muduo
概述
muduo是基于Reactor模式的网络库,用于响应计时器和IO事件。
muduo采用基于对象而非面向对象的设计风格,其事件回调采用function+bind,用户在使用muduo的时候不需要继承其中的class
架构
Multiple Reactor
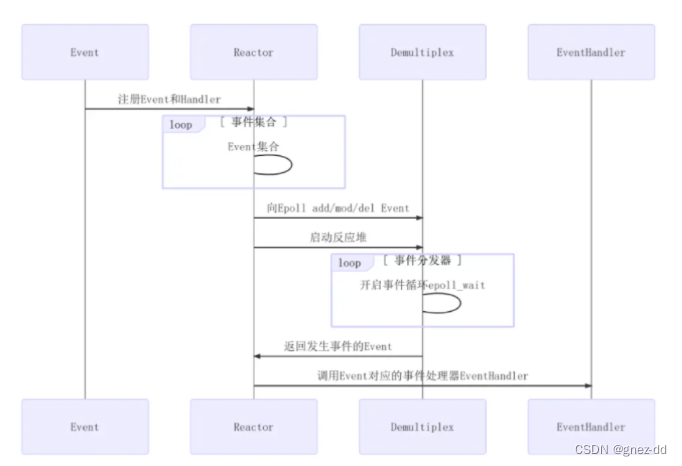
Reactor模式:有一个循环过程(IO多路复用),不断监听对应事件是否触发,事件触发时调用对应的callback进行处理
将事件注册到Reactor上,Reactor会向事件分发器添加对应的事件,事件分发器进行监听,如果事件发生时会告诉Reactor,由Reactor调用相应的事件处理器
每个Reactor都是一个线程,MainReactor是主IO线程,将监听套接字加入进去,只负责accept客户端连接,返回的已连接套接字通过算法添加到subReactor中被监听处理
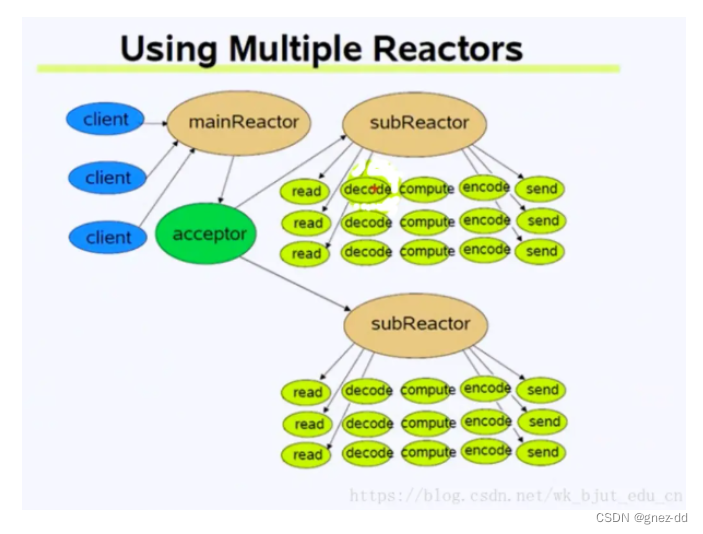
线程模型:one loop per thread + thread pool
将多线程服务端编程问题转换为如何设计一个高效且易于使用的event loop,然后让每个线程run一个event loop就可以了,就可以保证eventLoop所拥有的资源是线程安全的了
比如muduo中每个TcpConnection(客户端连接)都有属于自己的缓冲区,如果TcpConnection可以被其他Loop操作的话会导致缓冲区属于临界资源,在操作时需要保证线程安全;而使用one loop per thread的话,每个线程最多有一个EventLoop,每个TcpConnection归某一个EventLoop管理,所有的IO都会转移到这个线程上,保证了TcpConnection的线程安全
总结
muduo采用Multiple Reactor + ThreadPool的形式:Multiple Reactor由主从Reactor组成,Main Reactor只负责监听新的连接,在accept之后会将新连接分配到Sub Reactor上,由Sub Reactor负责连接的事件处理;线程池中维护了两个队列,任务队列和线程队列,外部线程将任务添加到任务队列中,如果线程队列非空则会唤醒其中一个线程进行任务的处理(相当于生产者与消费者模型)
代码模块
Buffer
为什么non-blocking网络编程中应用层buffer是必须的
TcpConnection必须要有output buffer
- 比如应用程序要发送100kb的数据,但是在write调用中操作系统只发送出去了80KB还剩下20KB的数据需要发送
- 此时如果没有缓冲区的话,需要一直在原地等待操作系统将剩下的20KB发送出去,会造成阻塞
- 但是如果有了缓冲区,应用程序就可以只负责生成数据,不需要关心数据怎么发送出去,这些都可以由网络库来负责。网络库会接管剩下的20KB的数据保存在该TcpConnection的output buffer中并主从POLLOUT事件,当socket变得可写时就可以发送数据,等到数据发送完毕就停止关注POLLOUT
TcpConnection必须要有input buffer
- TCP是一个无边界的字节流协议,接收方必须处理收到的数据尚不构成一条完整的消息和一次收到两条消息的数据等情况
- 对于数据不完整的情况如果没有缓冲区则需要一直阻塞等待接收数据
- 如果有缓冲区则可以先将数据存放在缓冲区中,等有数据可读再次进行读取直到构成一条完整的消息再通知程序
总的来说就是为了避免我们的程序阻塞,而引入了输入输出缓冲区
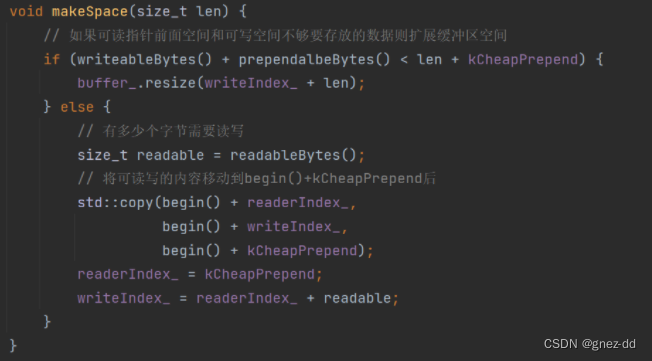
缓冲区大小如何设置
- 内存分配的时候会涉及系统调用,应该准备一个比较大的缓冲区
- 如果缓冲区太大但是每个连接使用到的空间又很小会导致缓冲区使用率低
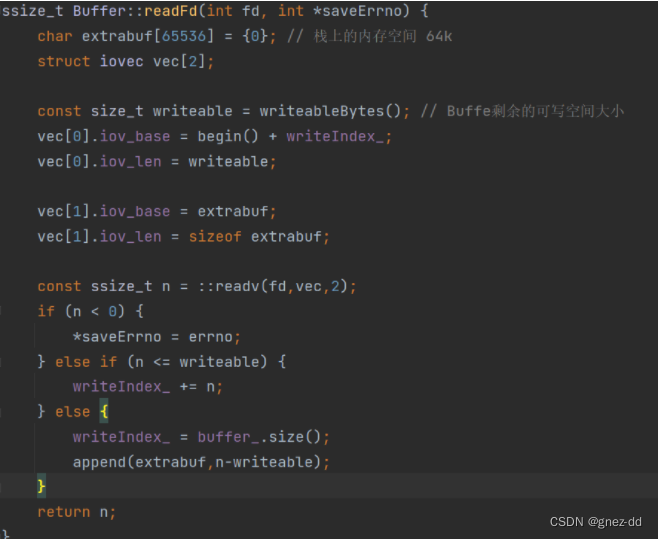
利用临时栈空间避免初始Buffer过大造成内存浪费,同时避免反复调用read的开销
- 在栈上准备一个64K的extrabuf,再利用readv()读取数据存放入iovec中,iovec有两块,第一块指向Buffer中的writeable字节,另一块指向栈上的extrabuf
- 如果读入的数据不多那么全部都读到Buffer中了
- 如果长度超过Buffer的writable字节数就会读到栈上的extrabuf中,然后重新再将extrabuf中的数据append到Buffer中
对于LT模式只需要一次read就可以了,不需要反复调用read直到返回EAGAIN;对于追求低延迟的程序是比较高效的,每次读取数据只需要一次系统调用,同时照顾了多个连接的公平性,不会因为某个连接上的数据量太大影响其他连接处理消息
缓冲区空间不够如何扩展
是否是线程安全的
input buffer的onMessage回调始终发生在该TcpConnection所属的IO线程中,在所属的IO线程完成对buffer的操作,并且不将buffer暴露给其他线程,就可以保证buffer是线程安全的了
output buffer需要暴露给其他线程,比如心跳检测线程会使用send向客户端发送消息需要使用到output buffer,其是通过assertInLoopThread保证buffer是线程安全的
- 如果TcpConnection::send()发送在TcpConnection所属的IO线程会转去调用TcpConnection::sendInLoop(),其会在当前线程操作output buffer
- 如果发生在其他线程则是通过EventLoop::runInLoop将sendInLoop调用哦个转移到TcpConnection所属的IO线程上
也就是说buffer通过只会在其对于TcpConnection所属的线程上操作,不会在其他线程上被操作保证线程安全
EventLoop
如何保证one loop per thread
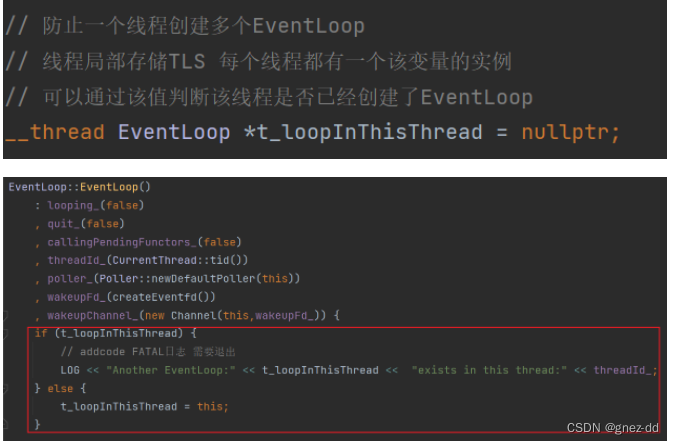
线程局部存储让每个线程都拥有一个变量的实例,可以用于存储EventLoop
EventLoop的构造函数会检查当前线程是否已经创建了其他EventLoop对象,如果没有创建就将当前loop给予线程,否则遇到错误终止程序
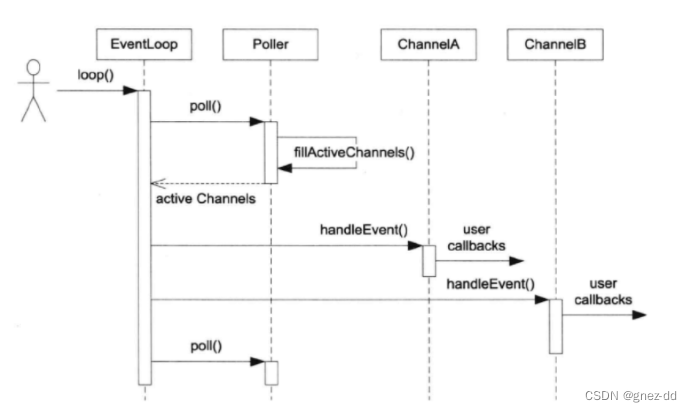
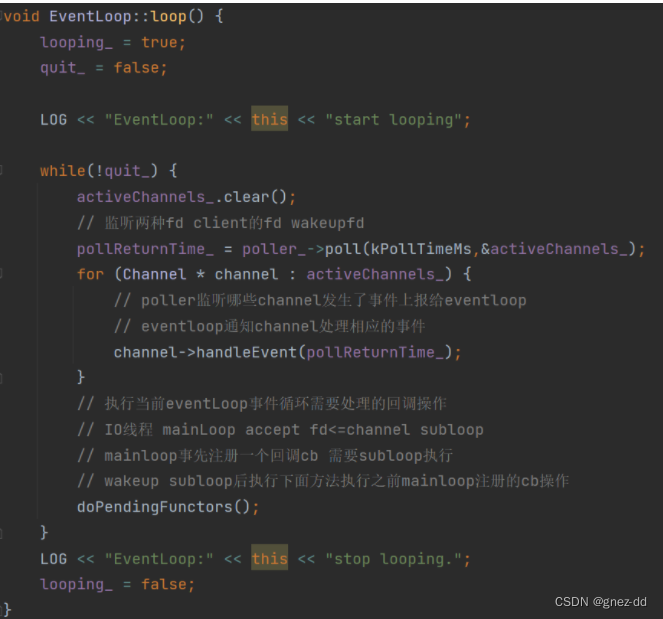
EventLoop::loop
调用Poller::poll通过activeChannels获得当前活动事件的channel列表,再依次调用每个channel的handleEvent去执行相应的回调
EventLoop::runInLoop
EventLoop的成员函数存在一些允许跨线程调用,比如在某个IO线程中执行一个连接超时回调会带来线程安全问题,muduo不使用加锁,而是将超时回调的操作转移到该连接属于的EventLoop中执行
如果用户在当前IO线程调用则回调同步进行,否则cb会被加入队列中,IO线程会被唤醒调用这个cb

EventLoop::queueInLoop
pendingFunctors是可以被多个线程操作所以需要加锁
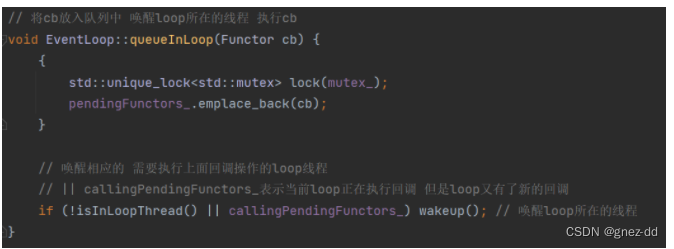
IO线程平时阻塞在事件循环EventLoop::loop的poll调用中,为了能够让IO线程立即执行回调需要唤醒这个IO线程
如何唤醒IO线程
- 使用pipe,让IO线程始终监视该管道的可读事件,在需要唤醒时,其他线程往管道中写入一个字节,IO线程就会从IO多路复用阻塞调用中返回
- eventfd类似于管道,但是比管道更加高效
- 比pipe少用一个文件描述符,节省了资源
- 缓冲区管理比较简单,只有8字节,而pipe可能有不定长的真正buffer
- eventfd的缓冲区是一个64位的计数器,写入递增计数器,读取将得到计数器的值并且清零
在初始化EventLoop时创建一个wakefd并初始化其对应的wakeupChannel用于处理wakeupFd上的可读事件,将事件分发到其handleRead函数
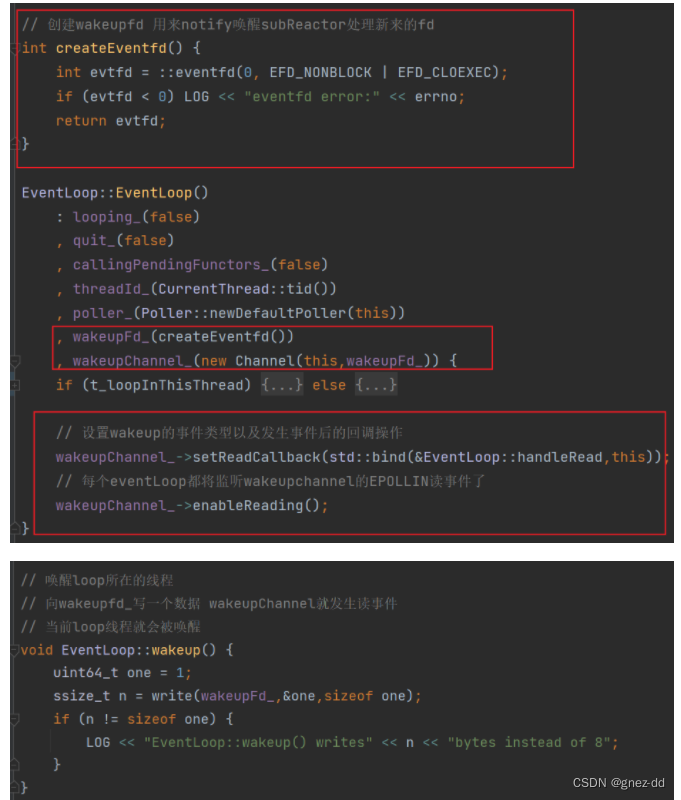
EventLoop::doPendingFunctors
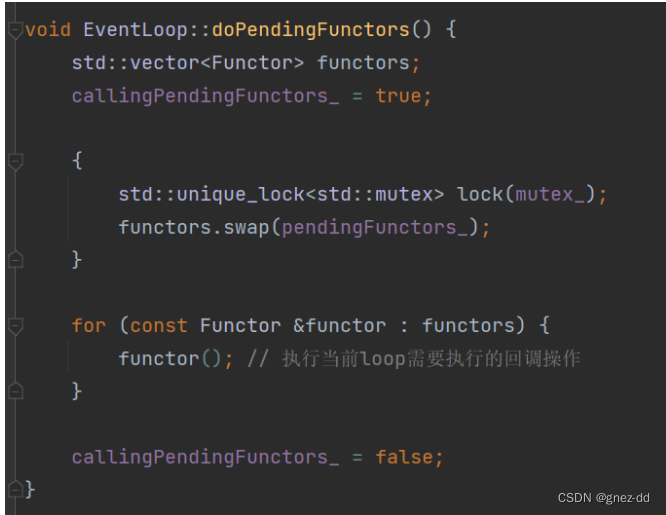
将回调列表swap到局部变量functors中
- 减少临界区长度,不会阻塞到其他线程调用queueInLoop
- 避免死锁:Functor可能再次调用queueInLoop
什么时候需要唤醒
- 调用queueInLoop的线程不是IO线程
- 在IO线程中调用queueInLoop但此时正在调用pendingFunctor
- doPendingFunctor调用的functor可能再次调用queueInLoop,由于doPendingFunctor中调用的functors是局部变量,重新添加的在局部变量中不可见没办法执行所以需要wakeup
也就是说只有在IO线程事件回调中调用queueInLoop才不需要唤醒
EventLoop::quit
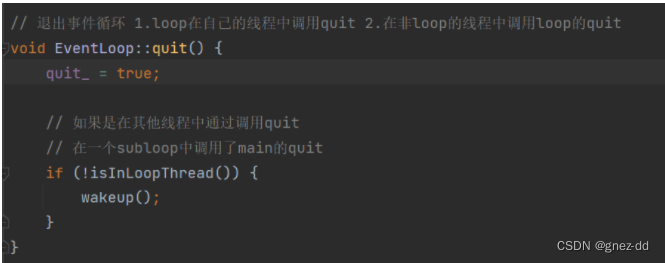
如果是IO线程自己调用quit则说明此时没有卡在poll中,只需要quit_=true,下一次再while判断时就会跳出循环;如果是其他线程调用IO线程的quit则此时IO线程可能卡在poll中,需要唤醒
Channel
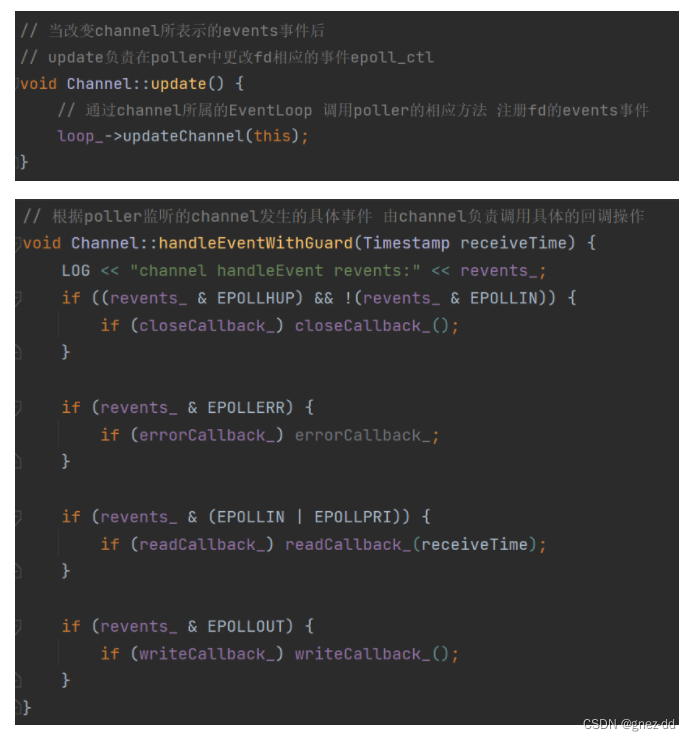
每个channel对象只属于一个EventLoop,封装了一个文件描述符以及其感兴趣的事件,通过loop交给poller监听,poller告诉loop返回的事件,由loop调用channel相应的事件回调
用户一般不会直接使用channel而是使用更上层的封装如TcpConnection,生命期由其上层管理
Poller
IO多路的封装,是一个抽象基类,支持poll和epoll
Poller是EventLoop的间接成员,只供其owner EventLoop在IO线程中调用,无须加锁,生命期与EventLoop相等
EpollPoller
EpollPoller::poll
监听EventLoop传递过来的channel并将发生的事件填入EventLoop传递过来的activeChannels,交给EventLoop去完成事件分发
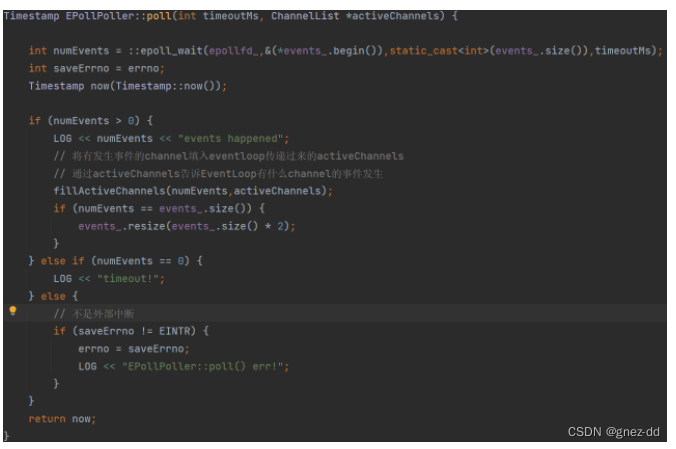
EpollPoller::fillActiveChannels
为什么不能一边调用Channel::handlerEvent一边遍历events
简化Poller的职责,让其只负责IO多路复用,不负责事件分发,将来可以方便替换其他IO多路复用机制
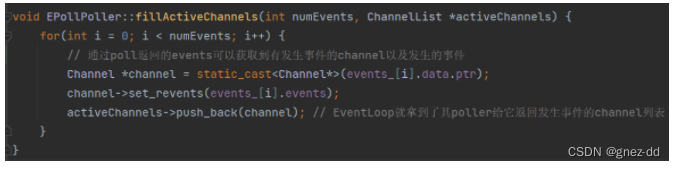
EpollPoller::updateChannel
修改channel的状态并交给EpollPoller::update去修改其中poller中监听的事件
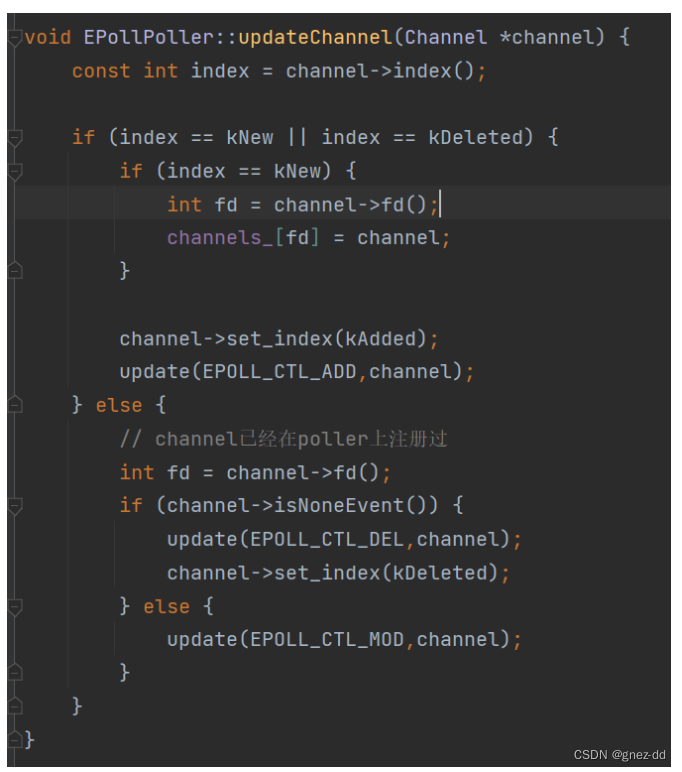
EpollPoller::update
EventLoopThread
EventLoopThread会启动自己的线程并在其中运行EventLoop::loop
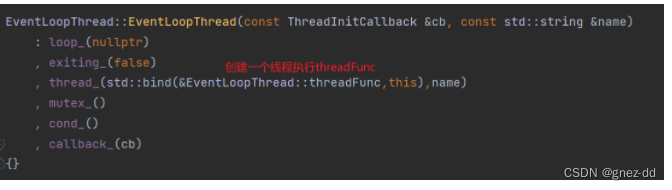
创建一个EventLoop并通知startLoop说loop创建完毕,之后运行loop
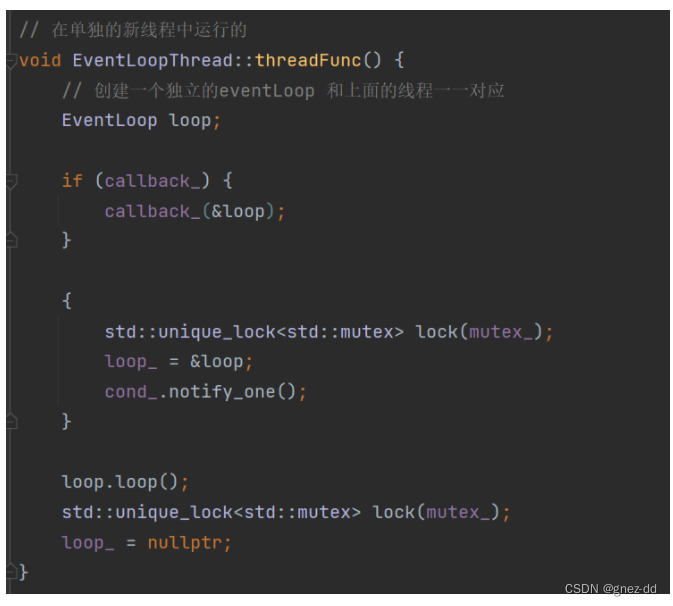
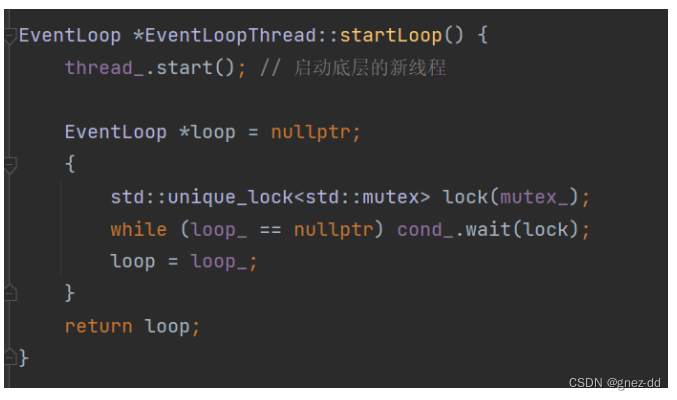
线程开始运行时需要先保证loop创建完毕,所以使用条件变量实现同步
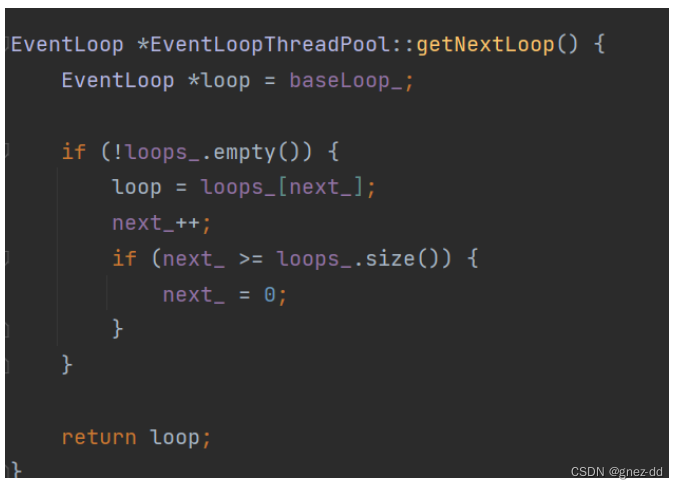
EventLoopThreadPool
开启线程池创建多个线程

通过轮询算法获得EventLoop
Acceptor
用于接收新连接并通过回调通知使用者,供TcpServer使用,生命期由其管理
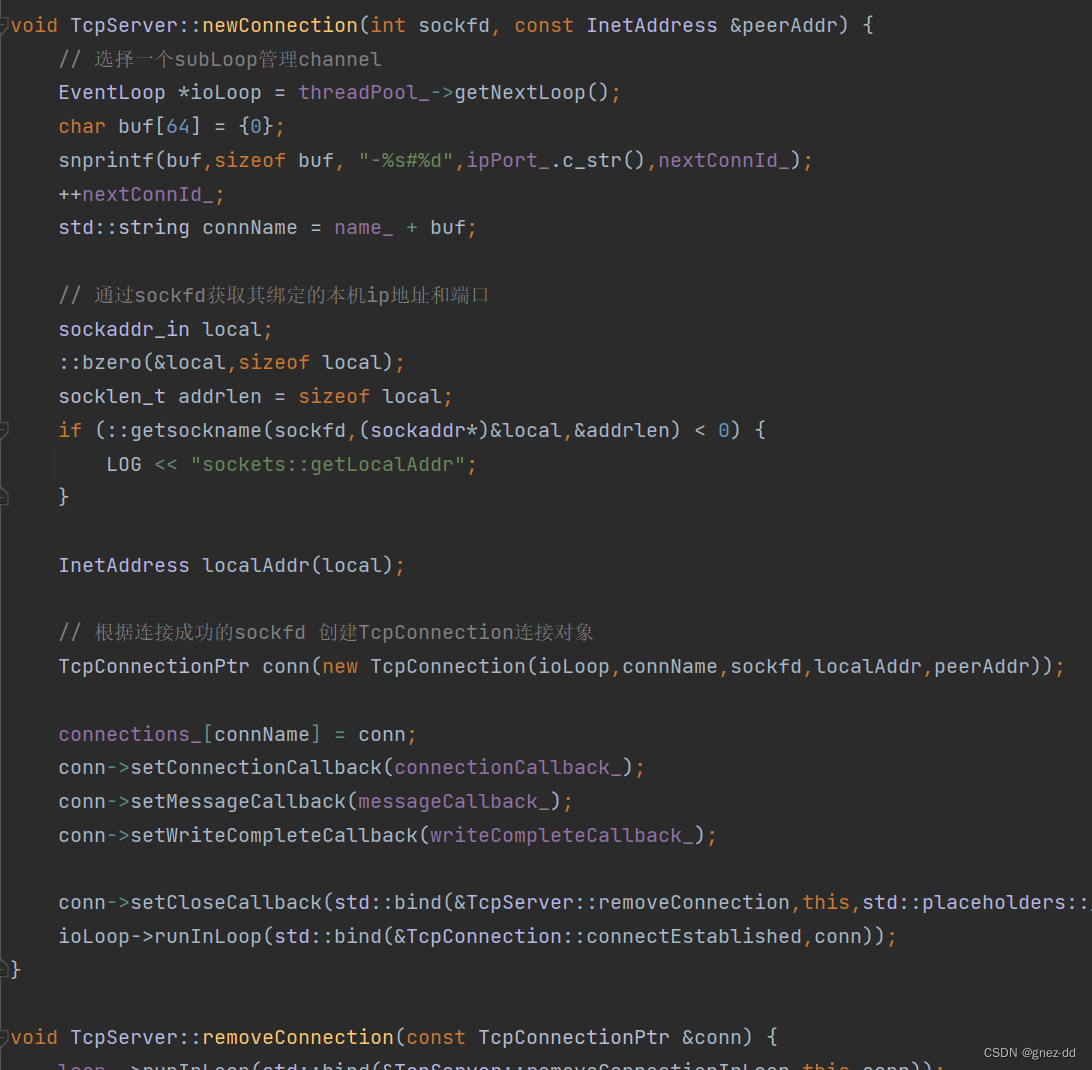
TcpServer会创建Acceptor并给予其要监听的端口以及新连接到来的处理方法newConnection,Acceptor在初始化时会创建listenFd并将其与监听端口进行绑定,同时将listenFd封装成channel,并为channel绑定可读事件的回调函数handleRead,handleRead会接收新连接并执行newConnection
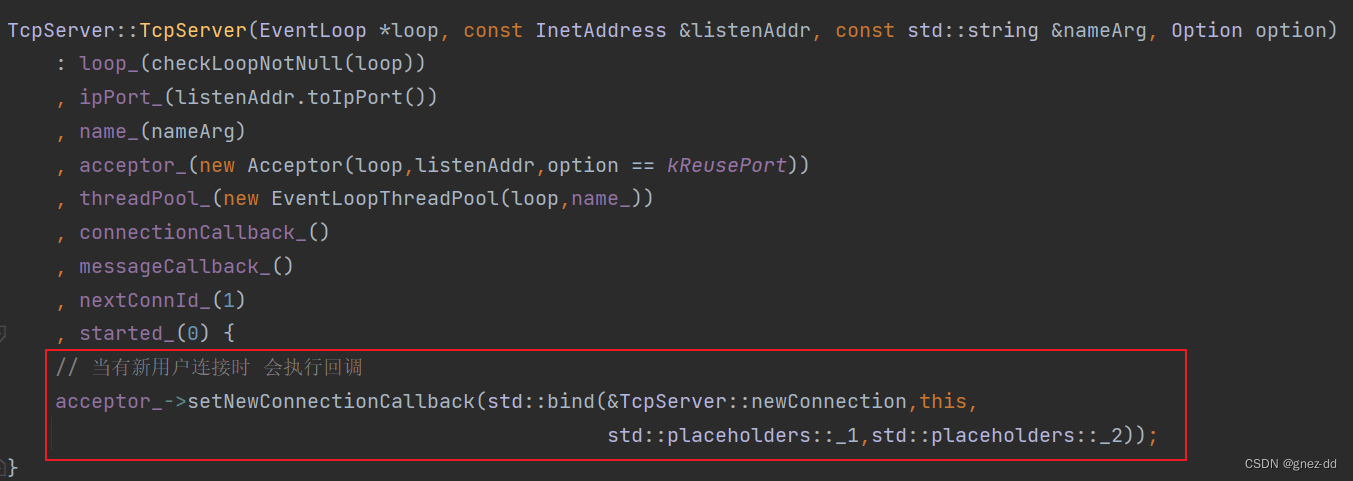
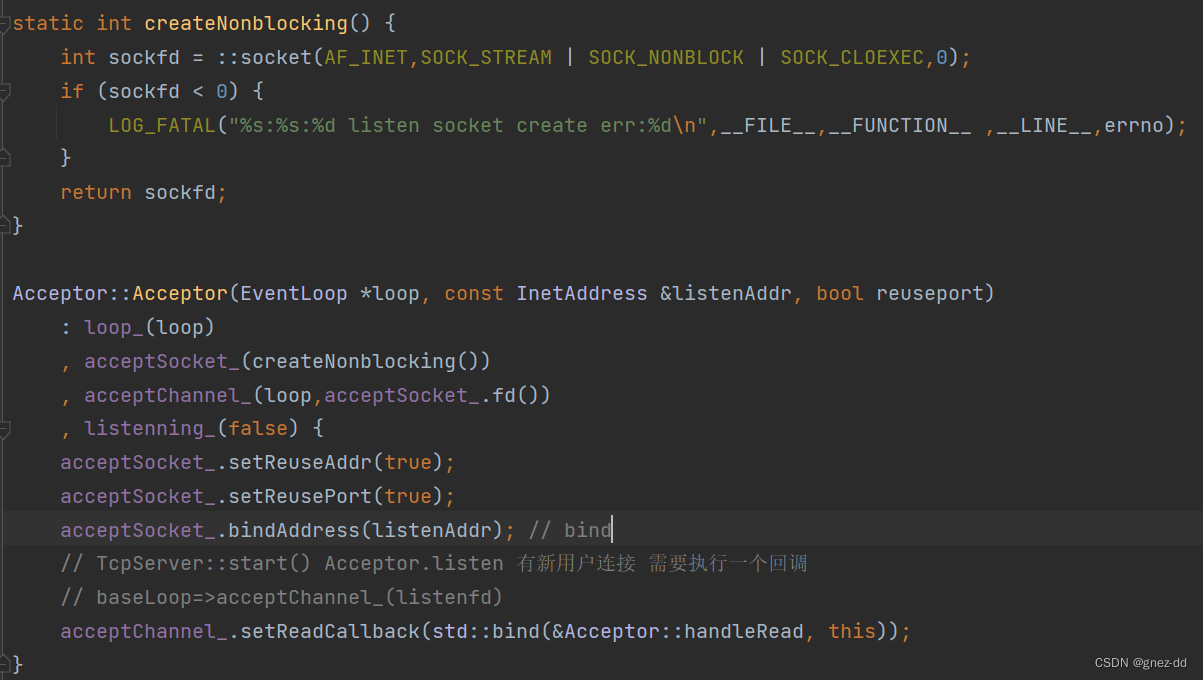
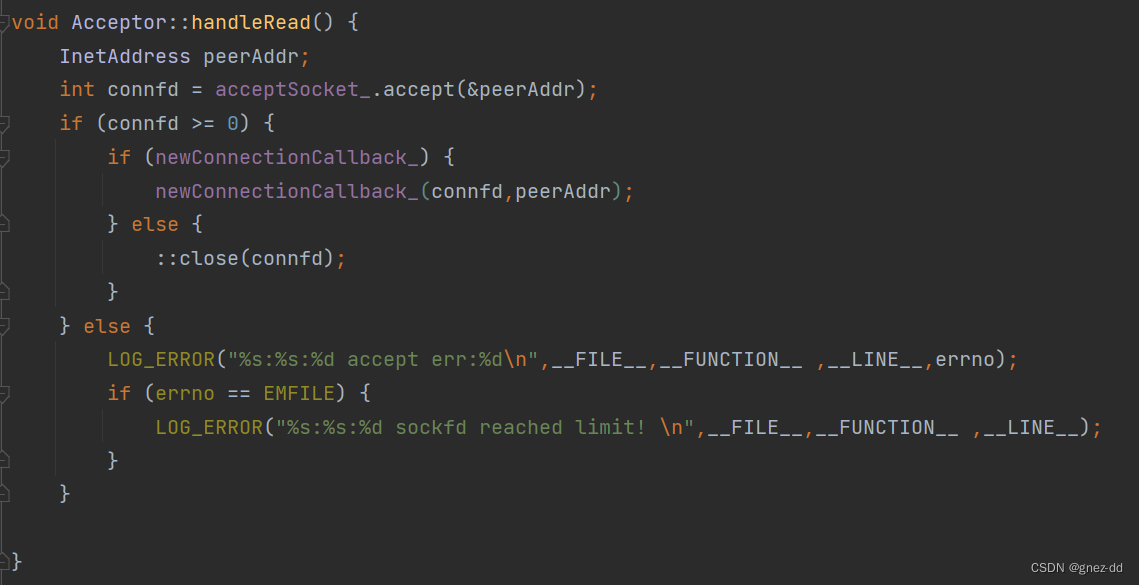
直接将connfd传递给cb时不够理想的,如果cb出现异常会导致connfd没办法关闭
- 可以先将connfd封装为socket对象,再通过移动语义将socket对象move会回调函数,确保资源安全释放。因为socket对象在析构时会close文件描述符
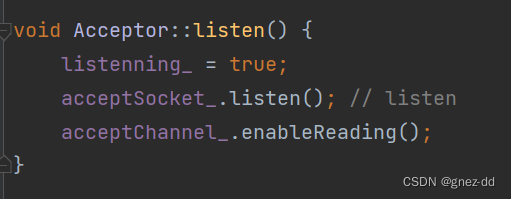
listen
开始监听则将acceptFd交给Poller监听
TcpServer
管理accep获得的TcpConnection,负责其连接建立、端口、数据的发送以及读取
供用户使用,生命期由用户控制
接受新连接
Poller监听到accept Socket有事件可读就会通知EventLoop,EventLoop会调用acceptChannel的handleEvent回调方法,通过判断出是可读事件会调用channel对应的handleRead,在acceptChannel中handleRead接收新连接并执行TcpServer传递给acceptorChannel的回调函数newConnection
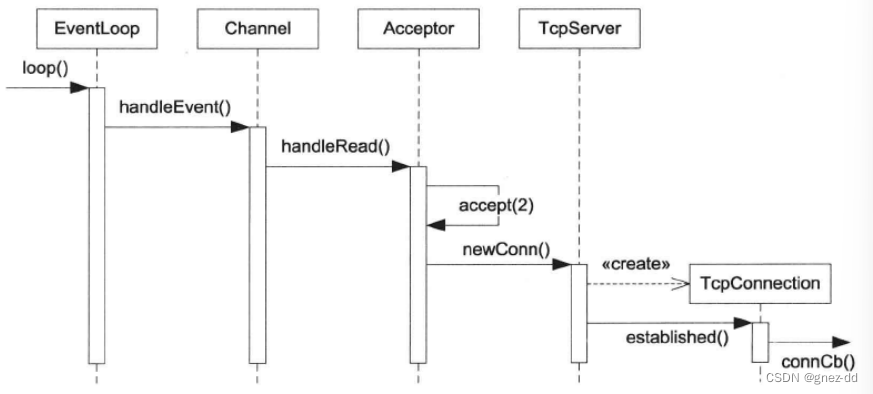
将新连接封装为TcpConnection并设置相应的回调函数(实质上在初始化TcpConnection时会创建channel,并设置TcpConnection给予回调函数),并通过connectEsablished将TcpConnection对应的fd交给Poller监听以及执行用户提供的新连接到来的回调函数

断开连接
Poller监听到要关闭连接的fd有事件可读就会通知EventLoop,EventLoop会调用其channel的handleEvent回调方法,handleEvent会调用channel对应的handleRead,在handleRead中发现是要关闭连接,所以就会调用channel中设置的handleClose去执行关闭连接
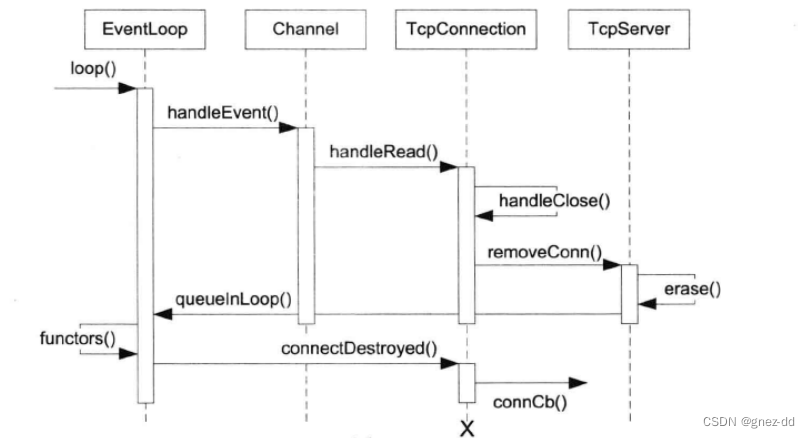
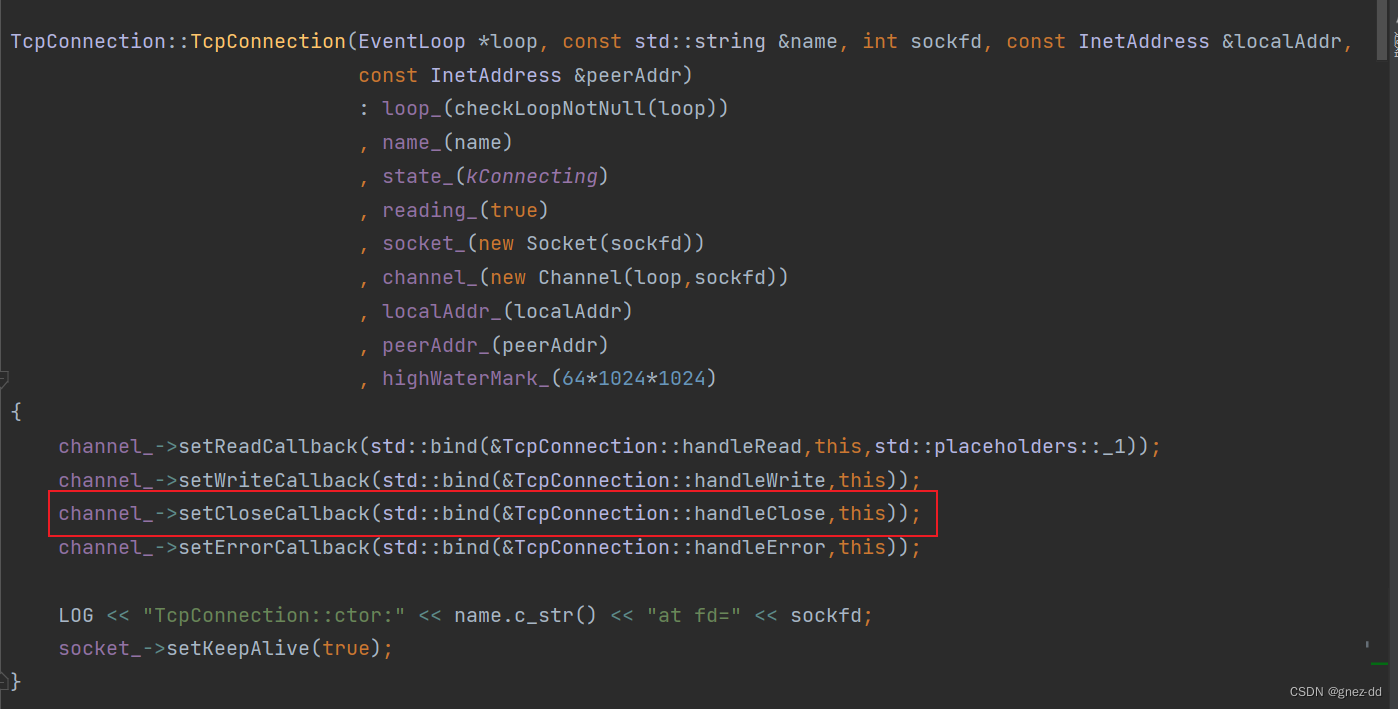
handleClose是由TcpConnection传递给Channel的
将channel所拥有的fd在poller中取消事件监听,同时执行两个回调
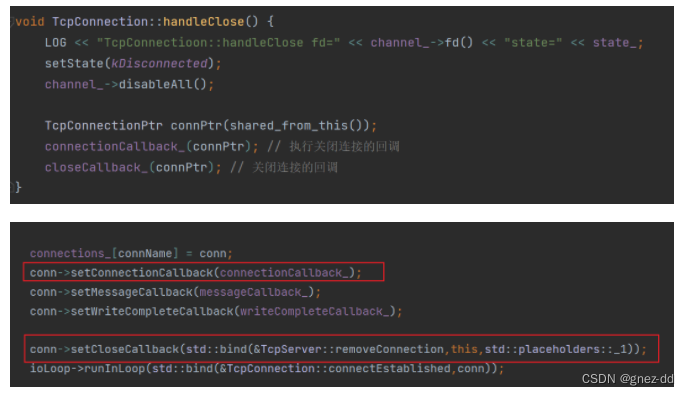
connectionCallback_
用户提供的回调,处理用户在连接断开时需要执行的事情(比如告诉用户说连接已经成功断开)
closeCallback_
由TcpServer提供,绑定到TcpServer::removeConnection中
通知TcpServer将TcpConnection从其保存的连接数组中移除,再将channel从EventLoop中取消注册
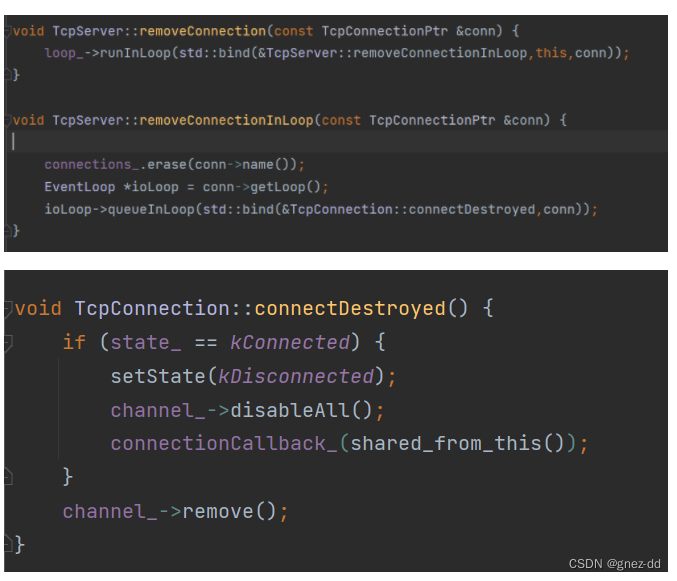
为什么再connectDestroyed中remove而不是在handleClose中移除
因为连接断开不一定是由客户端主动断开调用handleClose的,所以handleClose可能调用不到
TcpConnection从connections_中移除后引用计数减1,如果用户不持有TcpConnection的shared_ptr指针那么在调用TcpConnection::connectionDestroyed不会是访问已经析构的对象吗
TcpConnection内部在注册回调函数时使用bind绑定其shared_ptr调用shared_from_this()获取以此增加引用计数,延长生命周期
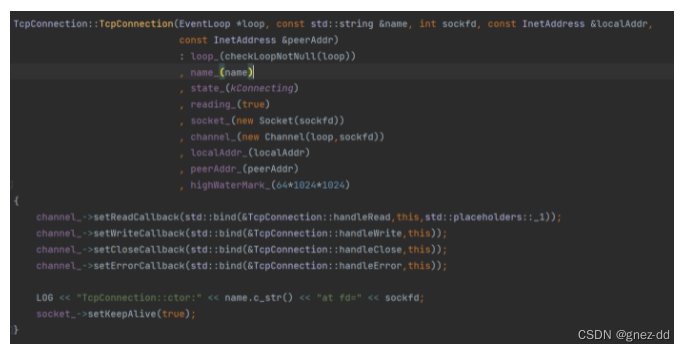
读取数据
TcpConnection在初始化时会为其拥有的channel设置有可读事件来临时应该执行的事件回调
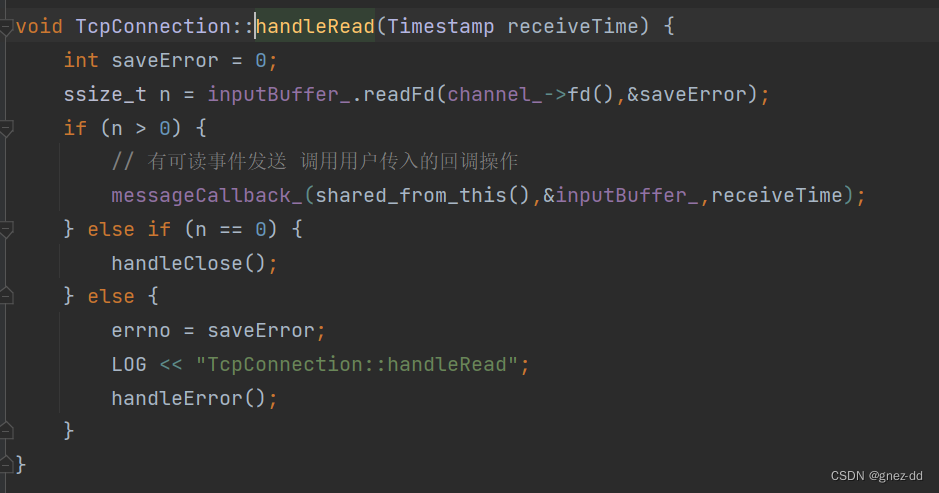
通过input buffer读取数据
- 如果读到数据则调用用户的消息有数据到来的回调函数,并将数据传递给回调函数
- 如果读取到0个字节说明用户是要断开连接,此时执行连接断开的回调函数
- 如果读取<0则说明发生错误需要进行错误处理
发送数据
TcpConnection将send接口暴露给其他线程,比如TcpServer就可以调用send向用户发送数据,所以需要保证send的操作是在其所属的IO线程中执行
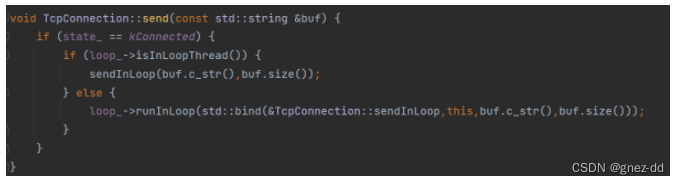
sendInLoop
会先尝试直接发送数据,如果一次发送完毕就不会启动writeCallback
如果只发送了部分数据,就会将剩下的数据放入outputbuffer中并开始关注writable事件,以后在handleWrite中发送剩余数据
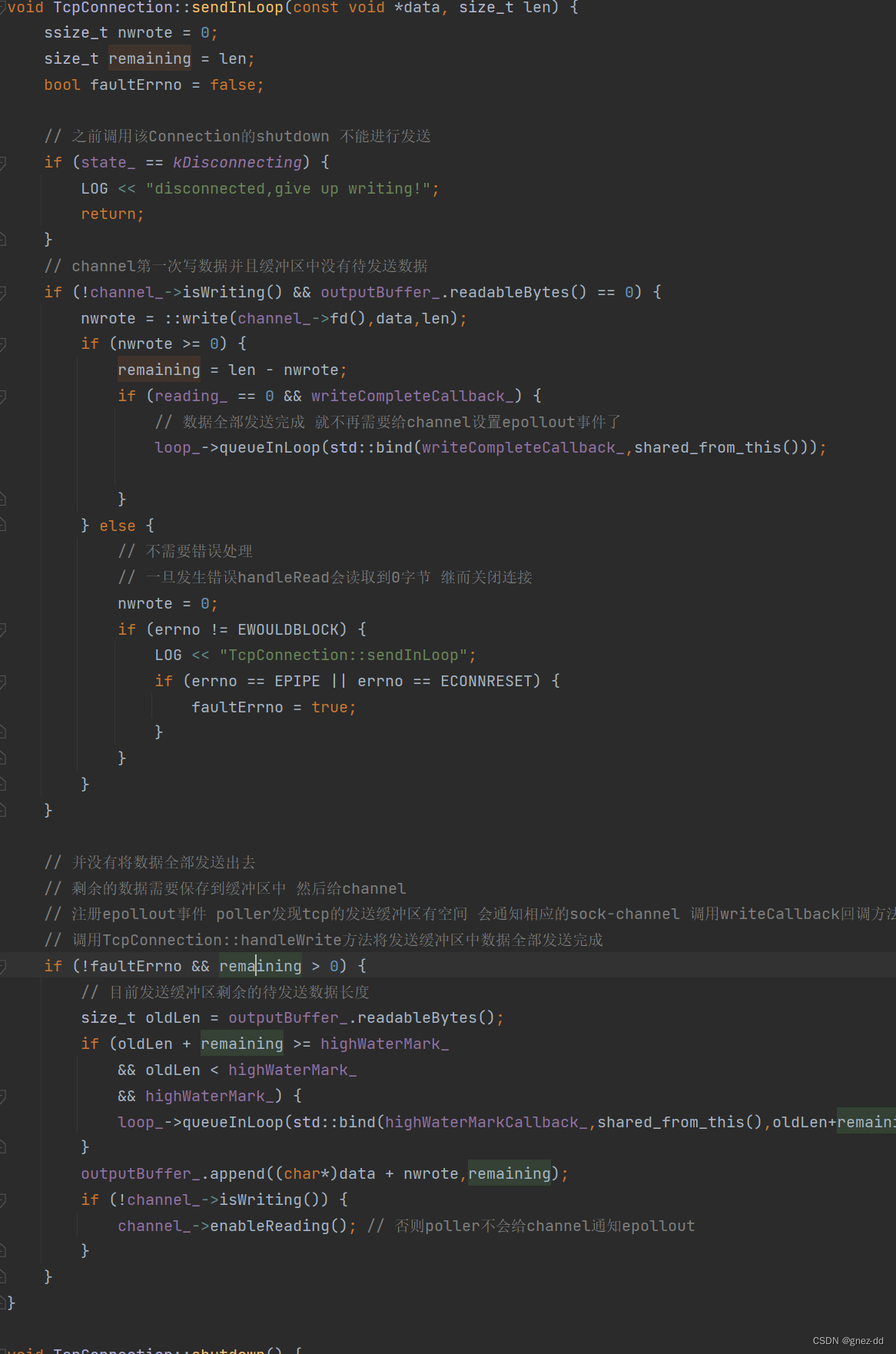
handlewrite
当socket变得可写时,Channel会调用TcpConnection::handleWrite继续发送outputBuffer中的数据
一旦发送完毕就会停止观察writeable事件,避免busy loop
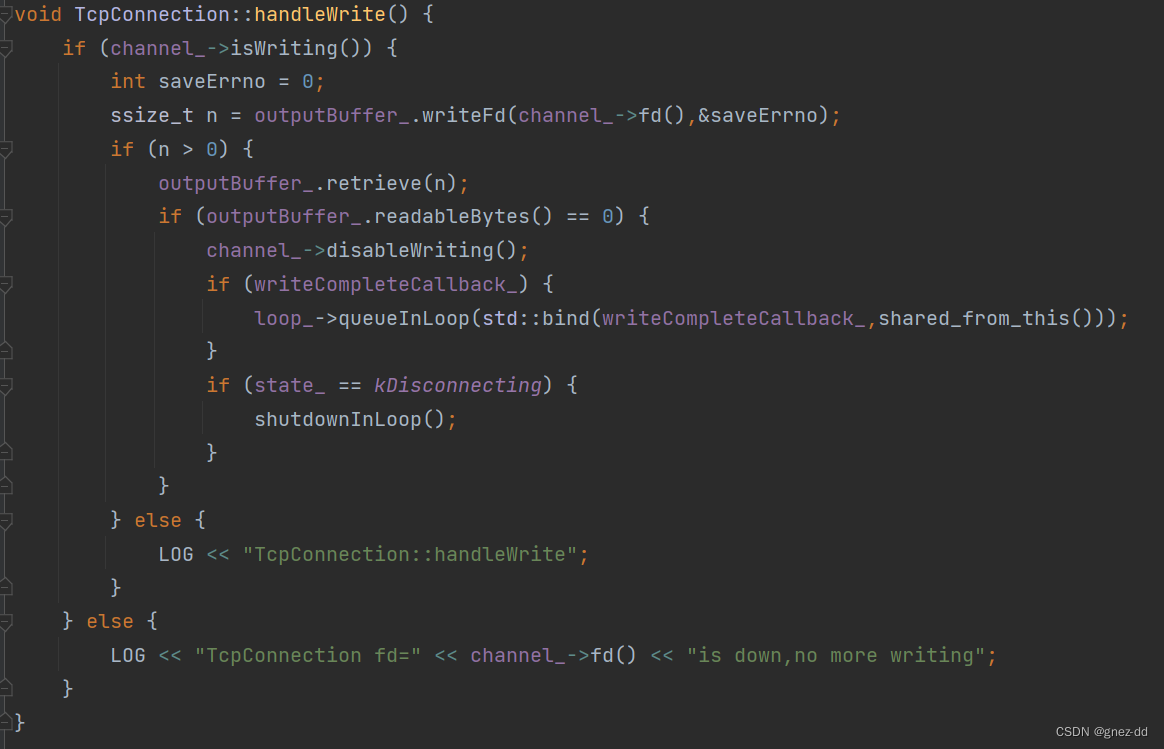
什么时候关注writable事件?如果发送数据速度高于对方接收数据速度导致数据在本地内存堆积怎么办?
muduo提供两个回调:高水位回调和低水位回调
低水位回调WriteCompleteCallback:当发送缓冲区被清空就调用
高水位回调HighWaterMarkCallback:如果输出缓冲区长度超过用户指定大小就触发回调
TcpConnection
使用shared_ptr管理,继承enable_shared_from_this,因为TcpConnection的生命期是模糊的,用户也可以持有TcpConnection
亮点
限制服务器的最大并发连接数
并发连接数:一个服务端程序能够同时支持的客户端连接数
为什么要限制并发连接数
- 不希望服务程序超载:连接越多说明要处理的事情越多,占用的资源越多
- 会导致文件描述符耗尽,程序没有可用文件描述符表示新连接进而导致程序一直在accept重复调用中失败
- 在Linux中任何事物都是用文件描述符表示的,每个进程可以使用的文件描述符是由限制的,如果超过限制会就没办法获取新的文件描述符来表示对于的文件
- 当accept返回EMFILE时就意味进程的文件描述符已经达到上限,没办法为新连接创建socket文件描述符,也就意味着没有socket文件描述符表示这个连接,我们就没办法close这个连接,程序继续运行回到再次调用epoll_wait时会立刻返回因为还有新连接在等待处理,如果一直没有可以使用的文件描述符会导致程序进入该循环
如何避免文件描述符耗尽
-
调高进程的文件描述符数量
- 治标不治本,只要有足够多的客户端,文件描述符总有耗尽的一天
-
准备一个空闲的文件描述符,遇到文件描述符耗尽时就先关闭这个空闲的文件描述符获得一个文件描述符名额给新连接,再acceptor拿到新socket连接的描述符,随后立刻close该连接,就可以优雅断开与客户端连接,最后重新打开一个空闲文件将坑占住,以备再次遇到这种情况时使用
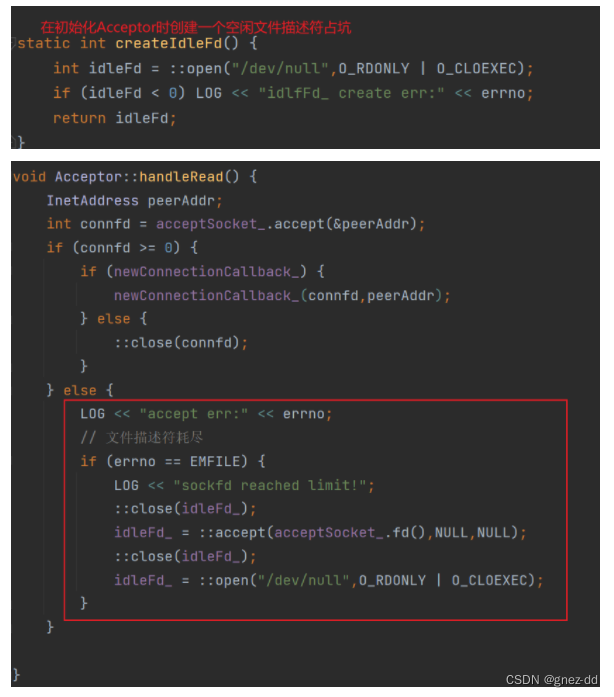
-
自己设定一个稍低一点的文件描述符数目,如果超过就主动关闭新连接
- 在Server中增加一个atomic_int成员表示当前的活动连接数,在onConnection中判断当前活动连接数,如果超过则踢掉连接

-
及时处理空闲连接
日志库
异步日志
同步日志需要等日志消息写入磁盘后才可以执行后续操作,会导致程序阻塞在磁盘写入上
异步日志将日志消息存储在内存中,等积累到一定量或达到一定时间间隔时由后台线程自动将存储的所有日志输出到磁盘上
使用双缓冲技术:准备两块buffer:A和B,前端负责往bufferA填数据,后端负责将bufferB的数据写入文件;当buffer A写满后,交换A和B,让后端将buffer A的数据写入文件,前端往buffer B填入新的日志消息,如此循环
- 前端线程不会阻塞在写日志上
- 等后台线程真正写日志时,日志消息已经积累比较多了,此时只需要调用一次IO函数就可以了,不需要每次都调用(批处理)
日志存储
日志的输出形式为流形式,muduo没有使用C++自带的iostream库,而是自己实现LogStream,抛去其他不需要的冗杂功能,使代码效率更高
缓冲区FixedBuffer
日志流的实现需要一个内置缓冲区存放输入的数据
是一个模板类,模板参数用于指定缓冲区data_的大小,并提供一系列缓冲区操作函数

日志流LogStream
包含FixedBuffer,负责将用户要记录的日志内存存放在日志流的缓冲区中,因为包含多种数据类型,所以先将数据转换为字符串类型再存放入缓冲区中
LogStream通过重载<<实现日志流的形式,无论是哪一种重载版本,最终都是append,append又会去调用FixedBuffer中的append
日志输出
Impl
作为日志输出的类应该包含LogStream的实例用于存储日志消息
Impl包含了一条记录的内容:时间、文件名、行数、日志内容
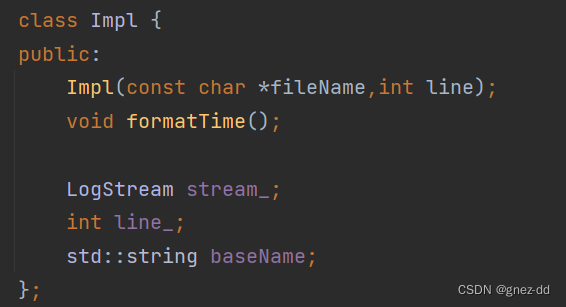
日志输出类Logger
存在Impl的实例保存一条日志消息,Loggeer在构造的时候会构造Impl,也就是会初始化impl的文件名和行号,Impl在构造时还会将时间存储在缓冲区中
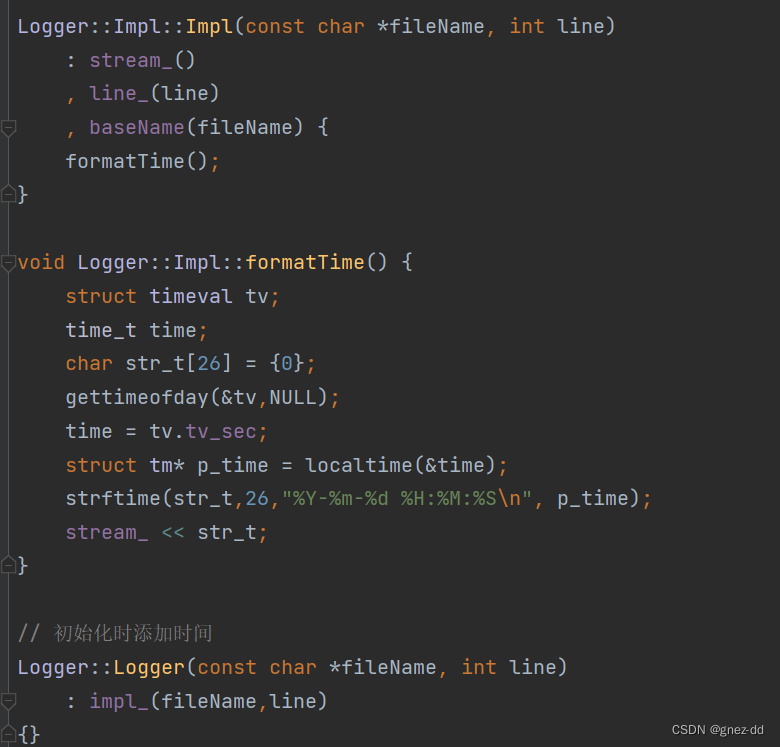
Logger在析构时会将Impl的文件名和行号添加到缓冲区中,再调用output将日志内容刷新到日志文件中

如何保证一条日志只输出一次
在多线程中有些事情只需要执行一次,通常初始化应用程序时可以将其放在main中,但是写一个库时就不行了
可以用静态初始化,使用一次初始化pthread_once就可以了:多线程中尽管pthread_once会调用出现在多个线程中,但once_init只会被执行一次
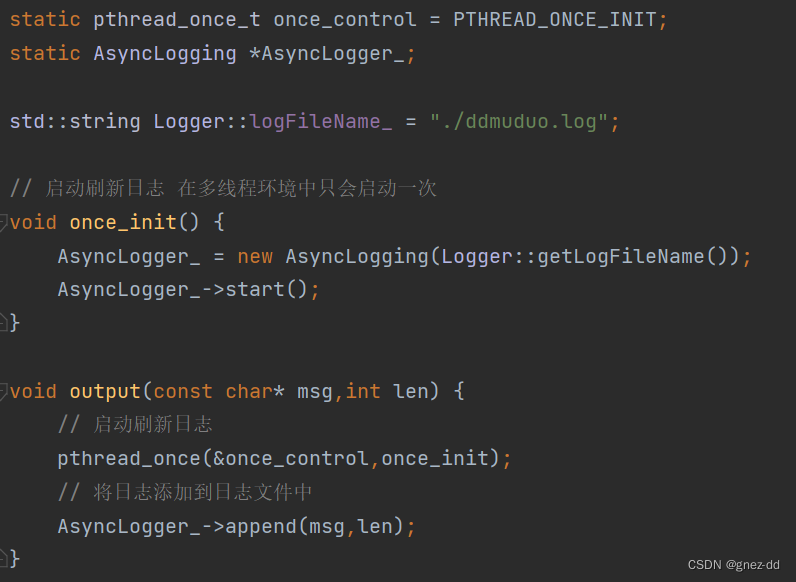
宏定义记录日志

使用时的格式:LOG << "hello dd" <<;
会构造一个临时的Logger对象,并传入文件名和行数,再通过stream获取Logger中的日志流,再通过重载<<将日志内容记录到缓冲区中,当这条语句执行结束就会将Logger析构,析构时就可以实现将日志内容写入到日志文件中
每一条日志消息都会对应一个Logger的临时对象,可以及时将日志消息进行输出,占用的内存也可以立即释放
后端与日志文件
AppendFile
包含一个文件指针指向外部文件,与磁盘文件进行交互
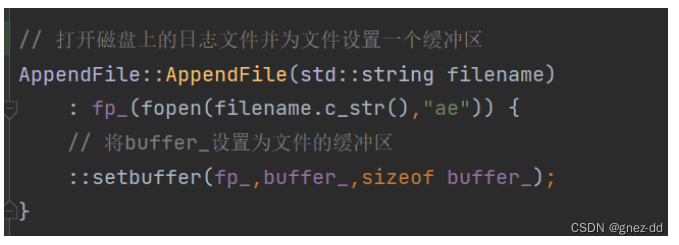
开放给外部的接口,写入日志文件的缓冲区中,并不是真正写入磁盘上的日志文件
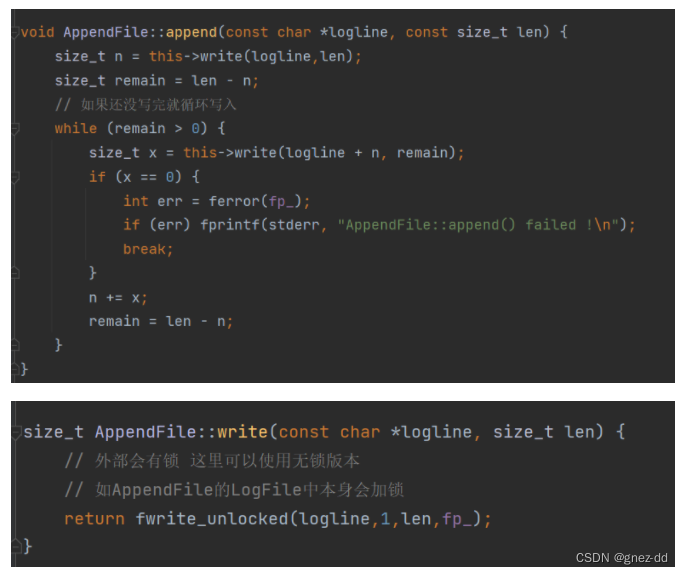
将日志文件缓冲区中的内容正在写入到磁盘上的日志文件
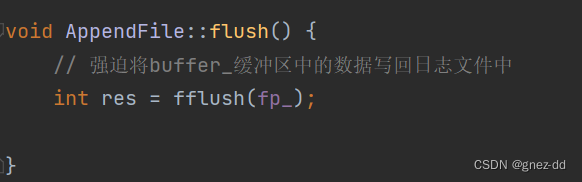
LogFile
通过unique_ptr包装一个AppendFile类实例file_,在后端线程写出时调用LogFile类的append,append就会通过该实例调用AppendFile的append将后端缓冲区中的内容写入到日志文件的缓冲区中
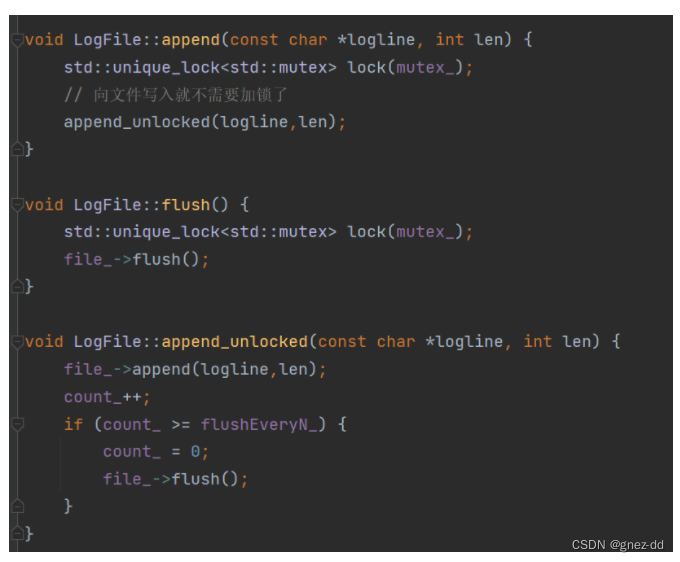
自动flush缓冲区
通过与日志文件交互的文件流是全缓冲的,只有当文件缓冲区满或者flush时才会将缓冲区中的内容写到文件中
如果不调用flush,那么就只有缓冲区满了才会将数据写出到文件中,如果进程突然崩溃,缓冲区中还未写出的数据就丢失了,而如果调用flush的次数过多,无疑又会影响效率
muduo通过两种方式决定什么时候flush
- append的次数到达flushEvenyN时会调用flush
- 每过3秒就flush
滚动日志LogFile::rollFile
- 文件的大小会有限制
- 根据时间查找不同时刻的文件
rollFile发生在两种情况
- 写出到日志文件的字节数达到滚动阈值
- 到达新的一天
并不是到了新的一天的第一条日志消息就会导致rollFile,而是每调用1024次append函数时会去检查是否到了新的一天
- 可能存在到了新的一天但是没有达到1024次调用的情况,不过如果连1024次都没有达到,说明日志消息很少,也没有什么必要创建一个新的日志文件
- 如果每次调用append都去判断是否是新的一天,那么每次都需要通过gmtime、gettimeofday这类的函数去获取时间,这样一来可能就显得得不偿失了
前端与后端的交互
muduo通过AsyncLogging实现异步日志
异步日志分为前端和后端,前端负责存储生成的日志消息,后端负责将日志消息写出到磁盘上
前端
当前缓冲区与预备缓冲区时前端用于暂时存储生成的日志消息,当前缓冲区不够用时会使用预备缓冲区来填充当前缓冲区
buffers是用于存储准备写到后端的缓冲区,当前缓冲区写满后就会将其存放到buffers中
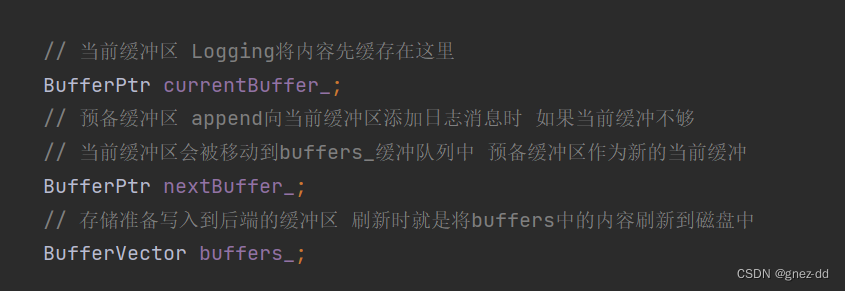
前端只需要调用append函数即可,如果currentBuffer足以放下当前日志消息就调用缓冲区的append函数放入消息,如果放不下,就会将currentBuffer放入buffer中,此时如果预备缓冲区nextBuffer尚未使用,那么就会将nextBuffer的拥有权转移给currentBuffer,转移后nextBuffer为NULL,意为已被使用;而如果预备缓冲区本身就为NULL,则为currentBuffer重新分配新的空间。当前端向buffers中移入缓冲区后,就会唤醒条件变量
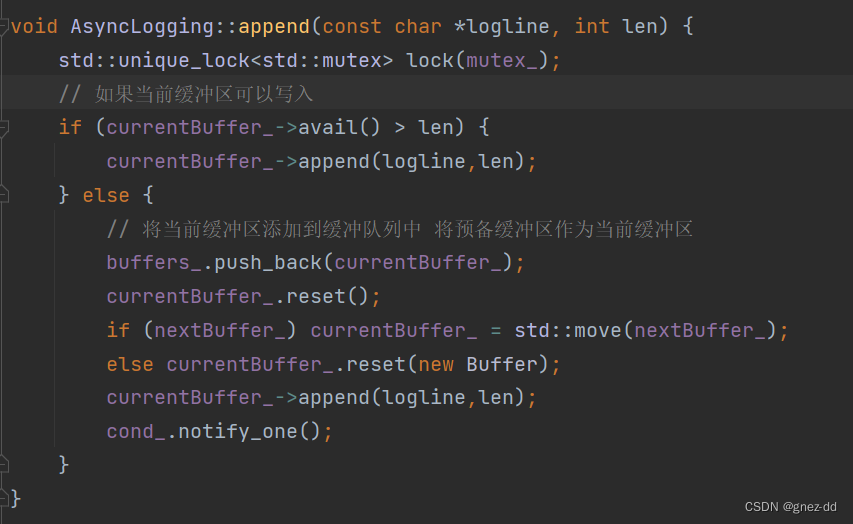
后端
负责与buffers交互,将buffers中的缓冲区的内容全部写出到磁盘上,通过开启一个线程来执行(后端线程)
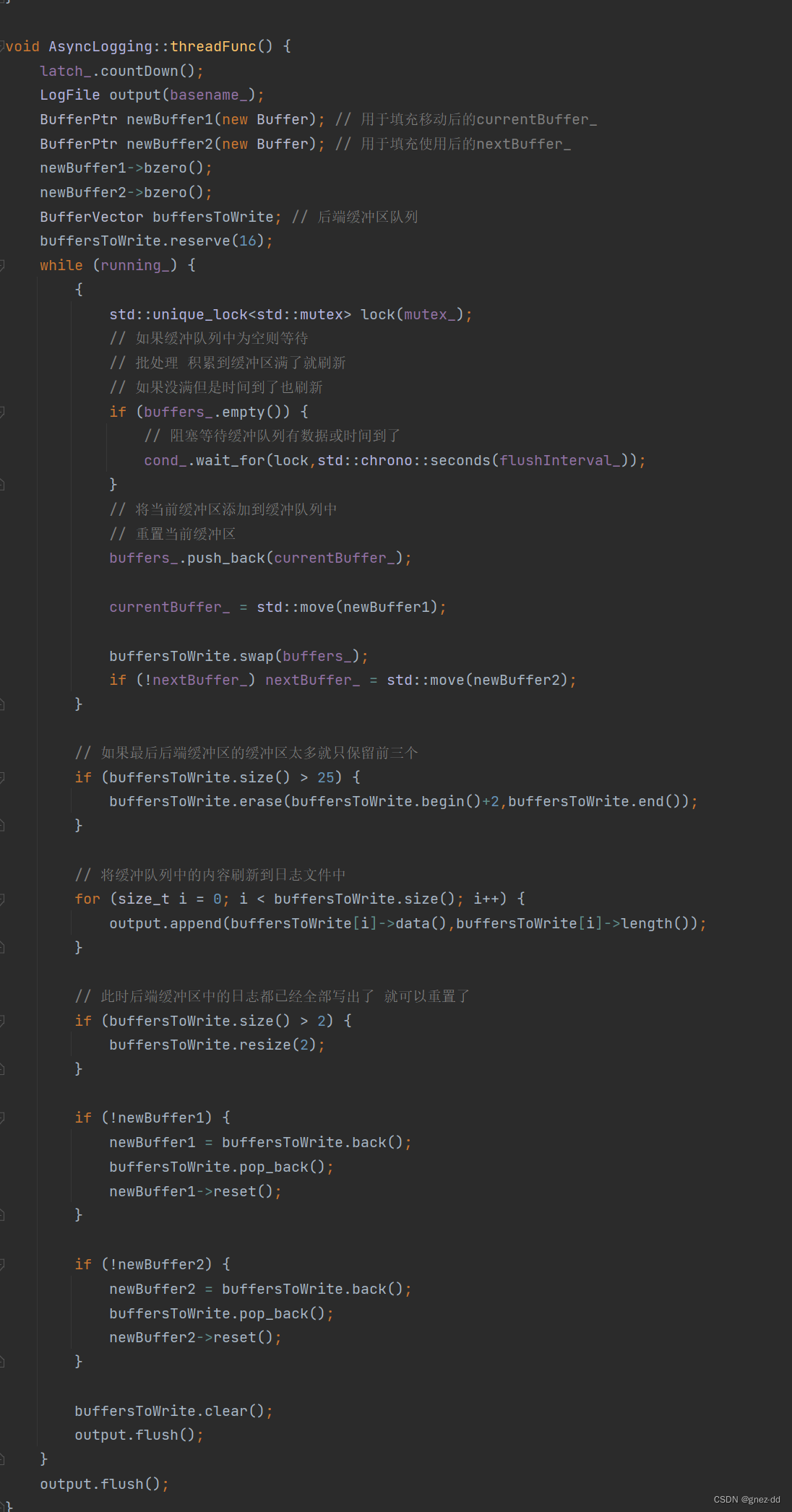
后端线程会循环去检查buffers_,如果buffers为空,那么后端线程就会休眠最多为flushInterval指定的秒数(默认为3秒),如果在此期间buffers中有了数据,后端线程就会被唤醒,否则就一直休眠直到超时,不管是哪种唤醒,都会将currentBuffer移入buffers中,这是因为后端线程每次操作都是准备将所有日志消息进行输出,而currentBuffer中大多数情况下都存有日志消息,因此即使其未满也会被放入buffers中,然后用newBuffer1来补充currentBuffer
buffersToWrite就是后端缓冲区队列,负责将前端buffers中的数据拿过来,然后把这些数据写出到磁盘。因此,当currentBuffer被移入buffersToWrite后,就会立刻调用swap函数交换buffersToWrite和buffers,这一部交换了这两个vector中的内存指针,相当于二者交换了各自的内容,buffers变成了空的,而前面所有存有日志消息的缓冲区,则全部到了buffersToWrite中
如果此时预备缓冲区为空,说明已经被使用过,就会用newBuffer2来补充它,至此,互斥锁释放。在buffersToWrite获得了buffers的数据之后,其它线程就可以正常的调用append来添加日志消息了,因为此时buffers重置为空,并且buffersToWrite是局部变量,二者互不影响
再通过output的appedn将buffersToWrite中的内容写入中日志文件的缓冲区中
资源回收
在写出结束后bufferToWrite中缓冲区的内容已经没有价值了,但是可以废物回收,由于前面newBuffer1和newBuffer2都有可能被使用过变为空,因此可以将buffersToWrite的元素用于填充newBuffer1和2
在正常情况下currentBuffer、nextBuffer、newBuffer1和newBuffer2是不需要二次分配空间的,因为它们之间通过buffers和buffersToWrite恰好可以构成一个资源使用环:前端将currentBuffer移入buffers后用nextBuffer填补currentBuffer,后端线程将新的currentBuffer再次移入buffers,然后用newBuffer1和newBuffer2去填充currentBuffer和nextBuffer,最后又从buffersToWrite中获取元素来填充newBuffer1和newBuffer2,可见,资源的消耗端在currentBuffer和nextBuffer,而资源的补充端在newBuffer1和newBuffer2,如果这个过程是平衡的,那么这4个缓冲区都无需再分配新的空间
最后调用flush将日志缓冲区中的内容写入到日志文件中
core dump后查找还未来得及写出的日志
异步日志中日志消息并不是生成后会立刻写出,而是先存放在前端缓冲区currentBuffer或前端缓冲区队列buffers中,等到合适的时机才会将缓冲区中的日志消息刷新到磁盘中,那么如果程序在中途core dump了,缓冲区中还未来得及写出的日志消息怎么找回
查看core文件,从core文件中分析原因,通过gdb看程序挂在哪里,分析前后变量找出原因
当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存状态记录下来,保存在一个文件中,这种行为就叫做Core Dump(中文有的翻译成“核心转储”)。我们可以认为 core dump 是“内存快照”,但实际上,除了内存信息之外,还有些关键的程序运行状态也会同时 dump 下来,例如寄存器信息(包括程序指针、栈指针等)、内存管理信息、其他处理器和操作系统状态和信息。core dump 对于编程人员诊断和调试程序是非常有帮助的,因为对于有些程序错误是很难重现的,例如指针异常,而 core dump 文件可以再现程序出错时的情景
定时器
通过alarm发送信号配合服务端处理SIGALRM信号实现定时机制在多线程中是不太好的,在多线程中应该尽量避免使用信号
- 信号打断了正在运行的线程,在信号处理中只能调用可重入函数,但并不是每个线程安全的函数都是可重入的
- 如果信号处理需要修改全局变量,那么被修改的变量必须的sig_atomic_t类型的,否则被打断的函数在恢复执行后可能不能立刻看到信号处理改动后的数据,因为编译器可能假定这个变量不会被他处修改从而优化了内存访问
muduo中使用Linux提供的timerfd将时间变成了一个文件描述符,该描述符在定时器超时那一刻变为可读,可以方便得融入IO多路复用中,统一事件源
Timer
对定时操作的封装,主要由定时时刻到来需要执行的回调函数、定时时刻以及是否需要重复执行三个要素组成
TimerId
用户可见类:只包含一个定时器指针以及定时器的编号
TimerQueue
定时器队列
数据结构要求能够高效组织目前未到期的Timer,能够快速根据当前时间找到已经到期的Timer,也能够高效添加和删除Timer
- 线性表
- 查找O(N)
- 二叉堆组织优先队列
- 查找O(logN),但是C++标准库中的make_heap等函数不能高效删除heap中间的某个元素
- 二叉搜索树map
- 将Timer按时间先后排序,O(logN)
- 不能直接用map<Timestamp,Timer*>,无法处理两个定时器到期时间相同的情况
- 用multimap
- 区分key:pair<Timestamp,Timer*>为key,这样子及时到期时间相同,但是地址必定不同
muduo使用平衡二叉搜索树,使用容器set管理
TimerQueue中的函数只能在所属的loop中调用所以不需要加锁,每个loop只有一个TimerQueue用于管理定时时间,在创建loop的同时TimerQueue已经创建号了,同时timerfd也已经加入poller中监听
timing wheel踢掉空闲连接
- 每个连接保存最后收到数据的时间,用一个定时器每秒遍历一遍所有连接,断开规定时间内没有活动的连接
- 全局只有一个repeated timer,但是每次timeout都需要检查所有连接,如果连接数目比较大,会耗时
- 每个连接设置一个one-shot timer,在超时的时候就断开连接;每次收到数据就更新timer
- 需要多个one-shot timer,会频繁更新timers,如果连接数目比较大,会对TimerQueue造成压力
- timing wheel
- n个桶组成的循环队列,第一个桶放1秒之后将要超时的连接,第二个桶放2秒之后将要超时的连接。每个连接收到数据就放到第n个桶,每秒的timer将第一个桶中的连接断开就可以了,并将这个桶移动到队尾
- 每次不需要检查所有的连接,只需要检查第一个桶中的连接(将任务分散)
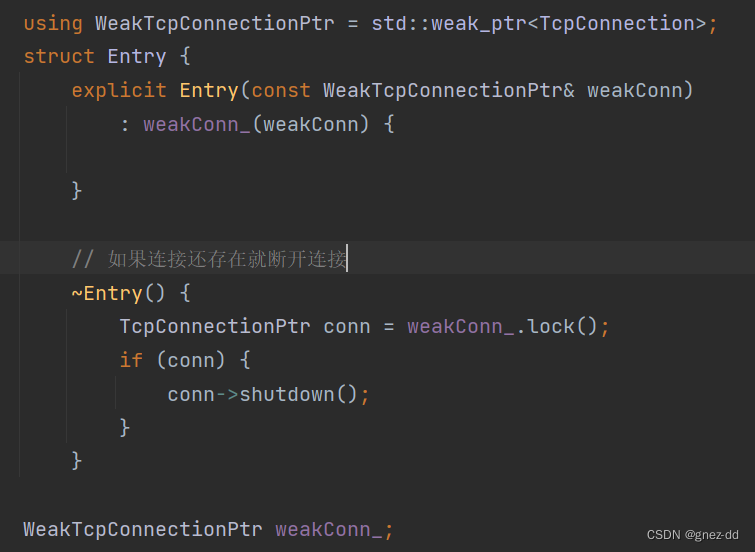
通过weak_ptr判断连接是否还存在
自定义一个结构体Entry表示连接,包含TcpConnection的weak_ptr,Entry的析构函数会判断连接是否存在,如果存在就断开连接
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kSUEMgPh-1665728911894)(C:\Users\gnezd\AppData\Roaming\Typora\typora-user-images\image-20220929142800679.png)]
并通过boost::any可以存放容易类型的数据将Entry存放到TcpConnection中
引用计数实现析构
采用引用计数方法,从连接收到数据就将EntryPtr放在对应的格子中,引用计数就增加了,当Entry的引用计数减小到零时就说明没有在任何一个格子中出现过,连接超时,Entry析构函数会断开连接
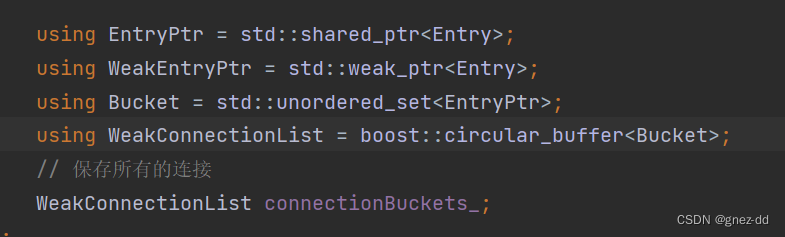
circulae_buffer
是boost实现的固定大小的环形缓冲区,当缓冲区满了后,新来的数据会覆盖调旧的数据
buffer中的元素保存Bucket,Bucket保存在一秒内所有连接的shared_ptr,对buffer进行初始化并用空填满
当有一个连接时就会将连接插入到Bucket中,每一秒都会往buffer中插入空的Bucket
给予circular_buffer的特性,现有的连接1就会自动往前滚动
连接到来
在连接建立时,以对应的TcpConnection对象conn来创建一个 Entry 对象entry,把它放到 timing wheel 的队尾。另外,我们还需要把 entry的弱引用保存到 conn的 context 里,因为在收到数据的时候还要用到 Entry,且弱引用不影响引用计数
有新消息
在收到消息时,从 TcpConnection 的 context 中取出 Entry 的弱引用,把它提升为强引用 EntryPtr,然后放到当前的 timing wheel 队尾。(提升为强引用的时候,引用计数+1)
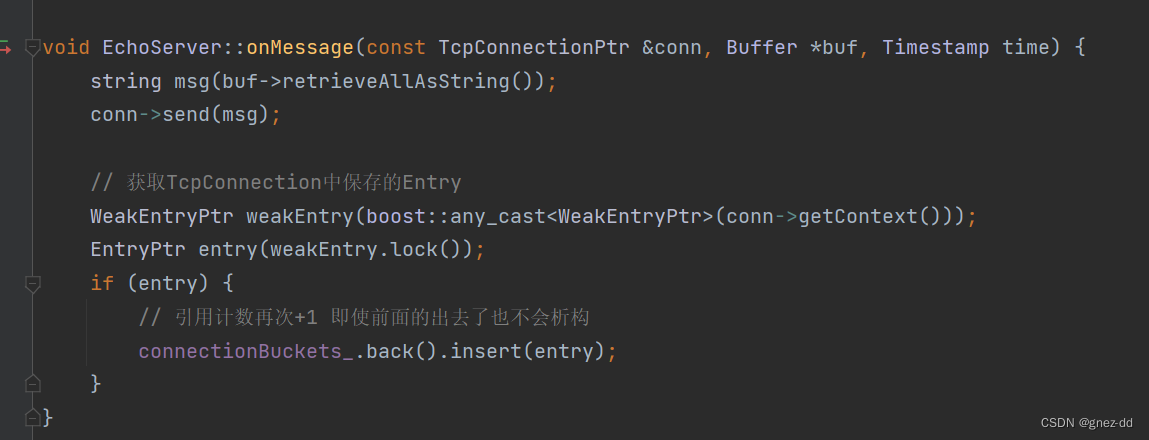
总结
每个TcpConnection有一个Context变量保存Entry的WeakPtr。因为回调机制,每个连接都需要有其关联的Entry,这里直接用WeakPtr不影响其引用计数。有了context,服务器每当收到客户端的消息时(onMessage),可以拿到与该连接关联的Entry的弱引用,再把它提升到强引用,插入到circular_buffer,这样就相当于把更新了该连接在时间轮盘里面的位置了,相应的use_count会加1