 一般类型 | T v |
v |
v's slot |
| 定长数组 | T[10] v |
v[n] |
(v's slot) + n * (size of T) |
| 不定长数组 | T[] v |
v[n] |
keccak256(v's slot) + n * (size of T) |
v.length |
v's slot | ||
| Mapping | mapping(T1 => T2) v |
v[key] |
keccak256(key . (v's slot)) |
- 查看合约的存储可通过编译合约查看
solc --bin --asm --optimize test.sol- 参考链接:
- 理解以太坊中智能合约中的存储
- EVM深度分析之数据存储