文章目录
系统内置函数
查看系统自带的函数
show functions;
会返回289个函数的列表
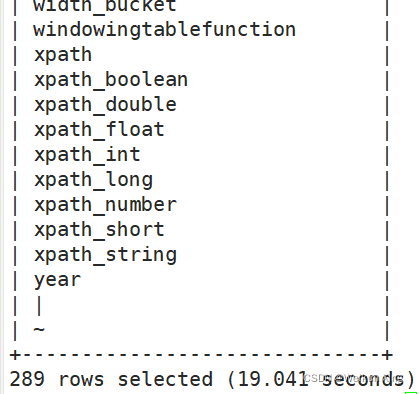
显示自带的函数的用法
desc function upper;
+----------------------------------------------------+
| tab_name |
+----------------------------------------------------+
| upper(str) - Returns str with all characters changed to uppercase |
+----------------------------------------------------+
详细显示自带的函数的用法
desc function extended upper;
+----------------------------------------------------+
| tab_name |
+----------------------------------------------------+
| upper(str) - Returns str with all characters changed to uppercase |
| Synonyms: ucase |
| Example: |
| > SELECT upper('Facebook') FROM src LIMIT 1; |
| 'FACEBOOK' |
| Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDFUpper |
| Function type:BUILTIN |
+----------------------------------------------------+
常用内置函数
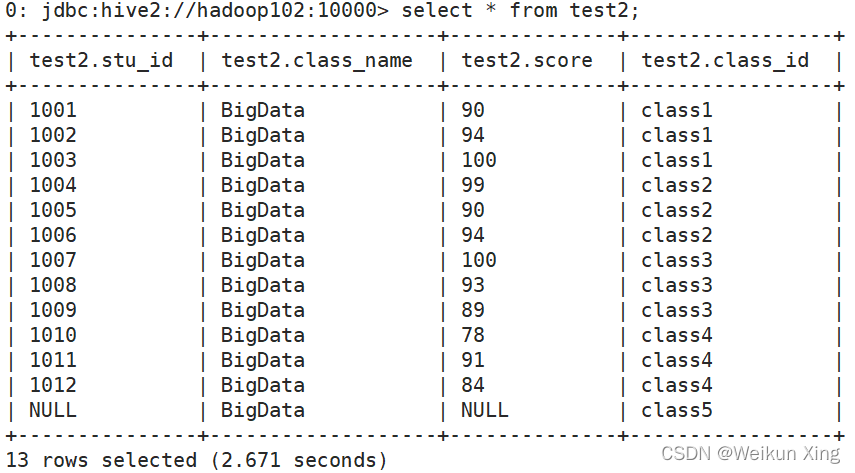
空字段赋值
select nvl(stu_id,1111),nvl(score,0) from test2;
+-------+------+
| _c0 | _c1 |
+-------+------+
| 1001 | 90 |
| 1002 | 94 |
| 1003 | 100 |
| 1004 | 99 |
| 1005 | 90 |
| 1006 | 94 |
| 1007 | 100 |
| 1008 | 93 |
| 1009 | 89 |
| 1010 | 78 |
| 1011 | 91 |
| 1012 | 84 |
| 1111 | 0 |
+-------+------+
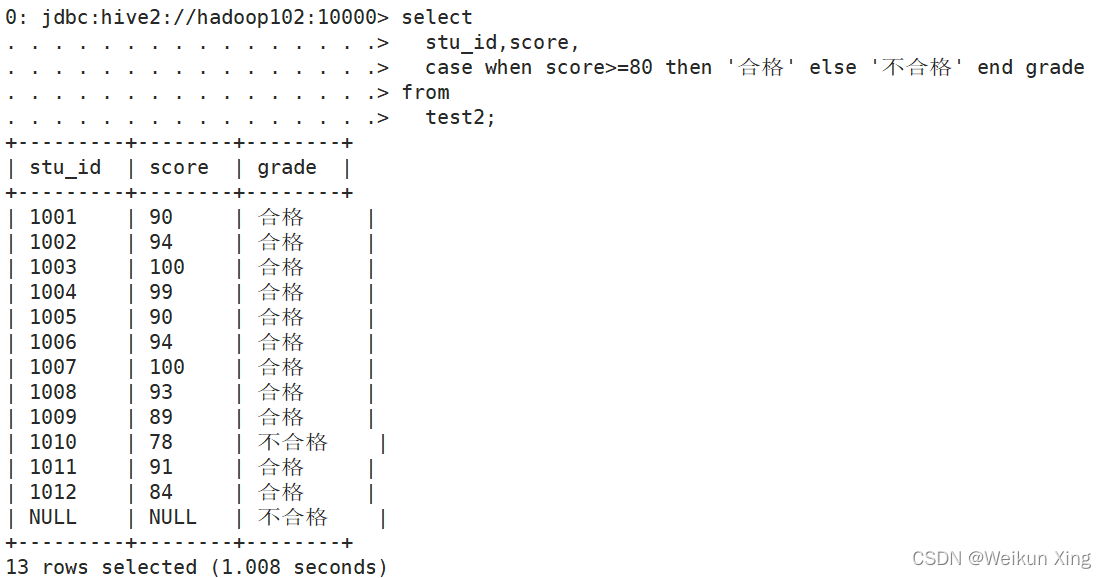
CASE WHEN THEN ELSE END
select
stu_id,score,
case when score>=80 then '合格' else '不合格' end grade
from
test2;
行转列
vim person_info.txt
一鼠 白羊座 A
二牛 射手座 A
三虎 白羊座 B
四兔 白羊座 A
五龙 射手座 A
六蛇 白羊座 B
create table person_info(
name string,
constellation string,
blood_type string)
row format delimited fields terminated by "\t";
load data local inpath "/opt/datafiles/person_info.txt" into table person_info;
SELECT t1.c_b , CONCAT_WS("|",collect_set(t1.name))
FROM (
SELECT NAME ,CONCAT_WS(',',constellation,blood_type) c_b
FROM person_info
)t1
GROUP BY t1.c_b;
+---------+--------+
| t1.c_b | _c1 |
+---------+--------+
| 射手座,A | 二牛|五龙 |
| 白羊座,A | 一鼠|四兔 |
| 白羊座,B | 三虎|六蛇 |
+---------+--------+
列转行
vim movie_info.txt
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作
create table movie_info(
movie string,
category string)
row format delimited fields terminated by "\t";
load data local inpath "/opt/datafiles/movie_info.txt" into table movie_info;
SELECT movie,category_name
FROM movie_info
lateral VIEW
explode(split(category,",")) movie_info_tmp AS category_name;
+--------------+----------------+
| movie | category_name |
+--------------+----------------+
| 《疑犯追踪》 | 悬疑 |
| 《疑犯追踪》 | 动作 |
| 《疑犯追踪》 | 科幻 |
| 《疑犯追踪》 | 剧情 |
| 《Lie to me》 | 悬疑 |
| 《Lie to me》 | 警匪 |
| 《Lie to me》 | 动作 |
| 《Lie to me》 | 心理 |
| 《Lie to me》 | 剧情 |
| 《战狼2》 | 战争 |
| 《战狼2》 | 动作 |
+--------------+----------------+
窗口函数(开窗函数)
vim business.txt
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
create table business(
name string,
orderdate string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
load data local inpath "/opt/datafiles/business.txt" into table business;
(1) 查询在2017年4月份购买过的顾客及总人数
select name,count(*) over()
from business
where substring(orderdate,1,7)='2017-04'
group by name;
(2) 查询顾客的购买明细及月购买总额
select name,orderdate,cost,sum(cost) over(partition by month(orderdate)) from business;
(3) 将每个顾客的cost按照日期进行累加
select name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加
sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加
sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行
from business;
(4) 查看顾客上次的购买时间
select name,orderdate,cost,
lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as time1, lag(orderdate,2) over (partition by name order by orderdate) as time2
from business;
(5) 查询前20%时间的订单信息
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;
Rank(排名函数)
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
数据准备
vim score.txt
name subject score
张三 语文 87
张三 数学 95
张三 英语 68
李四 语文 94
李四 数学 56
李四 英语 84
王五 语文 64
王五 数学 86
王五 英语 84
赵六 语文 65
赵六 数学 85
赵六 英语 78
create table score(
name string,
subject string,
score int)
row format delimited fields terminated by "\t";
load data local inpath '/opt/datafiles/score.txt' into table score;
select name,
subject,
score,
rank() over(partition by subject order by score desc) rp,
dense_rank() over(partition by subject order by score desc) drp,
row_number() over(partition by subject order by score desc) rmp
from score;
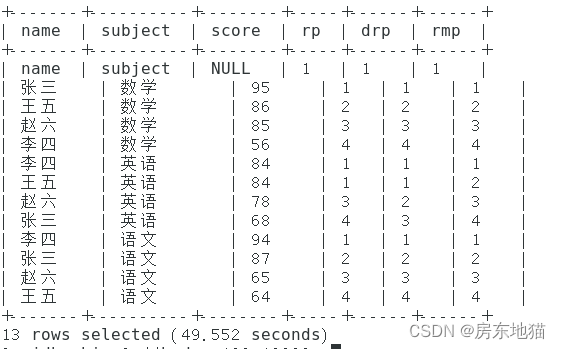
观察三种排序结果有何不同
自定义函数
UDF 一进一出
UDAF 多进一出
UDTF 一进多出
自定义UDF函数
需求:实现计算给定字符串的长度
例如:
select my_len("abcd");
4
new java class ‘CalStringLengthUDF’
package learn_hive;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* 插件性质的开发
* 1.实现接口或者继承类
* 2.重写相应的方法
* 3.打包
* <p>
* 自定义UDF函数类
* 继承Hive提供的GenericUDF类
*/
public class CalStringLengthUDF extends GenericUDF {
/**
* 初始化方法
*
* @param arguments 传入到函数中的参数对应的类型的鉴别器对象
* @return 指定函数的返回值类型对应的鉴别器对象
* @throws UDFArgumentException
*/
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
//1.校验函数的参数个数
if (arguments == null || arguments.length != 1) {
throw new UDFArgumentLengthException("函数参数格式不正确!");
}
//2.校验函数参数类型
if (!arguments[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)) {
throw new UDFArgumentTypeException(0, "函数参数类型不正确!");
}
//3.返回函数的返回值类型对应的鉴别器类型
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 函数核心处理方法
*
* @param arguments 传入到函数的参数
* @return 函数的返回值
* @throws HiveException
*/
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
//1.获取参数
Object argument = arguments[0].get();
if (argument == null) {
return 0;
}
return argument.toString().length();
}
@Override
public String getDisplayString(String[] strings) {
return "";
}
}
打包上传至虚拟机/opt/datafiles目录(参考两种方法,目录随意)
第一种方式
将打包好的jar包放到hive的lib目录下,重新启动hive服务,永久加载
第二种方式
hive命令行运行,临时加载
add jar xx目录/xx.jar;
我用第二种
hive命令行运行
//将jar包添加到hive的classpath
add jar /opt/datafiles/CalStringLengthUDF.jar
//创建临时函数与开发好的java class关联
create temporary function mylen as 'learn_hive.CalStringLengthUDF';
0: jdbc:hive2://hadoop102:10000> select mylen("abcde");
+------+
| _c0 |
+------+
| 5 |
+------+
select mylen(null);
+------+
| _c0 |
+------+
| 0 |
+------+
自定义UDTF函数
实现将一个任意分割符的字符串切割成独立的单词
new java class SplitStringToRowsUDTF
package learn_hive;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructField;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;
public class SplitStringToRowsUDTF extends GenericUDTF {
private List<String> outs = new ArrayList<>();
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
List<? extends StructField> structFieldRefs = argOIs.getAllStructFieldRefs();
if (structFieldRefs.size() != 2) {
throw new UDFArgumentLengthException("函数的参数个数不正确!");
}
for (int i = 0; i < structFieldRefs.size(); i++) {
StructField structFieldRef = structFieldRefs.get(i);
if (!structFieldRef.getFieldObjectInspector().getCategory().equals(ObjectInspector.Category.PRIMITIVE)) {
throw new UDFArgumentTypeException(i, "函数的参数类型不正确!");
}
}
List<String> structFieldNames = new ArrayList<>();
structFieldNames.add("word");
List<ObjectInspector> structFieldObjectInspectors = new ArrayList<>();
structFieldObjectInspectors.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(structFieldNames, structFieldObjectInspectors);
}
@Override
public void process(Object[] args) throws HiveException {
String words = args[0].toString();
String split = args[1].toString();
String[] splitwords = words.split(split);
for (String word : splitwords) {
outs.clear();
outs.add(word);
forward(word);
}
}
@Override
public void close() throws HiveException {
}
}
add jar /opt/datafiles/SplitStringToRowsUDTF.jar;
create temporary function splitwords as 'learn_hive.SplitStringToRowsUDTF';
select splitwords('hello,world,hello,hive,hello,hadoop',',');
+---------+
| word |
+---------+
| hello |
| world |
| hello |
| hive |
| hello |
| hadoop |
+---------+