一.RabbitMQ的一些知识
1.消息属性
RabbitMQ是基于AMQP消息传输协议来实现的消息中间件;类似HTTP有header和body两部分数据,Message是RabbitMQ中的消息体概念。
Message由Properties和Body组成,前者是一些元信息,如消息的优先级、持久化、传输格式(如JSON)、延迟等高级特性,Body则是传递的消息数据实体
2.消息投递
Exchange、Queue与Routing Key三个概念是理解RabbitMQ消息投递的关键。RabbitMQ中一个核心的原则是,消息不能直接投递到Queue中。
Producer只能将自己的消息投递到Exchange中,由Exchange按照routing_key投递到对应的Queue中。
3.消息可靠性
不同于HTTP的同步访问,RabbitMQ中,Producer并不知道消息是否被可靠地投递到了Consumer中处理。那么,RabbitMQ是如何保证消息的可靠投递?
主要是两点:第一,消息确认机制。Consumer处理完消息后,需要发送确认消息给Broker Server,可以选择“确认接收”、“丢弃”、“重新投递”三种方式。如果Consumer在Broker Server收到确认消息之前挂了,Broker Server便会重新投递该消息。
第二,可以选择数据持久化,这样即使RabbitMQ重启,也不会丢失消息
二.RabbitMQ使用场景
1.数据接入
假设有一个用户行为采集系统,负责从App端采集用户点击行为数据。通常会将数据上报和数据处理分离开,即App端通过REST API上报数据,后端拿到数据后放入队列中就立刻返回,而数据处理则另外使用Worker从队列中取出数据来做,如下图所示。

这样做的好处有:
第一,功能分离,上报的API接口不关心数据处理功能,只负责接入数据;
第二,数据缓冲,数据上报的速率是不可控的,取决于用户使用频率,采用该模式可以一定程度地缓冲数据;
第三,易于扩展,在数据量大时,通过增加数据处理Worker来扩展,提高处理速率。这便是典型的生产消费者模式,数据上报为生产者,数据处理为消费者。
2.事件分发
假设有一个电商系统,用户“收藏”、“下单”、“付款”等行为都是非常重要的事件,通常后端服务在完成相应的功能处理外,还需要在这些事件点上做很多其他处理动作,比如发送短信通知、记录用户积分等等。
我们若将这些动作放到每个模块中,不利于功能解耦和代码维护,此时我们需要一个事件分发系统,在各个功能模块中将对应的事件发布出来,由对其感兴趣的处理者进行处理。
这里涉及两个角色:A对B感兴趣,A是处理者,B是事件,由事件处理器完成二者的绑定,并向消息中心订阅事件。服务模块是后端的业务逻辑服务,在不同的事件点发布事件,事件经过消息中心分发给事件处理器对应的处理者。
整个流程如下图所示,这边是典型的订阅发布模式。

三.RabbitMQ的六种工作模式
1.简单模式:只有一个队列一个消费者
简单模式下我们无需指定交换机,RabbitMQ会通过默认的default AMQP交换机将我们的消息投递到指定的队列,它是一种Direct类型的交换机,队列与它绑定时的binding key其实就是队列的名称
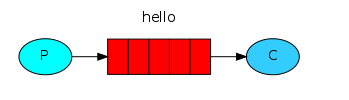
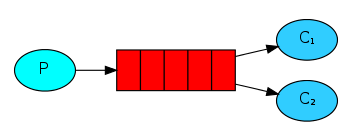
2.WorkQueues:工作队列模式,只有一个队列,有多个消费者
工作队列模式也是采用默认的default AMQP交换机,Queue中的消息会被平均分发给多个消费者处理。有两种消息分发方式:
轮询分发:一个消费者消费一条,按均分配,woek模式下默认是采用轮询分发方式。轮询分发就不写代码演示了,比较简单,比如生产费者发送了6条消息到队列中,如果有3个消费者同时监听着这一个队列,那么这3个消费者每人就会分得2条消息。下面主要介绍公平分发。
公平分发:根据消费者的消费能力进行公平分发,处理得快的分得多,处理的慢的分得少,能者多劳。
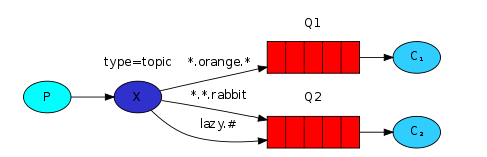
3.Publish/Subscribe:发布订阅模式,有N个队列,N个消费者,需要声明绑定交换机
RabbitMQ中交换机有三种:fanout、direct、topic
(1)fanout:扇出模式,消息广播到所有于交换机绑定的队列当中
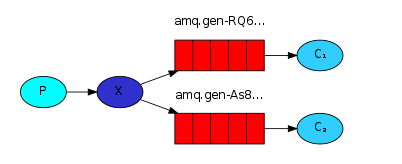
(2)direct:路由模式,消息发布者指定一个key,消息路由到所有匹配key的队列当中
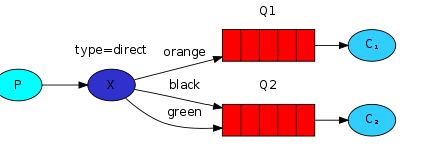
(3)topic:主题模式,与路由模式差不多,可以通过通配符进行模糊匹配
4.RPC模式:支持生产者和消费者不在同一个系统中,即允许远程调用的情况

- RPC模式下通常消费者作为服务端,放置在远程的系统中,提供接口;生产者调用接口,并发送消息。
- RPC模式是一种远程调用的模式,因为需要http请求,因此速度比系统内部调用慢。而且rpc模式下,通常不易区分哪些是来自外部的请求,哪些是内部的请求,导致整体速度较慢。因此,不能滥用rpc模式。
- 在MessageProperties中有两个属性:
reply_to:用于定义回调队列的名字
correlation_id:用于关联rpc的消息请求发送与消息响应接收。
- 要实现RPC模式,生产者需要发送回调队列,工作流程:
1、生产者(Client)开始生产消息后,创建了匿名的、独占的回调队列。
2、生产者(Client)发送请求时,包含两个属性:reply_to,即回调队列;correlation_id,即本次请求的ID
3、请求(request )被发送到rpc_queue队列。
4、消费者(The RPC worker)在rpc_queue上等待请求,收到时,它处理消息并使用replyTo字段中的队列将结果发回客户机
5、生产者在回调队列上等待消息,当消息出现时,校验correlation_id,如果匹配请求中的值则向程序返回该响应数据。