文章目录
前言
为了获取最佳阅读体验,推荐移步个人博客

BERT等语言模型在多数NLP任务中取得优异的表现,但如果直接取BERT输出的句向量作表征,取得的效果甚至还不如Glove词向量。
Bert-flow论文中指出,产生该现象的原因是BERT模型的各向异性过高,Transformer模型的输出中,高频词汇分布集中,低频词汇分布分散,整个向量空间类似于锥形结构。
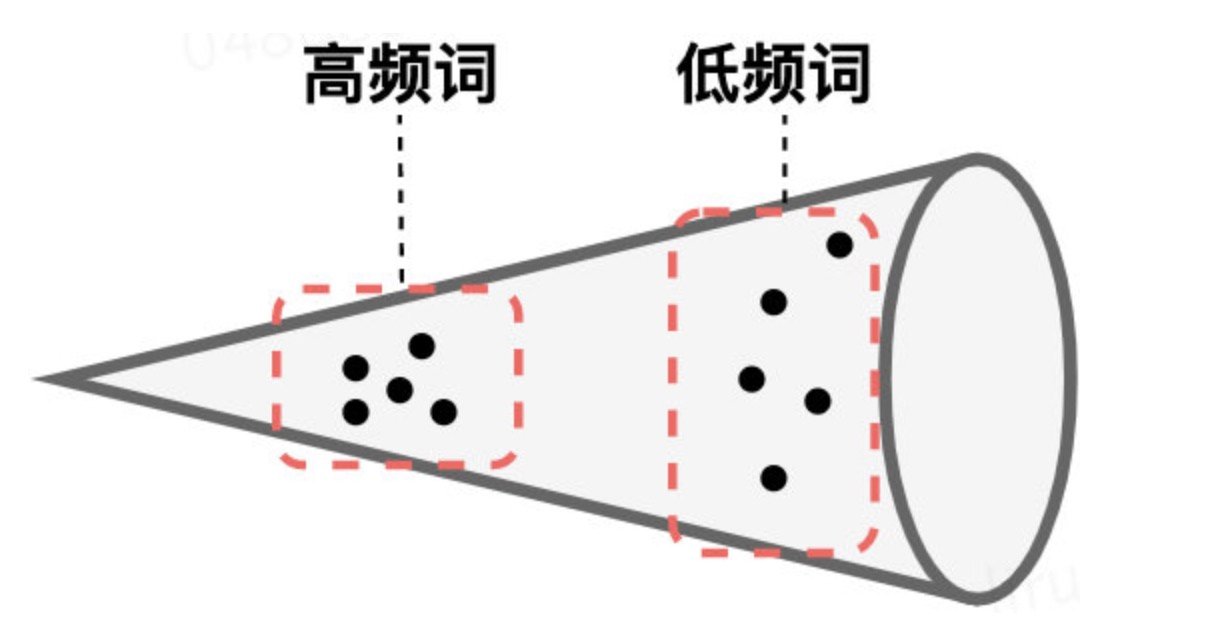
余弦相似度使用的前提是向量空间在标准正交基下,而BERT输出的句向量很明显 不符合该条件,因此直接使用BERT输出的句向量计算余弦相似度,效果表现很差。
针对该问题,BERT-flow、BERT-Whitening模型将输出的句向量映射到标准正交的高斯空间。SimCSE引入对比学习的方式, 在保证向量空间的uniformity情况下,也提高alignment。此后,多种对比学习方式层出不穷,其核心改进点在于正负例的生成方式,提高正负样本的难度,本文主要介绍ConSERT、SimCSE、ESimCSE、DiffCSE、PromptBert、SNCSE、EASE。
Sentence-Bert(EMNLP 2019)
题目:Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
地址:https://arxiv.org/abs/1908.10084
代码:https://github.com/UKPLab/sentence-transformers
核心思路
出发点:
解决文本匹配推理次数过多的问题,BERT的传统文本匹配任务是输入sentence1与sentence2 作一个分类任务,给定一个语料库查找最相似句子的时间复杂度高达O(n^2)。
直接使用BERT的embdeeing向量,存在各向异性问题,相似度计算效果甚至低于Glove词向量。
解决方式:
采用孪生网络的双塔结构,这样推理的次数降低到了O(n),计算相似度的点积复杂度还是O(n^2)
其他:
论文比较了三种pooling方式:CLS、AVG、MAX。也设计了分类任务、回归任务、Triplet形式的任务。
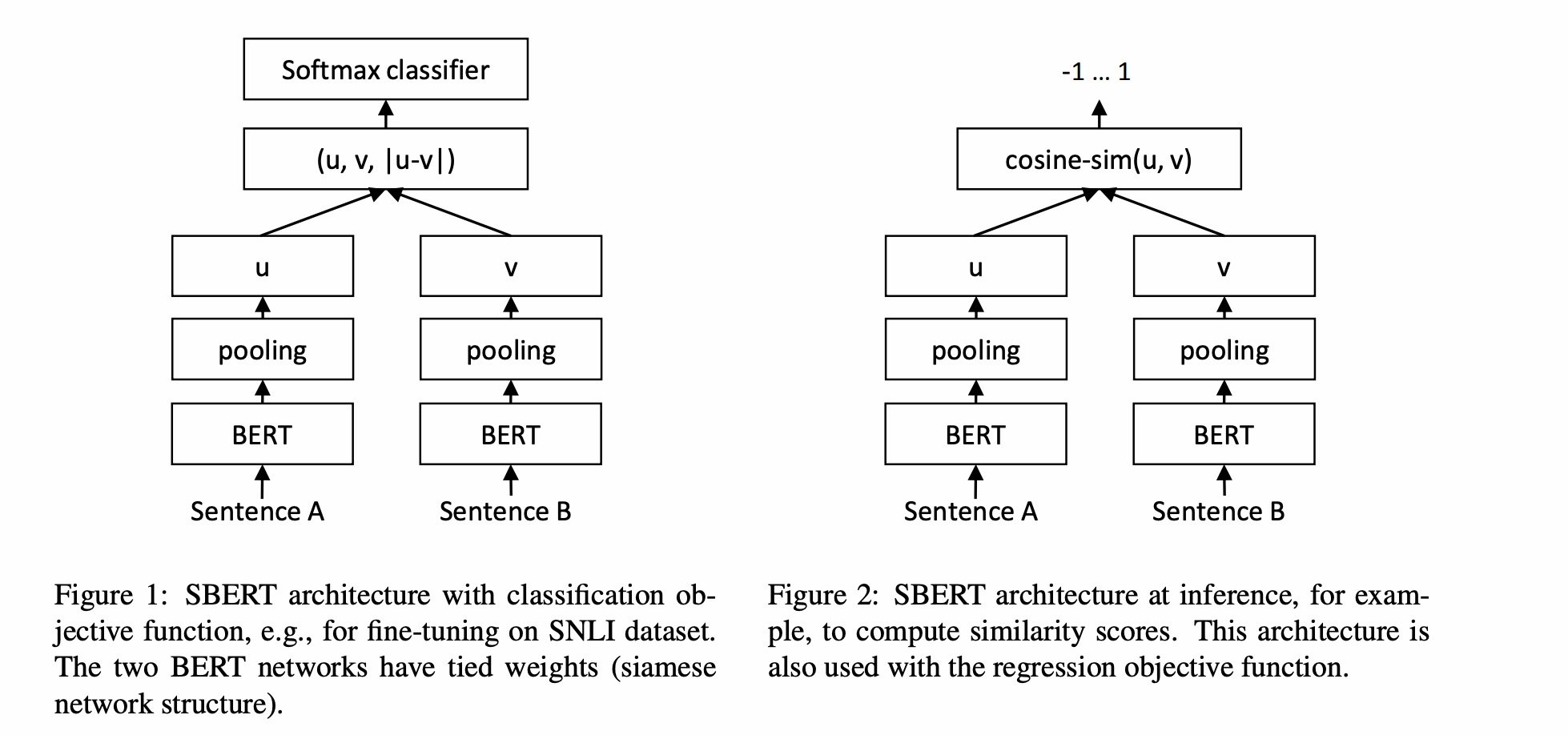
SBERT通过图1的方式进行训练,微调学习BERT句向量的embedding,通过图2的方式完成推理,计算文本相似度。
BERT-flow(EMNLP 2020)
题目:On the Sentence Embeddings from Pre-trained Language Models
地址:https://arxiv.org/pdf/2011.05864.pdf
代码:https://github.com/bohanli/BERT-flow
核心思路
出发点:
指出BERT句向量存在的问题:各向异性,高频词汇分布集中
解决方式:
引入flow流式模型,映射为同向性,将BERT句向量映射到标准高斯空间.
计算公式如下:
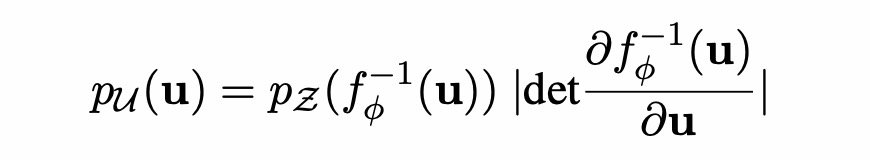
BERT-whitening
题目:Whitening Sentence Representations for Better Semantics and Faster Retrieval
地址:https://arxiv.org/abs/2103.15316
代码:https://github.com/bojone/BERT-whitening
核心思路
出发点:在句向量维度,通过一个白化的操作直接校正局向量的协方差矩阵。
解决方式:
PCA白化,并且可以降维实现更好的效果。
将句向量进行标准化映射,即白化操作:
x ~ i = ( x i − μ ) W \tilde{\boldsymbol{x}}_i=\left(\boldsymbol{x}_i-\boldsymbol{\mu}\right) W x~i=(xi−μ)W
均值与协方差矩阵计算方式如下:
μ = 1 N ∑ i = 1 N x i \boldsymbol{\mu}=\frac{1}{N} \sum_{i=1}^N \boldsymbol{x}_i μ=N1i=1∑Nxi
Σ = U Λ U ⊤ , 即原向量矩阵的协方差矩阵 S V D 分解 \boldsymbol{\Sigma}=\boldsymbol{U} \boldsymbol{\Lambda} \boldsymbol{U}^{\top},即原向量矩阵的协方差矩阵SVD分解 Σ=UΛU⊤,即原向量矩阵的协方差矩阵SVD分解
W = U Λ − 1 \boldsymbol{W}=\boldsymbol{U} \sqrt{\boldsymbol{\Lambda}^{-1}} W=UΛ−1
代码如下:
def compute_kernel_bias(vecs):
"""计算kernel和bias
vecs.shape = [num_samples, embedding_size],
最后的变换:y = (x + bias).dot(kernel)
"""
mu = vecs.mean(axis=0, keepdims=True)
cov = np.cov(vecs.T)
u, s, vh = np.linalg.svd(cov)
W = np.dot(u, np.diag(1 / np.sqrt(s)))
return W, -mu
ConSERT(ACL 2021)
题目:ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
地址:https://arxiv.org/abs/2105.11741
代码:https://github.com/yym6472/ConSERT
核心思路
出发点:
解决BERT本身表征的语义塌缩问题。再来看对比学习,它是通过拉近相同样本的距离、拉远不同样本的距离,来刻画样本本身的表示,正好可以解决BERT表示的塌缩问题。
解决方式:
NLP的数据增强方式很重要,使用了5种数据增强方式进行对比:Adversarial attack、shuffle、token cutoff、feature cutoff、dropout
损失函数:对比学习损失
L i , j = − log exp ( sim ( r i , r j ) / τ ) ∑ k = 1 2 N 1 [ k ≠ i ] exp ( sim ( r i , r k ) / τ ) \mathcal{L}_{i, j}=-\log \frac{\exp \left(\operatorname{sim}\left(r_i, r_j\right) / \tau\right)}{\sum_{k=1}^{2 N} \mathbb{1}_{[k \neq i]} \exp \left(\operatorname{sim}\left(r_i, r_k\right) / \tau\right)} Li,j=−log∑k=12N1[k=i]exp(sim(ri,rk)/τ)exp(sim(ri,rj)/τ)
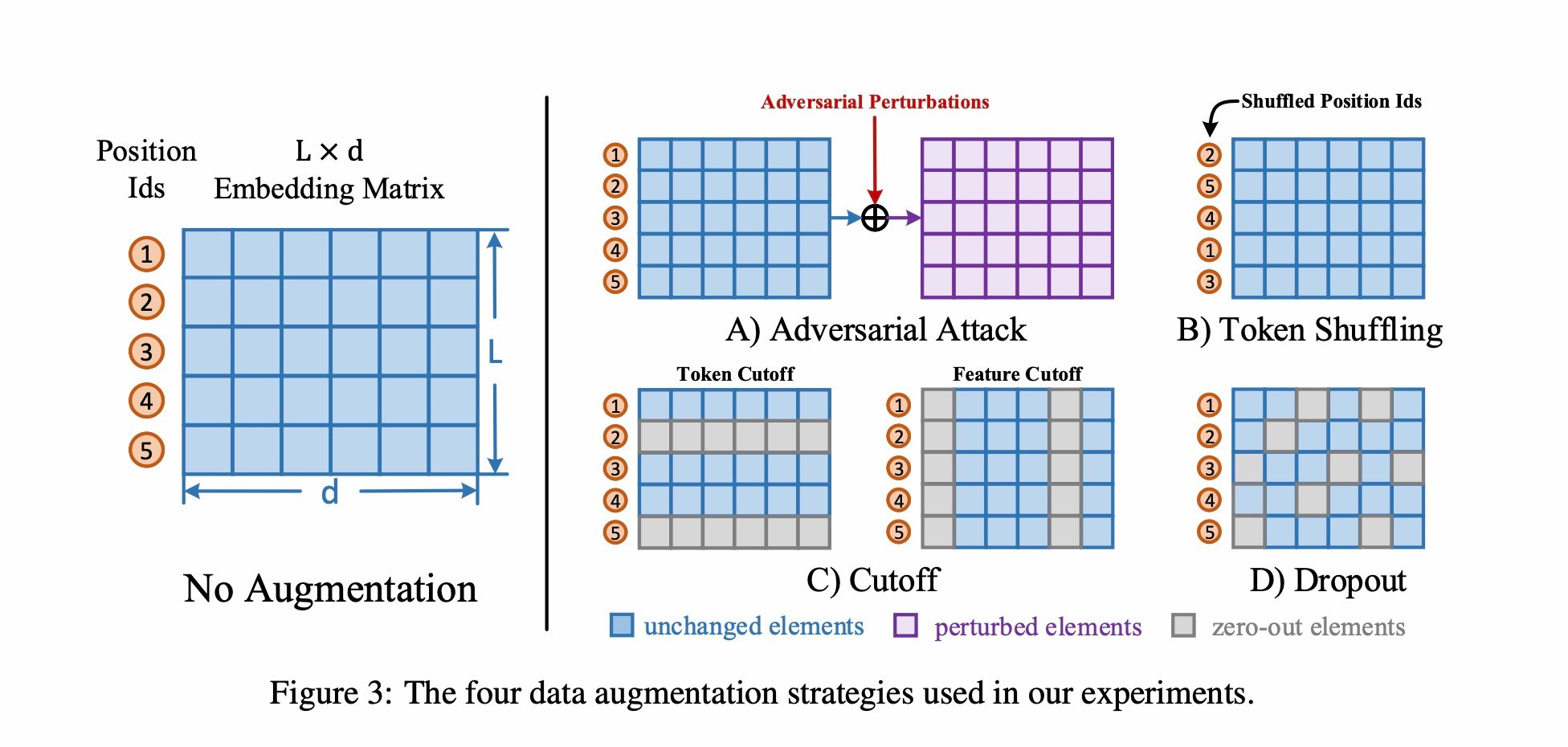

正例构建方式
- shuffle:更换position id的顺序
- token cutoff:在某个token维度把embedding置为0
- feature cutoff:在embedding矩阵中,有768个维度,把某个维度的feature置为0
- dropout:dropout
- Adversarial attack:对抗扰动
负例构建方式
同一batch内其他样本
SimCSE(EMNLP 2021)
题目:SimCSE: Simple Contrastive Learning of Sentence Embeddings
地址:https://aclanthology.org/2021.emnlp-main.552.pdf
代码:https://github.com/princeton-nlp/SimCSE
核心思路
出发点:
将对比学习方式引入句向量表征领域。
解决方式:
引入对比损失的难点在于正样本的构建,该文提出dropout的正样本构建方式。
无监督SimCSE:
Dropout构建正例样本,batch内其他样本作为负样本
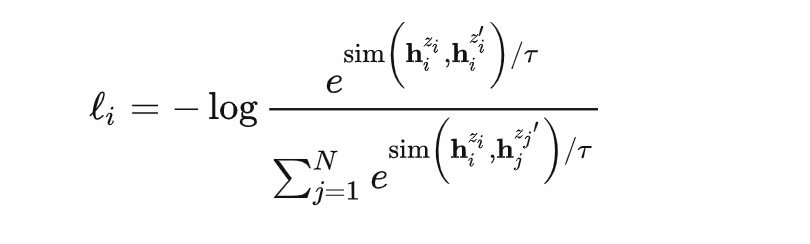
有监督SimCSE:
句子蕴含任务中同一标签的作为正样本,同一batch的其他样本的是负样本
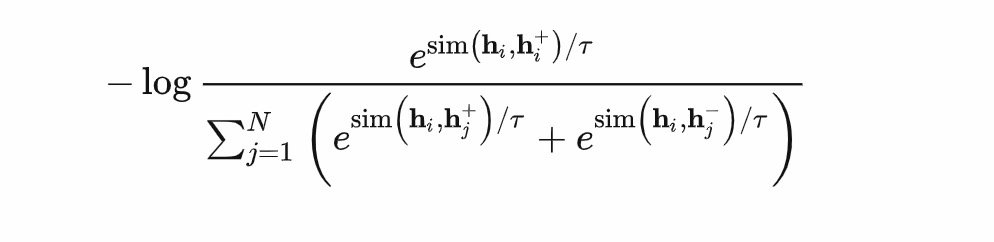
正例构建方式
Dropout两次产生的数据
负例构建方式
同一batch内其他样本

ESimCSE(COLING 2022)
题目:ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
地址:https://arxiv.org/pdf/2109.04380.pdf
代码:https://github.com/caskcsg/sentemb/tree/main/ESimCSE
核心思路
出发点:
解决SimCSE的两个问题:
- Dropout构建的正例均是相同长度的,会导致模型认为相同句子长度的句子更相似
- SimCSE增加batchsize,引入更多负例,反而引起效果下降【猜测:更多的负例中,部分与正例接近质量不高】
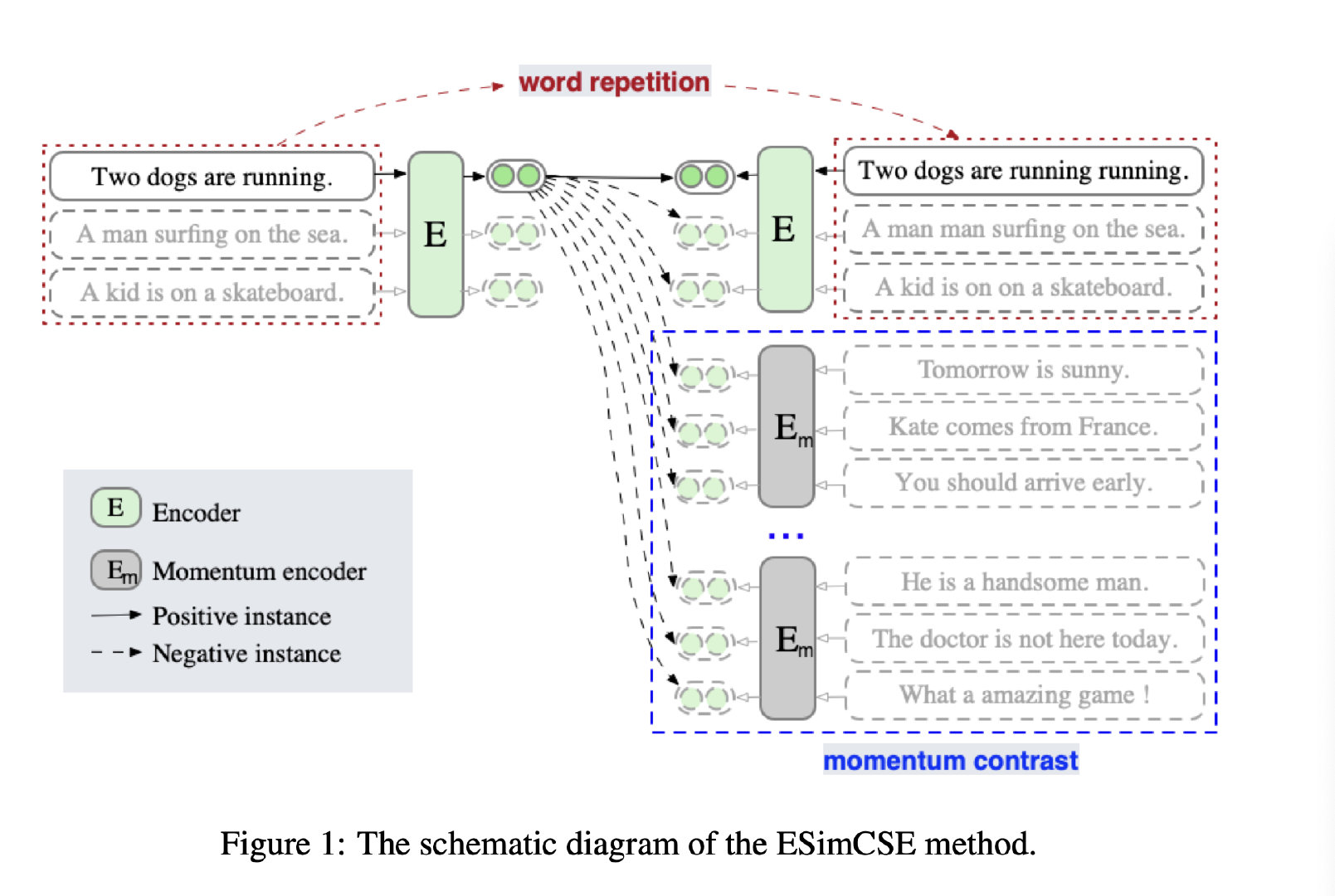
核心改动点:
正例生成方式:重复一定单词
负例生成方式:动量序列,扩展负样本数量
正例生成方式
重复单词
负例生成方式
动量序列,扩展负样本数量
DiffCSE(NAACL2022)
题目:DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings
地址:https://arxiv.org/pdf/2204.10298.pdf
代码:https://github.com/voidism/DiffCSE
核心思路(将敏感变化作为负例,非敏感变化的dropout作为正例)
出发点:
NLP任务中,词语EDA的数据增强方式是敏感变化,dropout方式是 不敏感变化。SimCSE的成功也说明了dropout masks机制来构建正样本,比基于同义词或掩码语言模型的删除或替换等更复杂的增强效果要好得多。“。这一现象也说明,「直接增强(删除或替换)往往改变句子本身语义」。
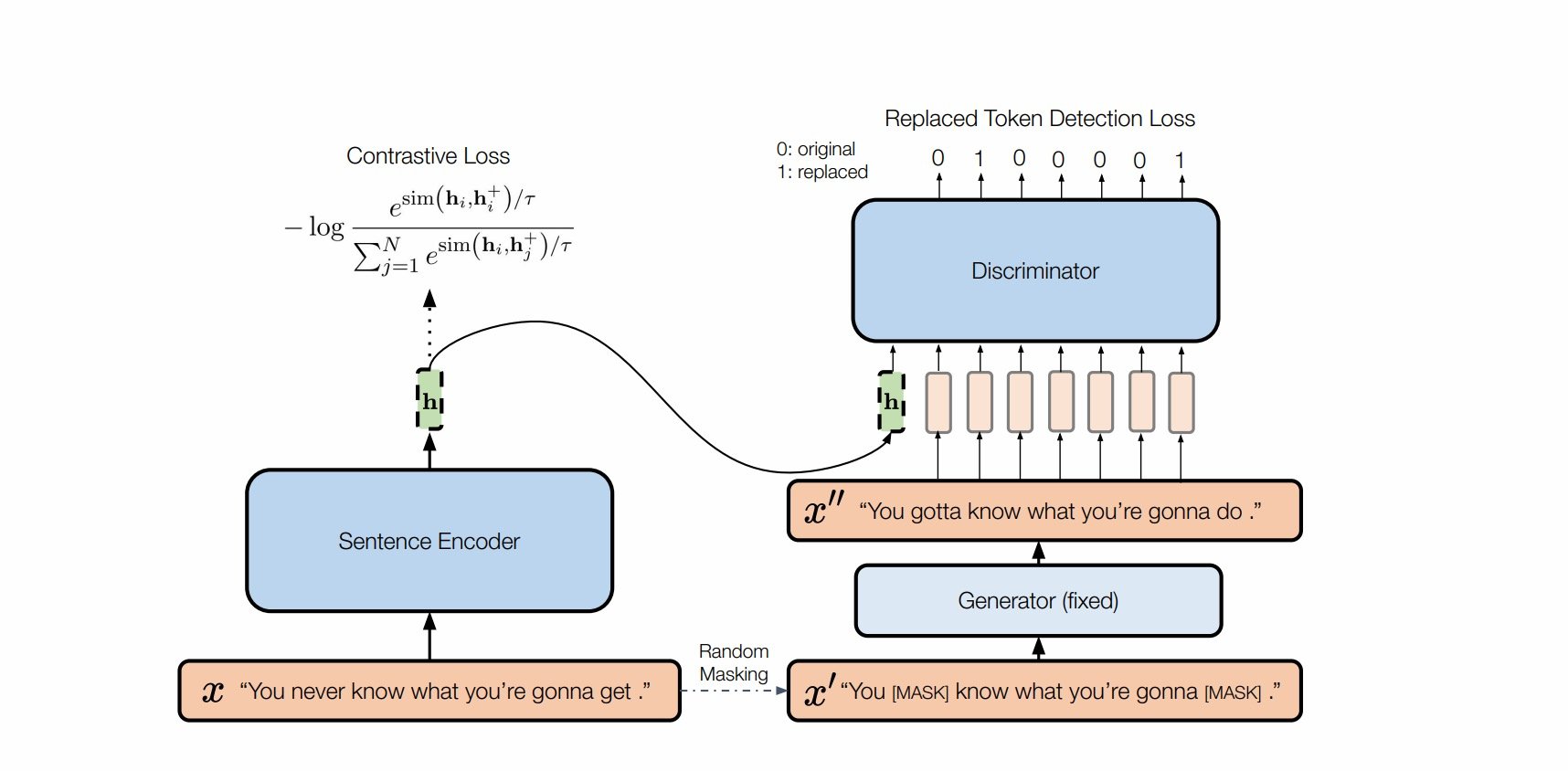

正例生成方式
与SimCSE相同,Dropout产生正例
负例生成方式
通过ELECTRA模型,完成句子改写任务
PromptBert(EMNLP 2022)
题目:PromptBERT: Improving BERT Sentence Embeddings with Prompts
地址:https://arxiv.org/pdf/2201.04337.pdf
代码:https://github.com/kongds/Prompt-BERT
核心思路
出发点:
BERT句向量存在各向异性,并受到词频、字母大小写、子词等影响。
解决方式:
通过Prompt模版,得到句子的表征向量,与CLS、AVG、MAX取表征向量不同,没有用到具体某个词语的信息。
模版去噪对比学习:
通过不同模版产生句子表征向量,构建正样本。为了剔除不同模版的影响,减去纯模版得到的句子表征向量。

正例构建方式
通过不同模版产生的句子表征向量
负例构建方式
同一batch内其他样本
SNCSE
题目:SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples
地址:https://arxiv.org/pdf/2201.05979.pdf
代码:https://github.com/Sense-GVT/SNCSE
核心思路
出发点:
目前的数据增强方法,获取的正样本均极为相似,导致模型存在特征抑制,即**「模型不能区分文本相似度和语义相似度,并更偏向具有相似文本,而不考虑它们之间的实际语义差异」。** 导致模型更多关注的是字面匹配,而非语义匹配。
解决方式:
新增软负例以及双向边际损失,限制样本与软负例相似度到一定范围内。 并利用PromptBert方式获取词向量。
计算公式如下:

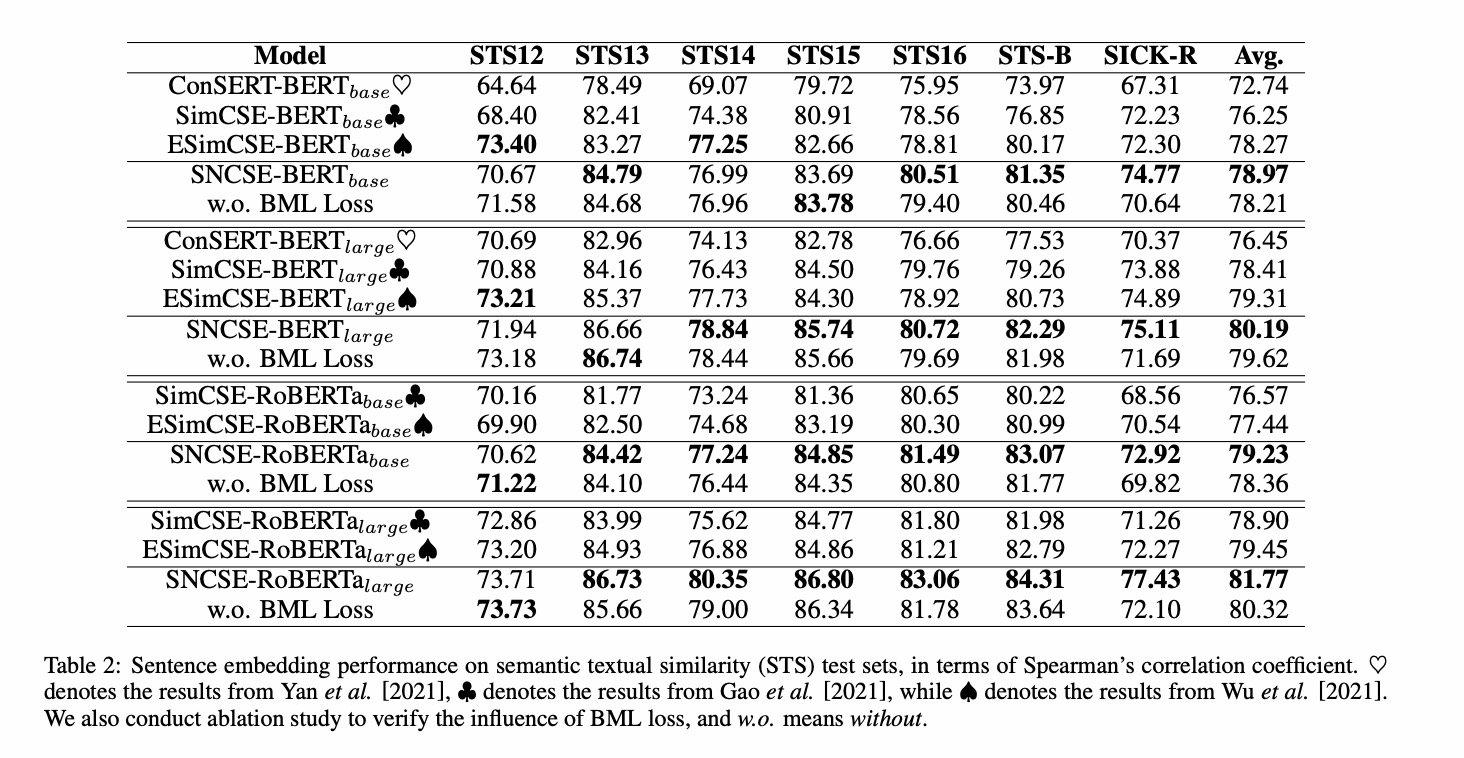
正例生成方式
与SimCSE相同,Dropout产生正例
负例生成方式
- 纯负例:batch内其他数据
- 软负例:通过spacy进行语法解析,为动词添加否定词前缀。
EASE(NAACL2022)
题目:EASE: Entity-Aware Contrastive Learning of Sentence Embedding
地址:https://arxiv.org/pdf/2205.04260.pdf
代码:https://github.com/studio-ousia/ease
核心思路
出发点:实体是一个句子的重要部分,可以作为一个句子的指示器,通过学习实体与句子之间的差异,可以为句子向量的学习提供额外信息。
解决方式:通过维基百科的实体超链接引入实体信息。
损失函数:实体句子对比损失+自监督对比损失
正例生成方式
- 实体正例:维基百科超链接实体。(为了提高实体质量,仅保留超链接实体出现次数超过10次的实体。)
- 样本正例:与SimCSE相同,Dropout产生正例
负例生成方式
- 实体负例:
负例实体需要与正例实体具有相同的类型;
负例实体不能与正例实体出现在同一维基百科页面中。
随机在满足上诉条件的候选实体中选择一个实体作为硬负例数据,构建(句子,正例实体,负例实体)的triple数据。 - 样本负例:batch内其他数据
TODO
- 在中文数据集上,验证各方法效果