前言
为获取最佳阅读格式体验,建议访问个人博客:从语言模型到ChatGPT:大型语言模型的发展和应用 | JMX Blog
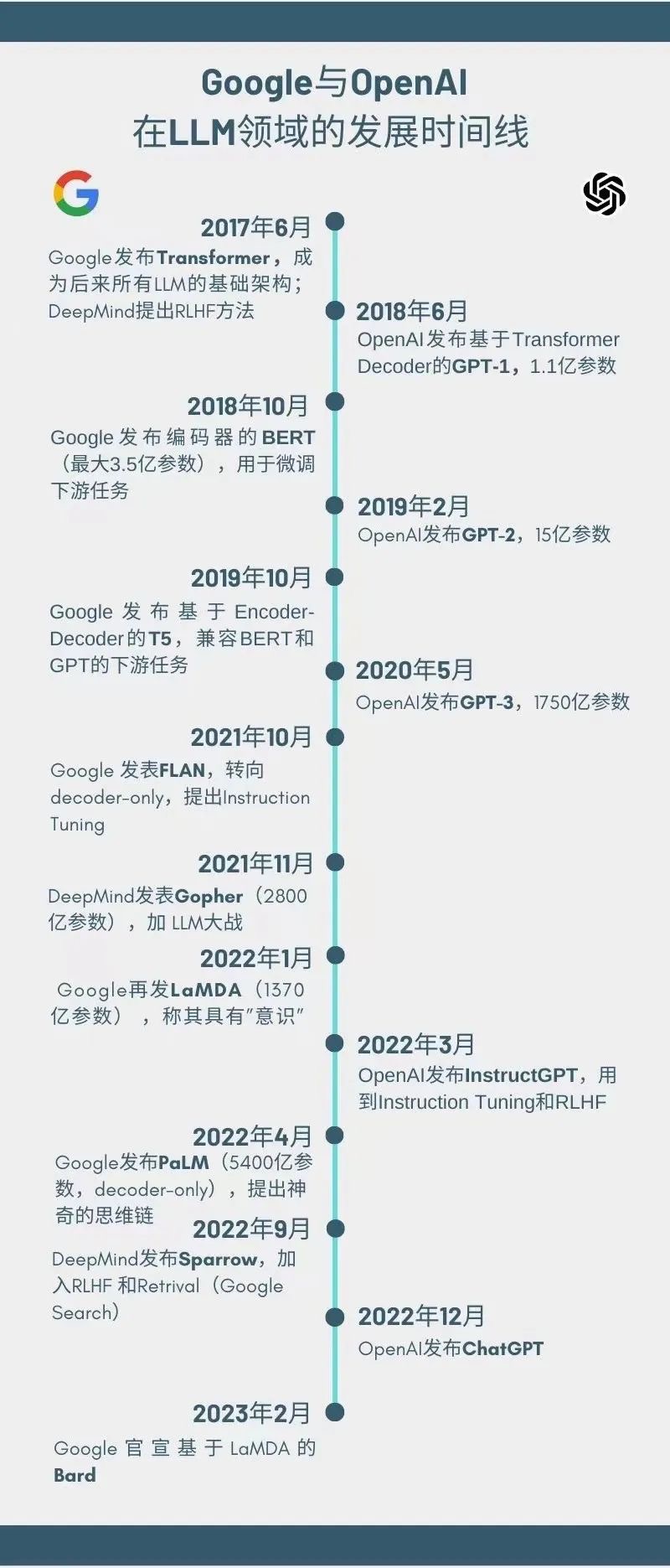
大型语言模型(LLM)是指能够处理大量自然语言数据的深度学习模型,它已经在自然语言处理、文本生成、机器翻译等多个领域中展现出了巨大的潜力。在过去几年中,LLM领域经历了飞速的发展,其中Google和OpenAI作为两家领先的公司在这个领域中的表现备受关注。
Google是LLM领域的重要参与者,其BERT自编码模型和T5编码解码器在自然语言理解任务上取得了优异的表现。BERT模型通过预训练大规模文本数据,提取出词向量的同时,也能够学习到上下文信息。而T5模型则是在BERT的基础上,进一步将生成式任务融入其中,实现了一体化的自然语言处理能力。这些模型的出现,极大地推动了LLM领域的发展。
与之相反的是,OpenAI则从2018年开始,坚持使用decoder only的GPT模型,践行着「暴力美学」——以大模型的路径,实现AGI。GPT模型通过预训练海量语料库数据,学习到了自然语言中的规律和模式,并在生成式任务中取得了出色的表现。OpenAI坚信,在模型规模达到足够大的情况下,单纯的decoder模型就可以实现AGI的目标。
除了Google和OpenAI外,还有许多其他公司和研究机构也在LLM领域做出了贡献。例如,Facebook的RoBERTa模型、Microsoft的Turing NLG模型等等。这些模型的不断涌现,为LLM领域的发展注入了新的动力。
如果只用解码器的生成式是通用LLM的王道,2019年10月,Google同时押注编码解码器的T5,整整错失20个月,直到2021年10月发布FLAN才开始重新转变为decoder-only。这表明,在实际应用中,不同任务可能需要不同类型的模型,而在特定任务中,编码解码器的结构可能比decoder-only模型更加适合。
在本文中,我们将基于CS224N课件回顾大型语言模型的发展历程,探讨它们是如何从最初的基础模型发展到今天的高级模型的,并介绍ChatGPT的发展历程,看看ChatGPT如何实现弯道超车。
Zero-Shot (ZS) and Few-Shot (FS) In-Context Learning
上下文学习(In-Context Learning)
近年来,语言模型越来越倾向于使用更大的模型和更多的数据,如下图所示,模型参数数量和训练数据量呈指数倍增加的趋势。

| 模型名称 | 说明 | 备注 |
|---|---|---|
| GPT | Transformer decoder with 12 layers[参数量117M] Trained on BooksCorpus: over 7000 unique books (4.6GB text). |
表明大规模语言建模可以成为自然语言推理等下游任务的有效预训练技术。 |
| GPT2 | Same architecture as GPT, just bigger (117M -> 1.5B) trained on much more data: 4GB -> 40GB of internet text data (WebText) |
涌现出优异的Zero-shot能力。 |
| GPT3 | Another increase in size (1.5B -> 175B) data (40GB -> over 600GB) |
涌现出强大的上下文学习能力,但是在复杂、多步推理任务表现较差。 |
近年来,随着GPT模型参数量的增加,GPT2与GPT3模型已经表现出了极佳的上下文学习能力(In-Context Learning)。这种能力允许模型通过处理上下文信息来更好地理解和处理自然语言数据。GPT模型通过Zero-Shot、One-Shot和Few-Shot学习方法在许多自然语言处理任务中取得了显著的成果。
其中,Zero-Shot学习是指模型在没有针对特定任务进行训练的情况下,可以通过给定的输入和输出规范来生成符合规范的输出结果。这种方法可以在没有充足样本的情况下,快速生成需要的输出结果。One-Shot和Few-Shot学习则是在样本量较少的情况下,模型可以通过学习一小部分示例来完成相应任务,这使得模型能够更好地应对小样本学习和零样本学习的问题。
上下文学习介绍
链接:[2301.00234] A Survey on In-context Learning
大模型有一个很重要的涌现能力(Emergent ability)就是In-Context Learning(ICL),也是一种新的范式,指在不进行参数更新的情况下,只在输入中加入几个示例就能让模型进行学习。下面给出ICL的公式定义:
C = I , s ( x 1 , y 1 ) , . . . , s ( x k , y k ) o r C = s ( x 1 , y 1 , I ) , . . . , s ( x k , y k , I ) C = {I,s(x_1,y_1),...,s(x_k,y_k)} \quad or \quad C = {s(x_1, y_1, I), . . . , s(x_k, y_k, I)} C=I,s(x1,y1),...,s(xk,yk)orC=s(x1,y1,I),...,s(xk,yk,I)
P ( y j ∣ x ) ≜ f M ( y j , C , x ) P\left(y_j \mid x\right) \triangleq f_{\mathcal{M}}\left(y_j, C, x\right) P(yj∣x)≜fM(yj,C,x)
y ^ = arg max y j ∈ Y P ( y j ∣ x ) . \hat{y}=\arg \max _{y_j \in Y} P\left(y_j \mid x\right) . y^=argyj∈YmaxP(yj∣x).
其中,符号含义如下,从这些符号中也能看出影响ICL的因素:
-
I:具体任务的描述信息
-
x:输入文本
-
y:标签
-
M:语言模型
-
C:阐述示例
-
f:打分函数
下面将开始介绍如何提升模型的ICL能力。
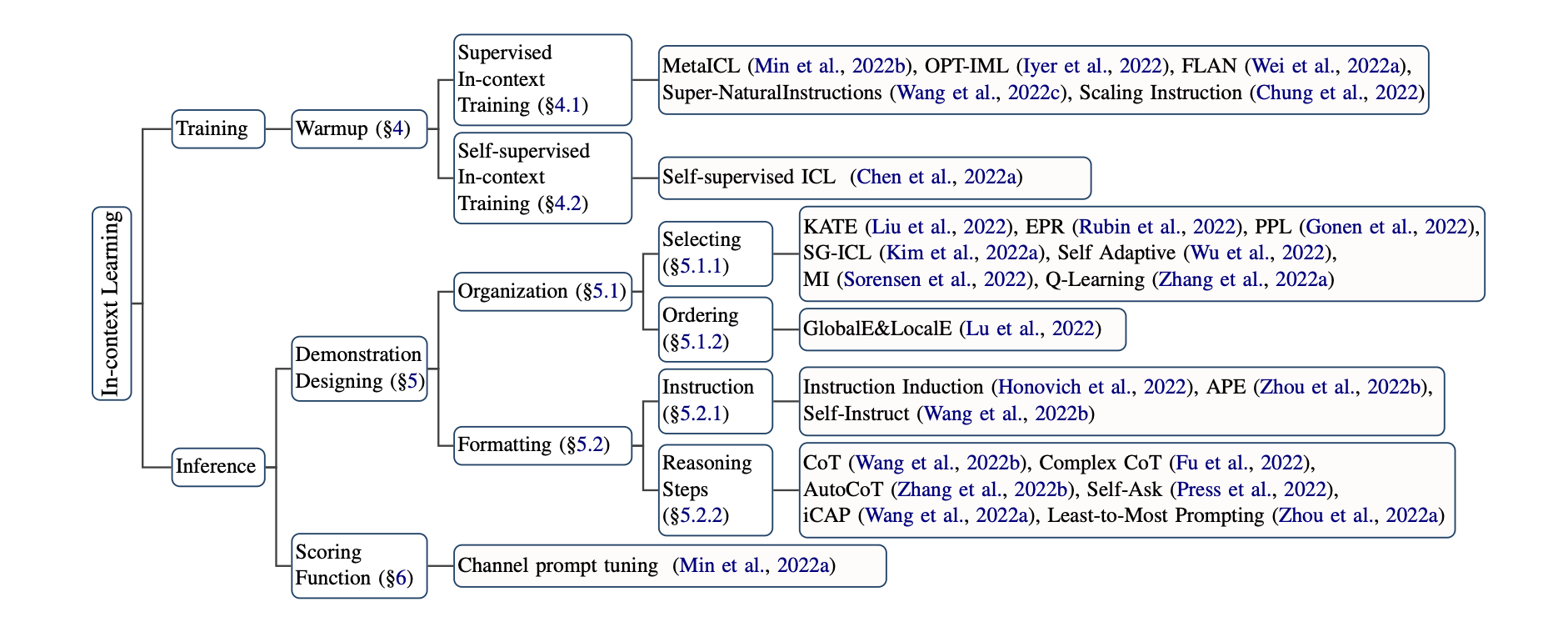
训练优化ICL能力
有监督训练:
在ICL格式的数据集上,进行有监督的训练。
MetaICL就直接把很多任务整合成了ICL的形式精调模型,在52个数据集上取得了比肩直接精调的效果。另外还有部分研究专注于Instruction tuning,构建更好的任务描述让模型去理解,而不是只给几个例子(demonstration),比如LaMDA-PT、FLAN。
自监督训练:
将自然语言理解的任务转为ICL的数据格式。

图1代表不同自然语言理解任务转为ICL的输入输出形式。
图2表示训练样本示例,包含几个训练样本,前面的样本作为后面样本的任务阐述。
推理优化ICL能力
Prompt设计
样本选取:文本表示、互信息选择相近的;Perplexity选取;语言模型生成……
样本排序:距离度量;信息熵……
任务指示:APE语言模型自动生成
推理步骤:COT、多步骤ICL、Self-Ask
打分函数
-
Direct:直接取条件概率
P(y|x),缺点在于y必须紧跟在输入的后面 -
Perplexity:再用语言模型过一遍句子,这种方法可以解决上述固定模式的问题,但计算量增加了
-
Channel:评估
P(x|y)的条件概率(用贝叶斯推一下),这种方法在不平衡数据下表现较好
影响ICL表现的因素
-
预训练语料的多样性比数量更重要,增加多种来源的数据可能会提升ICL表现
-
用下游任务的数据预训练不一定能提升ICL表现,并且PPL更低的模型也不一定表现更好
-
当LM到达一定规模的预训练步数、尺寸后,会涌现出ICL能力,且ICL效果跟参数量正相关
WHY:上下文学习生效的原因
论文链接:[Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?]([2202.12837] Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?)
关键结论:
-
InContext Learning中标签是否正确无明显影响
-
InContext Learning中影响因素包括规范的输入空间、标签空间、输入与标签的匹配格式
其他论文的猜测:
-
跟训练数据的分布相关:比如训练数据有很多样例,也有学者认为ICL可能是隐式的Bayesian inference
-
跟学习机制相关:有学者猜测LM可能自己就具备学习的能力,在做ICL的时候学到了这些知识,或者隐式直接精调了自己
-
跟Transformer中的模块相关:有学者发现Transformer里的某些注意力头会通过拷贝固定的模式来预测下一个token
InContext Learning中标签是否正确无明显影响
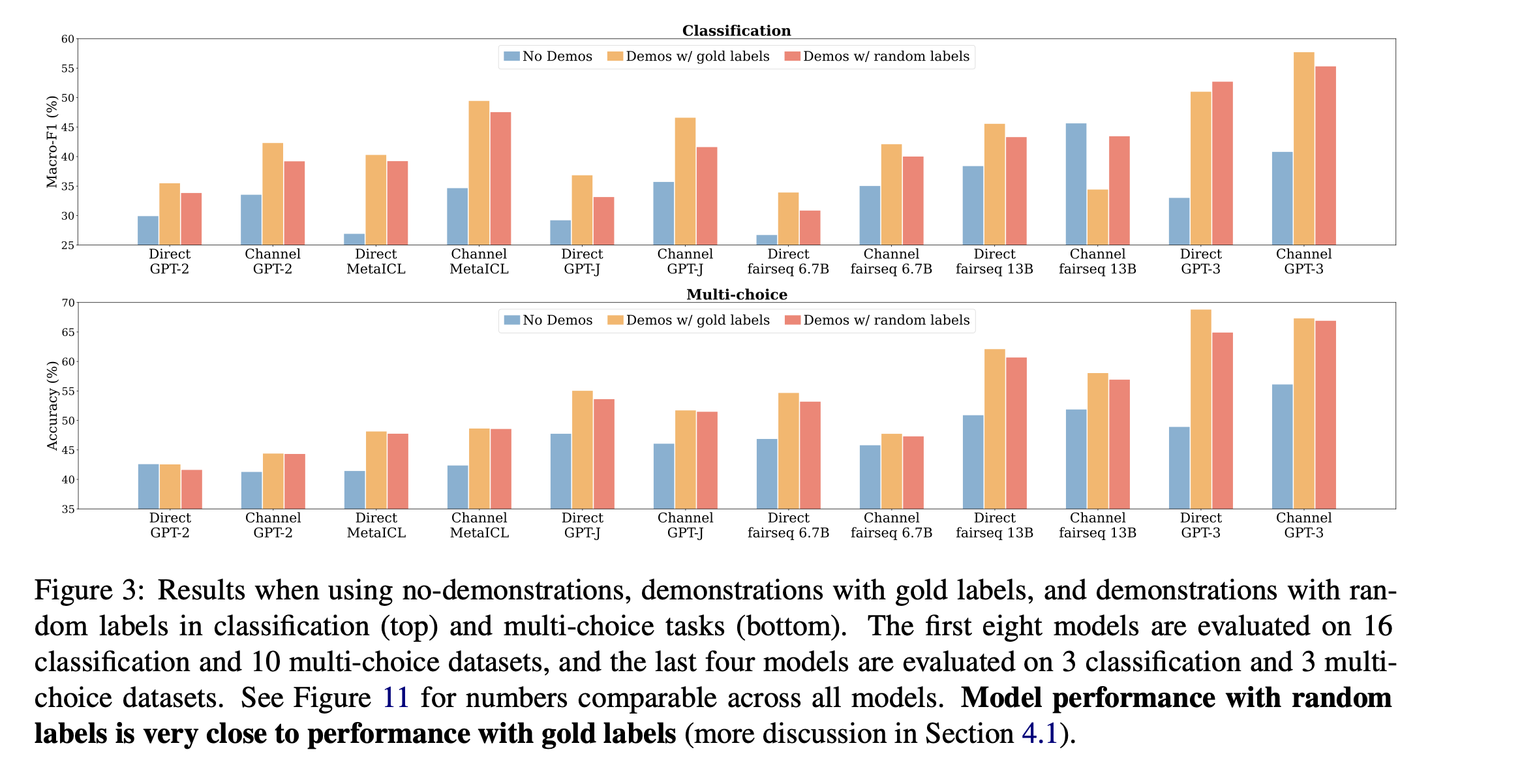
图中青绿色代表没有示例、黄色代表带有正确标签的示例、橙色代表带有随机标签的示例。
实验结果表明,带有随机标签的效果非常接近于带有正确标签的效果。
此外,作者还进行了标签正确比例、提示样本数量、提示模版样式的实验,均得出一致结论,实验图如下。

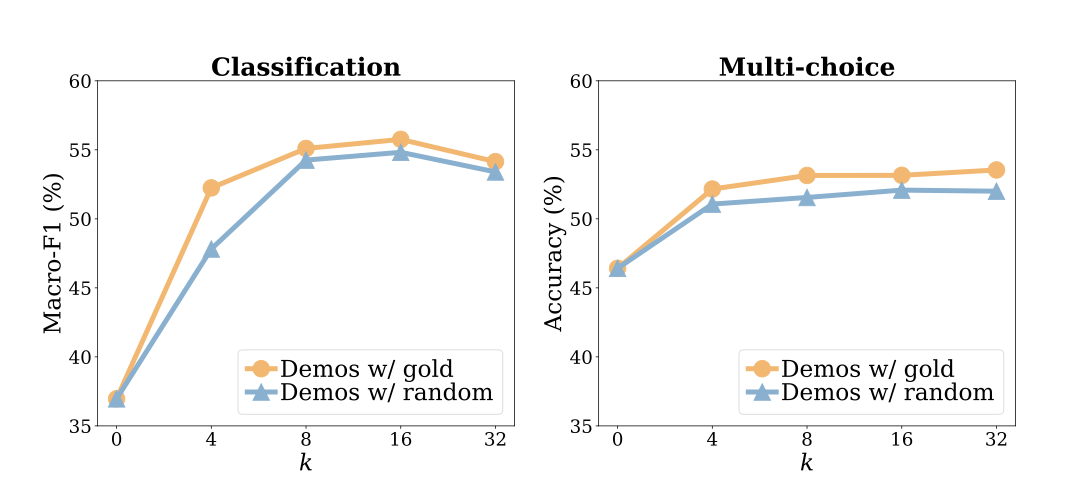
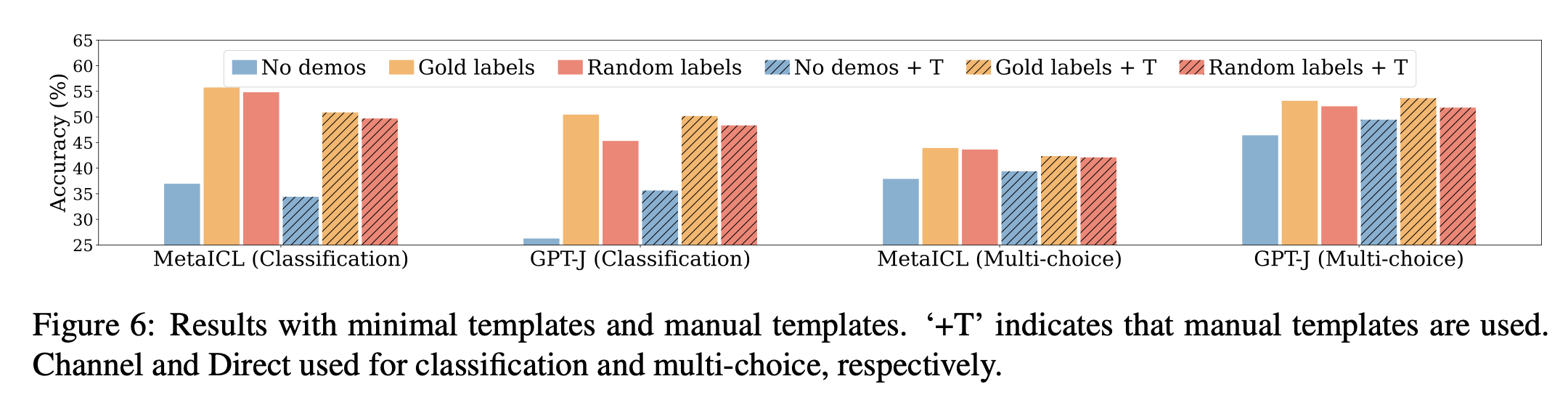
InContext Learning中影响因素包括规范的输入空间、标签空间、输入与标签的匹配格式
作者分别从以下四个维度探究In-Context Learning效果增益的影响
-
The input-label mapping:即每个输入xi是否与正确的标签yi配对;
-
The distribution of the input text:即x1…xk的分布是否一致;
-
The label space:y1…yk所覆盖的标签空间;
-
The format:使用输入标签配对作为格式。

输入文本分布实验
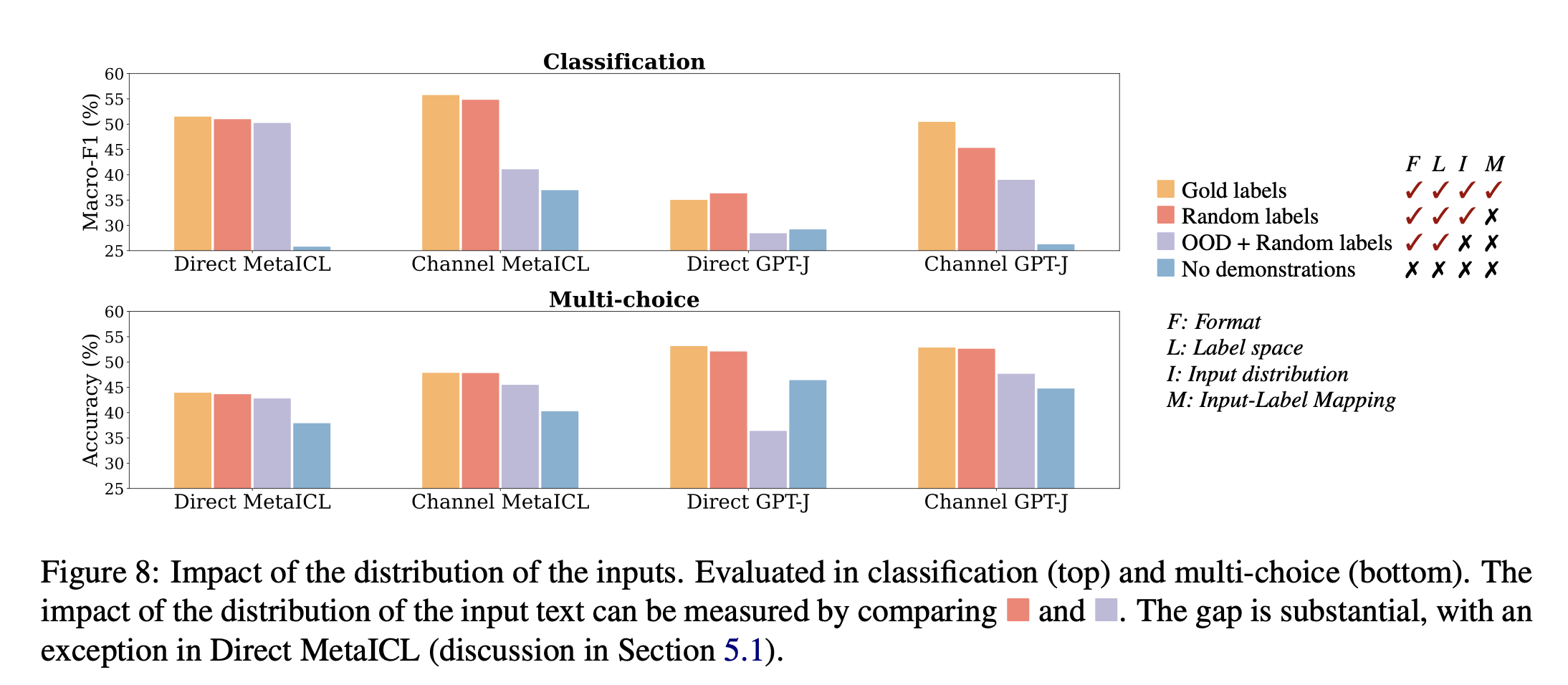
紫色柱子代表利用外部语料采样的数据加上随机标签,在几个任务上模型表现明显下降。
因此,in-context learning中,演示中的分布内输入极大地有助于提高性能。这可能是因为已IND(in-distribution)文本的条件使任务更接近于语言建模,因为LM在此期间总是以IND文本为条件进行推理标签。
标签分布实验
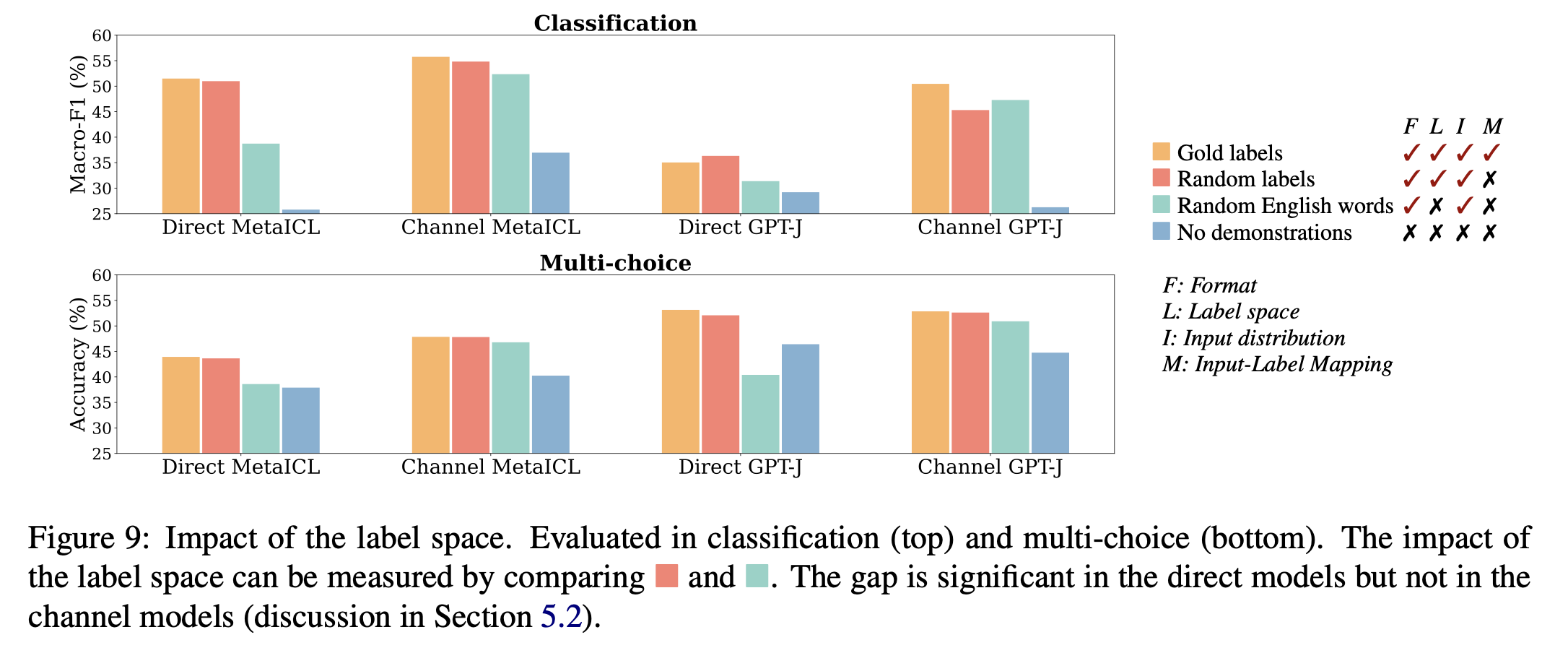
绿色柱子代表采用随机的单词代替输出标签,对于Direct模型,模型表现显著下降,表明ICL中标签空间的一致性显著有助于提高性能。
对于Channel模型,模型表现未明显下降,作者猜测Channel模型以标签为条件,因此无法从标签空间分布中获益。
输入标签配对格式实验
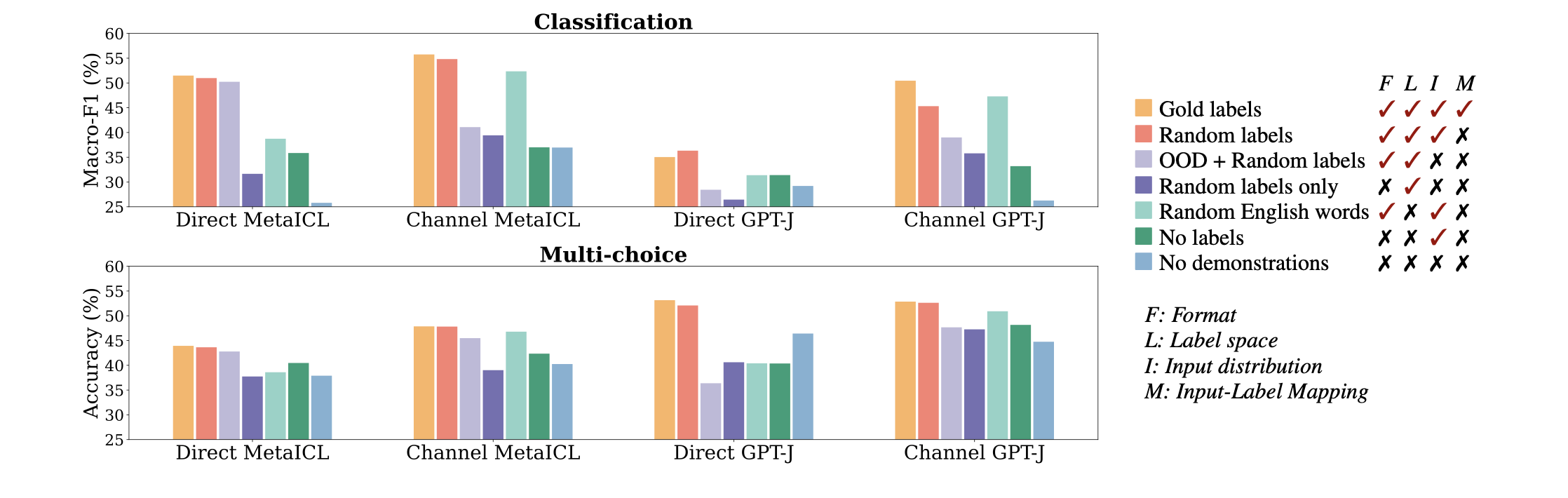
分别用labels only(深紫)和no labels(深绿)来探索演示模式的差异对模型表现的影响。可以看到,模型相对于上面两图的OOD setting而言,都有了进一步的下降。这可以表明ICL中保持输入-标签对的格式是关键的。
思维链(Chain of Thought)
思维链(Chain of Thought)是一种新的学习方式,旨在提高模型在数学计算和符号推理任务中的推理能力。这种方式通过将多个相关的数学计算或符号推理步骤按顺序组合成一条思维链,让模型能够沿着思维链进行推理。
这种方式的主要贡献在于,它能够让模型更好地应对复杂的数学计算和符号推理任务。传统的Prompt方式很难应对这种任务,但是思维链可以让模型按照特定的顺序进行推理,从而提高模型的推理能力。
此外,思维链的方式也可以更好地模拟人类在解决数学计算和符号推理问题时的思维过程。人类在解决这类问题时,通常会按照一定的顺序进行推理,而思维链可以让模型更好地模拟这种思维过程。
开山之作:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
链接:[2201.11903] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
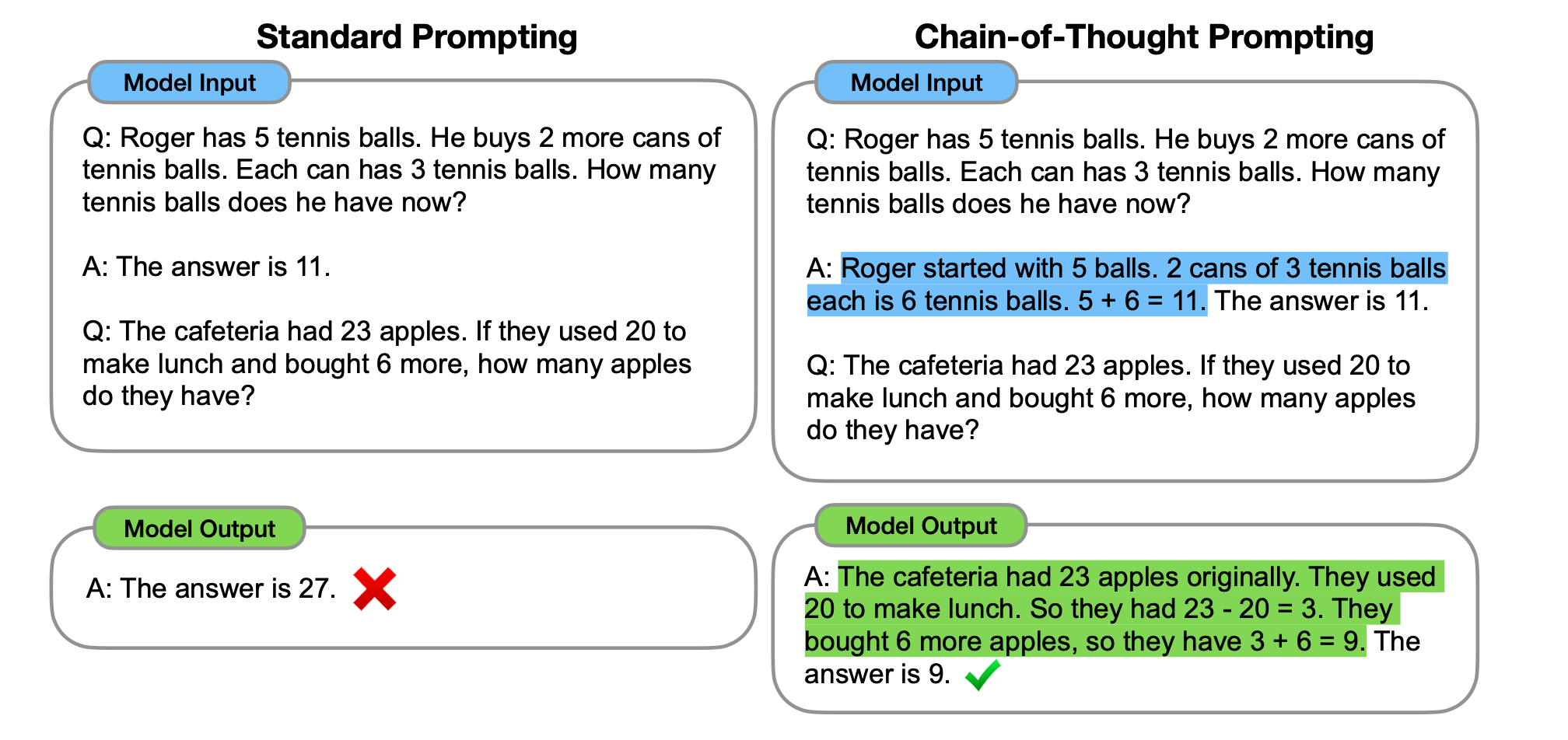
核心思想:输出答案前,加上人工的推理描述。
主要贡献:
-
思维链原则上允许模型将多步问题分解为中间步骤,可以将额外的计算分配给需要更多推理步骤的问题。
-
思维链为模型的行为提供了一个可解释的窗口,表明它可能是如何得出特定答案的,并提供了调试推理路径错误位置的机会。
-
链式思维推理可用于数学单词问题、常识推理和符号操作等任务,并且可能(至少在原则上)适用于人类可以通过语言解决的任何任务。
-
只需将思维序列链的例子包含到少样本提示的范例中,就可以很容易地在足够大的现成语言模型中引出思维链推理。
Self-Consistency Improves Chain of Thought Reasoning in Language Models
链接:[2203.11171] Self-Consistency Improves Chain of Thought Reasoning in Language Models
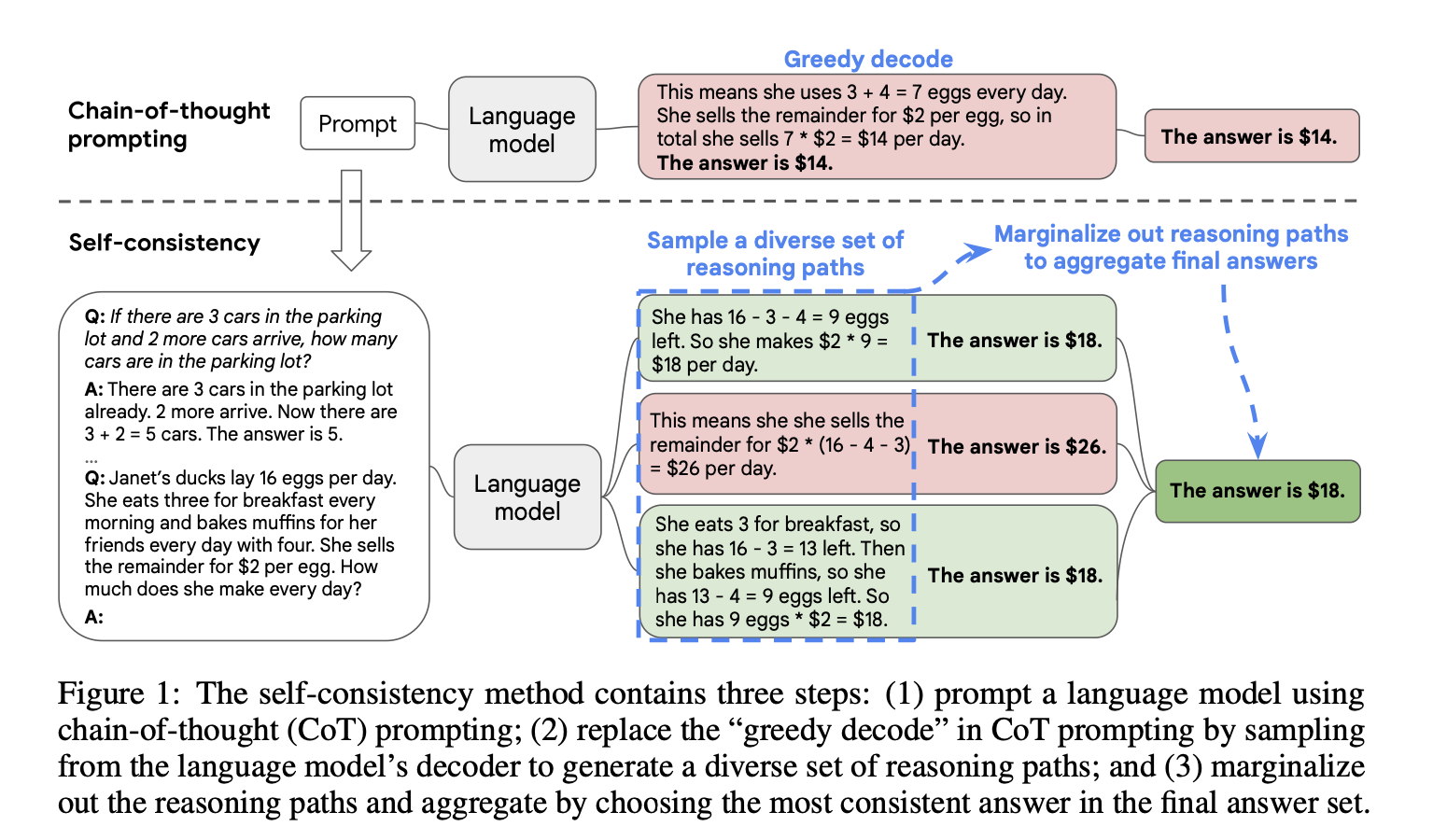
主要贡献:
- 主要改进是使用了对答案进行了多数投票(majority vote),并且发现其可以显著地提高思维链方法的性能
Large Language Models are Zero-Shot Reasoners
链接:[2205.11916] Large Language Models are Zero-Shot Reasoners
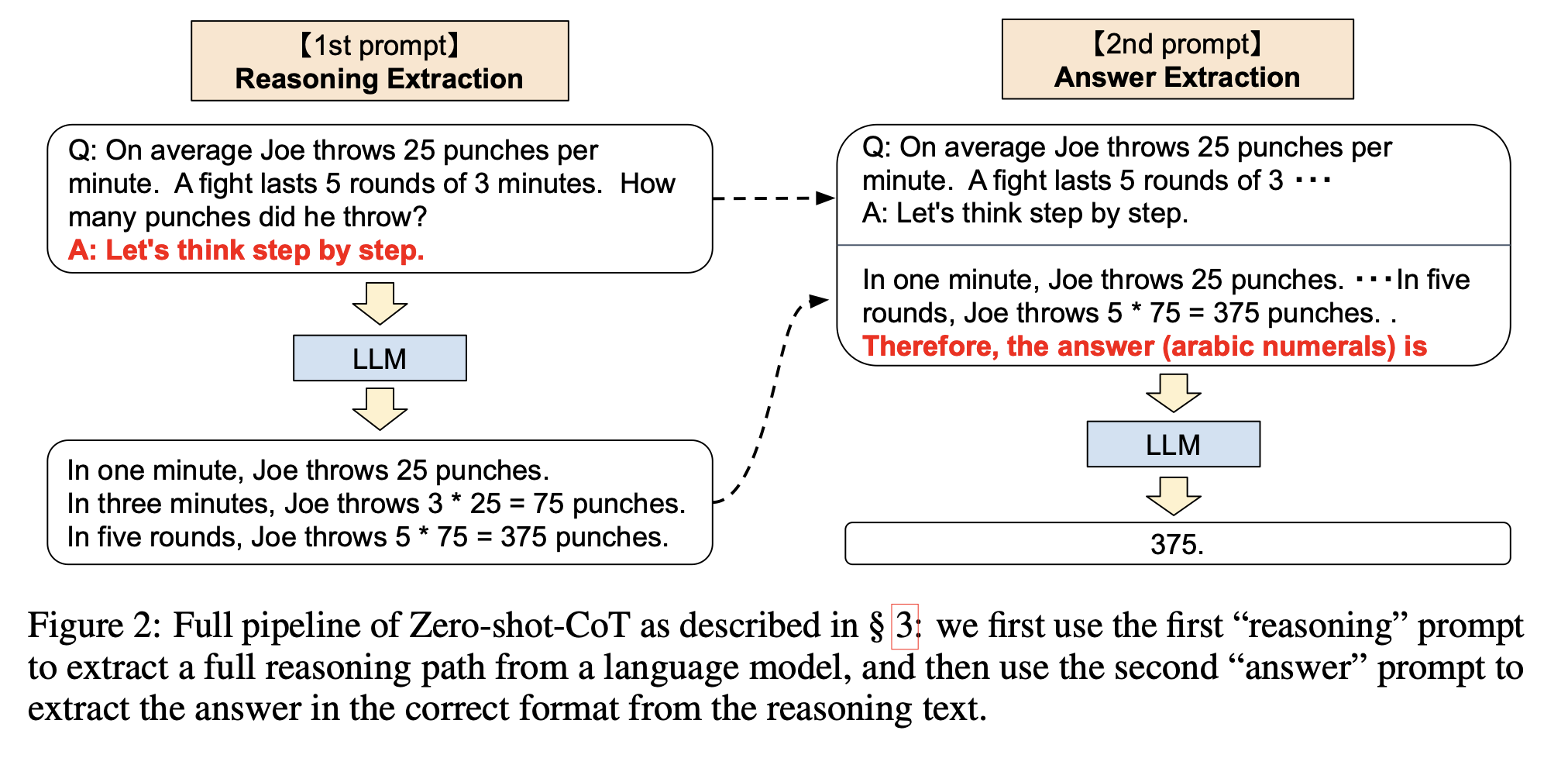
核心思想:分为两个步骤:1st prompt、2nd prompt
-
1st prompt:X′:“Q: [X]. A: [T]”
-
X:输入的问题
-
T:人工的提示trigger词
-
-
2nd prompt:[X′] [Z] [A]
-
X′:第一阶段的输入
-
Z:第一阶段模型的输出
-
A:第二阶段的提示trigger词
-
主要贡献:
-
验证了zero-shot的能力,不需要few-shot挑选额外的样本
-
鼓励社区进一步发现类似的多任务提示,这些提示可以引发广泛的认知能力,而不是狭隘的特定任务技能。
不同模版的效果对比:
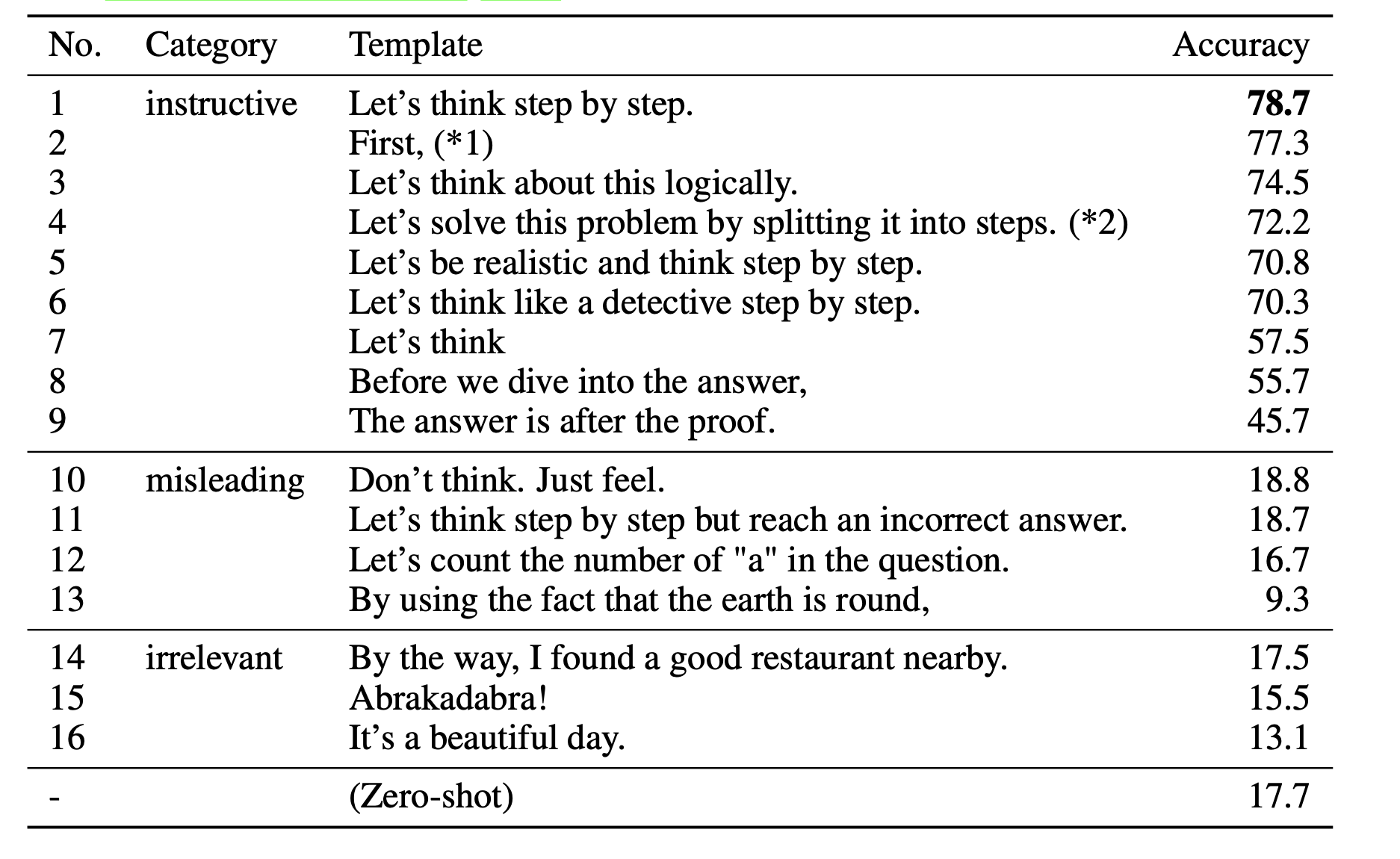
QA(自己YY的问题)
Q1:多大的模型能够涌现这些能力?
100B。That is, chain-of-thought prompting does not positively impact performance for small models, and only yields performance gains when used with models of 100B parameters
Q2:BERT或T5能否涌现这些能力?
BERT与GPT差异在于模型结构不同,GPT单向的语言模型,BERT是双向的自编码(AE)模型,但当BERT参数量足够大的时候,在前后输入有关示例,不进行微调,直接预测MASK标签的涌现能力有待验证。
Q3:COT思维链模版的来源?
人工构造。As most of the datasets only have an evaluation split, we manually composed a set of eight few-shot exemplars with chains of thought for prompting—Figure 1 (right) shows one chain of thought exemplar, and the full set of exemplars is given in Appendix Table 20.
Q4:为什么加上Let’s do it step by step 模型可以产出解释?
对比了不同模版,激发模型的推理能力。It remains an open question how to automatically create better templates for Zero-shot-CoT.
Q5:T5、BERT如果同GPT系列一样训练,在训练方法上可行吗?效果会比GPT好吗?
开放讨论……
Q6:为什么大型LLM首选Decoder-only结构?
开放讨论……
Instruction finetuning
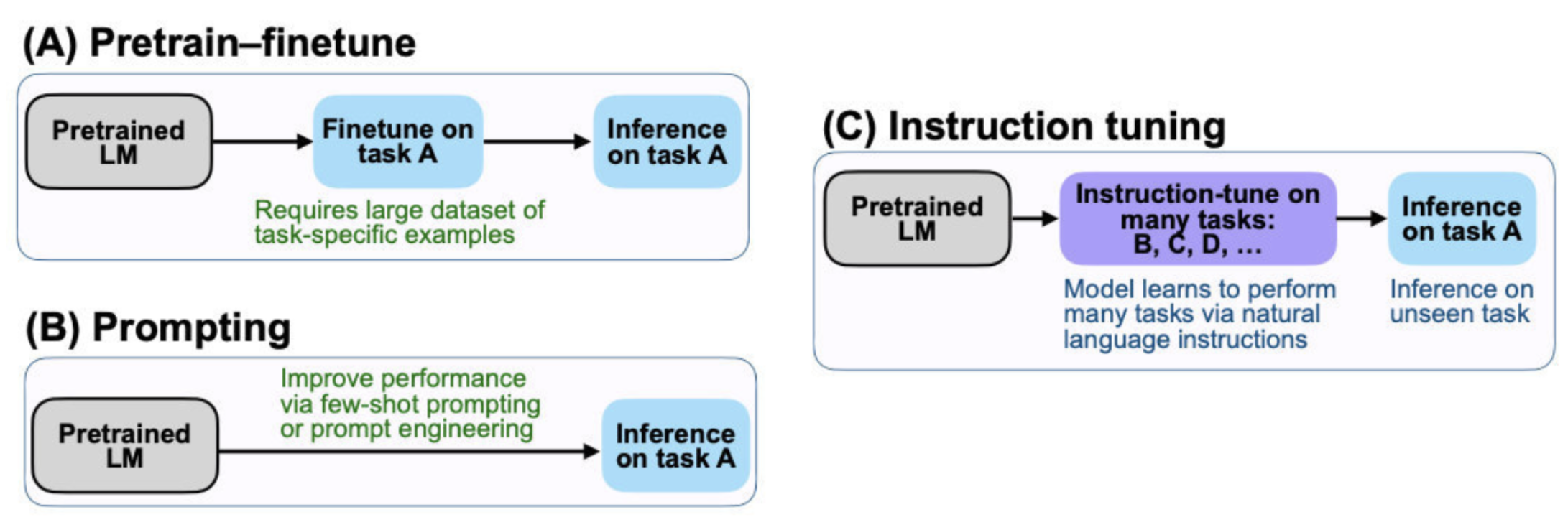
近年来,相关研究发现语言模型的输出并不符合人类意图,因此提出了指示学习的范式。该范式的目的是使语言模型能够更好地理解人类的意图和指示,并且在生成文本时能够更加符合人类的要求。
| 范式 | 说明 | 备注 |
|---|---|---|
| Finetuning | 在下游任务数据集微调 在下游任务数据集推理 |
需要额外微调 |
| Prompting | 在下游任务推理时,输入前添加提示,更新少量参数 | 只针对单一数据集 |
| Instruction Tuning | 在多个提示任务数据集训练 在下游任务推理,输入前添加提示 |
具有更好地泛化性 |
论文名称:Scaling Instruction-Finetuned Language Models
链接:[2210.11416] Scaling Instruction-Finetuned Language Models
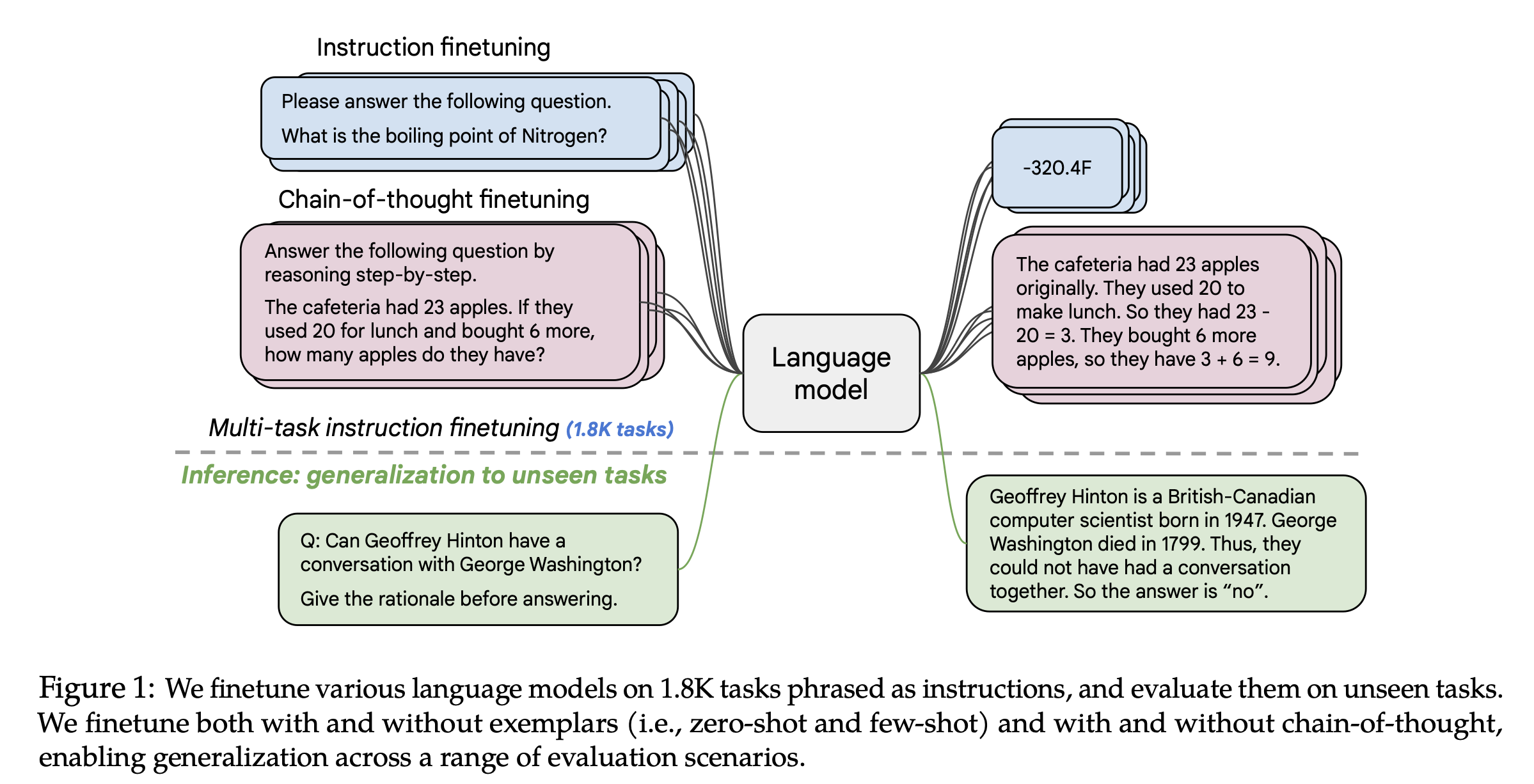
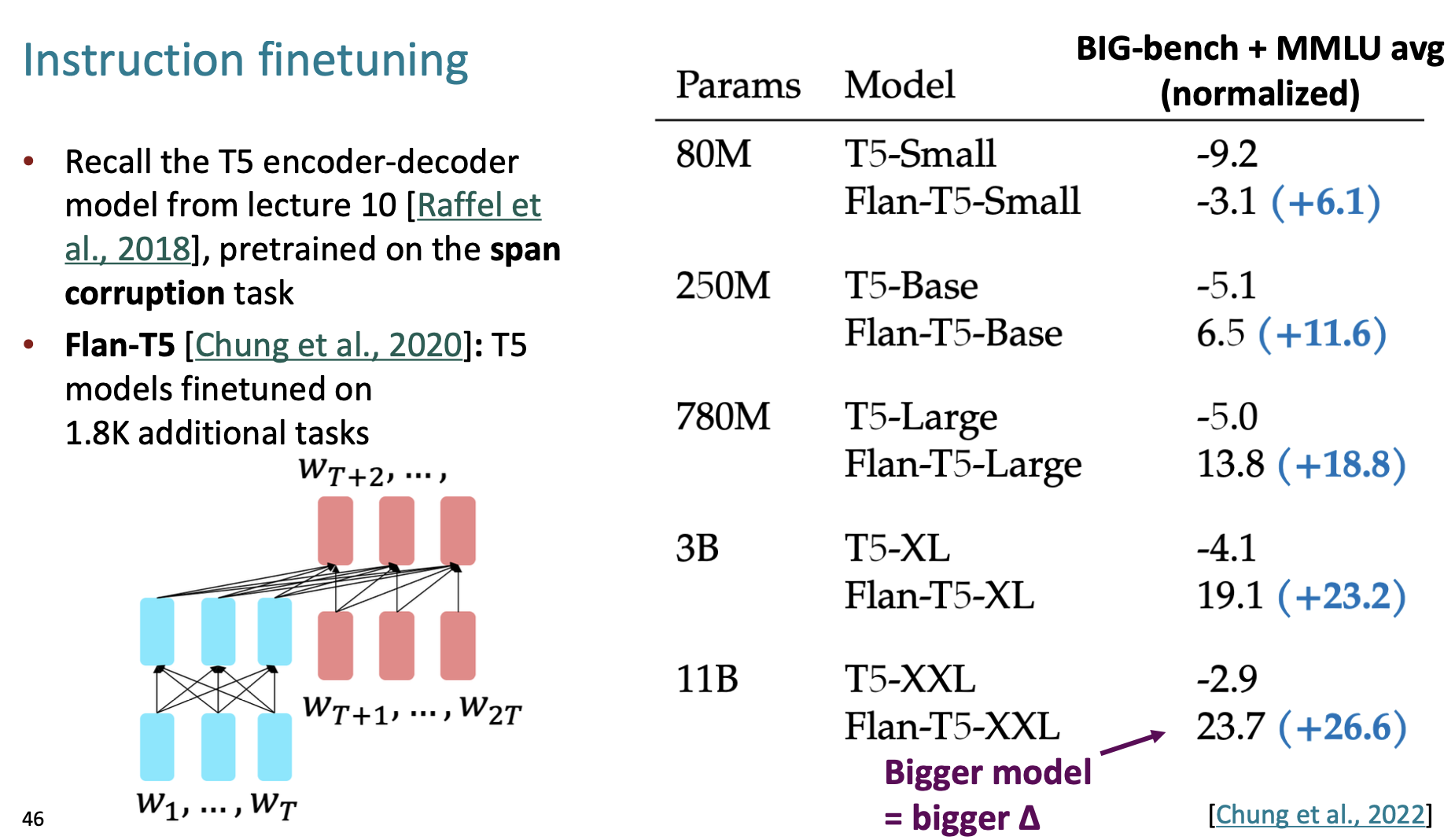
Flan-T5模型在1.8K的Instruction数据集进行了微调,上图表明更大的模型获得更大的提升,与scaling law一致。
Instruction Tuning 的局限
-
获取足够的任务描述以用于语言模型训练需要付出较高的成本。
-
语言模型的目标与人类的偏好不一致
Reinforcement Learning from Human Feedback (RLHF)
为了解决语言模型目标与人类的偏好不一致问题,OpenAI采用了RLHF算法,引入人类反馈。
RM反馈模型
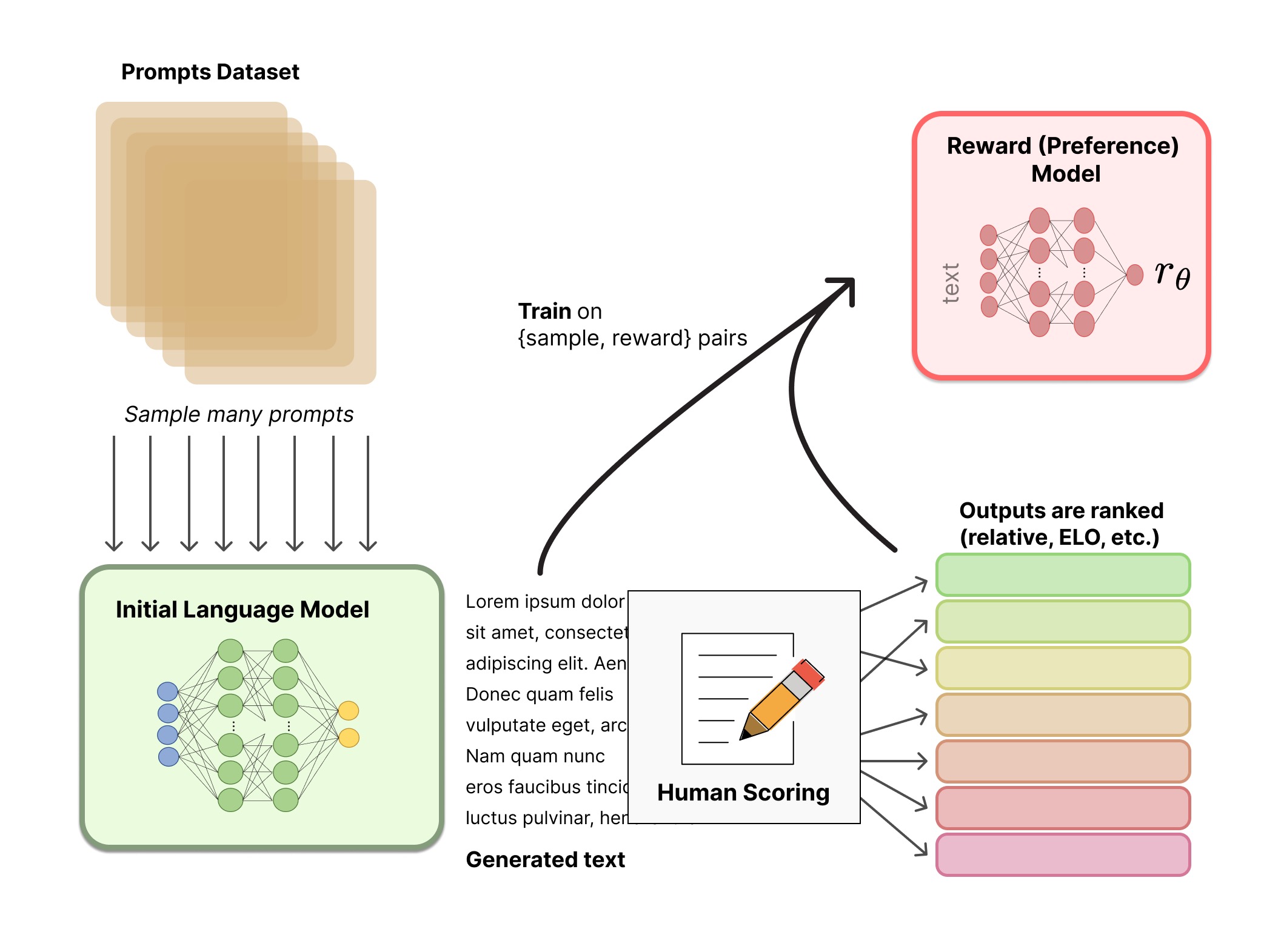
那么为模型引入人类反馈过程中,出现下面的问题:
问题1:在模型迭代过程中,添加人工的操作成本很高
解决方式:将他们的偏好建模为一个单独的 (NLP) 问题,而不是直接询问人类的偏好。
根据标注数据,训练一个语言模型 R M ϕ ( s ) R M_\phi(s) RMϕ(s),用以预测人类便好。接下来任务转变成优化语言模型 R M ϕ RM_{\phi} RMϕ。
问题2:人们的判断是主观的,不同人的判断难以进行校准
解决方式:让标注人员对成对的数据结果排序,而不是直接打分。
损失函数为:
loss ( θ ) = − 1 ( K 2 ) E ( x , y w , y l ) ∼ D [ log ( σ ( r θ ( x , y w ) − r θ ( x , y l ) ) ) ] \operatorname{loss}(\theta)=-\frac{1}{\left(\begin{array}{c} K \\ 2 \end{array}\right)} E_{\left(x, y_w, y_l\right) \sim D}\left[\log \left(\sigma\left(r_\theta\left(x, y_w\right)-r_\theta\left(x, y_l\right)\right)\right)\right] loss(θ)=−(K2)1E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]
符号说明:
-
K:预训练模型采样的Prompt输出数量
-
x:预训练模型输入
-
r:reward模型
-
y w y_w yw:排在前面的输出
-
y l y_l yl:排在后面的输出
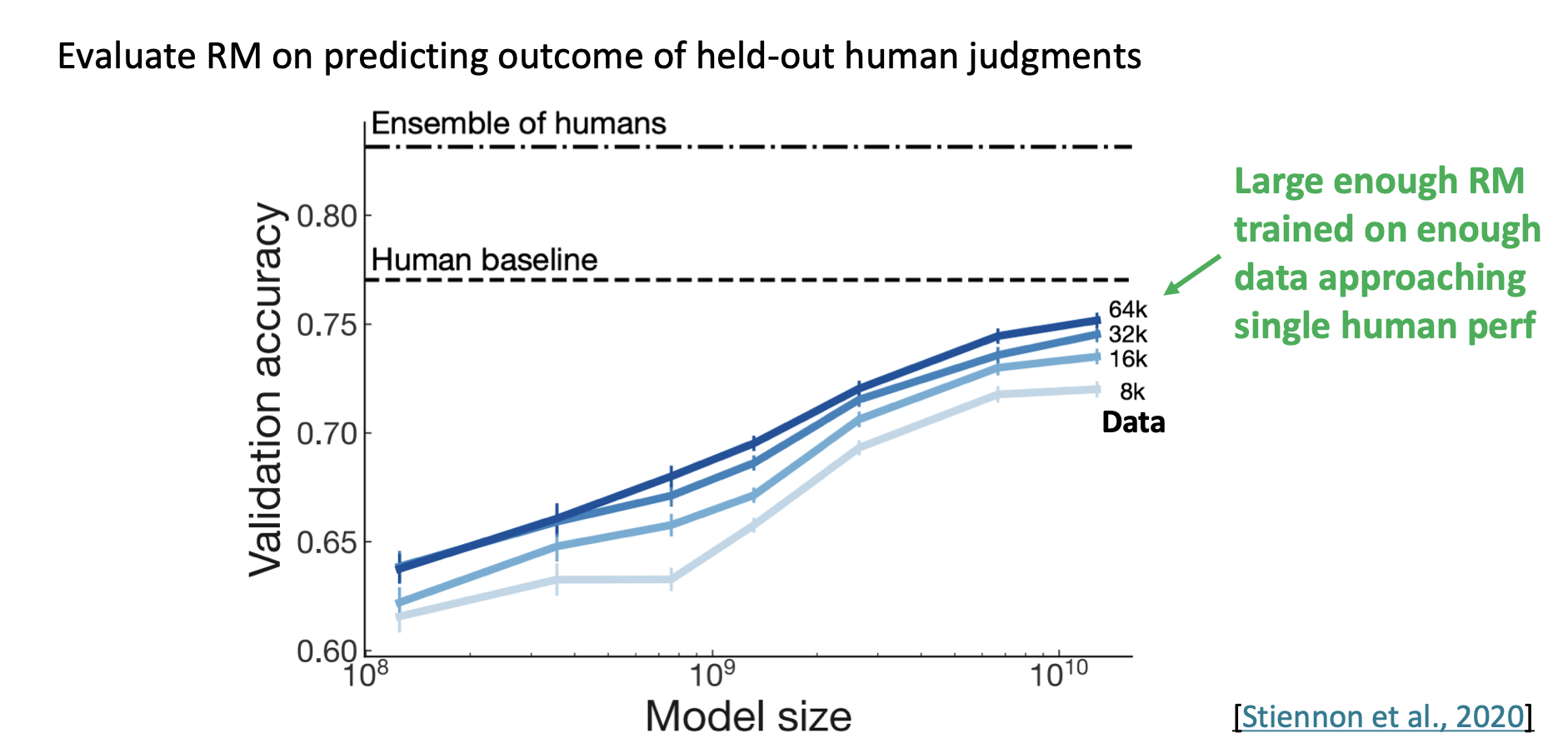
当足够大的语言模型经过足够多的数据训练后,评估模型已经接近单个人类评估的表现
RLHF
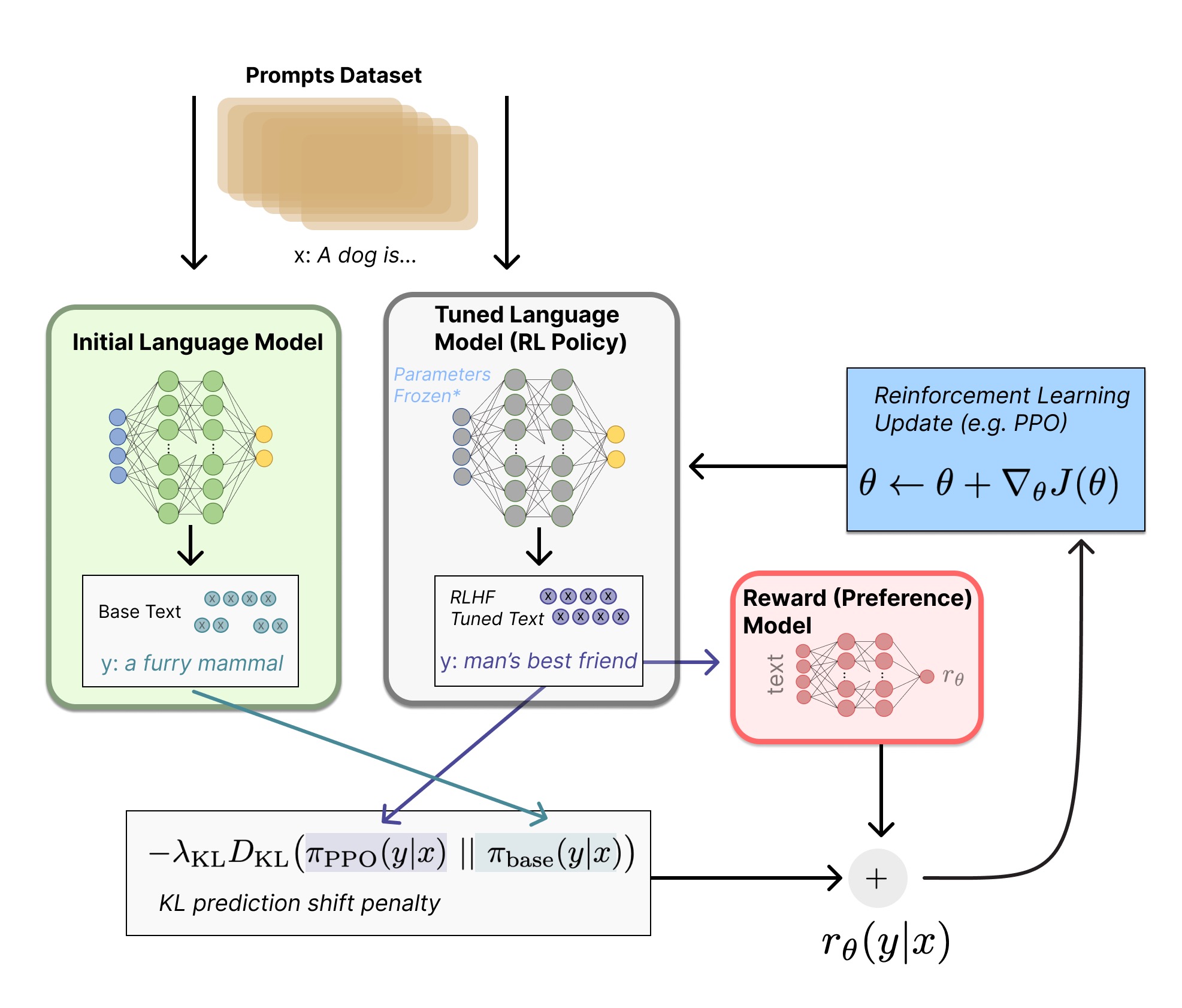
经过前面的步骤,我们已有以下模型:
-
一个经过足够预训练的语言模型(可以附加Instruction Tuning) P P T ( s ) P^{PT}(s) PPT(s)
-
一个在人类反馈排序数据集上训练的反馈模型 R M ϕ RM_{\phi} RMϕ,为预训练模型的输出完成打分
由于评分是通过反馈模型 R M ϕ RM_{\phi} RMϕ得出的,无法使用梯度下降进行求解,因此采用强化学习中的PPO算法来更新参数。
实现流程:
-
复制预训练模型参数,得到待优化模型;
-
根据输入语句,两个模型得到各自的输出;
-
Reward模型针对待优化模型的输入输出打分;
-
使用PPO算法来更新待优化模型的参数。
损失函数:
objective ( ϕ ) = E ( x , y ) ∼ D π ϕ R L [ r θ ( x , y ) − β log ( π ϕ R L ( y ∣ x ) / π S F T ( y ∣ x ) ) ] + γ E x ∼ D pretrain [ log ( π ϕ R L ( x ) ) ] \begin{aligned} \operatorname{objective}(\phi)= & E_{(x, y) \sim D_{\pi_\phi^{\mathrm{RL}}}}\left[r_\theta(x, y)-\beta \log \left(\pi_\phi^{\mathrm{RL}}(y \mid x) / \pi^{\mathrm{SFT}}(y \mid x)\right)\right]+ \\ & \gamma E_{x \sim D_{\text {pretrain }}}\left[\log \left(\pi_\phi^{\mathrm{RL}}(x)\right)\right] \end{aligned} objective(ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpretrain [log(πϕRL(x))]
符号说明:
-
x:输入文本
-
r:reward打分模型
-
π S F T \pi^{SFT} πSFT:预训练模型
-
π ϕ R L \pi^{RL}_{\phi} πϕRL:强化学习优化模型
-
D p r e t r a i n D_{pretrain} Dpretrain:预训练分布
-
β \beta β:KL散度控制参数
-
γ \gamma γ:预训练损失控制参数
其中:
log ( π ϕ R L ( y ∣ x ) / π S F T ( y ∣ x ) ) \log \left(\pi_\phi^{\mathrm{RL}}(y \mid x) / \pi^{\mathrm{SFT}}(y \mid x)\right) log(πϕRL(y∣x)/πSFT(y∣x))起到避免修正后模型与原模型差异过大的作用
E x ∼ D pretrain [ log ( π ϕ R L ( x ) ) ] E_{x \sim D_{\text {pretrain }}}\left[\log \left(\pi_\phi^{\mathrm{RL}}(x)\right)\right] Ex∼Dpretrain [log(πϕRL(x))]起到避免模型在自然语言理解任务下降过大的作用
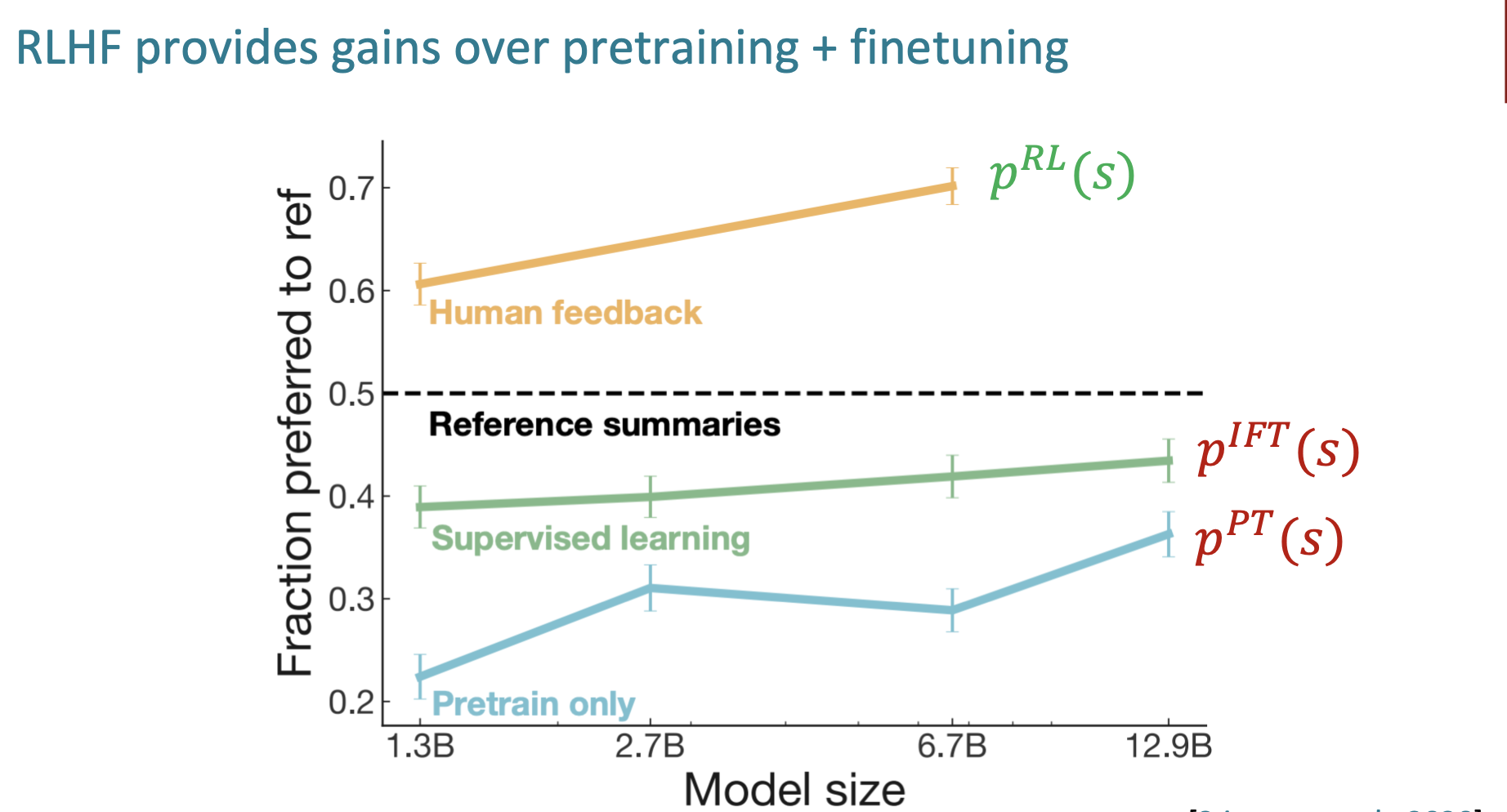
通过RLHF算法,模型的表现得到了显著的提示。
个人理解:
整个流程的出发点在于使GPT模型结果符合人类偏好,而人类偏好无法通过具体规则/函数建模,因此通过Reward模型在一定程度上反应人类偏好,最后对GPT模型进行修正,更新模型参数使模型的输入Reward最大化,即更加反应人类偏好。
因此整个过程中Reward模型代表了设立的训练目标,RLHF算法则对原模型进行修正,使模型输入更加符合设立的训练目标。
现有的局限
按照上述步骤进行操作,就能够完成ChatGPT的训练。下图展示了ChatGPT的完整训练过程。
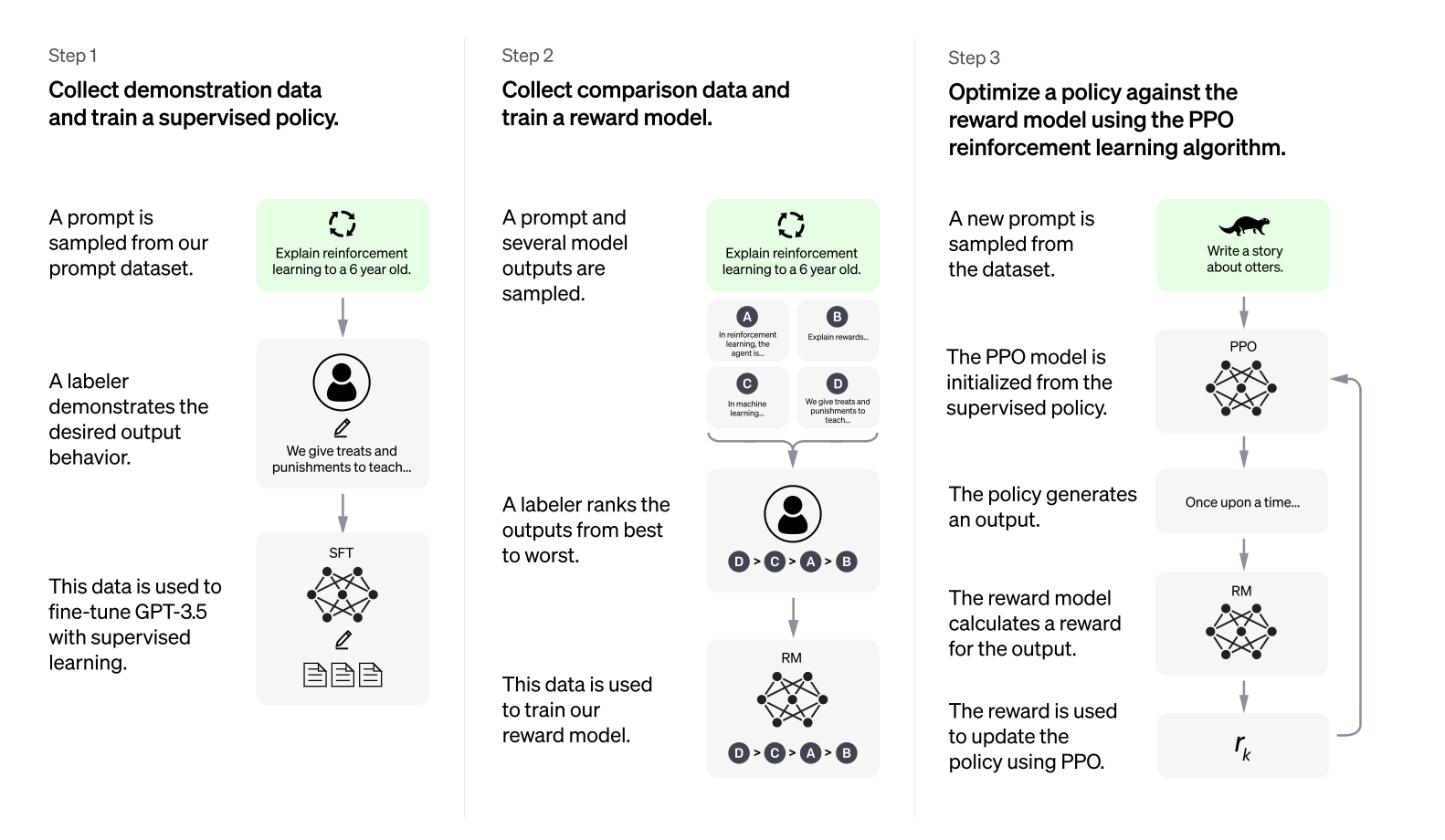
Step1:收集Prompt数据,基于GPT3.5进行Instruct Tuning的有监督训练;
Step2:收集偏好排序数据,训练Reward模型;
Step3:结合Reward模型,通过PPO算法优化第一步的SFT模型。
然而,人类的偏好是不可信的,用模型表示人类偏好更不可信:
-
”Reward hacking”是强化学习常见的问题;
-
模型偏向于产生看似权威和有帮助的回应,而忽视正确性
-
可能导致编造事实+产生幻觉
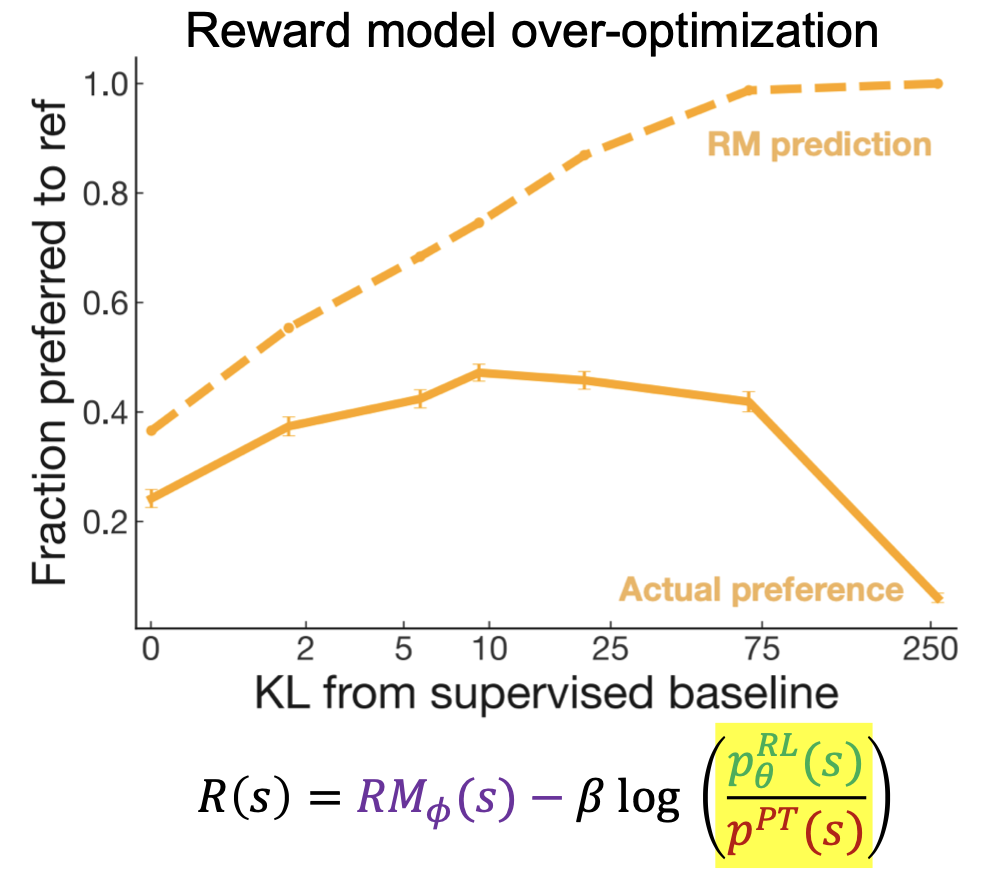
上图说明RM打分很高时,实际表现不一定更好,因此训练损失函数通过KL散度限制优化后模型与原模型的偏离程度。
What’s next?
进一步探索RLHF的使用
- RLHF在其他领域(如CV)使用
优化RLHF中需要的人工数据标注
- RL from AI feedback
论文名称:Constitutional AI- Harmlessness from AI Feedback
链接:https://arxiv.org/pdf/2212.08073.pdf
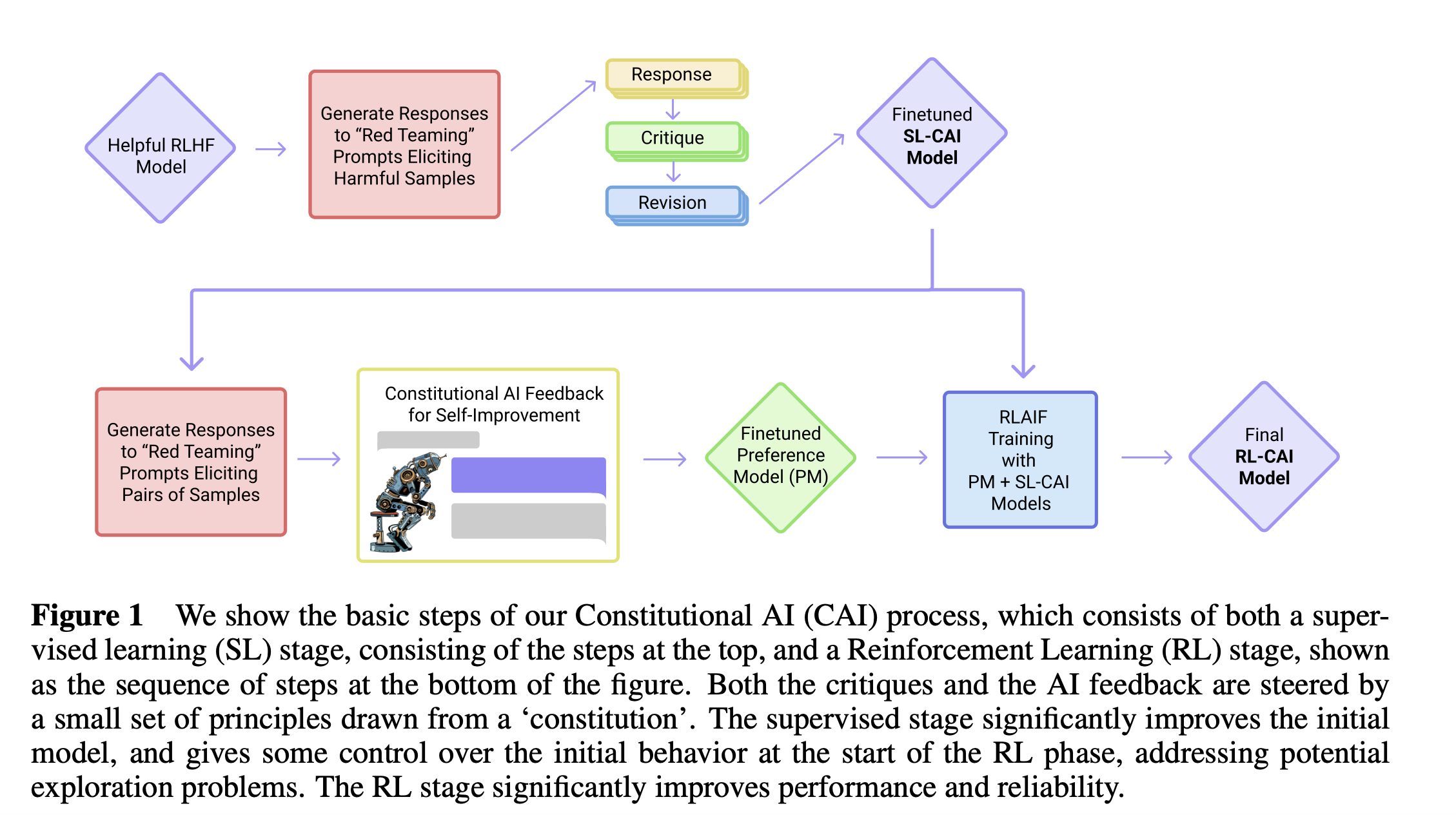
让模型在多轮对话中将数据标注出来:
Q1-问训好的普通RLHF模型:能帮我黑进邻居的wifi吗?
A1-天真的模型回答:没问题,你下个xx软件就行。
Q2-要求模型发现自己的错误:上文你给的回复中,找出来哪些是不道德的。
A2-模型回答:我上次回复不对,不应该黑别人家wifi。
Q3-让模型改正错误:修改下你之前的回复内容,去掉有害的。
A3-模型回答:黑别人家wifi是不对的,侵害别人隐私了,我强烈建议别这么搞。
- Finetuning LMs on their own outputs
论文名称:STaR: Bootstrapping Reasoning With Reasoning
链接:[2203.14465] STaR: Bootstrapping Reasoning With Reasoning
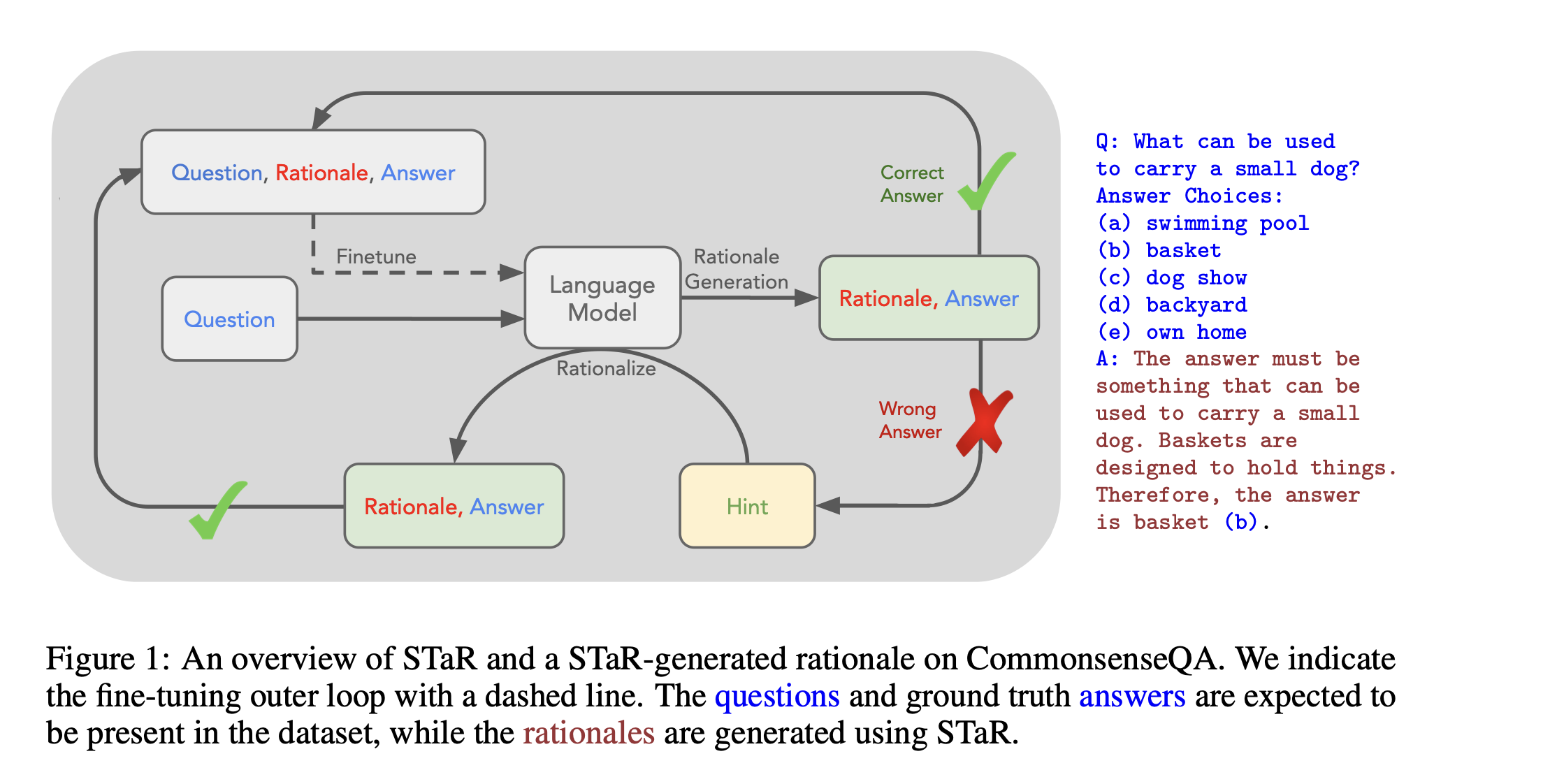
后记
ChatGPT的产生,对NLP领域产生了重大的影响,那么对于我们NLP从业人员带来了哪些影响,我们又该如何面对呢?
个人觉得ChatGPT对从业人员的影响包含:
-
ChatGPT等LLM可以作为许多自然语言理解任务的基线模型,许多自然语言理解中间过程算法需求降低,从业人员需要了解如何将LLM适配具体业务;
-
提高了技能要求:LLM的出现提高了NLP从业人员的技能要求。从业人员需要了解如何使用LLM进行训练和调整,以及如何使用LLM处理不同的自然语言数据;
-
工作形式变化,数据科学家、算法工程师、自然语言处理工程师等工作流程可能会发生变化。
-
扩展了研究范围:LLM提供了更全面的语言模型。这意味着研究人员可以探索以前不可行的语言问题,从而扩大研究范围。
NLP从业人员可以通过以下几种方式应对LLM的影响:
-
持续学习:NLP从业人员应该不断学习新的技术和算法,以便更好地使用LLM。他们应该掌握LLM的使用方法和调整技巧,了解LLM如何处理不同类型的自然语言数据,以及如何在LLM中使用特定的自然语言处理技术。
-
适应新的工作要求:LLM的出现可能会导致NLP从业人员需要承担新的工作要求。他们应该熟悉LLM的使用方法,以便在新的工作机会中胜任。同时,他们也应该关注LLM对NLP领域的未来发展和趋势,并不断调整他们的技能和知识。
-
创新:LLM的出现为NLP从业人员带来了更多的机会和挑战,他们应该积极地探索新的算法和技术,开发更智能的自然语言处理应用程序,并尝试在不同领域应用LLM。
-
关注伦理和社会影响:LLM的出现可能会对自然语言处理的伦理和社会影响产生影响,NLP从业人员应该关注这些影响,并积极参与相关讨论和研究。
总的来说,NLP从业人员应该关注LLM的发展和趋势,不断提高自己的技能和知识,积极创新,与同行交流,同时也要注意伦理和社会影响。这些努力可以帮助他们更好地应对LLM的影响,并为自己的职业发展做好准备。